
【 导读】本文是专栏《计算机视觉40 例简介》的第10 个案例《隐身术》。该专栏简要介绍李立宗主编《计算机视觉40 例——从入门到深度学习(OpenCV-Python )》一书的40 个案例。
目前,该书已经在电子工业出版社出版,大家可以在京东、淘宝、当当等平台购买。
大家可以在公众号"计算机视觉之光"回复关键字【案例10 】获取本文案例的源代码及使用的测试图片等资料。
针对本书40 个案例的每一个案例,分别录制了介绍视频。如果嫌看文字版麻烦,可以关注公众号"计算机视觉之光"直接观看视频介绍版。
隐身术演示如图1所示,图中左侧是正常显示的图像、右侧是隐身效果。从图中可以看出,红色部分会被显示为背景,当人身着红色衣服时可以实现隐身效果。
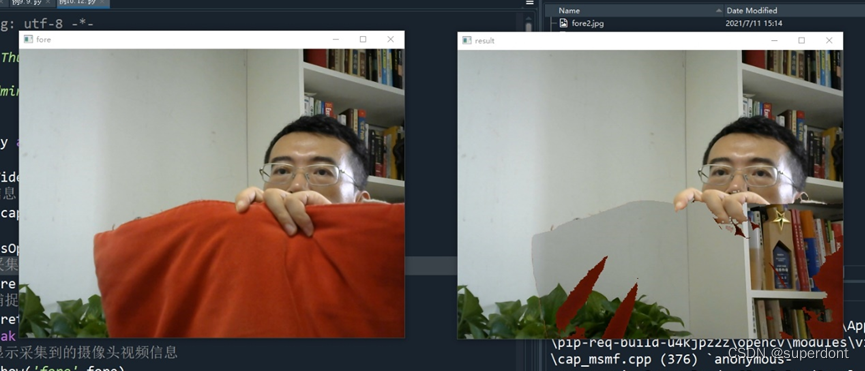
图1 答题卡识别
如图2所示,是隐身效果图。

图2 隐身效果图
隐身术的基本原理,其原理如图3所示。图中各个图像具体为:
- 图像A:原始背景。该图像采集自某一个特定时刻,是希望被伪装成的背景;
- 图像B:实际前景(红斗篷)。此时,前景中出现两个人,其中左边的人,正常着装,右侧的人身穿作为伪装的红色斗篷;
- 图像C:红斗篷对应的原始背景。该图像是从图像A中提取的,是图像A中对应着图像B中红色斗篷位置的图像,是用来替换红色斗篷的;
- 图像D:抠除红斗篷的前景。该图像由图像B得到,是将图像B中红色斗篷位置的图像抠除后得到的。
- 图像E:隐身效果。该图像是通过"图像E = 图像C + 图像D"得到。

图3 隐身术原理
在《计算机视觉40例——从入门到深度学习(OpenCV-Python)》一书中,从算法原理、实现流程等角度系统深入地介绍了该案例的理论基础和实现过程,并对具体的代码实现进行了细致的介绍与解释。欢迎大家阅读第10章《隐身术》获取详细内容。
《计算机视觉40例——从入门到深度学习(OpenCV-Python)》在介绍Python基础、OpenCV基础、计算机视觉理论基础、深度学习理论的基础上,介绍了计算机视觉领域内具有代表性的40个典型案例。这些案例中,既有传统的案例(数字识别、答题卡识别、物体计数、缺陷检测、手势识别、隐身术、以图搜图、车牌识别、图像加密、指纹识别等),也有深度学习案例(图像分类、风格迁移、姿势识别、实例分割等),还有人脸识别方面的案例(表情识别、驾驶员疲劳监测、识别性别与年龄等)。

Original: https://blog.csdn.net/superdont/article/details/126226553
Author: superdont
Title: 【计算机视觉40例】案例10:隐身术
相关阅读1
Title: Mac 安装 TensorFlow 2.7 环境,支持 AMD 显卡
先抛出问题,望高人指点迷津:
跑 mnist 的 demo,GPU 比 CPU 慢 了很多,为啥呢?
本机环境:
CPU:Intel I9 8核16线程
内存:64G
显卡:AMD Radeon Pro 5500M
示例代码
import tensorflow as tf
def run():
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
print(len(x_train), len(y_train), len(x_test), len(y_test))
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
if __name__ == '__main__':
devices = tf.config.list_physical_devices()
print(devices)
with tf.device("cpu:0"):
print('start with cpu')
run()
with tf.device("gpu:0"):
print('start with gpu')
run()
示例结果
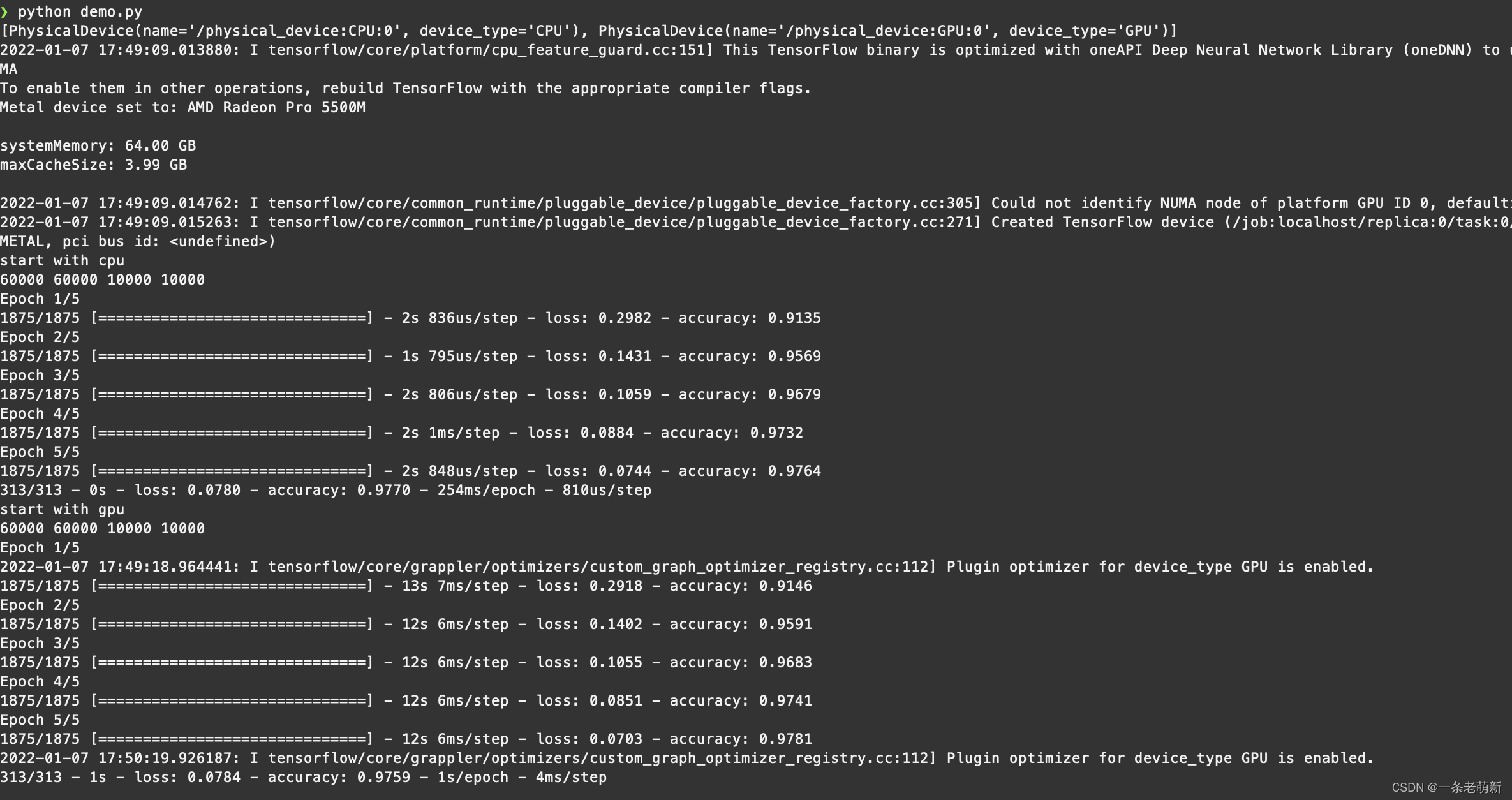
[PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2022-01-07 17:49:09.013880: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Metal device set to: AMD Radeon Pro 5500M
systemMemory: 64.00 GB
maxCacheSize: 3.99 GB
2022-01-07 17:49:09.014762: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-01-07 17:49:09.015263: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: )
start with cpu
60000 60000 10000 10000
Epoch 1/5
1875/1875 [==============================] - 2s 836us/step - loss: 0.2982 - accuracy: 0.9135
Epoch 2/5
1875/1875 [==============================] - 1s 795us/step - loss: 0.1431 - accuracy: 0.9569
Epoch 3/5
1875/1875 [==============================] - 2s 806us/step - loss: 0.1059 - accuracy: 0.9679
Epoch 4/5
1875/1875 [==============================] - 2s 1ms/step - loss: 0.0884 - accuracy: 0.9732
Epoch 5/5
1875/1875 [==============================] - 2s 848us/step - loss: 0.0744 - accuracy: 0.9764
313/313 - 0s - loss: 0.0780 - accuracy: 0.9770 - 254ms/epoch - 810us/step
start with gpu
60000 60000 10000 10000
Epoch 1/5
2022-01-07 17:49:18.964441: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
1875/1875 [==============================] - 13s 7ms/step - loss: 0.2918 - accuracy: 0.9146
Epoch 2/5
1875/1875 [==============================] - 12s 6ms/step - loss: 0.1402 - accuracy: 0.9591
Epoch 3/5
1875/1875 [==============================] - 12s 6ms/step - loss: 0.1055 - accuracy: 0.9683
Epoch 4/5
1875/1875 [==============================] - 12s 6ms/step - loss: 0.0851 - accuracy: 0.9741
Epoch 5/5
1875/1875 [==============================] - 12s 6ms/step - loss: 0.0703 - accuracy: 0.9781
2022-01-07 17:50:19.926187: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.
