

导读: 随着全球数据量的不断增长,越来越多的业务需要支撑高并发、高可用、可扩展、以及海量的数据存储,在这种情况下,适应各种场景的数据存储技术也不断的产生和发展。与此同时,各种数据库之间的同步与转化的需求也不断增多,数据集成成为大数据领域的热门方向,于是SeaTunnel应运而生。SeaTunnel是一个分布式、高性能、易扩展、易使用、用于海量数据(支持实时流式和离线批处理)同步和转化的数据集成平台,架构于Apache Spark和Apache Flink之上。本文主要介绍SeaTunnel 1.X在交管行业中的应用,以及其中如何实现从Oracle数据库把数据增量导入数仓这样一个具体的场景。
今天的介绍会围绕下面六点展开:
- SeaTunnel简介
- SeaTunnel应用场景
- 相关业务痛点
- 选择SeaTunnel的原因
- 具体实现方案
- 具体实现流程
--
01 SeaTunnel简介
下面对SeaTunnel从产品功能,技术特性、工作流程、环境依赖、用户使用等方面做一个总体的介绍。
1. Apache SeaTunnel整体介绍
互联网行业数据量非常大,对性能还有其他各方面的技术要求都非常高,在笔者所在的交管行业中,情况就不太一样,各方面的要求也没有互联网行业那么高,在具体的数据集成应用中,主要是使用SeaTunnel1.X版本。
上图所示内容引用了Apache SeaTunnel官网中的介绍。
Apache Spark对于分布式数据处理来说是一个伟大的进步,但是直接使用Spark框架还是有一定门槛的,SeaTunnel这个产品把业界使用Spark的优质经验固化到了其中,明显降低了学习成本,加快分布式数据处理能力在生产环境中落地。在SeaTunnel2.X版本中,除了Spark,也增加了对Flink的支持。
除此之外,SeaTunnel还可以较好的解决实际业务场景中碰到的下列问题:
- 数据丢失与重复
- 数据集成中任务堆积与延迟
- 数据同步较低的吞吐量
- Spark/Flink应用到生产环境周期较长、复杂度较高
- 缺少应用运行状态的监控
2. Apache SeaTunnel技术特性
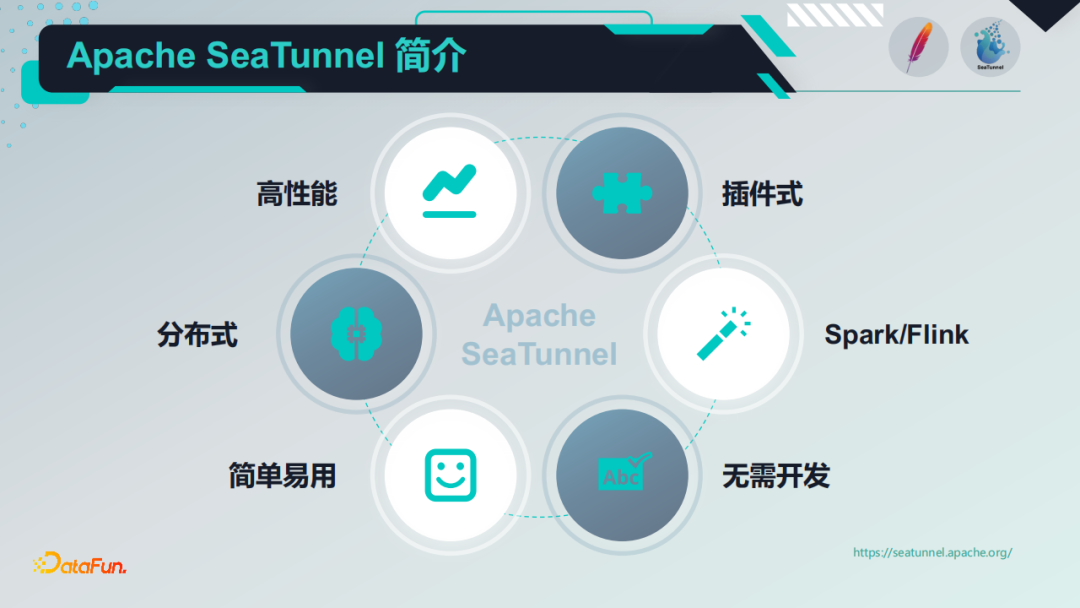
SeaTunnel具备如上图所示的技术特性:
- 简单易用,开发配置简单、灵活,无需编码开发,支持通过SQL进行数据处理和聚合,使用成本低
- 分布式,高性能,经历大规模生产环境使用和海量数据检验,成熟稳定
- 模块化和插件化,内置丰富插件,并且可以开发定制个性化插件,支持热插拔,具备高扩展性
- 使用Spark/Flink作为底层数据同步引擎使其具备分布式执行能力
3. Apache SeaTunnel工作流程
SeaTunnel的架构和整个工作流程如下图所示,Input/Source [数据源输入] -> Filter/Transform [数据处理] -> Output/Sink [结果输出],数据处理流水线由多个过滤器构成,以满足多种数据处理需求。如果用户习惯了SQL,也可以直接使用SQL构建数据处理管道,更加简单高效。目前,SeaTunnel支持的过滤器列表也在扩展中。
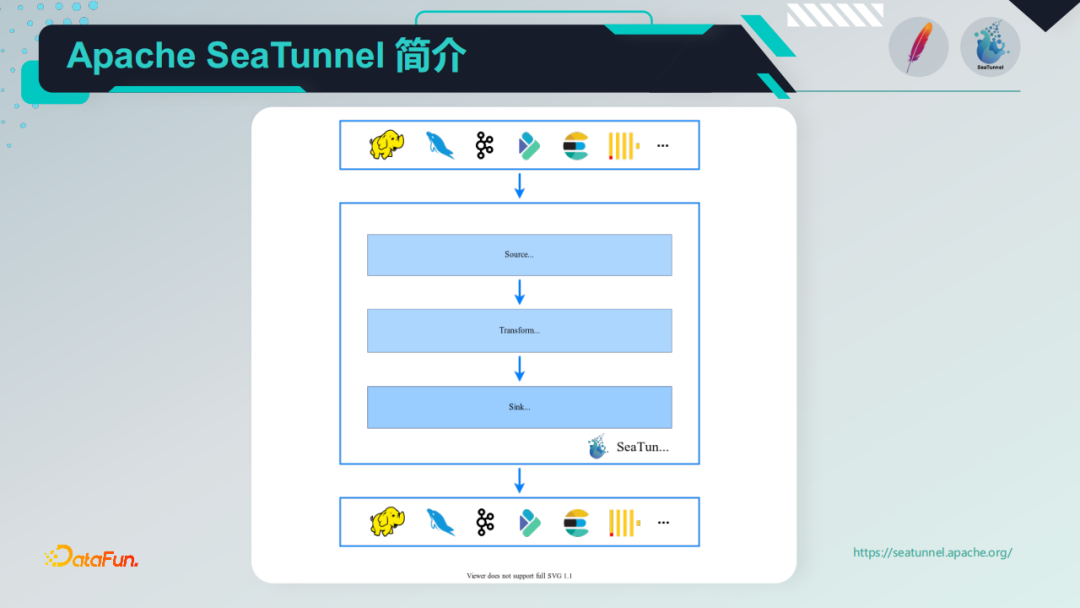
在插件方面,SeaTunnel已支持多种Input/Sink插件,同时也支持多种Filter/Transform处理插件,整体上基于系统非常易于扩展,用户还可以自行开发数据处理插件,具体如下:
- I *nput/Source 插件
Fake, File, Hive/Hdfs, Kafka, Jdbc, ClickHouse, TiDB, HBase, Kudu, S3, Socket, 自行开发的Input插件
- *Filter/Transform 插件
Add, Checksum, Convert, Date, Drop, Grok, Json, Kv, Lowercase, Remove, Rename, Repartition, Replace, Sample, Split, Sql, Table, Truncate, Uppercase, Uuid, 自行开发的Filter/Transform插件
- *Output/Sink 插件
Elasticsearch, File, Hdfs, Jdbc, Kafka, Mysql, ClickHouse, Stdout, 自行开发的Output 插件
4. Apache SeaTunnel环境依赖
SeaTunnel1.X支持Spark计算引擎,SeaTunnel2.X目前支持Spark/Flink两种计算引擎,在笔者的实际项目中使用的是SeaTunnel1.X版本。

