
问题描述:用tensorflow环境运行jupyter时显示没有skimage包:no module named 'skimage',用conda终端下载skimage包
activate tensorflow39(我的虚拟环境名字)
conda install skimage
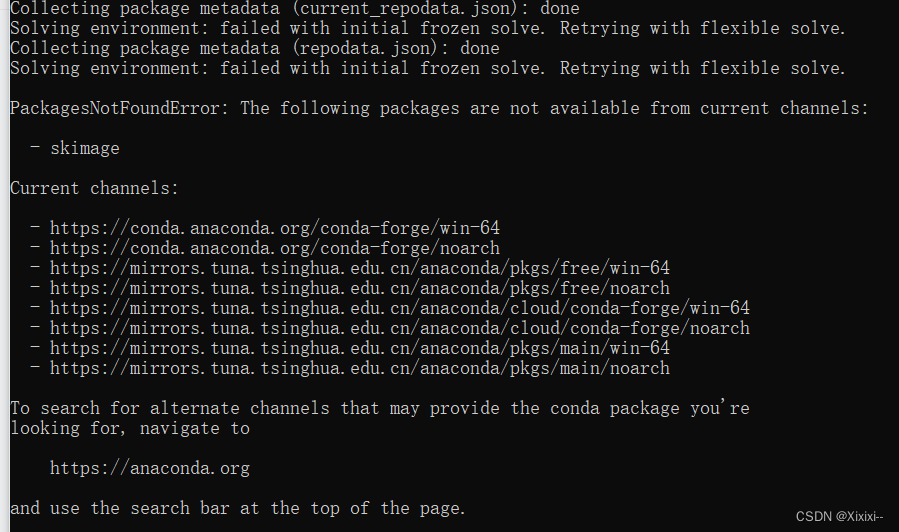
显示:
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
PackagesNotFoundError: The following packages are not available from current channels:
- skimage
尝试方法如下:没有用
conda config --add channels conda-forge
而后发现最简单的方法是在anaconda3中直接操作:
- 打开anaconda3
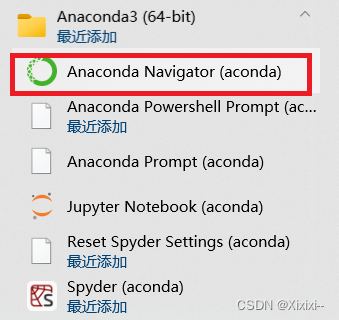
- 切换到你要下载包的环境
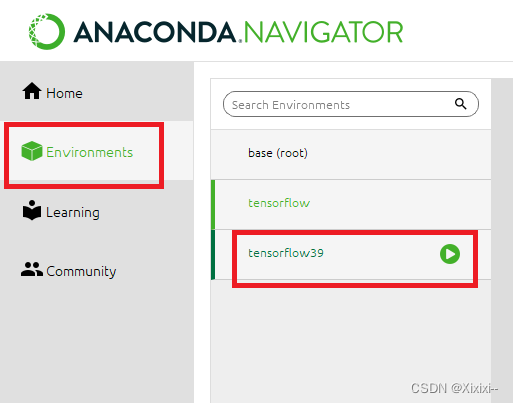
- 选择not install
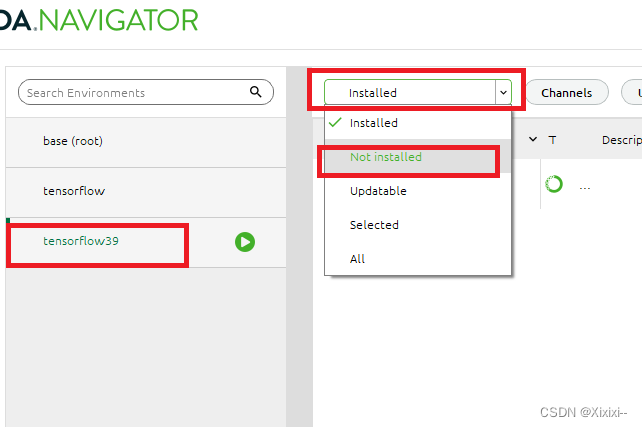
- 右上角搜索你要下载的包
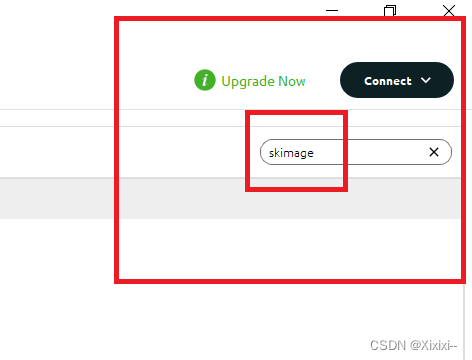
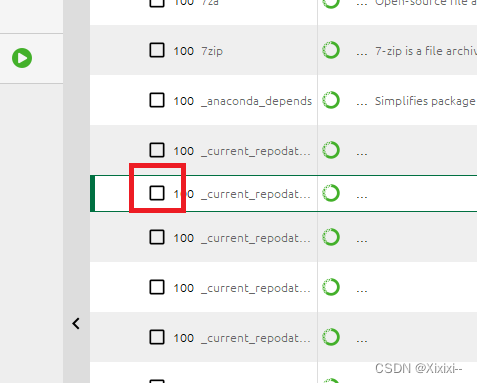
- 点击前面的小方格,选中要安装的包
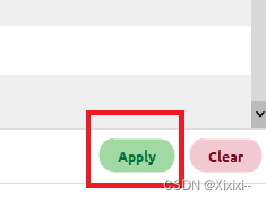
- 右下角apply
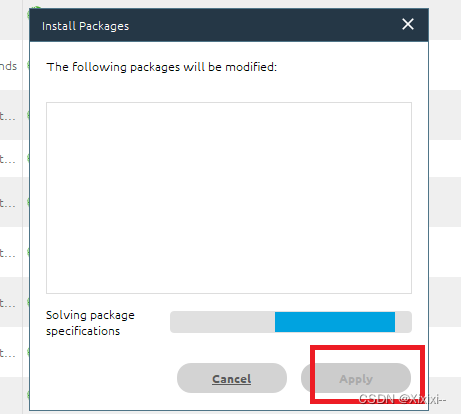
- 等加载出来点击apply,等待它下载完就好啦,底部可以看下载进度
Original: https://blog.csdn.net/m0_51933492/article/details/124584340
Author: —Xi—
Title: 解决PackagesNotFoundError: The following packages are not available from current channels:问题