313/313 - 1s - loss: 0.0784 - accuracy: 0.9759 - 1s/epoch - 4ms/step
环境安装
英文好的可以看参考原文 Tensorflow Plugin - Metal - Apple Developer
确保Python 是 3.8版本。不是的话, brew 安装一下
#查看py版本
python3 -V
# 不是3.8的话,安装一下
brew install python@3.8
# 创建虚拟环境
python3 -m venv ~/tensorflow-metal
source ~/tensorflow-metal/bin/activate
python -m pip install -U pip
# 安装 tensorflow-macos
SYSTEM_VERSION_COMPAT=0 python -m pip install。tensorflow-macos
python -m pip install tensorflow-metal
# 现在就可以跑上面的 demo 了
坑1: 本来使用anaconda来装,死活报下面的错,浪费了很多时间
PSGraph adamUpdateWithLearningRateTensor:beta1Tensor:beta2Tensor:epsilonTensor:beta1PowerTensor:beta2PowerTensor:valuesTensor:momentumTensor:velocityTensor:maximumVelocityTensor:gradientTensor:name:]: unrecognized selector sent to instance
python 环境详情
```bash
❯ pip list
Package Version
Original: https://blog.csdn.net/weixin_45919616/article/details/122369508
Author: 一条老萌新
Title: Mac 安装 TensorFlow 2.7 环境,支持 AMD 显卡
相关阅读2
Title: 个推科普漫画,解读《女心理师》中的智能语音识别系统
近期的很多热播剧都和心理咨询相关,在《女心理师》中,有这样一个数据智能应用,吸引了Mr.Tech的目光。

▲图片来源:优酷网剧《女心理师》
在女主工作的心理救援中心,不仅有酷炫的可视化数据大屏,还有看起来非常高级的 智能语音识别系统。这个智能语音识别系统不仅能实时将通话双方的语音内容转译成文本,还能根据通话内容做出预警,帮助心理咨询师做判断和决策,从而更好地实施援助。
这样的"黑科技"具体如何实现呢?接下来,Mr.Tech就为大家图文并茂做深入解读。
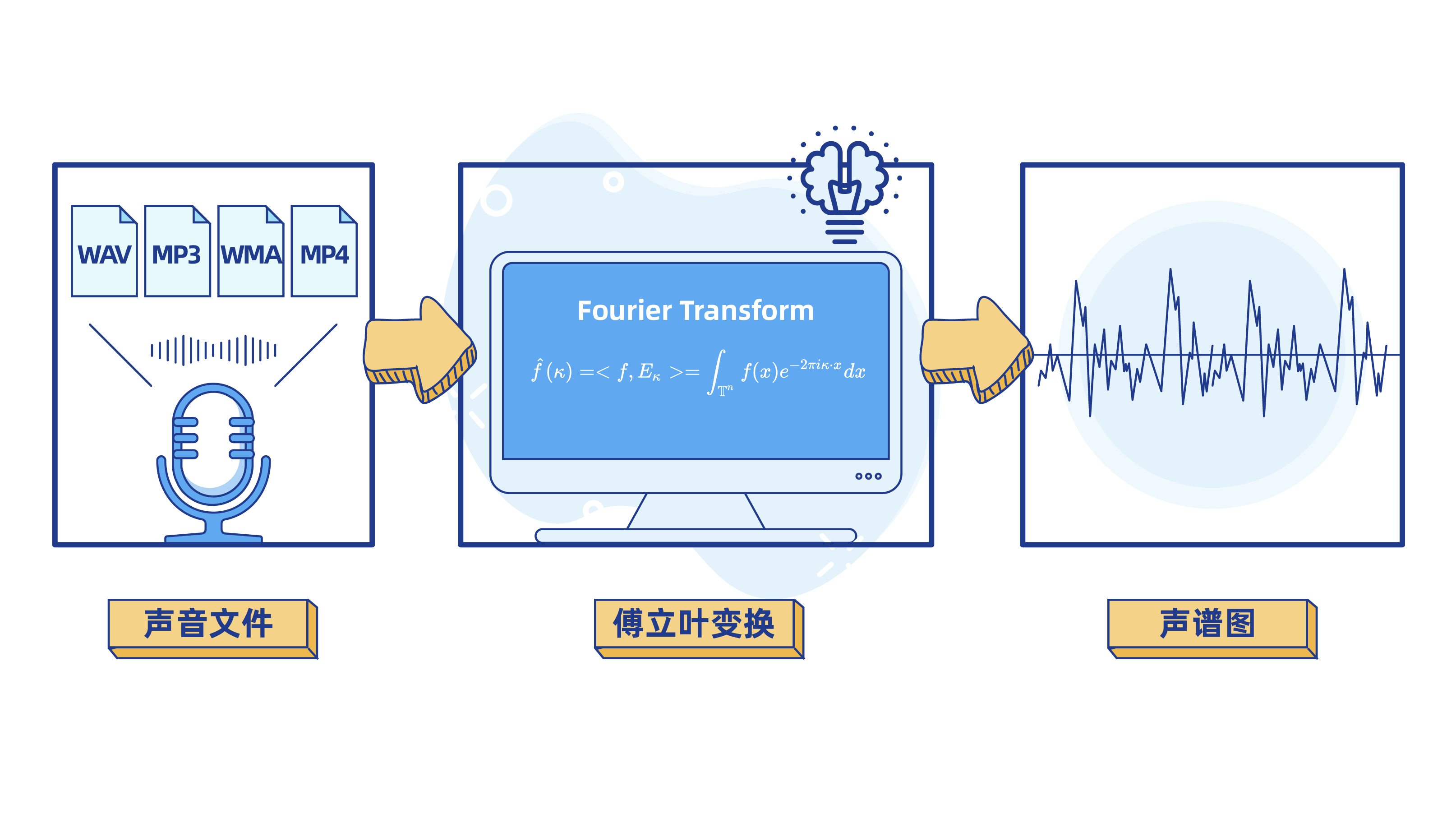
第一步: 用傅里叶变换将声音信号处理成波数据
众所周知,计算机不能直接对声音文件进行计算和机器学习训练。算法工程师需要对声音文件进行处理,把MP3、MP4等声音文件转化成计算机擅长解决的数学问题。
学过中学物理课,我们都知道, 声音的本质是波,频率和振幅是描述声波的两个重要属性。我们将一定时间内声音的振幅和频率做成可视化图表,就能得到声波图。
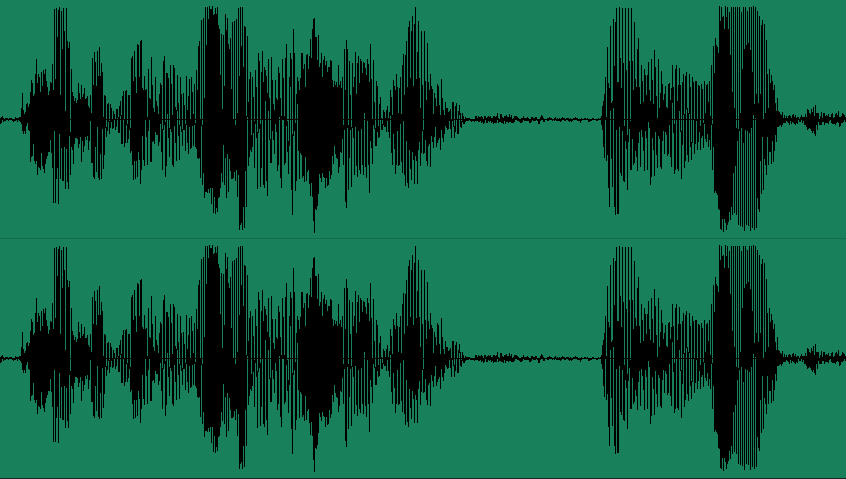
看到以上的声波图,你想到了什么?是不是和数学里的 正弦函数图像长得特别像呢?
