
项目结构图

下载好项目压缩包后解压,得到以上的文件,首先将 画红圈的文件删除(如果有)
; 安装软件
安装Anaconda
安装Pycharm
安装格式工厂
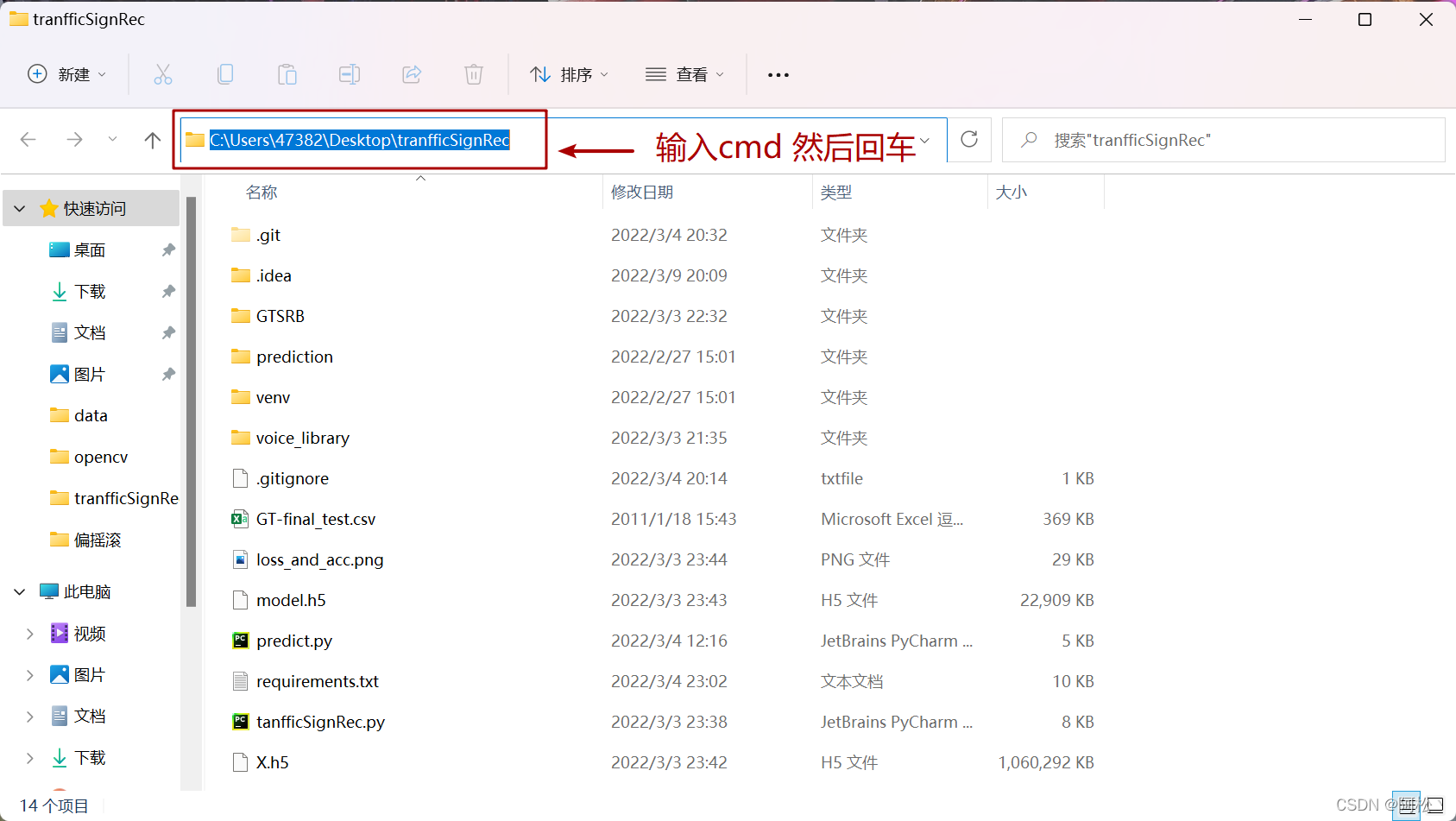
在上图中这个位置输入cmd回车,即可打开命令终端。用这样的方式打开命令终端可以确保输入命令的位置就是当前文件夹所在的位置:
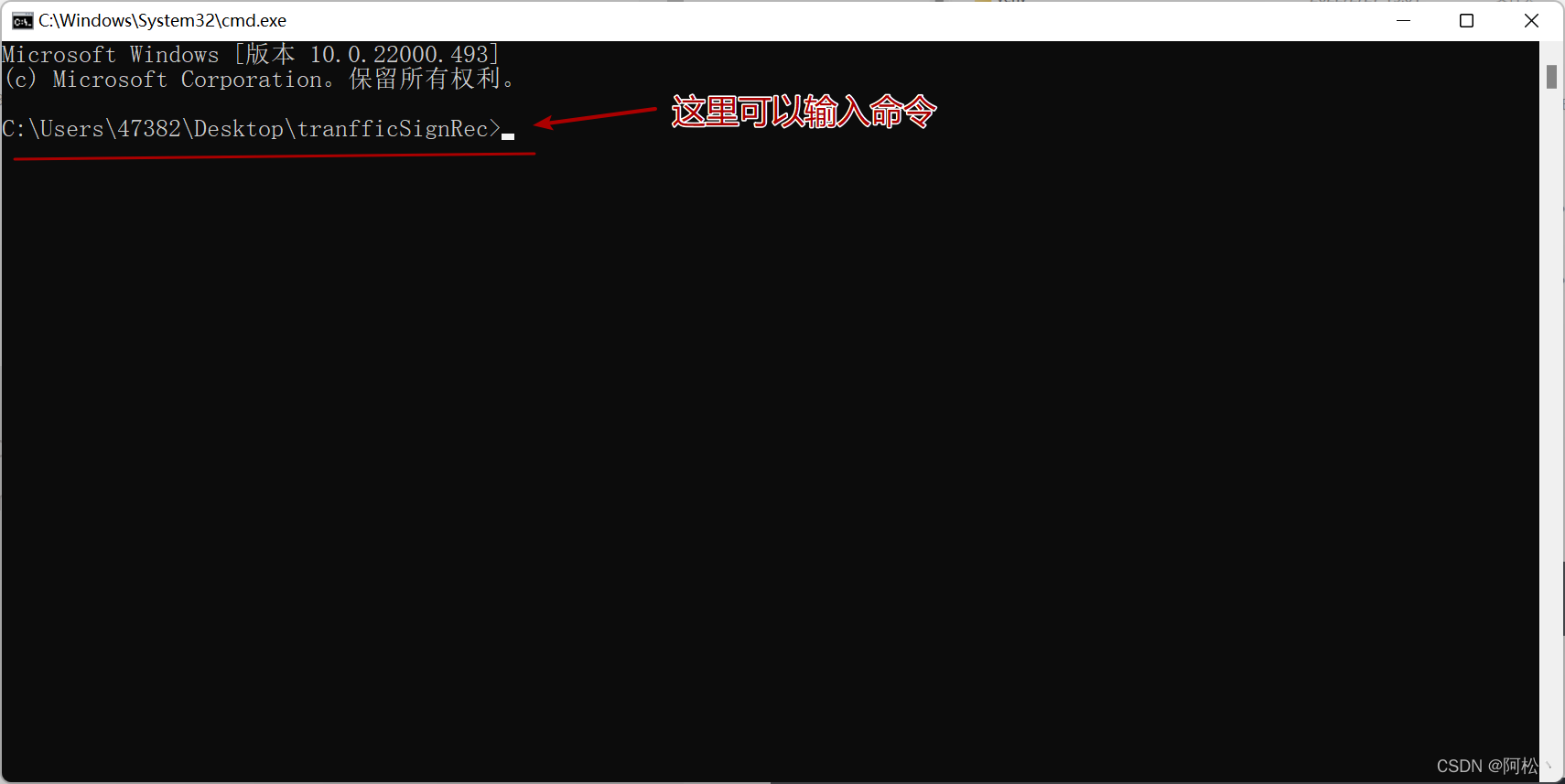
如果不放心,可以输入dir验证一下:
接下来我们开始虚拟环境的创建虚拟环境,并且安装本项目中python用到的第三方库
; 创建虚拟环境
conda create -n tranfficSignRec python=3.8
激活虚拟环境
activate tranfficSignRec
国内常用镜像源地址
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/
安装项目所需的包
安装格式如下( ==版本号可以省略)
pip install XXX==版本号 -i 镜像源地址
方案一
分别执行以下命令:
pip install tensorflow-cpu==2.5.0
pip install pandas==1.4.1
pip install matplotlib==3.5.1
pip install scikit-image==0.19.2
pip install playsound ==1.3.0
方案二
