
from aip import AipSpeech
#baidu-aip
APP_ID = ' '
API_KEY = ' '
SECRET_KEY = ' '
百度AI库获取的参数
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
构造读取语音文件函数
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
识别本地文件 主函数
result = client.asr(get_file_content(r'C:\Users\1\PycharmProjects\pythonProject\record.pcm'), 'pcm', 16000, { 'lan': 'zh',})
#此处地址处必须要加r,使其成为绝对地址,要么容易字符转义出现错误
print(result)
事实证明,baidu aip 录音转文字对录音长度有限制,要求每次只能转60秒的录音文件
若想解决这个问题,初步的解决思路就是切片,将录音文件切成多个文件,分批导入
让baidu aip 去 识别它,然后分段整合起来就好。
Original: https://blog.csdn.net/jidawanghao/article/details/124342523
Author: jidawanghao
Title: python baidu语音转文字
相关阅读1
Title: 音乐音频 | 语音识别与音乐流派分类
文章目录
- 语音识别步骤
- 一、用SVM做音乐分类应用实例
* - 1、数据集:EchoNest。
- 2、代码:
- - 二、TTS(text to speech):文本转声音(可以播放中英文)
- 三、播放音频
- 四、STT(speech to text):语音转文本
- 五、麦克风语音转文字
贝尔实验室
连续语音识别 continuous speech recognizer
自动音乐分类系统Automatic
语音识别步骤
1、声波输入计算机 decoding Raw audio
2、将声波sound waves 转化为 数字 进行存储。声波是一维的,只需要等距地记录 波的高度。
3、抽样sampling ,每秒钟读取N个样品。
奈奎斯特定理:采样速度 >= 2 * 声音最高频率f_max

将声音分成多个片段,如每段20ms
4、将 数字 转化成 简单的折线图
5、计算每个 频段 的能量,为音频片段audio snippet 创建 声纹:将声音信号 画成 频谱图spectrogram。纵轴频率,横轴时间。
6、对音频片段进行切片,找出声音的字母。元音Vowel。

通过神经网络 预测每个字母的下一个字母的可能性。
音频进行 特征提取 ,取出 pitch和 MFCC,进行模型训练,训练分类器。当输入未知音频时,模型会进行预测。

