
No dashboards are active for the current data set.
Probable causes:
You haven't written any data to your event files.
TensorBoard can't find your event files.
If you're new to using TensorBoard, and want to find out how to add data and set up your event files, check out the README and perhaps the TensorBoard tutorial.
If you think TensorBoard is configured properly, please see the section of the README devoted to missing data problems and consider filing an issue on GitHub.
Last reload: Apr 18, 2021, 2:56:06 PM
Log directory: \logs
问题描述: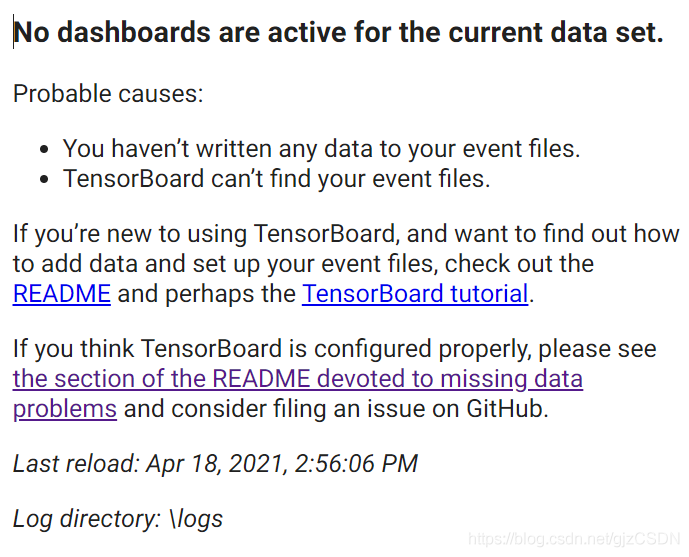
参照好多博客都没解决这个问题(查看端口,更新tensorboard版本,把=换成"",把6006换成其他端口,更改路径都试过,对我来说都没解决)
解决办法:
tensorboard --logdir="torch learning\logs"
也可以使用全局路径:"D:\pythonProject\torch learning\logs"
tensorboard --logdir="logs"
tensorboard --logdir='logs'
tensorboard --logdir=logs
tensorboard --logdir=\logs
tensorboard --logdir=D:\pythonProject\torch learning\logs
tensorboard --logdir="\logs"
tensorboard --logdir="torch learning\logs"
tensorboard --logdir="D:\pythonProject\torch learning\logs"
总结:这个问题搞了好几个小时,很是头疼,不知道因为版本问题还是什么问题,用双引号(单引号不行)""引号里面写logs的路径,如果只索引logs需要在前面加上\
Original: https://blog.csdn.net/gjzCSDN/article/details/115830082
Author: 西域虎鲸
Title: Tensorboard --logdir=logs 无法显示图像的处理办法,亲测有效!