一步到位直接安装requirements.txt中所有的依赖包,确保requirements.txt文件在当前文件夹,如果不在当前文件夹就需要加上requirements.txt的路径。
pip install -r requirements.txt
用pycharm打开项目
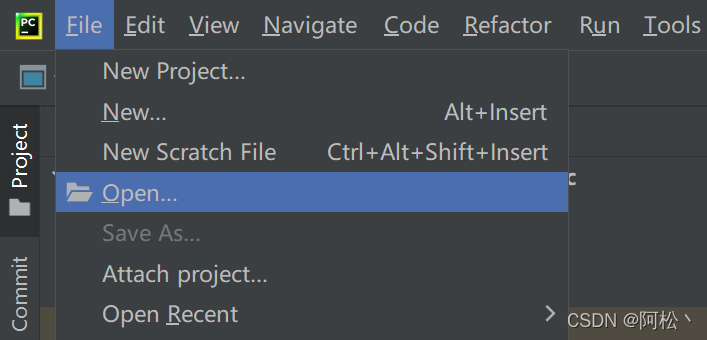
打开pycharm后鼠标在左上角找到File点击Open
选择项目所在路径,选择项目对应的文件夹点击打开。注意图片中文件夹下面的黑点表示之前打开过这个项目,相当于一个小标记,方便我们寻找自己的项目文件。
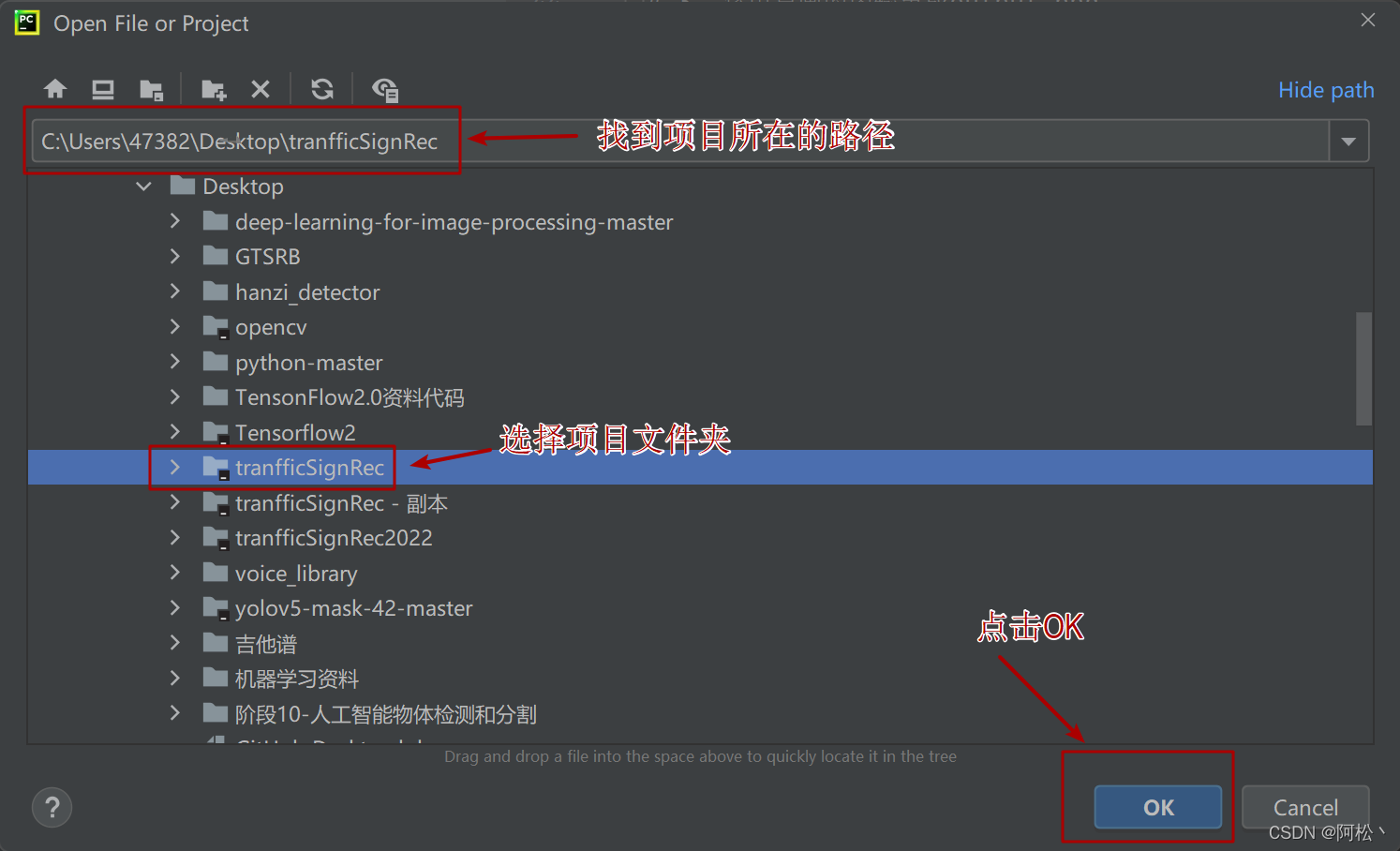
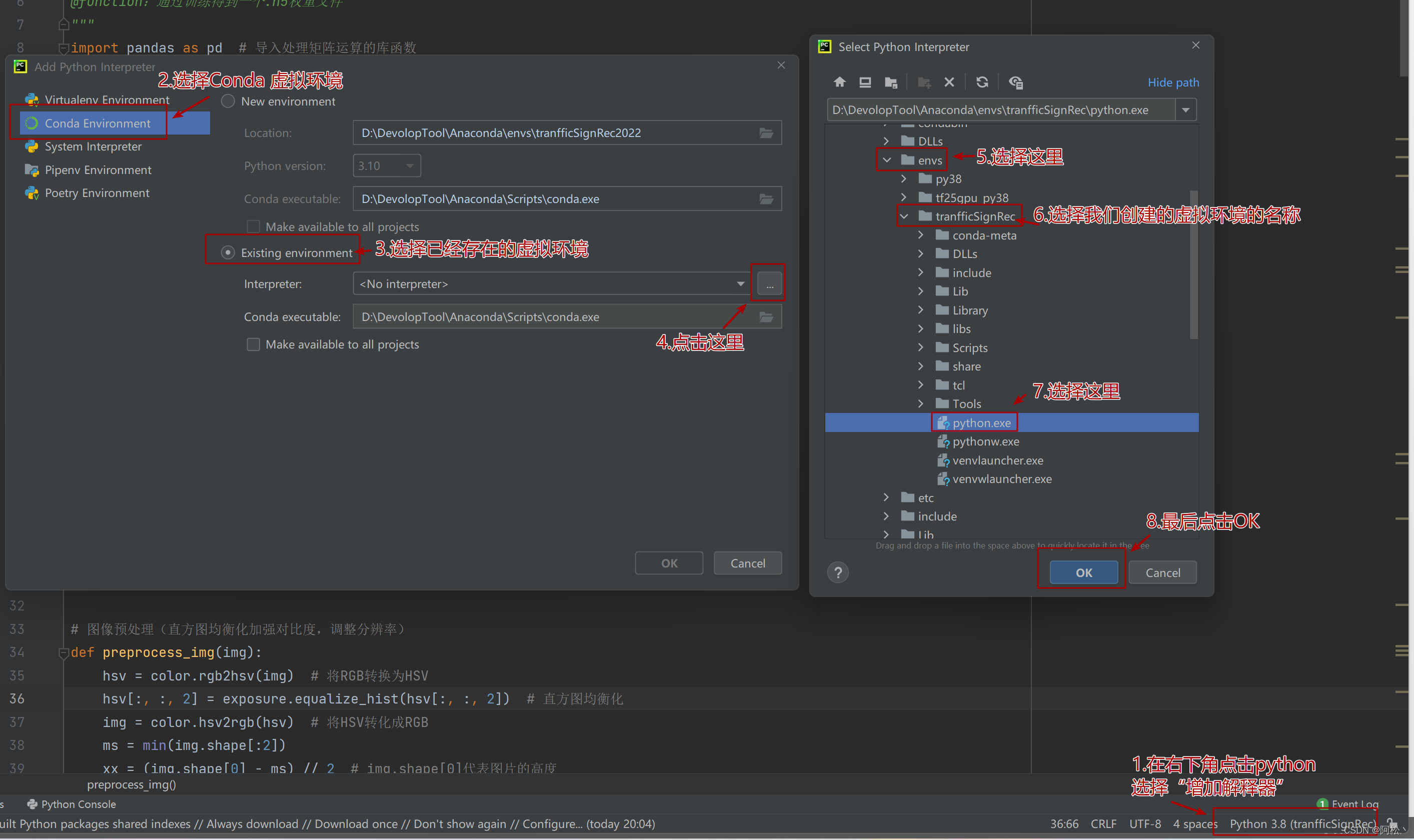
; 选择python解释器(也就是我们创建的虚拟环境)
运行代码
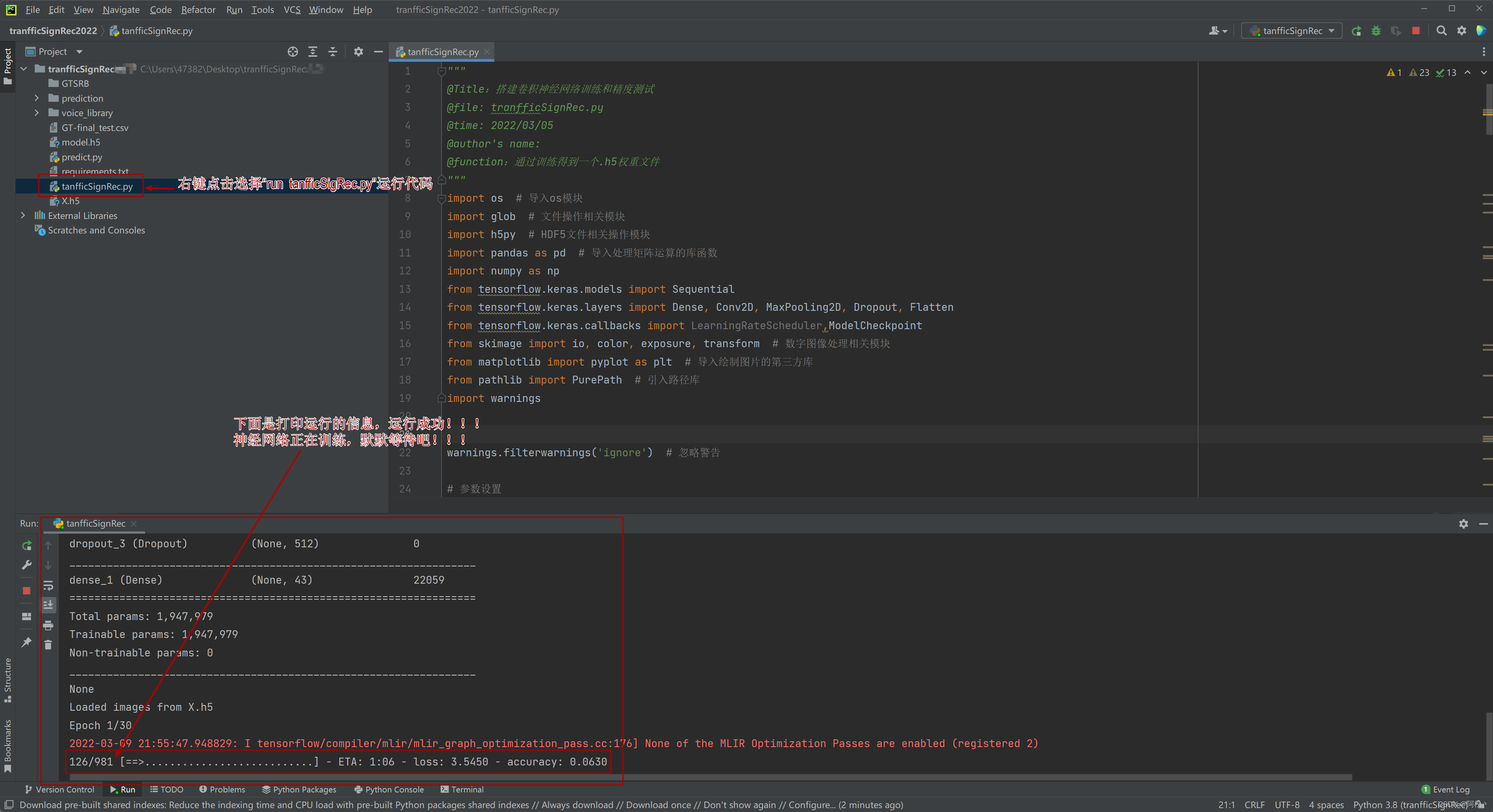
整个神经网络训练的过程大概需要"30分钟–3个小时",具体取决于你的电脑的性能。
; 预测部分的代码
在此之前简单科普一下Python中的正斜杠与反斜杠:
首先,"/"左倾斜是正斜杠,""右倾斜是反斜杠,可以记为:除号是正斜杠一般来说对于目录分隔符,Linux和Web用正斜杠/,Windows用反斜杠。
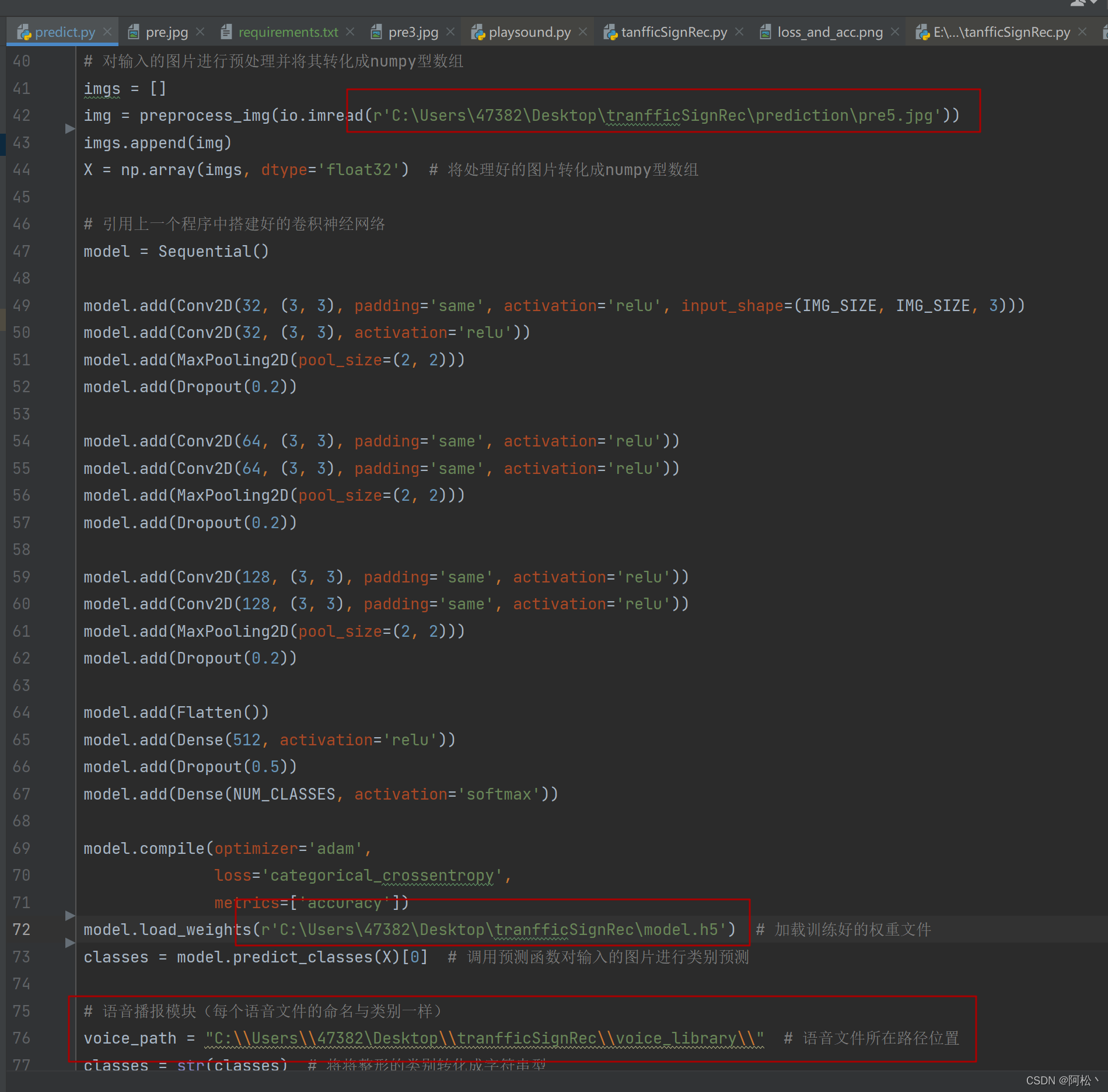
比如我们要用python读取windows电脑中的一张图片它的路径为C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg
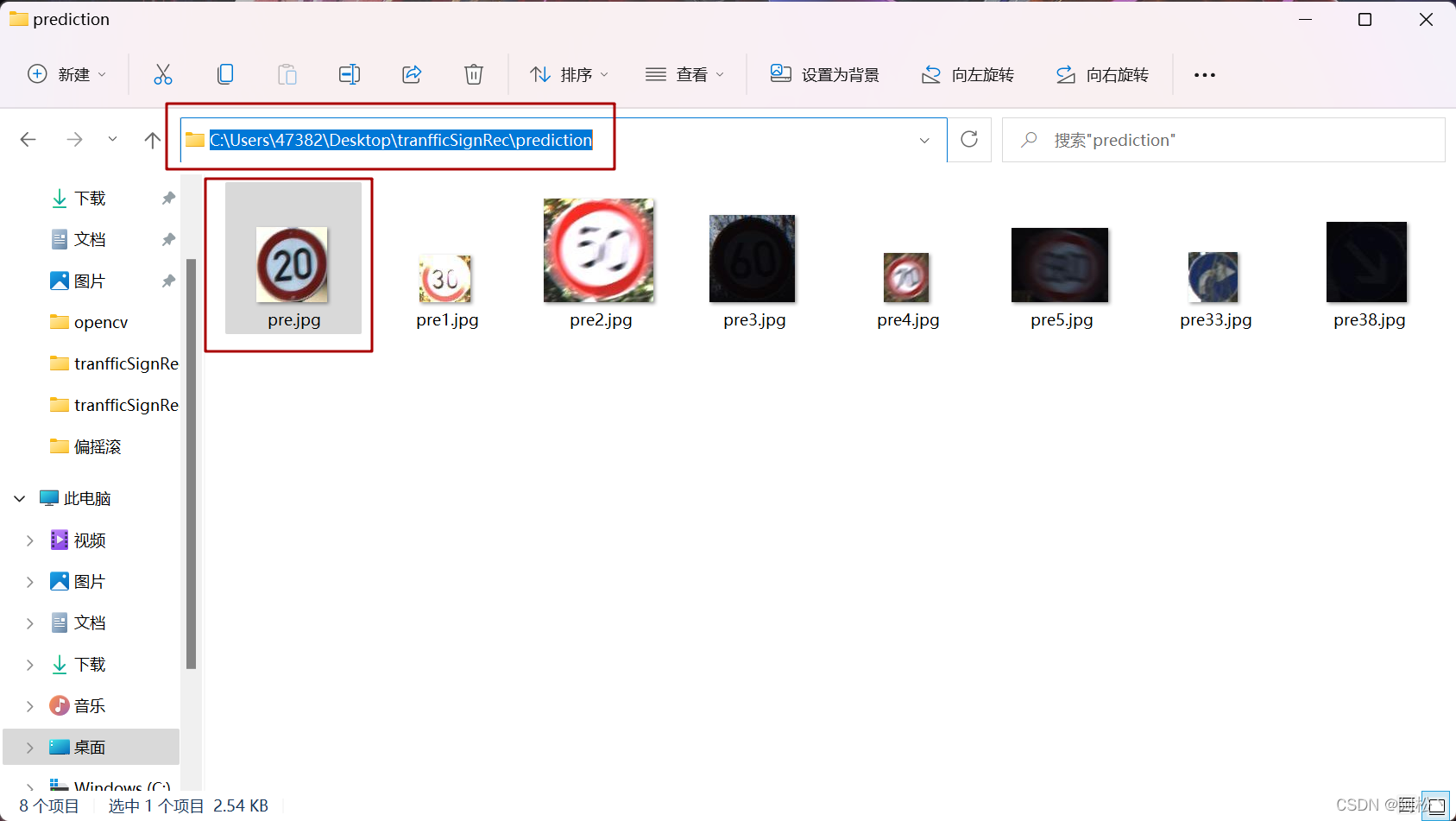
直接用path = "C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg"是会报错的。
因为python代码默认会对"\t"、"\r"等进行转义,正确方式如下:
path = "C:\\Users\\47382\\Desktop\\tranfficSignRec\\prediction\\pre.jpg"
path = r"C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg"
path = r"C:/Users/47382/Desktop/tranfficSignRec/prediction/pre.jpg"
用训练好的神经网络识别交通标志
关于语音提示功能
本项目额外的一个功能是识别出交通标志的同时给出语音提示。打开文件voice_library这个文件夹里面有对应(0-42)一共43个标志的语音提示。
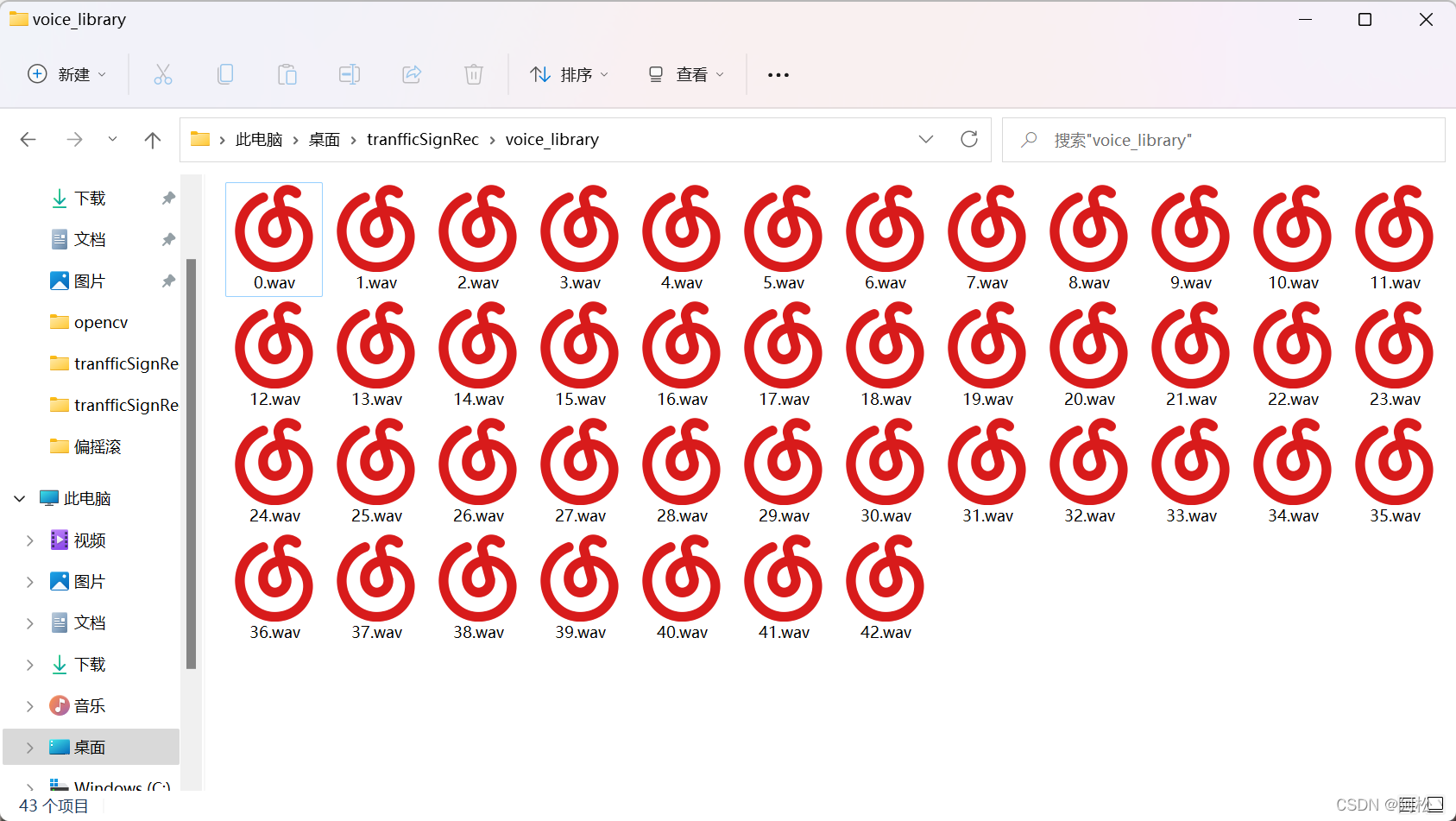
上图这(0-42)一共43个标志的语音提示,对应的就是下图的顺序。这个交通标志的语音提示,需要我们自己录一下(可以根据自己的喜好弄得有个性一点哦-),但是注意语音包的命名和格式需要跟上面保持一致。 命名是0-42,格式是wav格式。可以下载一个叫"格式工厂"的软件转化一下,很简单弄的。
