
ll 列出当前目录下的文件,带文件信息
ls 列出当前目录下的文件,只有名字
ls -a 列出当前目录下的所有文件,包括隐藏文件
cd .. 切换到上一级目录
cd / 切换到根目录
cd ~ 切换到用户主目录
su 切换用户
pwd 列出当前目录路径
mkdir 创建目录
mkdir -p 可以递归创建目录,创建已经存在的目录不会报错
touch 创建一个空文件
vim/vi 打开一个文件,如果这个文件不存在会创建,如果vim不能使用需要安装一个软件包,用yum -y install vim (-y的意思是在安装软件包的过程中所有的问题都回答yes,就不用手动输入了)
打开文件后键盘输入i或a可以进入插入模式,此时可以编辑文件内容,编辑结束后可以按esc进入命令行模式,此时可以键盘输入大写的ZZ来保存退出,也可以键盘输入:(冒号)wq来保存退出,不保存退出是:!q
rm -rf 删除一个文件或者目录(rm 是删除一个文件,rm -r 是删除目录,rm -f 是强制删除,一般直接用rm -rf 就好)
cp 复制一个文件到目标目录下,如果复制到另外一个文件上,会提示是否覆盖
cp -r 复制文件或者目录
mv 移动文件或者目录
mv 旧目录名 新目录名 修改目录的名字
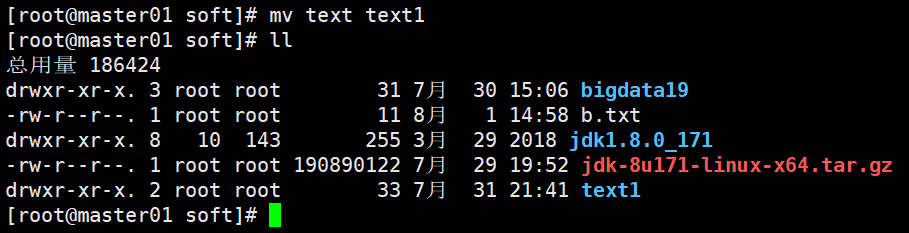
history 可以查看历史输入的命令
cat 不打开文件查看文件内容
tac 倒序查看
echo 输入内容>>文件完整路径 不打开文件往文件里写入内容
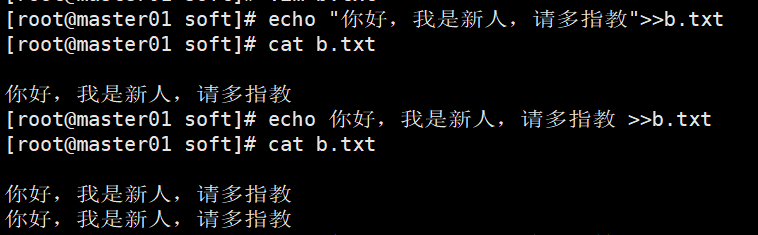
tail -f 监控文件内容的变化,但是如果删除文件后再创建,输入内容监控是没有提示的
