
1. 什么是RGB-Ir?
首先解释下:RGB是颜色模式,分别代表Red, Green, Blue,是最广泛应用的色彩模式。
IR是Infrared,即红外线,其波长(约760nm~1mm)比红光长,是不可见光。
在光线比较暗的情况下,使用IR摄像头增强现实效果。
传统的COMS图像传感器采用Bayer格式作为色彩滤波阵列(CFA, Color Filter Array),像素点的色彩信息根据特定波长的光来确定。
RGB-Ir技术使用RGB-Ir CFA,基于Bayer格式,修改部分像素点为IR像素点,而IR像素点只允许红外光通过。
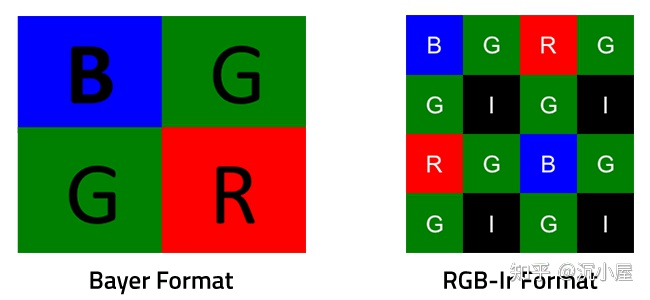
使用RGB-Ir技术可以通过一个传感器设备同时捕捉到RGB彩图和IR图,
也就是同时拥有白天和夜间的可视能力 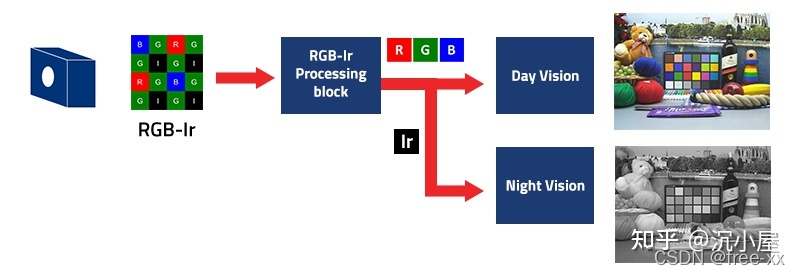
ISP's side
需要从RGB-Ir格式的图像中分别提取出RGB和IR信息,并生成对应的RGB图和IR图。
具体算法不做描述了,可根据具体传感器的数据手册开发。
- 支持RGB-IR技术的sensor厂
三大image sensor厂家sony、OV和ON中,
OV首先推出了RGB-IR技术的产品,比较经典的代表如OV2778,另外还有多款其他的产品;
ON也推出了AR0237;
SONY则先是研究了类似的技术RGBW,但后来又将RGBW的称谓改回RGB,
不知道是不是现在的RGB就已经是RGBW,还是说SONY发现RGBW技术有什么缺陷。
3 .RGB-IR技术目的
RGB-IR技术最初引入是为了解决监控相机应用中白天和黑夜两种模式切换的问题,
引入了机械控制的IR-CUT解决RGB模式下红外光干扰的问题,但IR-CUT容易损坏。
RGB-IR技术直接通过一颗sensor获取RGB图像和IR图像,彻底解决了IR-CUT的问题。
然而事实是,RGB-IR技术并没有想象中的那样普及!!
