
PIL库的使用
要点:PIL库是一个具有强大图像处理能力的第三方库,不仅包含了丰富的像素、色彩操作功能,还可以用于图像归档和批量处理。
1.PIL库概述
PIL(Python Image Library)库是Python语言的第三方库,需要通过pip工具安装。安装PIL库的方法如下,需要注意,安装库的名字是pillow。
:\>pip install pillow #或者 pip3 install pillow
PIL库支持图像存储、显示和处理,它能够处理几乎所有图片格式,可以完成对图像的缩放、剪裁、叠加以及向图像添加线条、图像和文字等操作。
PIL库主要可以实现图像归档和图像处理两方面动能需求
(1)图像归档:对图像进行批处理、生成图像预览、图像格式转换等。
(2)图像处理:图像基本处理、像素处理、颜色处理等。
根据功能不同,PIL库共包括21个与图片相关的类,这些类可以被看作是子库
或PIL库中的模块,子库列表如下。
Image、 ImageChops、 ImageColor、 ImageCrackCode、 ImageDraw.ImageEnhance、 ImageFile、 ImageFilelO、 ImageFilter、 ImageFont、ImageGL、 ImageGrab、 Imagemath、 ImageOps、 ImagePalette、 ImagePath.ImageQt、 ImageSequence、 ImageStat ImageTk, ImageWin
重点介绍PIL库最常用的子库:Image、ImageFilter、ImageEnhance。
2.PIL库Image类解析
Image是PIL最重要的类,它代表一张图片,引入这个类的方法如下:
>>>from PIL import Image
在PIL中,任何一个图像文件都可以用Image对象表示。Image类的图像读取和创建方法如下(共5个):
方法描述Image.open(filename)根据参数加载图像文件Image.new(mode, size, color)根据给定参数创建一个新的图像Image.open(StringlO.StringlO(buffer))从字符串中获取图像Image.frombytes(mode, size, data)根据像素点data 创建图像Image.verify()对图像文件完整性进行检查、返回异常
通过Image打开图像文件时,图像的栅格数据不会被直接解码或者加载,程序只是读取了图像文件头部的元数据信息,这部分信息标识了图像的格式、颜色、大小等。因此,打开一个文件会十分迅速,与图像的存储和压缩方式无关。
要加载一个图像文件,最简单的形式如下,之后所有操作对im起作用。
>>>from PIL import Image
>>>im = Image.open ("a.jpg")
在使用IDLE交互方式处理图片文件时,建议采用文件的全路径;如果使用Python文件形式,建议采用相对路径,将文件和程序放到一个目录中。
Image类有4个处理图片的常用属性,如表所示(共4个)
属性描述Image.format标识图像格式或来源,如果图像不是从文件读取,值为NoneImage.mode图像的色彩模式,"L"为灰度图像、"RGB"为真彩色图像、"CMYK"为出版图像Image.size图像蜜度和高度,单位是像素(px),返回值是二元元组(tuple)Image.palette调色板属性,返回一个ImagePalette类型
查看已经读取的图像文件的属性如下:
>>>print (im. format, im.size, im.mode)
JPEG (900, 598) RGB
Image还能读取序列类图像文件,包括GIF、FLI、FLC、TIFF等格式文件。open()方法打开一个图像时自动加载序列中的第一帧,使用seek()和tell()方法可以在不同帧之间移动。
Image类的序列图像操作方法(共2个):
方法描述Image.seek(frame)跳转并返回图像中的指定帧Image.tell()返回当前帧的序号
【实例1】GIF文件图像提取
对一个GIF格式动态文件,提取其中各帧图像,并保存为文件。
from PIL import Image
#读入一个GIF文件
im = Image.open("pybit.gif")
try:
im.save('picframe{:02d).png'.format(im.tell()))
while True:
im.seek(im.tel1 ()+1)
im.save('picframe{:02d).png'.format(im.tell()))
except:
print("处理结束")
实例1展示了一种采用try-except编写程序的方法,通过seek()方法和save()方法配合提取GIF图像格式的每一帧,并保存为文件。
Image类的图像转换和保存方法 (共3个) 如表所示。
方法描述Image.save(filename, format)将图像保存为filename文件名,format是图片格式Image.convert(mode)使用不同的参数,转换图像为新的模式Image.thumbnail(size)创建图像的缩略图,size是缩略图尺寸的二元元组
其中,save()方法有两个参数:文件名filename和图像格式format。如果调用时不指定保存格式,如微实例1,PIL将自动根据文件名filename后缀存储图像;如果指定格式,则按照格式存储。搭配采用open()和save()方法可以实现图像的格式转换,例如,将 jpg格式转换为png格式」代码如下。需要注意,Image 类的 save()方法主要用于保存文件到硬盘,PIL库还提供了功能更强大的格式转换方法。
im = Image.open("a.jpg")
im.save("a.png")
Image类可以缩放和旋转图像,其中,rotate(方法以逆时旋转的角度值作为参数来旋转图像。
Image类的图像旋转和缩放方法(共2个):
方法描述Image.resize(size)按size大小调整图像,生成副本Image.rotate(angle)按angle角度旋转图像,生成副本
Image类能够对每个像素点或者一幅RGB图像的每个通道单独进行操作。split()方法能够将RGB 图像各颜色通道提取出来;
merge()方法能够将各独立通道再合成一幅新的图像。
lmage类的图像像素和通道处理方法(共4个):
方法描述Image.point(func)根据函数func的功能对每个元素进行运算,返回图像副本Image.split()提取RGB图像的每个颜色通道,返回图像副本Image.merge(mode,bands)合并通道,其中mode表示色彩,bands表示新的色彩通道Image.blend(im1,im2,alpha)将两幅图片iml和im2按照如下公式插值后生成新的图像:im1
(1.0-alpha) + im2
alpha
【实例2】图像的颜色交换
交换图像中的颜色。可以通过分离RGB图片的3个颜色通道实现颜色交换。
from PIL import Image
im = Image.open('a.jpg')
r, g, b = im.split()
om = Image.merge("RGB" , (b, g, r))
om.save('aBGR.jpg')
运行结果:

原图:

操作图像的每个像素点需要通过函数实现,可以采用(lambda)函数和point()方法,例子如下,显示效果如图7所示。
>>>im=Image.apen('a.jpg')#打开文件
>>>>r,g,b=im.splitO#获得RGB通道数据
>>>>newg=g.point(lambda i:i*0.9)#将G通道颜色值变为原来的0.9
>>>>newb=b.point(lambda i:i<100)#选择B通道值(低于100的像素
>>>>om=Image.merge(im.mode,(r,newg,newb)#将3个通道合成为新图
>>>>om.save('new_a.jpg')#输出图片
3.图像的过滤和增强
PIL库的ImageFilter类和ImageEnhance类提供了过滤图像和增强图像的方法。
ImageFilter类共提供10种预定义图像过滤方法(共10个):
方法表示描述ImageFilter.BLUR图像的模糊效果ImageFilter.CONTOUR图像的轮廓效果ImageFilter.DETAIL图像的细节效果ImageFilter.EDGE_ENHANCE图像的边界加强效果ImageFilter.EDGE_ENHANCE_MORE图像的阈值边界加强效果ImageFilter.EMBOSS图像的浮雕效果ImageFilter.SMOOTHL图像的平滑效果ImageFilter.FIND_EDGES图像的边界效果ImageFilter.SMOOTH_MORE图像的阈值平滑效果ImageFilter.SHARPEN图像的锐化效果
利用Image类的filter()方法可以使用ImageFilter类,使用方式如下:
Image.filter(ImageFilter.fuction)
【实例3】图像的轮廓获取。
获取图像的轮廓,代码如下,程序执行效果如图所示,图片变得更加抽象、更具想象空间!
