
文章目录
- 1. 提取指定位置的像素RGB值(BGR)
- 2. 修改指定像素的BGR值
* - 2.1 修改一个像素
- 2.2 修改一个区域的像素
- 3. 图像的创建
* - 3.1 创建纯黑/白图像
- 3.2 创建黑白相间图像
- 3.3 创建彩色图像
- 3.4 随机颜色图像(雪花点图)
- 4. 图像的拼接
* - 水平拼接 hstack()
- 垂直拼接 vstack()
ʚʕ̯•͡˔•̯᷅ʔɞ
🍹 欢迎各路大佬来到小啾主页指点☀️欢迎大家前来学习OpenCV像素处理基本操作 - Open_CV系列博文,我是侯小啾。
✨ 博客主页:云雀编程小窝 🌹꧔ꦿ
🌹꧔ꦿ博文如有帮助,还请给个 点赞 + 关注 + 收藏✨

上期传送门:OpenCV图像处理基本操作 Open_CV系列(一)
如果您的numpy数组基础不足,可参考这篇超详细的blog总结:Numpy库速通教程典藏版 #一篇就够了系列
如有疑问欢迎随时在评论区交流。☀️
正文开始!
首先准备一张图片,用于代码的示例,
这里我选择使用这只cat图(忽略这个去不掉的水印):

; 1. 提取指定位置的像素RGB值(BGR)
import cv2
image = cv2.imread("pic.jpg")
print(image.shape)
px = image[300, 456]
print(px)
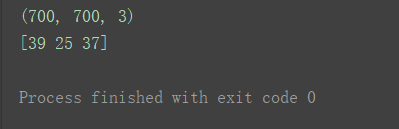
[39 25 37] 表示红绿蓝三种不同的颜色(是光学三原色,不是我们小学美术课学的颜料三原色红黄蓝)
光学三原色是人眼能够感知的三种颜色,这三种颜色也称三基色,将这三种颜色以不同比例匹配,就可以得到其他不同的颜色。计算机利用 色彩空间 对颜色进行编码。
RGB色彩空间即彩色,存在三个色彩通道:R通道,G通道,B通道,即对应这里的[39 25 37]三个数字。且每个通道的色彩值都在区间[0, 255]内。
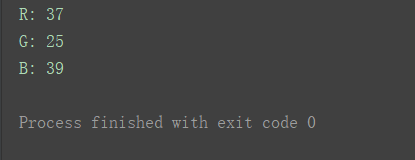
RGB色彩空间的色彩通道在OpenCV中的顺序不是RGB,而是BGR色彩空间(顺序相反)。即R为37,G为25,B为39。
- 对于BGR色彩空间的图像,当每个像素的BGR三个值相等时,就可以得到灰度图像。
- B、G、R三个值都为0时表示纯黑色
- B、G、R三个值都为255时表示纯白色

逐个打印出:
import cv2
image = cv2.imread("pic.jpg")
print("R:", image[300, 456, -1])
print("G:", image[300, 456, 1])
print("B:", image[300, 456, 0])
- 修改指定像素的BGR值
提取到BGR值之后,可以对其进行修改操作。
2.1 修改一个像素
import cv2
image = cv2.imread("pic.jpg")
image[291, 218] = [255, 255, 255]
cv2.imshow("cat", image)
cv2.waitKey()
cv2.destroyAllWindows()
这里将图片截取一部分查看,可以看到这里图中圈出的地方,多了一个白色的点。即为我们修改的结果。

2.2 修改一个区域的像素
以竖直方向上[100,150]范围的像素块,水平方向上[200,251]范围的像素块为例。将其BGR值都修改为白色。
从程序执行效果可以看出,竖直方向,像素的位置是从上往下排的,水平方向上,像素的位置在从左往右排列的。即零轴在左上角。(pic的shape为(700,700,3),修改的白块儿在偏左上角的位置。)
import cv2
image = cv2.imread("pic.jpg")
cv2.imshow("cat", image)
for i in range(100, 151):
for j in range(200, 251):
image[i, j] = [255, 255, 255]
cv2.imshow("cat", image)
cv2.waitKey()
cv2.destroyAllWindows()
程序执行结果如图所示:

- 图像的创建
创建图像,即创建三维数组或二维数组,使其像素的每个色彩值分布在[0,255]内。然后使用Open_CV的方法将其显示出来即可。
3.1 创建纯黑/白图像
创建纯黑图像,即创建二维的全零数组。
import cv2
import numpy as np
width = 800
height = 600
img = np.zeros((height, width), np.uint8)
cv2.imshow("BLACK", img)
cv2.waitKey()
cv2.destroyAllWindows()
同理创建纯白图像即在上边的基础上把数组的每个值都改为255.
代码示例:
import cv2
import numpy as np
width = 800
height = 600
img = np.ones((height, width), np.uint8) * 255
cv2.imshow("img", img)
cv2.waitKey()
cv2.destroyAllWindows()

3.2 创建黑白相间图像
- 将全零数组的局部值改为255即可。
全黑+白块
import cv2
import numpy as np
width = 400
height = 300
img = np.zeros((height, width), np.uint8)
img[50:101, 50:100] = 255
cv2.imshow("BLACK-WHITE", img)
cv2.waitKey()
cv2.destroyAllWindows()
黑条白条相间
import cv2
import numpy as np
width = 440
height = 300
img = np.zeros((height, width), np.uint8)
for i in range(0, width, 40):
img[:, i:i + 20] = 255
cv2.imshow("BLACK-WHITE", img)
cv2.waitKey()
cv2.destroyAllWindows()

