
目录
前言
注意:不讲实现原理,也没有做UI,精度就玩玩的级别,记得打(尽量柔和的)光。
博主是一名机械设计制造及其自动化专业的学生,以前在车间上课时总需要挑选特定尺寸的毛坯作为被加工工件,奈何本人较懒,所以就有了码这么一个py文件出来助我偷懒的想法。

完整的文件(某U加速"学术资源"可以访问):
- https://github.com/Yjie0929/object-size-measurement-based-on-OpenCV.git
; 一、开发前准备
喜欢用Pycharm还是Anaconda或其它都可以,没有关系。
因为摄像头使用的只是普通的家用摄像头(某夕夕个位数包邮),所以在码程序之前需要准备一个尺寸精度较高(尽量高)的参照物来获取欧氏距离和真实长度的比率。
穷得只能3D打印的屑博主:10mm³,20mm³,30mm³

二、需要的库
from scipy.spatial.distance import euclidean
import numpy as np
import imutils
import time
import cv2
三、程序主体
3.0 mian()
if __name__ == '__main__':
camera_type = set_camera_type()
filter_area, reference_points = reference_processing()
rate = rate_calculation()
real_time_processing()
3.1设置被调用的摄像头类型
这段函数是为了方便程序能够在内置相机或外置相机之间来回切换工作。如果确定仅使用外置相机的情况下可以忽略这一步。
def set_camera_type():
while True:
try:
set_type = int(input('摄像头调用(输入数字代号:0.内置,1.外置):'))
except ValueError:
delay('输入参数类型错误')
continue
else:
if (set_type < 0) or (set_type > 1):
delay('输出参数不在范围内')
continue
elif set_type == 0:
print('选择:内置摄像头')
else:
print('选择:外置摄像头')
break
return set_type
3.2调用相机
如确认仅使用外置相机时将camera_type设置为'1',cv2.CAP_DSHOW为可选参数,在相机调用过程中出现不知名报错时试着加入。关于第二个if,是防止遇到窗口关闭了但又没有完全关闭的情况而导致的堵塞。
def call_camera():
camera = cv2.VideoCapture(camera_type, cv2.CAP_DSHOW)
if camera.isOpened() is False:
print('摄像头调用失败')
raise AssertionError
else:
while True:
frame = camera.read()[1]
image = cv2.flip(frame, 1, dst=None)
cv2.imshow('Camera', image)
if (cv2.waitKey(1) > -1) or (cv2.getWindowProperty('Camera', cv2.WND_PROP_VISIBLE) < 1.0):
cv2.destroyWindow('Camera')
break
return image
3.3图像处理(轮廓端点查找)
cv2.Canny中的min_val与max_val参数值的大小可以判断是否为边,且 值越小,拾取到的边缘信息就越多。
- cv2.findContours有2个返回值,分别是contours和hierarchy,前者是被检测到的轮廓信息,后者意义不明。
- imutils.grab_contours用来获取 cv2.findContours的contours,contours才是需要被用于计算的数据。
def get_points(image):
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gaussian_blur = cv2.GaussianBlur(gray_image, (5, 5), 0)
min_val, max_val = 50, 100
margin = cv2.Canny(gaussian_blur, min_val, max_val)
open_margin = cv2.dilate(margin, None, iterations=15)