然后还需要安装一个python的语音模块的第三方库:
pip install playsound ==1.3.0
如下图所示,我们用的数据集 德国的交通标志的数据集,所以你得先知道各个交通标志的含义,自己百度一下。

预测我们选择的一张交通标志
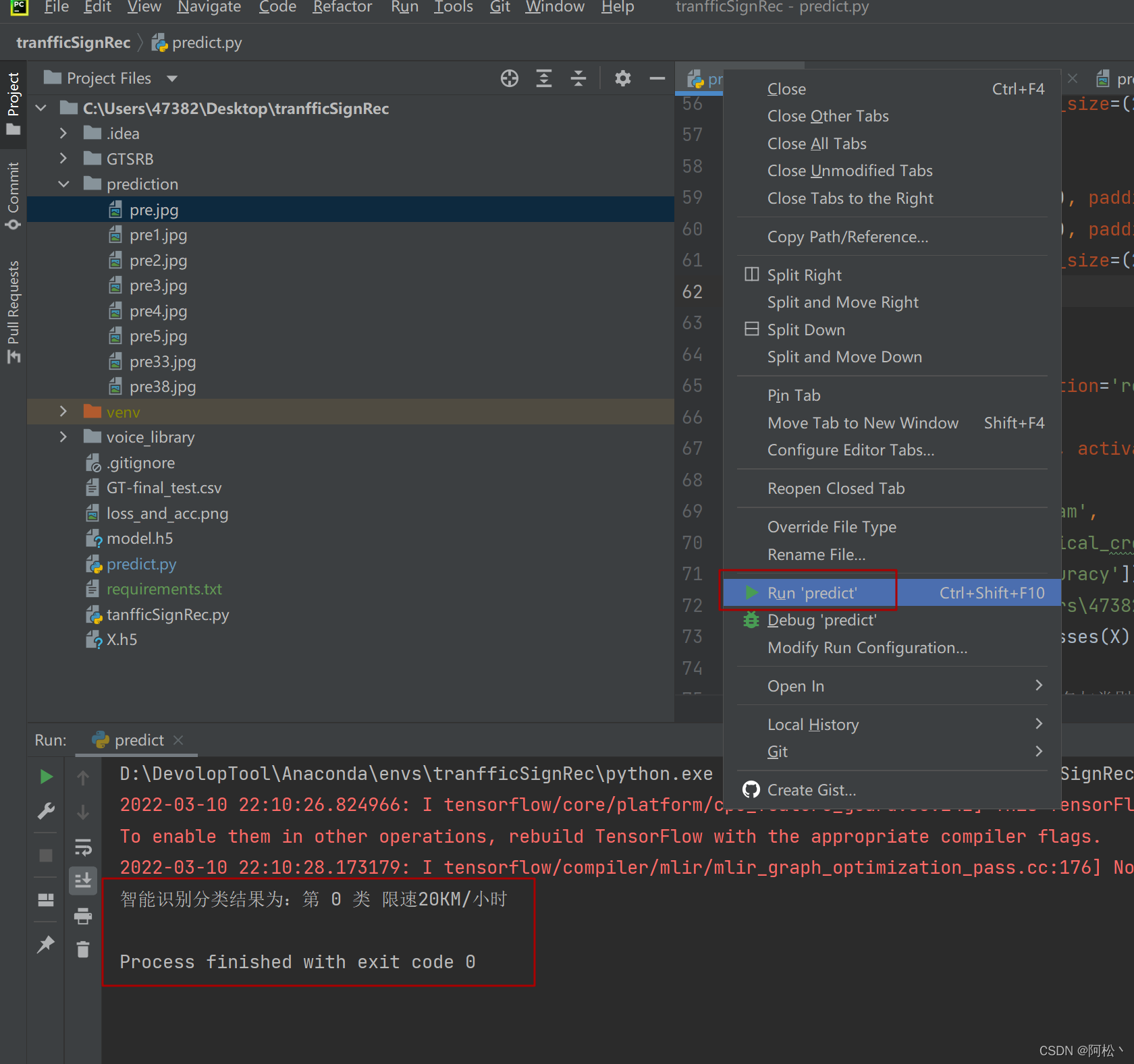
找一张交通标志图像(格式最好是jpg)将它放在prediction这个目录下面.
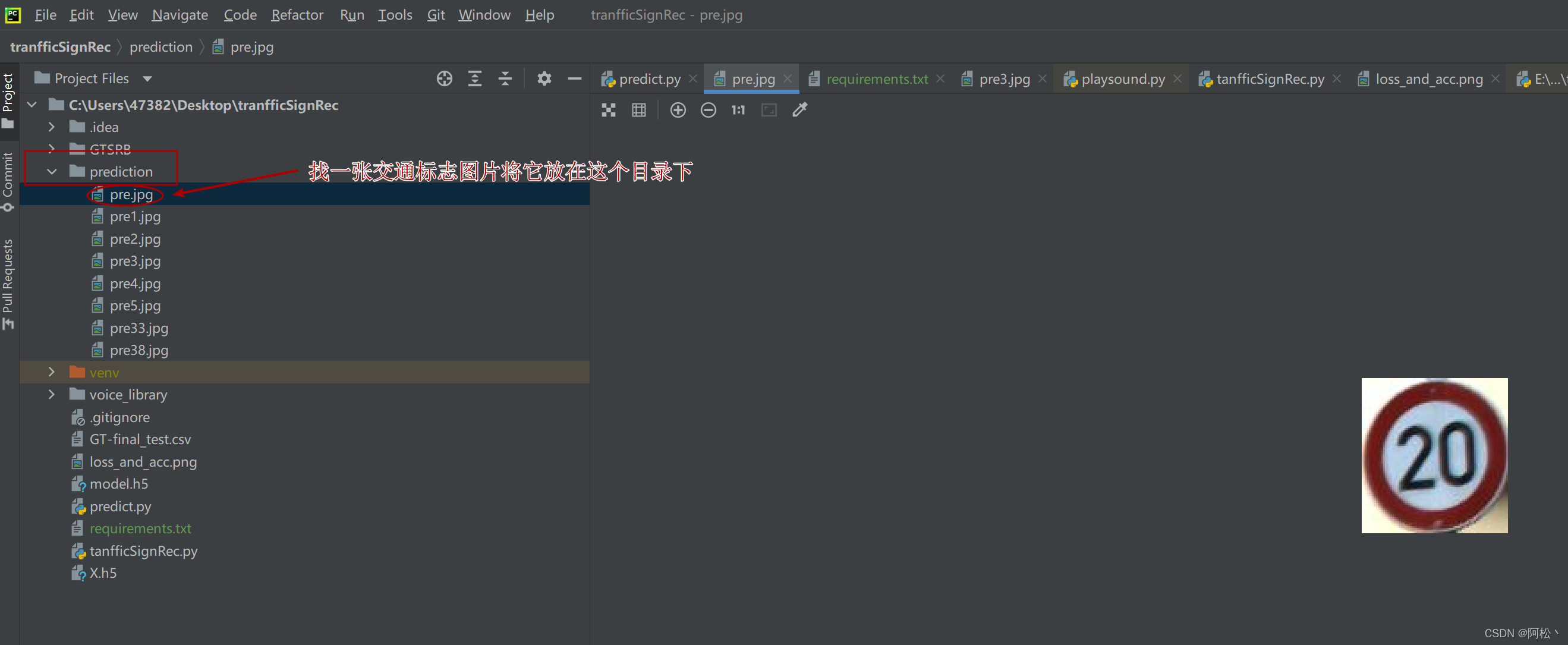
复制这个图片的路径:
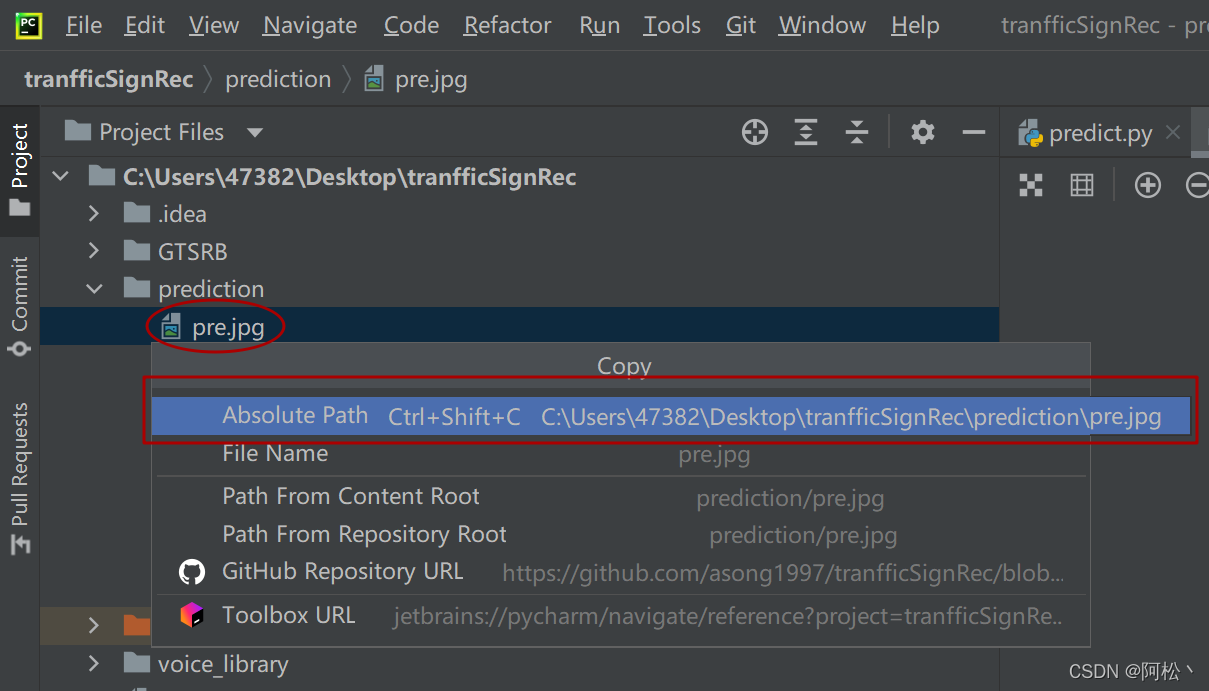
右击选择copy path选项,可以选择图片的绝对路径:
我这里是:C:\Users\47382\Desktop\tranfficSignRec\prediction\pre.jpg
用这中方法将代码predict.py里的路径换成自己实际的路径。然后运行就可以实现交通标志的识别和语音提示了。
; 点击运行
Original: https://blog.csdn.net/qq_34184505/article/details/123385851
Author: 阿松丶
Title: 交通标志识别项目教程
相关阅读1
Title: python3.6 import matplotlib pyparsing 包版本获取报错
python3.6 import matplotlib报错信息如下:
File "D:\python3.6\Lib\site-packages\pyparsing_ _init__.py", line 165, in
_ _version__ = version_info.version
AttributeError: 'version_info' object has no attribute 'version'
pyparsing 版本3.0.6
matplotlib 版本3.3.4
解决过程方法:
根据报错信息,找到文件:"D:\python3.6\Lib\site-packages\pyparsing_ _init__.py"
版本信息获取类:
class version_info(NamedTuple):
major: int
minor: int
micro: int
releaselevel: str
serial: int
@property
def __version__(self):
return "{}.{}.{}".format(self.major, self.minor, self.micro) + (
"{}{}{}".format(
"r" if self.releaselevel[0] == "c" else "",
self.releaselevel[0],
self.serial,
),
"",
)[self.releaselevel == "final"]
def __str__(self):
return "{} {} / {}".format(__name__, self.__version__, __version_time__)
def __repr__(self):
return "{}.{}({})".format(
__name__,
type(self).__name__,
", ".join("{}={!r}".format(*nv) for nv in zip(self._fields, self)),
)
经测试后发现类参数定义方式python3.6无法识别,对该方法按以下内容修改:
class version_info():
def __init__(self,major:int,minor:int,micro:int,releaselevel:str,serial:int):
self.major = major
self.minor = minor
self.micro = micro
self.releaselevel = releaselevel
self.serial = serial
@property
def __version__(self):
return "{}.{}.{}".format(self.major, self.minor, self.micro) + (
"{}{}{}".format(
"r" if self.releaselevel[0] == "c" else "",
self.releaselevel[0],
self.serial,
),
"",
)[self.releaselevel == "final"]
def __str__(self):
return "{} {} / {}".format(__name__, self.__version__, __version_time__)
def __repr__(self):
return "{}.{}({})".format(
__name__,
type(self).__name__,
", ".join("{}={!r}".format(*nv) for nv in zip(self._fields, self)),
)
替换原来方法,报错解决!
import matplotlib.pyplot as plt
x=np.arange(0,5,0.1)
y=x*0.04761905-1.19047619
plt.plot(x,y)
plt.show()
[Finished in 35.7s]

Original: https://blog.csdn.net/m0_37806296/article/details/121877683
Author: 菜鸟码农_ynuun
Title: python3.6 import matplotlib pyparsing 包版本获取报错
相关阅读2
Title: 景联文科技:语音识别技术有哪些应用场景?
近年来,全球各行各业都遭受了新冠疫情的冲击,越来越多的企业致力于研发新兴技术,为疫情防控做出贡献。目前市面上已经推出了一款语音识别智慧电梯系统,通过语音识别技术和电梯控制系统相结合,可有效地避免人们在乘用电梯时存在的接触感染风险。
什么是语音识别技术?