5. Apache SeaTunnel用户使用情况
目前有很多公司都在使用SeaTunnel,其中不乏大型公司,例如:中国移动、腾讯云、今日头条、还有笔者所在的中电科。

--
02 SeaTunnel应用场景
SeaTunnel特别适合以下场景使用:
- 海量数据集成和ETL
- 海量数据聚合
- 多源数据处理
下面主要介绍SeaTunnel在交管行业中的应用。
1. 交管行业数据简介
在交管行业中,数据主要包括驾驶人、车辆相关的数据,平时在道路上发生的一些交通警情数据,交通违法数据,机动车登记信息,执勤执法的数据,交通事故以及其他一些互联网数据,这些数据的量不是很大,另外还有卡口过车、车辆GPS数据,这两种数据的数据量都比较大,例如一些省会城市,每秒钟至少有几千条过车数据,这些数据都是属于交管行业内的数据。

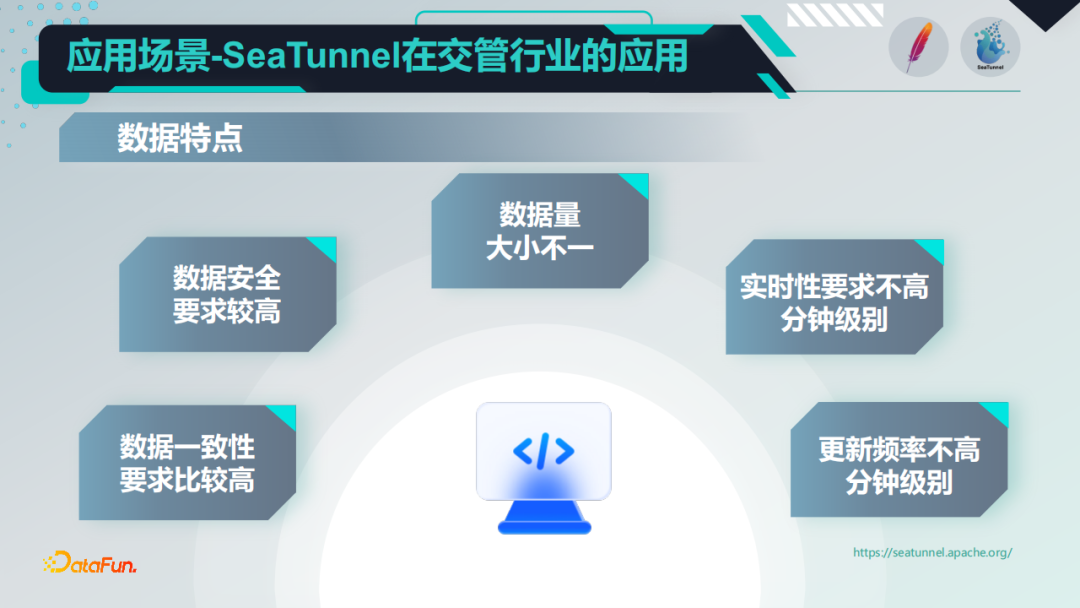
2. 交管行业数据特点
交管行业数据,跟互联网行业的数据还是有很大区别的,首先这些数据的体量大小不一,并且分布在内部的公安网以及智能专网,这两个网之间是物理隔离的,我们需要把这些数据在两个网络之间转移,在这个过程中,还要做一些数据处理。其次,在数据处理实时性方面的要求,并不是非常高,数据的更新频率也不是很高。然后,在数据安全方面,要求比较高,数据是不能丢的,同时对保密性要求也比较高,所以具体的数据也不能展示出来。
--
03 相关业务痛点
1. 数据抽取限制较多
在做业务的过程中,会有一些业务痛点,首先因为交管行业是政府行业,基本各个子平台的数据都是存储在Oracle数据库中的,我们需要把数据从Oracle数据库中抽取到我们的数仓里面,出于安全性的考虑,无法得到用户级别的权限,我们只能通过一些视图级别的用户权限去处理数据,对于数据源表结构的变更也无法及时知晓。其次,会话数是受到限制的,多线程抽取数据的话,如果会话数达到上限,连接就会受到影响,而且这个分配的用户也同时会用于其他用途。最后,我们在处理一些增量数据的时候,一般情况下需要一个增量列,用于保持一个增量更新,很多时候,是没办法确定哪些列可以作为增量列的。以上就是在做业务的过程中,经常会遇到的一些问题,下图也把这些问题列举了出来。

--
04 选择SeaTunnel的原因
最初的时候,做数据处理、数据抽取的时候,并没有使用SeaTunnel,而是使用Apache NiFi,这个工具功能比较强大而且全面,但是NiFi中用于数据处理的处理器比较多,而且数据处理链路中要做很多转换,所以需要对NiFi里面的各种组件要非常熟悉,对使用者的要求也比较高。
1. SeaTunnel的优势
我们一开始也用Spark程序做数据处理,对大数据相关人员的要求比较高,我们这边大数据人员比较少,有时处理一些新的需求的时候,会比较繁忙。如果不需要通过编码,而是直接使用工具,进行简单的配置就能实现的话,会带来较大的便利和效率的提高。