有可能是AP端没有支持,这样也有可能是没法普及的因素
Original: https://blog.csdn.net/jzwjzw19900922/article/details/123481376
Author: free-xx
Title: RGB-IR技术
相关阅读1
Title: Pascal VOC数据集介绍,内网环境下在上运行TFA代码(Frustratingly Simple Few-Shot Object Detection)
(转载)记录ubuntu16.04安装torch0.4+torchvision0.2 (pip方法,python2.7)。其中torchvision中有的包安装不成功,可以从报错日志中找到下载链接,然后通过第三方离线安装包的方式安装。
https://blog.csdn.net/qq_45577581/article/details/108032792
有两种加速训练的方法:半精度和图像先从硬盘放到内存中
Pascal voc介绍

VOC07一共有9963张图片,由train/val/test三部分组成。
- 其中VOCtrainval有5011张,其中train2501张,val2510张,图像共标注24,640个对象,每张图片可能有多个对象被标注,每张图片大约是2.4个对象,
- VOCtest有4952张,(test的标注信息也提供了)ImageSets-Main有21个文件。有一个test.txt,20个xx_test.txt。
Pascal voc2012
总共11540张图片,其中5717张训练集和5823张验证集,收集了08-11年的图片,不与VOC07有重合图片。
20类分为15个基类和5个新类,采取了三种随机划分(但是为了方便模型的性能对比,实际三种划分的类别分布是固定的),分别为split1,split2,split3。对三种划分之后采用的方式方法完全相同。这里,以split1为例子。split1的
novel1为["bird", "bus", "cow", "motorbike", "sofa"]。base1为 [ "aeroplane", "bicycle", "boat", "bottle", "car", "cat", "chair" "diningtable", "dog", "horse", "person", "pottedplant", "sheep", "train", "tvmonitor",],
第一步:
Datasets:
TRAIN: ('voc_2007_trainval_base1', 'voc_2012_trainval_base1')
TEST: ('voc_2007_test_base1',)
nohup python3 -m tools.train_net --num-gpus 2 \
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_base1.yaml \
> base1.log 2>&1 &
第二步:
–src1 的参数是由第一步产生的。使用随机最后的检测头参数(Box Classifier和Box Regressor)
python3 -m tools.ckpt_surgery \
--src1 checkpoints/voc/faster_rcnn/faster_rcnn_R_101_FPN_base1/model_final.pth \
--method randinit \
--save-dir checkpoints/voc/faster_rcnn/faster_rcnn_R_101_FPN_all1
第三步:
Datasets:
TRAIN: ('voc_2007_trainval_all1_1shot',)
TEST: ('voc_2007_test_all1',)
平衡的基类和新类数据集,20类都有参与微调,只需要指定07,程序会在07和12间自动加载。
指令中的 模型参数,来自上一步得到的,比如model_reset_surgery.pth就是上一步随机初始化得到的。
python3 -m tools.train_net --num-gpus 2 \
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_1shot.yaml \
--opts MODEL.WEIGHTS checkpoints/voc/faster_rcnn/faster_rcnn_R_101_FPN_all1/model_reset_surgery.pth
评估:
python3 -m tools.test_net --num-gpus 2 \
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_1shot.yaml \
--eval-only

多次运行:
python3 -m tools.run_experiments --num-gpus 2 \
--shots 1 2 3 5 10 --seeds 0 30 --split 1
python3 -m tools.aggregate_seeds --shots 3 --seeds 30 --split 1 \
--print --plot
====================================== 分割线 =============================================
1.本地机子搭建环境,使用conda pack命令迁移到服务器
2.数据集放置,VOC07+VOC12放在dataset下,voc07和voc12的train/val集合用于训练,voc07的test集合用于测试,要求的目录结构是(test貌似也是混合到一起吗?)
