
略,一搜一大把,官网地址可以看看,具体如下:
2.1 编译opus-tools
opusinfo只能查看ogg封装格式的opus编码的音频;opusrtp可以从opus的抓包文件中提取出来opus音频,opusrtp输出的是已经封装到ogg中的音频。
输出的封装到ogg里面的音频可以直接用ffplay播放。
例子1:从opus.pcap中提取音频
opusrtp -e opus.pcap -o audio.opus
例子2:将 audio.opus 转换成 wav
opusdec audio.opus audio.wav
3.1 几个RFC文档的理解
RTP封装OPUS PACKET的过程可以参考RFC 7587,概括一句话就是一个RTP包中只能封装一个opus packet,而一个opus packet可以包含多个opus frame(RFC6716)。
从RTP中提取出的OPUS数据如果直接落盘是不能播放的,必须将其内部的opus packet按照RFC7845封装成ogg packet(一个一个的ogg packet连接起来就组成了logical ogg bitstream),然后再通过RFC3533将logical ogg bitstream封装成physical ogg bitstream。将physical ogg bitstream落盘就可以播放了。
RFC7845将 opus packet进一步封装成 ogg packet的目的主要是:精确seek,崩溃检测等等,RFC7845的第二页都讲了。
RFC3533中主要就是可以将多个logical ogg bitstream MUX到 一个physical ogg bitstream中。
3.2 audio.opus文件分析
// 第一页
4f67 6753 //OggS
00 //version
02 //header type ===> bos
0000 0000 0000 0000 //granule_position
a741 0000 //bitstream_serial_number
0000 0000 //page_sequence_number
fb69 fc11 //crc_checksum
01 // page_segments 本页有1个segment
13 // segment table 这一个segment的长度是19个字节
//id header
4f70 7573 4865 6164 // opusHead 共有19个字节
01 Version
02 channel count
0000 pre-skip
80bb 0000 48000采样率
0000
00 mapping family
// 第二页
4f67 6753 // OggS
00 //version
00 // header type ===> 表示该页不是logical opus bitstream的第一页、不是最后一页、也不是延续之前的packet
0000 0000 0000 0000 //granule_position
a741 0000 //bitstream_serial_number
0100 0000 //page_sequence_number
48d4 f428 //crc_checksum
01 // page_segments 本页有1个segment
24 // segment table 这一个segment的长度是36个字节
// comment header
4f70 7573 5461 6773 //OpusTags
14 0000 00 // Vendor String Length 小端 0x00000014 ===> 20 个字节
6f 7075 7320 7274 7020
7061 636b 6574 2064 756d 70 // Vendor String
00 0000 00 // User Comment List Length 这里为0,表示没有评论
// 第三页
4f6767 53 //OggS
00
00
80 5200 0000 0000 00 // granule_position
a7 410000 // bitstream_serial_number
02 0000 00 // page_sequence_number
8d a82c 7f // crc_checksum
18 // page_segments 本页有24个segment,说明下面 segment_table 共有24个字节,每个字节表示一个segment的长度
c9 // 表示第一个 segment 的长度是 0xc9,也就是 201 个字节,刚好对应RTP包中所包含的opus packet 的长度
ff 1ac8 c4c5
c6c1 bfbd b5ae a5a5 a2a4 9e9c 9fa5 a7a2
ff1a //到这里都是 segment_table
//第一个segment,刚好对应第一个RTP包中的所包含的opus packet
f8d0 821a b662 97f9 96d0 0e8d be38
b5a0 4ff5 75ec 4ce9 2348 c92a b039 e12e
a290 fcef 174a b620 baa6 29cb 4095 817f
d439 6b4f 57ee 5e9c a663 e908 88d4 f91e
6270 8f2a 9902 d881 5f9c 8d4c a657 e88b
deab 9c0e 1238 be7b 0b93 9d71 d854 7db5
698e e912 ecd6 6b74 fb9f 7f84 470e ac29
2c33 fa48 d9c6 2a96 a322 da5f 2296 43ee
4141 9e73 3c25 72b7 30ad 4adb 3322 8432
a3dd fbc3 d4d0 6c2d 52e6 3810 5426 12dc
2966 e689 bea0 0925 1b98 04e2 47d5 9947
921c eff3 63b7 126b 8897 9150 44f7 7101
63fa 648f 3a94 242c bc9e 21
//第二个segment
f8 d51f a7a4 ........