3.3 创建彩色图像
关于色素,
显示红色即R值为255,G值与B值为0
显示绿色即G值为255,R值与B值为0
显示蓝色即B值为255,R值与G值为0
接下来依次创建这三种彩色图像:
import cv2
import numpy as np
width = 300
height = 200
img = np.zeros((height, width, 3), np.uint8)
blue = img.copy()
blue[:, :, 0] = 255
green = img.copy()
green[:, :, 1] = 255
red = img.copy()
red[:, :, 2] = 255
cv2.imshow("blue", blue)
cv2.imshow("green", green)
cv2.imshow("red", red)
cv2.waitKey()
cv2.destroyAllWindows()
程序执行结果如下,依次创建了红绿蓝三种颜色的图像:

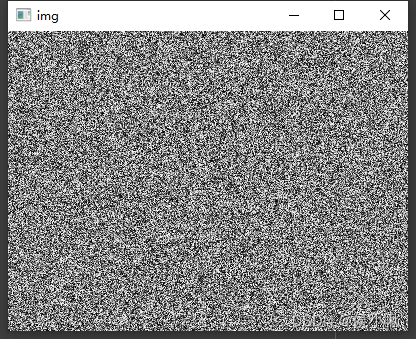
3.4 随机颜色图像(雪花点图)
创建随机灰度图像
import cv2
import numpy as np
width = 400
height = 300
img = np.random.randint(256, size=(height, width), dtype=np.uint8)
cv2.imshow("img", img)
cv2.waitKey()
cv2.destroyAllWindows()
程序执行结果如下:
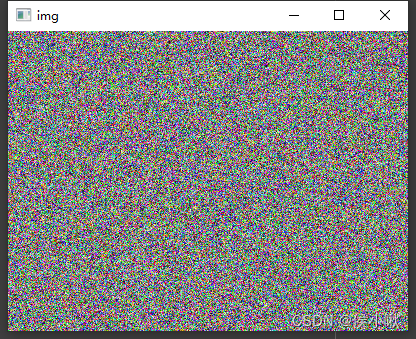
创建随机彩色图像
import cv2
import numpy as np
width = 400
height = 300
img = np.random.randint(256, size=(height, width, 3), dtype=np.uint8)
cv2.imshow("img", img)
cv2.waitKey()
cv2.destroyAllWindows()
程序执行结果如下:
- 图像的拼接
首先准备两个图片,这里将其命名为a,b。

; 水平拼接 hstack()
import cv2
import numpy as np
img1 = cv2.imread("a.jpg")
img2 = cv2.imread("b.jpg")
img_h = np.hstack((img1, img2))
cv2.imshow("img_h", img_h)
cv2.waitKey()
cv2.destroyAllWindows()

垂直拼接 vstack()
import cv2
import numpy as np
img1 = cv2.imread("a.jpg")
img2 = cv2.imread("b.jpg")
img_v = np.vstack((img1, img2))
cv2.imshow("img_v", img_v)
cv2.waitKey()
cv2.destroyAllWindows()