相关阅读1
Title: [数据库系统概论学习笔记]3.关系
重点与难点
一组概念的区分:围绕关系的县官概念,如域,笛卡尔积,关系,关系模式,关键字/键/码, 外码/外键, 主码/主键, 主属性与非主属性.
三个完整性:实体完整性,参照完整性和用户自定义的完整性;
最早由E.F.Codd在1970年提出
是从表(Table)及表的处理方式中抽象出来的,是在传统表及其操作进行数学化严格定义基础上,引入集合理论与逻辑学理论提出的
是数据库的三大经典数据模型之一,也是现在大多数商品化数据库系统所仍然使用的数据模型
标准的数据库语言(SQL语言)是建立在关系模型基础之上的,数据库领域的众多理论也都是建立在关系模型基础之上的
形象地说,一个关系(relation)就是一个Table
关系模型就是处理Table的,它由三个部分组成:
描述DB各种数据的基本结构形式(Table/Relation)
描述Table与Table之间所可能发生的各种操作(关系运算)
描述这些操作所应遵循的约束条件(完整性约束)
就是要学习:Table如何描述,有哪些操作,结果是什么,有哪些约束等?
基本结构:Relation/Table
基本操作:Relation Operator
基本的:并,差,广义积,选择,投影,
扩展的:交,连接,除运算
完整性约束:实体完整性,参照完整性和用户自定义完整性
关系运算:关系代数和关系演算; 关系演算:元组演算和域演算
关系代数实例:基于集合的运算
与元组演算不同,域演算以域进行计算
哈工大数据库课件整理.pdf
域的基数即域当中元素的个数
同一关系模式下,可有很多的关系
关系模式是关系的结构,关系是关系模式在某一时刻的数据
关系模式是稳定的:而关系是某一时刻的值,是随时间可能变化的
列是同质:即每一列中的分量来自同一域,是同一类型的数据
不同的列可来自同一个域,称其中的每一列为一个属性,不同的属性要给予不同的属性名
列位置互换性:区分哪一列是靠列名
行位置互换性:区分哪一行是靠某一或某几列的值(关键字/键字/码字)
关系是以内容(名字或值)来区分的,而不是属性在关系的位置来区分
理论上,关系的任意两个元组不能完全相同.(集合的要求:集合内不能有相同的两个元素);现实应用中,表(Table)可能并不完全遵守此特性.
