
repl-ping-slave-period主从心跳ping的时间间隔。默认10
repl-timeout 从节点超时时间。默认60
repl-backlog-size 主节点保存操作日志的大小。默认1M
repl-backlog-ttl 主节点保存操作日志的时间。默认3600秒
client-output-buffer-limit 这个参数分为3部分,第二部分涉及slave。表示主节点输出给从节点的缓存(output-buffer)大小。默认是:256M 64M 60秒。意思是:如果output-buffer>256M则从节点需要重新全同步,如果256>output-buffer>64且持续时间60秒,则从节点需要重新全同步。
主从同步的健康监控项(info Replication ):
主节点:
master_repl_offset 主节点backlog偏移量
slave0: offset 从节点backlog偏移量
master_repl_offset-offset master_repl_offset与offset的差量为延迟backlog
从节点:
master_last_io_seconds_ago 从节点超时时间
从网络断开到恢复后。slave redis 重新链接上主库。判断是否需要做全同步,或者是增量恢复的流程图如下:
- repl-timeout 从节点超时时间。超时了会怎样?
超时了,从节点会直接重新同步一份主节点的完整数据。没有超时,则根据其他参数还可能同步增量数据而已。
- client-output-buffer-limit 这个参数分为3部分,第二部分涉及slave。表示主节点输出给从节点的缓存(output-buffer)大小。缓冲区里放的是什么?
这个参数针对有从库的主节点,output-buffer缓冲区里放的是主库待同步给从库的操作数据。
- repl-backlog-size 主节点保存操作日志的大小。这个和client-output-buffer-limit有什么关联关系吗?
针对有从库的主节点,repl-backlog-size 设置主节点缓存操作数据的可用大小。如果网络阻塞,主节点操作数据未同步给从节点而积累在缓冲区,这个缓冲区大小超过repl-backlog-size 。网路恢复之后,slave节点就必须重新从主节点同步一份完整数据。
client-output-buffer-limit 和 repl-backlog-size没有什么紧密关联。
redis 4.0 从节点需要停止一段时间的时候,可以设置 repl-backlog-ttl 为0 。不释放backlog的内容,这样启动slave的时候 可以部分同步。当然与repl-backlog-size client-output-buffer-limit 的大小也有关
Original: https://www.cnblogs.com/wangcp-2014/p/15504775.html
Author: 飘飘雪
Title: redis主从同步收到以下参数影响
相关阅读1
Title: 管道符、重定向和环境变量
一、输入重定向和输出重定向
输入重定向就是把文件作为命令的参数,输出重定向就是把原本要输出到屏幕上的内容写到文件里面。

(1)输入重定向:

(2)输出重定向;
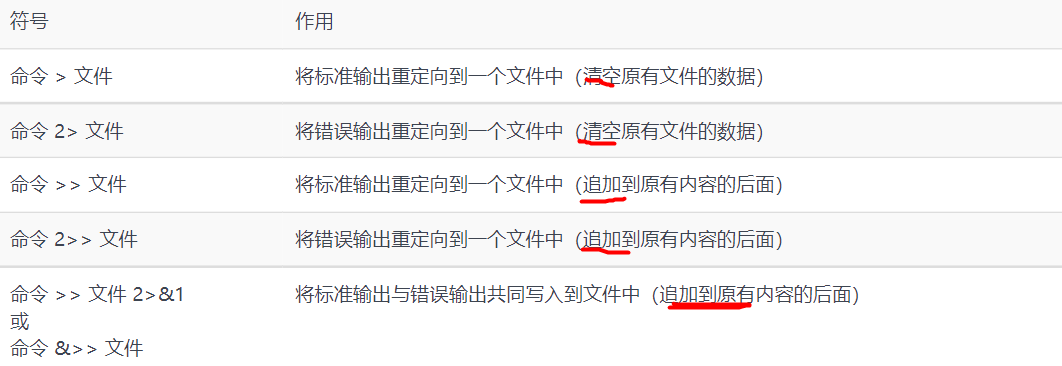
对于重定向中的标准输出模式,可以省略文件描述符1不写,而错误输出模式的文件描述符2是必须要写的。
示例:
重定向中的覆盖写入和追加写入的不同:
覆盖写入就是清除原有数据,只保留最后一次的输入;追加写入就是保留原来的数据在后面添加后来的数据