(因为图片过长,图片未显示全)
🌹꧔ꦿ本系列blog传送门:
✨OpenCV图像处理基本操作 【Python-Open_CV系列(一)】
✨OpenCV像素处理基本操作 【Python-Open_CV系列(二)】
✨OpenCV之 BGR、GRAY、HSV色彩空间&色彩通道专题 【Python-Open_CV系列(三)】
✨OpenCV绘制图像与文字(可作为脚手架代码)(python) 【Python-Open_CV系列(四)】
✨OpenCV图像几何变换专题(缩放、翻转、仿射变换及透视)【python-Open_CV系列(五)】
✨基于梵·高《向日葵》的 图像阈值处理专题(二值处理、反二值处理、截断处理、自适应处理及Otsu方法)【Python-Open_CV系列(六)】
✨OpenCV基本功 之 图像的掩模、运算 & 合并专题 -小啾带学【Python-Open_CV系列(七)】
✨《三英战吕布》 - 图像模板匹配 【Python-Open_CV系列(八)】
✨OpenCV滤波器 龙门石窟篇【Python-Open_CV系列(九)】(均值滤波器、中值滤波器、高斯滤波器、双边滤波器)
✨Open_CV形态学运算专题 (腐蚀&膨胀、开&闭运算、梯度运算、顶帽运算黑帽运算 )【Python-Open_CV系列(十)】
✨霍夫变换看不懂?小啾带你串一遍:OpenCV图形检测专题 这样学最简单【Python-Open_CV系列(十一)】
✨小啾带你开天眼 之 开启py-OpenCV摄像头及视频处理【Python-Open_CV系列(十二)】
✨小啾带你开天眼 之 人脸检测与识别(以及华强、皇叔、高祖配墨镜特效)【Python-Open_CV系列(十三)】
Original: https://blog.csdn.net/weixin_48964486/article/details/123754294
Author: 侯小啾
Title: OpenCV像素处理基本操作 Open_CV系列(二)
相关阅读1
Title: 基于C++和Python实现的手写信息识别
资源下载地址:https://download.csdn.net/download/sheziqiong/85997092
资源下载地址:https://download.csdn.net/download/sheziqiong/85997092
1 要求
输入图像为:
普通 A4纸,上有手写的如下信息:
- 学号
- 手机号
- 身份证号
所有输入格式一致,数字不粘连,但是拍照时角度可能不正。
输出:
- 每个主要步骤的输出结果,包括对 A4纸的矫正结果,行的切割,以及单个字符的切割结果。
- 对 A4纸上信息进行识别,以 xlsx 格式保存。
2 程序主要流程
提交的程序包含 C++和 Python 编写的两个部分。C++程序包含了 A4纸的矫正、A4纸行信息的识别、数字的切割以及使用 Adaboost 对数字信息的识别。Python 部分则使用 TensorFlow库通过卷积神经网络对数字信息进行识别,与 Adaboost 相比识别效果有较大的改进。对于每个给出的测试数据集都根据目录结构给出了 SHELL 脚本。脚本将自动调用Python 与 C++程序,程序执行中将所有数字图像分到识别出的对应的文件目录下,然后生成一个记录每个图片的信息的 csv 文件,最后脚本将调用一个 Python 程序将 csv 文件转为 xlsx 文件。
1.3 程序各个主要步骤简述
纸矫正:
纸的识别与矫正部分由第七次作业的代码修改而来,主要的流程如下:
-
使用K-means算法根据图像像素值分为两个聚类,输出图像的高灰度聚类置为255,地灰度聚类置为0.
-
使用区域生长去除图像中除中心部分的纸张之外的其他纸张及亮度较高的部分。
- 遍历图像,将所有8邻域均为255的点去除,输出图像仅保留 A4纸的边缘
- 使用霍夫变换求出 A4纸的四条边,获取4个角点坐标
- 根据4个角点坐标计算从原图到矫正后图像的单应性矩阵,对生成图像的每个坐标值使用单应性矩阵计算原图中的坐标,使用双线性插值计算出矫正后的像素值。
程序将把对每一张图片矫正后的 a4纸图像保存在执行目录的 a4文件夹下。
自适应二值化处理
在第7次作业中 Adaboost 识别图像前会先将 A4纸图像进行全局固定阈值二值化处理,由于当时测试数据较少,可以找出一个适合所有测试数据的阈值;但在本次作业中测试数据较多,而且很多图片有阴影区域造成影响,无法找出一个适合所有的全局阈值,因此改用了局部的自适应阈值二值化处理。其原理是对每一个像素点计算以其为中心的一定范围内的像素点平均值,若该像素点值大于平均值的一定阈值比例,则认为将该点置为255,否则置0,在本次因为使用了 MNIST 数据集训练,一样地将高于阈值的点置0,其余置255.
自适应二值化的处理结果将保存在程序执行目录下的thresh 文件夹中。
图像分割
对图像的分割方法为首先对图像沿着边缘去除灰度值为255的区域,这一步的目的是去除在 A4矫正过程中可能将一部分背景包括在了图像边缘对图像分割所造成的影响。对处理后的图片,使用投影法进行分割,首先求出垂直方向下每一行的有效像素个数,根据获得的数据即可求出图像中数字的行数以及每行的位置。然后,对每行像素作水平方向上每一列的有效像素数求和,即可求得每行上数字的个数和位置。然而上述过程仅在理想状态下有较好的效果,测试数据中却有许多字迹歪斜或者粘连的情况,当这种情况出现时分割效果变差,因此对于分出的每一个数字还要再次尝试进行分割获取实际的单个数字,然而这种做法的缺点是最终获得的每行的数字可能顺序不准确,而且因为不能识别每行中到底有多少个数字,最终生成的结果中对应行的数字是不正确的。
图像分割的结果将以"图片序号-行数-行中位置.jpg"的格式 存入segmentations文件夹中。
Adaboost进行数字识别
Adaboost 通过将多个将多个稍微好于随机的弱分类器进行组合获得一个强分类器,在作业7中已经进行了使用,此次仅包括了 Adaboost 的预测部分的代码,使用的数据为作业7中训练获得的数据。
Adaboost 获得的结果将会把识别的图像根据识别出的数字放入AdaboostResult文件夹中对应数字的目录,若无法识别则放入-1目录。同时会在 AdaboostResult/xlsx目录下对每个图片生成一个 csv 文件,包含了对应图像中每一行识别出的数据。在执行目录下还会生成一个 Adaboost-result.csv文件,以给出的例子格式保存每张图的前三行数据。