Bingo!
智能语音识别第一步要做的,就是选择正确类型的函数来描述不同的声波,然后再将数据交给机器去学习和计算。
理解了这点,你的右脚就已经踏进了智能语音识别科学的大门!
但是,声波是很复杂的。声波是不同频率、不同强度的正弦波的叠加。我们在将声音可视化时,得到的仅仅是叠加合成后的声波图。为了更好地理解声音信号,算法工程师还需要将声波图进行分解。
如下图:

这个将声音信号进行分解(变换)的过程,就是机器学习里经常提到的 "傅里叶变换"。

傅里叶变换(Fourier Transform,简称"FT")
是机器学习领域一个很常用的算法,它的作用是对数字信号进行解析,以方便后续进行数据处理。
第二步: 对声音进行基础的特征识别
将声音文件解析成声谱图之后,机器就可以对声音进行简单的特征识别和判断,比如发声人的性别、年龄层次等。
我们知道,男性和女性的声音具有非常明显的区别。一般来说,男性声音洪亮,振幅较高,频率较低;女性声音尖细,频率较高,振幅较低。同时,还有一些异常情况,比如大声的呼救、病痛时的呻吟等,也都可以通过频率和振幅来进行刻画描述。
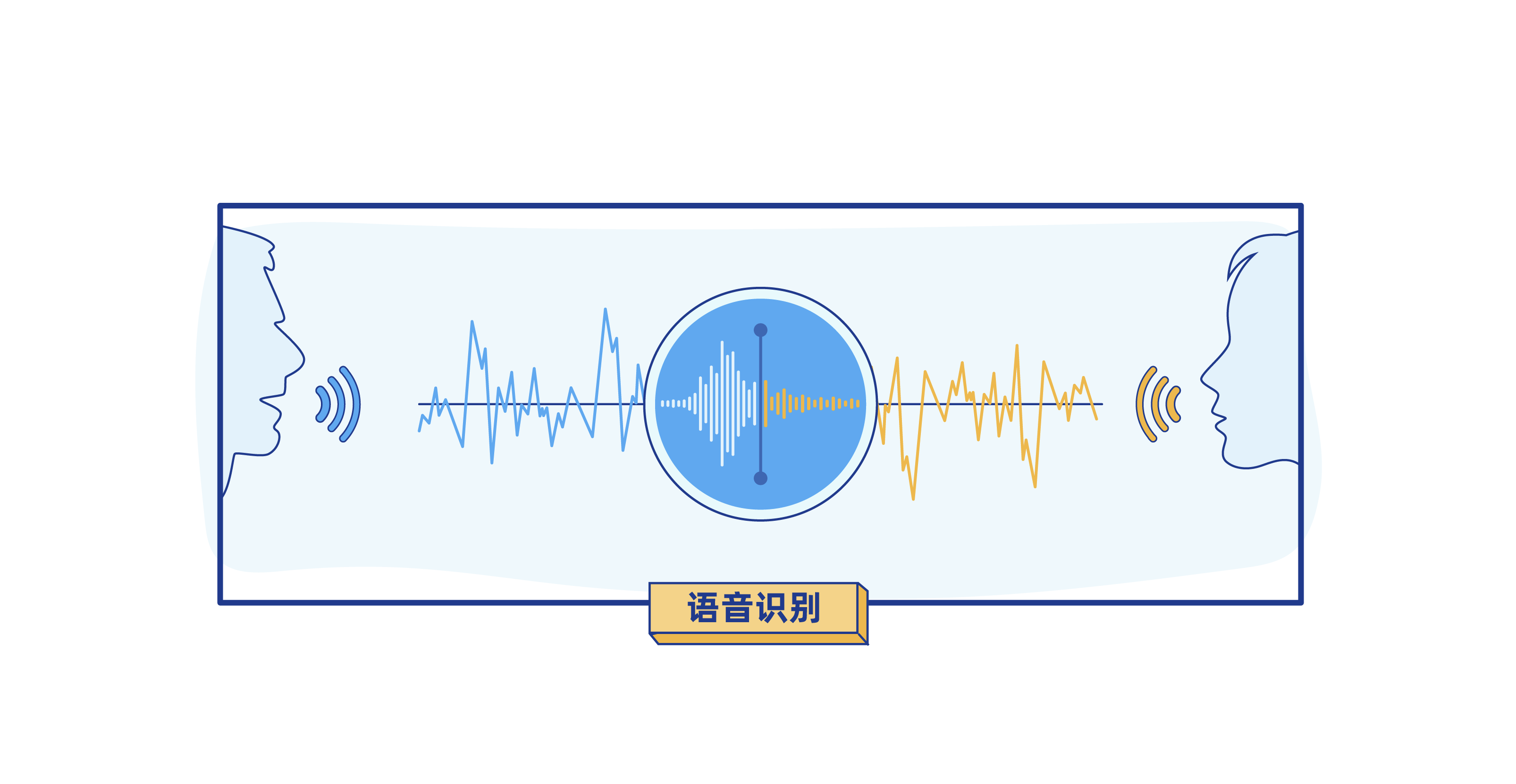
第三步: 将语音转化成文本,便于机器学习
《女心理师》中的智能语音识别系统还能将语音内容实时转译成文本,并根据语音内容做出预警提醒。
计算机是如何听懂人类语言的呢?
