
以下是在u bantu18.04 版本下的配置教程:
Step 1 去PyCharm官网下载Linux版的PyChram安装压缩包
网址:https://www.jetbrains.com/zh-cn/pycharm/download/#section=linux
选择社区版本下载如图
Step 2下载完成后找到你的目录下的压缩包进行解压操作
双击解压提取到你自定义的文件夹
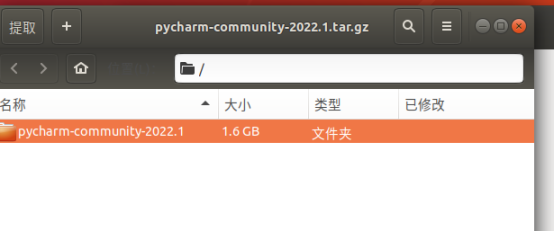
进去这个文件夹里找到bin文件夹,进入bin文件夹中
进入后打开终端
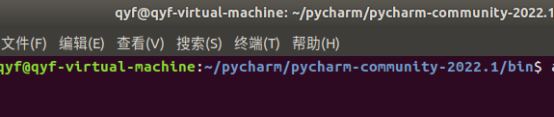
输入指令./pycharm.sh
然后开始运行安装包程序

勾上后点continue
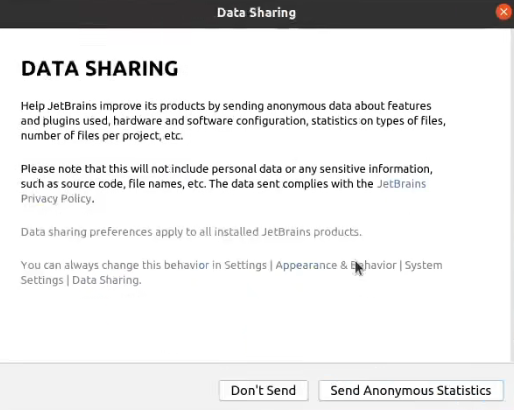
选Don't Send
出现一下界面就说明PyCharm已经安装完成了
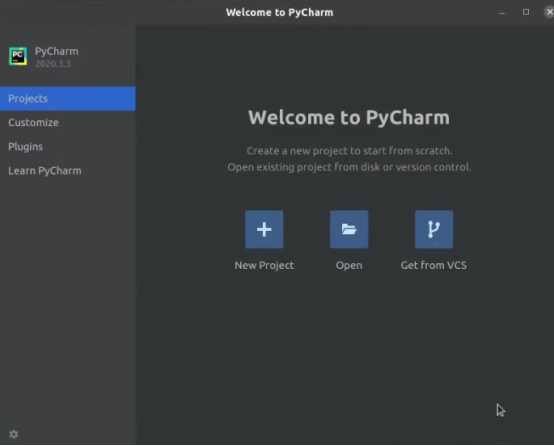
接下来我们还需要配置环境,考虑到以后要用到conda的库,所以我接下来安装了anaconda
先去anaconda官网下载其安装包
网址:https://www.anaconda.com/products/distribution ;
下载后找到安装包目录
在目录上打开终端
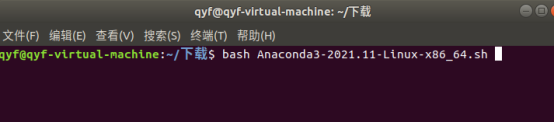
输入指令bash 如上图
安装过程中遇到停顿按Enter或者输入YES
默认安装在用户目录下,直接回车即可安装;若想要自定义安装目录,直接输入安装目录回车即可
看到下面信息说明已经安装完成

配置环境
打开终端

这里"——"要结合自己的conda安装的目录位置找到bin文件夹的位置目录然后填入
输入指令 conda -V 检测一下conda是否安装成功
这里出现4.10.3说明版本号即安装成功
输入Python3,看下python3版本
最后回到pycharm中
添加新工程

这里是工程存放文件的位置
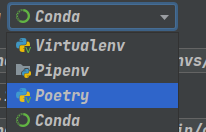
这里选conda
然后位置选择你的conda的位置
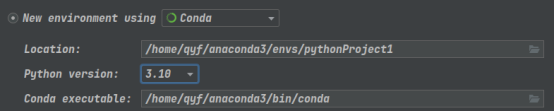

这个可勾可不勾,勾上会给你自动写上一个简单的程序描述。
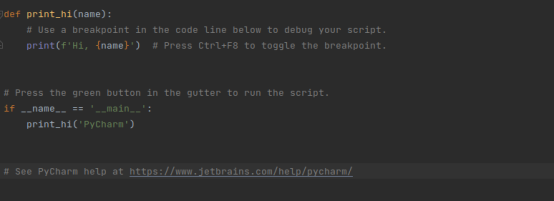
最后运行一下这个代码

修改一下代码验证一下
此时配置成功
Original: https://www.cnblogs.com/sitqyflinux/p/16219281.html
Author: qy凡
Title: LINUX系统下安装PyCharm和annaconda3并配置
相关阅读1
Title: shell相关知识1
组命令,就是将多个命令划分为一组,或者看成一个整体。
用法区别
Shell 组命令的写法有两种:
{ command1; command2;. . .; }
(command1; command2;. . . )
两种写法的重要不同: 由 {} 包围的组命令在当前 Shell 进程中执行,由 () 包围的组命令会创建一个子Shell,所有命令都会在这个子 Shell 中执行。
在子 Shell 中执行意味着,运行环境被复制给了一个新的 shell 进程,当这个子 Shell 退出时,新的进程也会被销毁,环境副本也会消失,所以在子 Shell 环境中的任何更改都会消失(包括给变量赋值)。因此,在大多数情况下,除非脚本要求一个子 Shell,否则 使用 {} 比使用 () 更受欢迎,并且 {} 的进行速度更快,占用的内存更少。
举栗 将多条命令的输出重定向到out.txt文件
1.普通模式
2.使用组命令
{ ls -l ;echo "test432";cat test .txt; }>out.txt
(ls -l ;echo "test432";cat test .txt)>out.txt
组命令与管道结合
(ls -l ;echo "test432";cat ../test.txt)|wc -l
子进程的概念是由父进程的概念引申而来的。在 Linux 系统中,系统运行的应用程序几乎都是从 init(pid为 1 的进程)进程派生而来的,所有这些应用程序都可以视为 init 进程的子进程,而 init 则为它们的父进程。