卷积神经网络进行数字识别
在本次程序中另外使用了TensorFlow来训练卷积神经网络对数字进行识别。卷积神经网络的主要组成部分包括卷积层,池化层和密集层。相对于传统的BP神经网络,卷积神经网络同样使用反向传播的方法进行训练,但是仅有密集层为全连接。卷积神经网络中的卷积层作用为对图像中的每个子区域应用卷积核,从而输出图像特征。池化层一般跟在卷积层后,作用为降低卷积层输出的特征图维度,减少神经网络的处理时间,处理方法有取区域的最大值或平均值进行池化。
在本次代码实现中主要参考了 TensorFlow 官方教程进行 CNN 的构建,通过对 MNIST 数据集进行训练后获得的结果对MNIST 测试集准确率达到97.87%,但是对于作业中的数据实际的准确率目测仅有30%左右。因此,在代码下 CNN 文件夹中还包含了从给出的图片中经过图片分割后选出的部分数字作为训练集进行训练,以及560个数字作为测试集,经过训练后对MNIST 测试集准确率为39%,对自制的测试集准确率为99.8%,对作业中图片数据的识别效果远好于此前使用 MNIST 数据集时的效果。
4 文件结构
提交的文件根目录下中包含三个文件夹:ImageData 文件夹包含了作业第一部分的10张测试图片和测试结果,part2Data文件夹包含了第二部分的各个文件夹的原图片与测试结果,project文件夹中包含 C++与 Python 的代码文件。
AdaboostPredict 文件夹中包含了 A4纸矫正,图像分割以及 Adaboost 进行识别的代码,使用 cmake 构建,要求系统具有 OpenCV 环境。编译指令如下:
cmake .
make -j 4
cmake -G "NMake Makefiles" .
nmake
C++代码中各个部分作用如下:
- utils.h与utils.cpp文件包含多个类进行图像处理时都可能用到的函数
- OpenCV_utils包含 CImg 到 OpenCV 的 Mat 的转换方法以及对测试数字图像数据的预处理
- Adaboost 文件夹中包含于 adaboost 有关的代码,执行时从执行目录下的 mnist 文件夹中读取训练好的 Adaboost 数据。
- a4文件夹下包含 a4纸矫正相关的代码文件
- segmentation 文件夹下包含与数字的分割相关的代码文件。
- 主程序的使用方法如下:
- ./recognition lower higher [skipA4] [skipAdaboost]
- 其中 lower 代表文件的起始序号,higher 代表最后一个文件的序号-1,程序将从执行目录下的testcases文件夹读取图片并输出结果至对应文件夹。若指定skipA4参数,则程序直接从 a4文件夹读取已矫正的输入,不进行矫正操作,若指定skipAdaboost,则程序不会进行 Adaboost 识别数字的操作。
CNN 目录下包含了使用卷积神经网络的 Python 代码,各个文件作用如下:
- tf_cnn_mnist_test.py, tf_cnn_mnist_train.py 以上2个文件分别对MNIST 数据集进行测试与训练,训练结果保存在mnist 文件夹下。
- tf_cnn_mySet_test.py, tf_cnn_mySet_train.py 以上2个文件分别对自制的数据集进行测试与训练,训练结果保存在myTrainSet 文件夹下。
- tf_cnn_mnist_predict.py tf_cnn_mySet_predict.py 以上两个文件提供对传入的数字使用 MNIST 训练的模型以及自制数据集训练的模型进行数字识别的函数,若直接运行则从命令行读取文件名列表并返回所有接受的文件名对应的图片所识别的数字。
- tf_cnn_mnist_run.py tf_cnn_mySet_run.py 以上两个文件使用方法为./py lower higher,lower 和 higher 参数意义为文件序号的范围,程序将读取上面 C++程序分割完后的数字文件进行识别并将图片放入结果中对应的文件夹中,最后生成 csv 文件。
此外,在每个测试数据下都放置了5个 SHELL 脚本文件,作用如下:
- clean.sh: 清理运行程序所生成的所有文件
- init.sh: 运行程序前需先运行此脚本生成所有文件夹,否则运行过程中会出错。
- adaboost.sh执行完整的 adaboost 识别数字程序,并自动将生成的 csv 转为 xlsx,需在运行参数中指定图片文件序号范围。
- CNN_mnist.sh:执行 C++代码中除 Adaboost 以外的部分,并调用 Python 使用 MNIST 数据集训练的模型进行识别输出结果,需在运行参数中指定图片文件序号范围,若已生成过 A4矫正则可通过 skipA4参数跳过 A4矫正。
- CNN_mnist.sh:执行 C++代码中除 Adaboost 以外的部分,并调用 Python 使用 自制的数据集训练的模型进行识别输出结果,
5 程序运行结果
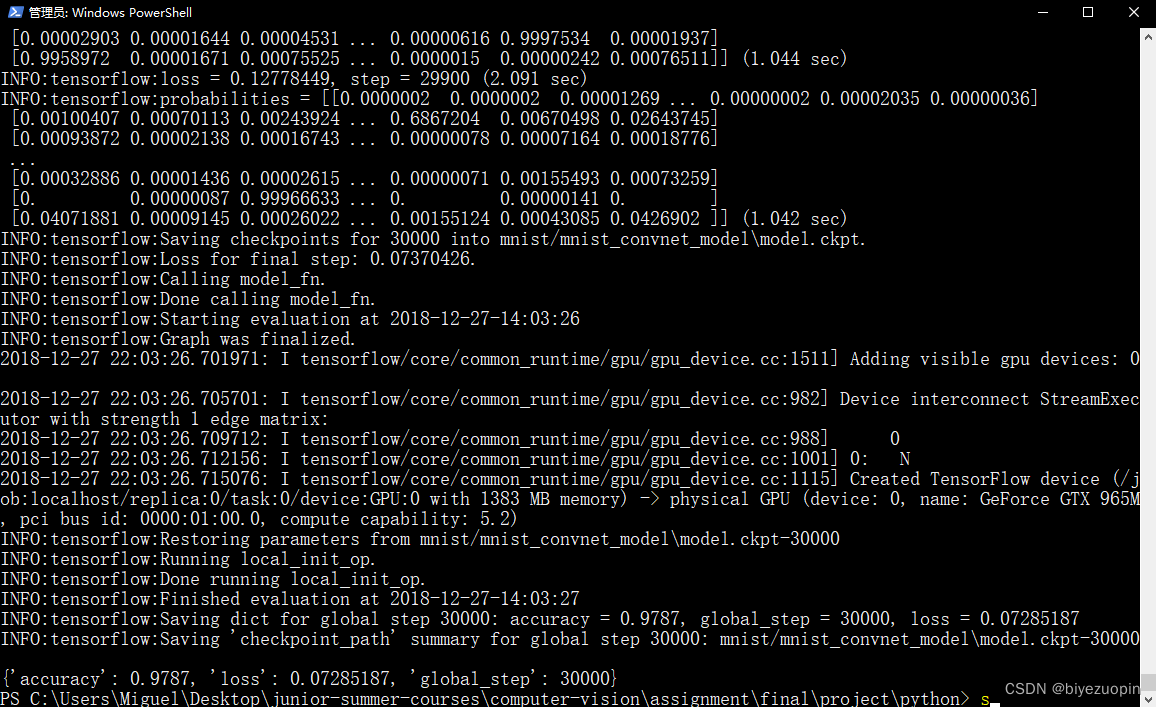
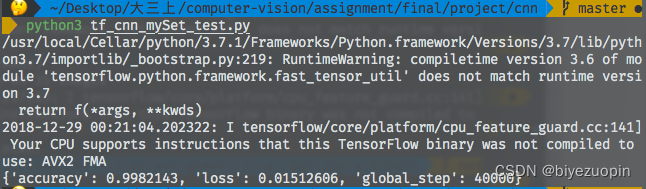
CNN 训练的结果如下:
在搭载 GTX 965M的 Windows 笔记本下进行MNIST数据集训练结果,准确率为97.87%:
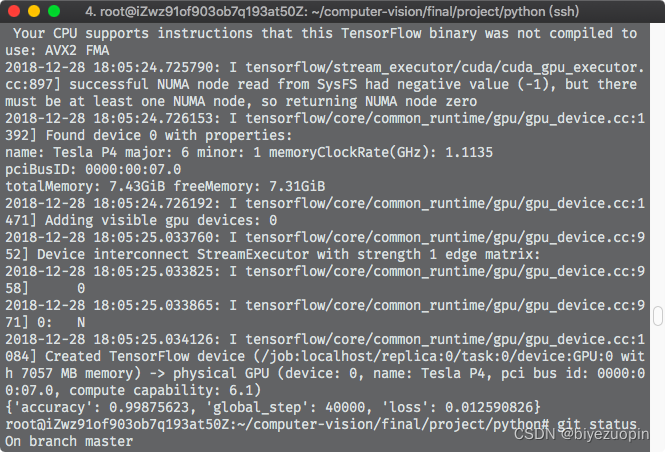
在阿里云 GPU实例下进行自制的数据集的训练,对训练集自身进行测试准确率为99.87%:
对自制的测试集进行训练,准确率为99.82%:
对给出的10张图片测试获得的xlxs文件如下:
Adaboost(X代表无法识别的数字):
filenamestudentIDphonecitizenID0.jpg177177911X7577X7X1147X57X1773XX171117771.jpg15771117171X41557X3XXX5151711772567752.jpg17X7177717775115777571711111517X777173.jpg1777177717991115X759751791771379777714.jpg15X71X711X1X7X771117713X73XX7775171155.jpg75XX71051X61766X1718451X117711736113X6.jpg5115157551757757777XX77777777717175577.jpg17X717X117167X7771X1X51551171172515718.jpg15X913771X17X7XX37X70177X517X1177XX7757X7777X15776X11X159.jpg17771577157771377777771771751567X9719
