
文章目录
容我废话一下
最近几个月,毒教材被曝光引发争议,那些编写度教材的人着实可恶。咱程序员也没有手绘插画能力,但咱可以借助强大的深度学习模型将视频转动漫。所以今天的目标是让任何具有python语言基本能力的程序员,实现短视频转动漫效果。
效果展示

; 一、思路流程
- 读取视频帧
- 将每一帧图像转为动漫帧
- 将转换后的动漫帧转为视频
难点在于如何将图像转为动漫效果。这里我们使用基于深度学习的动漫效果转换模型,考虑到许多读者对这块不了解,因此我这边准备好了源码和模型,直接调用即可。不想看文章细节的可以 直接拖到文章末尾,获取源码。
二、图像转动漫
为了让大家不关心深度学习模型,已经为大家准备好了转换后的onnx类型模型。接下来按顺序介绍运行onnx模型流程。
安装onnxruntime库
pip install onnxruntime
如果想要用GPU加速,可以安装GPU版本的onnxruntime:
pip install onnxruntime-gpu
需要注意的是:
onnxruntime-gpu的版本跟CUDA有关联,具体对应关系如下:
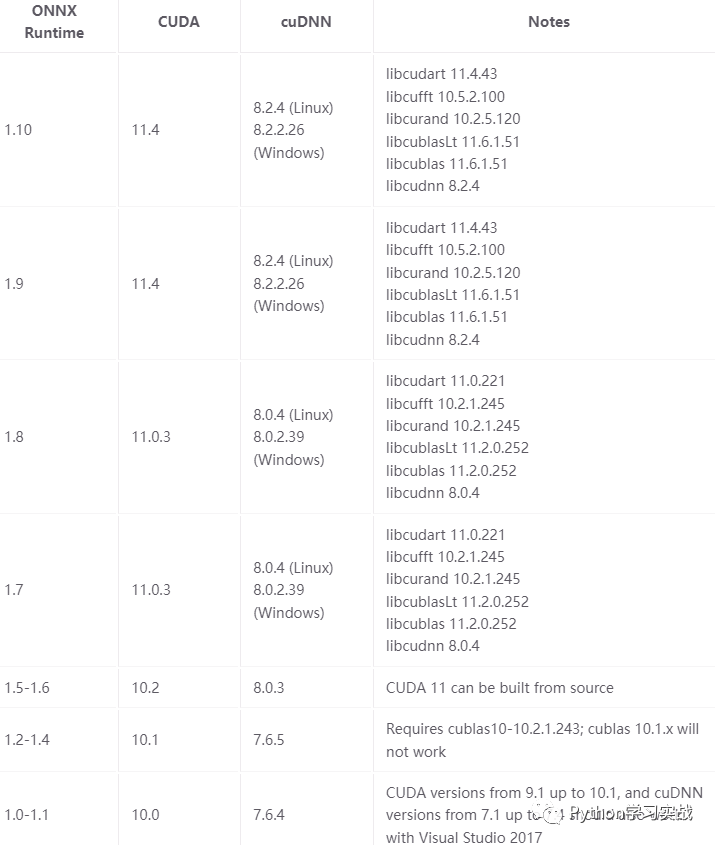
当然,如果用CPU运行,那就不需要考虑那么多了。考虑到通用性,本文全部以CPU版本onnxruntime。
运行模型
先导入onnxruntime库,创建InferenceSession对象,调用run函数。
如下所示
import onnxruntime as rt
sess = rt.InferenceSession(MODEL_PATH)
inp_name = sess.get_inputs()[0].name
out = sess.run(None, {inp_name: inp_image})
具体到我们这里的动漫效果,实现细节如下:
import cv2
import numpy as np
import onnxruntime as rt
MODEL = "models/anime_2.onnx"
sess = rt.InferenceSession(MODEL)
inp_name = sess.get_inputs()[0].name
def infer(rgb):
rgb = np.expand_dims(rgb, 0)
rgb = rgb * 2.0 / 255.0 - 1
rgb = rgb.astype(np.float32)
out = sess.run(None, {inp_name: rgb})
out = out[0][0]
out = (out+1)/2*255
out = np.clip(out, 0, 255).astype(np.uint8)
return out
def preprocess(rgb):
pad_w = 0
pad_h = 0
h,w,__ = rgb.shape
N = 2**3
if h%N!=0:
pad_h=(h//N+1)*N-h
if w%2!=0:
pad_w=(w//N+1)*N-w
rgb = np.pad(rgb, ((0,pad_h),(0, pad_w),(0,0)), "reflect")
return rgb, pad_w, pad_h
其中, preprocess函数确保输入图像的宽高是8的整数倍。这里主要是因为考虑到深度学习模型有下采样,确保每次下采样能被2整除。
单帧效果展示