相关阅读1
Title: 目标检测数据集标注文件统计并可视化--yolov5
坚持写博客💪,分享自己的在学习、工作中的所得
- 给自己做备忘
- 对知识点记录、总结,加深理解
- 给有需要的人一些帮助,少踩一个坑,多走几步路
尽量以合适的方式排版,图文兼有
如果写的有误,或者有不理解的,均可在评论区留言
如果内容对你有帮助,欢迎点赞 👍 收藏 ⭐留言 📝。
虽然平台并不会有任何奖励,但是我会很开心,可以让我保持写博客的热情🙏🙏🙏
文章目录
🧁统计标注文件
使用代码对数据集进行统计,可以对数据集进行可视化,得到一些有用的信息
使用的数据集标注格式时yolo格式的
# 坐标格式:
# VOC: [x_min, y_min, x_max, y_max] 左上角和右下角
# COCO: [x_min, y_min, width, height] 左上角和宽高
# YOLO: [x_center, y_center, width, height] 归一化的中心点和宽高
import os
import random
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sn
from glob import glob
from PIL import Image, ImageDraw
category = ['class1', 'class2', 'class3', ..., 'class100']
num_classes = len(category)
colors = [(random.randint(0,255),random.randint(0,255),random.randint(0,255)) for _ in range(num_classes)]
这部分代码来自yolov5,已经做了初步修改:
def plot_labels(labels, names=(), save_dir=''):
print('Plotting labels... ')
c, b = labels[:, 0], labels[:, 1:].transpose()
nc = int(c.max() + 1)
x = pd.DataFrame(b.transpose(), columns=['x', 'y', 'width', 'height'])
sn.pairplot(x, corner=True, diag_kind='auto', kind='hist', diag_kws=dict(bins=50), plot_kws=dict(pmax=0.9))
plt.savefig(os.path.join(save_dir, 'labels_correlogram.jpg'), dpi=200)
plt.close()
matplotlib.use('svg')
ax = plt.subplots(2, 2, figsize=(8, 8), tight_layout=True)[1].ravel()
y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)
ax[0].set_ylabel('instances')
if 0 < len(names) < 30:
ax[0].set_xticks(range(len(names)))