可以看到 Adaboost 经常出现无法识别数字的情况,而且识别到的数字准确率非常低。
CNN(MNIST训练):
filenamestudentIDphonecitizenID0.jpg1333133335211153951458237133248103313181.jpg15351180152828510818823131778432633512.jpg15331327138118183712411211836122333123.jpg13331344133111158185331321775322773214.jpg15331367136337538319712812373333138355.jpg15371366156171541218861011718102521386.jpg13331351331173153554452333000515102587.jpg15351052155505537835509251771122210128.jpg153313481415456033320152341841188431180022218155264114189.jpg1533139118733181323350105174105092319
可看到识别准确率已高了许多,把4识别为9,把9识别为7,把5识别为3的情况在错误中比较多。
CNN(自制训练集):
filenamestudentIDphonecitizenID0.jpg1533133393777132461456757137446163313781.jpg15331180132608310414423131998032730592.jpg15331029138274183924417211996122730123.jpg15331344155211456783501021996022943214.jpg15331364136325528314412812345030934355.jpg15331646136191547214453011998102527346.jpg13331351137192743064452022000010100587.jpg15331052155605639833504261997122210128.jpg153313481415456033320162341941198461180022218156264114189.jpg1533134718950182323350106199705042314
可以看到使用自制的数据集训练的 CNN 可以达到较高的识别率。
另外可以看到的一个问题是在第9张图中,由于其第2,3,4行的字迹歪斜:
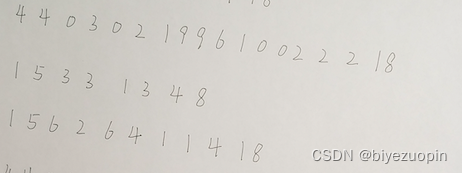
从而导致程序在进行投影法分割时会将其错误地识别为一行,从而导致了错误的长输出。
识别前的各个步骤的输出图像结果也已保存在压缩包中。
资源下载地址:https://download.csdn.net/download/sheziqiong/85997092
资源下载地址:https://download.csdn.net/download/sheziqiong/85997092
Original: https://blog.csdn.net/sheziqiong/article/details/125704506
Author: biyezuopin
Title: 基于C++和Python实现的手写信息识别
相关阅读2
Title: 山东大学nlp实验--CRF环境配置
前言
按照实验指导中的方式配出来的环境,是跑不通代码的!!!
python-3.6 + tensorflow=1.14 + keras=2.2.5亲测有效!!!
缺点是可能不能启动 gpu,即使下载的是 tesorflow-gpu=1.14,因为和硬件可能不匹配
因为本次实验只是体验 CRF,如果需要长时间训练,还是建议下载与 CUDA匹配的版本,然后再改代码的语法,来利用 GPU训练。检查 GPU是否能使用的代码
import tensorflow as tf
tf.test.is_gpu_available()
按实验指导执行一遍
pip install keras-preprocessing==1.0.9。这个版本的貌似找不到了,直接pip install keras-preprocessing就好了。unzip work/keras-contrib-master.zip。这个work/是工作目录下的意思,直接cd word进入存储文件的目录解压即可python keras-contrib-master/setup.py install。这个就是你刚刚解压的zip生成的文件夹keras-contrib-master,直接执行命令即可unzip work/bi-lstm-crf-master.zippython bi-lstm-crf-master/setup.py install。这两步和刚刚的两步是一个道理。
额外步骤
更换 keras 版本
- 运行
python keras-contrib-master/setup.py install会安装上最新版本的keras==2.8.0 - 没有安装
tensorflow,如果安装上keras==2.8.0对应版本的tensorflow是无法跑通代码的 - 于是用了比较常用的
tesorflow==1.14 + keras==2.2.5,可以跑通。
dl_segmenter找不到的问题
path1和path2需要改成自己相应文件的对应路径,比如我的是 path1 = "/home/nsy/nlp/exp3/CRF/bi-lstm-crf-master"。这样才能够导入 dl_segmenter,因为它在 bi-lstm-crf-master里面,是自定义的模块。
上述用法的原因可参考 sys.path用法介绍
模型加载
可能出现的问题,有同学和我版本,代码都一致,但并没有出现这个问题
在使用 get_or_create加在模型时,总会报错 no weights found,create a new model。这在训练和测试时都会出现