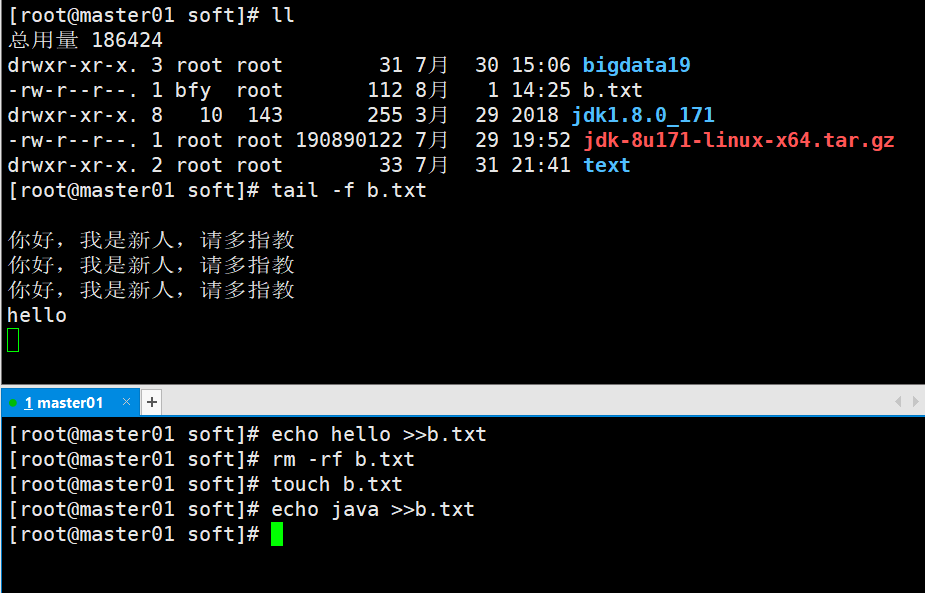
tail -F 文件存在时监控,如果不存在会提示断开
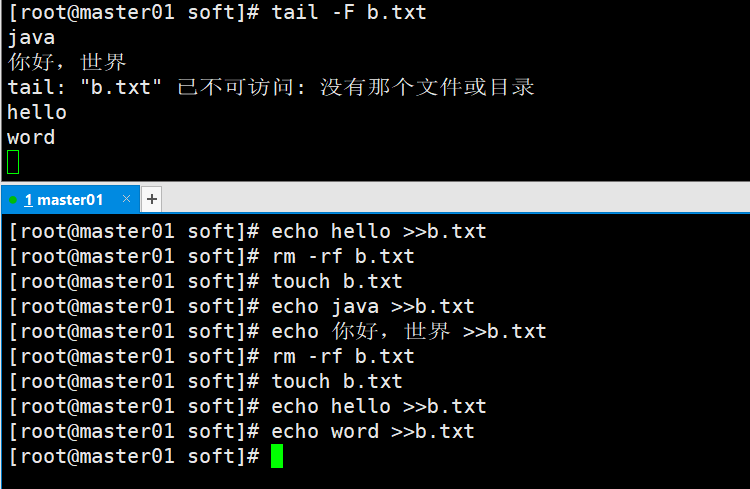
ls --help 查看ls用法,同理也适用于其他命令
tar -zxvf 解压(我们通过xftp上传压缩包后通过这个命令解压)
远程复制
从本地复制到远程
scp b.txt root@190.168.137.160:/usr/local/soft/(我配置了免密登录,这里不需要输入密码)
scp b.txt node1: pwd(我配置了映射,这里输入主机名就行,不需要ip地址,因为我远程复制的文件路径和我的目标路径一模一样,这里使用( pwd)就可以直接拿到路径)
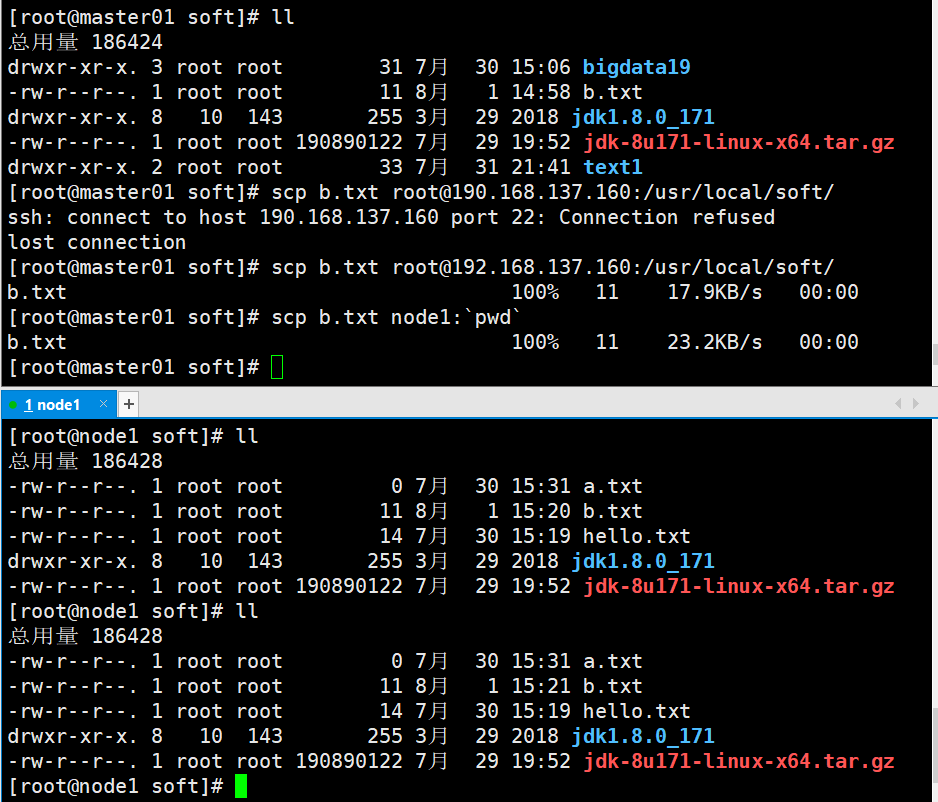
同理也可以实现远程到本地,远程到远程直接的文件复制
用户组管理
后面我们可能会创建很多用户,但这些用户不可能给同样的权限,有些用户的权限又有可能一样,所以我们通过用户组的方式,将他们区分开
groupadd 添加用户组
例如:[root@master01 soft]# groupadd hr
我们可以通过etc目录下的group来查看组

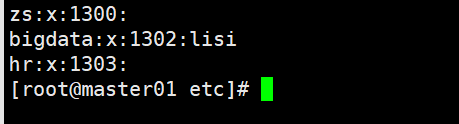
这里的x表示密码,后面的数字是用户组id,默认从1000之后递增,要想自定义id,可以加个-g

groupmod 用户组修改
-g:设置用户组id数字
-n:设置新的用户组名称
[root@master01 etc]# groupmod -g 1400 -n student hr(-n后是新的组名 旧的组名)