ax[0].set_xticklabels(names, rotation=90, fontsize=10)
else:
ax[0].set_xlabel('classes')
sn.histplot(x, x='x', y='y', ax=ax[2], bins=50, pmax=0.9)
sn.histplot(x, x='width', y='height', ax=ax[3], bins=50, pmax=0.9)
labels[:, 1:3] = 0.5
labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * 2000
img = Image.fromarray(np.ones((2000, 2000, 3), dtype=np.uint8) * 255)
for cls, *box in labels[:1000]:
ImageDraw.Draw(img).rectangle(box, width=1, outline=colors[int(cls)])
ax[1].imshow(img)
ax[1].axis('off')
for a in [0, 1, 2, 3]:
for s in ['top', 'right', 'left', 'bottom']:
ax[a].spines展开收缩.set_visible(False)
plt.savefig(os.path.join(save_dir, 'labels.jpg'), dpi=200)
matplotlib.use('Agg')
plt.close()
def xywh2xyxy(x):
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
return y
all_files = glob(r'path\to\labels\*.txt')
shapes = []
ids = []
for file in all_files:
if file.endswith('classes.txt'):
continue
with open(file, 'r') as f:
for l in f.readlines():
line = l.split()
ids.append([int(line[0])])
shapes.append(list(map(float, line[1:])))
shapes = np.array(shapes)
ids = np.array(ids)
lbs = np.hstack((ids, shapes))
plot_labels(labels=lbs, names=np.array(category))
解释一下 rectangles部分:代码中的注释 rectangles,对应 labels.jpg的第二个子图。
因为标注数据时归一化过的,将所有标注框的中心点设置为 (0.5, 0.5),将图片宽高设置为 2000 x 2000,并且只对前1000个框进行可视化,如果全部可视化的话,数据太大就会密密麻麻一团黑。
labels.jpg
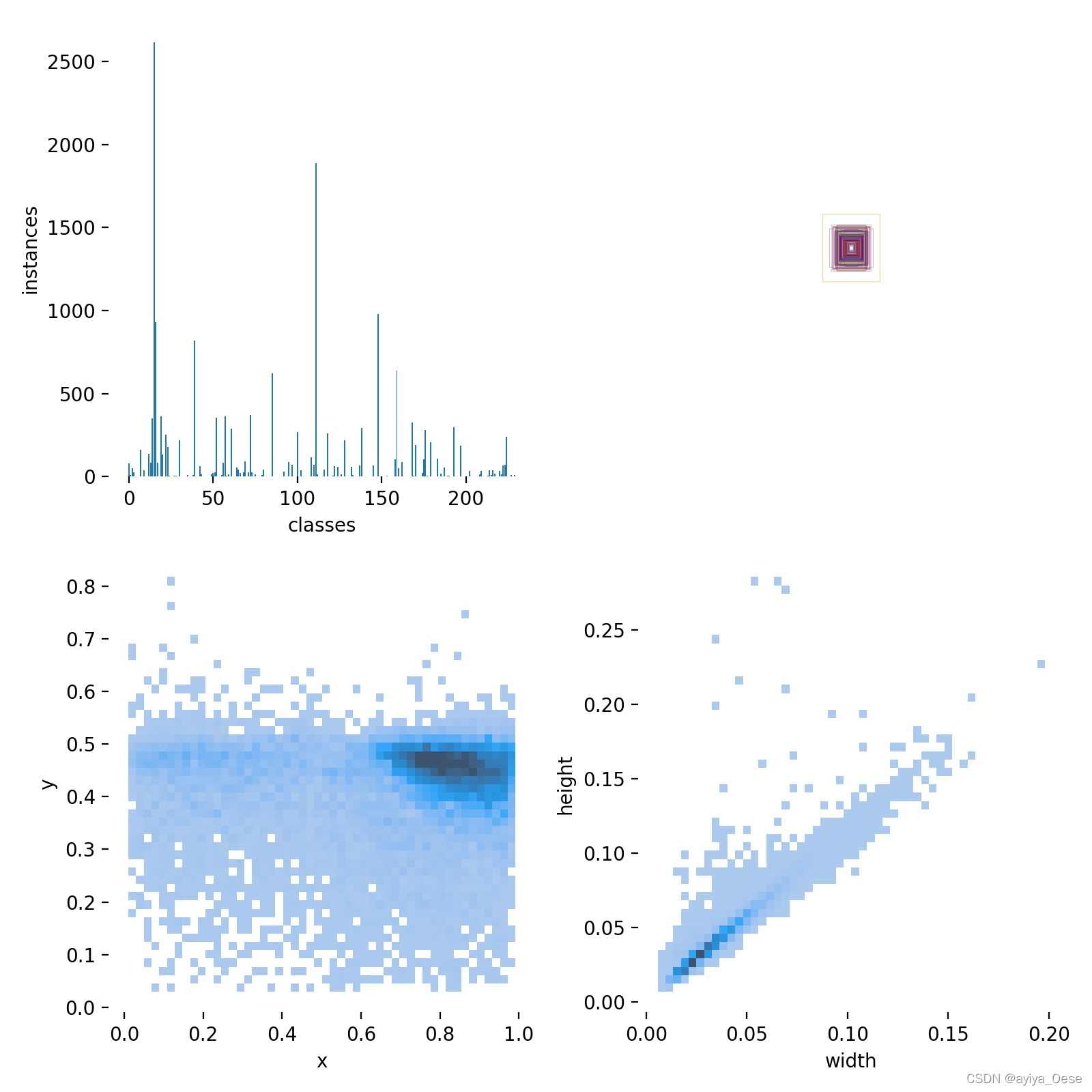
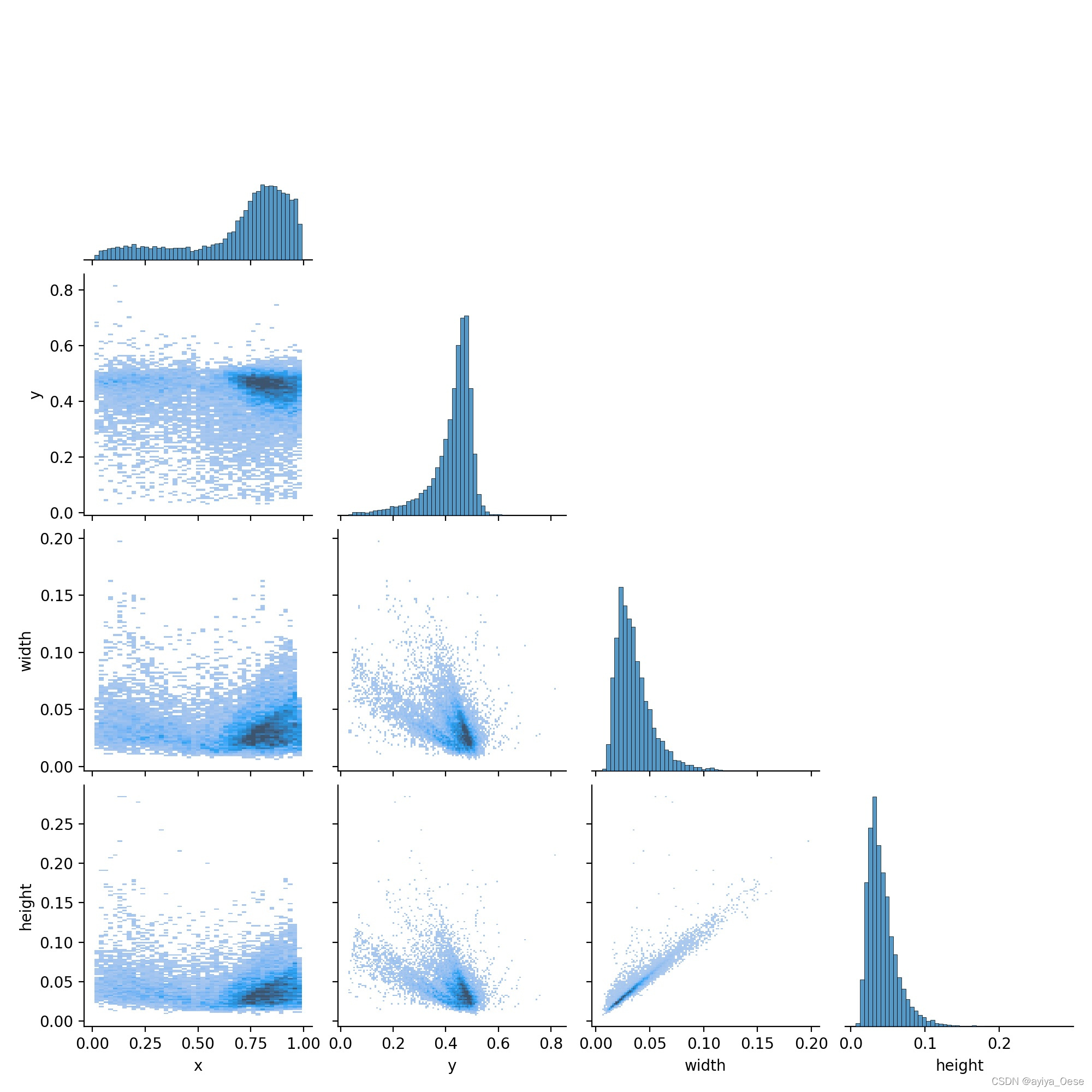
labels_correlogram.jpg