但是,路径和环境都是没有问题的,于是去找源码,看看 get_or_create函数是怎么定义的。
真正不能加载模型要在测试时看,因为训练的时候,读模型权重的路径少了一个 -,(应该是故意的),想要训练一个新的模型。如果直接读取预训练模型接着训练的话, loss一会就变成负的了。
- 在
CRF/bi-lstm-crf-master/dl_segmenter/core.py中找到相关内容


我们发现错误是从这里来的, try没有成功,但是我们现在想看看 try为什么不成功,而且在测试时,我们是一定要加载预训练模型的。于是改成

再次运行测试代码 test.py,发现报错
Traceback (most recent call last):
File "/home/nsy/nlp/exp3/CRF/bi-lstm-crf-master/dl_segmenter/core.py", line 188, in get_or_create
DLSegmenter.__singleton = DLSegmenter(**config)
File "/home/nsy/nlp/exp3/CRF/bi-lstm-crf-master/dl_segmenter/core.py", line 55, in __init__
self.model.load_weights(weights_path)
File "/home/nsy/anaconda3/envs/nlp/lib/python3.6/site-packages/keras/engine/saving.py", line 458, in load_wrapper
return load_function(*args, **kwargs)
File "/home/nsy/anaconda3/envs/nlp/lib/python3.6/site-packages/keras/engine/network.py", line 1217, in load_weights
f, self.layers, reshape=reshape)
File "/home/nsy/anaconda3/envs/nlp/lib/python3.6/site-packages/keras/engine/saving.py", line 1145, in load_weights_from_hdf5_group
original_keras_version = f.attrs['keras_version'].decode('utf8')
AttributeError: 'str' object has no attribute 'decode'
我们定位到错误位置 keras/engine/saving.py

这是 Python2和Python3字符编码上的区别
Python3的str默认不是bytes,所以不能decode,只能先encode转为bytes,再decode
python2的str默认是bytes,所以能decode
因此,我们将原代码改为