contours = cv2.findContours(open_margin, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
points = imutils.grab_contours(contours)
return points
3.4边框绘制(数据计算)
这一部分程序的用处主要是绘制框架与数据计算。程序前期在对参照物对象拍照时需要绘制框架呈现出被选中的对像,在程序后期除了要绘制框架外,还要通过比率计算真实长度、面积,最后在绘制框架的同时把计算结果也显示出来。
def draw_frame(image, points, tag):
if tag == 0:
for point in points:
min_area = cv2.minAreaRect(point)
min_area_point = cv2.boxPoints(min_area)
int_point = [min_area_point.astype('int')]
cv2.drawContours(image, int_point, -1, (0, 0, 255), 1)
return min_area_point
else:
for point in points:
min_area = cv2.minAreaRect(point)
min_area_point = cv2.boxPoints(min_area)
left_point, right_point = min_area_point[0], min_area_point[1]
X = left_point[0] + int(abs(right_point[0] - left_point[0]) / 2)
Y = left_point[1] + int(abs(right_point[1] - left_point[1]) / 2)
int_point = [min_area_point.astype('int')]
cv2.drawContours(image, int_point, -1, (0, 0, 255), 1)
radius = (euclidean(left_point, right_point) / 2) / rate
area = int((3.1415926 * pow(radius, 2)))
cv2.putText(image, '{}'.format(area), (int(X), int(Y)), cv2.FONT_HERSHEY_SIMPLEX, 5, (0, 0, 255), 5)
我的检测对象一般以圆形为主,所以只需要取出最左、最右的两个点坐标就能够用于计算了
min_area_point = cv2.boxPoints(min_area)
left_point, right_point = min_area_point[0], min_area_point[1]
3.5比率计算
比率是参照物两点在度量空间内两点距离和真实距离的比值,本项目后期所有的计算尺寸均由欧氏距离比上比率得出。
def rate_calculation():
delay('计算比率')
left_point, right_point = reference_points[0], reference_points[1]
length_euclidean = euclidean(left_point, right_point)
while True:
try:
length_reference = int(input('输入参照物长度(mm):'))
except ValueError:
delay('输入参数类型错误')
continue
else:
if length_reference 0:
delay('参数不可小于或等于0')
continue
else:
break
rate = length_euclidean / length_reference
print('(参照物)欧氏长度:{}mm'.format(length_euclidean))
print('(参照物)实际长度:{}mm'.format(length_reference))
print('长度比率:{}'.format(rate))
return rate
3.6参照物选取(拍照)
在调试过程中有多次遇到过拍照后参照物 选取不正确,为了防止这一情况的出现就设置了while循环,只有在手动确认参照物被正常框选的情况下才能进入下一步。
值得关注的是selected_points 的筛选方式是采用了将筛选面积不断加一,直到只剩下参照物对象的方式,即len(selected_points) = 1。
