
T5L车载控制器使用T5L ASIC自带CAN接口与车载主机CAN通讯,省去单片机主板,可以有效降低硬件成本。本方案使用的智能屏型号为DMG10600T070_A5WTC。
DMG10600T070_A5WTC性能
- 接口资源丰富:提供2路232,1路485,1路CAN,若干IO口以及AD接口,本方案主要使用了CAN接口。
- 电容触摸屏触摸手感顺滑,交互动作流畅,透光率高达90%,画面显示通透;同时支持灵敏可调,最快 400Hz 触控打点速度。
- IPS全视角液晶屏前后左右可观察视角85°,背光寿命可达3W小时,1024*600分辨率24位RGB真彩色显示画面清晰。
- 支持WAE格式按键语音播放提示,每个按键均可触发语音词条,1 路 15bit 32Ksps PWM 数字功放驱动扬声器,节约功放成本并获得高信噪比和音质还原,板载扬声器功率为2W,人机交互立体。
- 32MB NOR Flash支持海量素材存放,包含图片、图标、字库、音乐等丰富素材文件,JPEG 压缩模式存储图片、图标,大幅度缩小素材空间占用。
- 支持RTC时钟显示,法拉电容供电,精度为±20ppm @25℃,掉电后可维持 7 天正常工作。
- PCB三防处理,外壳面板IP65防水等级满足各类型工业级使用场景。

方案展示
bilibi平台视频地址:
https://www.bilibili.com/video/bv12T4y1Q7Va
方案开源程序:
https://download.csdn.net/download/gmingxin123/85082036
更多开源方案请前往迪文开发者论坛下载。
Original: https://blog.csdn.net/gmingxin123/article/details/123981746
Author: gmingxin123
Title: T5L芯片做主控在车载控制器行业的应用
相关阅读1
Title: Swig简单实验和理解
一 问题起源
在看tensorflow的源码的时候,发现python调用c++框架是如何实现的引起了我的好奇,发现编译的时候使用的是Swig
操作环境
为了搞清楚swig使用方法,简单做了一个实验验证Swig; Swig是一个独立库可以让用户使用python调用c++程序;
环境问题
tensorflow本身在编译依赖的时候都是直接下载对应的库放在一个临时编译目录
比如我的编译路径如下,注意红色的部分每个工程编译都是一个独立的目录,其实tensorflow这样搞也有好处,多个工程之间不耦合;但是对我们验证Swig程序会有影响,因为不在标准的lib库下
/root/.cache/bazel/_bazel_root/ 014e8ed0b29435778e37e53e83f1c80c/execroot/org_tensorflow/bazel-out/k8-opt/bin/tensorflow/python/tools/inspect_checkpoint.runfiles/org_tensorflow/tensorflow/python/pywrap_tensorflow_internal.py
解决办法:
只是做测试,所以干脆暴力单独拷贝swig库测试
创建独立测试目录 /home/test_swig;拷贝可执行程序swig到上面的/home/test_swig目录,执行过程中可能会报错,直接去tensorflow路径下找对应的文件就可以了,肯定能找到的,找到后拷贝到一起的样子如下:

二 编写测试程序
1. 比如我们写一个example.c的文件
/* File : example.c */
double My_variable = 3.0;
/* Compute factorial of n */