关系数据库语言中都是以关系来描述的,而商用数据库中使用的是表
元组相同是指两个元组的每个分量都相同
属性不可再分特性:又被称为关系第一范式
候选码(Candidate Key)/候选键
关系中的一个属性组,其值能唯一标识一个元组,若从该属性组中去掉任何一个属性,它就不具有这一性质了,这样的属性组称作候选码
主码(Primary Key)/主键
当有多个候选码时,可以选定一个作为主码
DBMS以主码为主要线索管理关系中的各个元组
主属性与非主属性
包含在任何一个候选码中的属性被称为主属性,而其他属性被称作非主属性
最简单的,候选码只包含一个属性
最极端的,所有属性构成这个关系的候选码,称为全码(All-Key)
比如:关系"教师授课"(T#,C#)中的候选码(T#,C#)就是全码
外码(Foreign Key)/外键
关系R中的一个属性组,他不是R的候选码,但它与另一个关系S的候选码相对应,则称这个属性组为R的外码或外键
Attachment
Attachment
Attachment
Attachment
Attachment
Attachment
Original: https://blog.csdn.net/qq_31714533/article/details/120290903
Author: 橙飒
Title: [数据库系统概论学习笔记]3.关系
相关阅读2
Title: Python图像处理笔记——傅里叶变换
文章目录
一、前言
图像的频率是表征图像中灰度变化剧烈程度的指标,是灰度在平面空间上的梯度。(灰度变化得快频率就高,灰度变化得慢频率就低)。傅立叶变换是将图像从空间域转换到频率域,其逆变换是将图像从频率域转换到空间域。
傅立叶变换的物理意义:
将图像的灰度分布函数变换为图像的频率分布函数,傅立叶逆变换是将图像的频率分布函数变换为灰度分布函数。
傅立叶变换以前,图像(未压缩的位图)是由对在连续空间(现实空间)上的采样得到一系列点的集合,我们习惯用一个二维矩阵表示空间上各点,则图像可由z=f(x,y)来表示。由于空间是三维的,图像是二维的,因此空间中物体在另一个维度上的关系就由梯度来表示,这样我们可以通过观察图像得知物体在三维空间中的对应关系。为什么要提梯度?因为实际上对图像进行二维傅立叶变换得到频谱图,就是图像梯度的分布图,当然频谱图上的各点与图像上各点并不存在一一对应的关系,即使在不移频的情况下也是没有。
关于傅里叶变换的详细解读推荐阅读大佬的知乎专栏:链接
二、傅里叶变换在图像中的应用
空域的卷积相当于频域的乘法。
在空间域,图像与高斯核卷积可以实现 高斯模糊的效果。相当于,高斯核和图像在频域的 乘积。
0. 本文用到的库
import timeit
import matplotlib.pylab as plt
import numpy as np
import pylab
from skimage.io import imread
from scipy import signal
import scipy.fftpack as fp
from matplotlib import cm
from matplotlib.ticker import LinearLocator, FormatStrFormatter
1. 图像的傅里叶变换和逆变换
将图像转换到频域,然后逆变换重建图像,信噪比不变。基于 _scipy.fftpack_的傅里叶变换函数实现。
def calc_snr(img, axis=0, ddof=0):
a = np.asanyarray(img)
m = a.mean(axis)
sd = a.std(axis=axis, ddof=ddof)
return np.where(sd == 0, 0, m / sd)
im = np.array(Image.open('images.jpg').convert('L'))
snr = calc_snr(img, axis=None)
