
1、安装Python
首先是得有python环境,这里可以自行安装python 3.8或者3.9 ,安装的时候要记得配置环境变量 https://www.python.org/downloads/
2、安装pycharm
pycharm也不用多说,直接到官网安装社区办就ok
3、Anaconda下载与安装
当以上都完事的时候,就可以安装Anaconda了,Anaconda下载网址:https://www.anaconda.com/distribution/ ,根据自己的系统,以及系统的位数,选择需要的版本。这里我的是Windows64位系统。

下载后,选择安装包,点击next
一直下一步,到安装完毕
然后检查是否安装成功
进入Windows系统的cmd界面:然后输入: conda --version检查anaconda的版本

检查目前安装了哪些环境变量: conda info --envs,如下所示即为成功

直观的来说,Anacoda就像一个VMware(虚拟机),虚拟机安装好以后,就需要安装操作系统!所以我们开始创建一个适合使用tensorflow的python环境吧。
我们创建一个叫tensorbase的虚拟环境,此环境使用3.6版本的python,打开终端输入创建虚拟环境的命令:
conda create -n tensorbase python=3.7
然后会弹出提示,输入y,然后回车等待安装!安装成功后,我们可以使用命令查看所有可用的虚拟环境:
conda env list
到这里显示 有一个tensorbase 的虚拟环境就成功了,这里我不在Anacoda去安装tensorflow,到后面直接一键安装所有环境
4、安装tensorflow + muggle_ocr
到pycharm里把,环境配置一下。
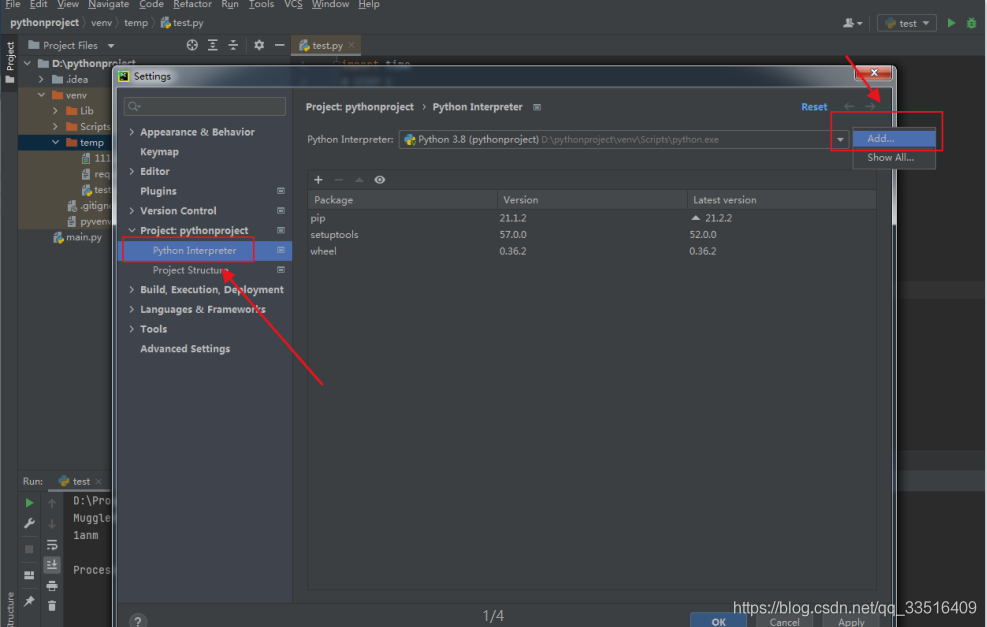
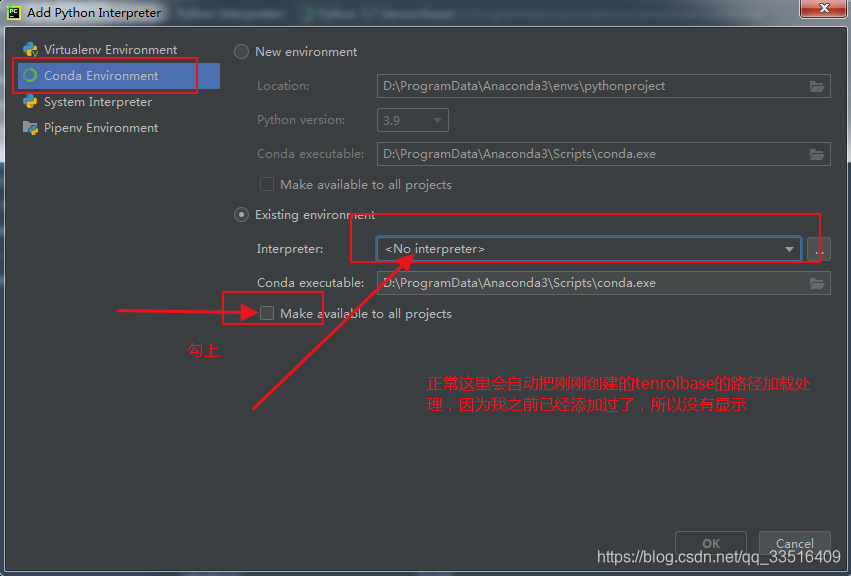
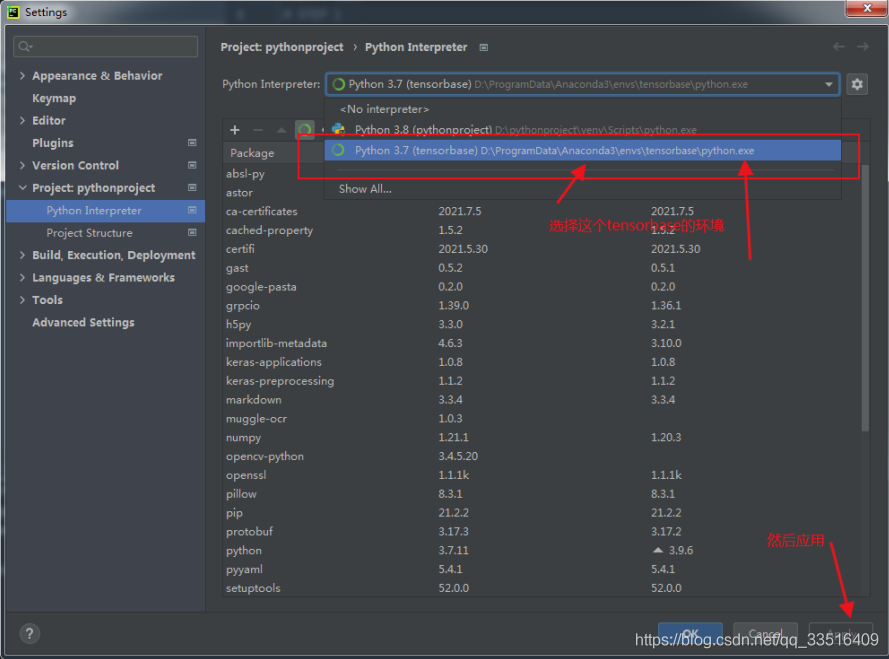
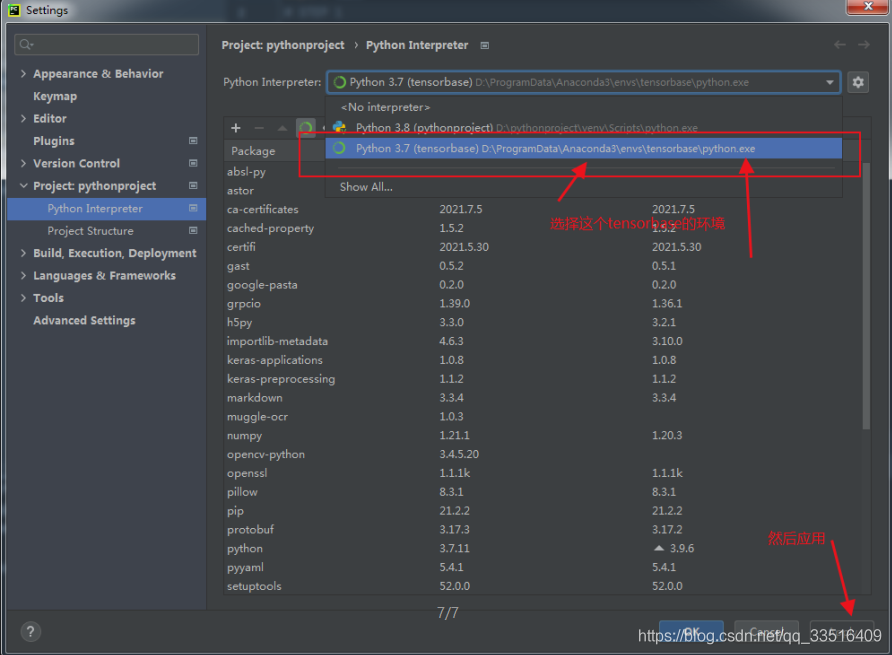
完成以上设置后,就是一键来安装环境了。话不多说,直接整。
pip install -i https://pypi.douban.com/simple/ -r requirements.txt
requirements.txt里面是所需环境配置
tensorflow==1.14
numpy
pillow
opencv-python==3.4.5.20