from PIL import Image
from PIL import ImageFilter
im = Image.open('a.jpg')
om = im.filter(ImageFilter.CONTOUR)
om.save('aContour.jpg')
运行结果:

原图:

ImageEnhance类提供了更高级的图像增强功能,如调整色彩度、亮度、对比度、锐化等。
ImageEnhance类的图像增强和滤镜方法(共5个):
方法描述ImageEnhance.enhance(factor)对选择属性的数值增强factor倍ImageEnhance.Color(im)调整图像的颜色平衡ImageEnhance.Contrast(im)调整图像的对比度ImageEnhance.Brightness(im)调整图像的亮度ImageEnhance.Sharpness(im)调整图像的锐度
【实例4】图像的对比度增强。
增强图像的对比度为初始的20倍。代码如下,程序执行效果如图7所示。
from PIL import Image
from PIL import ImageEnhance
im = Image.open('a.jpg')
om = ImageEnhance.Contrast(im)
om.enhance(20).save(aEnContrast.jpg')
运行结果:

原图:
Original: https://blog.csdn.net/weixin_45627039/article/details/124114475
Author: 衍生星球
Title: Python -- 图像处理—PIL库的使用
相关阅读1
Title: 语音识别原理与应用 洪青阳 第一章 概论
目录
第一章 语音识别概论
语音识别的基础理论包括 语音的产生和感知过程、语音信号基础知识、语音特征提取等。
关键技术包括高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔科夫模型(Hidden Markov Model,HMM)、深度神经网络(Deep Neural Network,DNN),以及基于这些模型形成的 GMM-HMM、DNN-HMM 和 端到端(End-to-End,E2E)系统。语言模型和 解码器 也非常关键,直接影响语音识别实际应用的效果。
1.1 语音的产生和感知
人的 发音器官包括 肺、气管、声带、喉、咽、鼻腔、口腔、和唇。
肺部产生的气流冲击声带,产生振动。
声带每开启和闭合一次的时间是一个 基音周期(Pitch period)T,其倒数为 基音频率(F0=1/T, 基频),范围在70HZ---450HZ。基频越高,声音越尖细。基频随时间的变化,也反映了声调的变化。
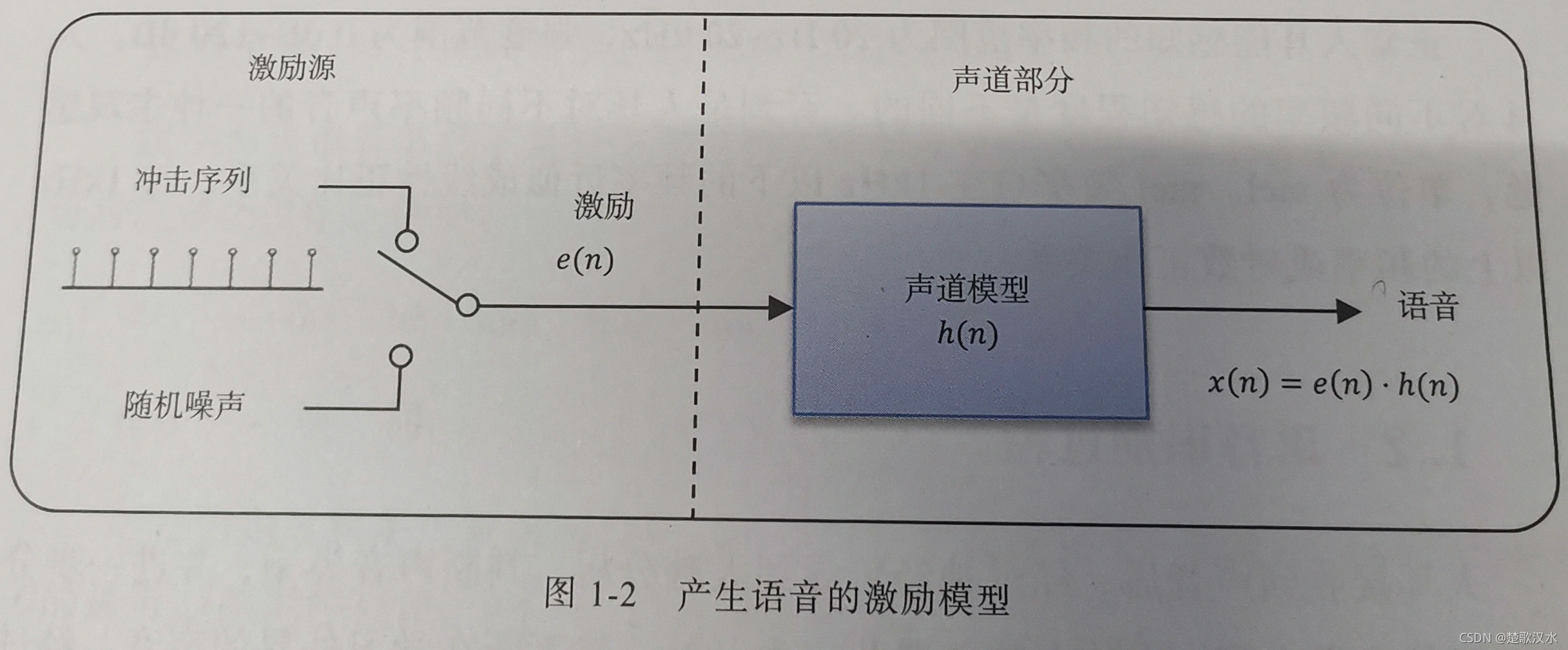
