
1 慢查询
默认情况下命令若是执行时间超过10ms就会被记录到日志,slowlog只会记录其命令执行的时间,不包含io往返操作,也不记录单由网络延迟引起的响应慢。如果想修改慢命令的标准可以使用下面的命令
超过5毫秒为慢命令
config set slowlog-log-slower-than 5000
获取最慢的n条数据
slowlog get {n}
eg.
127.0.0.1:6379> slowlog get 2
1) 1) (integer) 7923
2) (integer) 1544423728
3) (integer) 27501
4) 1) "KEYS"
2) "*"
参数含义:
- 1=日志的唯一标识符
- 2=被记录命令的执行时间点,以 UNIX 时间戳格式表示
- 3=查询执行时间,以微秒为单位。例子中命令使用27毫秒。
- 4= 执行的命令,以数组的形式排列。完整命令是config get *。
2 大对象
使用scanning方式,对redis整个keyspace进行统计(数据量大时采样),寻找每种数据类型key的最大size(key)和平均size。(5种数据类型(String、hash、list、set、zset)的最大key). 该程序使用 SCAN 命令,因此它可以在不影响客户端操作的情况下在繁忙的服务器上执行,不过也可以使用-i选项来限制所请求的每100个键的扫描过程的秒数。 例如,-i 0.1会减慢程序的执行速度,但也会大幅减轻服务器上的负载 执行命令:
redis-cli -h {ip} -p {port} --bigkeys
建议:
把大对象拆分为多个小对象,防止一次命令操作过多数据
eg.
~]# redis-cli --bigkeys
#Scanning the entire keyspace to find biggest keys as well as
#average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
#per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far 'db:zz' with 23 bytes
[00.00%] Biggest string found so far 'prefix_1519436646796_2018_5_320401_001_9' with 73 bytes
[00.00%] Biggest string found so far 'prefix_1511407515841_2018_5_320586_101_-1' with 74 bytes
[00.00%] Biggest string found so far 'XX152844756614862018' with 1219 bytes
[00.03%] Biggest string found so far 'xxxx.m.164c2285-f8ed-4ed9-ad5e-c8633846ac95.21001004' with 24662 bytes
[00.25%] Biggest string found so far 'cpt.xml.model.key:280' with 32914 bytes
[00.71%] Biggest string found so far 'xxxx.m.164c2285-f8ed-4ed9-ad5e-c8633846ac95.48' with 94341 bytes
[01.84%] Biggest set found so far 'spring:session:expirations:1545198360000' with 2 members
[05.58%] Biggest hash found so far 'spring:session:sessions:53490998-30c2-4850-8f73-646fe82cd7ee' with 4 fields
[06.29%] Biggest string found so far 'xxxx.m.164c2285-f8ed-4ed9-ad5e-c8633846ac95.35001001' with 120437 bytes
[07.74%] Biggest hash found so far 'spring:session:sessions:c28d62e7-27c5-439b-aaf7-7e3d7915db62' with 10 fields
[08.14%] Biggest string found so far 'xxxx.m.d526ca6d-f9a3-48f4-8117-3474778d1fbd.221' with 420048 bytes
[08.70%] Biggest string found so far 'xxxx.m.164c2285-f8ed-4ed9-ad5e-c8633846ac95.221' with 420086 bytes
[53.84%] Biggest set found so far 'spring:session:expirations:1545198540000' with 4 members
[81.98%] Biggest hash found so far 'spring:session:sessions:f3459c14-fb8d-44cc-beab-20a68a2699f0' with 11 fields
[82.04%] Biggest string found so far 'qwer' with 443204 bytes
