
记录OpenCV正确安装与调用过程
我的CMakeLists.txt如下:
cmake_minimum_required(VERSION 3.18)
project(test)
set(CMAKE_CXX_STANDARD 11)
set(OpenCV_DIR "G:\\opencv\\mingw64_build")
find_package( OpenCV REQUIRED )
include_directories( ${OpenCV_INCLUDE_DIRS} )
add_executable(test test01.cpp)
target_link_libraries(test ${OpenCV_LIBS})
cpp代码如下:
#include
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
int main()
{
Mat images;
images = imread("1.jpg",0);
cv::Mat grayim;
Size dsize = Size(120, 160);
Mat shrink;
resize(images, shrink, dsize, 0, 0, INTER_AREA);
imwrite("after.jpg", shrink);
cout<<"处理完成!"<<endl;
return 0;
}
因为我的c++程序采用mingw64编译,所以使用
cmake -G "MinGW Makefiles" ..
mingw32-make
之后,总是出现undefined reference to cv::Mat::Mat()等一系列的undefined reference to XXX
原因是没有正确链接到动态库。或者之前有安装其他版本的opencv
解决办法
重新编译一份OpenCV的源码再使用
编译过程参考:
https://blog.huihut.com/2018/07/31/CompiledOpenCVWithMinGW64/
https://github.com/huihut/OpenCV-MinGW-Build
第二个链接提供了已经有编译好opencv库,使用这个编译好的库的前提是自己的环境和作者的环境一样。所以还是自己编译吧。否则到最后会出现下图这样的问题:

这个错误是我下载上面链接提供的opencv库,cmake 、make 都没问题,最后执行可执行文件时,出现的错误。
其实就是版本的问题,后来我自己编译出来的动态库就是libopencv_core460.dll。就没有这样的问题。
最后还要添加环境变量
将bin目录加到系统的环境变量PATH里,方便程序在运行时能够找到对应的动态库。
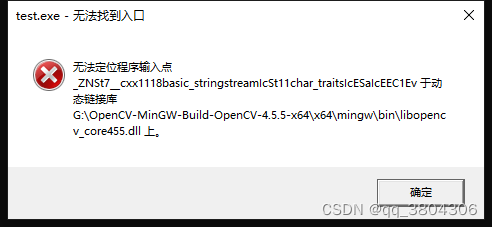
将bin(G:\opencv\mingw64_build\bin)目录下的所有.dll文件复制到C:\Windows\System32目录下, 否则会出现无法定位程序输入点...于动态链接库...上。如下图:
最后程序正常运行。


在这之前还将/Mingw/bin目录下的libstdc+±6.dll文件放在了C:\Windows\System32目录下。不知道有没有发挥这个作用,也懒得验证了。
ubuntu也是一样的,gcc, g++版本样一样,编译自己写的程序使用的gcc/g++版本要和编译opencv库时使用的gcc/g++版本要一样。
如有错误之处,欢迎指正!
https://blog.csdn.net/qq_45662588/article/details/115949733
https://blog.csdn.net/diaolunlaoshi/article/details/117451891
https://blog.huihut.com/2018/07/31/CompiledOpenCVWithMinGW64/
Original: https://blog.csdn.net/qq_38043069/article/details/125321250
Author: qq_3804306
Title: 调用OpenCV库出现: undefined reference to `xxxxx‘ 的解决办法(使用MinGW编译器)
相关阅读1
Title: win10/win11系统下安装tensorflow-GPU版本
win10/win11系统下安装tensorflow-GPU版本
使用前注意
GPU版本
GPU版的tensorflow在调用的时候有加速效果,运行会比较快一些,当然,如果你的硬件没有GPU,只能使用CPU版本的tensorflow,就不需要安装CUDA和cuDNN,直接运行
pip install tensorflow
即可。
版本匹配!!!
tensorflowGPU版本对python、cuda和cuDNN的版本之间的匹配要求是非常高的,如果版本不匹配很有可能出现运行报错的情况。建议在使用和安装tensorflow之前查询官方文档,确定版本关系。
版本对应关系见网站:
链接: https://tensorflow.google.cn/install/source_windows.