语音的产生过程可进一步抽象成如上图所示的激励的模型。包括 激励源和声道部分。在激励源部分, 冲击序列发生器以基音周期产生周期性信号,经过声带振动, 相当于经过 声门波模型,肺部气流大小相当于振幅; 随机噪声发生器产生非周期性信号。 声道模型模拟口腔、鼻腔等声道器官,最后产生语音信号。我们要发浊音时,声带振动形成准周期的冲击序列。发清音时,声带松弛,相当于发出一个随机噪声。
1.2 语音识别过程
音素(phone)是构成语音的最小单位。英语中有48个音素(20个元音和28个辅音)。
若采用元音和辅音来分类,汉语普通话有32个音素,包括元音10个,辅音22个。 但普通话的韵母多是复韵母,不是简单的元音,因此 拼音一般分为声母(initial)和韵母(final)。
音节(syllable)是听觉能感受到的最自然的语音单位,由一个或多个音素按一定的规律组合而成。英语音节可由一个元音或元音和辅音构成。汉语的音节由声母、韵母和音调构成,其中音调信息包括在韵母中。所以,汉语音节结构可以简化为:声母+韵母。
注:音素(序列)组成音节(序列),从而识别出文字。
汉字与汉语音节并不是一一对应的。一个汉字可以对应多个音节,一个音节可对应多个汉字。
例如:
和 ----- he二声 he四声 huo二声 huo四声 hu二声
tian二声 ----- 填 甜
语音识别过程是个复杂的过程,但其最终任务归结为,找到对应 观测值序列O的最可能的 词序列W'。按贝叶斯准则转化为:
W' = arg max P(W|O) = arg max(P(O|W)P(W))/(P(O))
W' = arg max P(O|W)P(W)
其中,P(O)与P(W)没有关系,可认为是常量,因此P(W|O)的最大值可转换为P(O|W)和P(W)两项乘积的最大值,第一项P(O|W)由声学模型决定,第二项P(W)由语言模型决定。
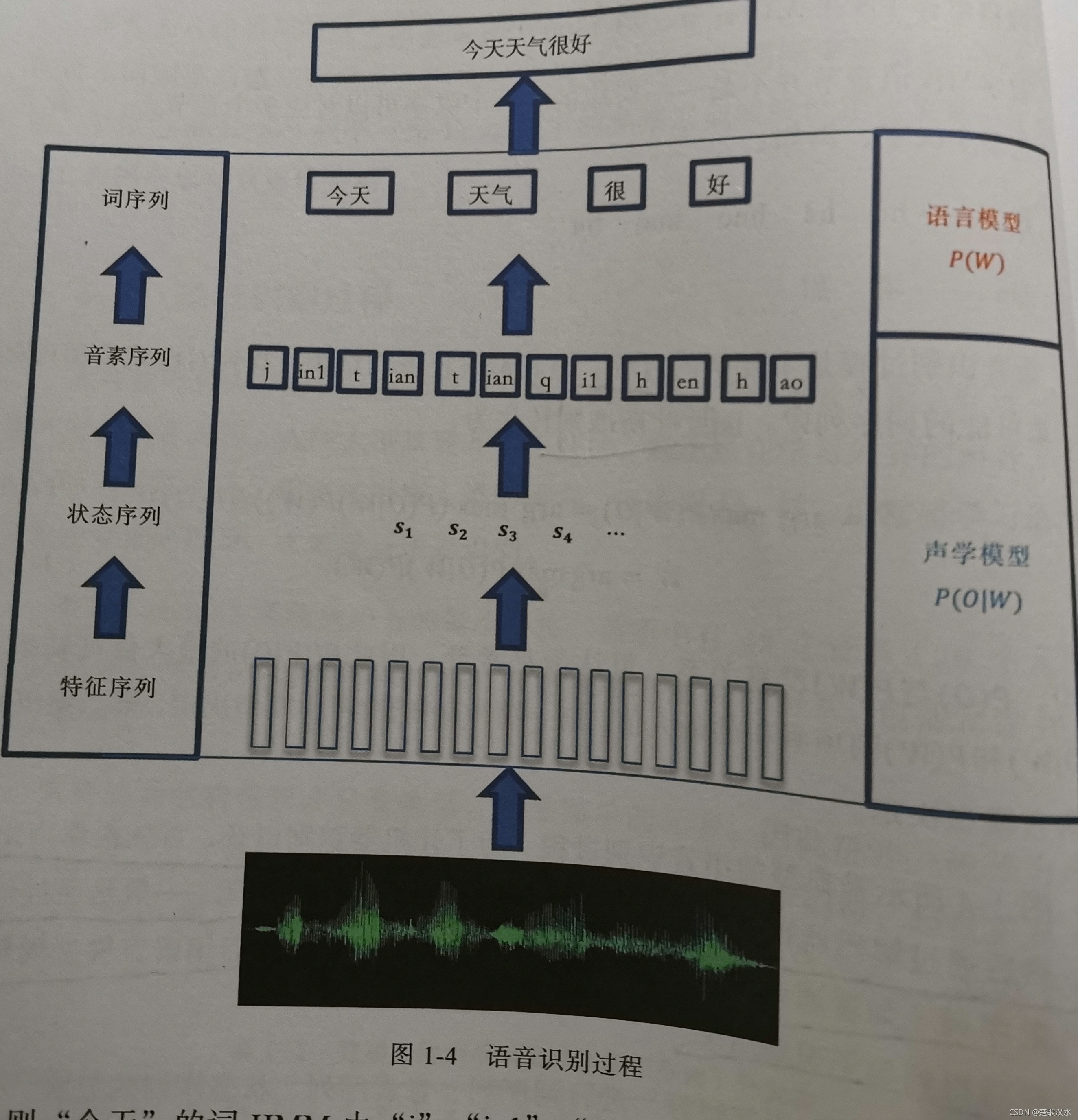
上图是典型的语音识别过程。为了让机器识别语音,首先提取声学特征,然后通过解码器得到状态序列,并转换为对应的识别单元。一般是通过词典将音素序列(如普通话的声母和韵母),转换为词序列,然后用语言模型规整约束,最后得到句子识别结果。

如上图所示,对"今天天气很好"进行词序列、因素序列、状态序列的分解,并和观测值序列对应,其中每个音素对应一个HMM,并且其发射状态(深色)对应多帧观测值。
现在工业应用普遍要求 大词汇量连续语音识别(LVCSR)。
1.3语音识别发展历史
解决任务: 孤立词识别 → 大规模连续语音识别 → 复杂场景识别
技术发展: 模板匹配(DTW) → 统计模型(GMM-HMM) → 深度学习(DNN-HMM,E2E)