pyyaml>=3.13

等待安装完毕就行
最后安装 muggle_ocr
pip install -i https://pypi.douban.com/simple/ muggle_ocr
这里用的都是豆瓣 源,嘎嘎快
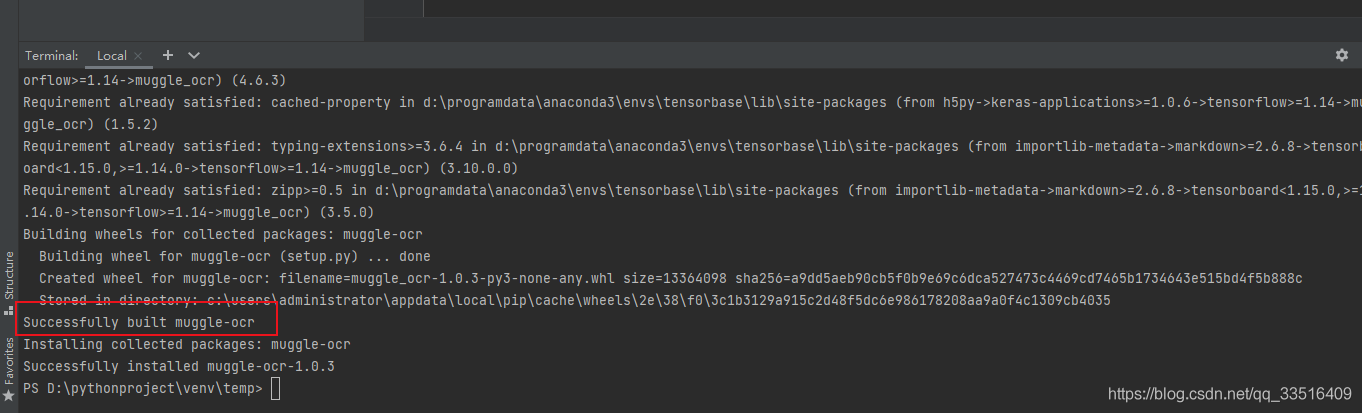
整完了,是真的快。
接下来搞个demo试试看
import time
STEP 1
import muggle_ocr
import os
#设置log日志的级别
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
STEP 2
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
如要自定义模型来识别,可以配置路径训练好的模型路径(基于大佬开源的captcha_trainer)
path = r"H:\gpu-win64-20200912\projects\tt1-CNNX-GRU-H64-CTC-C1\out\model\tt1-CNNX-GRU-H64-CTC-C1_model.yaml"
#sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR,conf_path=path)
with open(r"1anm_c6c0fc0a3fc20223577dffe04dbffd45.png", "rb") as f:
b = f.read()
text = sdk.predict(image_bytes=b)
print(text)
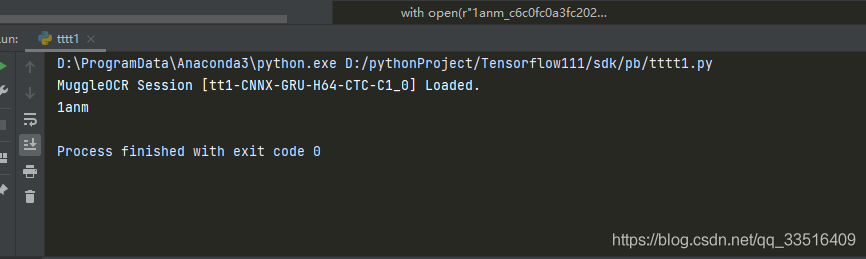
完事。
可能会报的错
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX AVX2
解决办法:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
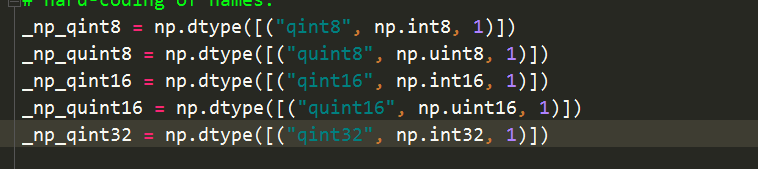
FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'._np_quint8 = np.dtype([("quint8", np.uint8, 1)])
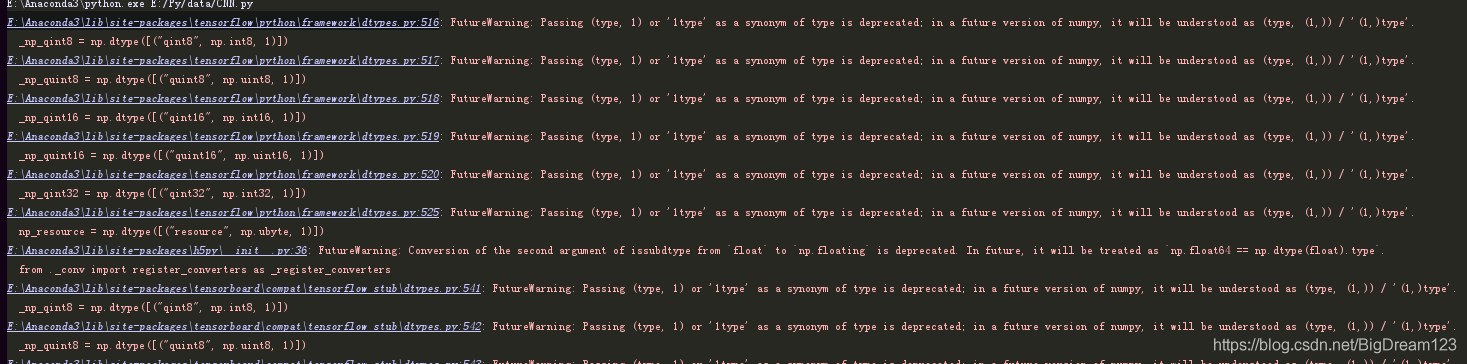
解决办法:
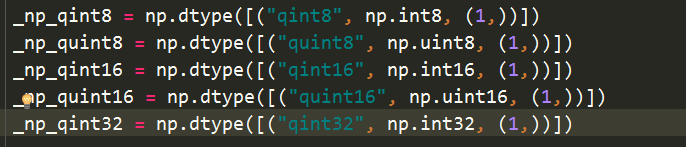
把 np.dtype([("quint8", np.uint8, 1)])修改为 np.dtype([("quint8", np.uint8, (1,))])就完美解决了
修改为下图
Original: https://blog.csdn.net/qq_33516409/article/details/119654415
Author: 天黑不算黑
Title: 【Python爬虫】tensorflow + muggle_ocr最快的安装教程
相关阅读1
Title: Python数据挖掘——数据预处理
Python数据挖掘——数据预处理
- 数据预处理
- 数据质量
- 准确性、完整性、一致性、时效性、可信性、可解释性
- 数据预处理的主要任务
- 数据清理
- 数据集成
- 数据归约
- 维归约
- 数值归约
- 数据变换
- 规范化
- 数据离散化
- 概念分层产生
- 数据清理(试图填充缺失的值,光滑噪声并识别离群点,纠正数据的不一致)
- 缺失值
- 忽略元组
- 人工填写缺失值
- 使用一个全局常量填充缺失值
- 使用属性的中心度量(均值/中位数)填充缺失值
- 使用与给定元组属于同一类的所有样本的均值/中位数
- 使用最可能的值 填充缺失值
- 注:某些情况,缺失值并不代表错误
- 噪声数据(噪声是被测量的变量的随机误差或方差)
- 分箱(通过考察数据的近邻,来光滑有序数据值)
- 用箱均值
- 用箱中位数
- 用箱边界
- 回归
- 离群点分析(通过聚类来检测离群点)
- 数据清理化为一个过程
- 首先进行偏差检测,还要防止字段过载
- 唯一性规则
- 连续性规则
- 空值规则
- 偏差检测商业工具
- 数据清洗工具
- 数据审计工具
- 数据迁移工具
- EIL工具
- 数据集成
- 实体识别问题
- 冗余和相关分析
- 元组重复
- 数据值冲突的检测与处理
- 数据归约
- 数据变换与数据离散化
本文来自博客园,作者:OCEANEYES.GZY,转载请注明原文链接:https://www.cnblogs.com/oceaneyes-gzy/p/12317371.html
关于作者
👋 读书城南,🤔 在未来面前,我们都是孩子~
-
📙 一个热衷于探索学习新方向、新事物的智能产品经理,闲暇时间喜欢coding💻、画图🎨、音乐🎵、学习ing~
-
🛠️ Blog: http://oceaneyes.top
- ⚡ PM导航: https://pmhub.oceangzy.top