cuda版本
使用控制面板 ,找到NVIDIA控制面板
点击左下角《系统信息》,出现如下界面:
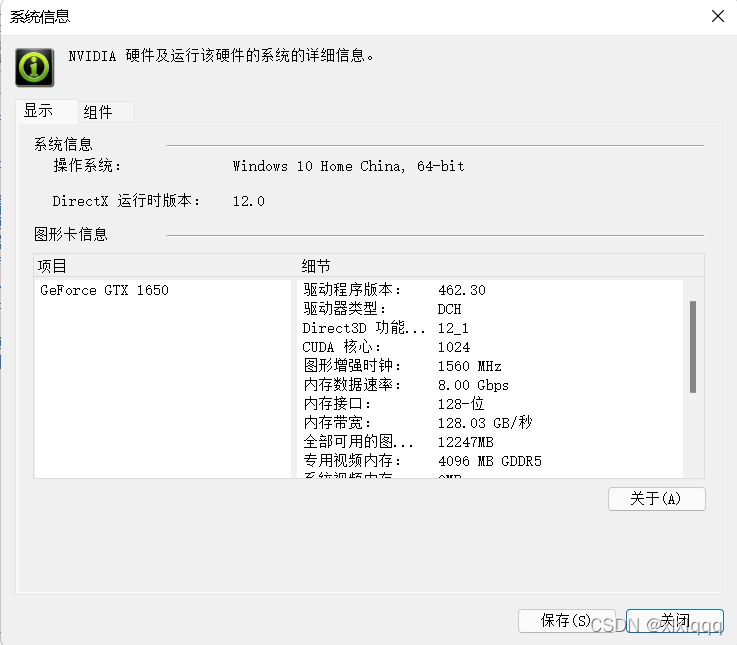
切换至《组件》,呈现如下:
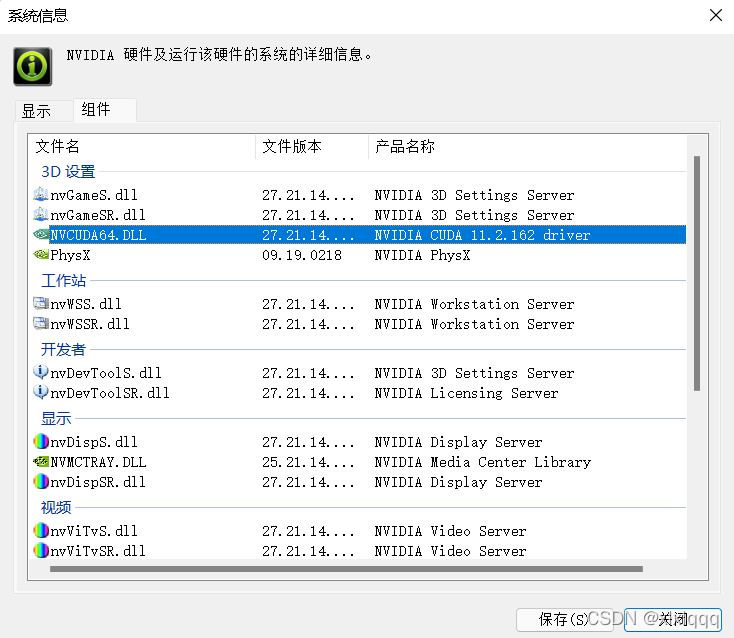
可以看到,我的电脑CUDA的版本为11.2版本。
; 安装anaconda
Anaconda的安装和CUDA系列安装并无必须的匹配关系,可以自行搜索教程安装。
安装对应版本的CUDAtoolkit
NVIDIA控制面板显示我的CUDA为11.2版本,因此进入到anaconda prompt下(也可以在conda提供的虚拟环境下)采用如下命令安装
conda install cudatoolkit=11.2
意外的是,在我安装的时候(2022.1.29),国内的镜像源还没有出现11.2版本的cuda去安装,这里我便采用了官网去下载cuda安装包。
官网下载cuda: https://developer.nvidia.com/cuda-toolkit-archive.