def reference_processing():
circulation = True
while circulation:
image = call_camera()
points = get_points(image)
selected_points = []
filter_area = 1
while True:
[selected_points.append(i) for i in points if cv2.contourArea(i) > filter_area]
if len(selected_points) > 1:
selected_points.clear()
filter_area += 1
else:
break
reference_area_point = draw_frame(image, selected_points, 0)
while True:
cv2.imshow('reference', image)
if (cv2.waitKey(1) > -1) or (cv2.getWindowProperty('reference', cv2.WND_PROP_VISIBLE) < 1.0):
cv2.destroyWindow('reference')
break
while circulation:
try:
tag = str(input('是否是理想参照物(Y/N):'))
except ValueError:
delay('输入参数类型错误')
continue
else:
if (tag == 'Y') or (tag == 'y'):
circulation = False
break
elif (tag == 'N') or (tag == 'n'):
break
return filter_area, reference_area_point
3.7实时测量
这段就不多说了,和前面基本一样的原理。
def real_time_processing():
print('进入实时测量,按下回车键结束程序')
camera = cv2.VideoCapture(camera_type, cv2.CAP_DSHOW)
while True:
frame = camera.read()[1]
image = cv2.flip(frame, 1, dst=None)
points = get_points(image)
selected_points = []
[selected_points.append(i) for i in points if cv2.contourArea(i) > filter_area]
draw_frame(image, selected_points, 1)
cv2.imshow('Camera', image)
if (cv2.waitKey(1) > -1) or (cv2.getWindowProperty('Camera', cv2.WND_PROP_VISIBLE) < 1.0):
cv2.destroyWindow('Camera')
break
四、成果展示
参照物拍照:(指方为圆)
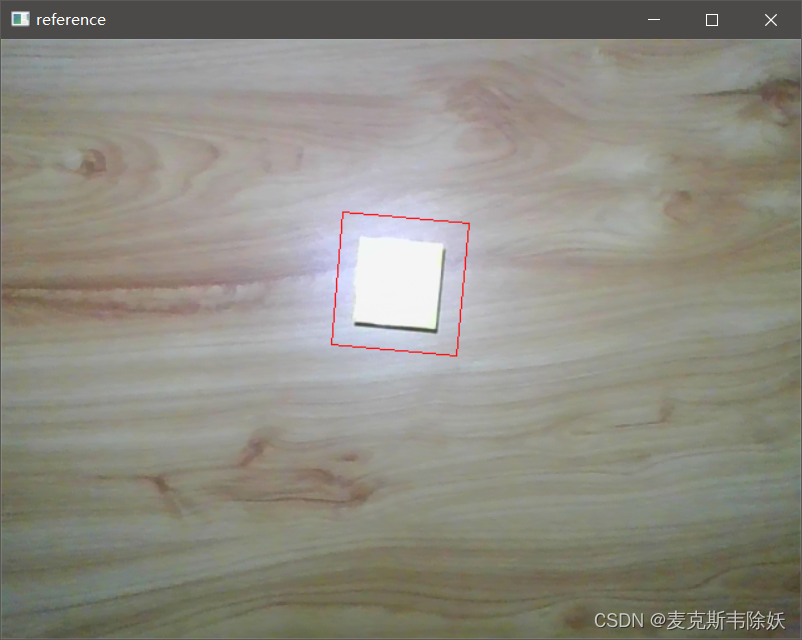
实时测量:(指方为圆),这里摄像头高度发生了变化,拍摄角度也出现误差,可以采用只存储最小值数据尽量保证精度。
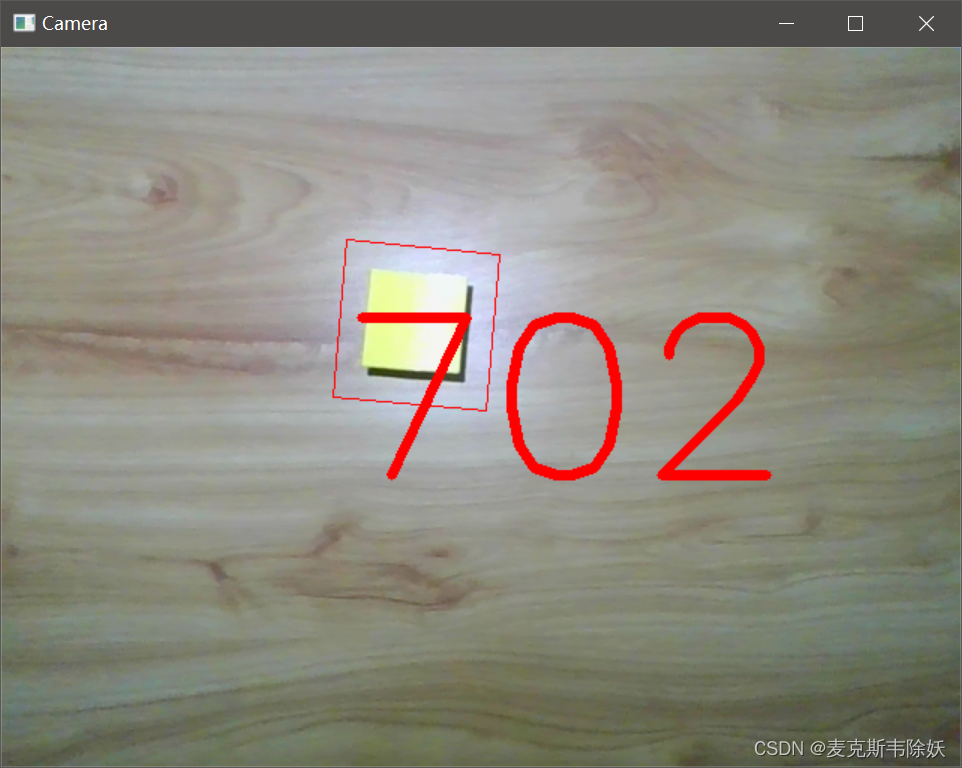
验证:(高度发生变化出现的误差为-4)
Original: https://blog.csdn.net/lyj3112424/article/details/122315162
Author: 麦克斯韦除妖
Title: 使用Python-OpenCV实时测量物体的尺寸大小(仅供参考)
相关阅读1
Title: 正确简单地安装Tensorflow和Keras
安装前注意:
- 这里只讨论tensorflow和keras的安装,如果你的电脑不支持CUDA、没有CUDA Toolkit、没有cuDNN这些基本的深度学习运算环境,那这篇文章可以关闭了。
- 安装tensorflow和keras不要直接复制官网的任何命令,因为大部分情况下都会装错。
- 安装一定要注意自己的cuda、python等环境的版本要对应,然后手动编写安装命令,不然全都错。
好了,言归正传,下面开始安装。
1、Tensorflow安装
首先明确好自己的Python、cuda版本,比如我是:
Python Version: 3.6.13
CUDA Version: 10.0
关于怎么查版本请自行百度
然后查询版本对照表:
linux/macOS版本对照表: https://www.tensorflow.org/install/source#gpu