所谓"人工智能",其中离不开"人工"的作用。实现智能语音识别的本质其实是将声音波形特征和特定文字一一匹配。这就需要在前期构建 语音样本库,由人工对语音样本进行标注,然后抽取出声音波形特征和文字的对应关系,让机器去学习。通过大量的训练、学习,计算机便拥有了将语音转化成文字的能力。

不过,在该阶段,转译后的文字对于计算机而言,就如同"天书",计算机并不能理解文字中蕴含的涵义,更不能Get到文字中说话人所要表达的情感。

因此,还需要教会计算机听"懂"人话,并使其拥有一定程度的专业知识水平,能够对文本内容进行情感分析和自主推理,从而实现智能预警,更好地辅助研判。
具体如何实现呢?一起来看第四步。
第四步: 对文本内容进行情感分析
我们知道,句子由词汇组成,包括停顿词(的、和、地、得、之间......),正面评价词(价格便宜、干净、美丽、物美价廉......),负面评价词(埋汰、脏、差、坏......),程度词(还行、非常好、凑合、一般、特别......),疑问词(难道、岂、居然、竟然、究竟、简直、难道、反倒、何尝、何必......)以及否定词(不、莫、无、弗、非、否......)等等。要理解一句话的情感和态度,就需要对句子中各个词汇的词性进行分析。 所以我们需要对上阶段转译好的文本进行分词处理,然后综合每个词的情感倾向最终得出该语句整体的情感态度。
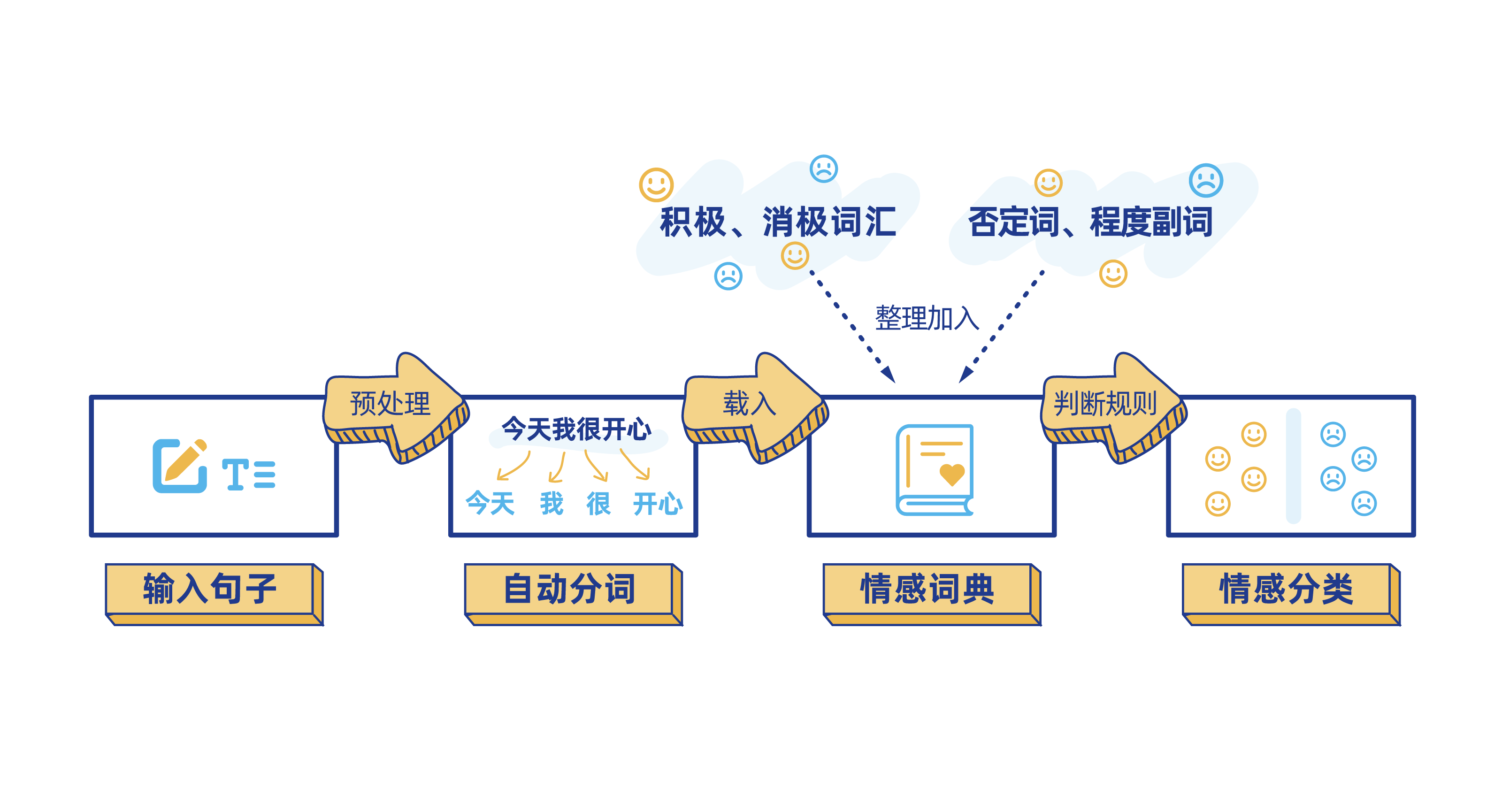
计算机在进行文本的情感分析时,还是要先将其转化为数学问题才能解决。
计算机一般采用如下类型的数学表达式来计算一句话的情感态度:

举个例子,比如在"难道非得让我说差么?" (疑问词"难道"往往和否定词结合起到双重否定的作用,有时人们也会把"难道"单独当成否定词来使用) 这样一句话中,"难道"和"非"都是否定词,所以该句话的整体分值就可以计算出来了,是(-1)^21-1 = -1,那么这句话要表达的就是偏负面的态度。
再比如"难道这样不好吗?"中,"难道"和"不"都是否定词,分值为(-1)^211=1,那这句话的情感就是偏正面的。
一般来说,词汇的情感是偏正面还是负面,在不同的领域有不同的标准和说法。比如,"声音大",在音响行业,其实就是非常正向的的词汇,但是在家电行业,说一个洗衣机"声音大",其实表达的是负向的态度。 所以,不同行业的算法工程师,都需要构建所属行业或领域的特色词库。
此时再看《女心理师》剧中的智能语音识别系统,就很好理解它的"聪明"所在了。在心理咨询或救援领域,"跳楼""自杀"这些都是负向词汇,"不用来找我了"这句话中也有否定词"不"。因此当系统判断语音内容非常消极和负面时,就会自动弹出相应警报。

▲图片来源:优酷网剧《女心理师》
看到这步,恭喜你把左脚也踏进了智能语音识别科学的大门!