print('SNR for the original image is ' + str(snr))
freq = fp.fft2(img)
im1 = fp.ifft2(freq).real
freq2 = fp.fftshift(freq)
img_mag = 20 * np.log10(0.1 + np.abs(freq2))
img_phase = np.angle(freq2)
snr = calc_snr(im1, axis=None)
print('SNR for the image obtained after fft reconstruction is ' + str(snr))
assert(np.allclose(im, im1))
输出
SNR for the original image is 3.3597120699464553
SNR for the image obtained after fft reconstruction is 3.3597120699464553

2. 高斯模糊
在空域中,图像与高斯核卷积可以实现高斯模糊。利于傅里叶变换的方法可以大幅减少计算量。以下是Python代码:
im = np.mean(imread('image.jpg'), axis=2)
gauss_kernel = np.outer(signal.gaussian(im.shape[0], 2), signal.gaussian(im.shape[1], 2))
freq = fp.fft2(im)
assert (freq.shape == gauss_kernel.shape)
freq_kernel = fp.fft2(fp.fftshift(gauss_kernel))
freq_convolved = freq_kernel * freq
im1 = fp.ifft2(freq_convolved).real
freq = 20 * np.log10(0.1 + fp.fftshift(freq)).astype(int)
freq_kernel = 20 * np.log10(0.1 + fp.fftshift(freq_kernel)).astype(int)
freq_convolved = 20 * np.log10(0.1 + fp.fftshift(freq_convolved)).astype(int)
示例


3. 傅里叶变换频域滤波
不同的频率分量对应图像中的不同部分。简单来说,低频对应细节,高频对应边缘。
(1)低通滤波
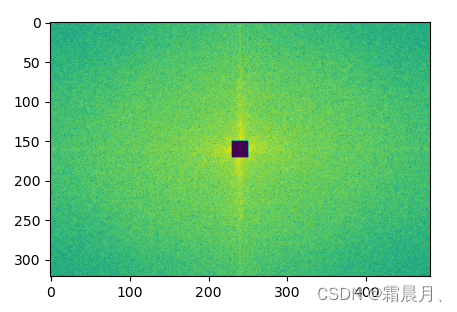
im = np.array(Image.open('../images/rhino.jpg').convert('L'))
freq = fp.fft2(im)
(w, h) = freq.shape
half_w, half_h = int(w/2), int(h/2)
snrs_lp = []
ubs = list(range(1,17))
plt.figure(figsize=(10,10))
for u in ubs:
freq1 = np.copy(freq)
freq2 = fp.fftshift(freq1)
freq2_low = np.copy(freq2)
freq2_low[half_w-u:half_w+u+1,half_h-u:half_h+u+1] = 0
freq2 -= freq2_low
im1 = np.clip(fp.ifft2(fp.ifftshift(freq2)).real,0,255)
snrs_lp.append(calc_snr(im1, axis=None))


(2)高通滤波
snrs_hp = []
lbs = list(range(1,17,1))
for l in lbs:
freq1 = np.copy(freq)