Original: https://blog.csdn.net/hclbeloved/article/details/115528990
Author: hclbeloved
Title: 从RTP包中分析OPUS码流
相关阅读1
Title: GPU的使用说明
查看显卡信息
!nvidia-smi
计算设备
import tensorflow as tf
tf.device('/CPU:0'), tf.device('/GPU:0'), tf.device('/GPU:1')
查询GPU数量
len(tf.config.experimental.list_physical_devices('GPU'))
张量与GPU
我们可以查询张量所在的设备。 默认情况下,张量是在CPU上创建的。
x = tf.constant([1, 2, 3])
x.device
存储在GPU上
我们需要确保不创建超过GPU显存限制的数据。
with try_gpu():
X = tf.ones((2, 3))
假设你至少有两个GPU,下面的代码将在第二个GPU上创建一个随机张量。
with try_gpu(1):
Y = tf.random.uniform((2, 3))
with try_gpu(1):
Z = X
print(X)
print(Z)
现在数据在同一个GPU上(Z和Y都在),我们可以将它们相加。
假设变量Z已经存在于第二个GPU上。 如果我们仍然在同一个设备作用域下调用Z2 = Z会发生什么? 它将返回Z,而不会复制并分配新内存。
with try_gpu(1):
Z2 = Z
Z2 is Z
神经网络与GPU
类似地,神经网络模型可以指定设备。 下面的代码将模型参数放在GPU上。
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
net = tf.keras.models.Sequential([
tf.keras.layers.Dense(1)])
当输入为GPU上的张量时,模型将在同一GPU上计算结果。
net(X)
让我们确认模型参数存储在同一个GPU上。
net.layers[0].weights[0].device, net.layers[0].weights[1].device
所有的数据和参数都在同一个设备上, 我们就可以有效地学习模型
- 我们可以指定用于存储和计算的设备,例如CPU或GPU。默认情况下,数据在主内存中创建,然后使用CPU进行计算。
- 深度学习框架要求计算的所有输入数据都在同一设备上,无论是CPU还是GPU。
- 不经意地移动数据可能会显著降低性能。一个典型的错误如下:计算GPU上每个小批量的损失,并在命令行中将其报告给用户(或将其记录在NumPy ndarray中)时,将触发 全局解释器锁,从而使所有GPU阻塞。最好是为GPU内部的日志分配内存,并且只移动较大的日志。
Original: https://blog.csdn.net/YUNFanZ/article/details/122771254
Author: 林觉棉
Title: GPU的使用说明
相关阅读2
Title: 聚类(六)—— 聚类评估
六、聚类评估
聚类评估用于对在数据集上进行聚类的可行性和被聚类方法产生的结果的质量进行评估。聚类评估主要包括以下任务。
1.估计聚类趋势
2.确定数据集中的划分簇数
3.测定聚类质量
聚类趋势的估计



(3)

如果D是均匀分布的,H接近0.5。
聚类簇数的确定
找出正确的簇数依赖于数据集分布的形状和尺度,也依赖于用户要求的聚类分辨率。有许多估计簇数的可能方法。这里简略介绍几种简单但流行和有效的方法。

它基于如下观察:增加簇数有助于降低每个簇的簇内方差之和。这是因为有更多的簇可以捕获更细的数据对象簇,簇中对象之间更为相似。然而,如果形成太多的簇,则降低簇内方差和的边缘效应可能下降,因为把一个凝聚的簇分裂成两个簇只能使簇内方差和的稍微降低。因此,一种选择正确的簇数启发式方法是使用簇内方差和关于簇数曲线的拐点。
聚类质量的测定
1.外在方法
有许多度量(如熵、纯度、精度、召回率和F度量)用来评估分类模型的性能。对于分类,度量预测的类标号与实际类标号的对应程度。但是这些度量通过使用簇标号而不是预测的类标号,不需要做较大的改变。
兰德系数RI 和ARI:
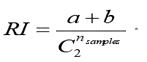
a表示表示在实际类别信息与聚类结果中都是同类别的元素对数,b表示在实际类别信息与聚类结果中都是不同类别的元素对数,分母表示数据集中可以组成的总元素对数。
兰德系数的值在[0,1]之间,当聚类结果完美匹配时,兰德系数为1。对于随机结果,RI并不能保证分数接近零。为了实现"在聚类结果随机产生的情况下,指标应该接近零",调整兰德系数(Adjusted rand index)被提出,它具有更高的区分度。
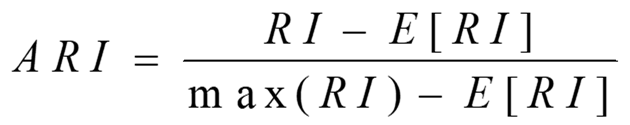
ARI取值范围为[-1,1],负数代表结果不好,值越大意味着聚类结果与真实情况越吻合。ARI可用于聚类算法之间的比较。
sklearn中的ARI计算
from sklearn import metrics
labels_true = [0,0,0,1,1,1]
labels_pred = [0,0,1,1,2,2]
print(metrics.adjusted_rand_score(labels_true,labels_pred))
0.24242424242424243
2.内在方法
内在方法用于没有基准可用时的聚类质量评估,通过考察簇的分离情况和簇的紧凑度进行聚类评估。


sklearn中通过sklearn.metrics.silhouette_score()方法计算聚类的轮廓系数。
对Iris数据聚类并计算轮廓系数。
import numpy as np
from sklearn.cluster import KMeans
from sklearn import metrics
from sklearn.metrics import silhouette_score
from sklearn.datasets import load_iris
X = load_iris().data
kmeans_model = KMeans(n_clusters=3,random_state=1).fit(X)
labels = kmeans_model.labels_
metrics.silhouette_score(X,labels,metric='euclidean')
0.5528190123564091