DTW(Dynamic Time Warping)动态时间规整:使用动态规划算法将两段不同长度的语音在时间轴上进行了对齐。该算法把时间规整和距离的计算有机地结合起来,解决了不同时长语音的匹配问题。在一些要求资源占用率低、识别人比较特定的环境下,DTW是一种很经典很常用的模板匹配算法。
统计模型两项很重要的成果是 声学模型和 语言模型,语言模型以 n元语言模型(n-gram)为代表,声学模型则以 HMM为代表。
GMM-HMM:(1)用HMM对语音状态的转移概率建模;(2)用 高斯混合模型(Gaussian Mixture Model,GMM)对语音状态的观测值概率建模。
HTK(Hidden Markov Tool Kit)是一款开源的基于HMM的语音识别工具包。
Ka1di,是DNN-HMM系统的基石,在工业界得到广泛应用。
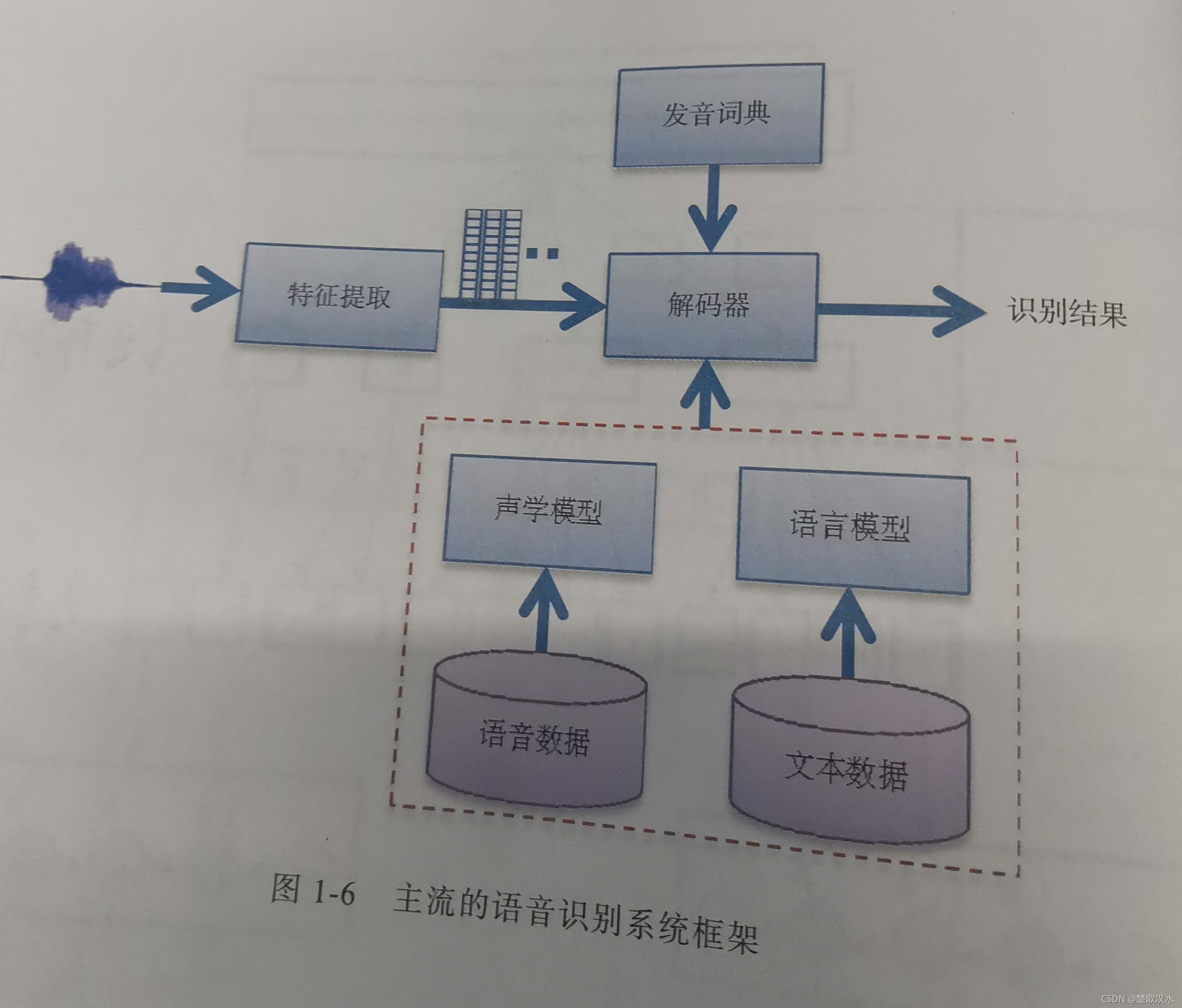
大多数主流的语音识别解码器基于 加权有限状态转换器(WFST),把发音词典、声学模型和语言模型编译成静态解码网络,这样可大大加快解码速度,为语音识别的实时应用奠定基础。
RNN可更有效、更充分地利用语音中的上下文信息。引入LSTM或其变体以解决梯度消失的问题。
CNN可通过共享权值来减少计算的复杂度,并且CNN被证明在挖掘语音局部信息的能力上更为突出。
Attention模型的对齐关系没有先后顺序的限制,完全靠数据驱动得到,对齐的盲目性会导致训练和解码时间过长。而CTC的前向后向算法可以引导输出序列和输入序列按时间顺序对齐。
Transformer架构:在 Decoder和Encoder中均采用Attention机制。
Original: https://blog.csdn.net/hnlg311709000526/article/details/120912777
Author: 楚歌汉水
Title: 语音识别原理与应用 洪青阳 第一章 概论
相关阅读2
Title: 记一次调试YOLOv5+DeepSort车辆跟踪项目的经过
摘要:学习别人的开源项目是日常的一项必备技能,本文通过一个车辆跟踪(YOLOv5+DeepSort)的例子介绍如何配置和调试GitHub上的开源代码。以第一人称的视角给出本人调试代码的过程,包括项目readme的阅读、python环境配置、代码调试运行等,详细的过程已录制在视频中。完整的代码和配置文件可三连博主B站视频后获取。
关注视频获取代码资料: https://www.bilibili.com/video/BV1W34y1Y71w/(欢迎关注博主B站视频)
前言
相传,当你找到一处好代码,雄心勃勃打算"学习"一下时,总会出现一些"灵异事件",武力值低的人往往"出师未捷身先死"。别人的代码荡下来到自己机器上,怎么就是各种Error铺天盖地?不是环境报错、缺少文件,就是语法错误...于是乎在想这帮人总是分享一堆Bug作甚呢?还是我自己没Get到大佬的点?
