
专栏地址:『youcans 的 OpenCV 例程300篇 - 总目录』
01. 图像的读取(cv2.imread)
02. 图像的保存(cv2.imwrite)
03. 图像的显示(cv2.imshow)
04. 用 matplotlib 显示图像(plt.imshow)
【OpenCV 例程300篇】001. 图像的读取(cv2.imread)
函数 cv2.imread() 用于从指定的文件读取图像。
函数说明:
retval = cv.imread(filename[, flags])
- 函数 cv2.imread() 从指定文件加载图像并返回该图像的矩阵。
- 如果无法读取图像(文件丢失,权限不正确,格式不支持或无效),该函数返回一个空矩阵。
- 目前支持的文件格式:
- Windows 位图 - * .bmp,* .dib
- JPEG 文件 - * .jpeg, .jpg,.jpe
- JPEG 2000文件 - * .jp2
- 便携式网络图形 - * .png
- WebP - * .webp
- 便携式图像格式 - * .pbm, .pgm, .ppm * .pxm,* .pnm
- TIFF 文件 - * .tiff,* .tif
参数说明:
- filename:读取图像的文件路径和文件名
- flags:读取图片的方式,可选项
- cv2.IMREAD_COLOR(1):始终将图像转换为 3 通道BGR彩色图像,默认方式
- cv2.IMREAD_GRAYSCALE(0):始终将图像转换为单通道灰度图像
- cv2.IMREAD_UNCHANGED(-1):按原样返回加载的图像(使用Alpha通道)
- cv2.IMREAD_ANYDEPTH(2):在输入具有相应深度时返回16位/ 32位图像,否则将其转换为8位
- cv2.IMREAD_ANYCOLOR(4):以任何可能的颜色格式读取图像
- 返回值 retval:读取的 OpenCV 图像,nparray 多维数组
注意事项:
- OpenCV 读取图像文件,返回值是一个nparray 多维数组。OpenCV 对图像的任何操作,本质上就是对 Numpy 多维数组的运算。
- OpenCV 中彩色图像使用 BGR 格式,而 PIL、PyQt、matplotlib 等库使用的是 RGB 格式。
- cv2.imread() 如果无法从指定文件读取图像,并不会报错,而是数返回一个空矩阵。
- cv2.imread() 指定图片的存储路径和文件名,在 python3 中不支持中文和空格(但并不会报错)。必须使用中文时,可以使用 cv2.imdecode() 处理,参见扩展例程。
- cv2.imread() 读取图像时默认忽略透明通道,但可以使用 CV_LOAD_IMAGE_UNCHANGED 参数读取透明通道。
- 对于彩色图像,可以使用 flags=0 按照读取为灰度图像。
基本例程:
imgFile = "../images/imgLena.tif"
img1 = cv2.imread(imgFile, flags=1)
img2 = cv2.imread(imgFile, flags=0)
扩展例程:
import urllib.request as request
response = request.urlopen("https://profile.csdnimg.cn/8/E/F/0_youcans")
imgUrl = cv2.imdecode(np.array(bytearray(response.read()), dtype=np.uint8), -1)
imgFile = "../images/测试图01.png"
img = cv2.imdecode(np.fromfile(imgFile, dtype=np.uint8), -1)

(本节完)
版权声明:
youcans@xupt 原创作品,转载必须标注原文链接:(https://blog.csdn.net/youcans/article/details/121168935)
Copyright 2022 youcans, XUPT
Crated:2021-11-18
更多内容请见:>『youcans 的 OpenCV 例程300篇 - 总目录』 (https://blog.csdn.net/youcans/article/details/125112487)Original: https://blog.csdn.net/youcans/article/details/121168935
Author: YouCans
Title: 【OpenCV 例程300篇】01. 图像的读取(cv2.imread)
相关阅读1
Title: seldom 2.0 让接口自动化测试更简单
前言
HTTP接口测试很简单,不管工具、框架、还是平台,只要很的好的几个点就是好工具。
- 测试数据问题:比如删除接口,重复执行还能保持结果一致,必定要做数据初始化。
- 接口依赖问题:B接口依赖A的返回值,C接口依赖B接口的返回值。
- 加密问题:不同的接口加密规则不一样。有些用到时间戳、md5、base64、AES,如何提供种能力。
- 断言问题:有些接口返回的结构体很复杂,如何灵活的做到断言。