音乐格式:
WMA——Windows Media、
Mp3、
wav
CD的采样率是44.1khz
; 一、用SVM做音乐分类应用实例
1、数据集:EchoNest。
2、代码:
import pandas as pd
tracks = pd.read_csv('D:/My life/music/echonest/fma-rock-vs-hiphop.csv')
print(tracks.shape)
tracks
(17734, 21)
track_idbit_ratecommentscomposerdate_createddate_recordeddurationfavoritesgenre_topgenres...informationinterestlanguage_codelicenselistenslyricistnumberpublishertagstitle01352560001NaN2008-11-26 01:43:262008-11-26 00:00:008370Rock[45, 58]...NaN2484enAttribution-NonCommercial-ShareAlike 3.0 Inter...1832NaN0NaN[]Father's Day11362560001NaN2008-11-26 01:43:352008-11-26 00:00:005090Rock[45, 58]...NaN1948enAttribution-NonCommercial-ShareAlike 3.0 Inter...1498NaN0NaN[]Peel Back The Mountain Sky21511920000NaN2008-11-26 01:44:55NaN1920Rock[25]...NaN701enAttribution-NonCommercial-ShareAlike 3.0 Inter...148NaN4NaN[]Untitled 0431521920000NaN2008-11-26 01:44:58NaN1930Rock[25]...NaN637enAttribution-NonCommercial-ShareAlike 3.0 Inter...98NaN11NaN[]Untitled 1141532560000Arc and Sender2008-11-26 01:45:002008-11-26 00:00:004055Rock[26]...NaN354enAttribution-NonCommercial-NoDerivatives (aka M...424NaN2NaN[]Hundred-Year Flood..................................................................177291550633200000NaN2017-03-24 19:40:43NaN2833Hip-Hop[21, 811]...NaN1283NaNAttribution1050NaN4NaN['old school beats', '2017 free instrumentals'...Been On177301550643200000NaN2017-03-24 19:40:44NaN2502Hip-Hop[21, 811]...NaN1077NaNAttribution858NaN2NaN['old school beats', '2017 free instrumentals'...Send Me177311550653200000NaN2017-03-24 19:40:45NaN2193Hip-Hop[21, 811]...NaN1340NaNAttribution1142NaN1NaN['old school beats', '2017 free instrumentals'...The Question177321550663200000NaN2017-03-24 19:40:47NaN2526Hip-Hop[21, 811]...NaN2065NaNAttribution1474NaN3NaN['old school beats', '2017 free instrumentals'...Roy177331552473200000Fleslit2017-03-29 01:40:28NaN2113Hip-Hop[21, 539, 811]...NaN1379NaNAttribution1025NaN0Fleslit['instrumental trap beat', 'love', 'instrument...Love In The Sky
17734 rows × 21 columns
echonest_metrics = pd.read_json('D:/My life/music/echonest/echonest-metrics.json', precise_float = True)
print(echonest_metrics.shape)
echonest_metrics
(13129, 9)
输出:
track_idacousticnessdanceabilityenergyinstrumentalnesslivenessspeechinesstempovalence020.4166750.6758940.6344760.0106280.1776470.159310165.9220.576661130.3744080.5286430.8174610.0018510.1058800.461818126.9570.269240250.0435670.7455660.7014700.0006970.3731430.124595100.2600.6216613100.9516700.6581790.9245250.9654270.1154740.032985111.5620.96359041340.4522170.5132380.5604100.0194430.0965670.525519114.2900.894072..............................131241248570.0075920.7903640.7192880.8531140.7207150.082550141.3320.890461131251248620.0414980.8430770.5364960.8651510.5479490.074001101.9750.476845131261248630.0001240.6096860.8951360.8466240.6329030.051517129.9960.496667131271248640.3275760.5744260.5483270.4528670.0759280.033388142.0090.569274131281249110.9936060.4993390.0506220.9456770.0959650.065189119.9650.204652
13129 rows × 9 columns
echo_tracks = pd.merge(echonest_metrics, tracks[['track_id', 'genre_top']], on = 'track_id')
print(echo_tracks.shape)
echo_tracks
(4802, 10)
输出:
track_idacousticnessdanceabilityenergyinstrumentalnesslivenessspeechinesstempovalencegenre_top020.4166750.6758940.6344761.062807e-020.1776470.159310165.9220.576661Hip-Hop130.3744080.5286430.8174611.851103e-030.1058800.461818126.9570.269240Hip-Hop250.0435670.7455660.7014706.967990e-040.3731430.124595100.2600.621661Hip-Hop31340.4522170.5132380.5604101.944269e-020.0965670.525519114.2900.894072Hip-Hop41530.9883060.2556610.9797749.730057e-010.1213420.05174090.2410.034018Rock.................................47971247180.4121940.6868250.8493096.000000e-100.8675430.36731596.1040.692414Hip-Hop47981247190.0549730.6175350.7285677.215700e-060.1314380.24313096.2620.399720Hip-Hop47991247200.0104780.6524830.6574987.098000e-070.7015230.22917494.8850.432240Hip-Hop48001247210.0679060.4324210.7645081.625500e-060.1044120.310553171.3290.580087Hip-Hop48011247220.1535180.6386600.7625675.000000e-100.2648470.30337277.8420.656612Hip-Hop
4802 rows × 10 columns
echo_tracks.info()
输出:
<class 'pandas.core.frame.dataframe'>
Int64Index: 4802 entries, 0 to 4801
Data columns (total 10 columns):
# Column Non-Null Count Dtype
> Original: https://blog.csdn.net/qq_44250700/article/details/120348315
> Author: Begonia_cat
> Title: 音乐音频 | 语音识别与音乐流派分类
## **相关阅读2**
## Title: 【图像分割】基于matlab萤火虫算法图像聚类分割【含Matlab源码 2106期】
## 一、萤火虫算法图像聚类分割简介
**1 萤火虫算法的基本原理<br>1.1 萤火虫算法的数学表述**
根据萤火虫算法的仿生原理,萤火虫算法的数学描述如下,萤火虫个体的相对发光强度可由式(2)确定