再次运行测试文件 test.py,发现运行成功,不再报错。至此,我们解决了不能加载模型的问题。
Original: https://blog.csdn.net/qq_52852138/article/details/123571242
Author: 长命百岁️
Title: 山东大学nlp实验--CRF环境配置
相关阅读3
Title: 跟着Cell学单细胞转录组分析(十二):转录因子分析
转录因子分析可以了解细胞异质性背后的基因调控网络的异质性。转录因子分析也是单细胞转录组常见的分析内容,R语言分析一般采用的是SCENIC包,具体原理可参考两篇文章。1、《SCENIC : single-cell regulatory networkinference and clustering》。2、《Ascalable SCENIC workflow for single-cell gene regulatory network analysis》。 但是说在前头,SCENIC的计算量超级大,非常耗费内存和时间,如非必要,不要用一般的电脑分析尝试。可以借助服务器完成分析,或者减少分析细胞数,再或者使用SCENIC的Python版本。这里我们也是仅仅进行演示,数据没有实际意义,人为减少了基因与细胞,然而就这也很费时间。重要的是看看流程。
首先开始前,需要做两件事。第一毫无疑问是安装和加载R包,需要的比较多,如果没有请安装。第二则是下载基因注释配套数据库。
library(Seurat)
library(tidyverse)
library(foreach)
library(RcisTarget)
library(doParallel)
library(SCopeLoomR)
library(AUCell)
BiocManager::install(c("doMC", "doRNG"))
library(doRNG)
BiocManager::install("GENIE3")
library(GENIE3)
#if (!requireNamespace("devtools", quietly = TRUE))
devtools::install_github("aertslab/SCENIC")
packageVersion("SCENIC")
library(SCENIC)
#这里下载人的
dbFiles <- c("https: resources.aertslab.org cistarget databases homo_sapiens hg19 refseq_r45 mc9nr gene_based hg19-500bp-upstream-7species.mc9nr.feather", "https: hg19-tss-centered-10kb-7species.mc9nr.feather") for(featherurl in dbfiles) { download.file(featherurl, destfile="basename(featherURL))" } < code></->
接着就是构建分析文件。
#构建分析数据
exprMat <- as.matrix(immune@assays$rna@data)#表达矩阵 exprmat[1:4,1:4]#查看数据 cellinfo <- immune@meta.data[,c("celltype","ncount_rna","nfeature_rna")] colnames(cellinfo) c('celltype', 'ngene' ,'numi') head(cellinfo) table(cellinfo$celltype) #构建scenicoptions对象,接下来的scenic分析都是基于这个对象的信息生成的 scenicoptions initializescenic(org="hgnc" , dbdir="F:/cisTarget_databases" ncores="1)" < code></->
构建共表达网络,最后一步很费时间。
# Co-expression network
genesKept <- 1 2 3 4 5 6 7 8 9 10 676 1839 genefiltering(exprmat, scenicoptions) exprmat.filtered <- exprmat[geneskept, ] exprmat.filtered[1:4,1:4] runcorrelation(exprmat.filtered, exprmat.filtered.log log2(exprmat.filtered + 1) rungenie3(exprmat.filtered.log, #using tfs as potential regulators... #running genie3 part #finished running genie3. #warning message: #in : # only (37%) of the in database were found dataset. do they use same gene ids? < code></->
构建基因调控网络GRN并进行AUC评分。也是耗费时间的过程。运行完成的结果就是整个分析得到的内容,需要按照自己的目的去筛选。
# Build and score the GRN
scenicOptions <- runscenic_1_coexnetwork2modules(scenicoptions) scenicoptions <- runscenic_2_createregulons(scenicoptions) exprmat_log log2(exprmat + 1) runscenic_3_scorecells(scenicoptions,exprmat_log) runscenic_4_aucell_binarize(scenicoptions) saverds(scenicoptions, file="int/scenicOptions.Rds" ) < code></->
以下是运行记录
>scenicOptions <- 1 2 3 13 27 149 174 236 436 500 523 617 671 676 12551 22290 1993247 runscenic_2_createregulons(scenicoptions) 13:21 step 2. identifying regulons tfmodulessummary: [,1] top5pertargetandtop3sd top5pertargetandtop50 top1sdandtop10pertarget top50pertargetandtop1sd top50andtop10pertarget w0.005 w0.005andtop1sd top50pertarget top50andtop3sd top3sd top50 w0.005andtop50pertarget top1sd top5pertarget top10pertarget w0.001 rcistarget: calculating auc scoring database: [source file: hg19-500bp-upstream-7species.mc9nr.feather] hg19-tss-centered-10kb-7species.mc9nr.feather] not all characters in c: users liuhl desktop 1.r could be decoded using cp936. to try a different encoding, choose "file | reopen with encoding..." from the main menu.17:17 adding motif annotation biocparallel... number of motifs initial enrichment: annotated matching tf: 17:38 pruning targets 19:04 that support regulons: preview enrichment saved as: output step2_motifenrichment_preview.html there were warnings (use warnings() see them)> exprMat_log <- log2(exprmat + 1)> scenicOptions <- 318 runscenic_3_scorecells(scenicoptions,exprmat_log) 19:06 step 3. analyzing the network activity in each individual cell number of regulons to evaluate on cells: biggest (non-extended) regulons: elf1 (1760g) ets1 (1734g) fli1 (1604g) elk3 (1493g) polr2a (1453g) chd2 (1251g) etv3 (1249g) elk4 (1148g) taf1 (974g) erg (956g) quantiles for genes detected by cell: (non-detected are shuffled at end ranking. keep it mind when choosing threshold calculating auc). min 1% 5% 10% 50% 100% 205.00 224.76 276.90 321.40 695.00 997.00 warning .aucell_calcauc(genesets="geneSets," rankings="rankings," ncores="nCores," : using only first (aucmaxrank) calculate auc. 19:07 finished running aucell. plotting heatmap... t-snes... message: max(denscurve$y[nextmaxs]) max里所有的参数都不存在;回覆-inf> scenicOptions <- 168 207 439 runscenic_4_aucell_binarize(scenicoptions) binary regulon activity: tf regulons x cells. (299 including 'extended' versions) are active in more than 1% (4.39)> saveRDS(scenicOptions, file = "int/scenicOptions.Rds")
</-></-></-></->
每一步的分析结果SCENIC都会自动保存在所创建的int和out文件夹。接下来对结果进行可视化,这里是随机选的,没有生物学意义。实际情况是要根据自己的研究目的。
1、可视化转录因子与seurat细胞分群联动
#regulons AUC
AUCmatrix <- readrds("int 3.4_regulonauc.rds") aucmatrix <- aucmatrix@assays@data@listdata$auc data.frame(t(aucmatrix), check.names="F)" regulonname_auc colnames(aucmatrix) gsub(' \\(','_',regulonname_auc) gsub('\\)','',regulonname_auc) scrnaauc addmetadata(immune, aucmatrix) scrnaauc@assays$integrated null saverds(scrnaauc,'immuneauc.rds') #二进制regulo auc binmatrix 4.1_binaryregulonactivity.rds") data.frame(t(binmatrix), regulonname_bin colnames(binmatrix) \\(','_',regulonname_bin) gsub('\\)','',regulonname_bin) scrnabin binmatrix) scrnabin@assays$integrated saverds(scrnabin, 'immunebin.rds') < code></->
作图使用Seurat中FeaturePlot函数。小提琴图也是可以的。
FeaturePlot(scRNAauc, features='CEBPB_extended_1035g', label=T, reduction = 'umap')
FeaturePlot(scRNAbin, features='CEBPB_extended_1035g', label=T, reduction = 'umap')