对于以上问题,工具和平台要么不支持,要么很麻烦,然而框架是最灵活的。
unittest/pytest + requests/https 直接上手写代码就好了,既简单又灵活。
那么同样是写代码,A框架需要10行,B框架只需要5行,然而又不失灵活性,那我当然是选择更少的了,毕竟,人生苦短嘛。
seldom适合个人接口自动化项目,它有以下优势。
- 可以写更少的代码
- 自动生成HTML/XML测试报告
- 支持参数化,减少重复的代码
- 支持生成随机数据
- 支持har文件转case
- 支持数据库操作
这些是seldom支持的功能,我们只需要集成HTTP接口库,并提供强大的断言即可。 seldom 2.0 加入了HTTP接口自动化测试支持。
Seldom 兼容 Requests API 如下:
seldom requests self.get() requests.get() self.post() requests.post() self.put() requests.put() self.delete() requests.delete()
Seldom VS Request+unittest
先来看看unittest + requests是如何来做接口自动化的:
import unittest
import requests
class TestAPI(unittest.TestCase):
def test_get_method(self):
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
self.assertEqual(r.status_code, 200)
if __name__ == '__main__':
unittest.main()
这其实已经非常简洁了。同样的用例,用seldom实现。
# test_req.py
import seldom
class TestAPI(seldom.TestCase):
def test_get_method(self):
payload = {'key1': 'value1', 'key2': 'value2'}
self.get("http://httpbin.org/get", params=payload)
self.assertStatusCode(200)
if __name__ == '__main__':
seldom.main()
主要简化点在,接口的返回数据的处理。当然,seldom真正的优势在断言、日志和报告。
har to case
对于不熟悉 Requests 库的人来说,通过Seldom来写接口测试用例还是会有一点难度。于是,seldom提供了 har 文件转 case 的命令。
首先,打开fiddler 工具进行抓包,选中某一个请求。
然后,选择菜单栏: file -> Export Sessions -> Selected Sessions...
选择导出的文件格式。
点击 next 保存为 demo.har 文件。
最后,通过 seldom -h2c 转为 demo.py 脚本文件。
> seldom -h2c .\demo.har
.\demo.py
2021-06-14 18:05:50 [INFO] Start to generate testcase.
2021-06-14 18:05:50 [INFO] created file: D:\.\demo.py
demo.py 文件。
import seldom
class TestRequest(seldom.TestCase):
def start(self):
self.url = "http://httpbin.org/post"
def test_case(self):
headers = {"User-Agent": "python-requests/2.25.0", "Accept-Encoding": "gzip, deflate", "Accept": "application/json", "Connection": "keep-alive", "Host": "httpbin.org", "Content-Length": "36", "Origin": "http://httpbin.org", "Content-Type": "application/json", "Cookie": "lang=zh"}
cookies = {"lang": "zh"}
self.post(self.url, json={"key1": "value1", "key2": "value2"}, headers=headers, cookies=cookies)
self.assertStatusCode(200)
if __name__ == '__main__':
seldom.main()
运行测试
打开debug模式 seldom.run(debug=True) 运行上面的用例。
> python .\test_req.py
2021-04-29 18:19:39 [INFO] A run the test in debug mode without generating HTML report!