进入后,找到你想下载的版本,下载好安装包之后,双击,之后根据提示完成安装即可,在这里一定要记下来CUDAtoolkit的安装路径!。
安装对应版本的cuDNN
根据之前的查询结果,cuda11.2版本最好对应cuDNN8.1版本,不幸的是,镜像源依旧没有该版本的cuDNN供下载,否则,你可以使用
conda install cuDNN=8.1
进行安装。
为了解决这一问题,可以去官网进行下载cuDNN包,
cuDNN官网:https://developer.nvidia.com/rdp/cudnn-archive.
这里比较麻烦的一点是:下载cuDNN必须注册NVIDIA账号!
从官网下载的cuDNN实际上只有一个压缩包,解压之后会发现:
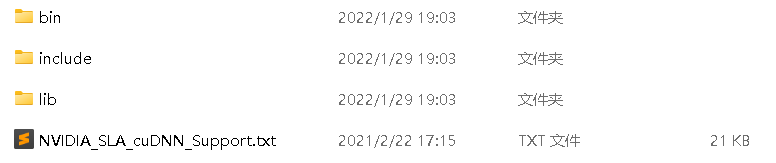
这时候,只需要将bin里面的所有文件复制到CUDAtoolkit的bin路径下,如下图:

然后将cuDNN下的include里面的所有文件复制到CUDAtoolkit的include的路径下,如下图:

将cuDNN下的lib里面的所有文件复制到CUDAtoolkit的lib路径下:

到这里cuDNN就算安装完成了。
; 安装tensorflow
实际上安装tensorflow并不难,只要运行
pip install tensorflow-GPU
会自动安装。
最后,运行
pip list
查看你安装的tensorflow版本号是多少,是否和你的CUDA/cuDNN匹配。
总结
安装tensotflow-GPU最要紧的就是注意你要需要的版本是什么,你安装的版本是什么!
祝顺利!
Original: https://blog.csdn.net/xlxlqqq/article/details/122747988
Author: xlxlqqq
Title: win10/win11系统下安装tensorflow-GPU版本
相关阅读2
Title: win11+RTX3060搭建tensorflow深度学习环境
cuda简介:
CUDA是NVIDIA发明的一种并行计算平台和编程模型。
它可以通过利用图形处理器(GPU)的能力来显著提高计算性能。
CUDA的开发有以下几个设计目标:
1.为标准编程语言(如C)提供一小组扩展,以实现并行算法的直接实现。
2.使用CUDA C/ c++,程序员可以专注于算法的并行化,而不是把时间花在算法的实现上。
3.支持异构计算,应用同时使用CPU和GPU。
应用程序的串行部分运行在CPU上,并行部分被卸载到GPU上,
这样CUDA就可以增量地应用到现有的应用程序上。
CPU和GPU被视为具有各自内存空间的独立设备。
这种配置还允许在CPU和GPU上进行同步计算,而无需争夺内存资源。
cuda支持的GPU有数百个内核,这些内核可以同时运行数千个计算线程。
这些核心拥有共享的资源,包括一个寄存器文件和一个共享的内存。
片上共享内存允许运行在这些核心上的并行任务共享数据,而无需通过系统内存总线发送数据
安装步骤:双击一直下一步就行
测试:打开cmd,执行命令 nvcc -V和 nvidia-sim 查看对应信息
cudnn简介:
1.cuDNN 8 的新功能
cuDNN 8 针对 A100 GPU 进行了优化,可提供高达 V100 GPU 5 倍的开箱即用性能,并且包含适用于对话式 AI 和计算机视觉等应用的新优化和 API。
它已经过重新设计,可实现易用性和应用集成,同时还能为开发者提供更高的灵活性。
2.cuDNN 8 的亮点包括
已针对 NVIDIA A100 GPU 上的峰值性能进行调优,包括全新 TensorFloat-32、FP16 和 FP32
通过重新设计的低级别 API,可以直接访问 cuDNN 内核,从而实现更出色的控制和性能调优
向后兼容性层仍然支持 cuDNN 7.x,使开发者能够顺利过渡到新版 cuDNN 8 API
针对计算机视觉、语音和语言理解网络作出了新优化