🧁修改rectangles部分
如果图片都是同样宽高的情况下, rectangles部分可以像下面修改
labels[:, 1:] = xywh2xyxy(labels[:, 1:]) * np.array([width, height, width, height])
img = Image.fromarray(np.ones((height, width, 3), dtype=np.uint8) * 255)
如下图,这样可以清楚看出目标在标注文件中的空间分布
labels.jpg
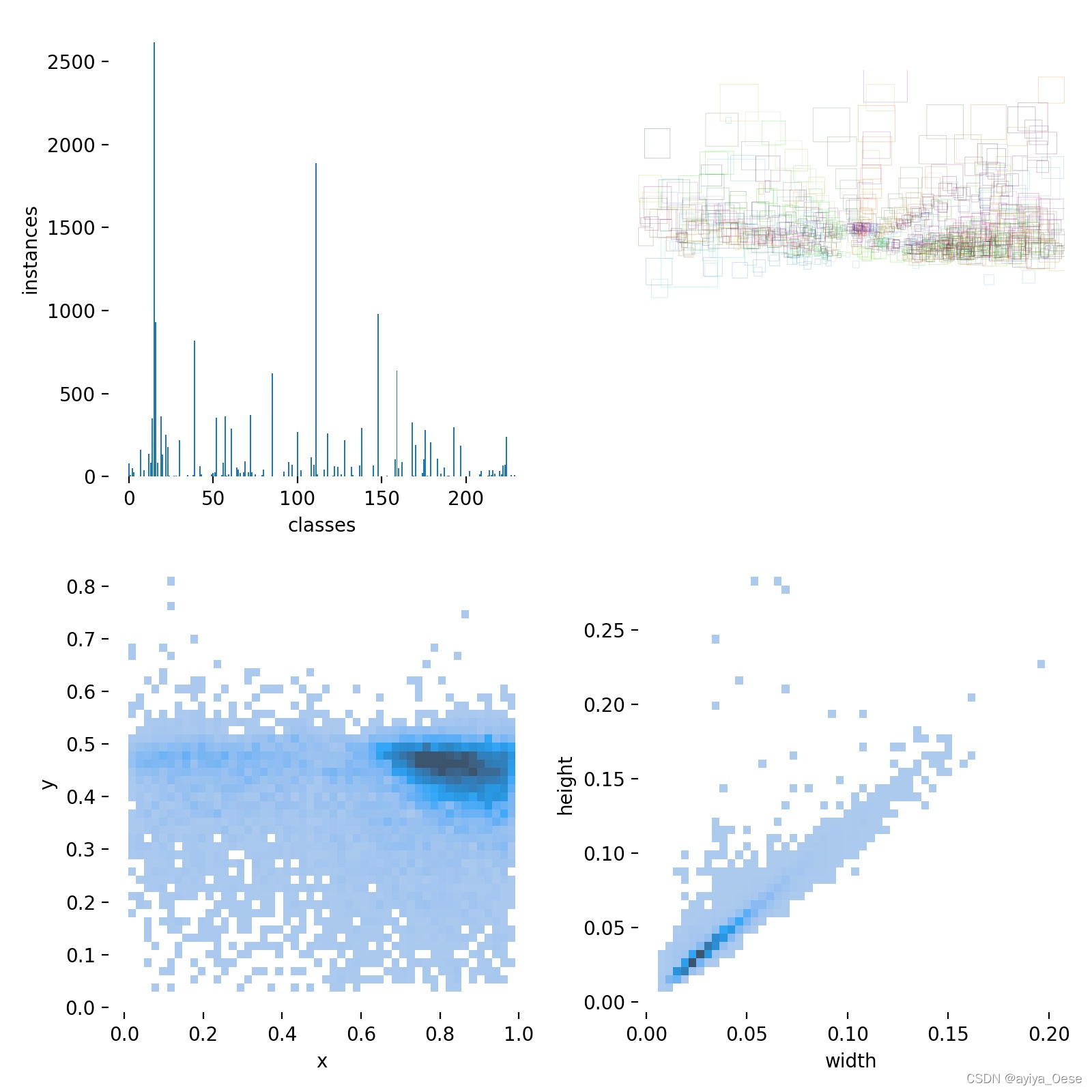
🧁保存到Excel
在上面的 plot_labels函数中 y = ax[0].hist(c, bins=np.linspace(0, nc, nc + 1) - 0.5, rwidth=0.8)之后添加:
data = {'category':names, 'nums':y[0]}
df0 = pd.DataFrame(data)
df0.to_excel(os.path.join(save_dir, 'labels.xlsx'), na_rep=False)
即可将每个类别的实例数量保存到文件中,因为类别多的时候,光看直方图并不容易准确知道每个类别的实例数量。
在我的数据集,由于有些类别还没有实例,按照上面的代码会出现 category和 nums维度不匹配的情况。可以修改:
nc = len(names)
如果内容对你有帮助,或者觉得写的不错
🏳️🌈欢迎点赞 👍 收藏 ⭐留言 📝
有问题,请在评论区留言Original: https://blog.csdn.net/ayiya_Oese/article/details/121681701
Author: ayiya_Oese
Title: 目标检测数据集标注文件统计并可视化--yolov5
相关阅读2
Title: 行为型设计模式(中)
中介者模式:
1、定义:用一个中介对象来 封装一系列的 对象交互,中介者使各对象不需要显式地相互引用,
从而使其 耦合松散,而且可以独立地改变它们之间的交互
2、模型结构:
(1)抽象中介者(Mediator):它是中介者的 接口,提供了同事对象注册与转发同事对象信息的抽象方法
(2)具体中介者(ConcreteMediator):实现中介者接口,通过一个数据结构来 管理同事对象,
协调各个同事角色之间的交互关系,因此它 依赖于同事角色
(3)抽象同事类(Colleague):定义同事类的接口, 保存中介者对象,提供同事对象交互的抽象方法,
实现所有相互影响的同事类的公共功能
(4)具体同事类(Concrete Colleague):抽象同事类的实现者,当与其他同事对象交互时,中介者对象负责后续的交互
3、优点:
(1) 降低了对象之间的 耦合性,使得对象易于独立地被复用
(2)将对象间的一对多关联转变为一对一的关联,提高系统的 灵活性,使得系统易于维护和扩展
(3) 减少子类生成
4、缺点:当同事类太多时, 中介者的职责将很大,它会变得复杂而庞大,以至于系统难以维护
5、适用环境:
(1)当对象之间存在 复杂的网状结构关系而导致依赖关系 混乱且 难以复用时
(2)当想创建一个运行于多个类之间的对象,又不想生成新的子类时
备忘录模式:
1、定义:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外 保存这个状态,
以便以后当需要时能将该对象 恢复到原先保存的状态
2、模型结构:
(1)发起人(Originator):记录当前时刻的内部状态信息, 提供创建备忘录和恢复备忘录数据的功能,
实现其他业务功能,它可以访问备忘录里的所有信息
(2)备忘录(Memento):负责 存储发起人的内部状态,在需要的时候提供这些内部状态给发起人
(3)管理者(Caretaker):管理备忘录,提供 保存与获取备忘录的功能,但其 不能对备忘录的内容进行 访问与修改
3、优点:
(1)提供了一种可以 恢复状态的机制:当用户需要时能够比较方便地将数据恢复到某个历史的状态
(2)实现了 内部状态的封装:除了创建它的发起人之外,其他对象都不能够访问这些状态信息
(3) 简化了发起人类:发起人不需要管理和保存其内部状态的各个备份,所有状态信息都保存在备忘录中,
并由管理者进行管理,这符合单一职责原则
4、缺点:资源消耗大,如果要保存的内部状态信息过多或者特别频繁,将会占用比较大的内存资源
5、适用环境:
(1)需要 保存与恢复数据的场景
(2)需要提供一个 可回滚操作的场景
观察者模式:
1、定义:定义对象间的一种 一对多依赖关系,使得每当一个对象状态发生改变时,
其相关依赖对象皆得到通知并被 自动更新
2、模型结构:
(1)抽象目标(Subject):提供了一个用于 保存观察者对象的聚集类和增加、删除观察者对象的方法,
以及 通知所有观察者的抽象方法
(2)具体目标(Concrete Subject):它 实现抽象目标中的通知方法,当具体目标的内部状态发生改变时,
通知所有注册过的观察者对象
(3)抽象观察者(Observer):它是一个抽象类或接口,它包含了一个 更新自己的抽象方法,
当接到具体主题的更改通知时被调用
(4)具体观察者(Concrete Observer):实现抽象观察者中定义的抽象方法
3、优点:
(1)降低了目标与观察者之间的耦合关系,两者之间是 抽象耦合关系
(2)目标与观察者之间建立了一套 触发机制
4、缺点:
(1)目标与观察者之间的依赖关系并没有完全解除,而且有可能出 现循环引用
(2)当观察者对象很多时,通知的发布会花费很多时间, 影响程序的效率
5、适用环境:
(1)对象间存在 一对多关系,一个对象的状态发生改变会影响其他对象
(2)当一个抽象模型有两个方面,其中 一个方面依赖于另一方面时,
可将这二者封装在独立的对象中以使它们可以各自独立地改变和复用
状态模式:
1、定义:对有状态的对象,把复杂的"判断逻辑"提取到不同的状态对象中,
允许状态对象在其内部状态发生改变时改变其行为
2、模型结构:
(1)环境(Context):也称为上下文,它定义了客户感兴趣的接口, 维护一个当前状态,
并将与状态相关的操作委托给当前状态对象来处理
(2)抽象状态(State):定义一个接口,用以 封装环境对象中的 特定状态所对应的行为
(3)具体状态(Concrete State): 实现抽象状态所对应的行为
3、优点:
(1)状态模式将与特定状态相关的行为 局部化到一个状态中,并将不同状态的行为分割开,满足 "单一职责原则"
(2)将不同的状态引入独立的对象中会使得 状态转换变得更加 明确,且 减少对象间的 相互依赖