前面在SeaTunnel的介绍中,已经讲到SeaTunnel是比较易于使用的,安装部署方便,开箱即用,执行效率很高,因为它是分布式的,可以应用整个集群资源来做数据处理工作。
SeaTunnel无需编程,只要做简单的配置,并且它的Source和Sink都比较丰富,并且可以自己根据接口开发需要的插件,对数据源的权限要求也不高。
更加重要的是,SeaTunnel是首个进入Apache孵化的国人开源数据集成平台。
2. SeaTunnel的安装部署

如上图所示是SeaTunnel官方部署文档,只需要简单几步,就可以把SeaTunnel安装到我们的环境之中,然后就可以使用了。
3. SeaTunnel配置文件
下图所示是一个配置文件的示例,这个配置文件是SeaTunnel1.X版本的一个配置,一个完整的SeaTunnel配置包含spark, input, filter, output四部分,其中spark是spark相关的配置,例如,启动多少个executor,每个 executor使用多少核数的CPU,多少内存等,input可配置任意的input插件及其参数,具体参数随不同的input插件而变化,filter可配置任意的filter插件及其参数,具体参数随不同的filter插件而变化,filter中的多个插件按配置顺序形成了数据处理的pipeline, 上一个filter的输出是下一个filter的输入,通过input插件把数据取出,成为了spark里面的一个数据集,然后filter插件会对这个数据集做一些转换操作,output可配置任意的output插件及其参数,具体参数随不同的output插件而变化,filter处理完的数据,会发送给output中配置的每个插件

4. SeaTunnel插件支持
如下图所示,SeaTunnel支持的插件非常丰富,日常所能用到的基本都有。

这里面着重介绍一下filter插件中的sql插件,这个插件非常灵活,在用sql插件做转换操作时,只要是sparksql里面支持的函数等内容,都可以在这里使用,然后再output到目标数据存储,例如HDFS、Kafka、ES、Clickhouse等。
--
05 具体实现方案
接下来讲一下具体的实现方案,在我们具体的业务中,如何把这些行业数据从智能专网直接抽取到公安网中,这里会涉及到数据的增量更新。
1. 数据增量更新具体实现
当需要实现一个增量更新的时候,首先就是增量列的选择,之前提到原先是用NiFi来做增量更新,但是对增量列的支持不是特别好,尤其是对日期类型的支持不是很好。但是SeaTunnel对增量列的支持不受列的类型限制,可以比较灵活的进行选择。

2. 具体方法
实际业务当中,选取了记录的更新时间列作为增量列,每次数据抽取过来,会记录增量列的最大值,下次数据抽取时,可以从这个位置继续抽取数据,这个也是受以前写spark程序的启发,把checkpoint存储在HDFS里面。当然,增量列的选择,在实际应用中,除了更新时间,增量ID以外,还有其他业务字段可以做为增量列,增量列的选择一定是根据真正的业务需求,实时的程度和粒度来决定的。
--
06 具体实现流程
做数据增量更新,最重要的是实现的思路,接下来详细描述一下具体实现过程。
1. 确定运算资源
首先,如下图所示,先要确定计算资源,这里使用了spark,并且针对spark做了相关的配置。

2. 确定数据来源
选择一个增量列,对增量列每次产生的最大值(checkpoint),保存在HDFS一个具体的目录下。这里input插件选择HDFS,每次产生的那个增量数据,指向HDFS的一个具体路径下面,input插件有个通用参数叫做result_table_name,当指定result_table_name时,处理后的数据,会被注册为一个可供其他插件直接访问的数据集,或者被称为临时表。当增量列的最大值保存到HDFS之后,需要取出时,会保存在result_table_name指定的表中。接下来因为是从Oracle数据库中取数据,所以设置相应的Jdbc。当数据量比较大的时候,还可以指定分区列,这样的话,数据处理的效率会提高,详细配置,如下图所示。

3. 数据转换
下图所示是必要的数据转换,在实际业务中,需要做一个过滤操作,取出大于最大更新时间的数据,convert插件里面做的是中间的一些数据类型转换操作,最后使用了一个sql插件,用于记录本次取到的数据的一个最大值,用于下次取数的比较。