Shell 脚本是从上至下、从左至右依次执行的,即执行完一个命令之后再执行下一个。 如果在 Shell 脚本中遇到子脚本(即脚本嵌套,但是必须以新进程的方式运行)或者外部命令,就会向系统内核申请创建一个新的进程,以便在该进程中执行子脚本或者外部命令,这个新的进程就是子进程。子进程执行完毕后才能回到父进程,才能继续执行父脚本中后续的命令及语句。
使用 pstree -p命令就可以看到 init 及系统中其他进程的进程树信息(包括 pid):
systemd(1)─┬─ModemManager(796)─┬─{ModemManager}(821)
│ └─{ModemManager}(882)
├─NetworkManager(975)─┬─{NetworkManager}(1061)
│ └─{NetworkManager}(1077)
├─abrt-watch-log(774)
├─abrt-watch-log(776)
├─abrtd(773)
├─accounts-daemon(806)─┬─{accounts-daemon}(839)
│ └─{accounts-daemon}(883)
├─alsactl(768)
├─at-spi-bus-laun(1954)─┬─dbus-daemon(1958)───{dbus-daemon}(1960)
│ ├─{at-spi-bus-laun}(1955)
│ ├─{at-spi-bus-laun}(1957)
│ └─{at-spi-bus-laun}(1959)
├─at-spi2-registr(1962)───{at-spi2-registr}(1965)
├─atd(842)
├─auditd(739)─┬─audispd(753)─┬─sedispatch(757)
│ │ └─{audispd}(759)
│ └─{auditd}(752)
创建子进程的方式说明
-
第一种只使用 fork() 函数,子进程和父进程几乎是一模一样的,父进程中的函数、变量(全局变量、局部变量)、文件描述符、别名等在子进程中仍然有效。我们将这种子进程称为 *子 Shell(sub shell)
-
第二种使用 fork() 和 exec() 函数,即使用 fork()创建子进程后立即调用 exec() 函数加载新的可执行文件,而不使用从父进程继承来的一切,子进程和父进程之间除了硬生生地维持一种"父子关系"外,再也没有任何联系了,它们就是两个完全不同的程序。
举栗:
在 ~/bin 目录下有两个可执行文件分别叫 a.out 和 b.out。现在运行 a.out,就会产生一个进程,比如叫做 A。在进程 A 中我又调用 fork() 函数创建了一个进程 B,那么 B 就是 A 的子进程,此时它们是一模一样的。但是,我调用 fork() 后立即又调用 exec() 去加载 b.out,这可就坏事了,B 进程中的一切(包括代码、数据、堆栈等)都会被销毁,然后再根据 b.out 重建建立一切。这样一折腾,B 进程除了 ID 没有变,其它的都变了,再也没有属于 A 的东西了。
子 Shell 虽然能使用父 Shell 的的一切,但是如果子 Shell 对数据做了修改,比如修改了全局变量,这种修改也只能停留在子 Shell,无法传递给父 Shell。 不管是子进程还是子 Shell,都是"传子不传父"。
子 Shell 才是真正继承了父进程的一切,这才像"一个模子刻出来的";普通子进程和父进程是完全不同的两个程序,只是维持着父子关系而已。
echo $$输出当前进程ID,echo $PPID输出父shell ID
输出当前进程与父进程ID
echo $$;echo $PPID
34451
34450
子进程形式输出进程ID
子进程
bash
echo $$;echo $PPID
exit
52886
34451
在普通的子进程中,$ 被展开为子进程的 ID
组命令形式输出进程ID
子shell
(echo $$;echo $PPID)
34451
34450
子shell和父shell中的ID是一样的
这是因为$ 变量在子 Shell 中无效!Base 官方文档说,在普通的子进程中,$ 确实被展开为子进程的 ID;但是在 子 Shell 中,$ 却被展开成父进程的 ID
管道形式输出进程ID
子shell
echo "test" | { echo $$;echo $PPID; }
34451
34450
进程替换形式输出进程ID
read <
Original: https://www.cnblogs.com/saolv/p/13197549.html
Author: 扫驴
Title: shell相关知识1
相关阅读2