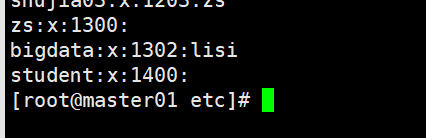
groupdel 删除用户组,跟上组名直接删除就行
前面都是用户组,这里开始添加用户
useradd 添加用户
添加一个新用户到并附加到一个组内,
-G附加组名或者组id
-u 自定义用户uid
-s 指定用户登入后所使用的shell 解释器,默认/bin/bash【专门的接待员】,如果不想让其登录,则可以设置为/sbin/nologin
-c 添加注释

usermod 修改用户
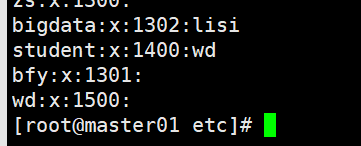
修改用户bfy的uid并将其附加到组student中
[root@master01 etc]# usermod -G student -u 1600 bfy
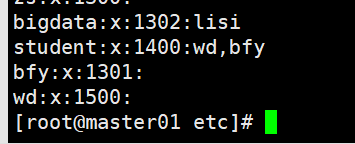
我们可以在/home目录下查看用户
在/etc/passwd/下查看用户的状态,包括,uid、密码、注释等
userdel 删除用户,但是这样/home路径下的这个用户目录还存在,我们可以再用rm -rf删掉,也可以一步到位用 userdel -r 用户名来删除。
更改用户权限
已知一个文件b.txt的权限是-rw-r--r-- 其中rw-是用户主的权限,第二个r--代表用户组的权限,第三个r--代表其他用户的权限。r代表可读,数字表示4,w代表可写,数字表示2。由此看出这个b.txt的权限是644
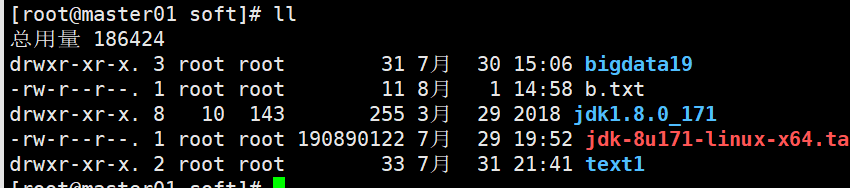
当我们用su命令切换用户的时候,这个文件只能读
我们如何令bfy这个用户也能获得这个文件的写权限呢?