4. 数据输出
下图所示的是数据处理后的输出,也就是output插件对应的配置,具体是把数据抽取到Clickhouse里面。然后数据集里面,那个更新列的最大值,通过追加模式,写回到HDFS中,供下次使用。
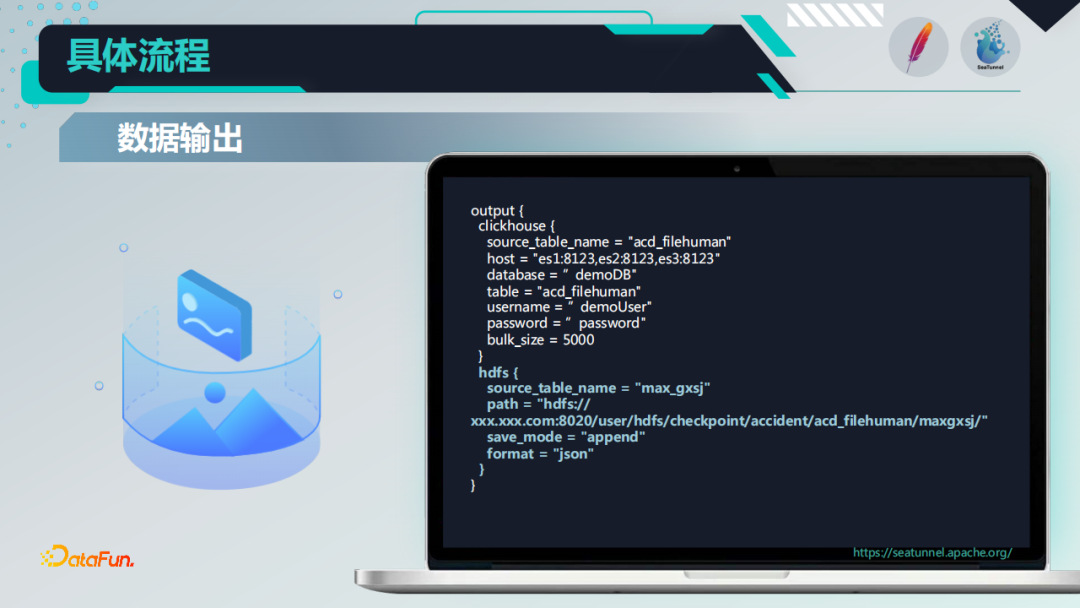
5. 脚本和调度执行
整个过程是通过下图所示的shell脚本来做的,通过nohup后台执行的方式,利用Crontab进行调度执行,因为在我们实际的业务中,对定时调度的要求不是很高,所以可以采用Crontab或者开源的Dolphin Scheduler都是可以满足的。
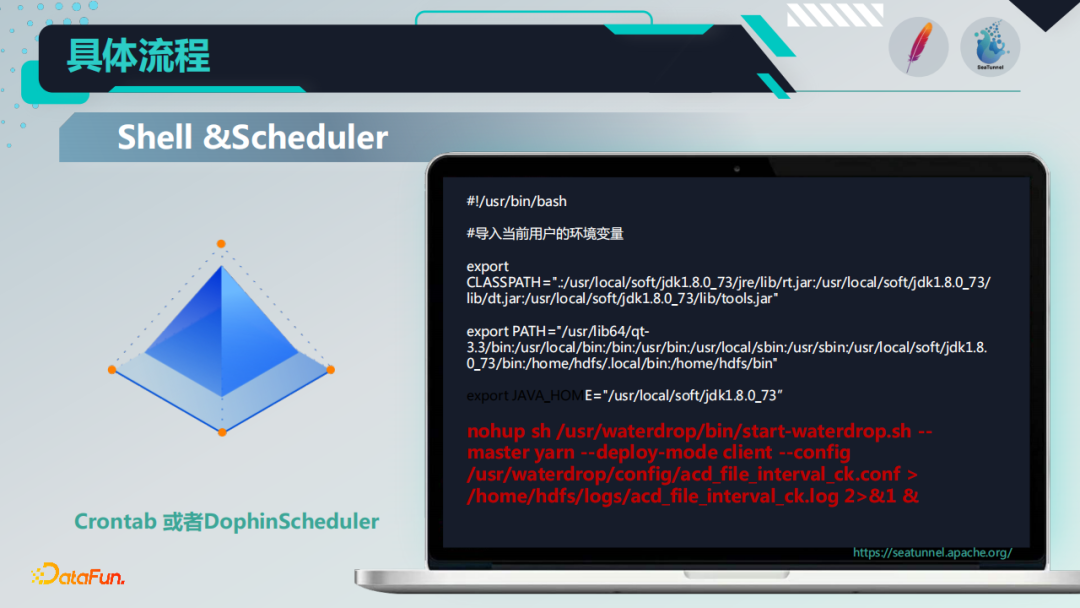
下面的截图,是实际运行过程中,产生在HDFS上的增量文件,Crontab调度脚本,以及执行过程中产生的一些Yarn任务列表。
在上述整体数据处理过程中,由于实际情况的限制,尤其我们的数据源是高度受限的Oracle数据库。但是对于很多传统公司,如果老系统是以Oracle为主,并且掌控力度比较大的话,现在想做数据架构升级,需要迁移Oracle中的数据,那么可以采用CDC读取日志或者触发器的方式,把数据变化写入到消息队列里面,通过SeaTunnel就可以很容易的把数据实时写入到其他异构的数据库。
本文首发于微信公众号"DataFunTalk"。
Original: https://www.cnblogs.com/datafuntalk/p/16290103.html
Author: DataFunTalk
Title: 陈胡:Apache SeaTunnel实现 非CDC数据抽取实践
相关阅读1
Title: 虚拟机ping不通的几种原因及解决办法
镜像下载、域名解析、时间同步请点击阿里云开源镜像站
一:虚拟机宿主机互ping不通
问题一:防火墙
略去,建议主机和宿主机都关闭防火墙,并关闭seLinux(Linux的安全系统)
问题二:网卡未生效
表现
输入命令 ifcongig,若输出的网卡信息不含inet [ip地址],则说明网卡未生效