第五步: 构建行业知识图谱
可以看到,上图中的警报弹框中,还有"需要专业支持"的提醒,智能水平较高。其实,在实际生活场景中,很多电商、互联网医疗等行业的企业所建设的智能客服系统,也已经进化到非常高的智能水平了,它们不仅能够理解文本内容,还能自主做推理、联想,提出相关专业建议,辅助决策。
而这个程度的"脑力"实现,使用到的正是 知识图谱(Knowledge Graph)的技术。
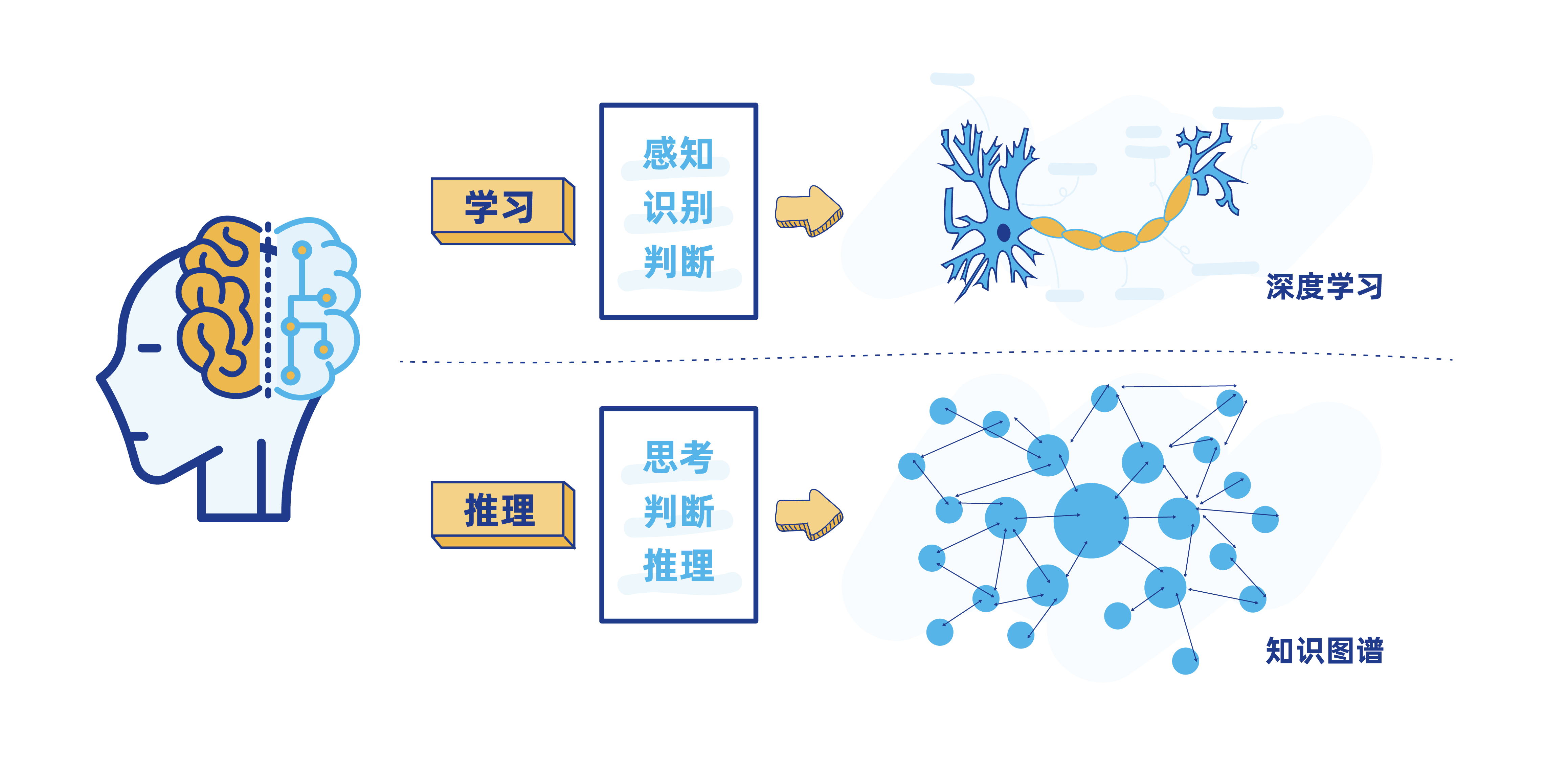
知识图谱,本质上是一种揭示实体之间关系的语义网络,在搜索引擎、文本挖掘等领域有广泛应用。比如,当用户使用搜索引擎搜索"水果"时,会出现"水果的分类""水果的营养价值""最近的水果店在哪里"等关联词条,其背后使用的就是"水果"领域的知识图谱。
我们在实际生活中使用到的智能客服系统,其"智力"也正是来自于对特定行业知识图谱的不断学习。比如,电商平台的智能客服,背后依托的就是商品、订单、物流等方面的知识图谱。当用户咨询某个商品时,智能客服就会调用相关图谱,为用户提供商品详情、订单状态、物流状态、商品历史价格走势、商品使用方式等相关信息和建议。
看完本文,相信大家已经比较深刻理解智能语音识别、知识图谱等的技术原理了。技术不仅是生产力,更是有温度的。在正确的应用姿势下,大数据和人工智能在各行各业都能发挥出巨大的正向价值。
个推的图挖掘实践
作为一家数据智能公司,个推在知识图谱、图挖掘等方面的实践也非常丰富。比如,个推在开展大数据抗疫时,正是基于万亿级图的构建和挖掘,实现了 疫情态势研判、传播路径分析等场景应用。详情查看>> 2021WAIC | 每日互动CTO叶新江:万亿级图下的数据智能
Original: https://blog.csdn.net/Androilly/article/details/122199531
Author: 个推技术
Title: 个推科普漫画,解读《女心理师》中的智能语音识别系统
相关阅读3
Title: 利用select/poll监听多个设备详解
如果一个应用程序去处理多个设备,例如应用程序读取网路数据,按键,串口,一般能想到的有三种方法:
方法1:
串行+阻塞的方式读取:
while(1) {
read(标准输入);
read(网络);
}
缺点:每当阻塞读取标准输入时,如果用户不进行标准输入的操作,而此时客户端给服务器发送数据,导致服务器无法读取客户端发送来的数据!