- ☘️ CNBLOG: https://www.cnblogs.com/oceaneyes-gzy/
- 🌱 AI PRJ自己部署的一些算法demo: http://ai.oceangzy.top/
- 📫 Email: 1450136519@qq.com
-
💬 WeChat: OCEANGZY
-
💬 公众号:UncleJoker-GZY
👋 加入小组~
👋 感谢打赏~
Original: https://www.cnblogs.com/oceaneyes-gzy/p/12317371.html
Author: OCEANEYES.GZY
Title: Python数据挖掘——数据预处理
相关阅读2
Title: 编程思想与算法leetcode_分治算法详解
一、基本概念
在计算机科学中,分治法是一种很重要的算法。字面上的解释是"分而治之",就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题......直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。这个技巧是很多高效算法的基础,如排序算法(快速排序,归并排序),傅立叶变换(快速傅立叶变换)......
任何一个可以用计算机求解的问题所需的计算时间都与其规模有关。问题的规模越小,越容易直接求解,解题所需的计算时间也越少。例如,对于n个元素的排序问题,当n=1时,不需任何计算。n=2时,只要作一次比较即可排好序。n=3时只要作3次比较即可,...。而当n较大时,问题就不那么容易处理了。要想直接解决一个规模较大的问题,有时是相当困难的。
二、基本思想及策略
分治法的设计思想是:将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
分治策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。这种算法设计策略叫做分治法。
如果原问题可分割成k个子问题,1
三、分治法适用的情况
分治法所能解决的问题一般具有以下几个特征:
1) 该问题的规模缩小到一定的程度就可以容易地解决
2) 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
3) 利用该问题分解出的子问题的解可以合并为该问题的解;
4) 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题。
第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;