windows版本对照表: https://www.tensorflow.org/install/source_windows#gpu

红框圈出来的表示都可以安在你的环境里,其他的版本安装都是错的。
比如现在我想安装tensorflow2.0的GPU版本。那我就可以在命令行输入:
pip install tensorflow-gpu==2.0.0
或者:我想安装tensorflow2.0的CPU版本。那我就可以在命令行输入:
pip install tensorflow==2.0.0
最后回车即可。
注意!!!
- 官网上说:tensorflow2 支持 CPU 和 GPU 的最新稳定版(适用于 Ubuntu 和 Windows),而对于 TensorFlow 1.x,CPU 和 GPU 软件包是分开的。这句话很有迷惑性,乍一看还以为是tensorflow2 把CPU 和 GPU 合并在一起了,其实不然,你要想使用gpu版本,还得在后面加个
-gpu。 - 如果pip命令拿不准可以去 https://pypi.org/ 搜索包的名字,搜索这个包及其历史版本的安装命令。如果是用conda: https://anaconda.org/anaconda/conda
2、Keras安装
keras安装之前需要TensorFlow、Theano、CNTK三个其中一个的环境,TensorFlow上面已经装好了,接下来只装keras即可。
和Tensorflow一样,安装Keras之前环境也必须对应,对照表如下:
- keras对照表:https://docs.floydhub.com/guides/environments/(网站已经关闭了,可以看国内的一些博客,如下)
- https://www.cnblogs.com/-yhwu/p/14619541.html(这篇博客很详细的搬运了keras环境对照表)
- 也可以去github上看,不过不是很详细:https://github.com/keras-team/keras#release-and-compatibility
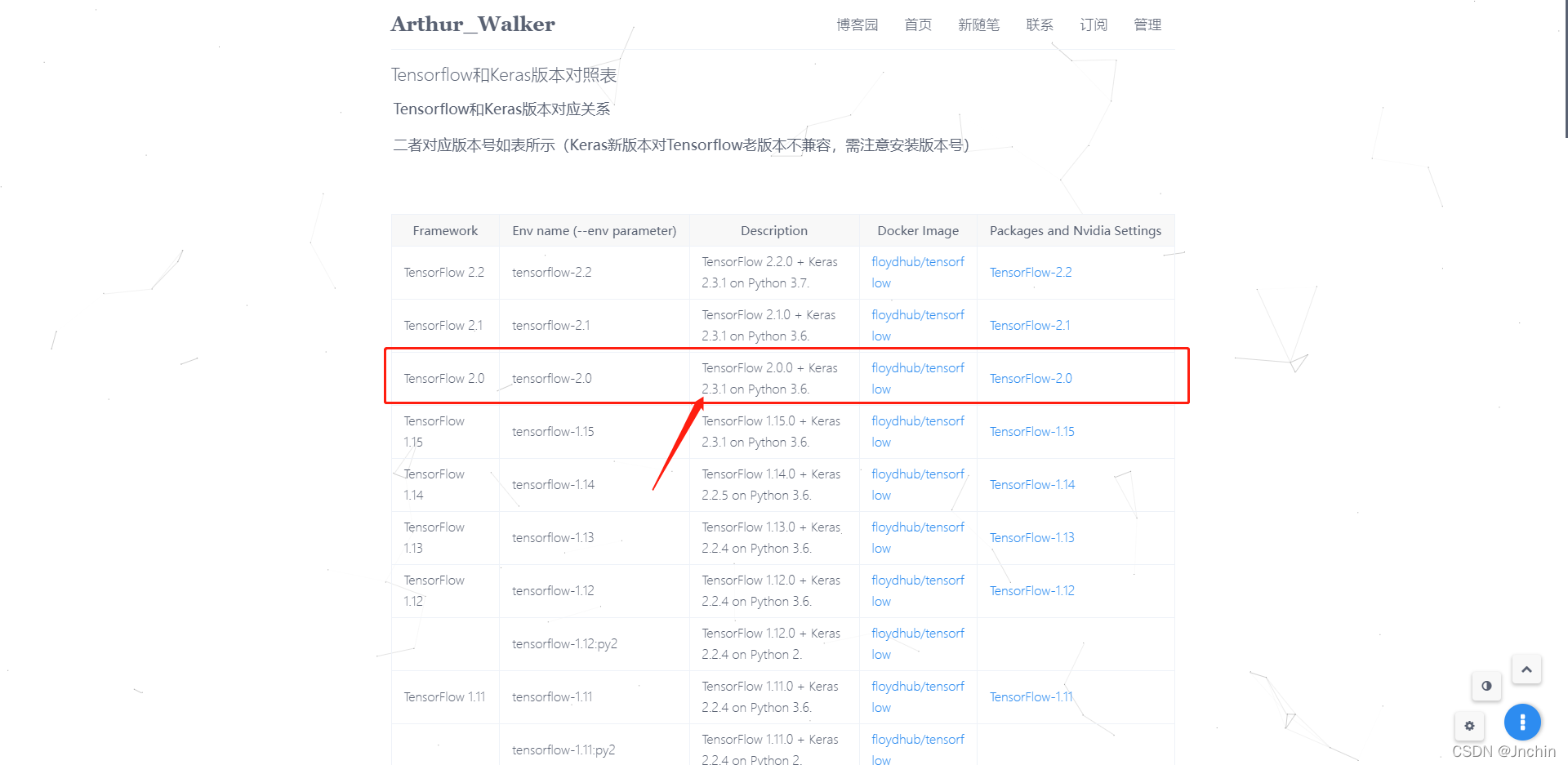
可以看到我只能安装 Keras 2.3.1的版本,安装其他的都会报错。命令如下:
pip install Keras==2.3.1
笔记
以下是拓展延伸,与上面的操作无关。
Tensorflow 和 Keras的关系?
tensorflow官网:https://www.tensorflow.org
keras官网:https://keras.io/
Keras 是一个模型级库,为开发深度学习模型提供了高层次的构建模块。它不处理诸如张量乘积和卷积等低级操作。相反,它依赖于一个专门的、优化的张量操作库来完成这个操作,它可以作为 Keras 的「后端引擎」。相比单独地选择一个张量库,而将 Keras 的实现与该库相关联,Keras 以模块方式处理这个问题,并且可以将几个不同的后端引擎无缝嵌入到 Keras 中。
目前,Keras 有三个后端实现可用: TensorFlow 后端, Theano 后端, CNTK 后端。而且如果安装了多个后端,是可以切换的,具体操作看官网。
什么是CUDA、CUDA Toolkit、cuDNN?
- CUDA:为"GPU通用计算"构建的运算平台。
- CUDA Toolkit (nvidia): CUDA完整的工具安装包,其中提供了 Nvidia 驱动程序、开发 CUDA 程序相关的开发工具包等可供安装的选项。包括 CUDA 程序的编译器、IDE、调试器等,CUDA 程序所对应的各式库文件以及它们的头文件。(NVCC 是CUDA的编译器,只是 CUDA Toolkit 中的一部分)
- CUDA Toolkit (Pytorch): CUDA不完整的工具安装包,其主要包含在使用 CUDA 相关的功能时所依赖的动态链接库。不会安装驱动程序。
- cuDNN:用于深度神经网络的GPU加速库,可以集成到更高级别的机器学习框架中,如tf、torch。
注意:CUDA 和 CUDA Toolkit 的版本是一致的。
可以这么理解:
- CUDA 是一个工作台。
- CUDA Toolkit 是一个工具箱,里面有扳手、螺丝刀等等,后面括号里表示在不同情况下所用的工具箱。
- cuDNN 是一个工具,比如是个钳子。
如果是为了使用 PyTorch/TensorFlow,推荐使用 conda 安装CUDA Toolkit 和 cuDNN。即:
conda install cudatoolkit==版本号
conda install cudnn==版本号