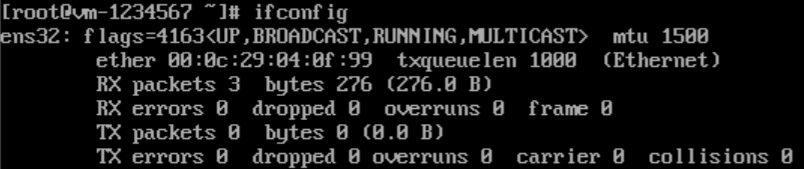
网卡生效后会变成
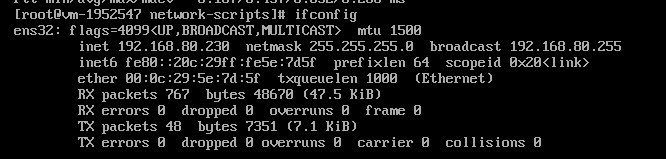
解决办法
这是由于网卡配置文件错误导致的。CentOS7系统网卡配置文件路径:
/etc/sysconfig/network-scripts/ifcfg-[网卡名]
网卡名为ifconfig命令输出信息最左列
eg:/etc/sysconfig/network-scripts/ifcfg-ens32
配置文件内容:
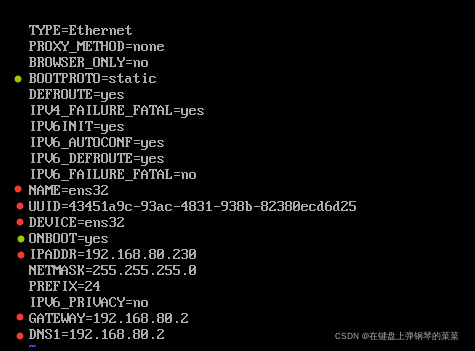
如果你还未修改过这个文件,那么你只需要加入与IP地址有关的IPADDR NETMASK GATEWAY DNS1,并最好将绿点配置修改,实现开机启动。
如果你有多个网卡,红点为各个网卡配置不同的项。如果UUID丢失,可通过uuidgen命令重新生成。笔者由于通过cp复制ens32网卡得到ens34网卡时误加了同步选项-s,导致ens32的UUID丢失,修改后网卡生效。
问题三:IP地址,网关,DNS设施
具体如何设置网上教程很多。简单来说,就是
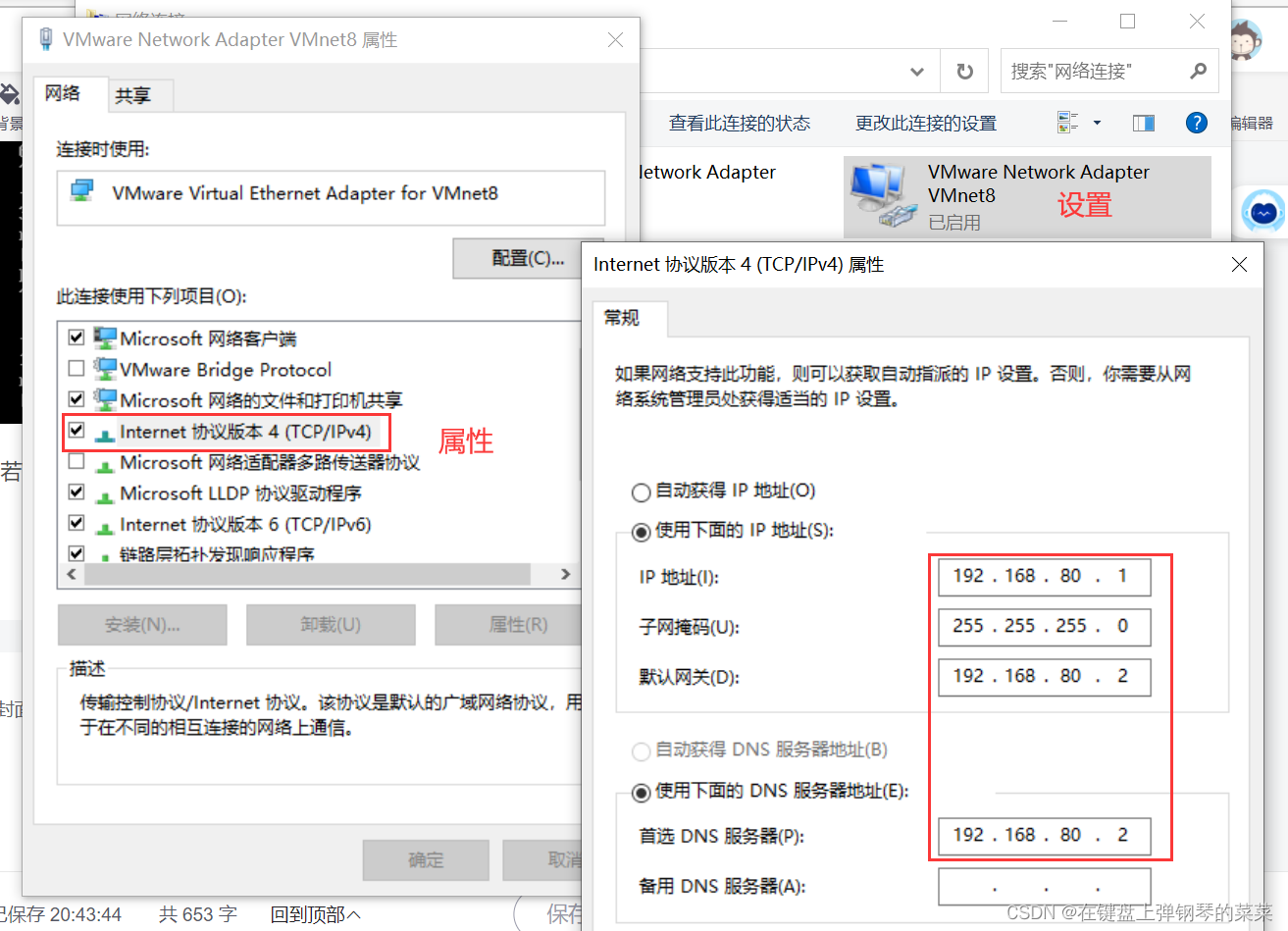
- Windows虚拟网卡VMnet8的IP地址 和 VMWare虚拟网卡VMnet8的子网IP地址 和 网卡设置文件的IPADDR在同一个局域网下
- Windows虚拟网卡VMnet8的网关和DNS地址 和 VMWare虚拟网卡的网关和DNS地址一致
- 以上所有都在同一个局域网下(IP地址的第三个数,这里是80)
宿主机设置:
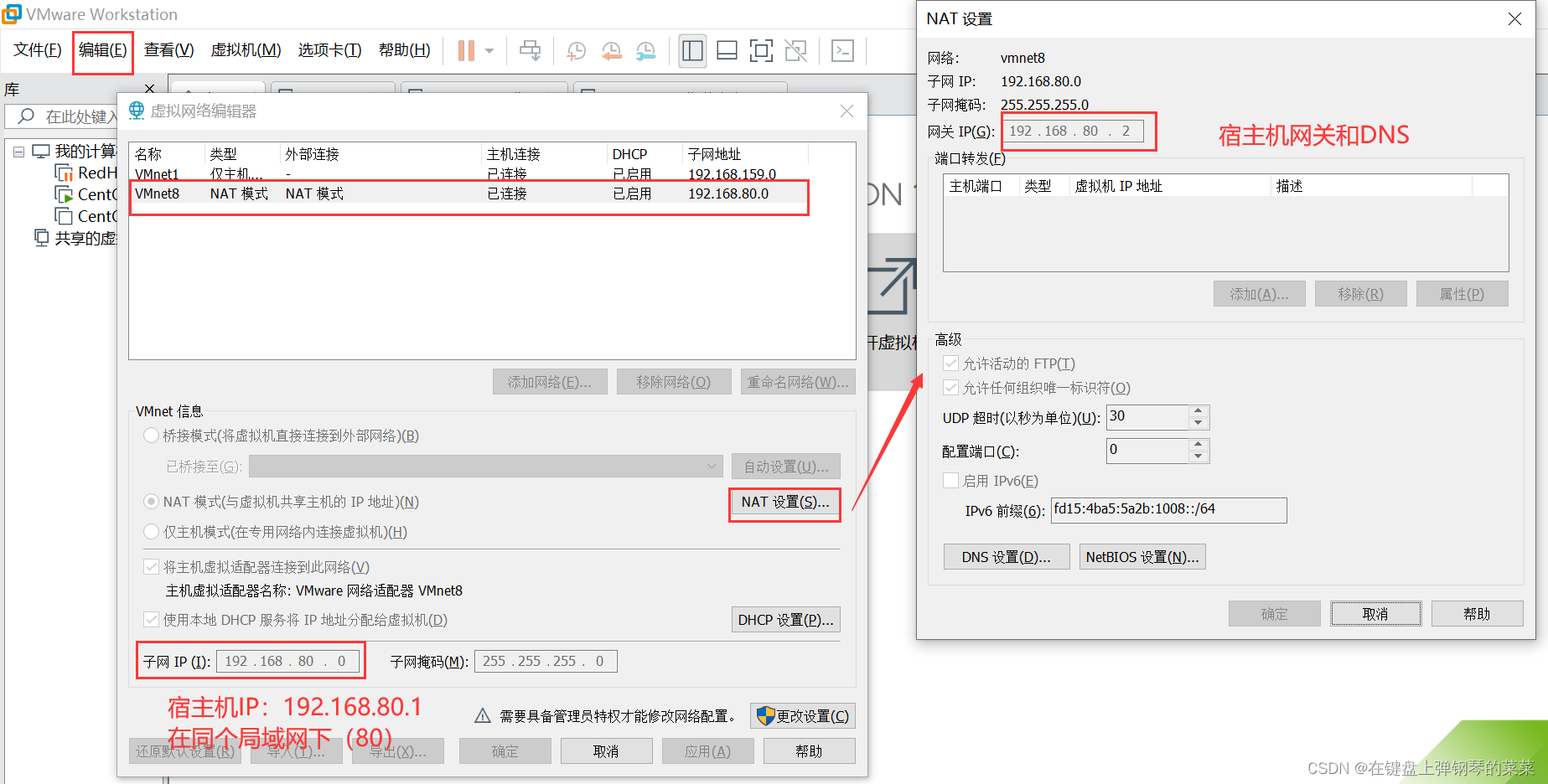
虚拟机设置方法为:编辑->虚拟网络编辑器
二:虚拟机对宿主机ping不通,但能ping外网
问题一:虚拟网卡VMnet8
虚拟机和宿主机之间的通信是通过虚拟网卡VMware Network Adapter VMnet8实现的,它的功能可参见如下关闭虚拟网卡实验:
控制面板->网络和Internet->网络和共享中心->更改适配器设置