(3)有利于 程序的扩展,通过定义新的子类很容易地增加新的状态和转换
4、缺点:
(1)状态模式的使用必然会 增加系统类和对象的个数
(2)状态模式的结构与实现都 较为复杂,如果使用不当将导致程序结构和代码的混乱
5、适用环境:
(1)当一个对象的行为取决于它的状态,并且它必须在 运行时根据状态改变它的行为时,就可以考虑使用状态模式
(2)一个操作中含有 庞大的分支结构,并且这些分 支决定于对象的状态时
Original: https://www.cnblogs.com/lemonyam/p/11623568.html
Author: 贵志
Title: 行为型设计模式(中)
相关阅读3
Title: 【CUDA基础练习】向量内积计算的若干种方法
先从一个简单,直观的方法来了解如何用CUDA计算向量内积。向量内积既然是将两个向量对应元素相乘的结果再求和,我们先考虑将对应元素相乘并行化,再来考虑相加。
【方法一】
#include
#include
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "error.cuh"
#define VECTOR_LENGTH 10000
__global__ void vec_product(float *out, float *vec_a, float *vec_b, int n)
{
extern __shared__ float temp[];
int idx = threadIdx.x;
int stride = blockDim.x;
for (int i=idx; i>>(d_out, d_a, d_b, VECTOR_LENGTH);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("time cost: %.3f\n", elapsed_time);
cudaMemcpy(out,d_out,sizeof(float),cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
printf("vector product: %f\n", *out);
free(a);
free(b);
free(out);
cudaFree(a);
cudaFree(b);
cudaFree(out);
return 0;
}
方法一中网格大小为1,线程块的大小根据由cudaOccupancyMaxPotentialBlockSize计算得到,对于这个简单示例来说,你也可以自己定义一个线程块的大小,一个线程块中的线程并行地执行。上述代码中,从头至尾只有一个线程块在运行。对于大小为N的向量,第1个线程处理第0,blocksize,2blocksize,....号位置上的元素,第2个线程处理第1,1+blocksize,1+2blocksize,...号位置上的元素。对应元素的乘积结果保存在一个长度为N的共享内存上面。等线程块内的所有线程完成乘机运算后,在第一个线程上将沉积的结果加起来并返回结果。
【nvpro测试】
==5245== NVPROF is profiling process 5245, command: ./sample_v1
minGridSize:16,blockSize:1024
time cost: 0.116