虽然都是输出重定向,但是标准输出和错误输出还是有区别的。如果文件存在则输出文件内容,如果不存在则错误消息会输出到屏幕,
如何把创建文件时的错误消息也写入呢?示例如下

还有一种常见情况,就是我们想不区分标准输出和错误输出,只要命令有输出信息则全部追加写入到文件中。这就要用到&>>操作符了:

二、管道符命令
其执行格式为" 命令A | 命令B"。管道命令符的作用也可以用一句话概括为" 把前一个命令原本要输出到屏幕的信息当作后一个命令的标准输入"
在修改用户密码时,通常都需要输入两次密码以进行确认,这在编写自动化脚本时将成为一个非常致命的缺陷。通过把管道符和passwd命令的--stdin
参数相结合,可以用一条命令来完成密码重置操作:

如果需要将管道符处理后的结果既输出到屏幕,又同时写入到文件中,则可以与tee命令结合使用。

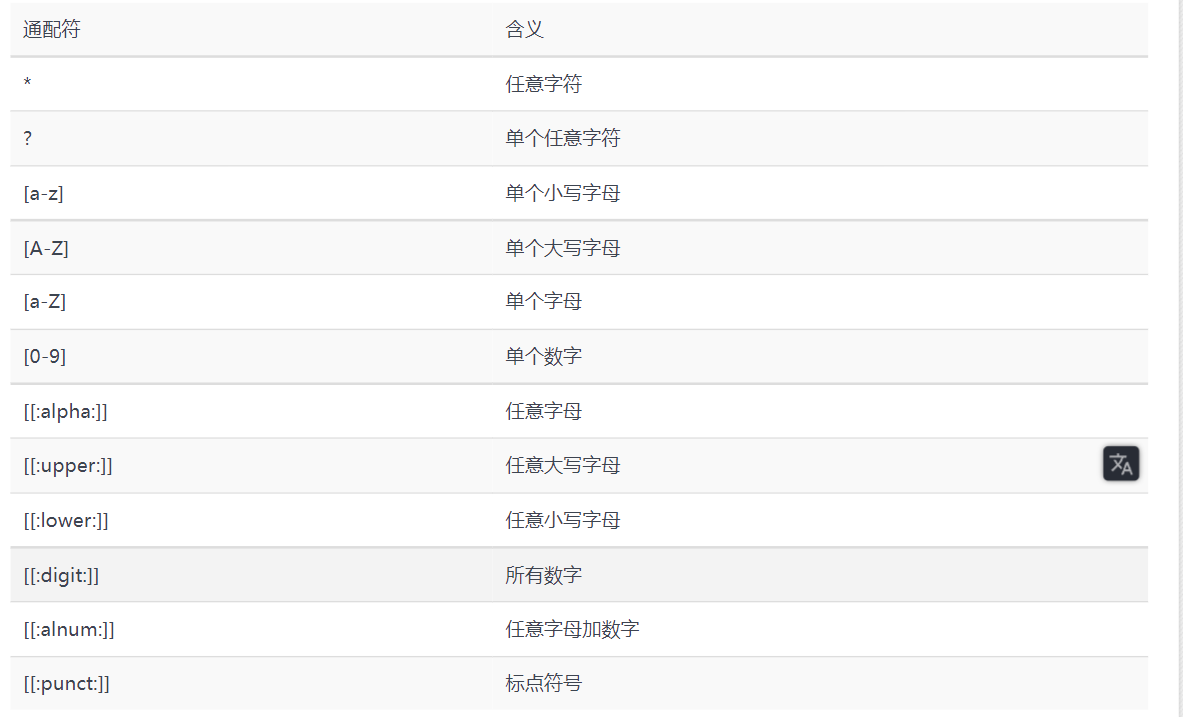
命令通配符
顾名思义,通配符就是通用的匹配信息的符号,比如星号()代表匹配零个或多个字符,问号(?)代表匹配单个字符,中括号内加上数字[0-9]代表匹配
0~9之间的单个数字的字符,而中括号内加上字母[abc]则是代表匹配a、b、c三个字符中的任意一个字符。
示例:
匹配所有在/dev目录中且以loop开头的文件:

如果只想查看文件名以ram开头,但是后面还紧跟其他某一个字符的文件的相关信息,这时就需要用到问号来进行通配了

通配符不仅可用于搜索文件或代替被通配的字符,还可以与创建文件的命令相结合,一口气创建出好多个文件。不过在创建多个文件时,需要使用大括号,
并且字段之间用逗号间隔:

转义字符
四个常见的转义字符:

我们先定义一个名为number的变量并赋值为5,然后输出以双引号括起来的字符串与变量信息:

而如果只需要某个命令的输出值,可以像 命令这样,将命令用反引号括起来,达到预期的效果。例如,将反引号与uname -a命令结合,然后使用echo命令
来查看本机的Linux版本和内核信息:

三、环境变量*
在Linux系统中,变量名称一般都是大写的,命令则都是小写的,这是一种约定俗成的规范。Linux系统中的环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的家目录、邮件存放位置等。可以直接通过变量名称来提取到对应的变量值。
为了更好地帮助大家理解变量的作用,给大家举个例子。前文中曾经讲到,在Linux系统中一切都是文件,Linux命令也不例外。那么,在用户执行了一条命令之后,Linux系统中到底发生了什么事情呢?简单来说,命令在Linux中的执行分为4个步骤。
第1步:判断用户是否以绝对路径或相对路径的方式输入命令(如/bin/ls),如果是绝对路径则直接执行,否则进入第2步继续判断。
第2步:Linux系统检查用户输入的命令是否为"别名命令",即用一个自定义的命令名称来替换原本的命令名称。
使用rm命令删除文件时,Linux系统都会要求用户确认是否执行删除操作,其实这就是Linux系统为了防止用户误删除文件而特意设置的rm别名命令—"rm -i"。

可以用alias命令来创建一个属于自己的命令别名,语法格式为"alias别名=命令"。若要取消一个命令别名,则是用unalias命令,语法格式为"unalias别名"。

第3步:Bash解释器判断用户输入的是内部命令还是外部命令。内部命令是解释器内部的指令,会被直接执行;而用户在绝大部分时间输入的是外部命令,这些命令交由步骤4继续处理。可以使用"type命令名称"来判断用户输入的命令是内部命令还是外部命令:

第4步:系统在多个路径中查找用户输入的命令文件,而定义这些路径的变量叫作PATH,可以简单地把它理解成是"解释器的小助手",作用是告诉Bash解释器待执行的命令可能存放的位置,然后Bash解释器就会乖乖地在这些位置中逐个查找。PATH是由多个路径值组成的变量,每个路径值之间用冒号间隔,对这些路径的增加和删除操作将影响到Bash解释器对Linux命令的查找。