freq2 = fp.fftshift(freq1)
freq2[half_w-l:half_w+l+1,half_h-l:half_h+l+1] = 0
im1 = np.clip(fp.ifft2(fp.ifftshift(freq2)).real,0,255)
snrs_hp.append(calc_snr(im1, axis=None))
以下是运行结果,可以看到截止频率对滤波效果的影响。


(3)带通滤波
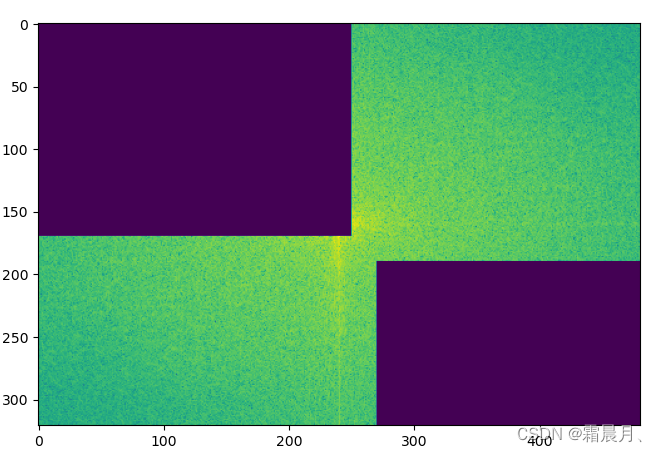
freq1 = np.copy(freq)
freq2 = fp.fftshift(freq1)
freq2[:half_w+10,:half_h+10] = freq2[half_w+30:,half_h+30:] = 0
im1 = np.clip(fp.ifft2(fp.ifftshift(freq2)).real,0,255)

Original: https://blog.csdn.net/qq_43360420/article/details/125553206
Author: 霜晨月、
Title: Python图像处理笔记——傅里叶变换
相关阅读3
Title: TensorFlow2.8.0代码分析之例子MultiBox Object Detection中main函数
该工具通过在计算机上运行音频识别模型,对连续不断的采样流,创建准确度统计信息。
这是一个新的模型运行环境设置以,了解它们在实际应用中的效果。
你需要为它提供一个包含你想要识别的声音的长音频文件,还有一个文本文件,列出每个声音的标签以及它们出现的时间。有了这些信息和冻结的模型,该工具将处理音频流式处理,应用模型,并记录有多少错误和成功模型实现。
匹配百分比是正确分类的声音数量,占列出的声音总数的百分比。
正确的分类是在短时间内选择正确的标签预期,其中时间容差由"time_tolerance_ms"命令行标志。
相同样品的文件,根据你的模型评分(通常每秒16000个样本),并记下声音会及时出现。将此信息保存为逗号分隔的文本文件,其中第一列是标签,第二列是从发生该事件的文件的开头。
运行这个例子的示例:
bazel run tensorflow/examples/speech_commands:test_streaming_accuracy -- \
--wav=/tmp/streaming_test_bg.wav \
--graph=/tmp/conv_frozen.pb \
--labels=/tmp/speech_commands_train/conv_labels.txt \
--ground_truth=/tmp/streaming_test_labels.txt --verbose \
--clip_duration_ms=1000 --detection_threshold=0.70 --average_window_ms=500 \
--suppression_ms=500 --time_tolerance_ms=1500
函数流程图如下:
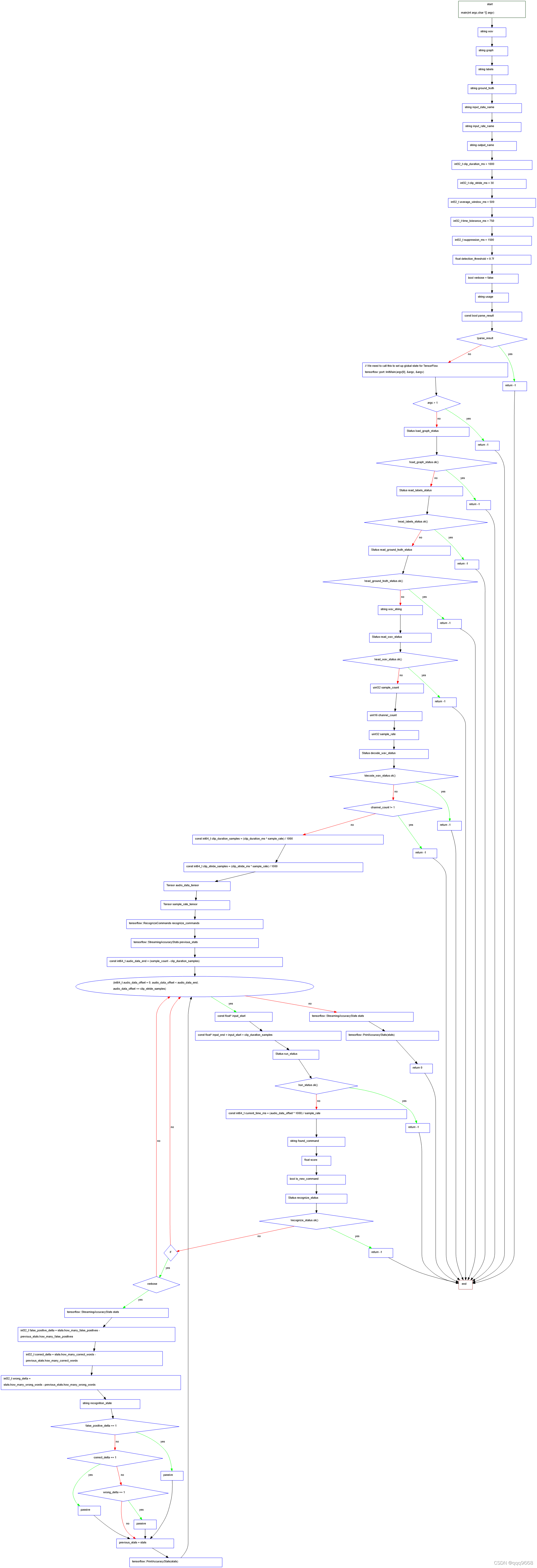
函数逻辑顺序图如下:
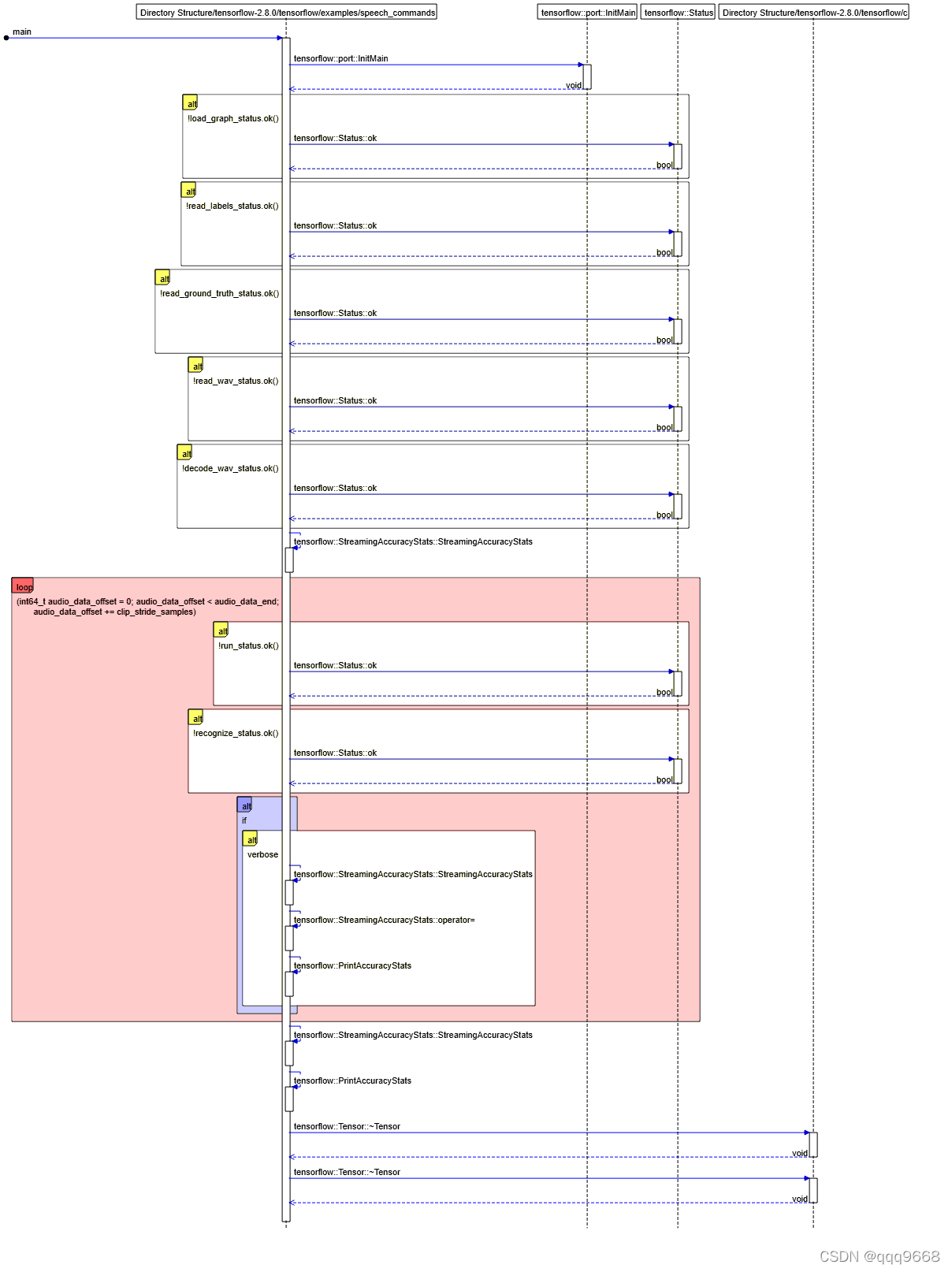
函数原始代码如下:
int main(int argc, char* argv[]) {
string wav = "";
string graph = "";
string labels = "";
string ground_truth = "";
string input_data_name = "decoded_sample_data:0";
string input_rate_name = "decoded_sample_data:1";
string output_name = "labels_softmax";