vocsplit需要生成,数据生成需要运行prepare_voc_few_shot.py去使用种子随机产生,代码里总共20组(包括最初的那一组),论文说是30组。

上图的文件则是使用内置函数自动生成,不需要手动生成。
3.base基类训练(ps:Detectron2会有联网操作,注意使用本地链接替代)
4.用tools/ckpt_surgery.py得到全模型的参数初始化,仅仅修改检测头的最后层,有两种方法,一个是随机初始化,一个是在新类上微调的
5.微调
整个训练流程
PASCAL VOC: Base training --> random initialization --> fine-tuning
COCO and LVIS: Base training --> novel weights initializaiton --> fine-tuning
1.先在基类上训练整个模型
python3 -m tools.train_net --num-gpus 8 \
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_base1.yaml
2.随机生成检测头的参数(还有另外一种方法,参见官方源码)
python3 -m tools.ckpt_surgery \
--src1 checkpoints/voc/faster_rcnn/faster_rcnn_R_101_FPN_base1/model_final.pth \
--method randinit \
--save-dir checkpoints/voc/faster_rcnn/faster_rcnn_R_101_FPN_all1
3.使用all全部类别(平衡的基类和新类)的1shot去微调
python3 -m tools.train_net --num-gpus 8 \
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_1shot.yaml \
--opts MODEL.WEIGHTS $WEIGHTS_PATH
最后验证:
python3 -m tools.test_net --num-gpus 8 \
--config-file configs/PascalVOC-detection/split1/faster_rcnn_R_101_FPN_ft_all1_1shot.yaml \
--eval-only
训练完成方可测试。
运行时ModuleNotFoundError: No module named 'fsdet'的解决方法:
https://blog.csdn.net/qq_33564045/article/details/116598663
FSCE中T-SNE的可视化代码https://github.com/MegviiDetection/FSCE/issues/3
在Universal-Prototype Enhancing for Few-Shot Object Detection中使用的就是两块GPU,在VOC数据集上只使用了10次随机种子
跟随的都是FSRW采样,
Original: https://blog.csdn.net/qq_36136196/article/details/122305253
Author: 暄染落墨
Title: Pascal VOC数据集介绍,内网环境下在上运行TFA代码(Frustratingly Simple Few-Shot Object Detection)
相关阅读2
Title: 基于python实现TF-IDF算法
标签:2021.09.27工作内容
参考资料:TF-IDF算法介绍及实现
声明:本文中大量内容转载至参考资料,仅归纳整理和加入部分个人观点心得,侵删
概念
- 定义
TF-IDF(term frequency-inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术,常用于挖掘文章中的关键词。 - 特点:简单高效,用于最开始的文本数据清洗。
- TF-IDF
(1)TF:词频
可以统计到停用词,并把它们过滤,避免对结果造成影响。
e.g.:"的"、"了"、"是"等等
(2)IDF:逆文档频率
在词的频率相同时,不同词的重要性却不同。IDF会给常见的词较小的权重。
e.g.:假设"量化"和"系统"的词频相同,则重要性:"量化" > "系统" - 实现方法
当有TF和IDF后,将其相乘,能够得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么它在文章中的重要性越高。
算法步骤
- 计算词频
词频 = 某个词在文章中出现的次数 / 文章的总次数 - 计算逆文档的频率
需要一个语料库(corpus)来模拟语言的使用环境。
逆文档频率 = log(语料库的文档总数 / (包含该词的文档数 + 1)) - 计算TF-IDF
TF-IDF= TF × IDF
与一个词在文档中出现的次数成正比。
与该词在整个语言中出现的次数成反比。
优缺点
- 优点
简单高效,容易理解。 - 缺点
(1)词频衡量此的重要性不够全面,有时重要的词出现得不多
(2)无法体现位置信息=>无法体现该词在上下文中的重要性=>用word2vec算法来支持
python实现TF-IDF算法
- 自己构建语料库
这个例子比较特殊,dataset既是语料库,可是我们要统计核心词的对象。
from collections import defaultdict
import math
import operator
"""
函数说明:创建数据样本
Returns:
dataset - 实验样本切分的词条
classVec - 类别标签向量
"""
def loadDataSet():
dataset = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'my'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1]
return dataset, classVec
"""
函数说明:特征选择TF-IDF算法
Parameters:
list_words:词列表
Returns:
dict_feature_select:特征选择词字典
"""
def feature_select(dataset):
doc_frequency = defaultdict(int)
for file in dataset:
for word in file:
doc_frequency[word] += 1
word_tf = {}
for i in doc_frequency:
word_tf[i] = doc_frequency[i] / sum(doc_frequency.values())
doc_num = len(dataset)
word_idf = {}
word_doc = defaultdict(int)
for word in doc_frequency:
for file in dataset:
if word in file:
word_doc[word] += 1
for word in doc_frequency:
word_idf[word] = math.log(doc_num / (word_doc[word] + 1))
word_tf_idf = {}
for word in doc_frequency:
word_tf_idf[word] = word_tf[word] * word_idf[word]
dict_feature_select = sorted(word_tf_idf.items(), key=operator.itemgetter(1), reverse=True)
return dict_feature_select
if __name__ == '__main__':
data_list, label_list = loadDataSet()
features = feature_select(data_list)
print(features)
运算结果:

2. NLTK实现TF-IDF算法
由于我的电脑安装了本地代理所以不能下载nltk的语料库,这里只贴代码供大家参考
from nltk.text import TextCollection
from nltk.tokenize import word_tokenize
sents=['this is sentence one','this is sentence two','this is sentence three']
sents=[word_tokenize(sent) for sent in sents]
print(sents)
corpus=TextCollection(sents)
print(corpus)
tf=corpus.tf('one',corpus)
print(tf)
idf=corpus.idf('one')
print(idf)
tf_idf=corpus.tf_idf('one',corpus)
print(tf_idf)
- 利用sklearn做tf-idf
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train = ['TF-IDF 主要 思想 是', '算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test = ['原始 文本 进行 标记', '主要 思想']
vectorizer = CountVectorizer(max_features=10)
tf_idf_transformer = TfidfTransformer()
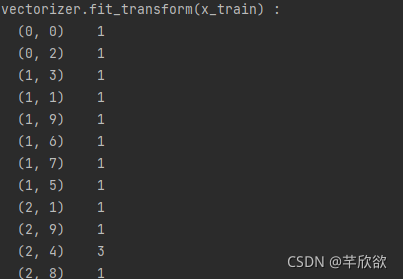
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
x_train_weight = tf_idf.toarray()
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray()
print('vectorizer.fit_transform(x_train) : ')
print(vectorizer.fit_transform(x_train))
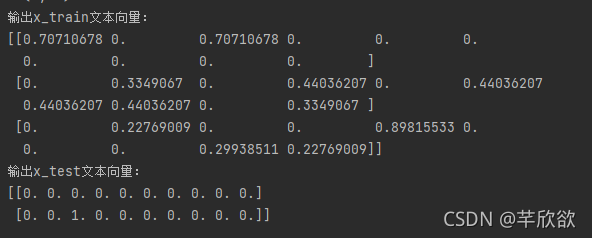
print('输出x_train文本向量:')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
4. 利用Jieba实现tf-idf
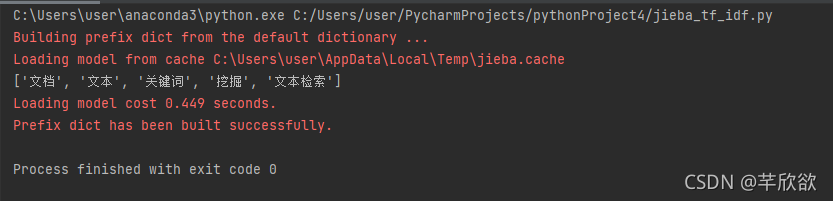
import jieba.analyse
text='关键词是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、
信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、
文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作'
keywords=jieba.analyse.extract_tags(text, topK=5, withWeight=False, allowPOS=())
print(keywords)
注:
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence 为待提取的文本
topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
withWeight 为是否一并返回关键词权重值,默认值为 False
allowPOS 仅包括指定词性的词,默认值为空,即不筛选
运行结果:
(安装不了就pip install jieba; conda install jieba; pip3 install jieba;都尝试一边,我用pip3安装才成功的,如果还不成功可以去jieba官网手动下载后自行配置到anaconda环境)
Original: https://blog.csdn.net/Daisy_Wang777/article/details/120510366
Author: 芊欣欲
Title: 基于python实现TF-IDF算法
相关阅读3
Title: 安装Keras,tensorflow,并将虚拟环境添加到jupyter notebook
写在面前:
最近需要用LSTM,今天开始搭环境,遇到了很多问题,其中主要是两个问题,不太懂装环境的朋友可以注意一下:
1、tensorflow和keras以及numpy等等版本的兼容问题。一般的keras安装教程tensorflow和keras版本都是兼容的,但是自己还得去装numpy,一不小心版本就不兼容了,所以我的每一步安装都规定了版本,防止不兼容问题;
2、因为用不惯pycharm,所以keras安装好了我想用jupyter打开,结果遇到了各种问题。例如无法识别jupyter notebook这个命令等等。所以我索性改变思路,先把虚拟环境加入到jupyter中,然后再在虚拟环境里面装包。
以下是我安装的全过程,都是用的清华园镜像,网速好两三分钟就能全部装好!