Title: redis key的过期时间
设置redis key的生存过期时间
Redis 有四个不同的命令可以用于设置键的生存时间(键可以存在多久)或过期时间(键什么时候会被删除) :
- EXPlRE 命令用于将键key 的生存时间设置为ttl 秒。
- PEXPIRE 命令用于将键key 的生存时间设置为ttl 毫秒。
- EXPIREAT < timestamp> 命令用于将键key 的过期时间设置为timestamp所指定的秒数时间戳。
PEXPIREAT < timestamp > 命令用于将键key 的过期时间设置为timestamp所指定的毫秒数时间戳。
redis通过exipre或则pexpire命令,可以以秒或则毫秒为精度为某个key设置过期时间,在经过指定的时间之后,redis服务器就会删除生存时间为0的key
下面的例子中把key1的过期时间设置为20秒,过20秒后redis就会吧key1删除
127.0.0.1:6379> set key1 'value1'
OK
127.0.0.1:6379> exipre key1 20
(error) ERR unknown command 'exipre'
127.0.0.1:6379> expire key1 20
(integer) 1
127.0.0.1:6379> get key1
"value1"
127.0.0.1:6379> get key1
"value1"
127.0.0.1:6379> get key1
(nil)
127.0.0.1:6379>
setex命令可以在设置一个字符串key的时候,同时设置该key的过期时间,因为这个命令是一个类型限定的命令(只能用于字符串键),但SETEX 命令设置过期时间的原理和EXPIRE命令设置过期时间的原理是完全一样的。
与EXPlRE 命令和PEXPIRE 命令类似,客户端可以通过EXPlREAT 命令或PEXPlREAT命令,以秒或者毫秒精度给数据库中的某个键设置过期时间(expire time)。过期时间是一个UNIX时间戳,当键的过期时间来临时,服务器就会自动从数据库中删除这个键:
使用方式如下
127.0.0.1:6379> set key1 'value1'
OK
127.0.0.1:6379> expireat key1 1545470885
(integer) 1
127.0.0.1:6379> time
1) "1545470897"
2) "996846"
127.0.0.1:6379> get key1
(nil)
127.0.0.1:6379>
TTL 命令和PTTL 命令接受一个带有生存时间或者过期时间的键,返回这个键的剩余生存时间,也就是,返回距离这个键被服务器自动删除还有多长时间:
127.0.0.1:6379> time
1) "1545470973"
2) "878082"
127.0.0.1:6379> set key1 'value1'
OK
127.0.0.1:6379> expireat key1 1545471973
(integer) 1
127.0.0.1:6379> ttl key1
(integer) 962
127.0.0.1:6379> ttl key1
(integer) 961
移除过期时间
PERSIST命令可以移除一个键的过期时间:使用方式如下:
127.0.0.1:6379> set key1 'value1'
OK
127.0.0.1:6379> time
1) "1545471314"
2) "556941"
127.0.0.1:6379> expireat key1 1545481314
(integer) 1
127.0.0.1:6379> ttl key1
(integer) 9980
127.0.0.1:6379> persits key1
(error) ERR unknown command 'persits'
127.0.0.1:6379> persist key1
(integer) 1
127.0.0.1:6379> ttl key1
(integer) -1
Original: https://www.cnblogs.com/senlinyang/p/10161836.html
Author: 木易森林
Title: redis key的过期时间
相关阅读3
Title: 005 Linux 命令三剑客之-sed
- grep:数据查找定位
- awk:数据切片,数据格式化,功能最复杂
- *sed:数据修改
三剑客各有所长,和锅锅一一搞起就是了!