方法2:
采用多线程或者多进程机制来实现读取:
开辟多个线程,每一个线程处理一个设备,不会导致的数据的无法读取,但是系统的开销相比方法1要大!
方案3:采用linux系统提供的高级IO的处理机制
select/poll:两者一样,主进程能够利用select或者poll能够对多个设备进行监听!
其原理好像:方法1相当于有一个保安,看十户房子,如果小偷进来从第十户开始偷,保安却从第一户挨个检查,没有小偷确还在第一家等着。
方法2相当于雇了十个保安,开销大
方法3相当于买了10套监控设备,一个保安看监控录像,有情况报警
select函数原型:
int select(int nfds,
fd_set readfds,
fd_set writefds,
fd_set exceptfds,
struct timeval timeout);
函数功能:
主进程利用此函数能够对多个设备进行监听,一旦发现监听的设备都不可用(不可读、也不可写、也没有异常),那么主进程进入休眠状态,一旦监听的设备中,只要有一个设备可用(可读或者可写或者有异常)都会唤醒休眠的主进程,select也就会返回。
注意这个函数仅仅起到一个监听的功能,数据的后续处理,例如读写都是通过read,write,ioctl来进行!
参数说明:
nfds:
对设备的访问永远先open获取fd;
监听的设备中,最大的文件描述符fd+1;
数据类型fd_set:文件描述符集合,用来保存描述监听的设备,里面存放是被监听设备的文件描述符;如果select要监听某一个设备,必须把这个设备的fd添加到对应的文件描述符集合中!
readfds:读文件描述符集合指针,如果select要监听设备是否可读,需将设备的fd添加到这个集合中!
writefds:写文件描述符集合指针,如果select要监听设备是否可写,需将设备的fd添加到这个集合中!
exceptfds:异常文件描述符集合指针,如果select要监听设备是否有异常,需将设备的fd添加到这个集合中!
注意:一个设备的fd可以同时添加到三个集合中!
timeout:指定监听的超时时间,如果此参数指定了一个时间,例如5秒钟,select发现设备不可用,主进程进入休眠状态,如果5秒之内设备还不可用,5秒到期,主进程主动唤醒;如果此参数指定为NULL,休眠为永久休眠!
返回值:有三种
如果等于0:表明是超时;
如果小于0:表明系统出错;
如果大于0:表明设备可用(至少是一个设备,或者全部);
文件描述符集合操作的方法:
fd_set rfds; //定义读文件描述符集合
//从集合中解除对fd设备的监听
void FD_CLR(int fd, fd_set *set);
//判断是否是设备fd引起的主进程的唤醒,如果是返回true,否则返回false
int FD_ISSET(int fd, fd_set *set);
//添加一个新的被监听的设备
void FD_SET(int fd, fd_set *set);
//清空文件描述符集合
void FD_ZERO(fd_set *set);
注意:如果要重复监听,需要再次清空集合和添加监听设备!
以上是应用程序层面上的函数调用
其在内核层面上:
在sys_select中做休眠,poll不引起休眠
select系统调用过程:
1.应用程序调用select,首先调用C库的select函数实现;
2.C库的select保存select系统调用号到R7寄存器中,调用SVC(新的
)或者SWI(老的)触发软中断,至此由用户空间陷入内核空间,ARM
的工作模式由用户模式转变为SVC管理模式;
3.跳转到内核准备好的异常向量表的入口地址,根据R7保存的系统调
用号,以它为索引在系统调用表中找到对应的实现函数sys_select
4.sys_select要完成:
1.把被监听的设备对应驱动程序的poll函数挨个调用一遍,
被监听的设备都不可用时,它们的驱动的poll函数都返回0;
2.判断是否是驱动主动唤醒,还是超时唤醒,还是接收到信号唤醒;
3.如果即没有驱动主动唤醒,也没有超时唤醒,没有接收到信号,
sys_select调用poll_schedule_timeout主动让进程进入休眠;
4.假设被监听的设备中,有一个设备可用(可读或者可写或者异常
,硬件通过中断来判断),都会唤醒休眠的主进程;
5.sys_select的poll_schedule_timeout函数返回,不再休眠
6.再次把被监听的设备驱动的poll函数挨个调用一遍,此时可用
的设备对应的驱动poll函数会返回非0;
7.if (ret || time_out || ...) //ret = 1,立即返回到用户空
间,返回值为ret值
总结:
1.明确本来应该底层驱动的poll函数利用等待队列机制让进程休眠,
但是等待队列休眠9步骤并不都是驱动的poll来编写,有一部分是有内
核sys_select来实现;
2.驱动poll函数完成如下内容即可:
1.调用poll_wait,将当前进程添加到驱动定义的等待队列头中
2.根据设备是否可用,决定返回0还是非0

3.明确:监听机制,底层poll函数不是必须的,如果要监听设备还可
以使用多线程机制也能够完成监听;但是如果要使用select/poll监
听设备,驱动必须有poll实现!