直接点,开始我们的故事吧。从前,有个夜黑风高的夜晚,收到上峰指示,先前的"目标跟踪"行动需立即执行:YOLOv4+Sort不好再用了,升级为YOLOv5+DeepSort。我想:"不会写啊,Python都没学过,额忘记我有没有学过了,晓得了先网上找一下吧"。咦,GitHub上有,和要求上差不多,妥了妥了,荡一下改改跑跑好不啦,小似情唷。喏这是原作者的效果,这个项目的地址:https://github.com/duongcongnha/Vehicle-tracking,下面说一下我调试该项目的经过。
1. 打量工作
看到这样一个项目,检测和跟踪效果都不错,所以动手要把它在我的机器上运行起来。这里是GitHub的项目主页,我先下载一下代码到我的G盘,与此同时打量一下这个代码。
下载好了,打开pycharm运行一下?别急,先看一眼训练好的模型有木有,老夫推断在models文件夹下,定睛一看存在yolov5的pt模型文件。Nice啊,目测可以先白嫖模型,预感这个程序靠谱。
再看Readme里面如何使用,这里有Python环境版本,以及要安装的依赖列表(requirement.txt)。想来按照这个要求来,应该能跑通的吧,那现在能打开pycharm运行一下程序?那主程序是哪个不看看你就运行?待我先目测一下主程序在哪里,还有要怎么运行有没有介绍。
这里记载了运行方式,用的命令行运行,这里有个cd命令,看来是在这个程序文件夹的application\main这个文件夹下,有个app_track.py,运行它应该就能跑起来了。
这个项目代码写得比较规范,所以能很方便找到这三个点,其他的项目就不能保证这么幸运了,那样就得自己琢磨,当你阅码无数自然就能积累经验了。
2. 运行调试
虽然看起来介绍齐全,但是我掐指一算可能会有坑,但是具体是什么坑我不知道。先启动pycharm,打开下载程序的文件夹,找到app_track.py这个主程序,然后运行程序?——先配置环境。有人问我:"原来有Python环境,配置好了很多三方依赖,直接用呗可以吗?",那我不建议,这俩环境很可能不兼容,还是要改部分依赖包的版本,最终可能这个程序运行不通,你自己原来的程序也'灵异'报错。"
既然如此,我用Anaconda创建一个新环境,然后在新环境里收requirements.txt列出的这些"牛鬼蛇神",目测靠谱一点。打开PyCharm的终端,输入一下命令:
conda create -n yolo5_track python==3.7
我这里pycharm内置的终端是cmd,有些新版的pycharm变成了powershell,那后面部分命令可能不一样。各自实际情况不一样,大家具体问题具体分析,千万别只是照葫芦画瓢。那在终端里面输入,如下:
然后激活环境,常规操作是吧,那就不要出错。输入以下代码,这里如果是powershell执行下去效果可不一样,如果有需要就自己解决一下哈。