2021-04-29 18:19:39 [INFO]
__ __
________ / /___/ /___ ____ ____
/ ___/ _ \/ / __ / __ \/ __ ` ___/
(__ ) __/ / /_/ / /_/ / / / / / /
/____/\___/_/\__,_/\____/_/ /_/ /_/
url: http://httpbin.org/get method: GET
Ran 1 test in 0.619s
OK
通过日志/报告都可以清楚的看到。
- 请求的方法
- 请求url
- 响应的类型
- 响应的数据
更强大的断言
断言接口返回的数据是我们在做接口自动化很重要的工作。
assertJSON
接口返回结果如下:
{
"args": {
"hobby": [
"basketball",
"swim"
],
"name": "tom"
}
}
我的目标是断言 name 和 hobby 部分的内容。seldom可以针对 JSON文件进行断言。
import seldom
class TestAPI(seldom.TestCase):
def test_assert_json(self):
payload = {'name': 'tom', 'hobby': ['basketball', 'swim']}
self.get("http://httpbin.org/get", params=payload)
assert_json = {'args': {'hobby': ['swim', 'basketball'], 'name': 'tom'}}
self.assertJSON(assert_json)
运行日志
test_get_method (test_req.TestAPI) ...
type: json
{'args': {'hobby': ['basketball', 'swim'], 'name': 'tom'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.22.0', 'X-Amzn-Trace-Id': 'Root=1-608a896d-48fac4f6139912ba01d2626f'}, 'origin': '183.178.27.36', 'url': 'http://httpbin.org/get?name=tom&hobby=basketball&hobby=swim'}