int32_t clip_duration_ms = 1000;
int32_t clip_stride_ms = 30;
int32_t average_window_ms = 500;
int32_t time_tolerance_ms = 750;
int32_t suppression_ms = 1500;
float detection_threshold = 0.7f;
bool verbose = false;
std::vector
// We need to call this to set up global state for TensorFlow.设置TensorFlow的全局状态
tensorflow::port::InitMain(argv[0], &argc, &argv);
if (argc > 1) {
LOG(ERROR) << "Unknown argument " << argv[1] << "\n" << usage;
return -1;
}
// First we load and initialize the model.第一:装载模型并初始化模型
std::unique_ptr
std::vector
std::vector
string wav_string;
Status read_wav_status = tensorflow::ReadFileToString(
tensorflow::Env::Default(), wav, &wav_string);
if (!read_wav_status.ok()) {
LOG(ERROR) << read_wav_status;
return -1;
}
std::vector
const int64_t clip_duration_samples = (clip_duration_ms * sample_rate) / 1000;
const int64_t clip_stride_samples = (clip_stride_ms * sample_rate) / 1000;
Tensor audio_data_tensor(tensorflow::DT_FLOAT,
tensorflow::TensorShape({clip_duration_samples, 1}));
Tensor sample_rate_tensor(tensorflow::DT_INT32, tensorflow::TensorShape({}));
sample_rate_tensor.scalar
tensorflow::RecognizeCommands recognize_commands(
labels_list, average_window_ms, detection_threshold, suppression_ms);
std::vector
const int64_t audio_data_end = (sample_count - clip_duration_samples);
for (int64_t audio_data_offset = 0; audio_data_offset < audio_data_end;
audio_data_offset += clip_stride_samples) {
const float input_start = &(audio_data[audio_data_offset]);
const float input_end = input_start + clip_duration_samples;
std::copy(input_start, input_end, audio_data_tensor.flat
// Actually run the audio through the model.
std::vector
const int64_t current_time_ms = (audio_data_offset * 1000) / sample_rate;