常见环境变量:
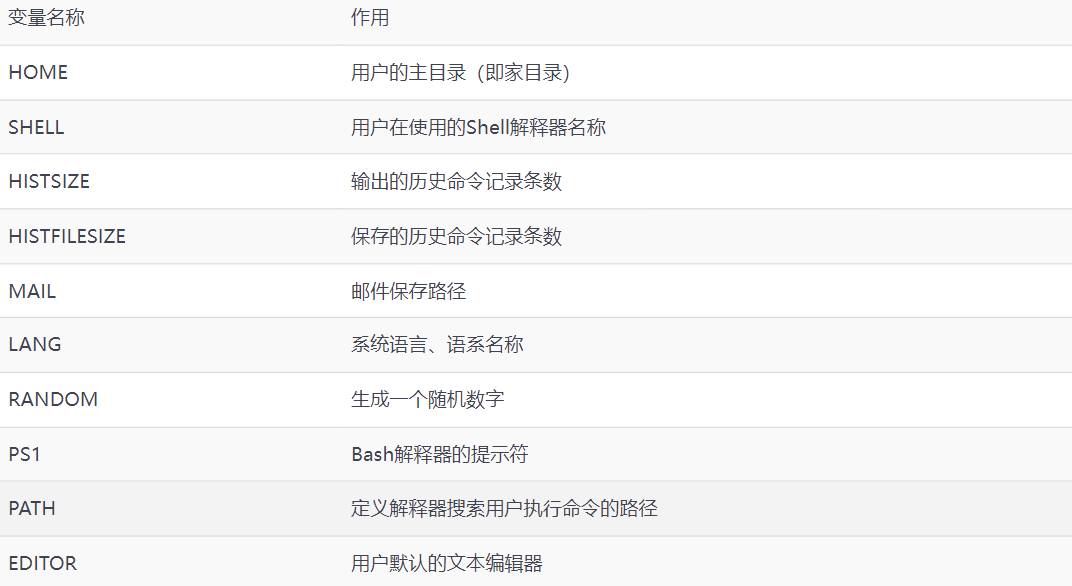
Linux作为一个多用户、多任务的操作系统,能够为每个用户提供独立的、合适的工作运行环境。因此,一个相同的变量会因为用户身份的不同而具有不同的值。

其实变量是由固定的变量名与用户或系统设置的变量值两部分组成的,我们完全可以自行创建变量来满足工作需求。例如,设置一个名称为WORKDIR的变量,方便用户更轻松地进入一个层次较深的目录:

但是这样的变量不具有全局性,如果工作需要,可以使用export命令将其提升为全局变量,这样其他用户也就可以使用它了:
后续要是不使用这个变量了,则可执行unset命令把它取消掉:
Original: https://www.cnblogs.com/-xiaopeng1/p/16267609.html
Author: 江公
Title: 管道符、重定向和环境变量
相关阅读2
Title: Bash shell
例一:
函数、返回状态值、比较
#!/bin/bash
NUM=$(date +%S)
echo "当前苹果价格是每斤$NUM元"
echo "========================"
sleep 1
clear
ipple(){
echo '这苹果多少钱一斤啊?
请猜0-60的数字'
read -p "请输入你的价格:" A
expr $A + 1 &>/dev/null
if [ $? -ne 0 ]
then
echo "别逗我了,快猜数字"
ipple
fi
}
guess(){
if [ $A -eq $NUM ]
then
echo "猜对了,就是$NUM元"
exit 0
elif [ $A -gt $NUM ]
then
echo "嘿嘿,要不你用这个价买?"
ipple
elif [ $A -lt $NUM ]
then
[root@A11-11 mnt]# vi apple.sh
#!/bin/bash
NUM=$(date +%S)
echo "当前苹果价格是每斤$NUM元"
echo "========================"
sleep 1
clear
ipple(){
echo '这苹果多少钱一斤啊?
请猜0-60的数字'
read -p "请输入你的价格:" A
expr $A + 1 &>/dev/null
if [ $? -ne 0 ]
then
echo "别逗我了,快猜数字"
ipple
fi
}
guess(){
if [ $A -eq $NUM ]
then
echo "猜对了,就是$NUM元"
exit 0
elif [ $A -gt $NUM ]
then
echo "嘿嘿,要不你用这个价买?"
ipple
elif [ $A -lt $NUM ]
then
echo "太低太低"
ipple
fi
}
main(){
ipple
while true
do
guess
done
}
mai
Original: https://www.cnblogs.com/bluewelkin/p/4843402.html
Author: kin2321
Title: Bash shell
相关阅读3
Title: Linux 磁盘挂载和swap空间管理
mount device mountpoint --- mount 设备名 挂载点(一个目录)
#mountpoint:挂载点目录必须事先存在,建议使用空目录
- -t fstype:指定文件系统类型,比如ext4
- -r readonly,只读挂载
- -w read and write, 读写挂载,此为默认设置,可省略
- -n 不更新/etc/mtab,mount不可见
- -a 自动挂载所有支持自动挂载的设备(定义在了/etc/fstab文件中,且挂载选项中有auto功能)
- -o options:(挂载文件系统的选项),多个选项使用逗号分隔
#使用-o命令后面的一些选项:
# async   异步模式,内存更改时,写入缓存区buffer,过一段时间再写到磁盘中,效率高,但不安全
# sync   同步模式,内存更改时,同时写磁盘,安全,但效率低下
# remount 重新挂载(相当于umount后再mount)
# ro/rw 只读、读写
# defaults(默认挂载) 相当于rw, suid, dev, exec, auto, nouser, async
- 一个挂载点同一时间只能挂载一个设备,如果挂载了多个设备就只显示最后一个设备
- 一个设备可以挂载到多个挂载点
- 挂载点通常是空的目录文件
#执行mount命令时,通过查看/etc/mtab文件显示当前已挂载的所有设备
mount
#查看内核追踪到的已挂载的所有设备
cat /proc/mounts
findmnt   MOUNT_POINT|device #挂载点或者设备名
#可以用来判断某个文件夹是不是挂载点,如果是会显示对应的数据信息
lsof MOUNT_POINT ---也可以用来查看某个挂载点是否被别人使用
fuser -v MOUNT_POINT -- 查看是谁在使用
fuser -km MOUNT_POINT
将挂载保存到 /etc/fstab 中可以下次开机时,自动启用挂载
#使用`man 5 fstab `查看/etc/fstab配置文件格式
格式:
要挂载的文件系统 挂载点 文件系统类型 挂载属性 备份频率 sck检查的文件系统的顺序
#说明:
- 要挂载的文件系统:可以用设备名、uuid、卷标 #查看uuid: blkid
- 挂载点:必须是事先存在的目录
- 挂载属性:defaults ,acl,bind
- 备份频率(一般用不上):0:不做备份 1:每天转储 2:每隔一天转储
- 文件系统检查的次序:开机检测文件系统的过程。其中允许的数字是0 1 2
#0:不自检 ,1:首先自检;一般只有rootfs才用 2:非rootfs使用
umount 设备名或挂载点
swap:一种特殊的文件系统,叫交换文件系统。
缓解内存不足的情况。拿硬盘的分区来模拟内存,把内存中暂时不用的数据导入swap硬盘分区中,给内存腾出空间。利用硬盘来模拟内存.
硬盘速度没有内存的速度快,所以会降低速度。
实际内存 分配的swap空间
1. 创建交换分区或者文件 -- fdisk
2. 使用mkswap写入特殊签名 -- maswap 分区
3. 在/etc/fstab文件中添加适当的条目 # 文件系统没有挂挂载点就写none 因为swap是用来模拟内存的
4. 使用swapon -a 激活交换空间
swapon [OPTION]... [DEVICE]
#选项
-a: 启用所有的交换分区
-s: 显示交换区的使用状况
swapoff [OPTION]... [DEVICE]
#选项:
-a:禁用所有的swap分区
有多个二swap分区的时候,指定优先使用谁。
swapon -s 可以查看swap的优先级
#可以指定swap分区0到32767的优先级,值越大优先级越高
在编写/etc/fstab文件的时候,通过pri来指定它的优先级
例如:UUID=xxxxswap   swap    pri=100    0 0 #更改完成以后禁用再重新启用就生效了
#创建一个指定大小的文件
dd if=/dev/null of=filename bs=大小 count=1
#因为这个文件后面要用来放内存中的信息,所以为了安全要更改权限
chmod a= filename #除了root谁也看不到
#创建文件系统
mkswap filename
#挂载 /etc/fstab
file_name(不能写uuid,uuid是针对设备来说的) none swap defaults 0 0
#启用swap
swapon file_name
/proc/sys/vm/swappiness `的值决定了当内存占用达到一定的百分比时,会启用swap分区的空间
例如/proc/sys/vm/swappiness这个值是30,则内存在使用到100-30=70%的时候,就开始出现有交换分区的使用
#/proc/sys/vm/swappiness值为0不会禁止交换分区的使用,是最大限度地降低了使用swap的可能性
Original: https://www.cnblogs.com/heyongshen/p/16437676.html
Author: 背对背依靠
Title: Linux 磁盘挂载和swap空间管理