💡 Assert data has not key: headers
💡 Assert data has not key: origin
💡 Assert data has not key: url
ok
> Original: https://www.cnblogs.com/fnng/p/14887574.html
> Author: 虫师
> Title: seldom 2.0 让接口自动化测试更简单
## **相关阅读2**
## Title: NET框架下如何使用PaddleOCRSharp

打开VSIDE,新建Windows窗体应用(.NET Framework)类型的项目,选择一个.NET框架,如.NET Framework 4.0,右键点击项目,选择属性》生成,目标平台设置成X64.

菜单》工具》选项,Nuget包管理器》程序包管理,默认包管理格式切换为:
**PackageReferene**格式, **此设置可以在安装包以后,自动复制相关的依赖文件到输出目录**。

安装nuget包
**方法一:**
菜单》视图》其他窗口》程序包管理器控制台:
Install-Package PaddleOCRSharp -Version 1.2.2
回车,等待安装nuget包完成
**方法二:**
命令行:
cd /d xxx.csproj文件全路径
dotnet add package PaddleOCRSharp --version 1.2.2
**方法三:**
项目文件.csproj中直接添加
添加
"PaddleOCRSharp" Version="1.2.2" />
**方法四:**
项目名称右键点击》管理nuget程序包,在浏览界面,搜索"PaddleOCRSharp"选择版本点击【安装】

在窗体界面添加一个按钮,在按钮的事件中添加net示例代码,F5运行,打开一个本地图片进行识别。
```csharp;gutter:true;
OpenFileDialog ofd = new OpenFileDialog();
ofd.Filter = "*.*|*.bmp;*.jpg;*.jpeg;*.tiff;*.tiff;*.png";
if (ofd.ShowDialog() != DialogResult.OK) return;