第一种:更改文件的权限,将644改成666
chmod 修改权限
[root@master01 soft]# chmod 666 b.txt

此时用户bfy就可以修改文件了
第二种:将b.txt的所属用户改成bfy
chown 修改所属用户
[root@master01 soft]# chown bfy b.txt

此时,b.txt文件所属用户已经从root改成了bfy,切换用户后就可以读写了。
如果还有其他方法,请告诉我一声,我也不会
我也是第一次学习这些,如果有出错的地方还请大家批评指正,万分感谢!
Original: https://www.cnblogs.com/bfy0221/p/16540234.html
Author: 伍点
Title: Linux基础命令
相关阅读1
Title: 【spring-boot】Redis的整合与使用详解
在pom.xml中添加依赖
org.springframework.boot
spring-boot-starter-data-redis
2.2.1.RELEASE
io.lettuce
lettuce-core
redis.clients
jedis
3.1.0
添加配置文件 appliaction.yml
server: port: 8090 servlet: context-path: /springbootmybatis: # 对应实体类的包名 type-aliases-package: com.komiles.study.domain mapper-locations: classpath:mybatis/mapper/*.xml config-location: classpath:mybatis/mybatis-config.xmlspring: datasource: url: jdbc:mysql://127.0.0.1:3306/komo?characterEncoding=utf-8 username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver redis: database: 0 host: 127.0.0.1 port: 6379 jedis: pool: max-active: 8 max-idle: 8 max-wait: 1ms min-idle: 0
因为我的Redis没有设置密码,所以这个地方也没加密码。
新建User实体对象 User.java
package com.komiles.study.domain;
import java.io.Serializable;
import lombok.Data;
@Data
public class User implements Serializable {
private Integer id;
private String username;
private String password;
}
新建Controller测试入口 RedisTestController.java
package com.komiles.study.controller;
import com.komiles.study.domain.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.data.redis.core.ValueOperations;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author komiles@163.com
* @date 2020-04-02 14:22
*/
@RequestMapping("/redis")
@RestController
public class RedisTestController {
@Autowired
RedisTemplate redisTemplate; // 对象Redis实例
@Autowired
StringRedisTemplate stringRedisTemplate; // 字符串Redis实例
@GetMapping("/strTest")
public String redisStrTest()
{
ValueOperations valueOperations = stringRedisTemplate.opsForValue();
valueOperations.set("name", "hello world");