下图是sys_select的简单实现:

通过对内核代码的分析,真正的休眠实现是在内核中实现的
poll_schedule_timeout函数中的schedule_hrtimeout_range中的schedule_hrtimeout_range_clock函数实现的
并不是在poll函数中实现的
poll(轮询)操作在应用程序中用于同时阻塞在多个文件上,当其中任何一个文件有应用程序所等待的事件(可读、可写、出错等)时,poll返回相应的掩码通知应用程序,使得应用程序知道应该对哪个文件做何种操作。按照我的理解,poll的本质可以这样解释:休眠等待多个指定文件中的任何一个发生特定的事件,并将被该文件唤醒;醒来后轮询所有相关文件(通过再次调用所有文件对应驱动的poll方法),获取所有被监控文件的事件信息返回给应用程序。
从这里就可以看出:
(1)其中等待队列的使用是必不可少的。实际上调用poll的进程将会休眠在多个等待队列(一般所有被监控文件的都有至少一个的等待队列)上,从其中任何一个队列上唤醒该进程,都可能使poll函数返回。
(2)驱动中的poll方法不实现休眠,而是:
- i、把当前进程添加到相应的等待队列中(仅在休眠时执行,唤醒时不会执行此功能)。
- ii、返回文件当前的状态掩码(告知是否有事件发生,休眠和唤醒都会执行)。
通过对内核源码、 《深入Linux设备驱动程序内核机制》的学习,我对Poll系统调用和内核驱动的poll方法的关系和结构有了整体且深入的了解,基本搞清了poll系统调用的执行脉络。对于poll系统调用的内核原理,请大家先看 《深入Linux设备驱动程序内核机制》那本书写的比较详细了,我不废话了。以后我会把我自己觉得需要注意的地方写出来。这里我把这个关系和数据结构图绘制了出来,请大家指正:
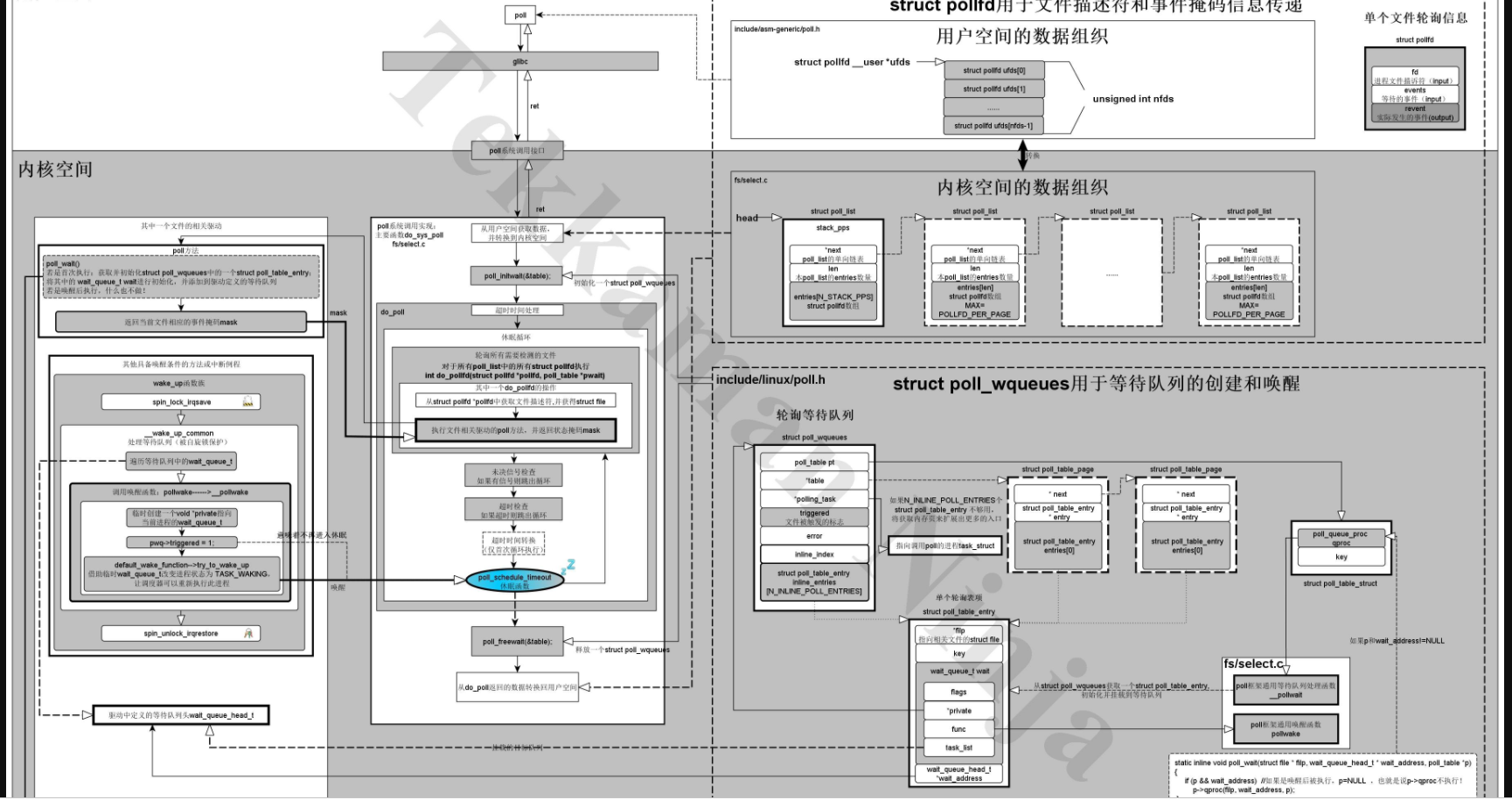
对于等待队列的情况,我用下面一个例子和图来示意一下:
例如有3个进程:
task-1:使用poll检测文件1~3
task-2:使用poll检测文件2~3
task-3:使用poll检测文件3
则等待队列的情况如下:
之后,假设task-2由于文件2或3被唤醒,且task-1/3对此不感兴趣(未设置该掩码),那么等待队列的情况如下:
等待队列入口项的添加和删除主要是由poll_initwait(&table);和poll_freewait(&table);完成。
poll_initwait(&table);完成初始化struct poll_wqueues table的工作,而poll_freewait(&table);负责清理这个结构体。这里需要注意的是等待队列中的wait_queue_t并不是在唤醒函数pollwake从队列中删除的,而是最后由poll_freewait(&table);集中处理的。而唤醒函数和普通的wait_event的唤醒函数有很大不同,请大家对比上面的图和之前我写的
《对Linux系统休眠的理解》
中的图。
Original: https://www.cnblogs.com/jiangzhaowei/p/11727957.html
Author: 江召伟
Title: 利用select/poll监听多个设备详解