安装 cudnn 时不加版本号会自动安装与 cudatoolkit 兼容的版本。
吐槽:tf不像torch那样很好装,torch官网直接提供了完整正确的安装命令生成器和完美的历史版本查询表。tf则没有,完全靠自己人肉对号入座,而且文档也写得一塌糊涂,链接引来引去,把重要的东西全写在后面了。
Original: https://blog.csdn.net/qq_38237214/article/details/122157197
Author: Jnchin
Title: 正确简单地安装Tensorflow和Keras
相关阅读2
Title: [Yolov5]模型选择,参数修改,目标检测,训练数据集以及训练自己数据集全过程。
目录
a.Roboflow: Give your software the power to see objects in images and video
c.会在这个路径下产生两个.pt,一个是best一个last
d.最后将这个训练完的best.pt放到detect.py作为一个权重文件,最后直接run行了。
a.https://colab.research.google.com
d.将训练完成的的best.pt下载下来,替换detect的权重路径即可。
小样本成果展示
华北理工一角yolov5检测
说在前面一些配置
Cuda11.4+Cudnn8.2.4

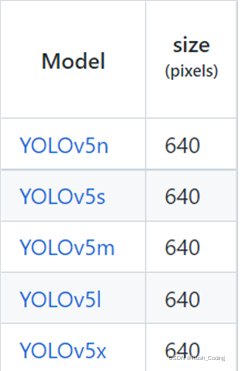
1.Yolov5模型与像素大小。
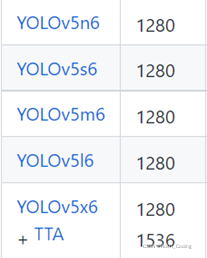
2.常用参数
a.detect.py
'--weights' #选择网络模型,路径选择.pt文件
'--source' #待检测图片路径
b.train.py
'--weights' #选择网络模型
'--cfg' #关于模型的配置,可修改为model下的.yaml
'--data' #可修改为data下的.yaml一些数据集
'--hyp' #超参数,用于对应模型的微调
'--epochs' #训练多少轮
'--batch-size' #尽量调小一点,最好是2的幂次方
'--imgsz', '--img', '--img-size'#
'--rect' #矩阵,满足网络模型要求,对图像进行部分填充,最小填充
'--resume' #在某一模型基础上继续训练,指定之前训练的last.pt
'--noautoanchor'#默认开启锚点
'--evolve' #寻找最优秀参数的方式
'--bucket'
'--cache' #是否对图片进行缓存
'--image-weights'
'--device''--multi-scale' #图片尺寸变换
'--single-cls'
'--adam' #选择优化器
'--project' #项目默认保存位置
'--quad'
'--linear-lr' #以线性方式学习
3.如何目标检测
a.Pycharm
直接选择需要的模型权重,待检测图片路径以及以及(如果需要的话)修改上述其他参数
b.Linux
Python 待运行.py --参数1 参数值 --参数2 参数值
Ex:python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65
4.如何训练别人数据集
修改以下参数,直接运行就行,Linux同上。
'--weights'#选择网络模型.pt
'--cfg'#关于模型的配置,可修改为model 下的.yaml
'--data'#可修改为data 下的.yaml 一些数据集
5.如何训练属于自己的数据集
到这个网址训练自己的数据集。
记得导出为yolo格式,解压后如下图。
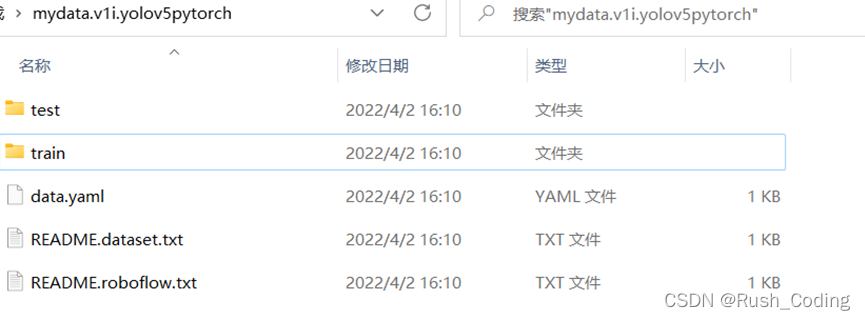
b.修改下面参数,选择需要训练的模型,
但是记得weights和cfg也就是选择的网络模型要与配置的.yaml对应。
'--data' #可修改为data下的.yaml一些数据集
(这个要选择自己在上述网站做好的训练配置,比如这个地方是)
parser.add_argument('--data', type=str, default=ROOT / 'mydata.v1i.yolov5pytorch/data.yaml', help='dataset.yaml path')
c.会在这个路径下产生两个.pt,一个是best一个last
'runs/train/exp7/weights/best.pt'
d.最后将这个训练完的best.pt放到detect.py作为一个权重文件,最后直接run行了。
6.云端GPU训练数据集。
b.上传自己yolo包。
c.