vector product: 40000.000000
==5245== Profiling application: ./sample_v1
==5245== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 88.81% 53.821us 1 53.821us 53.821us 53.821us vec_product(float*, float*, float*, int)
9.08% 5.5030us 2 2.7510us 2.6550us 2.8480us [CUDA memcpy HtoD]
2.11% 1.2800us 1 1.2800us 1.2800us 1.2800us [CUDA memcpy DtoH]
API calls: 99.74% 273.58ms 3 91.195ms 4.9430us 273.57ms cudaMalloc
0.10% 262.02us 97 2.7010us 252ns 104.97us cuDeviceGetAttribute
0.07% 195.46us 1 195.46us 195.46us 195.46us cuDeviceTotalMem
0.02% 58.494us 3 19.498us 13.723us 29.006us cudaMemcpy
0.02% 50.682us 1 50.682us 50.682us 50.682us cudaEventSynchronize
0.02% 45.974us 1 45.974us 45.974us 45.974us cuDeviceGetName
0.01% 28.094us 1 28.094us 28.094us 28.094us cudaLaunchKernel
0.01% 17.564us 1 17.564us 17.564us 17.564us cuDeviceGetPCIBusId
0.00% 9.0360us 2 4.5180us 815ns 8.2210us cudaEventCreate
0.00% 7.9480us 2 3.9740us 3.8540us 4.0940us cudaEventRecord
0.00% 4.2820us 1 4.2820us 4.2820us 4.2820us cudaFuncGetAttributes
0.00% 3.3040us 1 3.3040us 3.3040us 3.3040us cudaDeviceSynchronize
0.00% 3.2010us 3 1.0670us 609ns 1.9100us cudaFree
0.00% 3.1560us 4 789ns 418ns 1.6510us cudaDeviceGetAttribute
0.00% 2.5620us 3 854ns 353ns 1.4010us cuDeviceGetCount
0.00% 1.8870us 1 1.8870us 1.8870us 1.8870us cudaEventElapsedTime
0.00% 1.6540us 1 1.6540us 1.6540us 1.6540us cudaOccupancyMaxActiveBlocksPerMultiprocessorWithFlags