int fact(int n) {
if (n <= 1) return 1; else n*fact(n-1); } * compute n mod m int my_mod(int n, m) { return(n % m); }< code></=>
2. 导出文件写一个example.i
/* File : example.i */
%module example
%{
/* Put headers and other declarations here */
extern double My_variable;
extern int fact(int);
extern int my_mod(int n, int m);
%}
extern double My_variable;
extern int fact(int);
extern int my_mod(int n, int m);
- 编译执行
$swig -python example.i
$gcc -c -fpic example.c example_wrap.c -I/usr/local/python36/include/python3.6m/
$gcc -shared example.o example_wrap.o -o _example.so
$python
>>> import example
>>> example.fact(4)
最后生成出的文件
so _example.so
example_wrap.c
example.py

4 . 分析讨论(验证玩一下)
(1)对比tensorlfow导出的/pywrap_tensorflow_internal.cc 和example_wrap.c发现基本一样都是3000行代码,而别地方不同;原因大家自己分析吧,我还在研究
(2)查看example.py中的代码 是在加载_example.so ;其他没啥逻辑
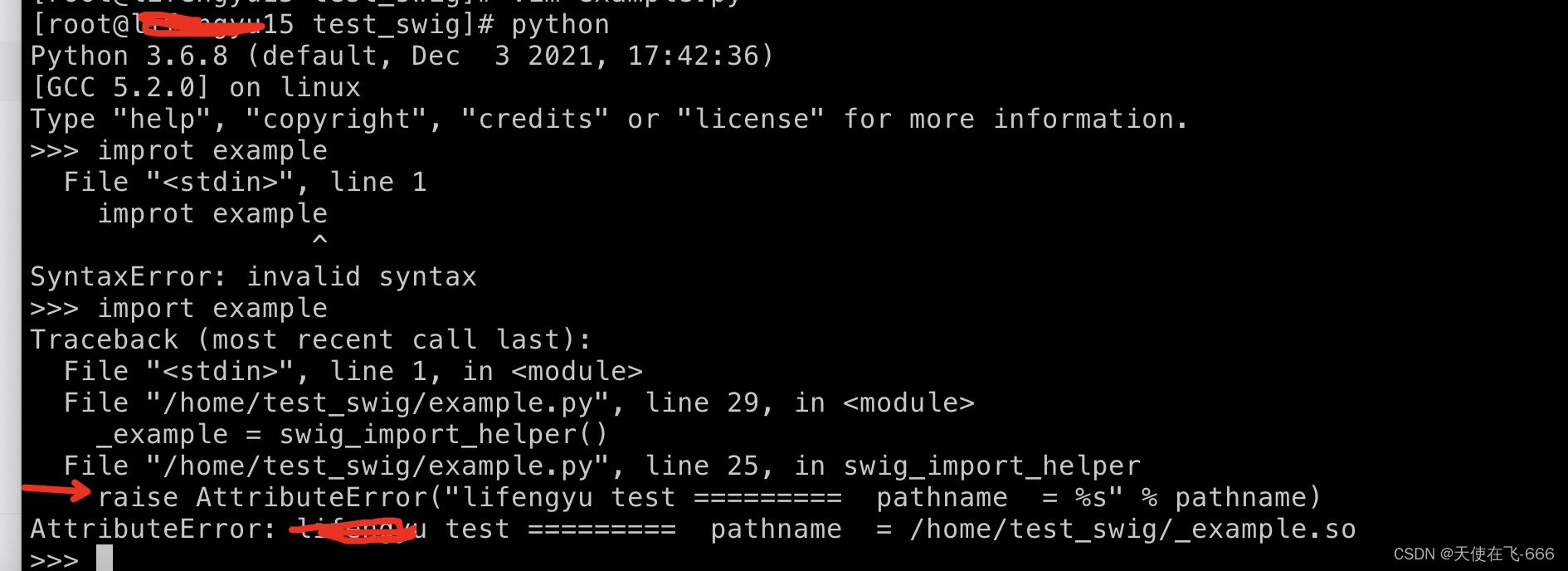
使用打印日志的方式可以显示出加载的路径 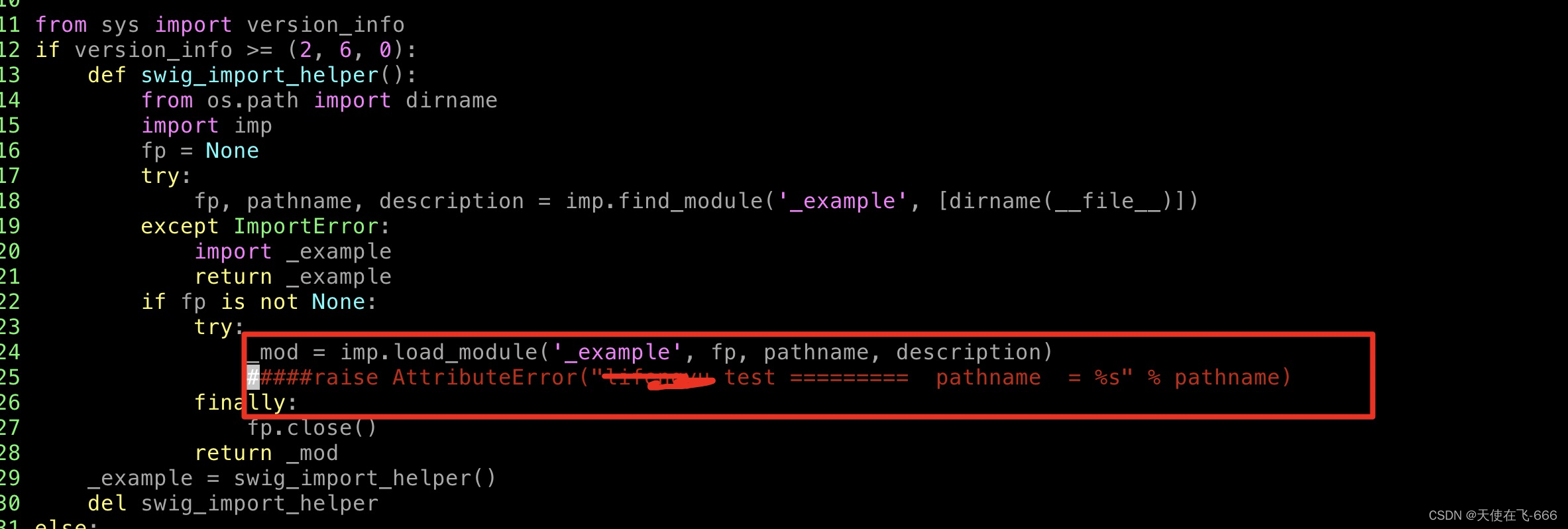
Original: https://blog.csdn.net/weixin_37614967/article/details/122266053
Author: 天使在飞-666
Title: Swig简单实验和理解
相关阅读2
Title: 无监督学习
现实生活中常常会有这样的问题:缺乏足够的先验知识,因此难以人工标注类别或进行人工类别标注的成本太高。很自然地,在建模的过程中希望计算机能代我们完成这些工作,或至少提供一些帮助。根据类别未知(没有被标记)的训练样本解决模式识别中的各种问题,称之为无监督学习。
无监督学习里典型例子是聚类。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
聚类算法一般有五种方法,最主要的是划分方法和层次方法两种。划分聚类算法通过优化评价函数把数据集分割为K个部分,它需要K作为 输人参数。典型的分割聚类算法有K-means算法, K-medoids算法、CLARANS算法。层次聚类由不同层次的分割聚类组成,层次之间的分割具有嵌套的关系。它不需要输入参数,这是它优于分割聚类 算法的一个明显的优点,其缺点是终止条件必须具体指定。典型的分层聚类算法有BIRCH算法、DBSCAN算法和CURE算法等。
(1)缺乏足够的先验知识,因此难以人工标注类别;
(2)进行人工类别标注的成本太高。很自然地,我们希望计算机能代我们(部分)完成这些工作,或至少提供一些帮助。
(3)一从庞大的样本集合中选出一些具有代表性的加以标注用于分类器的训练。