三、视频帧读取与视频帧写入
这里使用Opencv库,提取视频中每一帧并调用回调函数将视频帧回传。在将图片转视频过程中,通过定义VideoWriter类型变量WRITE确保唯一性。具体实现代码如下:
import cv2
from tqdm import tqdm
WRITER = None
def write_frame(frame, out_path, fps=30):
global WRITER
if WRITER is None:
size = frame.shape[0:2][::-1]
WRITER = cv2.VideoWriter(
out_path,
cv2.VideoWriter_fourcc(*'mp4v'),
fps,
size)
WRITER.write(frame)
def extract_frames(video_path, callback):
video = cv2.VideoCapture(video_path)
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
for _ in tqdm(range(num_frames)):
_, frame = video.read()
if frame is not None:
callback(frame)
else:
break
完整源码获取点击下方微信名片获取哟~
给大家推荐一套爬虫教程,涵盖常见大部分案例,非常实用!
代码总是学完就忘记?100个爬虫实战项目!让你沉迷学习丨学以致用丨下一个Python大神就是你!
Original: https://blog.csdn.net/ooowwq/article/details/126319182
Author: 轻松学Python
Title: 如何用Python将普通视频变成动漫视频
相关阅读1
Title: 语音驱动嘴型与面部动画生成的现状和趋势
本文首发于行者AI
引言
随着硬件与虚拟现实设备的快速发展,人们说话时的面部表情、唇部动作,甚至是头部与肢体的动作都可以帮助听众理解对话内容。视觉和听觉的双模态信息融合的交互方式,不仅能提高用户对内容的理解度,还能提供一种更为准确的交互体验,提高歌唱的艺术性和观赏度。
语音驱动嘴型和面部动画生成技术可以让开发者快速构建一些基于数字人的应用,如虚拟主持人、虚拟客服和虚拟教师等。除了能提供更友好的人机交互方式之外,该技术在感知研究、声音辅助学习等方面具有重要应用价值,同时,能够在游戏和电影特效等娱乐化方面降低作品制作成本。
语音驱动嘴型与面部动画生成技术,可以让用户输入文本或语音,通过某种规则或者深度学习算法生成对应的虚拟形象的表情系数,从而完成虚拟形象的口型和面部表情的精准驱动。基于深度学习的语音驱动嘴型与面部动画生成技术具有------特点。基于深度学习的嘴型与面部动画生成算法可以自动从训练集中学习训练集中嘴型生成规则和面部表情生成规则和技巧。而基于规则的嘴型和面部表情生成算法可能存在规则复杂,多样性不足,不同的风格对应的作曲规则差距过大等缺陷。
本文将从下面几个方面介绍语音驱动的嘴型和面部生成算法:
- 当前主流语音驱动的嘴型和面部动画生成技术的一些缺陷。
- 能够解决上述缺陷的算法介绍。
1.当前语音驱动嘴型和面部动画生成技术的一些缺陷
语音驱动嘴型和面部动画生成技术需要解决以下几点缺陷:
- 数据少
开源的语音与3D模型同步数据集少。而自行采集数据需要通过专业的动作捕捉软件录制专业演员的表演视频,成本较高。现有的语音驱动面部动画生成技术可操作性不强,要求在训练样本比较比较充分的情况下才能获得比较好的判断效果,否则对于形变、尺度改变、光照改变等干扰,就不能很好地哦安定。
- 真实性
现今绝大多数研究学者仅仅关注语音驱动三维人脸口型动画,忽略了语音驱动人脸面部姿势,导致生成的虚拟人的人脸木讷呆滞,没有任何表情信息的反馈。因此很多语音驱动面部动画生成技术并不能反映人脸最真实的状况,甚至会产生恐怖谷效应。
- 同步性
深度学习合成的嘴型和面部动画存在合成动画不够连续,跳变现象较多,且动画流畅度和自然度欠佳的不足。语音常常比生成的视频帧超前。
2.能够解决上述缺陷的算法介绍
现有的语音驱动嘴型和面部动画生成算法可以部分解决上述缺陷,下面分别介绍几种现有的语音驱动嘴型和面部动画生成算法。
2.1数据少
2.1.1《Capture, Learning, and Synthesis of 3D Speaking Styles》 [1]
提供了一个独特的 4D 人脸数据集 VOCASET,它包括以 60 fps 的帧速率捕捉到的 4D 扫描(共 29 分钟),以及来自 12 名说话者的同期声。
此外本论文提出了模型 VOCA (Voice Operated Character Animation) 可使用任意语音信号作为输入(即使不是英语也可以),然后将大量成人面部转化为逼真的动图。除此之外,VOCA可以改变说话风格,与身份相关的面部姿势(头部,下巴和眼球旋转),还适用于训练集中未出现过的人物形象。
该模型的主要结构如下图:

该算法的网络架构如下图
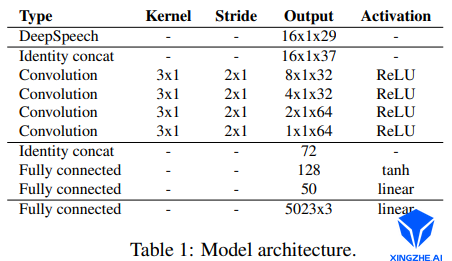
输入:音频、具体人物目标模板。
输出:60fps 3D mesh。
语音特征提取:采用DeepSpeech模型。
编码网络:加入了身份信息,拼接one-hot向量到语音特征上。
解码网络:最后的fc层,输出5023*3个顶点的偏移量,加上模板平均脸,得到说话的表情脸。
该模型的输入使用3~5分钟的高质量动画视频数据训练网络也能获得较好的结果,而且对不同性别、口音、语种的人声训练,都能获得较好的训练效果。
该算法的主要结构如下图:
给定一个音频窗口数据,模型负责输出窗口中心时间点的脸部表情参数。作者用与一个固定拓扑的脸部mesh的逐顶点差分向量表示表情。实际inference时,沿着音频的时间滑窗,每一个step进行推理驱动mesh动画。每个窗口单独作为输入。每个step单独推理,虽然没有像RNN网络一样记忆前后帧的关系,但是滑窗窗口本身窗口让模型具备了前后帧稳定性。
; 2.2真实性
2.2.1《A Deep Learning Approach for Generalized Speech Animation》 [3]
这个算法采用音视频数据库训练模型。其中音频已经标注了对应的音位信息,使用AMM (Active Appearance Model)从视频中提取人脸表情相关的参数;根据音位和人脸表情动画参数数据集,训练模型。推断过程中,使用语音识别等已有的技术,从音频中提取音位信息,并输入给训练好的模型,输出对应的人脸表情参数。最终将人脸表情参数转移到目标卡通模型脸上,即可驱动卡通模型的面部表情动作。
由于这个算法采用了标准的AAM模型描述模型并使用了滑动窗口预测器,因此可以在成本较低的条件下精准生成自然动作和可视化的协同发音效果。
该算法的主要结构如下图:
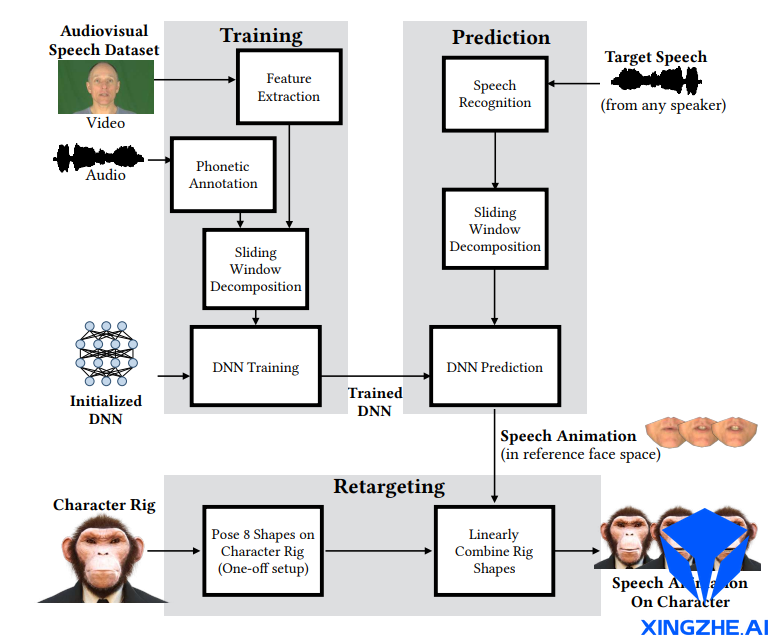
音频特征与人脸表情动画特征之间为序列到序列的映射。常用的学习序列到序列的映射的方法(up to 2017)包括滑动窗口(sliding window model)和循环定义网络(recurrently defined model)。其中前者强调序列的局部短时相关性,而后者强调序列的长时相关性。基于以下的归纳偏置,论文采用了滑动窗口方法。
- 由于协同发音与时序相关,因此在时序上协同发音对应的动画特征序列长度变化很大
协同发音通常具备局部的短时相关性,而与较长序列无关。例如'prediction'和'construction'中的'-tion'发音相同,而与其之前的字母序列无关。 - 循环定义网络,包括RNN和LSTM网络虽然具备seq2seq的学习能力,但是不符合上述的归纳偏置,需要大量的训练数据才能得到较好的预测效果。论文也通过实验证明滑动窗口方法具有较好的性能特征。
使用滑动窗口方法进行模型训练的流程如下图所示(针对单个表情系数):
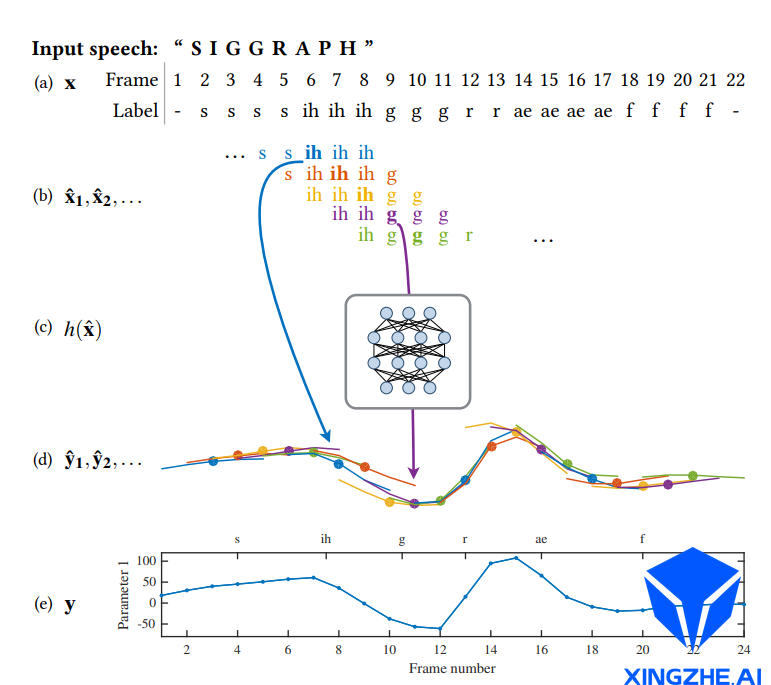
步骤一:首先将输入的音位帧序列按照长度为的滑动窗口,划分为连续重叠子序列,如图(b)
步骤二:将每个窗口内的序列作为输入,传递给前馈神经网络,输出对应长度为的表情参数序列,如图©和(d)
步骤三:使用逐帧平均,在融合得到每帧对应的表情参数,如图(e)
; 2.2.2《Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion》
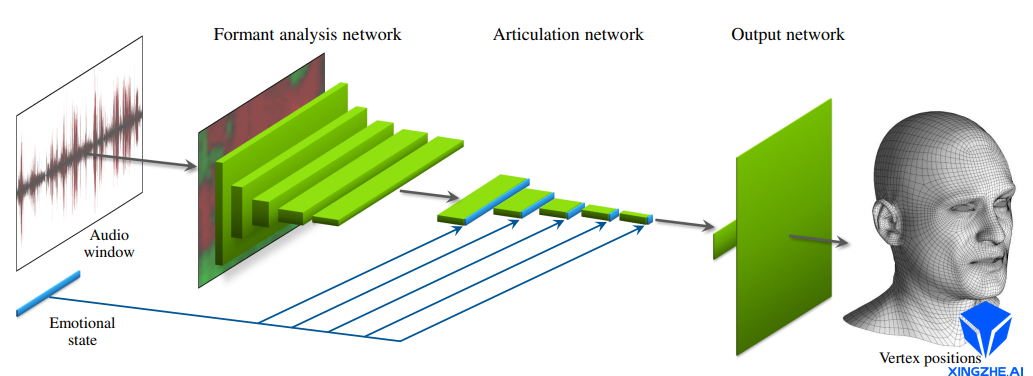
提出了一种端到端的卷积网络,从输入的音频直接推断人脸表情变化对应的顶点位置的偏移量。为了解决声音驱动过程中,情绪变化对表情驱动效果的影响,网络自动从数据集中学习情绪状态潜变量。推理阶段,可将情绪潜变量作为用户输入控制参数,从而输出不同情绪下的说话表情。让最终生成的嘴型效果更加真实。
其网络结构完成了对情绪的处理,让最终生成的结果更加真实。根据功能,网络主要划分为三个部分:频率分析层(Formant Analysis Network)、发音分析层(Articulation Network)、顶点输出层(Output Network)。
- Formant Analysis Network
频率分析层包括一个固定参数的自相关处层(autocorrelation)、以及5个卷积层。自相关层使用线性预测编码(Linear Predictive Coding, LPC)提取音频的前K个自相关系数。由于自相关系数描述了原始音频信号共振峰的能量普分布,因此可以用系数来描述音频的特征。自相关层以多帧音频信号为输入,经过处理输出WH的2D音频特征图。其中W表示帧数,H表示自相关系数的维度。2D音频特征图再经过五层的13的卷积,对自相关系数进行压缩,最终输出W*1的特征向量。语音处理层的网络结构如下所示:
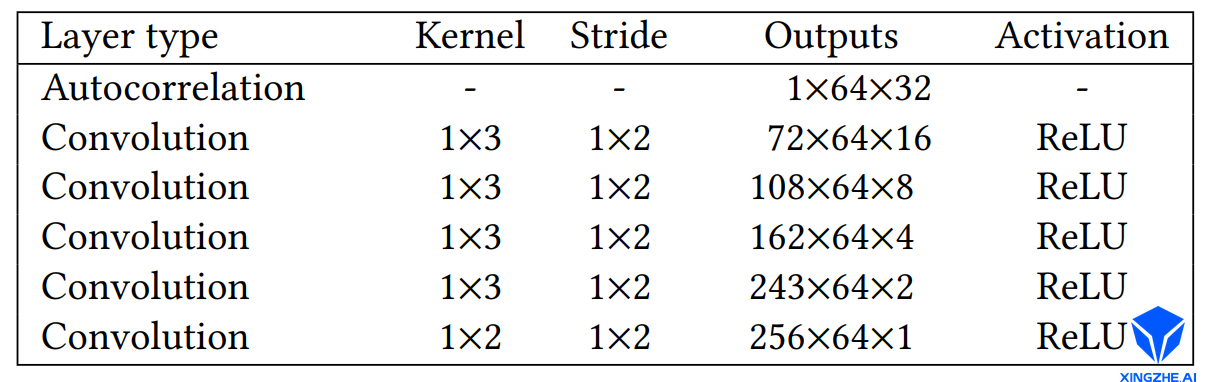
语音单帧时间长度为16ms,因此语音处理网络主要是针对音频的短时特征进行提取,包括语调、重音、以及特殊音位信息等。
- Articulation Network
语音处理层输出的音频特征向量维度为256 * W * 1。其中256为特征图的通道数。发音分析层包含5个卷积层,每层的卷积核为3*1,用于在时序上提取相邻序列帧的关联特征,输出发音特征图。由于发音不仅与声音频率相关,而且与说话者的情绪和类型等紧密相关。语音处理层同时接受训练提取的情绪状态,向量长度为E,直接连接到发音特征图,与发音特征图联合学习与表情的关系。语音处理层的网络结构如下图所示:

经过语音处理层处理后,最终输长度为(256+E)的特征向量,其中256为音频特征,E为情绪特征。在训练阶段,情绪向量的输入为E维的随机高斯分布采样。针对带情绪的输入样本,训练过程中存储语音处理层输出的特征向量,其中的E维特征向量即为自动学习到的该训练样本数据所蕴含的情绪状态。将不同情绪数据下学习到的情绪特征向量组合构成了情绪状态矩阵。在推断过程中,用户可以选择该矩阵的任意一组向量作为情绪输入(而非随机高斯分布采样),控制输出表情中包含指定的情绪。亦可通过线性组合不同的情绪向量作为输入,从而产生包含新情绪的表情动画。通过此中自动学习数据中蕴含的情绪,避免了手工标数据集的注情绪状态标签所造成的歧义和不准确性。情绪特征向量并没有实际的语义信息,因此并不能通过one-hot向量来描述不同的情绪,一个语义明确的情绪对应的情绪向量可能每一维度值都有取值。
- Output Network
语音处理层输出的(256+E)维的特征向量即为从训练集上学习到的人脸说话表情动画的特征。输出网络通过两层全连接层实现从特征到人脸表情顶点坐标的映射。第一层实现了从语音特征到人脸表情基系数的映射,第二层实现了从表情系数到每个顶点坐标值的映射。第二层的权重矩阵对应的其实就是传统表情驱动中的多线性人脸表情模型,因此可以预先用150个预计算的PCA分量进行初始化。输出网络的结构图如下所示:

2.3同步性
2.3.1《Audio-Driven Facial Animation by Joint End-to-End Learning of Pose and Emotion》
提出了一种端到端的卷积网络,从输入的音频直接推断人脸表情变化对应的顶点位置的偏移量。引入三个损失函数用于训练中约束时间稳定性,以及动画过程中保证响应速度。
该算法的主要结构如下图:
损失函数包括三项,分别为位置项、运动项、以及情绪正则项。对于包含多项的损失函数,一个较大的挑战在于如何给各项选择合适的权重值,用于调和量纲的不同以及重要程度。论文对每一项都进行归一化处理,避免了额外增加权重。
- Position term
位置项。描述了网络预测的人脸表情与gt人脸表情之间的逐顶点均方差值:

其中V为人脸模型的顶点数。y描述的是将所有顶点按照分量展开后组成的长度为3V的向量。
- Motion term
运动项。位置项只约束了单帧预测的误差,没有考虑帧间的关系,容易导致帧间表情动作的波动,通过约束预测输出帧间顶点运动趋势与数据集上顶点在帧间运动趋势一致,可以有效避免表情动作的抖动,保证动作的平滑。训练通常采用minbatch策略。假设minbatch中训练样本数为B,则按相邻两帧为一组,划分为B/2组,计算组内前后两帧输出差值,作为顶点运动速度。计算符号定义为m[.],则运动项的定义为:
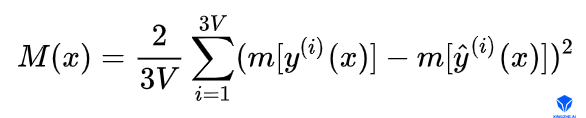
- Regularization term
正则项。为了避免学习到的情绪状态包含跟语音特征相似的特征,需要网络能够自动区分学习语言音频发音特征和情绪特征。考虑到语音频率的短时变化性,情绪在相对较长时间是不变的,可以通过约束情绪状态特征变化过快来引导网络通过音频发音特征描述短时的语音变化,而情绪特征描述长时的情绪变化。通过直接约束两帧情绪状态的变化速度为0即可达到目标:
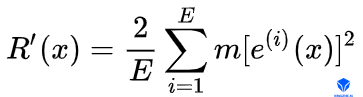
其中 $ e^{(i)}(x) $ 表示训练样本x时对应的情绪状态特征向量的第i个分量。为了避免网络通过增大权重,而抑制e变量各分量为0来满足该正则项要求,通过借鉴BN的思想,对其进行归一化处理.
; 3.总结
随着深度学习技术的发展和语音生成嘴型和面部动画技术的进步,会有越来越多的方案能够解决这些缺陷。
参考文献
[1]D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan and M. J. Black, "Capture, Learning, and Synthesis of 3D Speaking Styles," 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10093-10103, doi: 10.1109/CVPR.2019.01034.
[2] Tero Karras, Timo Aila, Samuli Laine, Antti Herva, and Jaakko Lehtinen. 2017. Audio-driven facial animation by joint end-to-end learning of pose and emotion. ACM Trans. Graph. 36, 4, Article 94 (August 2017), 12 pages.
[3]Sarah Taylor, Taehwan Kim, Yisong Yue, Moshe Mahler, James Krahe, Anastasio Garcia Rodriguez, Jessica Hodgins, and Iain Matthews. 2017. A deep learning approach for generalized speech animation. ACM Trans. Graph. 36, 4, Article 93 (August 2017), 11 pages.
我们是行者AI,我们在"AI+游戏"中不断前行。
前往公众号 【行者AI】,和我们一起探讨技术问题吧!
Original: https://blog.csdn.net/suiyuejian/article/details/125777897
Author: 行者AI
Title: 语音驱动嘴型与面部动画生成的现状和趋势
相关阅读2
Title: 全面解析Kmeans聚类算法(Python)
Clustering (聚类) 是常见的unsupervised learning (无监督学习)方法,简单地说就是把相似的数据样本分到一组(簇),聚类的过程.
我们并不清楚某一类是什么(通常无标签信息),需要实现的目标只是把相似的样本聚到一起,即只是利用样本数据本身的分布规律。
在本文中,我将详细介绍聚类算法, 喜欢本文记得收藏、关注、点赞。
【注】完整版代码、数据、技术交流文末提供。
聚类算法可以大致分为 传统聚类算法以 及深度聚类算法:
- 传统聚类算法主要是根据原特征+基于划分/密度/层次等方法。