String value = valueOperations.get("name");
return value;
}
@GetMapping("/objTest")
public User redisObjTest()
{
ValueOperations valueOperations = redisTemplate.opsForValue();
User user = new User();
user.setId(1111);
user.setUsername("哈哈哈");
user.setPassword("123456");
valueOperations.set("user_obj", user);
return (User) valueOperations.get("user_obj");
}
}
访问地址

注意事项:实体类中,需要实现接口 Serializable,不然在设置对象时,会报错。
参考地址:https://github.com/KoMiles/spring-example/tree/master/mybatis-generator-demo
Original: https://www.cnblogs.com/wangkongming/p/12619584.html
Author: KoMiles
Title: 【spring-boot】Redis的整合与使用详解
相关阅读2
Title: 怎么用vscode创建工程
以下内容为本人的学习笔记,如需要转载,请声明原文链接微信公众号「englyf」 https://mp.weixin.qq.com/s/x2OXMTaLlxb_Os7NDHrKsg
vs code创建工程,以koa框架为例
这里以应用koa框架写一个http服务器为例,来说明怎么用vs code创建工程。
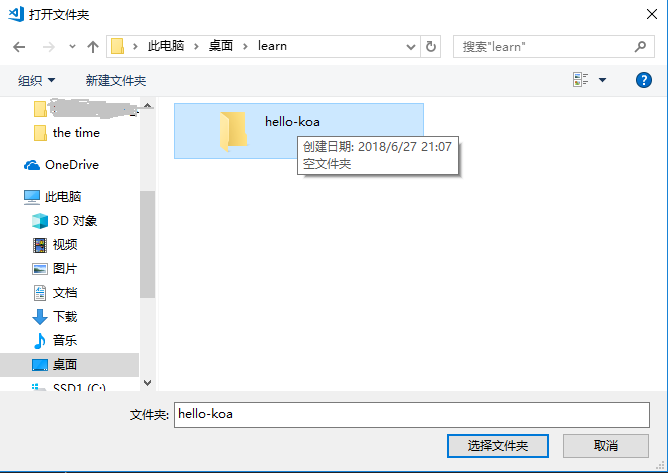
进入 vs code 后,打开文件夹,如下图
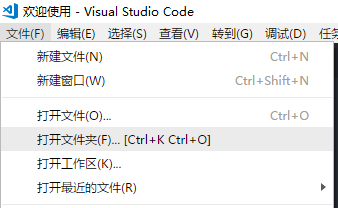
如果还没有准备好新文件夹,可以在弹出的窗口里新建一个,这里新建工程文件夹「hello-koa」
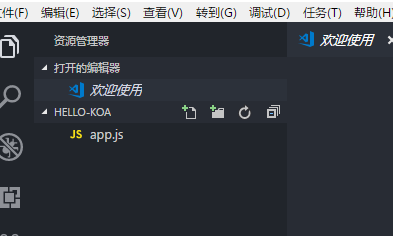
然后需要在文件夹里新建一个 js 代码文件 「app.js」
代码如下:
const Koa = require('koa');
const app = new Koa();
app.use(async (ctx, next) => {
await next();
ctx.response.type = 'text/html';
ctx.response.body = '<h1>Hello, koa2!</h1>';
});
app.listen(5000);
console.log('app started at port 5000 ...');
上面的代码实现了一个最简单页面的 http 服务器功能,里用到了 koa2 框架的知识。有了源文件还不能运行这个工程,因为工程还没有配置文件。
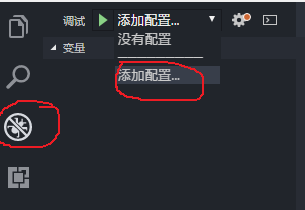
接下来就是配置工程,好让工程能被运行。点击 vs code 的调试功能,并添加配置。
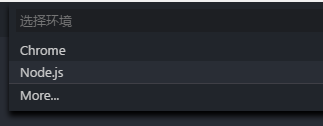
然后代码窗口会弹出一个选择框,由于 koa 框架是基于 node.js,所以这里选择 node.js。记得保存自动生成并打开的配置文件 「launch.json」。
其实,这是一个完成项目的简单配置,可以启动程序吗?点击启动程序后,我们可以在调试控制台中看到很多错误。
[En]
In fact, this is a simple configuration to complete the project, is it possible to start the program? After clicking to start the program, we can see a lot of errors in the debugging console.
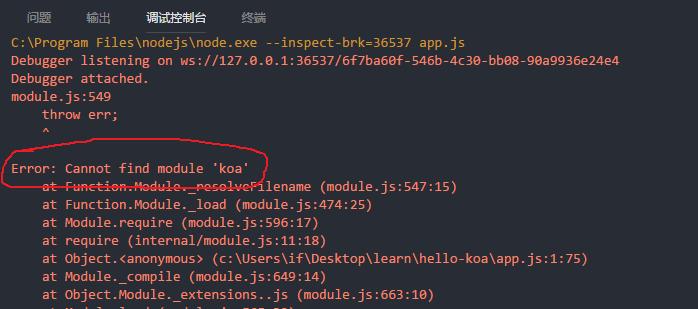
配置中是否有错误?事实上,我们可以在错误消息中看到此行。
[En]
Is there a mistake in configuration? In fact, we can see this line in the error message.