!unzip /content/yolov5-6.0.zip -d /content/yolov5 ORtar -zxvf /content/yolov5-6.0.tar -d /content/yolov5
%cd /content/yolov5/yolov5-6.0
!pip install -r requirements.txt
%load_ext tensorboard
%tensorboard --logdir=runs/data
!python train.py --rect
!python train.py --rect --data=data/coco.yaml //或者指定其他数据集
d.将训练完成的的best.pt下载下来,替换detect的权重路径即可。
Original: https://blog.csdn.net/weixin_42245756/article/details/123927786
Author: Rush_Coding
Title: [Yolov5]模型选择,参数修改,目标检测,训练数据集以及训练自己数据集全过程。
相关阅读3
Title: tensorflow hub模型下载不了问题解决
博主在根据官网配置图像分类迁移学习时,由于没有设置翻墙,程序执行如下语句时
model = image_classifier.create(train_data)
会因为模型下载超时而报错:urllib.error.URLError:
博主debug看了下,在/home/sxhlvye/anaconda3/envs/testTF/lib/python3.6/site-packages/tensorflow_examples/lite/model_maker/core/task/model_spec/init.py文件里(结合自己的路径)看到了预先设定好的模型配置
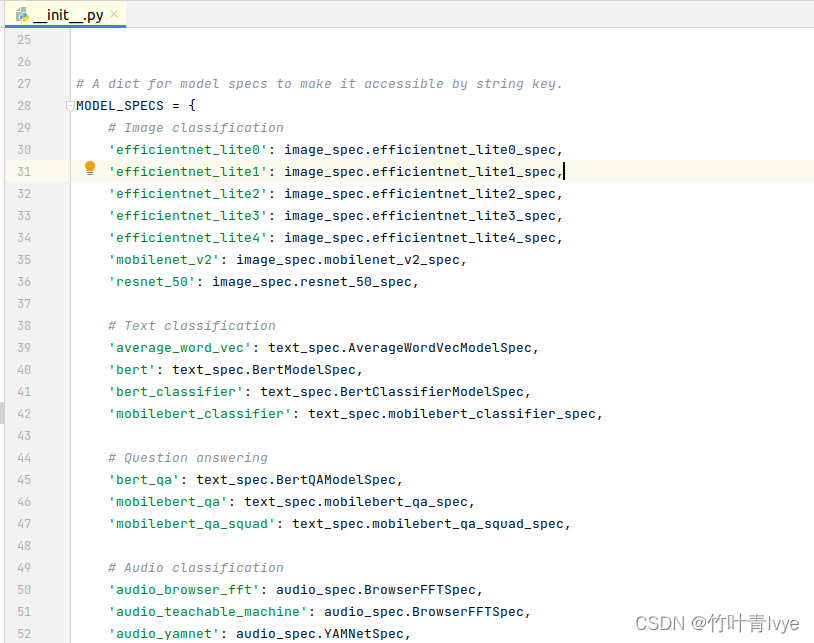
切换到/home/sxhlvye/anaconda3/envs/testTF/lib/python3.6/site-packages/tensorflow_examples/lite/model_maker/core/task/model_spec/image_spec.py文件,可以看到每个模型的下载路径
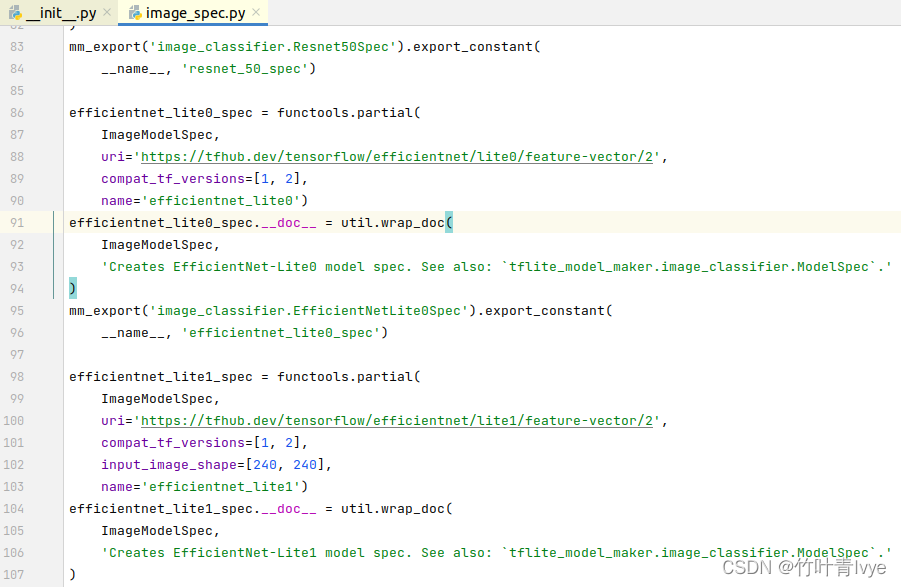
在不指定模型路径情况相下,系统默认使用的是efficientnet_lite0模型,对应路径是
https://tfhub.dev/tensorflow/efficientnet/lite0/feature-vector/2
博主想直接到tensorflow hub网站上去下载
TensorFlow Hub ![]() https://tensorflow.google.cn/hub/;但点击'查看模型'没有反应
https://tensorflow.google.cn/hub/;但点击'查看模型'没有反应
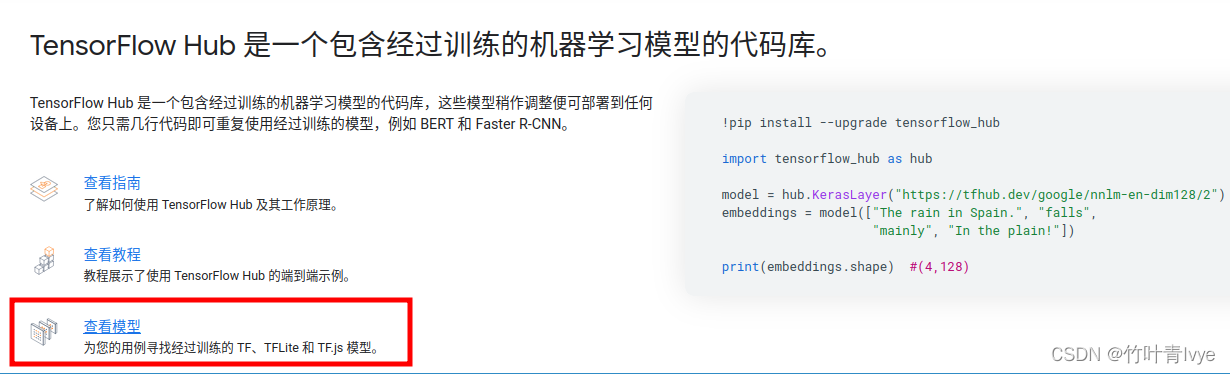
可看到图中示例可以直接通过tensorflow_hub.KerasLayer函数通过路径来加载模型,其实再深入debug,你会发现上面的mage_classifier.create()里面其实也调用了KerasLayer函数

为了网页浏览模型,可以访问如下网址:
TensorFlow Hub ![]() https://hub.tensorflow.google.cn ;如下页面中可以根据条件去筛选
https://hub.tensorflow.google.cn ;如下页面中可以根据条件去筛选