(4)先将所有样本自动分为不同的类别,再由人类对这些类别进行标注。
(5)在无类别信息情况下,寻找好的特征。
无监督学习方法主要有:聚类方法(层次聚类与K均值聚类)、奇异值分解(SVD)、主成分分析(PCA)、潜在语义分析(LSA)、概率潜在语义分析(PLSA)、马尔可夫蒙特卡洛法(MCMC,包括Metropolis-Hastings算法和吉布斯抽样)、潜在狄利克雷分配(LDA)、PageRank算法、非负矩阵分解(NMF)、变分推理、幂法。
目前深度学习中的无监督学习主要分为两类,一类是确定型的自编码方法及其改进算法,其目标主要是能够从抽象后的数据中尽量无损地恢复原有数据,一类是概率型的受限波尔兹曼机及其改进算法,其目标主要是使受限玻尔兹曼机达到稳定状态时原数据出现的概率最大。
确定型无监督学习主要有自编码及稀疏自编码、降噪自编码等。自编码可以看作是一个特殊的3层BP神经网络,特殊性体现在需要使得自编码网络的输入输出尽可能近似,即尽可能使得编码无损(能够从编码中还原出原来的信息)。虽然稀疏自编码可以学习一个相等函数,使得可见层数据和经过编码解码后的数据尽可能相等,但是其鲁棒性仍然较差,尤其是当测试样本和训练样本概率分布相差较大时,效果较差。为此,Vincent等人在稀疏自编码的基础上提出了降噪自编码,其基本思想是,以一定概率使输入层某些节点的值为0,此时输入到可视层的数据变为x^,隐含层输出为y,然后由重构x的输出z,使得z和x的差值尽可能的小。
概率型无监督学习的典型代表就是限制玻尔兹曼机,限制玻尔兹曼机是玻尔兹曼机的一个简化版本,可以方便地从可见层数据推算出隐含层的激活状态。
用于聚类的方法有:层次聚类、k 均值聚类、高斯混合模型。常用模型为:聚类树、K中心聚类、高斯混合模型。聚类树是为了使类内样本距离最小,K中心聚类是为了使样本与类中心距离最小,高斯混合模型是为了似然函数最大。为了达到此目的,常用的算法有启发式算法、迭代算法、EM 算法。
由于在实际机器学习过程中常用到高维数据,所以数据降维就显得尤为重要,常用到的对数据进行降维处理的方法有PCA,器模型为低维正交空间,这个模型是为了使方差最大,数据差异化最大,使用的算法为SVD。
对于话题分析方面的问题,则采取的是另一种模式,比如LSA、NMF、PLSA、LDA,对应的常常使用矩阵分解模型,利用非负矩阵分解方法使平方损失最小,而PLSA模型则是使用EM算法使似然函数大豆最大值来达成话题分析的目的。其中对于量级较大的数据,LDA模型有显著优势,因为LDA模型使基于后验概率来估计的,常常用到吉布斯抽样, 变分推理。
对与图分析则常常使用PageRank方法,利用有向图上的马尔可夫链方法达到完成平稳分布求解的目的,又称为幂法。
对于EM 算法,其使用的基本原理为迭代计算、后验概率估计,当收敛于局部最优时,模型达到最优,收敛熟读较快,比较容易实现,比较适合简单模型
变分推理适合于迭代计算、后验概率近似估计,当其收敛于局部最优时,模型最优,只不过收敛速度较慢,而且实现过程较为复杂,因此一般用于较为复杂的模型。
吉布斯抽样的基本原理为随机抽样、后验概率估计,也是当收敛于局部最优时,整个模型达到最优,只不过收敛速度较慢,但是使用方法简单容易,比较适合的问题为复杂模型。
如表所示,为无监督学习的主要算法总结。
无监督学习方法的特点
层次聚类
聚类树
类内样本距离最小
启发式算法
k 均值聚类
K中心聚类
样本与类中心距离最小
迭代算法
高斯混合模型
高斯混合模型
似然函数最大
EM 算法
PCA
低维正交空间
方差最大
SVD
话题分析
LSA
矩阵分解模型
平方损失最小
SVD
NMF
矩阵分解模型
平方损失最小
非负矩阵分解
PLSA
PLSA 模型
似然函数最大
EM 算法
LDA
LDA 模型