keys mem clients blocked requests connections
33463 39.28M 128 0 1597991946 (+0) 21894492
33463 39.37M 127 0 1597991987 (+41) 21894500
33463 39.29M 127 0 1597992021 (+34) 21894500
33463 39.26M 127 0 1597992060 (+39) 21894500
33463 39.37M 127 0 1597992098 (+38) 21894500
- 客户端相关参数 127.0.0.1:6379> info Clients #Clients connected_clients:126 client_longest_output_list:0 client_biggest_input_buf:0 blocked_clients:0
## 4 连接的客户端数量(connected_clients)sh redis-cli -h {ip} -p {port} info Clients | grep connected_clients
这个值跟使用redis的服务的连接池配置关系比较大,Redis默认允许客户端连接的最大数量是10000。
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "10000"
若是看到连接数超过5000以上,那可能会影响Redis的性能。倘若一些或大部分客户端发送大量的命令过来,这个数字会低的多。根据连接数负载的情况,这个数字应该设置为预期连接数峰值的110%到150之间,若是连接数超出这个数字后,Redis会拒绝并立刻关闭新来的连接。通过设置最大连接数来限制非预期数量的连接数增长,是非常重要的。 eg.
~]# redis-cli info Clients | grep connected_clients
connected_clients:129
5 拒绝连接数
redis-cli info stats | grep rejected_connections
eg.
~]# redis-cli info stats | grep rejected_connections
rejected_connections:0
6 阻塞客户端数量
blocked_clients,一般是执行了list数据类型的BLPOP或者BRPOP命令引起的,这个值最好应该为0
redis-cli -h {ip} -p {port} info Clients | grep blocked_clients
eg.
~]# redis-cli info Clients | grep blocked_clients
blocked_clients:0
7 内存碎片率
~]# redis-cli -h {ip} -p {port} info | grep mem_fragmentation_ratio
mem_fragmentation_ratio:1.58
info信息中的mem_fragmentation_ratio给出了内存碎片率的数据指标,它是由操系统分配的内存除以Redis分配的内存得出: used_memory和used_memory_rss数字都包含的内存分配有:
- 用户定义的数据:内存被用来存储key-value值。
- 内部开销: 存储内部Redis信息用来表示不同的数据类型。
used_memory_rss的rss是Resident Set Size的缩写,表示该进程所占物理内存的大小,是操作系统分配给Redis实例的内存大小。除了用户定义的数据和内部开销以外,used_memory_rss指标还包含了内存碎片的开销,内存碎片是由操作系统低效的分配/回收物理内存导致的。
内存碎片率稍大于1是合理的,这个值表示内存碎片率比较低,也说明redis没有发生内存交换。但如果内存碎片率超过1.5,那就说明Redis消耗了实际需要物理内存的150%,其中50%是内存碎片率。若是内存碎片率低于1的话,说明Redis内存分配超出了物理内存,操作系统正在进行内存交换。
8 监视在Redis中执行的命令
使用MONITOR模式后,将自动输入监控模式。它将打印Redis实例收到的所有命令
redis-cli -h {ip} -p {port} monitor
eg.
~]# redis-cli monitor
OK
1545199828.803965 [0 172.23.0.238:60576] "PING"
1545199828.804126 [0 172.23.0.238:60576] "SETNX" "scanKey" "xxxxxx"
1545199828.804392 [0 172.23.0.238:60576] "PING"
1545199828.804572 [0 172.23.0.238:60576] "PEXPIRE" "scanKey" "10000"
参考地址: https://redis.io/topics/rediscli https://www.cnblogs.com/mushroom/p/4738170.html
Original: https://www.cnblogs.com/rwxwsblog/p/13735048.html
Author: 秋楓
Title: Redis相关监控参数【转】
相关阅读1
Title: VirtualBox安装Ubuntu教程
镜像下载、域名解析、时间同步请点击阿里云开源镜像站
准备工作
virtualBox可在官网下载,Ubuntu镜像可在 阿里云下载,选择对应电脑位数的镜像。
开始安装
1、点击"新建"按钮