Original: https://blog.csdn.net/shi_jiaye/article/details/119840606
Author: shi_jiaye
Title: 聚类(六)—— 聚类评估
相关阅读3
Title: MacOS下使用conda安装TensorFlow 并在pycharm中使用(亲测成功)
以下内容参考:
一、下载tensorflow文件资源
参考1
二、安装TensorFlow
注:文章里的要在python=3.8时使用
/Users/dulei/Desktop/software/tensorflow_miniconda_macos_package下
/bin/bash ./Miniforge3-MacOSX-arm64.sh
miniforge3安装位置
/Users/dulei/miniforge3
三、创建虚拟环境1
conda create -n tensorflow_env2 python=3.8
激活虚拟环境
conda activate tensorflow_env2
此目录下,/Users/dulei/Desktop/software/tensorflow_miniconda_macos_package/tensorflow_macos/arm64
并激活环境
libs="/Users/dulei/Desktop/software/tensorflow_miniconda_macos_package/tensorflow_macos/arm64/"
env="/Users/dulei/miniforge3/envs/tensorflow_env1"
pip install --upgrade --no-dependencies --force numpy-1.18.5-cp38-cp38-macosx_11_0_arm64.whl grpcio-1.33.2-cp38-cp38-macosx_11_0_arm64.whl h5py-2.10.0-cp38-cp38-macosx_11_0_arm64.whl
pip install absl-py astunparse flatbuffers gast google_pasta keras_preprocessing opt_einsum protobuf tensorflow_estimator termcolor typing_extensions wrapt wheel tensorboard typeguard
pip install --upgrade --force --no-dependencies tensorflow_addons-0.11.2+mlcompute-cp38-cp38-macosx_11_0_arm64.whl
pip install --upgrade --force --no-dependencies tensorflow_macos-0.1a0-cp38-cp38-macosx_11_0_arm64.whl
创建虚拟环境2(快速版)
conda create -n tensorflow0330 python=3.8//任意路径下
conda activate tensorflow0330
//在/Users/dulei/Desktop/software/tensorflow_miniconda_macos_package/tensorflow_macos/arm64下执行
libs="/Users/dulei/Desktop/software/tensorflow_miniconda_macos_package/tensorflow_macos/arm64/"
env="/Users/dulei/miniforge3/envs/tensorflow_env1"
pip3 install --upgrade --no-dependencies --force grpcio-1.33.2-cp38-cp38-macosx_11_0_arm64.whl h5py-2.10.0-cp38-cp38-macosx_11_0_arm64.whl
pip3 install absl-py astunparse flatbuffers gast google_pasta keras_preprocessing opt_einsum protobuf tensorflow_estimator termcolor typing_extensions wrapt wheel tensorboard typeguard
pip3 install --upgrade --force --no-dependencies tensorflow_addons-0.11.2+mlcompute-cp38-cp38-macosx_11_0_arm64.whl
pip3 install --upgrade --force --no-dependencies tensorflow_macos-0.1a0-cp38-cp38-macosx_11_0_arm64.whl
激活环境
conda activate tensorflow_env2
import tensorflow as tf
print(tf.__version__)
(base) dulei@duleideMacBook-Pro 代码 % conda activate tensorflow_env2
(tensorflow_env2) dulei@duleideMacBook-Pro 代码 % python tensorflow_test.py
2.4.0-rc0
输出版本号
2. 命令行
(tensorflow_env2) dulei@duleideMacBook-Pro arm64 % python
Python 3.8.11 (default, Aug 16 2021, 12:04:33)
[Clang 12.0.0 ] :: Anaconda, Inc. on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow
>>>>
没有错误提示
四、在pycharm中使用环境
/Users/dulei/miniforge3/envs/tensorflow_env2/bin/python3
Original: https://blog.csdn.net/qq_42771487/article/details/123585458
Author: 萌的咋会有
Title: MacOS下使用conda安装TensorFlow 并在pycharm中使用(亲测成功)