conda activate yolo5_track
接下来要给这个环境装上依赖,它这个项目里是不是有requirements.txt,我们打开看一下。还挺齐全的,有依赖名字还有部分版本号要求,那就来呗。
上面有提示我们输入pip的安装命令,那就在刚刚的终端下输入以下命令,读取txt文件,然后执行各个依赖的安装。
pip install -r requirements.txt
当然要先切换到requirement.txt所在的文件夹目录,然后输入命令回车执行,ChuaChua一堆安装信息提示,然后耐心等待完成。
安装成功之后,在pycharm中选择一下环境,基本就是File->Setting->Project->Python Interpreter,进入Python环境选择conda环境,确定刚刚创建好的环境即可。
环境也选好了,是不是该点运行了啊?这时候是时候展现真正的技术了,打开app_track.py,在编辑器中右击选择"Run",开始运行,然后手动祈祷。
然后就是这样滴,what?不就是按照作者给出的吗,报错了是什么情况。看我干啥,想想什么原因啊。我们看一下最后三行,torch的module.py文件报错,显示没有某个属性。经验来看哈,这肯定是torch的版本不对,因为代码写错能出没有属性的可能性不大,除非是自己定义的,缺少了模块文件。这里显然是torch的调用问题,应该是版本问题。
我们是按作者给出的requirements.txt安装的,那么问题出现在哪里呢?我们再看一眼这个文件的内容,有些地方是固定版本,有的是给出了最低要求,比如要求这个torch>=1.8.0,大于等于?那我现在的torch版本呢,在终端输入pip list,可以看到torch版本1.11.0,没毛病确实大于1.8.0。
这个版本比1.8新多了,那你说有没有可能,到了某个版本来了个调整,把某些个属性给删掉或换成别的属性了呢?我想是很有可能的,在发布代码的时候作者想不到后面这些依赖会变成什么样的,所以只能告诉我们大于某个版本,所以这里装的时候就变成最新版。那如果我们把所有版本指定为特定的,是不是就能避免了。至于这里面这么多依赖,是不是所有版本都要调整呢,看经验或调试结果了。调整和测试后的依赖版本被我修改如下,然后保存在setup.txt中:
重新输入pip安装命令,在终端键入以下命令,重新安装:
pip install -r setup.txt
这时显然好起来了,运行结果如下,这其实是在处理中,等到进度完成,得到处理后的结果。完整版的资源代码和setup.txt配置文件,可关注并三连博主B站视频后评论获取,可轻松无Bug运行。
这时找到inference/output文件夹下的mp4结果,可以得到如下的画面,这是在原视频中检测后输出的文件。