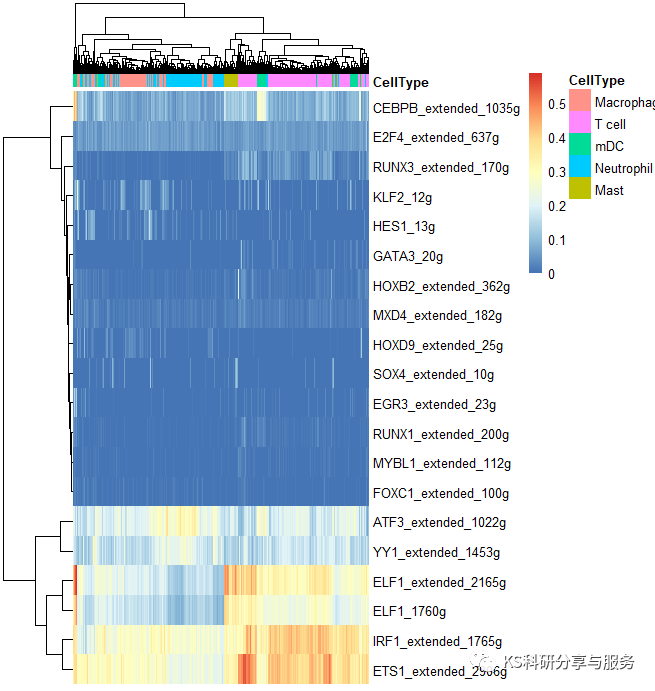
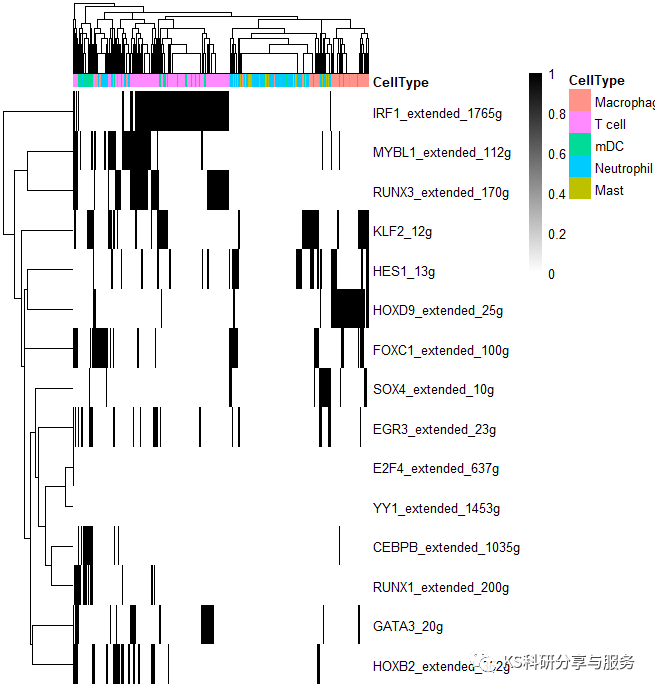
2、最常见的热图,选择需要可视化的regulons。
library(pheatmap)
celltype = subset(cellInfo,select = 'CellType')
AUCmatrix <- t(aucmatrix) binmatrix <- t(binmatrix) regulons c('cebpb_extended_1035g','runx1_extended_200g', 'foxc1_extended_100g','mybl1_extended_112g', 'irf1_extended_1785g', 'elf1_1760g','elf1_extended_2165g', 'irf1_extended_1765g','ets1_extended_2906g', 'yy1_extended_1453g','atf3_extended_1022g', 'e2f4_extended_637g', 'klf2_12g','hes1_13g', 'gata3_20g','hoxb2_extended_362g', 'sox4_extended_10g', 'runx3_extended_170g','egr3_extended_23g', 'mxd4_extended_182g','hoxd9_extended_25g') aucmatrix aucmatrix[rownames(aucmatrix)%in%regulons,] binmatrix[rownames(binmatrix)%in%regulons,] pheatmap(aucmatrix, show_colnames="F," annotation_col="celltype," width="6," height="5)" pheatmap(binmatrix, color="colorRampPalette(colors" = c("white","black"))(100), < code></->
好了,以上是一个基本的流程演示,具体怎么用这个结果,如何解读,可以参考相关的高分文献,了解分析原理,与自己的研究相结合。
更多精彩内容请访问我的个人公众号《KS科研分享与服务》!
Original: https://blog.csdn.net/qq_42090739/article/details/123701891
Author: TS的美梦
Title: 跟着Cell学单细胞转录组分析(十二):转录因子分析