已通过新 API 融合运算符,进而加速卷积神经网络
cuDNN 8 现以六个较小的库的形式提供,能够更精细地集成到应用中。开发者可以下载 cuDNN,也可从 NGC 上的框架容器中将其提取出来。
3.主要特性
3.1 为所有常用卷积实现了 Tensor Core 加速,包括 2D 卷积、3D 卷积、分组卷积、深度可分离卷积以及包含 NHWC 和 NCHW 输入及输出的扩张卷积
3.2 为诸多计算机视觉和语音模型优化了内核,包括 ResNet、ResNext、SSD、MaskRCNN、Unet、VNet、BERT、GPT-2、Tacotron2 和 WaveGlow
3.3 支持 FP32、FP16 和 TF32 浮点格式以及 INT8 和 UINT8 整数格式
3.4 4D 张量的任意维排序、跨步和子区域意味着可轻松集成到任意神经网络实现中能为任意 CNN 架构上融合的运算提速
3.5 数据中心采用 Ampere、Turing、Volta、Pascal、Maxwell 和 Kepler GPU 架构以及配备移动 GPU 的 Windows 和 Linux 支持 cuDNN。
安装:解压后将各文件夹下的文件复制到cuda安装路径下的对应文件夹里
# 相关配置
# conda配置国内清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
# 显示下载源
conda config --set show_channel_urls yes
# 查看conda的配置
conda config --show
# pip配置国内清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 创建并激活环境
conda create tf2_6 python=3.9
conda activate tf2_6
# 安装tf-gpu-2.6.2
pip install tensorflow-gpu==2.6.2
import tensorflow as tf
print(tf.__version__) #2.6.2
print(tf.test.is_gpu_available()) # 为True表示安装成功
注意:目前没有手动配置环境变量,如果后续代码有问题可能需要配一下
https://blog.csdn.net/qq_33534428/article/details/125337424?spm=1001.2014.3001.5502
- https://cloud.tencent.com/developer/article/1914694
- https://tensorflow.google.cn/install/gpu
- https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/
- https://docs.microsoft.com/en-us/windows/ai/directml/gpu-accelerated-training
Original: https://blog.csdn.net/qq_33534428/article/details/122235888
Author: 凌陨心
Title: win11+RTX3060搭建tensorflow深度学习环境
相关阅读3
Title: 深度学习地震勘探入门
深度学习地震勘探入门
简介
我们在论文中提供了一个例子,但是由于数据不容易下载,很多同学没有测试成功,这个帖子中我们将这个例子进行了详细注释,同时提供手把手教学,数据也上传到了百度网盘。如果大家觉得有用,就引用我们的文章吧。
文章引用:S. Yu, J. Ma*, Deep learning for geophysics: current and future trends, Reviews of Geophysics, 2021, 59 (3), e2021RG000742.