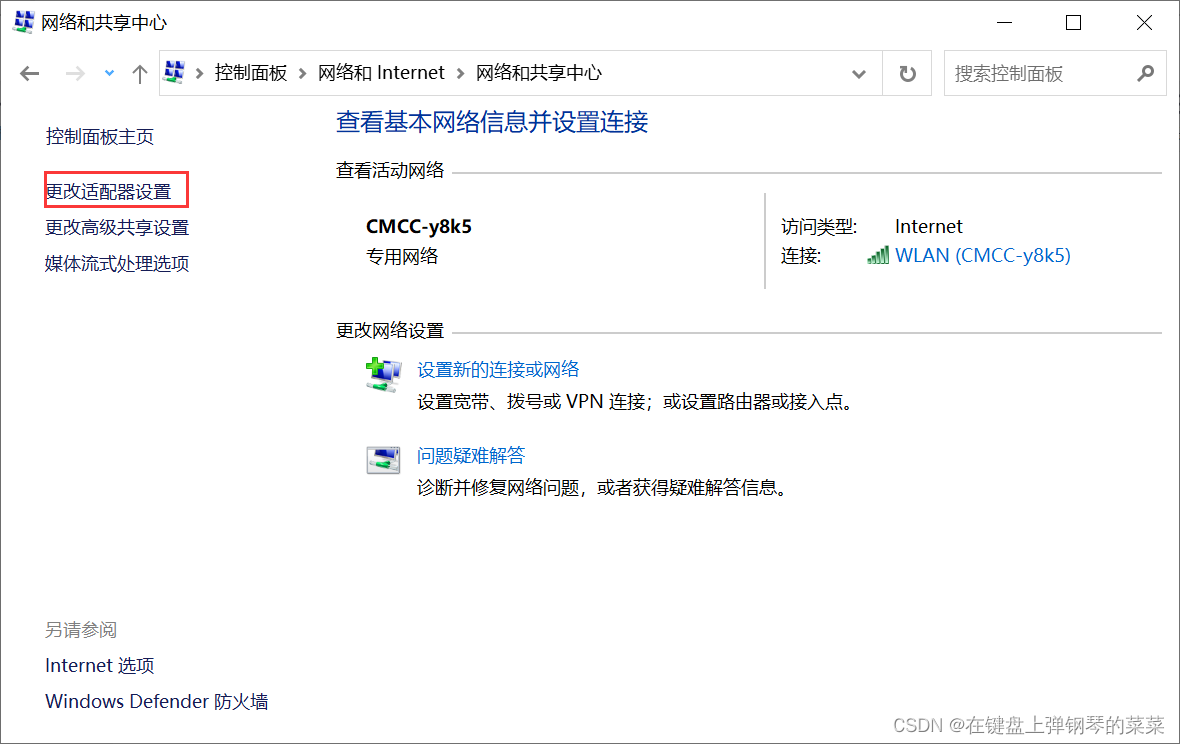
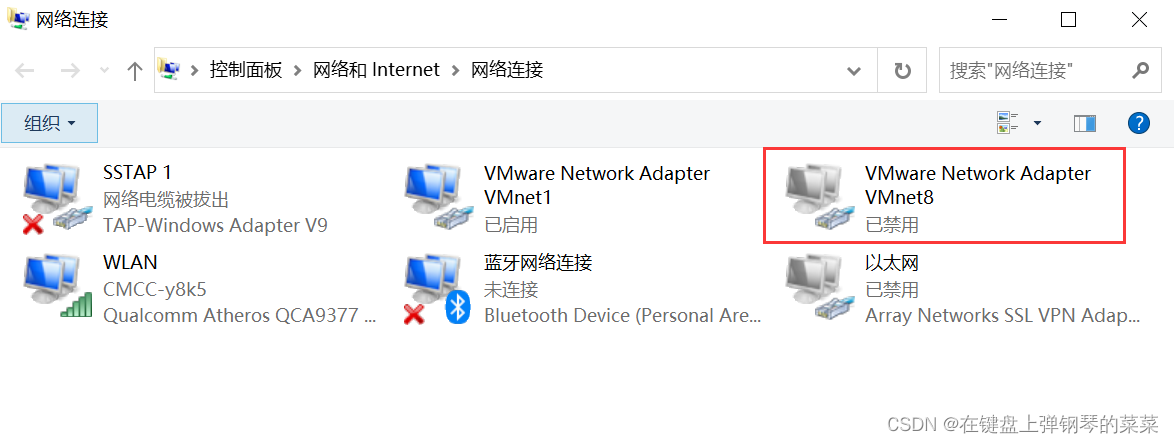
VMnet8被禁用,则主机和虚拟机无法通信,但可以与外网通信(因为虚拟机和主机公用一个网卡)如下:
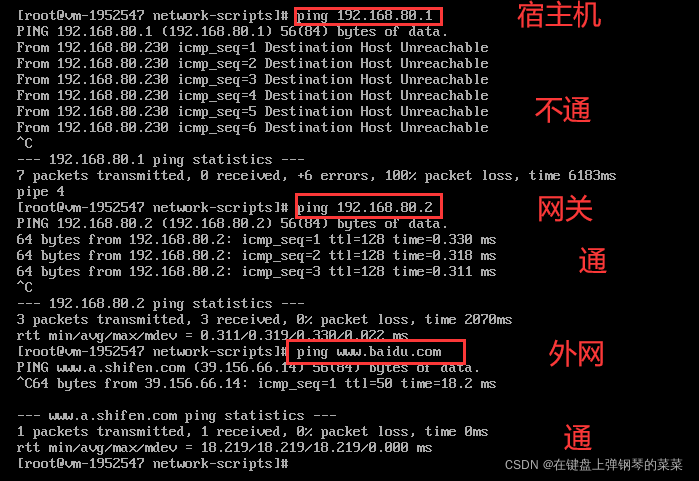
若VMNet8未被禁用,也不能排除它的问题,可能是它的设置有问题,具体见上一条。
问题二:虚拟机开机期间切换网络(博主遇到的问题)
如挂梯子,切换WIFI。这种操作使网关发生了变化,实质还是虚拟网卡VMnet8的原因。
问题三:防火墙
建议关掉
三:虚拟机对宿主机ping通,不能ping外网
问题:网关和DNS设置问题
具体设置方法见第一条
本文转自:https://blog.csdn.net/a_vegetable/article/details/122868444
Original: https://www.cnblogs.com/helong-123/p/16363170.html
Author: 萌褚
Title: 虚拟机ping不通的几种原因及解决办法
相关阅读2
Title: linux版powershell中,tab补全,linux外部命令参数名,的模块介绍
关键字 linux powershell pwsh 补全 complete bash zsh
摘要:
linux用户的福音!
在linux版powershell中,补全linux外部命令的参数(如ls补全-l),支持bash和zsh。
概述
在linux版powershell中,默认是无法补全linux外部命令的参数的。
但是有了这个模块,就可以实现,用tab补全【外部命令的参数名】了。
支持常用linux命令,如ls,find,grep等。
支持bash和zsh。
项目官网:
https://github.com/PowerShell/Modules/tree/master/Modules/Microsoft.PowerShell.UnixCompleters
界面gif动图:

linux中,的powershell中,安装:
Install-Module -Name Microsoft.PowerShell.UnixCompleters
linux中使用:
把下两条命令写入$profile,否则每次使用前需要打入此2条命令。
import-Module -Name Microsoft.PowerShell.UnixCompleters
Set-PSReadLineKeyHandler -Key Tab -Function MenuComplete
同时启用psreadline下拉列表,和linux外部命令tab补全后,$profile的样子:
【文件名=/root/.config/powershell/Microsoft.PowerShell_profile.ps1】
Set-PSReadlineOption -EditMode Windows
Set-PSReadlineOption -PredictionSource HistoryAndPlugin
Set-PSReadLineOption -PredictionViewStyle ListView
import-Module -Name Microsoft.PowerShell.UnixCompleters
Set-PSReadLineKeyHandler -Key Tab -Function MenuComplete
注意:
此时,应该先
1列出所有旧版psreadline:get-module psreadline -ListAvailable
2删除所有旧版的psreadline:rm -rf /xxx/psreadline
3用下列命令安装psreadline最新版:
Install-Module -Name PSReadLine -AllowPrerelease -Force -Scope CurrentUser
psreadline下拉菜单的gif效果:(支持linux)
此功能面向的用户群:
我想这个功能的主要用户,是win,linux都用的用户,如wsl用户。
或者是,从win中,用win terminal(或powershell),经ssh,连接linux。
本地powershell7---》ssh---》远程powershell7,还想用linux外部命令,参数名的tab补全。
那么问题来了,或许有人会问?为什么不用?
本地powershell7---》ssh---》被控机bash,bash里也有complete呀!
答:本地远程都是powershell7的话,可以从本地传递对象到远程,可以从远程返回对象到本地。
谢谢观看
Original: https://www.cnblogs.com/piapia/p/15578291.html
Author: PowerShell免费软件
Title: linux版powershell中,tab补全,linux外部命令参数名,的模块介绍
相关阅读3
Title: 配置免密登陆服务器
前言
原来自己学习的时候在阿里云买自己的学习机,一台主机自己瞎折腾。但是参加工作以后管理的主机越来越多了,上服务器看的频率也越来越频繁,虽然有时候shell管理工具可以很方便的保存,但是mac的终端实在是太香了,使用命令联通万物,配合一些ssh_config和hosts设置可以轻而易举的上服务器,这不比xshell酷和方便吗😏