1.1 设置好安装目录、系统类型、系统版本

1.2 分配内存
可以根据实际情况,且后期可以更改

1.3 默认"现在创建虚拟硬盘"

1.4 默认"VDI(VirtualBox磁盘映像)"

1.5 默认"动态分配"

1.6 确定文件位置和大小
文件位置根据1.1选择的位置默认生成,虚拟硬盘大小可以给大一点(默认10GB),毕竟它不会立即占用这么大的空间。

1.7.1 选择"设置"按钮配置虚拟机

1.7.2 在"存储"栏,依次选择

点击"选择虚拟盘"后,选择Ubuntu镜像即可。
2、点击"启动"

2.1 选择语言,点击"安装 Ubuntu"

2.2 一路"继续"

默认选中"安装Ubuntu时下载更新"(即使不选中,后边还是会下载......😶回想一下,它的意思应该是:我总是要下载的,你让我现在开始下还是待会下)





等待......

再等......

还要等......

等的花都谢了......


3、安装增强功能
3.1 点击"设备","安装增强功能"


则需要按照其提示安装 gcc make perl,

之后重启再安装。
3.2 共享文件夹


共享文件夹路径为windows系统上所要共享的路径;选中自动挂载,固定分配。
另外,共享文件夹在Ubuntu下的路径为:"/media/sf_share",如果提示权限不够,可以使用 sudo -s 命令切换到root用户即可,最后记得退出(exit)。

本文转自:https://blog.csdn.net/z456531/article/details/118613529
Original: https://www.cnblogs.com/helong-123/p/16135091.html
Author: 萌褚
Title: VirtualBox安装Ubuntu教程
相关阅读2
Title: 大小端存储是什么鬼?
以下内容为本人的著作,如需要转载,请声明原文链接微信公众号「englyf」 https://mp.weixin.qq.com/s/htYGddzO2xPl9kDN4lANpQ
大小端存储的划分是为了解决长度大于一个字节的数据类型内容在存储地址上以不同顺序分布的问题。
比如16位的short整形,32位的int整形,64位的long整形,它们在存储地址上,其实最小的划分单位是字节,那么高低位的字节排列在从低到高的存储地址上有什么规定呢?
如果最高位的字节数据存在最低地址上,而次高位的字节数据按次序排列在次低的地址上,那么这种存储方式就叫 大端存储。
如果最低位的字节数据存在最低地址上,而次低位的字节数据按次序排列在次低的地址上,那么这种存储方式就叫 小端存储。
那么怎么去判断当前系统属于大端存储还是小端存储呢?
判断方法一:利用单字节类型强制转换多字节类型变量获取返回值比较
下面让我们看看实例代码:
#include <iostream>
using namespace std;
bool IsSystemBigEndianStorage()
{
short src = 1;
char comp = (char)src;
return (comp == 0);
}
int main()
{
bool ret = IsSystemBigEndianStorage();
if (ret) {
cout << "big endian" << endl;
} else {
cout << "small endian" << endl;
}
return 0;
}
</iostream>
首先把单字节范围内的数据值(比如1)赋给更大长度的类型(比如2个字节的short)变量 src,然后利用单字节长度的数据类型(char)强制转换变量 src,会在内存空间上截取变量 src对应存储在最低地址的一个字节数据并返回。
bool IsSystemBigEndianStorage()
{
short src = 1;
char comp = (char)src;
return (comp == 0);
}
可以看到变量src的高位字节数据为0,低位字节数据为1,各不相同。
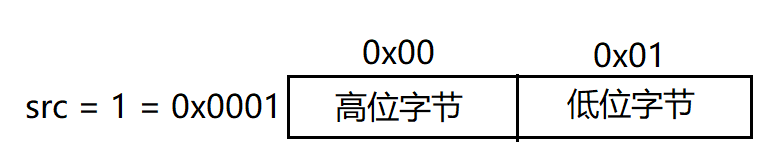
如果 (char)src的返回值等于0,就表示存储在最低地址的字节数据等于高位字节数据0x00,属于 大端存储,否则表示属于 小端存储。
判断方法二:利用联合体类型union比较内部的单字节数据
修改一下上面的函数 IsSystemBigEndianStorage:
bool IsSystemBigEndianStorage()
{
union {
short a;
char b;
} temp;
temp.a = 1;
return (temp.b == 0);
}
可以看到变量 temp.a的高位字节数据为0,低位字节数据为1,各不相同。