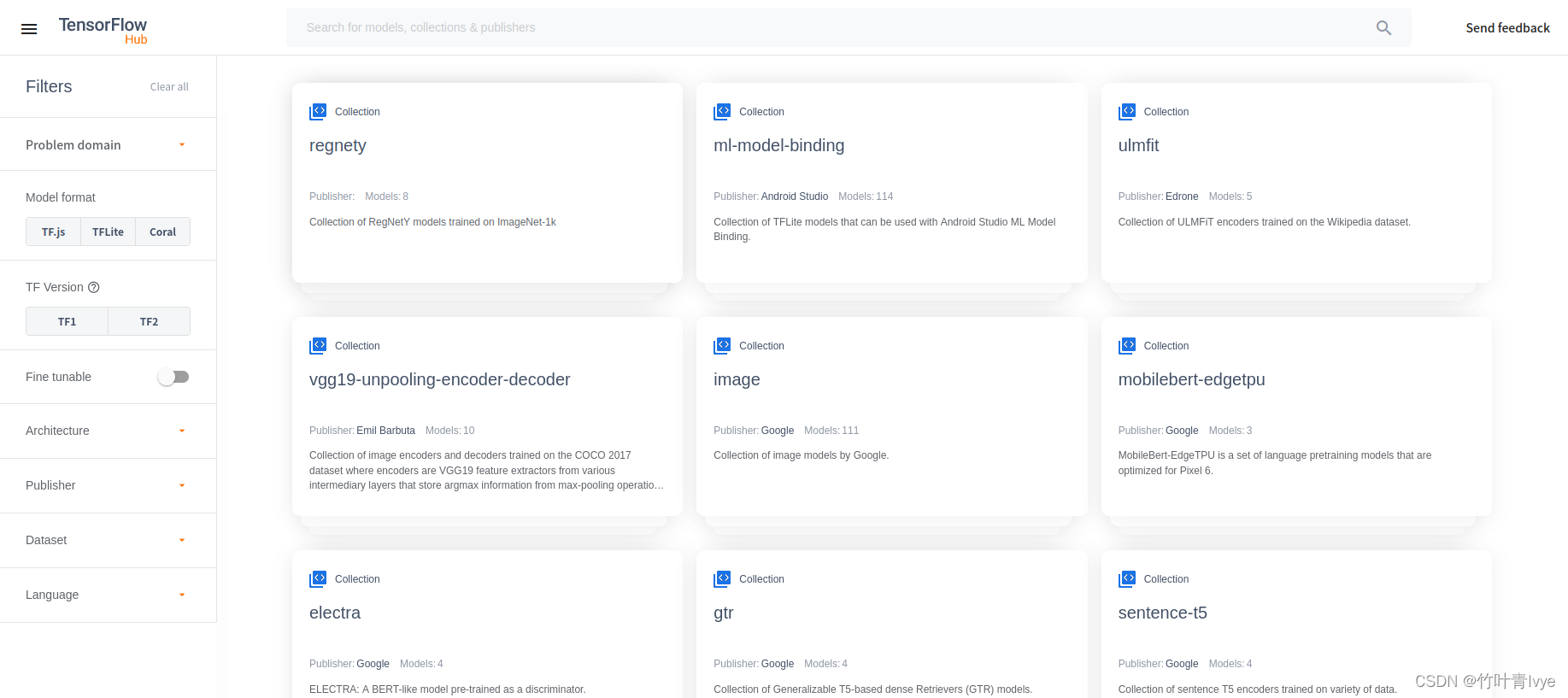
模型下载不了解决方法
输入上面的网址https://tfhub.dev/tensorflow/efficientnet/lite0/feature-vector/2,发现没有反应,可以对链接进行如下的更改即可。
(1)https://tfhub.dev修改为https://storage.googleapis.com/tfhub-modules
(2) 2修改为2.tar.gz
修改后的访问网址应该为:https://storage.googleapis.com/tfhub-modules/tensorflow/efficientnet/lite0/feature-vector/2.tar.gz
代码修改为如下:
import os
import numpy as np
import tensorflow as tf
assert tf.__version__.startswith('2')
from tflite_model_maker import model_spec
from tflite_model_maker import image_classifier
from tflite_model_maker.config import ExportFormat
from tflite_model_maker.config import QuantizationConfig
from tflite_model_maker.image_classifier import DataLoader
import matplotlib.pyplot as plt
from tensorflow_examples.lite.model_maker.core.task import model_spec as ms
import tensorflow_hub as hub
image_path = tf.keras.utils.get_file(
'flower_photos.tgz',
'https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz',
extract=True)
image_path = os.path.join(os.path.dirname(image_path), 'flower_photos')
data = DataLoader.from_folder(image_path)
train_data, test_data = data.split(0.9)
print(train_data.size)
print(test_data.size)
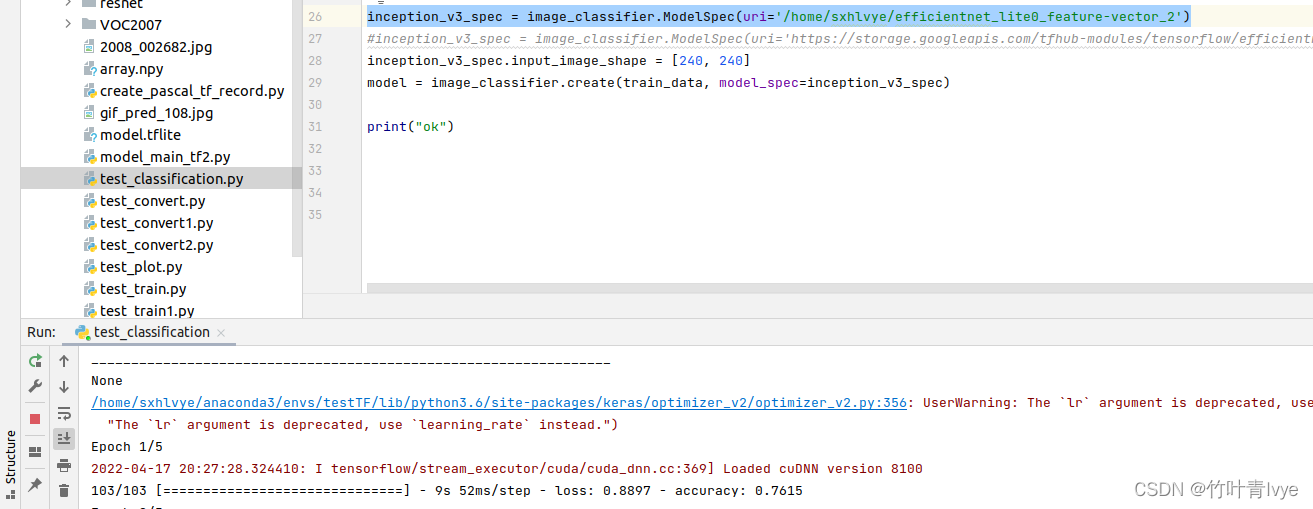
#inception_v3_spec = image_classifier.ModelSpec(uri='/home/sxhlvye/efficientnet_lite0_feature-vector_2')
inception_v3_spec = image_classifier.ModelSpec(uri='https://storage.googleapis.com/tfhub-modules/tensorflow/efficientnet/lite0/feature-vector/2.tar.gz')
inception_v3_spec.input_image_shape = [240, 240]
model = image_classifier.create(train_data, model_spec=inception_v3_spec)