- sed:擅长数据修改。
- grep:擅长数据查找定位。
-
awk:擅长数据切片,数据格式化,功能最复杂。
sed(全称:Stream Editor),擅长对文件做数据做修改的操作,非常高效。这里总结一些增删改的基础用法。 -
使用 vim 需要在文件内部编辑,有时只是想在文件底部添加一句话或一个参数,需要经历vim [文件] ->G (移动到底部)->o 下一行添加 ->编辑内容 ->保存退出。
- 这个步骤真麻烦,sed 可以轻便的实现这些功能!
- ps: 其实还有个echo命令也有这个功能,echo "文件内容" >> [文件名]。
使用示例:
- sed -i '$a 哈哈哈' info.log #在文件末尾追加"哈哈哈"字符串。
- sed -i '20a 啦啦啦' info.log #在文件【info.log】第20行字符下一行,追加字符串"啦啦啦"。
- sed -i '20i 啦啦啦' info.log #在文件【info.log】第20行字符上一行,追加字符串"啦啦啦"。
- sed -i 'a 嘎嘎' info.log #在文件【info.log】每行字符下一行追加字符串"嘎嘎"。
- sed -i 'i 大大' info.log #在文件【info.log】每行字符上一行追加字符串"大大"。
- sed -i '1i 第一行啦' info.log #在文件【info.log】开头插入字符串"第一行啦"。
- sed -i '/book/a HH' info.log #匹配包含 book 的行,并在其后添加 book。
使用示例:
- sed -i 's/book/books/' info.log #把【info.log】文件里第一个"book" 替换为"books"。
- sed -i 's/book/books/g' info.log #把【info.log】文件里所有的"book" 替换为"books"。
使用示例:
- sed -i '2d' info.log #删除【info.log】文件的第二行。
- sed -i '1,3d' info.log #删除【info.log】文件的1到3行。
- sed -i '/^啦啦啦/,/$HH/d' info.log #删除【info.log】中以 "啦啦啦" 开头一直到以"HH"结尾的行。
- sed -i '/^$/d' info.log #删除所有的空白行
(1)替换命令的格式
sed [选项] s/[pattern]/[replace]/[flags]
[选项]常用的几个参数:
- -f #script-file 从文件中读取脚本指令,对编写自动脚本程序很实用。
- -i #该选项将直接修改源文件,否则所有的操作对文件都不生效哦,当然线上使用的时候要谨慎!
- -e #script 允许多个脚本指令被执行。
[pattern]
含义:待匹配的需要替换的内容。
[replace]
常见的特殊含义字符:
- & # 用正则表达式匹配的内容进行替换。
- \ # 转义(转义替换部分包含:&、\等)。
[flags]
常见的可选参数:
- -n # 1-512之间的数字,表示对[pattern]中指定内容第n次出现进行替换。如一行中有3个H,而只想替换第二个H。
- -g # 对[pattern]中指定的内容进行全局更改。没有g则只有第一次匹配被替换。
(2) 多个sed命令执行
多个sed命令依次执行,用分号分割或加选项 -e,
使用示例:
- sed 's/yes/no/;s/static/dynamic/' info.log # 示例1,同时指定了2个sed命令。
- sed -e 's/yes/no/' -e 's/static/dynamic/' info.log #示例2,同时指定了2个sed命令。
(3)实践 sed 搜寻替换
把 test.html 文件中的第二个 <body></body> 替换为 。
<html>
<body>Hello the World!<body>
</body></body></html>
分析实际就是把第二个 body 替换为 /body,命令如下。
sed -i 's/body/\/body/2'  test.html
(4)实践 sed,写一个脚本实现替换功能
把 test.html 文件中的第二个 <body></body> 替换为 。
<html>
<body>Hello the World!<body>
</body></body></html>
分析实际就是把第二个 body 替换为 /body,命令如下。
编写执行脚本的步骤如下:
touch sed.sh
sed.sh 中写入脚本内容:
#sed替换脚本
s/body/\/body/2
对sed.sh 脚本赋予可执行权限
chmod ug+x sed.sh
执行sed.sh 脚本,对文件进行处理
sed -i -f sed.sh test.html
- (1)内置命令字符,即上面单引号内的的 i(insert)、a(append)、s(search&replace)、d(delete),插入、追加、替换、删除,分别小结了其用法。
- (2)$代表文件末尾,^代表文件开头。
- (3)sed 的 -i (注意这个是可选参数,和单引号内的 i 不是一个含义啦。)选项可以直接修改文件内容,这功能非常有帮助!如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!sed 命令却可以非常高效率的来干这个!
- (4)此外还介绍了 sed 的内置命令 s 的高级用法,sed 最擅长的就是数据修改!锅锅就说到这里,下期见!
「不甩锅的码农」原创,转载请注明来源,未经授权禁止商业用途!同名 GZH 请关注!
Original: https://www.cnblogs.com/bilahepan/p/15841199.html
Author: 不甩锅的码农
Title: 005 Linux 命令三剑客之-sed