Error: Cannot find module 'koa'
这行信息其实已经告诉我们,工程无法找到 koa 模块。因此需要再给工程安装 koa 模块,需要用到 npm 的功能。这里推荐使用以下方法安装依赖的模块。
在工程文件夹下,新建文件「package.json 」,内容如下
{
"name": "hello-koa2",
"version": "1.0.0",
"description": "Hello Koa2 example with VS Code",
"main": "app.js",
"scripts": {
"start": "node app.js"
},
"keywords": [
"koa",
"async"
],
"author": "englyf",
"license": "Apache-2.0",
"dependencies": {
"koa": "2.0.0"
}
}
可以看到其中有一段
"dependencies": {
"koa": "2.0.0"
}
这里的意思就是,依赖 koa 版本是2.0.0。
好了,npm 已经配置好,接着点击「终端」,然后输入以下命令试试。
npm install
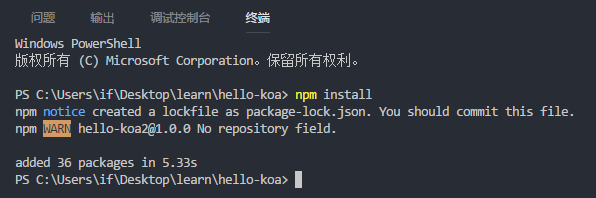
安装完,我们会在工程里发现多了一个子文件夹 「node_modules」和一个文件「package-lock.json 」。
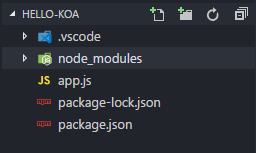
点击打开文件夹「node_modules」可以看到里面都是一些依赖包,可知安装 koa 模块的过程中会将其依赖的其它包一并安装。
这里要注意了,由于这个文件夹的内容都是依赖包可以通过上面的命令自动安装,并且体积比较大,所以在上传版本的时候,不需要包括这个文件夹。
但是,有的人可能会觉得,为了安装个依赖包就写那么一大堆内容在「package.json 」里面,未免有点麻烦了吧?其实 npm 还真有个命令可以省略掉创建文件「package.json 」,可以直接在终端里输入以下命令,即可自动开始安装 koa 2 的依赖包。
npm install koa@2.0.0
骚等片刻,等待完成依赖包的安装,就可以点击「启动程序」,正常启动 http 服务了。
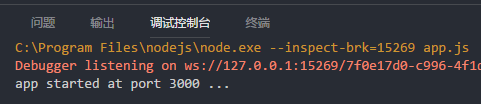
当然,除了点击 vs code 提供的「启动程序」按钮,这个方式来运行程序之外,还可以在终端里输入以下命令来启动程序。使用 node 之前,必须要先在机器里安装 node。
node app.js
回到上面,我们看看「package.json 」文件里其实有这么一段数据,
"scripts": {
"start": "node app.js"
}
所以同样可以使用 npm 来快速启动程序,在终端里输入下面的命令即可。
npm start
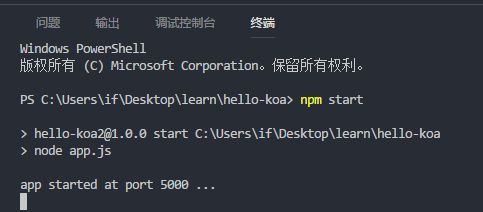
你可以看到,它们具有相同的效果。
[En]
You can see that they have the same effect.
最后,就可以打开浏览器,查看一下我们刚刚启动的 http 服务,在浏览器地址栏输入
http://localhost:5000
回车,可以看到页面返回,这就完成一个最简单的 http 服务了。
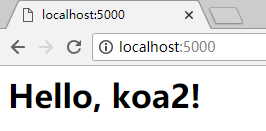
就这样。
[En]
That's all.