print("ok")
运行部分结果如下:
=================================================================
Total params: 3,419,429
Trainable params: 6,405
Non-trainable params: 3,413,024
_________________________________________________________________
None
/home/sxhlvye/anaconda3/envs/testTF/lib/python3.6/site-packages/keras/optimizer_v2/optimizer_v2.py:356: UserWarning: The `lr` argument is deprecated, use `learning_rate` instead.
"The `lr` argument is deprecated, use `learning_rate` instead.")
Epoch 1/5
2022-04-17 20:08:02.362645: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8100
103/103 [==============================] - 9s 49ms/step - loss: 0.8722 - accuracy: 0.7630
Epoch 2/5
103/103 [==============================] - 5s 50ms/step - loss: 0.6609 - accuracy: 0.8941
Epoch 3/5
103/103 [==============================] - 5s 50ms/step - loss: 0.6217 - accuracy: 0.9181
Epoch 4/5
103/103 [==============================] - 5s 51ms/step - loss: 0.6085 - accuracy: 0.9190
Epoch 5/5
103/103 [==============================] - 5s 52ms/step - loss: 0.5915 - accuracy: 0.9354
ok
上面图片会默认下载到如下路径(结合自己的博客)
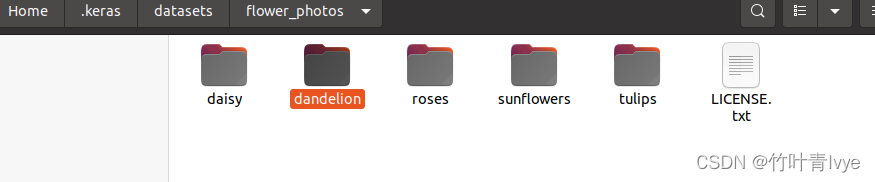
训练自己数据集用于分类的时候,就可以借鉴此目录结构。
补充:
从 TF Hub 缓存下载的模型 | TensorFlow Hub
可以看到下载的模型保存的位置
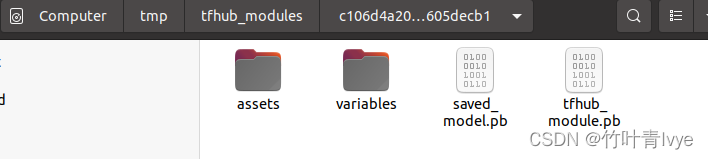
博主把上面文件夹中的内容拷贝别的一个位置
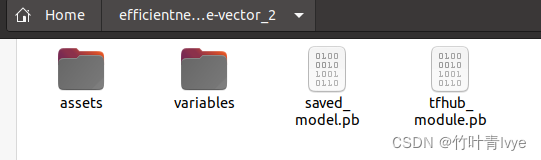
代码中路径设定为本地地址(结合自己的路径),程序可以正常运行
inception_v3_spec = image_classifier.ModelSpec(uri='/home/sxhlvye/efficientnet_lite0_feature-vector_2')
Original: https://blog.csdn.net/jiugeshao/article/details/124234529
Author: 竹叶青lvye
Title: tensorflow hub模型下载不了问题解决