式中:rij为萤火虫i和j之间的空间欧几里得距离;I0为rij=0时萤火虫的发光强度,即原始发光强度,与目标函数成正比;γ为亮度衰减参数,这意味着在特定的传播介质中亮度将会衰减。
萤火虫之间的相对吸引力由式(3)得出

其中β0为两只萤火虫之间的距离为零时的相互吸引力,也是两者之间的最大吸引力数值。萤火虫i依据式(4)向比其更亮的萤火虫j移动,

原始萤火虫算法的缺点是两只萤火虫之间的信息交换受到其搜索范围的影响,萤火虫初始化的位置是随机分配的,并且萤火虫之间的独立性较大,没有相互关联;萤火虫设置的荧光素值过于离散,以致无法相对较慢地运行;其次,在萤火虫算法中,控制搜索范围的参数是随机设置的,仿真结果也是随机的。为解决萤火虫算法目前存在的问题,文中对算法进一步的改进。
**2 基于改进萤火虫算法的多阈值分割**
用萤火虫算法解决最优化问题的关键是将适当的目标函数表示为萤火虫的亮度值,在确定合适的目标函数后,萤火虫个体迭代更新位置,来获得目标函数的最优化结果。文中采用结合改进萤火虫算法的最大熵阈值方法实现多阈值微生物图像分割,并将图像的熵值计算公式作为萤火虫算法的目标函数。假设灰度图像具有l个灰度等级,范围是{0,1,2,...,l-1},l∈[1,256],倘若t为分割图像的阈值,图像被划分为前景部分d和

Hd(t)和Hb(t)分别代表目标区域和背景区域的熵值,可由下式表示:

图像的总熵值可以表示为
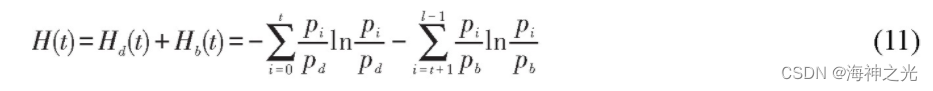
当t达到最大值t _时,即是图像分割所需的最佳阈值。如果分割一幅图像需要m个阈值,图像总的熵值可表示为
<br> 采用改进的萤火虫算法可获得关于图像分割阈值t1_,t2*,...,tm _的最优估计。基于萤火虫算法,假设分割所需的阈值数目为m,m同时也是熵函数的自变量数目,每只萤火虫的位置代表m维向量(t1,t2,...,tm)的可能分割阈值组,阈值的范围是tm∈[0,255],萤火虫的亮度是通过其位置(t1,t2,...,tm)计算的最大熵数值。依据该算法,萤火虫向更亮的近邻位置移动,移动行为遵循式(3)。相应地,由于文中分割图像有多个阈值,因此对变量R进行矢量化处理。为提高亮度,每只萤火虫都朝着一个更好的位置移动,迭代位置更新过程,最终萤火虫聚集在亮度最高的位置附近。迭代过程在熵值达到最大的阈值组合(t1_,t2*,...,tm*)附近收敛,因此,算法的最佳位置为最佳阈值。
基于改进萤火虫算法的多阈值分割实现步骤如下:
1)输入微生物图像,依据式(1)确定寻优过程的具体阈值数目m;
2)依据式(6),(8)初始化参数,包括萤火虫种群数量S、最大吸引度β0、亮度衰减参数γ、步长α和最大迭代次数Tmax;
3)将式(12)作为目标函数,随机初始化位于搜索范围内的萤火虫i的位置xi,依据目标函数计算每只萤火虫的亮度I0;
4)依据式(2)和(7)计算萤火虫i的相关亮度I以及相关吸引度β,萤火虫i的移动方向也由相关吸引度确定;
5)将式(6)和(7)分别代入式(4),更新每只萤火虫的位置,获得当前最优位置xi(t+1)和当前相对亮度I;