Original: https://www.cnblogs.com/englyf/p/16685082.html
Author: englyf八戒
Title: 怎么用vscode创建工程
相关阅读3
Title: linux命令__top
top
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。top显示系统当前的进程和其他状况,是一个动态显示过程,可以自动或者通过用户按键来不断刷新当前状态。如果在前台执行该命令,它将独占前台,直到用户终止该程序为止.。比较准确的说,top命令提供了实时的对系统处理器的状态监控,显示系统中CPU最"敏感"的任务列表。top命令可以按CPU使用、内存使用和执行时间对任务进行排序。而且该命令的很多特性都可以通过交互式命令或者在个人定制文件中进行设定。
需要注意的是:top命令监控的最小单位是进程,如果想监控更小单位时,就需要用到ps或者netstate命令来满足我们的要求。
top输出解释
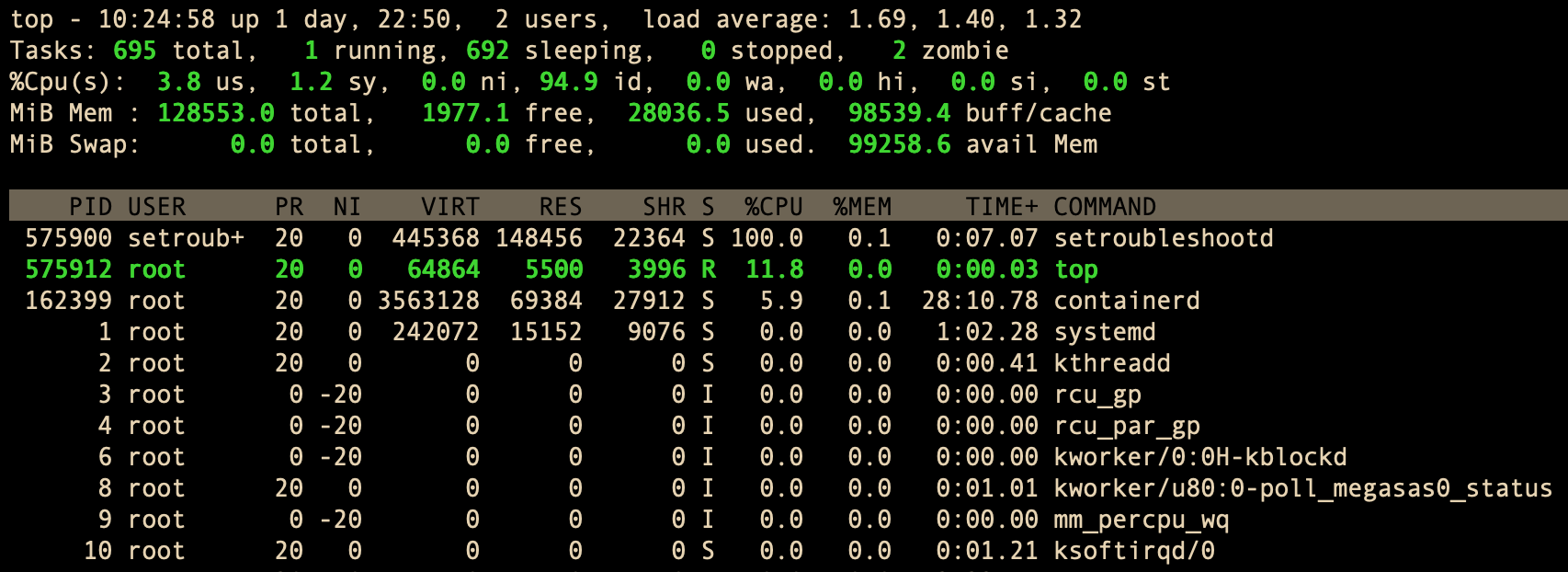
第一行:任务队列信息
top - |10:26:26 |up 1 day, 22:52,| 2 users, |load average: 1.43, 1.39, 1.32 |
用户空间(User Space)和内核空间(Kernel Space):
简单说,Kernel space 是 Linux 内核的运行空间,User space 是用户程序的运行空间。为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
Kernel space 可以执行任意命令,调用系统的一切资源;
User space 只能执行简单的运算,不能直接调用系统资源,必须通过系统接口(又称 system call),才能向内核发出指令。
第四行:内存状态
KiB Mem:Kib表示描述单位,MEM表示内存
- total:总内存量(4G)
- free:空闲内存(2G)
- used:已用内存(1G)
- buff/cache:缓存内存(307M)
第五行:swap交换分区信息
KiB Swap:Kib表示描述单位,Swap表示交换分区