后验概率估计
吉布斯抽样, 变分推理
图分析
PageRank
有向图上的马尔可夫链
平稳分布求解
6. 1 聚类:层次聚类、K 均值聚类、高斯混合模型 。
层次聚类,是一种很直观的算法。顾名思义就是要一层一层地进行聚类,可以从下而上地把小的cluster合并聚集,也可以从上而下地将大的cluster进行分割,似乎一般用得比较多的是从下而上地聚集。所谓从下而上地合并cluster,具体而言,就是每次找到距离最短的两个cluster,然后进行合并成一个大的cluster,直到全部合并为一个cluster。整个过程就是建立一个树结构。
对于聚类,关键的一步是要告诉计算机怎样计算两个数据点的"相似性",不同的算法需要的"相似性"是不一样的。对于以上两组样品,给出了每个数据点的空间坐标,我们就可以用数据点之间的欧式距离来判断,距离越近,数据点可以认为越"相似"。当然,也可以用其它的度量方式,这跟所涉及的具体问题有关。
使用以下方法来判断两个类之间的距离:每个数据点独自作为一个类,它们的距离就是这两个点之间的距离。而对于包含不止一个数据点的 cluster,就可以选择多种方法了。最常用的,就是average-linkage,即计算两个cluster各自数据点的两两距离的平均值。类似的还有single-linkage/complete-linkage,选择两个cluster中距离最短或最长的一对数据点的距离作为类的距离。个人经验complete-linkage基本没用,single-linkage通过关注局域连接,可以得到一些形状奇特的cluster,但是因为太过极端,所以效果也不是太好。
层次聚类较大的优点,就是它一次性地得到了整个聚类的过程,只要得到了上面那样的聚类树,想要分多少个cluster都可以直接根据树结构来得到结果,改变 cluster数目不需要再次计算数据点的归属。层次聚类的缺点是计算量比较大,因为要每次都要计算多个cluster内所有数据点的两两距离。另外,由于层次聚类使用的是贪心算法,得到的显然只是局域最优,不一定就是全局最优,这可以通过加入随机效应解决,这就是另外的问题了。
6.2 降维:PCA
从原理上来说PCA等数据降维算法同样适用于深度学习,但是这些数据降维方法复杂度较高,并且其算法的目标太明确,使得抽象后的低维数据中没有次要信息,而这些次要信息可能在更高层看来是区分数据的主要因素。所以现在深度学习中采用的无监督学习方法通常采用较为简单的算法和直观的评价标准。
6.3 话题分析:LSA、PLSA、LDA
潜在语义分析(latent semantic analysis, LSA)是一种无监督方法,主要用于文本的话题分析,其特点是通过矩阵分解发现文本与单词之间的基于话题的语义关系。潜在语义分析是非概率的话题分析方法,将文本集合表示为 单词-文本矩阵,对该矩阵进行进行奇异值分解,从而得到 话题向量空间和 文本在话题向量空间中的表示。也可以使用矩阵的因子分解方法进行分解。
基本思想为给定一个文本,用一个向量表示该文本的"语义",向量的每一维对应一个单词,其数值为该单词在该文本中出现的频数或权值。
在机器学习领域,LDA是两个常用模型的简称:Linear Discriminant Analysis 和 Latent Dirichlet Allocation。本文的LDA仅指代Latent Dirichlet Allocation. LDA 在主题模型中占有非常重要的地位,常用来文本分类。LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,用来推测文档的主题分布。它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题分布后,便可以根据主题分布进行主题聚类或文本分类。LDA涉及到的先验知识有:二项分布、Gamma函数、Beta分布、多项分布、Dirichlet分布、马尔科夫链、MCMC、Gibs Sampling、EM算法等。