6)迭代执行步骤4)和5),直到达到预先设定的最大迭代次数,输出最优目标函数值H(t1,t2,...,tm)max和最优解(t1*,t2*,...,tm*);
7)根据输出的最优解对微生物图像进行多阈值分割,输出微生物多阈值分割图像。
算法流程图如图1。
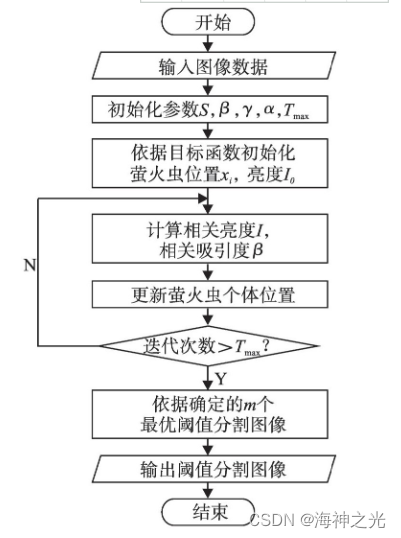
图1 改进萤火虫多阈值分割算法流程图
## <a name="_44">;</a> 二、部分源代码
clear;
clc;
warning('off');
img=imread('ant.jpg');
img=im2double(img);
% Separating color channels
R=img(:,:,1);
G=img(:,:,2);
B=img(:,:,3);
% Reshaping each channel into a vector and combine all three channels
X=[R(😃 G(😃 B(😃];
%% Starting DE Clustering
k = 6; % Number of Colors (cluster centers)
%---------------------------------------------------
CostFunction=@(m) ClusterCost(m, X); % Cost Function
VarSize=[k size(X,2)]; % Decision Variables Matrix Size
nVar=prod(VarSize); % Number of Decision Variables
VarMin= repmat(min(X),k,1); % Lower Bound of Variables
VarMax= repmat(max(X),k,1); % Upper Bound of Variables
% DE Parameters
MaxIt=100; % Maximum Iterations
nPop=k*2; % Population Size
%
beta_min=0.2; % Lower Bound of Scaling Factor
beta_max=0.8; % Upper Bound of Scaling Factor
pCR=0.2; % Crossover Probability
% Start
empty_individual.Position=[];
empty_individual.Cost=[];
empty_individual.Out=[];
BestSol.Cost=inf;
pop=repmat(empty_individual,nPop,1);
for i=1:nPop
pop(i).Position=unifrnd(VarMin,VarMax,VarSize);
[pop(i).Cost, pop(i).Out]=CostFunction(pop(i).Position);
if pop(i).Cost
## 三、运行结果