注意到源码里面读取了yml的设置文件,下意识打开可以发现设置识别视频的路径在第24行,我们可以修改为自己的视频所在目录,重新进行检测测试一下。
修改用自己的视频文件,测试结果如下,感觉可以满足一般的车辆检测跟踪和计数要求,感兴趣的朋友可以关注并三连博主B站视频后,评论获取完整代码和setup.txt依赖文件。
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。
Original: https://www.cnblogs.com/sixuwuxian/p/16245089.html
Author: 思绪无限
Title: 记一次调试YOLOv5+DeepSort车辆跟踪项目的经过
相关阅读3
Title: 主流的音视频SDK调研
需求来源:
● 功能需求:
1、文字聊天:包含文字聊天和简单的表情功能,以及发送图片功能
2、语音聊天:可以进行线上语音功能,语音与文字聊天计时方式是合并计算
3、自动录音:语音聊天自动进行录音并进行存储,客户不可见,管理端可见
● 技术需求:
1、语音的稳定性 音质
2、存储 不能丢失
3、是否支持二次开发 以及支持程度
市面上主流的音视频支持
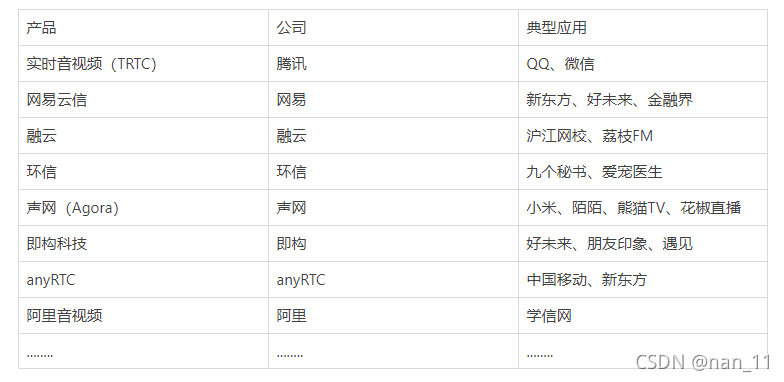
; 调研主流产品使用的第三方音视频
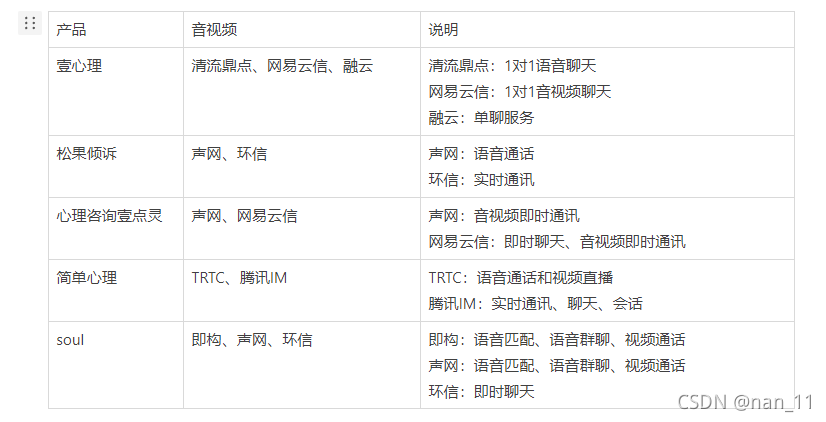
音视频产品选择考虑的因素
● 满足语音通话、音视频通话、音质、稳定性、录制模式和存储模式的使用场景
● 易于集成到公司产品中,产品应该具有开发SDK或者开源
● 支持接入设备的多样性,包括网页,Android,IOS,传统音视频设备
● 扩展性和灵活性,支持并发大量用户
● 使用成本考虑
选择商用产品还是开源产品?
● 集成容易程度:商用产品 > WebRTC
● 市场成熟程度:商用产品 > WebRTC
● 灵活定制程度:商用产品 < WebRTC
● 使用成本: 商用产品 > WebRTC
主流产品对比
一、平台覆盖对比
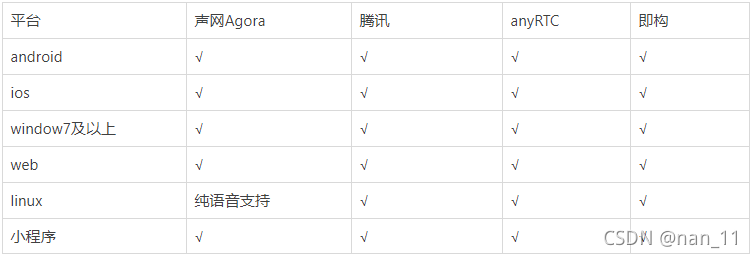
二、音视频参数对比
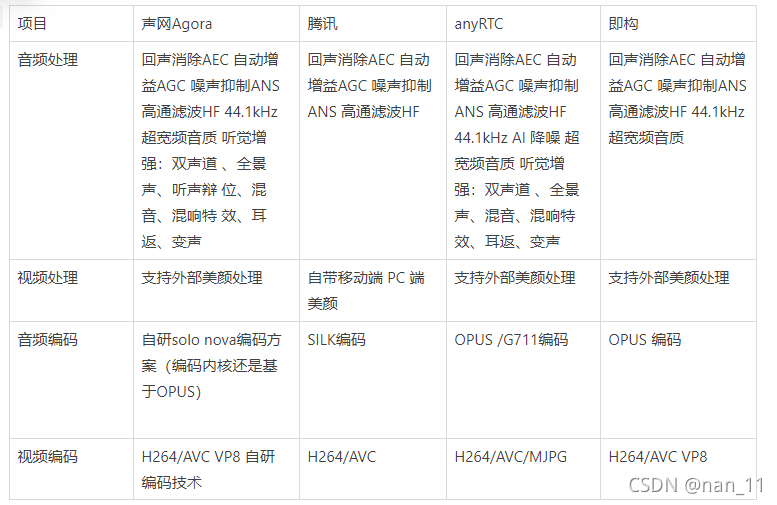
三、核心能力对比
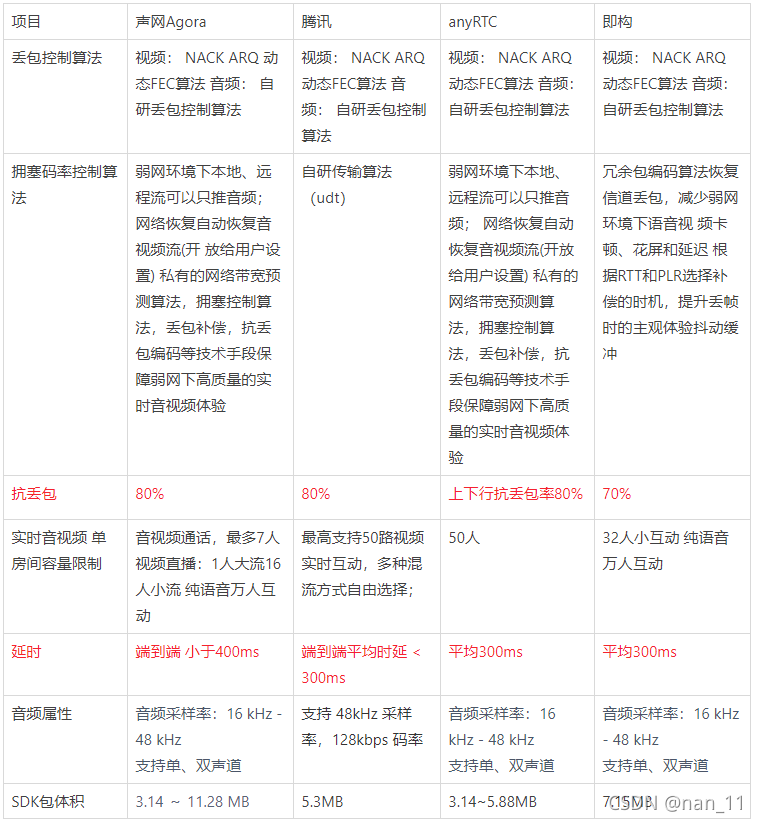
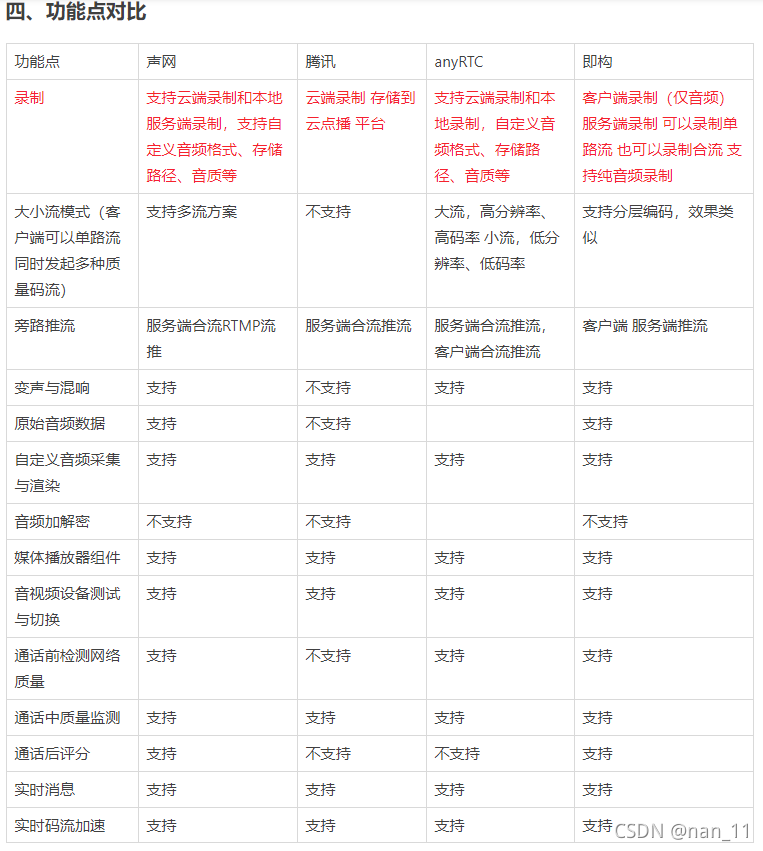
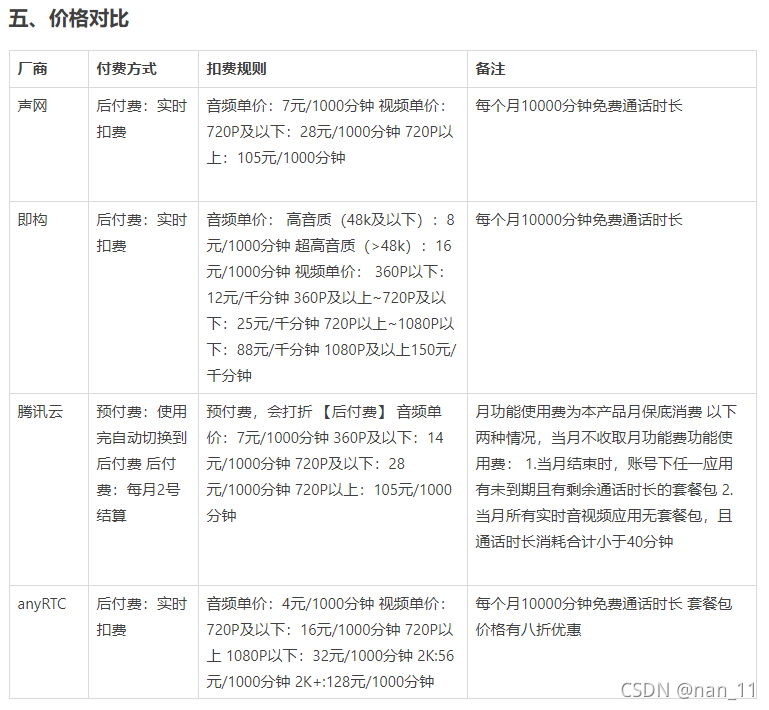
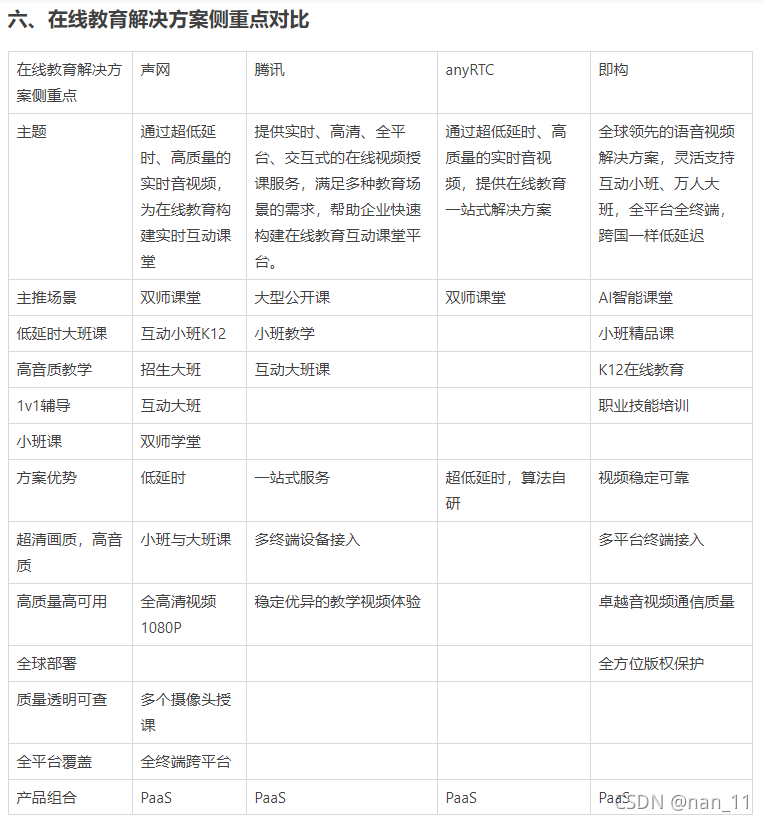
; 实时音视频选型
一、实时音视频与 IM 能力不宜分散
几乎 100% 的实时音视频在线应用都有文字/语音消息、文件传输、图片显示等 IM 需求。