6.4 图分析:PageRank
图分析(graph analytics)的目的是发掘隐藏在图中的统计规律或潜在结构。PageRank算法是无监督学习方法,主要是发现有向图中的重要结点。给定一个有向图,定义在图上的随机游走即马尔可夫链。随机游走者在有向图上随机跳转,到达一个结点后以等概率跳转到链接出 去的结点,并不断持续这个过程。PageRank算法就是求解该马尔可夫链的平稳分布的算法。一个结点上的平稳概率表示该结点的重要性,称为该结点的PageRank值。被指向的结点越多,该结点的PageRank值就越大。被指向的结点的PageRank值越大,该结点的PageRank值就越大。PageRank值越大结点也就越重要。
6.5 矩阵分解:SVD、NMF
矩阵分解的原因(作用):矩阵填充(通过矩阵分解来填充原有矩阵,例如协同过滤的ALS算法)、清理异常值和离群点、降维和压缩(本文的目的)、个性化推荐。
矩阵分解的方法:特征值分解;PCA(Principal Component Analysis)分解,作用:降维、压缩;SVD(Singular Value Decomposition)分解,也叫奇异值分解;LDA:线性判别分析;MF(Matrix Factorization)模型,叫做矩阵分解模型。
矩阵分解种类:基本矩阵分解(bastic matrix factorization);正则化矩阵分解(regularized matrix factorization);概率矩阵分解(probabilistic matrix factorization);非负矩阵分解(non-negative matrix factorization),NMF;正交非负矩阵分解(orthogonal non-negative matrix factorization),ONMF;PMF(probabilistic matrix factorization),概率矩阵分解。
6.6 矩阵特征值求解:幂法
幂法主要用于计算矩阵的按模为最大的特征值和相应的特征向量。
实际计算时,为了避免计算过程中出现绝对值过大或过小的数参加运算,通常在每步迭代时,将向量"归一化"即用的按模最大的分量, ,去除的各个分量,得到归一化的向量,并令
由此得到下列迭代公式 :
当k充分大时,或当时,
6.7 含隐变量的概率模型学习方法:EM算法
图模型的学习可以分为两部分:一是网络结构学习,即寻找最优的网络结构。网络结构学习一般比较困难,一般是由领域专家来构建。 二是网络参数估计,即已知网络结构,估计每个条件概率分布的参数。 对于不含隐变量的参数估计,如果图模型中不包含隐变量,即所有变量都是可观测的,那么网络参数一般可以直接通过最大似然来进行估计。对于含隐变量的参数估计,如果图模型中包含隐变量,即有部分变量是不可观测的,就需要用 EM算法进行参数估计。
EM 算法是含隐变量图模型的常用参数估计方法,通过迭代的方法来最大化边际似然。 EM算法具体分为两个步骤: E步和 M步。这两步不断重复,直到收敛到某个局部最优解。 EM算法的应用例子:高斯混合模型Gaussian Mixture Model, GMM)是由多个高斯分布组成的模型,其密度函数为多个高斯密度函数的加权组合。
Original: https://blog.csdn.net/qq_39477242/article/details/121939906
Author: 0KI0
Title: 无监督学习
相关阅读3