- 深度聚类方法主要是根据表征学习后的特征+传统聚类算法。

; kmeans聚类原理
kmeans聚类可以说是聚类算法中最为常见的,它是基于划分方法聚类的,原理是先初始化k个簇类中心,基于计算样本与中心点的距离归纳各簇类下的所属样本,迭代实现样本与其归属的簇类中心的距离为最小的目标(如下目标函数)。
其优化算法步骤为:
1.随机选择 k 个样本作为初始簇类中心(k为超参,代表簇类的个数。可以凭先验知识、验证法确定取值);
2.针对数据集中每个样本 计算它到 k 个簇类中心的距离,并将其归属到距离最小的簇类中心所对应的类中;
3.针对每个簇类,重新计算它的簇类中心位置;
4.重复迭代上面 2 、3 两步操作,直到达到某个中止条件(如迭代次数,簇类中心位置不变等)。

....
random.seed(1)
center = [[self.data[i][r] for i in range(1, len((self.data)))]
for r in random.sample(range(len(self.data)), k)]
for i in range(self.iters):
class_dict = self.count_distance()
self.locate_center(class_dict)
print("----------------迭代%d次----------------"%i)
print(self.center_dict)
if sorted(self.center) == sorted(self.new_center):
break
else:
self.center = self.new_center
可见,Kmeans 聚类的迭代算法实际上是 EM 算法,EM 算法解决的是在概率模型中含有无法观测的隐含变量情况下的参数估计问题。
在 Kmeans 中的隐变量是每个类别所属类别。Kmeans 算法迭代步骤中的 每次确认中心点以后重新进行标记 对应 EM 算法中的 E 步 求当前参数条件下的 Expectation 。而 根据标记重新求中心点 对应 EM 算法中的 M 步 求似然函数最大化时(损失函数最小时)对应的参数 。EM 算法的缺点是容易陷入局部极小值,这也是 Kmeans 有时会得到局部最优解的原因。
选择距离度量
kmeans 算法是基于距离相似度计算的,以确定各样本所属的最近中心点,常用距离度量有曼哈顿距离和欧式距离
- 曼哈顿距离 公式:

- 欧几里得距离 公式:
 曼哈顿、欧几里得距离的计算方法很简单,就是计算两样本(x,y)的各个特征i间的总距离。如下图(二维特征的情况)蓝线的距离即是曼哈顿距离(想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个"曼哈顿距离",也称为城市街区距离),红线为欧几里得距离:
曼哈顿、欧几里得距离的计算方法很简单,就是计算两样本(x,y)的各个特征i间的总距离。如下图(二维特征的情况)蓝线的距离即是曼哈顿距离(想象你在曼哈顿要从一个十字路口开车到另外一个十字路口实际驾驶距离就是这个"曼哈顿距离",也称为城市街区距离),红线为欧几里得距离:

; 四、k 值的确定
kmeans划分k个簇,不同k的情况,算法的效果可能差异就很大。K值的确定常用:先验法、手肘法等方法。
- 先验法
先验比较简单,就是凭借着业务知识确定k的取值。比如对于iris花数据集,我们大概知道有三种类别,可以按照k=3做聚类验证。从下图可看出,对比聚类预测与实际的iris种类是比较一致的。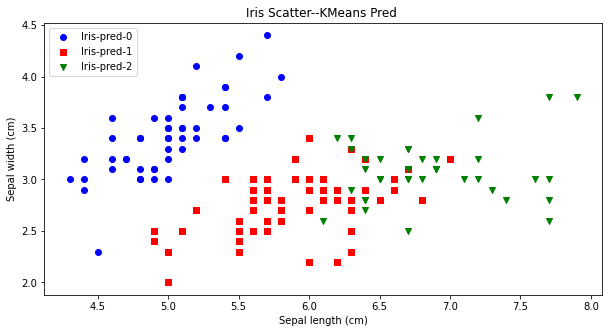

- 手肘法
可以知道k值越大,划分的簇群越多,对应的各个点到簇中心的距离的平方的和(类内距离,WSS)越低,我们通过确定WSS随着K的增加而减少的曲线拐点,作为K的取值。
手肘法的缺点在于需要人为判断不够自动化,还有些其他方法如:
- 使用 Gap statistic 方法,确定k值。
- 验证不同K值的平均轮廓系数,越趋近1聚类效果越好。
- 验证不同K值的类内距离/类间距离,值越小越好。
- ISODATA算法:它是在k-均值算法的基础上,增加对聚类结果的"合并"和"分裂"两个操作,确定最终的聚类结果。从而不用人为指定k值。
五、Kmeans的缺陷
5.1 初始化中心点的问题
kmeans是采用随机初始化中心点,而不同初始化的中心点对于算法结果的影响比较大。所以,针对这点更新出了Kmeans++算法,其初始化的思路是:各个簇类中心应该互相离得越远越好。基于各点到已有中心点的距离分量,依次随机选取到k个元素作为中心点。离已确定的簇中心点的距离越远,越有可能(可能性正比与距离的平方)被选择作为另一个簇的中心点。如下代码。
center = []
center.append(random.choice(range(len(self.data[0]))))
for i in range(self.k - 1):
weights = [self.distance_closest(self.data[0][x], center)
for x in range(len(self.data[0])) if x not in center]
dp = [x for x in range(len(self.data[0])) if x not in center]
total = sum(weights)
weights = [weight/total for weight in weights]
num = random.random()
x = -1
i = 0
while i < num :
x += 1
i += weights[x]
center.append(dp[x])
center = [self.data_dict[self.data[0][center[k]]] for k in range(len(center))]
5.2 核Kmeans
基于欧式距离的 Kmeans 假设了了各个数据簇的数据具有一样的的先验概率并呈现球形分布,但这种分布在实际生活中并不常见。面对非凸的数据分布形状时我们可以引入核函数来优化,这时算法又称为核 Kmeans 算法,是核聚类方法的一种。核聚类方法的主要思想是通过一个非线性映射,将输入空间中的数据点映射到高位的特征空间中,并在新的特征空间中进行聚类。非线性映射增加了数据点线性可分的概率,从而在经典的聚类算法失效的情况下,通过引入核函数可以达到更为准确的聚类结果。
5.3 特征类型
kmeans是面向数值型的特征,对于类别特征需要进行onehot或其他编码方法。此外还有 K-Modes 、K-Prototypes 算法可以用于混合类型数据的聚类,对于数值特征簇类中心我们取得是各特征均值,而类别型特征中心取得是众数,计算距离采用海明距离,一致为0否则为1。
5.4 特征的权重
聚类是基于特征间距离计算,计算距离时,需要关注到特征量纲差异问题,量纲越大意味这个特征权重越大。假设各样本有年龄、工资两个特征变量,如计算欧氏距离的时候,(年龄1-年龄2)² 的值要远小于(工资1-工资2)² ,这意味着在不使用特征缩放的情况下,距离会被工资变量(大的数值)主导。因此,我们需要使用特征缩放来将全部的数值统一到一个量级上来解决此问题。通常的解决方法可以对数据进行"标准化"或"归一化",对所有数值特征统一到标准的范围如0~1。
归一化后的特征是统一权重,有时我们需要针对不同特征赋予更大的权重。假设我们希望feature1的权重为1,feature2的权重为2,则进行0~1归一化之后,在进行类似欧几里得距离(未开根号)计算的时候, 我们将feature2的值乘根号2就可以了,这样feature2对应的上式的计算结果会增大2倍,从而简单快速的实现权重的赋权。如果使用的是曼哈顿距离,特征直接乘以2 权重也就是2 。
我们将feature2的值乘根号2就可以了,这样feature2对应的上式的计算结果会增大2倍,从而简单快速的实现权重的赋权。如果使用的是曼哈顿距离,特征直接乘以2 权重也就是2 。
如果类别特征进行embedding之后的特征加权,比如embedding为256维,则我们对embedding的结果进行0~1归一化之后,每个embedding维度都乘以 根号1/256,从而将这个类别全部的距离计算贡献规约为1,避免embedding size太大使得kmeans的聚类结果非常依赖于embedding这个本质上是单一类别维度的特征。
5.5 特征的选择
kmeans本质上只是根据样本特征间的距离(样本分布)确定所属的簇类。而不同特征的情况,就会明显影响聚类的结果。当使用没有代表性的特征时,结果可能就和预期大相径庭!比如,想对银行客户质量进行聚类分级:交易次数、存款额度就是重要的特征,而如客户性别、年龄情况可能就是噪音,使用了性别、年龄特征得到的是性别、年龄相仿的客户!
对于无监督聚类的特征选择:
- 一方面可以结合业务含义,选择贴近业务场景的特征。
- 另一方面,可以结合缺失率、相似度、PCA等常用的特征选择(降维)方法可以去除噪音、减少计算量以及避免维度爆炸。再者,如果任务有标签信息,结合特征对标签的特征重要性也是种方法(如xgboost的特征重要性,特征的IV值。)
- 最后,也可以通过神经网络的特征表示(也就深度聚类的思想。后面在做专题介绍),如可以使用word2vec,将高维的词向量空间以低维的分布式向量表示。
推荐文章
- 李宏毅《机器学习》国语课程(2022)来了
- 有人把吴恩达老师的机器学习和深度学习做成了中文版
- 上瘾了,最近又给公司撸了一个可视化大屏(附源码)
- 如此优雅,4款 Python 自动数据分析神器真香啊
- 梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
- 年终汇总:20份可视化大屏模板,直接套用真香(文末附源码)
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过 2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号: dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号: Python学习与数据挖掘,后台回复:加群