var imagebyte = File.ReadAllBytes(ofd.FileName);
Bitmap bitmap = new Bitmap(new MemoryStream(imagebyte));
OCRModelConfig config = null;
OCRParameter oCRParameter = new OCRParameter ();
//oCRParameter.use_gpu=1;当使用GPU版本的预测库时,该参数打开才有效果
OCRResult ocrResult = new OCRResult();
using (PaddleOCREngine engine = new PaddleOCREngine(config, oCRParameter))
{
ocrResult = engine.DetectText(bitmap );
}
if (ocrResult != null)
{
MessageBox.Show(ocrResult.Text,"识别结果");
}

微信公众号

Original: https://www.cnblogs.com/raoyutian/p/15912470.html
Author: 明月心技术学堂
Title: NET框架下如何使用PaddleOCRSharp
相关阅读3
Title: 语音识别原理与应用 洪青阳 第一章 概论
目录
第一章 语音识别概论
语音识别的基础理论包括 语音的产生和感知过程、语音信号基础知识、语音特征提取等。
关键技术包括高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔科夫模型(Hidden Markov Model,HMM)、深度神经网络(Deep Neural Network,DNN),以及基于这些模型形成的 GMM-HMM、DNN-HMM 和 端到端(End-to-End,E2E)系统。语言模型和 解码器 也非常关键,直接影响语音识别实际应用的效果。
1.1 语音的产生和感知
人的 发音器官包括 肺、气管、声带、喉、咽、鼻腔、口腔、和唇。
肺部产生的气流冲击声带,产生振动。
声带每开启和闭合一次的时间是一个 基音周期(Pitch period)T,其倒数为 基音频率(F0=1/T, 基频),范围在70HZ---450HZ。基频越高,声音越尖细。基频随时间的变化,也反映了声调的变化。