Title: 音视频开发者的福音,快速集成AI配音能力
音视频内容创作者对剪辑应用中的AI配音需求与日俱增。它的优点很多,不光可以解决雇佣人力配音的成本以及创作者本身的口音、语言等限制,还可以大幅提升生产效率。比如,短视频的播放时间短的几十秒,长的vlog类型视频有4-5分钟,使用AI配音功能可以在短时间内实现多个剪辑需求。
HMS Core音频编辑服务(Audio Editor Kit)提供AI配音服务,帮助开发者在应用中轻松构建语音合成功能,一键输出文字即可转换语音。它支持乖萌童声,亲切女声,阳光男声,英文男声、女声等多种风格音色,还可以定制自己想要的音色。音色自然流畅,情感丰富,满足有声阅读、音频内容制作、剪辑等多种开发者关注的热门场景。
开发实战
1.开发准备
详细准备步骤可参考华为开发者联盟官网:
https://developer.huawei.com/consumer/cn/doc/development/Media-Guides/config-agc-0000001154009063?ha_source=hms1
2.编辑工程集成
2.1设置应用的鉴权信息
开发者需要通过api_key或者Access Token来设置应用鉴权信息。
- (推荐)通过setAccessToken方法设置Access Token,在应用启动时初始化设置
HAEApplication.getInstance().setAccessToken("your access token");
- 通过setApiKey方法设置api_key,在应用启动时初始化设置一次即可,无需多次设置。
HAEApplication.getInstance().setApiKey("your ApiKey");
2.2初始化环境
初始化音频编辑管理类、创建时间线以及需要的泳道。
// 创建音频编辑管理类
HuaweiAudioEditor mEditor = HuaweiAudioEditor.create(mContext);
// 初始化Editor的运行环境
mEditor.initEnvironment();
// 创建时间线
HAETimeLine mTimeLine = mEditor.getTimeLine();
// 创建泳道
HAEAudioLane audioLane = mTimeLine.appendAudioLane();
导入音乐。
// 泳道末尾添加音频资源
HAEAudioAsset audioAsset = audioLane.appendAudioAsset("/sdcard/download/test.mp3", mTimeLine.getCurrentTime());
3. AI配音功能集成
调用HAEAiDubbingEngine实现AI配音功能。
// 通过此配置类来对AI配音引擎进行配置
HAEAiDubbingConfig haeAiDubbingConfig = new HAEAiDubbingConfig()
// 设置音量
.setVolume(volumeVal)
// 设置音速
.setSpeed(speedVal)
// 设置发音人
.setType(defaultSpeakerType);
// 单个AI配音任务回调
HAEAiDubbingCallback callback = new HAEAiDubbingCallback() {
@Override
public void onError(String taskId, HAEAiDubbingError err) {
// error处理
}
@Override
public void onWarn(String taskId, HAEAiDubbingWarn warn) {}