- total:总内存量(839M)
- free:空闲内存(839M)
- used:已用内存(0)
- avail Mem:可用内存(2G)
什么是交换分区:
类似于Windows的虚拟内存,就是当内存不足的时候,把一部分硬盘空间虚拟成内存使用,从而解决内存容量不足的情况;需要注意的是,存储在交换分区的数据性质,在内存不够的情况下,操作系统先把内存中 暂时不用的数据,存到硬盘的交换空间,腾出内存来让别的程序运行free和avail的区别:
free 是真正尚未被使用的物理内存数量。
available 是应用程序认为可用内存数量,available = free + buffer + cache (注:只是大概的计算方法)
对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化,说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。
第六行:各进程状态监控

PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态;R=运行;S=睡眠;T=跟踪/停止;Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
常用命令
常用命令参数为:

* -d
top -d 2 表示每2秒刷新一次


* -n
编辑设置
f 键

用上下键选择选项,按下空格键可以决定是否在基本视图中显示这个选项,按esc键退出编辑界面。
c 键
在top基本视图中,敲击c键,可以显示进程的路径:

k 键
在top基本视图中,敲击k键,可以在不退出top命令的情况下杀死某个正在运行的进程:

b 键
在top基本视图中,敲击b键,高亮显示当前正在运行的进程:

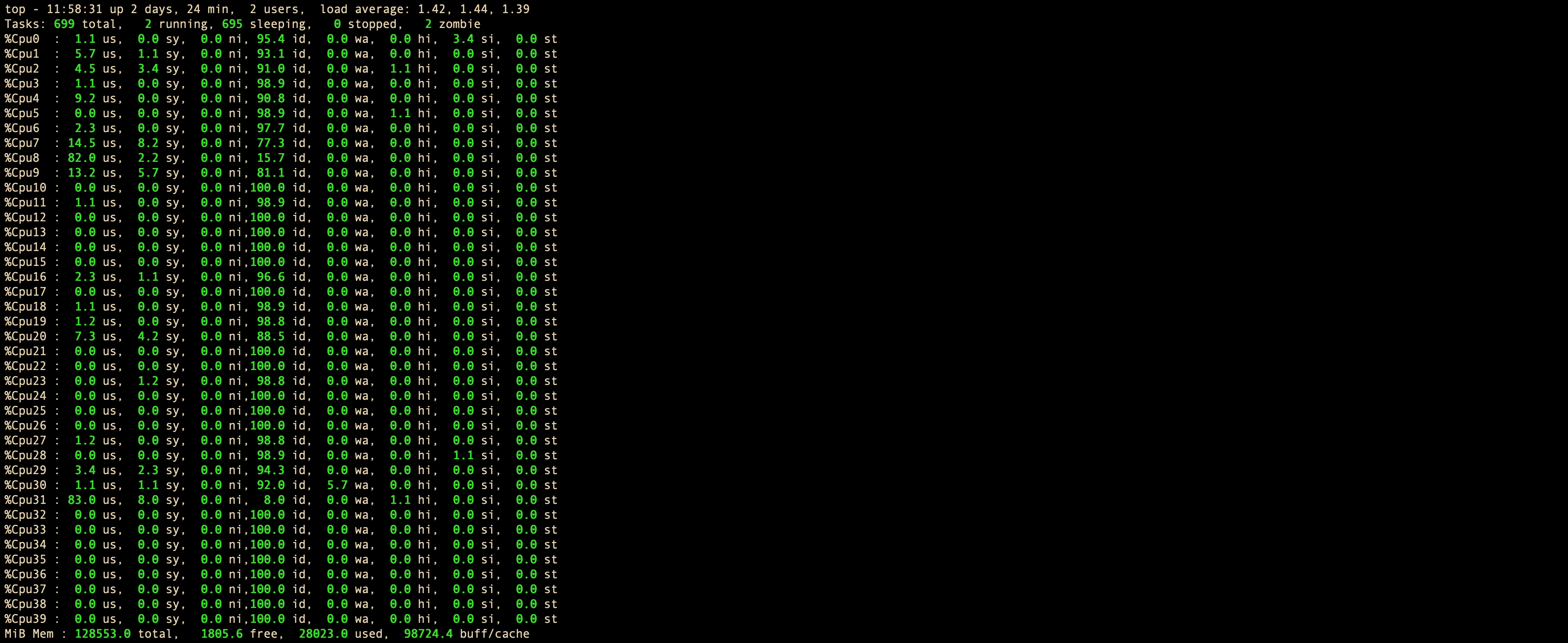
1 键
在top基本视图中,敲击数字1键,可监控每个逻辑CPU的状况
Original: https://www.cnblogs.com/ivanlee717/p/16341616.html
Author: ivanlee717
Title: linux命令__top