语音识别技术的目标就是将人类语音中的词汇内容转换为计算机可读的输入。
语音识别技术的原理就是让机器通过识别,把语音信号转变为文本,然后将理解转变为指令的技术。目的就是为了使机器能够"听懂"人在说什么,并作出相应的反应。

语音识别系统由声学识别模型和语言理解模型两部分组成,分别是对语音到音节和音节到字的计算。一个连续语音识别系统包含了特征提取、声学模型、语言模型和解码器这四个主要部分。
特征提取是指在除去语音信号中对于语音识别无用的信息后,保留能够反映语音本质特征的关键信息,对其进行处理,再用特定的形式表示出来,用于后续的进一步处理。
声学模型可以理解为是对声音进行建模,把语音输入转换为声学表示的输出。
语言模型是用来计算出一个句子出现概率的模型,简单来说,就是计算出这个句子在语法上是否正确的概率。
解码器就是指语音技术中的识别过程。
语音识别的本质就是一种模式识别的过程,将未知的语音模式与以知的语音模式进行对比,最佳匹配的参考模式就被视为识别结果。

语音识别技术的应用场景
语音输入
智能语音输入,可摆脱生僻字和拼音障碍,由实时语音识别实现,为用户节省输入时间、提升输入体验。
语音搜索
语音识别技术可用于语音搜索中,将搜索的内容直接以语音的方式输入,应用于手机搜索、网页搜索、车载搜索等多种搜索场景,很好地解放了人们的双手,让搜索变得更加高效。
语音指令
语音识别技术可用于语音指令中,不需要手动操作,可通过语音直接对设备或者软件发布命令,控制其进行操作,适用于视频网站、智能硬件等各大搜索场景。
社交聊天
语音识别技术可用于社交聊天中,直接用语音输入的方式转写成文字,让输入变得更快捷。或者在收到语音消息却不方便或者无法播放时,可直接将语音转换成文字进行查看,很好地满足了多样化的聊天场景,为用户提供了方便。
游戏娱乐
语音识别技术可用于游戏娱乐中,在游戏时,双手可能无法打字,语音输入可以将语音转换成文字,让用户在进行游戏娱乐的同时,也可直观地看到聊天内容,很好地满足了用户的多元化聊天需求。
字幕生成
语音识别技术可用于字幕生成中,可将直播和录播视频中的语音转换为文字,可以轻松便捷地生成字幕。
会议纪要
语音识别技术可用于撰写会议纪要中,将会议、庭审、采访等场景的音频信息转换为文字,通过实时语音识别及时实现,有效降低人工记录的成本、提升效率。

数据标注对语音识别技术的重要性
在语音识别技术中,基于动态时间规整(Dynamic Time Warping)的算法在连续语音识别中仍是主流方法。该方法的运算量较大,但技术上相对较简单,识别正确率高;基于非参数模型的矢量量化(VQ)的方法所需的模型训练数据,训练和识别的时间,工作存储空间都较小,在孤立字(词)语音识别系统中可以得到很好的应用。最后一种基于参数模型的隐马尔可夫模型(HMM)的方法主要被用在大词汇量的语音识别系统,它需要较多的模型以训练数据,需要较长的训练和识别时间,还需要较大的存储空间,一般连续隐马尔可夫模型要比离散隐马尔可夫模型的计算量要大,但识别率相比较高。
近年来,人工智能场景化应用不断发展,而实现人工智能的方法主要是以机器学习,尤其是以深度学习为主,在实际应用中,深度学习算法大多采用监督学习模式,对人工智能基础数据有着很强的依懒性。语音识别技术是人工智能技术中的一种,只有依托于海量且优质的数据来提高算法的准确性,才能使机器学习的质量达到最理想的效果。
可以说数据很大程度上决定了算法的准确性,也决定了语音识别技术落地的程度。
景联文科技为语音识别技术提供一站式数据解决方案
景联文科技作为一家专业的人工智能基础数据服务商,采集了《20小时麦克风采集射频噪音数据
集》、《1000人唤醒词麦克风语言数据集》、《21000段ASR语音转写数据集》等数据集,可直接提供给算法厂商用于算法研究。
景联文科技作为一家专业的数据采集标注公司,针对数据定制标注服务景联文科技建有先进的数据标注平台与成熟的标注、审核、质检机制,支持语音工程:语音切割、ASR语音转写、语音情绪判定、声纹识别标注等标注方法,可为语音识别技术提供数据支持。
此外,景联文科技在全国拥有四大标注基地,拥有全职标注团队900余人,为长三角地区规模最大的AI数据服务商。我们拥有自研数据标注平台和全品类标注工具,可全方位满足合作方各类数据标注需求。同时平台支持本地化部署,SAAS服务,甲方可直接通过后台进行在线质检和验收。景联文科技实行管家服务制,为每一位客户提供专属商务及项目经理,提前对项目进行部署,提前开始,提前交付,还可为客户加急需求提供24小时加班业务,尽力为客户提供高质量的一站式数据解决方案。
未来,景联文科技也将持续加强AI基础建设,不断提升企业级数智化运用能力搭建,继续助力人工智能应用的不断落地。
Original: https://blog.csdn.net/weixin_55551028/article/details/122502692
Author: 景联文科技
Title: 景联文科技:语音识别技术有哪些应用场景?
相关阅读3
Title: OpenCV-图像旋转Rotate
作者:翟天保Steven
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
功能函数
// 图像旋转
void Rotate(const cv::Mat &srcImage, cv::Mat &dstImage, double angle, cv::Point2f center, double scale)
{
cv::Mat M = cv::getRotationMatrix2D(center, angle, scale);//计算旋转的仿射变换矩阵
cv::warpAffine(srcImage, dstImage, M, cv::Size(srcImage.cols, srcImage.rows));//仿射变换
}
getRotationMatrix2D函数原型
getRotationMatrix2D用来获得旋转的仿射变换矩阵。
Mat getRotationMatrix2D(Point2f center, double angle, double scale);
getRotationMatrix2D参数说明
- Point2f类型的center,旋转中心。
- double类型的angle,逆时针旋转的角度。
- double类型的scale,图像旋转后的尺寸比例。
warpAffine函数原型
warpAffine用来仿射变换。
void warpAffine( InputArray src, OutputArray dst,
InputArray M, Size dsize,
int flags = INTER_LINEAR,
int borderMode = BORDER_CONSTANT,
const Scalar& borderValue = Scalar());
warpAffine参数说明
- InputArray类型的src,输入图像。
- OutputArray类型的dst,输出图像。
- InputArray类型的M,仿射变换矩阵。
- Size类型的dsize,输出图像的大小。
- int类型的flags,插值方法。
- int类型的borderMode,边界填充方法。
- const Scalar&类型的borderValue,边界填充数值。
C++测试代码
#include
#include
using namespace std;
using namespace cv;
// 图像旋转
void Rotate(const cv::Mat &srcImage, cv::Mat &dstImage, double angle, cv::Point2f center, double scale)
{
cv::Mat M = cv::getRotationMatrix2D(center, angle, scale);//计算旋转的仿射变换矩阵
cv::warpAffine(srcImage, dstImage, M, cv::Size(srcImage.cols, srcImage.rows));//仿射变换
}
int main()
{
// 载入图像
cv::Mat src = imread("0.jpg");
cv::Mat dst;
// 定义参数
int row = src.rows;
int col = src.cols;
double angle = 30;
cv::Point2f center(col / 2, row / 2);
double scale = 0.5;
// 图像旋转
Rotate(src, dst, angle, center, scale);
// 显示图像
imshow("src", src);
imshow("result", dst);
waitKey(0);
system("pause");
return 0;
}
测试效果

图1 原图

图2 旋转30°

图3 原图大小旋转45°
不难看出,旋转后原图的尺寸已经无法满足图像要求了,此时可以缩小比例,也可以扩展整图尺寸使其完全覆盖。
如果函数有什么可以改进完善的地方,非常欢迎大家指出,一同进步何乐而不为呢~
如果文章帮助到你了,可以点个赞让我知道,我会很快乐~加油!
Original: https://blog.csdn.net/zhaitianbao/article/details/124516085
Author: 翟天保Steven
Title: OpenCV-图像旋转Rotate