目前市场上 PaaS 服务商这两方面能力强弱不一:有的大厂虽然两方面能力都提供,但不能确保两种能力同样高质量;有的专业 RTC 厂商,只能提供 RTC 能力,IM 能力还得由第三方专业服务商提供。
这样,便迫使开发者在集成过程中不得不分别选择服务商。当实时音视频与 IM 质量不稳定时,需要逐一协调各个服务商,逐一排查问题,无形中增加了后期的运营成本。IM 和音视频在很多场景下有耦合,建议尽量"用一套 SDK,解决所有通信场景"。
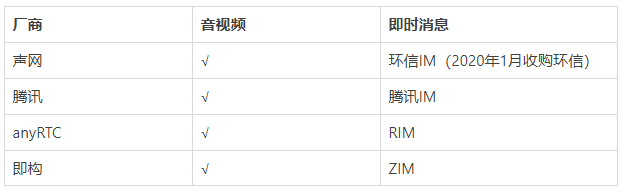
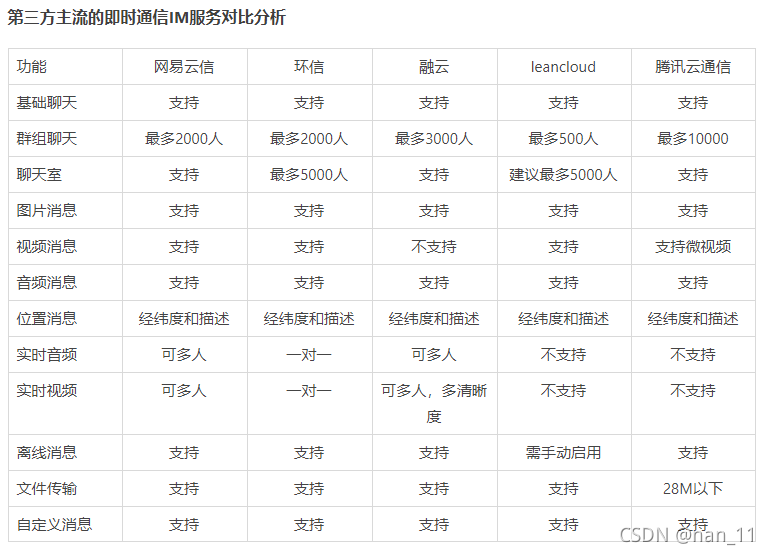
结合音视频+IM
声网 / 腾讯 > anyRTC / 即构
二、延时、卡顿、抖动的质量问题要解决好
用户最不能接受实时音视频的三个质量问题是延时、卡顿、抖动。

; 三、是否支持二次开发
二次开发,简单的说就是在现有的软件上进行定制修改,功能的扩展,然后达到自己想要的功能,一般来说都不会改变原有系统的内核。
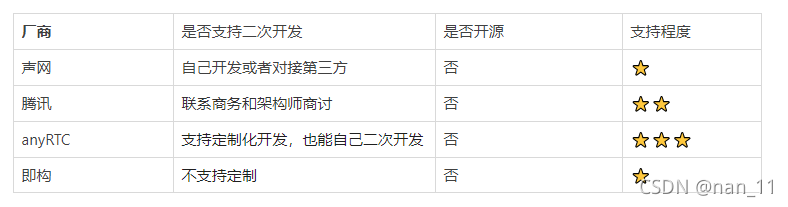
总结:
音视频结合IM即时通讯 声网和腾讯 优于 anyRTC和即构
根据主流产品使用的第三方音视频方案 声网选择多于腾讯
声网的音视频功能点多于腾讯
分享个外卖领券小程序,还可以领其他优惠券。

参考:
声网Agora: https://www.agora.io/cn/
即构:https://www.zego.im/
腾讯云:https://cloud.tencent.com/solution/education
anyRTC:https://www.anyrtc.io/
实时音视频选型 开发者应该避开哪些坑?
https://www.rongcloud.cn/blog/?p=4459
市面上主流的音视频竞品分析对比
https://juejin.cn/post/6986639440475062302
https://juejin.cn/post/6980246658562932767
艾瑞咨询-2020年全球互联网通信云行业研究报告-201202
http://pg.jrj.com.cn/acc/Res/CN_RES/INDUS/2020/12/2/31937f4e-8a46-4851-b274-192a17cb6be2.pdf
国内实时音视频老大,声网Agora是如何炼成的?
https://ifenxi.com/research/content/4901
第三方即时通信IM服务对比分析
http://blankh.cn/show/322.html
Original: https://blog.csdn.net/yanzeyanga/article/details/121031570
Author: nan_11
Title: 主流的音视频SDK调研