## <a name="matlab_126">;</a> 四、matlab版本及参考文献
**1 matlab版本**
2014a
**2 参考文献**
[1] 武治,孙照旋,周芳.基于改进萤火虫算法的多阈值微生物图像分割[J].安徽工业大学学报(自然科学版). 2020,37(01)
**3 备注**
简介此部分摘自互联网,仅供参考,若侵权,联系删除
> Original: https://blog.csdn.net/TIQCmatlab/article/details/126789721
> Author: 海神之光
> Title: 【图像分割】基于matlab萤火虫算法图像聚类分割【含Matlab源码 2106期】
## **相关阅读3**
## Title: 微信小程序语音识别、语音合成(微信同声传译)使用代码实例
最近在开发一款"单词大作战"的微信小程序,想增加语音识别、语音合成这2个功能。(让用户能听到单词的读音,并对比自己读音是否标准正确)。
查了一下资料,大概有几种方式:用百度翻译(需要配置后台来转发)、讯飞(听说效果最好,但好像要收费并要配置后台来转发 )。还有用微信同声传译插件。
微信同声传译插件使用最方便,目前功能还是尽善尽美,但一直在升级,是个人开发者不错的选择。用微信扫描下面小程序可以体验语音合成和语音识别的功能:

[官方的开发文档:](https://links.jianshu.com/go?to=%255Bhttps%3A%2F%2Fmp.weixin.qq.com%2Fwxopen%2Fplugindevdoc%3Fappid%3Dwx069ba97219f66d99%26token%3D251348119%26lang%3Dzh_CN%255D%28https%3A%2F%2Fmp.weixin.qq.com%2Fwxopen%2Fplugindevdoc%3Fappid%3Dwx069ba97219f66d99%26token%3D251348119%26lang%3Dzh_CN%29) [https://mp.weixin.qq.com/wxopen/plugindevdoc?appid=wx069ba97219f66d99&token=251348119&lang=zh_CN](https://links.jianshu.com/go?to=https%3A%2F%2Fmp.weixin.qq.com%2Fwxopen%2Fplugindevdoc%3Fappid%3Dwx069ba97219f66d99%26token%3D251348119%26lang%3Dzh_CN)
**使用步骤:**
1、 在微信公众平台配置,找到设置–第三方设置–插件管理–点击添加插件,
搜索微信同声传译并添加
2、 在项目根目录app.json文件中配置
"plugins": {
"WechatSI": {
"version": "0.3.4",
"provider": "wx069ba97219f66d99"
}
},
**语音合成:**
在pages的js中加入插件初始化代码
const innerAudioContext = wx.createInnerAudioContext();
innerAudioContext.autoplay = true;
const plugin = requirePlugin('WechatSI');
由于语音合成原理是微信同声传译是在同声传译后台生产录音,下载播放录音。可以在页面加载阶段生产录音,在使用的地方播放录音,就不会有延迟。
//在全局定义变量
var remoteAudio = null;
//在开始阶段加载
plugin.textToSpeech({
lang: "en_US",
tts: true,
content: word,
success: function(res) {
console.log("succ tts", res.filename)
// this.playAudio(res.filename);
remoteAudio = res.filename;
},
fail: function(res) {
console.log("fail tts", res)
}
})
},
//在实际需要使用语音合成地方
innerAudioContext.stop();
console.log("remoteAudio: " + remoteAudio);
innerAudioContext.src = remoteAudio;
innerAudioContext.play();
innerAudioContext.onError((e) => {
console.log(e.errMsg)
console.log(e.errCode)
})
**语音识别:**
在pages的js中加入插件初始化代码
//引入插件:微信同声传译
const plugin = requirePlugin('WechatSI');
//获取全局唯一的语音识别管理器recordRecoManager
const manager = plugin.getRecordRecognitionManager();
// 设置采集声音参数
const options = {
sampleRate: 44100,
numberOfChannels: 1,
encodeBitRate: 192000,
format: 'aac'
}
在 `onload()`中加入初始化代码
//识别语音
this.initRecord();
在需要加入语音识别地方加入下面代码:
//语音 --按住说话
touchStart: function(e) {
wx.vibrateShort() //按键震动效果(15ms)
manager.start(options)
this.setData({
recordState: true, //录音状态为真
tips: '松开结束',
})
},
//语音 --松开结束
touchEnd: function(e) {
// 语音结束识别
manager.stop();
this.setData({
recordState: false,
})
},
//识别语音 -- 初始化
initRecord: function() {
const that = this;
// 有新的识别内容返回,则会调用此事件
manager.onRecognize = function(res) {
console.log(res)
}
// 正常开始录音识别时会调用此事件
manager.onStart = function(res) {
console.log("成功开始录音识别", res)
}
// 识别错误事件
manager.onError = function(res) {
console.error("error msg:", res.retcode, res.msg)
}
//识别结束事件
manager.onStop = function(res) {
console.log('..............结束录音')
console.log('录音总时长 -->' + res.duration + 'ms');
console.log('语音内容 --> ' + res.result);
if (res.result == '') {
wx.showModal({
title: '提示',
content: '听不清楚,请重新说一遍!',
showCancel: false,
success: function(res) {}
})
return;
}
//下面有些代码有一些业务代码,要根据自己实际进行替换
if(res.result == this.myword){
that.setData({
content: that.myword + '读音正确' //去掉自动添加的句号
})
next();
}else{
that.setData({
recordState: false, //录音状态为真
content: that.myword +'读音不准',
})
plugin.textToSpeech({
lang: "en_US",
tts: true,
content: that.myword,
success: function(res) {
console.log("succ tts", res.filename)
},
fail: function(res) {
console.log("fail tts", res)
}
})
}
}
},
```
Original: https://blog.csdn.net/linweidong/article/details/115876413
Author: linweidong
Title: 微信小程序语音识别、语音合成(微信同声传译)使用代码实例