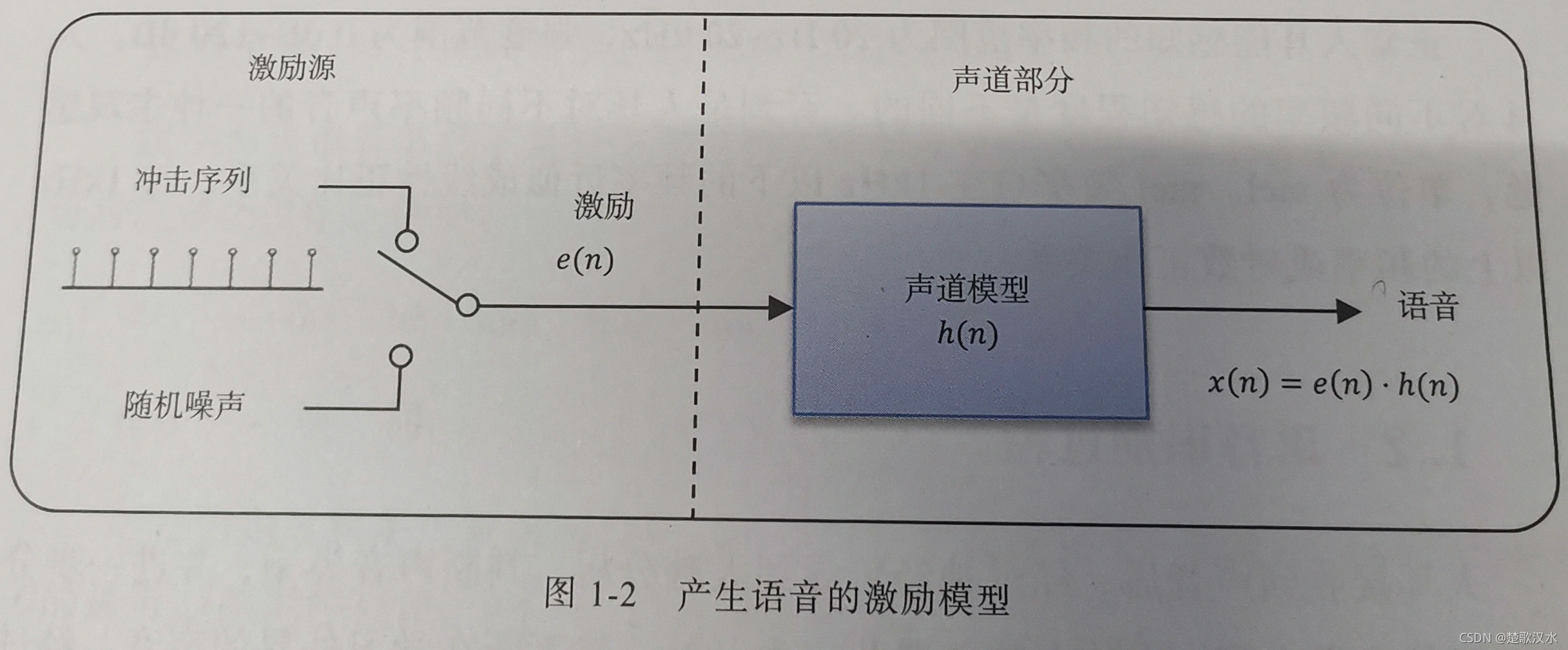
语音的产生过程可进一步抽象成如上图所示的激励的模型。包括 激励源和声道部分。在激励源部分, 冲击序列发生器以基音周期产生周期性信号,经过声带振动, 相当于经过 声门波模型,肺部气流大小相当于振幅; 随机噪声发生器产生非周期性信号。 声道模型模拟口腔、鼻腔等声道器官,最后产生语音信号。我们要发浊音时,声带振动形成准周期的冲击序列。发清音时,声带松弛,相当于发出一个随机噪声。
1.2 语音识别过程
音素(phone)是构成语音的最小单位。英语中有48个音素(20个元音和28个辅音)。
若采用元音和辅音来分类,汉语普通话有32个音素,包括元音10个,辅音22个。 但普通话的韵母多是复韵母,不是简单的元音,因此 拼音一般分为声母(initial)和韵母(final)。
音节(syllable)是听觉能感受到的最自然的语音单位,由一个或多个音素按一定的规律组合而成。英语音节可由一个元音或元音和辅音构成。汉语的音节由声母、韵母和音调构成,其中音调信息包括在韵母中。所以,汉语音节结构可以简化为:声母+韵母。
注:音素(序列)组成音节(序列),从而识别出文字。
汉字与汉语音节并不是一一对应的。一个汉字可以对应多个音节,一个音节可对应多个汉字。
例如:
和 ----- he二声 he四声 huo二声 huo四声 hu二声
tian二声 ----- 填 甜
语音识别过程是个复杂的过程,但其最终任务归结为,找到对应 观测值序列O的最可能的 词序列W'。按贝叶斯准则转化为:
W' = arg max P(W|O) = arg max(P(O|W)P(W))/(P(O))
W' = arg max P(O|W)P(W)
其中,P(O)与P(W)没有关系,可认为是常量,因此P(W|O)的最大值可转换为P(O|W)和P(W)两项乘积的最大值,第一项P(O|W)由声学模型决定,第二项P(W)由语言模型决定。
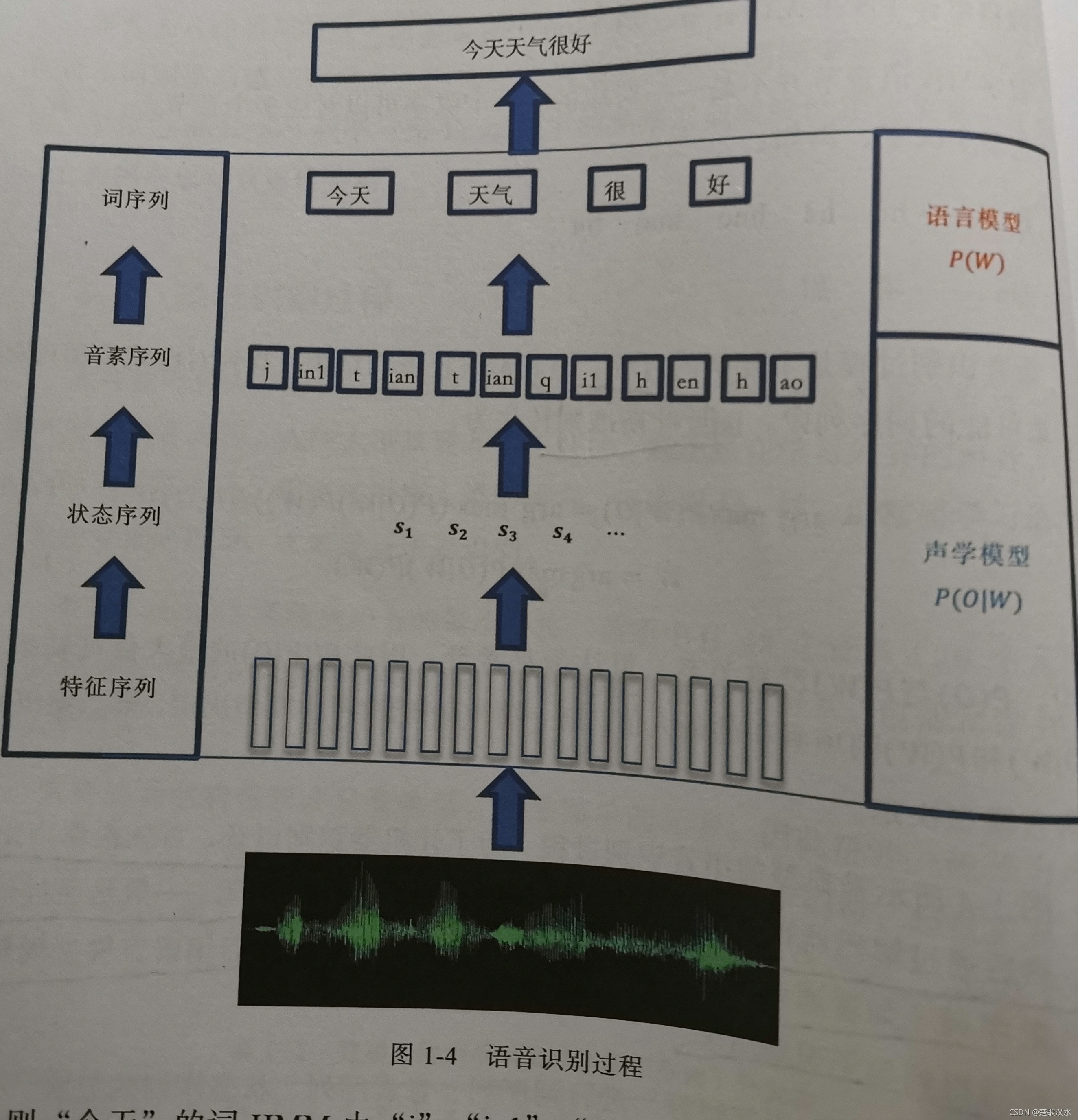
上图是典型的语音识别过程。为了让机器识别语音,首先提取声学特征,然后通过解码器得到状态序列,并转换为对应的识别单元。一般是通过词典将音素序列(如普通话的声母和韵母),转换为词序列,然后用语言模型规整约束,最后得到句子识别结果。