数据下载链接:链接:https://pan.baidu.com/s/1pS3ap4IUg2Zi5hcEwZldCw 提取码:zs8k (800M)
Gitee代码链接:https://gitee.com/sevenysw/deep-learning-geophysics
论文中的代码仅用15行(核心代码,不包括可视化)就实现了数据的加载,训练和测试(不包括训练数据的生成),我们选择使用Keras来实现这样紧凑结构的框架。Keras是TensorFlow、Theano等框架的高级封装。Keras的安装有两种简单的方法,第一种是安装tensorflow,通过tf.keras来调用(本代码的情况);第二种是分别安装tensorflow和keras,可以直接通过keras来调用。
测试的环境配置
环境1:
显卡:Nvidia 1080Ti,驱动版本496.13
软件:Windows 10,Cuda 10.0,VSCode 1.62.2,tensorflow_gpu 1.15.0 (或者2.1.0),python3.7
环境2:
参考Issue
显卡:Nvidia 3080Ti,驱动版本470.86
软件:Ubuntu 18.04, Cuda 11.0, tensorflow_gpu 2.6.1, python 3.6.13, conda 4.11.0
1,修改code.py为其它名字
2,pip uninstall keras
pip install keras==2.6.0
该程序对不同环境的容忍度比较大,所以不必完全一样。
环境配置步骤
1,python环境管理软件
安装anaconda:https://www.anaconda.com/products/individual
2,找到所需cuda安装,比如10.0:
https://developer.nvidia.com/cuda-10.0-download-archive
3,创建虚拟环境
conda可以配置源,加速下载包,https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
在命令行cmd(ubuntu中为terminal)中运行
conda create -n tfv2 python=3.7
开启虚拟环境
conda activate tfv2
4,安装tensorflow
在安装之前可以切换源:https://blog.csdn.net/afeiqiang/article/details/108257584
加速安装,而且更稳定
Windows用户:c:\Users\你的用户名\pip\pip.ini,没有就新建一个,
Linux用户:修改 ~/.pip/pip.conf 文件,没有就新建一个,写入以下内容:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/ *# 根据需要选清华源或者阿里源*
[install]
trusted-host=mirrors.aliyun.com
安装依赖包numpy, matplotlib:
pip install numpy matplotlib
然后开始安装:
pip install --upgrade tensorflow_gpu
如若要指定版本,则可以用
pip install --upgrade tensorflow_gpu==2.1.0
5,下载代码
git clone https://gitee.com/sevenysw/deep-learning-geophysics.git
修改code.py 中noise_dataset.h5的绝对目录位置
运行代码:
python code.py
不出意外,代码就可以正常运行了,整个过程在1080ti下大概要25分钟(共50次迭代)。
代码说明
import h5py
import matplotlib.pyplot as plt
from tensorflow.keras.layers import Input,Conv2D,BatchNormalization,ReLU,Subtract
from tensorflow.keras.models import Model
ftrain = h5py.File(r'E:\Datasets\noise_dataset.h5','r')
X, Y=ftrain['/X'][()],ftrain['/Y'][()]
for i in range(4):
plt.subplot(2,4,i+1);plt.imshow(X[i,:,:,0],vmin=-2,vmax=2)
plt.subplot(2,4,i+5);plt.imshow(Y[i,:,:,0],vmin=-2,vmax=2)
plt.show()
input = Input(shape=(None,None,1))
x=Conv2D(64,3,padding='same',activation='relu')(input)
for i in range(15):
x= Conv2D(64,3,padding='same',use_bias = False)(x)
x= ReLU()(BatchNormalization(axis=3,momentum=0.0,epsilon=0.0001)(x))
x= Conv2D(1,3,padding='same',use_bias = False)(x)
model = Model(inputs=input,outputs=Subtract()([input,x]))
model.compile(optimizer="rmsprop",loss="mean_squared_error")
model.fit(X[:-1000],Y[:-1000],batch_size=32,epochs=50,shuffle=True)
Y_ = model.predict(X[-1000:])
for i in range(4):
plt.subplot(2,4,i+1);plt.imshow(X[-1000+i,:,:,0],vmin=-2,vmax=2)
plt.subplot(2,4,i+5);plt.imshow(Y_[i,:,:,0],vmin=-2,vmax=2)
plt.show()
训练数据如下:

预测结果如下:

训练数据
训练数据的生成基本思路就是利用Matlab的h5write函数将数组转换成h5格式,需要注意的是数组维度的排序,Matlab和python是有一些区别的。
另外我们将数据生成和网络训练都写到一起,使用pytorch,在https://github.com/sevenysw/python_segy
Original: https://blog.csdn.net/u014347448/article/details/122093249
Author: 四尾
Title: 深度学习地震勘探入门