string found_command;
float score;
bool is_new_command;
Status recognize_status = recognize_commands.ProcessLatestResults(
outputs[0], current_time_ms, &found_command, &score, &is_new_command);
if (!recognize_status.ok()) {
LOG(ERROR) << "Recognition processing failed: " << recognize_status;
return -1;
}
if (is_new_command && (found_command != "silence")) {
all_found_words.push_back({found_command, current_time_ms});
if (verbose) {
tensorflow::StreamingAccuracyStats stats;
tensorflow::CalculateAccuracyStats(ground_truth_list, all_found_words,
current_time_ms, time_tolerance_ms,
&stats);
int32_t false_positive_delta = stats.how_many_false_positives -
previous_stats.how_many_false_positives;
int32_t correct_delta = stats.how_many_correct_words -
previous_stats.how_many_correct_words;
int32_t wrong_delta =
stats.how_many_wrong_words - previous_stats.how_many_wrong_words;
string recognition_state;
if (false_positive_delta == 1) {
recognition_state = " (False Positive)";
} else if (correct_delta == 1) {
recognition_state = " (Correct)";
} else if (wrong_delta == 1) {
recognition_state = " (Wrong)";
} else {
LOG(ERROR) << "Unexpected state in statistics";
}
LOG(INFO) << current_time_ms << "ms: " << found_command << ": " << score
<< recognition_state;
previous_stats = stats;
tensorflow::PrintAccuracyStats(stats);
}
}
}
tensorflow::StreamingAccuracyStats stats;
tensorflow::CalculateAccuracyStats(ground_truth_list, all_found_words, -1,
time_tolerance_ms, &stats);
tensorflow::PrintAccuracyStats(stats);
return 0;
}
Original: https://blog.csdn.net/qqq9668/article/details/123466253
Author: qqq9668
Title: TensorFlow2.8.0代码分析之例子MultiBox Object Detection中main函数