根据内存空间中字节对齐的规律,联合体union类型,各成员变量的起始地址是一样的。即使各成员变量的数据长度不一样也不影响。
也就是说 temp.a最低地址空间的数据内容就是 temp.b的数据内容。
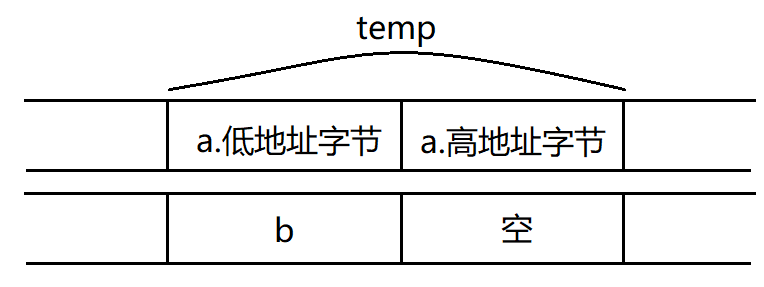
如果 temp.b的值等于0,就表示存储在最低地址的字节数据等于高位字节数据0x00,属于 大端存储,否则表示属于 小端存储。
关于网络字节顺序
网络中充斥着各种各样的终端设备或者中间代理路由等,数据利用网络进行传输,传输的基本数据单位也是字节,于是多字节类型的数据也会面临大小端的传输顺序定义。
所以,在传输前和传输后的设备怎么同步这个多字节类型数据的存储呢?由传输前后端的设备共同决定吗?
比如两个不同地区的人碰到一起,如果没有约定俗成的共同语言,一样不知如何去交流。
在数据成功传送和解读完整前,数据两端的设备不会理解对方的意图,那么就有必要由第三方来统一明确定义传输顺序。
于是,TCP/IP 协议规定了网络传输多字节类型数据时,先传输高位的字节数据,次高位的字节数据在其后接着传输。而数据在被网络接口发送到网络时,需要从内存逐字节读取出来,从低地址往高地址开始发送。那么可见在网络传输中,数据的字节顺序形式是大端存储。
本地数据怎么和网络字节顺序转换?
下面针对本地系统为linux举个例子
从本地系统存储顺序转换为网络字节顺序
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
从网络字节顺序转换为本地系统存储顺序
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
Original: https://www.cnblogs.com/englyf/p/16656222.html
Author: englyf八戒
Title: 大小端存储是什么鬼?
相关阅读3
Title: Bitmap在Redis中的应用(转)
原文:https://cloud.tencent.com/developer/news/387248
作者:一叶而不知秋
作为铺垫,我们先来介绍一些Bitmap的相关内容:
位图主要用于快速检索关键字状态,通常要求关键字是一个连续的序列(或者关键字是一个连续序列中的大部分), 最基本的情况,使用1bit标示一个关键字的状态(可标示两种状态),但根据需要也可以使用2bit(标示4种状态),3bit(标示8种状态)。 位图的主要应用场合:标示连续(或接近连续,即大部分会出现)的关键字序列的状态(状态数/关键字个数 越小越好)。
几种应用场景:
(1)磁盘空闲块的管理
很多文件系统采用bitmap管理磁盘空闲块,如果该块是空闲的,标为0,已使用则标为1; Ext3文件系统中使用位图来管理磁盘空闲块(空闲inode节点)。文件系统创建后,该文件系统拥有的块数以及inode节点数都是确定的,数据块区包含一系列连续的块(块号是连续的),于是可以用位图来标示数据块的分配状态(已分配、未分配两种状态,1bit即可标示)。
如下图,假设ext3的数据块从128开始,一直到1024,则需要1024-128 = 996bit = 128字节的位图空间。如下图,第1bit标示128号块已经被分配,第2bit标示129号块未被分配,依次类推。使用位图的高效性在于:1bit标示状态,节省存储空间,通过关键字来定位位图(偏移是固定的),效率高。
(2)区域服务器路由场景
腾讯的QQ号用一个数字标示,范围从0到20亿,每个QQ号都有可能出现,所有的QQ号被分散的存储北京、上海、深圳、武汉四个城市的服务器中,现在需要一个路由服务器快速的将登陆的QQ路由到正确的服务器,路由服务器可以读取四个QQ服务器的数据,并构建路由表(需全部存在内存中,内存限制1G),路由表该如何存储?
关键:QQ号从0-20亿,每个号码都有可能出现;服务器通过0、1、2、3标示,这四种状态可以用2bit来标示,于是可以考虑使用位图来描述路由表。