如上图所示,对"今天天气很好"进行词序列、因素序列、状态序列的分解,并和观测值序列对应,其中每个音素对应一个HMM,并且其发射状态(深色)对应多帧观测值。
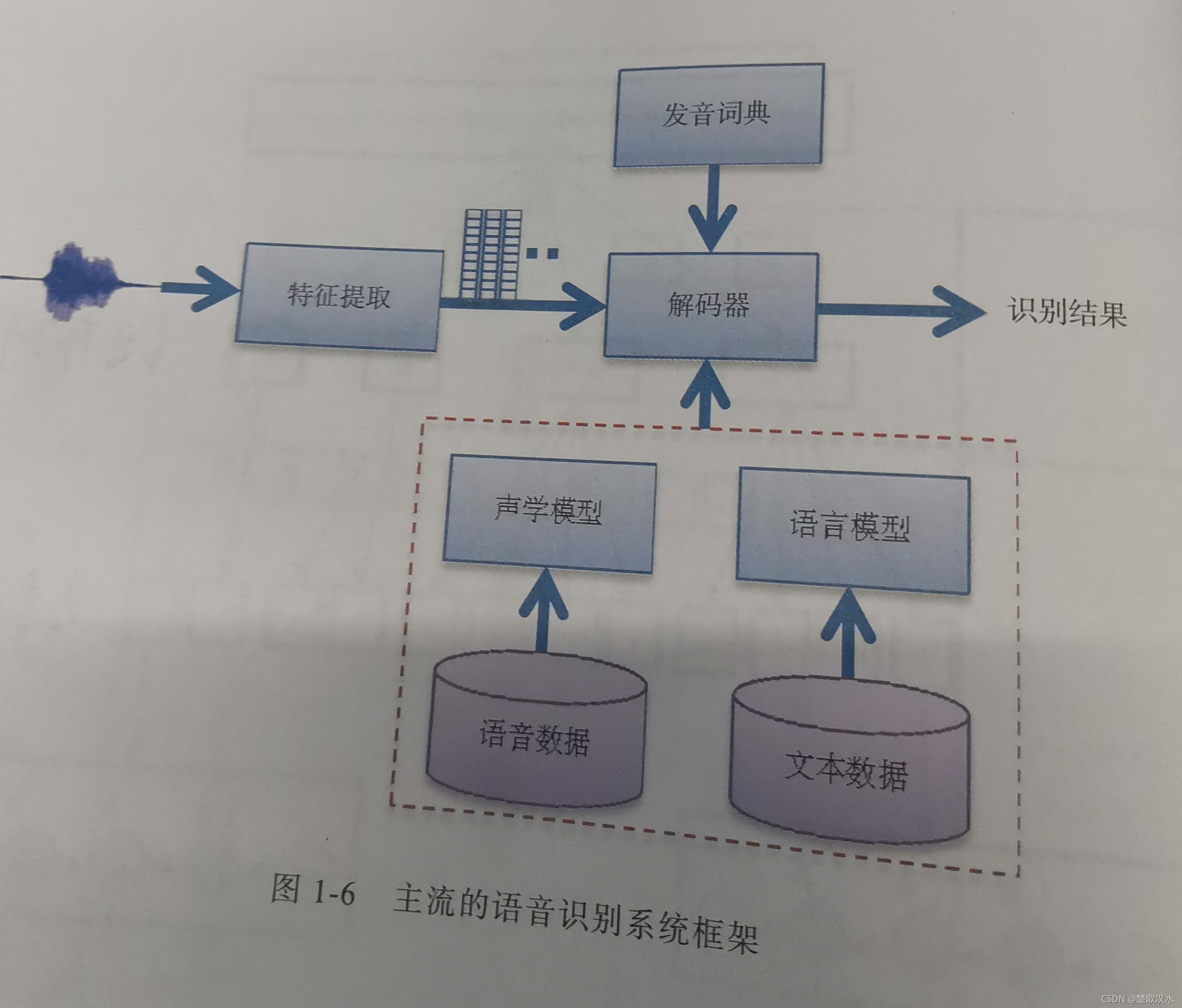
现在工业应用普遍要求 大词汇量连续语音识别(LVCSR)。
1.3语音识别发展历史
解决任务: 孤立词识别 → 大规模连续语音识别 → 复杂场景识别
技术发展: 模板匹配(DTW) → 统计模型(GMM-HMM) → 深度学习(DNN-HMM,E2E)
DTW(Dynamic Time Warping)动态时间规整:使用动态规划算法将两段不同长度的语音在时间轴上进行了对齐。该算法把时间规整和距离的计算有机地结合起来,解决了不同时长语音的匹配问题。在一些要求资源占用率低、识别人比较特定的环境下,DTW是一种很经典很常用的模板匹配算法。
统计模型两项很重要的成果是 声学模型和 语言模型,语言模型以 n元语言模型(n-gram)为代表,声学模型则以 HMM为代表。
GMM-HMM:(1)用HMM对语音状态的转移概率建模;(2)用 高斯混合模型(Gaussian Mixture Model,GMM)对语音状态的观测值概率建模。
HTK(Hidden Markov Tool Kit)是一款开源的基于HMM的语音识别工具包。
Ka1di,是DNN-HMM系统的基石,在工业界得到广泛应用。
大多数主流的语音识别解码器基于 加权有限状态转换器(WFST),把发音词典、声学模型和语言模型编译成静态解码网络,这样可大大加快解码速度,为语音识别的实时应用奠定基础。
RNN可更有效、更充分地利用语音中的上下文信息。引入LSTM或其变体以解决梯度消失的问题。
CNN可通过共享权值来减少计算的复杂度,并且CNN被证明在挖掘语音局部信息的能力上更为突出。
Attention模型的对齐关系没有先后顺序的限制,完全靠数据驱动得到,对齐的盲目性会导致训练和解码时间过长。而CTC的前向后向算法可以引导输出序列和输入序列按时间顺序对齐。
Transformer架构:在 Decoder和Encoder中均采用Attention机制。
Original: https://blog.csdn.net/hnlg311709000526/article/details/120912777
Author: 楚歌汉水
Title: 语音识别原理与应用 洪青阳 第一章 概论