免密登陆除了方便适用场景也非常多,公司代码一般都是配置ssh拉取,在github上配置了你电脑的公钥以后拉提起代码就不用输入密码也不用把密码记录到本地。
教程
了解ssh协议
ssh使用的是不对称加密的一个协议,后面我写https会详细介绍,简单来说两台主机使用非对称加密进行通信,通信和被通信的主机都需要拥有不同的秘钥,一般给发起通信方给出去的叫做公钥,自己留的叫做私钥,这个公钥和私钥都是进行解密数据的,为什么要整这么麻烦不直接http连接呢,周所周知http是透明协议,他的报文可以是没有加密的这不安全。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。
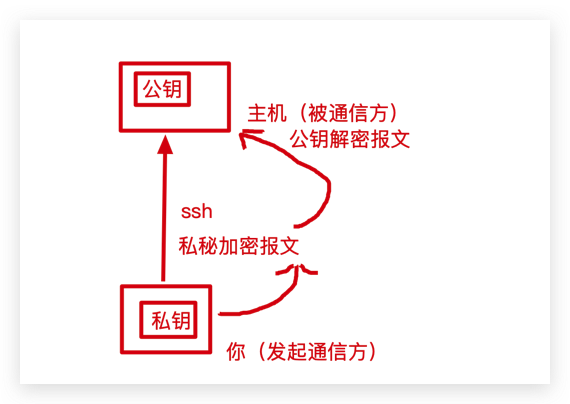
生成公钥和私钥
这里是linux和mac的操作,win可以点击这里,查看github官方教程
- 打开终端,然后输入
ssh-keygen -t rsa -C "www.someget.cn" -b 4096
// 其中-t是后面是加密算法,默认rsa,我这里画蛇添足只是想告诉大家
// -C是加入注释,一般都是自己的用户名
// -b是指定秘钥长度
// 以上参数都是无视,直接输入ssh-keygen也可以
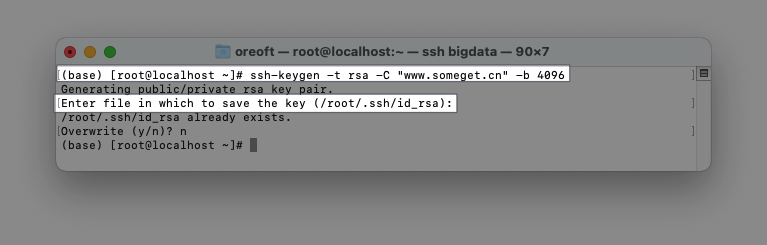
第二个高亮是指定私钥地址,这里直接回车选择默认路径就好
- 生成完了以后,在终端下面命令, 应该可以看到至少两个文件,一个是id_rsa还一个是id_rsa.pub,其中后缀为.pub的为公钥。把这个公钥发给你需要建立的通信方,对方就可以和你免密建立连接。
cd ~/.ssh & ll
// 去用户目录下面的.ssh查看下面的情况
把公钥给需要免密的主机
- 问题来了,既然这个.pub是发起通信方创建的,凭啥你给我.pub你就可以和我建立连接(建立连接意味着可以建立控制关系),刚刚只解决可以解析报文,现在解决如何能同意对方连接。
- 其实我刚刚里面有三个文件,还有一个authorized_keys的文件,这个文件里面记录了别人的公钥,也就是说只要别人的公钥在我这个authorized_keys里面,那么我就会可以解析对方的报文,并且同意对方连接。再提醒,这个authorized_keys是记录别人的公钥的,所以我们的公钥需要写到我们要免密登陆的主机上面。
- 那我们刚刚已经生成的公钥,那我们现在写入到我们要免密登陆的主机上吧
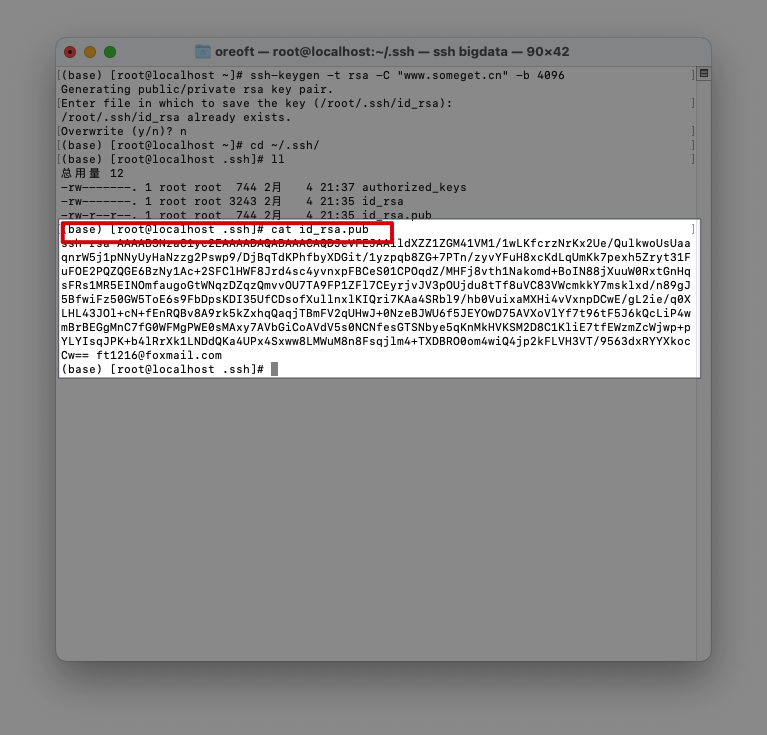
cat查看公钥信息,然后复制到剪贴板
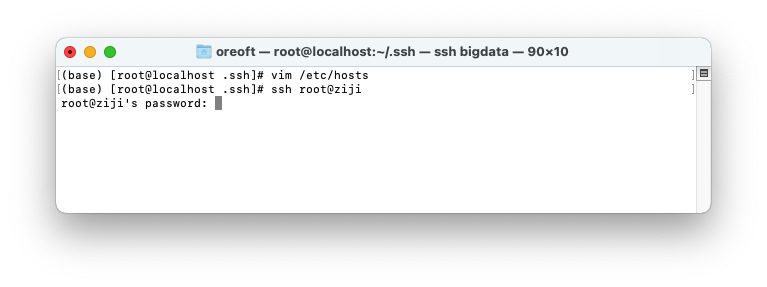
我修改host, 然后进行ssh登陆,还没配置需要密码
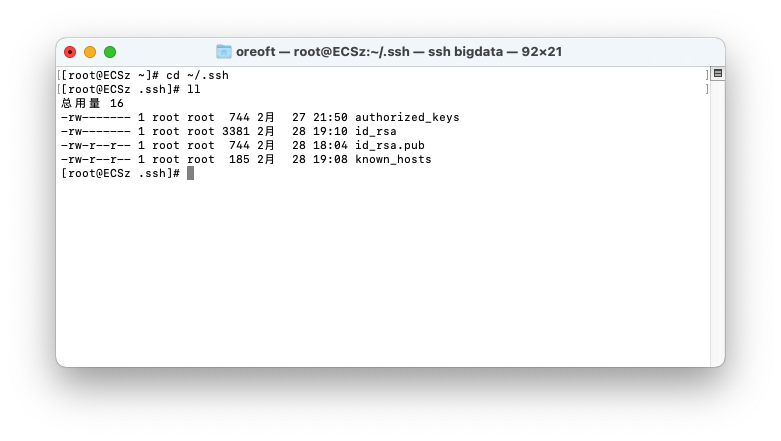
登陆上主机,打开用户目录下面的.ssh文件
- 这里注意,这个公钥和私钥都是我之前生成过的,如果你没生成过它里面是没有的,这个authorized_keys是需要自己创建的,还有一个known_hosts这是连接过的信息,有人连接过这个主机,会自动生成这个文件并且在里面添加一条记录
mkdir authorized_keys
echo "你的刚刚复制内容" >> authorized_keys
// 这样你就完成了配置了
- 最后你就可以直接登陆你的主机了
扩展
- 讲道理,这个ssh的非对称加密只使用公钥和私钥来进行鉴权,如果对安全不敏感,你可以分发自己的私钥、公钥和authorized_keys文件,这样在很多集群直接就可以相互通信,而不需要每一台都生成key,然后再进行每一台互相写入公钥。大数据集群直接很多这么使用,但是这有悖非对称加密的初衷。
-
如何配置github免密登陆
-
点击https://github.com/settings/keys
点击这个按钮
输入完在点击添加
- 然后你就可以使用ssh拉取代码啦
Original: https://www.cnblogs.com/oreoft/p/15731525.html
Author: 没有气的汽水
Title: 配置免密登陆服务器