解法:从0~20亿,为每个QQ号分配2bit,路由服务器从QQ服务器中获取信息,并设置QQ于服务器号的对应关系。当QQ登录时,路由服务器根据QQ号定位到其对应的状态,并返回对应的服务器号。总的内存大小20亿 * 2 /8 = 5亿字节(约为0.5G)。
(3)大量数据的快速排序、查找、去重
关键:去掉电话号码的800后面就是7位的十进制整数,每个整数都有可能出现而且不会重复出现,可以采用各种排序算法对这些数据进行排序,但时间复杂度都在O(NlogN)及以上。
解法:因每个七位以内的整数都有可能出现,可以用1bit来标示电话号是否出现,遍历整个电话号序列,设置相应的位,遍历位图收集位被设置的号码即可,时间复杂度为O(N);
【去重】场景:2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数。 关键:一个数字的状态只有三种,分别为不存在,只有一个,有重复。因此,我们只需要2bits就可以对一个数字的状态进行存储了,假设我们设定一个数字不存在为00,存在一次01,存在两次及其以上为11。那我们大概需要存储空间几十兆左右。
解法:遍历一次这2.5亿个数字,如果对应的状态位为00,则将其变为01;如果对应的状态位为01,则将其变为11;如果为11,,对应的状态位保持不变。 最后,我们将状态位为01的进行统计,就得到了不重复的数字个数,时间复杂度为O(n)。
Redis与Bitmap
因为redis的key和value本身就支持二进制的存储方式,所以bitmap只是一个独特的扩展,并不是新的数据类型。他的最大长度就是512M,即2^32个不同字节。
bitmap相关指令介绍:
getbit key offset //获取字符串类型键指定位置的二进制位的值
bitcount key [start] [end] //获取字符串类型键中为1的二进制位个数,start、end是字节的范围
bitpos key value start end //指定区间查询某个key的二进制位中首次出现0或1的位置(start和end是字节位置,不是bit位置)
bitop operation destkey key [key ...] //bitop命令可以对多个字符串进行位运算,并将结果存储在destkey参数指定的键中。bitop支持的运算操作有AND、OR、XOP和NOT。
魔术指令 bitfield:
bitfield key [GET type offset] [SET type offset value] [INCRBY type offset increment] [OVERFLOW WRAP|SAT|FAIL] bitfield 有三个子指令,分别是 get/set/incrby,它们都可以对指定位片段进行读写,但是最多只能处理 64 个连续的位,如果超过 64 位,就得使用多个子指令,bitfield 可以一次执行多个子指令。
示例:
应用场景:
(1)用户签到
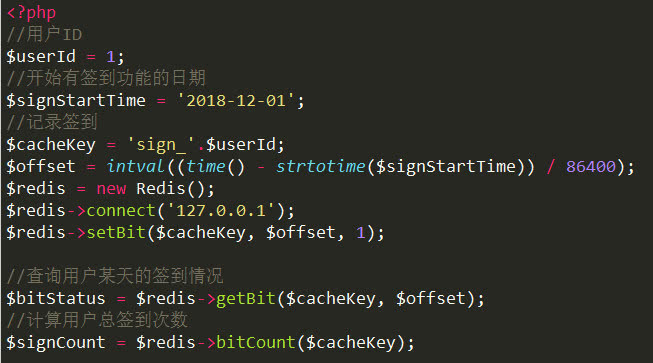
1个用户1年会占用大约:1bit*365/8=45.625字节;
如果使用普通的 key/value,每个用户要记录 365 个,当用户量巨大时,需要的存储空间是惊人的。
(2)用户在线状态
只需要一个key,用户ID为offset,如果在线就设置为1,不在线就设置为0,1000万用户只需要100000000bit/8*=1.2MB的空间;
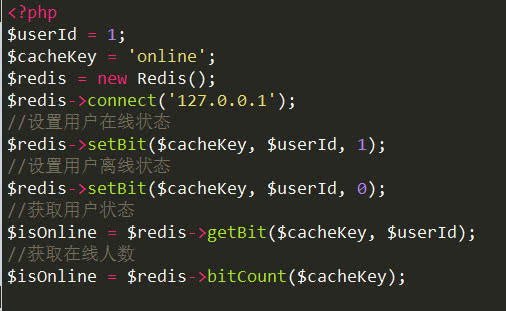
(3)统计活跃用户
使用时间作为cacheKey,然后用户ID为offset,如果当日活跃过就设置为1;
如果想计算某几天的活跃用户呢(暂且约定,统计时间内只要有一天在线就称为活跃);

Original: https://www.cnblogs.com/ajianbeyourself/p/15682237.html
Author: 奋斗终生
Title: Bitmap在Redis中的应用(转)