——————————————————————————————————————————
第一步:创建虚拟环境(tf3是我的虚拟环境的名称,你可以自己取)
conda create -n tf3 python=3.6.5
第二步:安装 ipykernel
pip install ipykernel -i https://pypi.tuna.tsinghua.edu.cn/simple/
第三步:把新建的虚拟环境(tf3)加入到jupter notebook里面
python -m ipykernel install --name tf3
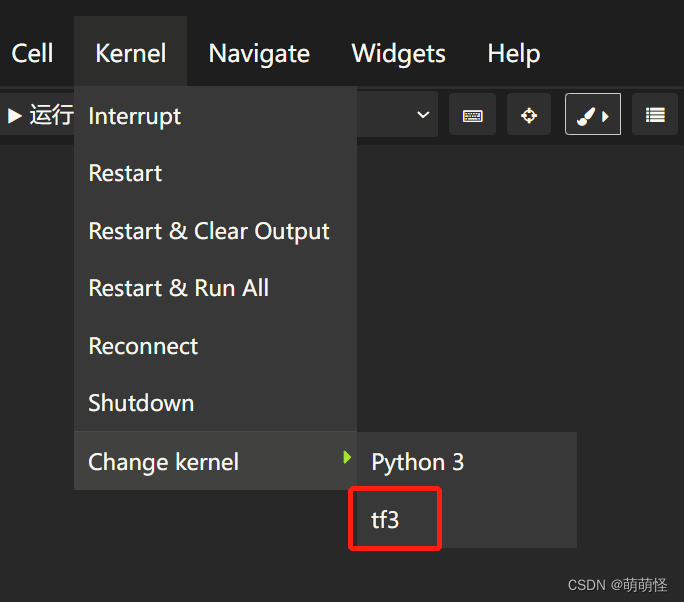
截至这里,虚拟环境就加入到jupter notebook里面了,接下来往虚拟环境装tensorflow和keras
第一步:首先要进入到新建的虚拟环境
conda activate tf3
第二步:安装tensorflow
pip install tensorflow==2.3.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第三步:安装keras
pip install keras==2.4.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第四步:安装numpy
pip install numpy==1.19.5 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第五步:安装pandas
pip install pandas==1.1.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第六步:安装scikit-learn
pip install scikit-learn==0.24.1 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第七步:安装scipy
pip install scipy==1.5.4 -i https://pypi.tuna.tsinghua.edu.cn/simple/
第八步:安装matplotlib
pip install matplotlib==3.3.3 -i https://pypi.tuna.tsinghua.edu.cn/simple/
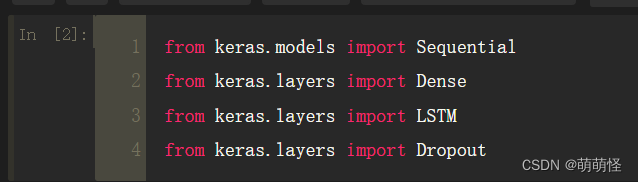
最后在jupyter notebook里面引入相关库,没报错就说明ok了
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from keras.layers import Dropout
Original: https://blog.csdn.net/qq_42183184/article/details/125622442
Author: 萌萌怪
Title: 安装Keras,tensorflow,并将虚拟环境添加到jupyter notebook