Original: https://blog.csdn.net/weixin_38037405/article/details/124315032
Author: 我爱Python数据挖掘
Title: 全面解析Kmeans聚类算法(Python)
相关阅读3
Title: YOLOv5的Neck端设计
YOLOv5的Neck端设计
在上一篇《YOLOv5的Backbone设计》中,我们从yolov5的backbone配置文件出发,细致讲解了backbone的网络架构及各模块的源码和结构,对骨架网络有了较为全面的初步认知。接下来我们会循着之前的学习思路,继续深入到网络结构源码中去探寻YOLO的Neck端设计。
1 Neck结构总览

网络结构配置文件中并未将neck和head进行区分,而是直接以head命名,这也是方便在models/yolo.py中的加载。为了读者能够清晰明白地感知neck的设计,在本文中我们只讨论head中的neck部分:
neck:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]],
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]],
[-1, 3, C3, [256, False]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]],
[-1, 3, C3, [512, False]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]],
[-1, 3, C3, [1024, False]],
]
可以看到,Neck部分的组件相较于Backbone较为单一,基本上就由CBS、Upsample、Concat和不带shortcut的CSP(C3)。
FPN与PAN

另外,Neck的网络结构设计也是沿用了FPN+PAN的结构。FPN就是使用一种 自顶向下的侧边连接在所有尺度上构建出高级语义特征图,构造了特征金字塔的经典结构,也就是上图中的a,具体细节可以参考我之前的文章:FPN网络结构+源码讲解;PAN的结构也不稀奇,FPN中间经过多层的网络后,底层的目标信息已经非常模糊了,因此PAN又加入了自底向上的路线,弥补并加强了定位信息,也就是上图中的b。贴一下FPN和PAN原文:
FPN: Feature Pyramid Networks for Object Detection
PAN: Path Aggregation Network for Instance Segmentation
2 Neck部件模块
2.1 CBS
在Backbone中,为了进一步提取图像中的信息,CBS在改变特征图通道的同时,也会控制卷积模块中的步长s下采样来改变特征图的尺寸。Neck中左侧采用FPN自顶向下设计的过程中,是特征图上采样的过程,因此这个时候再下采样就不合时宜了,所以在FPN中s=1;而到了右侧PAN再次自下而上提取位置信息时,就需要使用CBS继续下采样抽取高层次的语义信息,这也是CBS前后参数差异的原因。具体的CBS结构可以参考上篇文章:YOLOv5的Backbone详解,这里不再赘述。
2.2 nn.Upsample
[-1, 1, nn.Upsample, [None, 2, 'nearest']]
Pytroch内置的上采样模块,需要指定上采样的倍数和方式。

这里我们不指定size,上采样倍数为2,上采样方式为nearest,也就是最近填充。
2.3 Concat
[[-1, 6], 1, Concat, [1]],
Concat即拼接,接对象通过from传入,拼接的维度由args参数指定,此处即按照维度1(channel)拼接,其他维度不变。至于from中的特征图到底是哪一个,我建议大家运行模型将各层特征图打印出来,如:

通过上图就很容易确定concat的两个对象了,当然,我在文章最开始的时候已经给大家画出来网络结构,大家按图索骥也可以找到。
class Concat(nn.Module):
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
2.4 CSP/C3
Backbone需要更深层次的网络获取更多的信息,可以说backbone已经完成了主要特征信息的提取,所以在Neck阶段我们并不需要再一味地加深网络,采取不带残差的C3模块可能会更合适一些。

具体的模块结构及源码参考backbone中的介绍。
neck端的主要内容大体就是以上了。
OVER
Original: https://blog.csdn.net/weixin_43427721/article/details/123653669
Author: Marlowee
Title: YOLOv5的Neck端设计