0.00% 1.6410us 1 1.6410us 1.6410us 1.6410us cudaEventQuery
0.00% 1.5970us 2 798ns 430ns 1.1670us cuDeviceGet
0.00% 1.2450us 1 1.2450us 1.2450us 1.2450us cudaGetDevice
0.00% 506ns 1 506ns 506ns 506ns cuDeviceGetUuid
上面这种方法局限性很大。首先,CUDA中规定了一个线程块中的线程数量不能超过1024,所以你最多也就并行计算1024个位置上的数组对应元素的相乘。此外,一个线程块中可用的共享内存也是受限的,这种方法要求一个线程块中至少要sizeof(float)N大小的共享内存,当数组长度更大是,会存在资源不足。所以,怎么把它扩展到多个block?可以考虑对数组按blockSize进行切分,如:[0,....blockSize-1],[blockSize,...,2blockSize-1]....由多个block分别并行计算,方法二给出了核心代码。
【方法二】
#include
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "error.cuh"
#define VECTOR_LENGTH 10000
__global__ void vector_product(float *out, float *vec_a, float *vec_b, int N)
{
const int stride = blockDim.x;
const int tid = threadIdx.x;
const int idx = blockIdx.x*blockDim.x+ threadIdx.x;
extern __shared__ float s_y[];
s_y[tid] = (idx < N) ? vec_a[idx] * vec_b[idx] : 0.0;
if (tid == 0)
{
float sum=0;
for (int i=0; i>>(d_out, d_a, d_b, VECTOR_LENGTH);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("time cost: %.3f\n", elapsed_time);
cudaMemcpy(out,d_out,sizeof(float),cudaMemcpyDeviceToHost);
cudaDeviceSynchronize();
printf("vector product: %f\n", *out);
free(a);
free(b);
free(out);
cudaFree(a);
cudaFree(b);
cudaFree(out);
return 0;
}
【nvprof测试】
```
==26432== NVPROF is profiling process 26432, command: ./sample_v1_1
GPU has cuda devices: 1
Original: https://blog.csdn.net/ChuiGeDaQiQiu/article/details/121941434
Author: 昌山小屋
Title: 【CUDA基础练习】向量内积计算的若干种方法