@Override
public void onRangeStart(String taskId, int start, int end) {}
@Override
public void onAudioAvailable(String taskId, HAEAiDubbingAudioInfo haeAiDubbingAudioFragment, int i, Pair<integer, integer> pair, Bundle bundle) {
// 开始接收文件,保存成文件
}
@Override
public void onEvent(String taskId, int eventID, Bundle bundle) {
// The synthesis is complete.
if (eventID == HAEAiDubbingConstants.EVENT_SYNTHESIS_COMPLETE) {
// AI配音任务处理结束,即合成的音频数据全部处理完毕
}
}
@Override
public void onSpeakerUpdate(List<haeaidubbingspeaker> speakerList, List<string> lanList,
List<string> lanDescList) { }
};
// AI配音引擎
HAEAiDubbingEngine mHAEAiDubbingEngine = new HAEAiDubbingEngine(haeAiDubbingConfig);
// 设置AI配音任务播放过程侦听
mHAEAiDubbingEngine.setAiDubbingCallback(callback);
// 实时AI配音并播放API,text传入待转语音的文本,modeAI配音任务播放模式
String taskId = mHAEAiDubbingEngine.speak(text, mode);
// 暂停播放
mHAEAiDubbingEngine.pause();
// 恢复播放
mHAEAiDubbingEngine.resume();
// 关闭合成
mHAEAiDubbingEngine.stop();
</string></string></haeaidubbingspeaker></integer,>
Demo演示
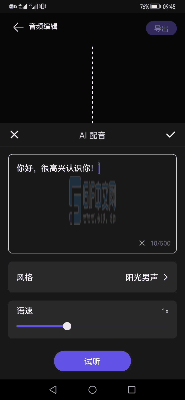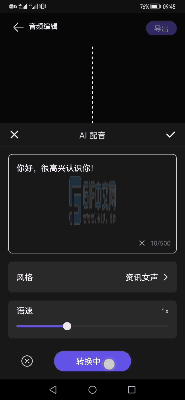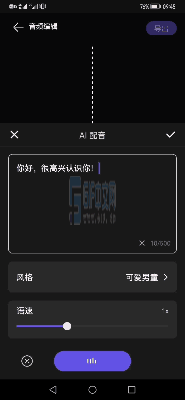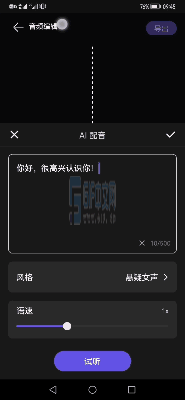
更多华为音频编辑服务详情,请参考:
服务官网:https://developer.huawei.com/consumer/cn/hms/huawei-audio-editor/?ha_source=hms1
获取指导文档:https://developer.huawei.com/consumer/cn/doc/development/Media-Guides/client-dev-0000001107465102?ha_source=hms1
了解更多详情>>
访问华为开发者联盟官网
获取开发指导文档
华为移动服务开源仓库地址:GitHub、Gitee
关注我们,第一时间了解 HMS Core 最新技术资讯~
Original: https://blog.csdn.net/HUAWEI_HMSCore/article/details/123185439
Author: 华为移动服务
Title: 音视频开发者的福音,快速集成AI配音能力