第二条特征是应用分治法的前提它也是大多数问题可以满足的,此特征反映了递归思想的应用;、
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑用贪心法或动态规划法。
第四条特征涉及到分治法的效率,如果各子问题是不独立的则分治法要做许多不必要的工作,重复地解公共的子问题,此时虽然可用分治法,但一般用动态规划法较好。
四、分治法的基本步骤
分治法在每一层递归上都有三个步骤:
step1 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
step2 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
step3 合并:将各个子问题的解合并为原问题的解。
它的一般的算法设计模式如下:
Divide-and-Conquer(P)
1. if |P|≤n0
2. then return(ADHOC(P))
3. 将P分解为较小的子问题 P1 ,P2 ,...,Pk
4. for i←1 to k
5. do yi ← Divide-and-Conquer(Pi) △ 递归解决Pi
6. T ← MERGE(y1,y2,...,yk) △ 合并子问题
7. return(T)
其中|P|表示问题P的规模;n0为一阈值,表示当问题P的规模不超过n0时,问题已容易直接解出,不必再继续分解。ADHOC(P)是该分治法中的基本子算法,用于直接解小规模的问题P。因此,当P的规模不超过n0时直接用算法ADHOC(P)求解。算法MERGE(y1,y2,...,yk)是该分治法中的合并子算法,用于将P的子问题P1 ,P2 ,...,Pk的相应的解y1,y2,...,yk合并为P的解。
五、分治法的复杂性分析
一个分治法将规模为n的问题分成k个规模为n/m的子问题去解。设分解阀值n0=1,且adhoc解规模为1的问题耗费1个单位时间。再设将原问题分解为k个子问题以及用merge将k个子问题的解合并为原问题的解需用f(n)个单位时间。用T(n)表示该分治法解规模为|P|=n的问题所需的计算时间,则有:1 T(n)= k T(n/m)+f(n)
通过迭代法求得方程的解:
递归方程及其解只给出n等于m的方幂时T(n)的值,但是如果认为T(n)足够平滑,那么由n等于m的方幂时T(n)的值可以估计T(n)的增长速度。通常假定T(n)是单调上升的,从而当 mi≤n
六、可使用分治法求解的一些经典问题
(1)二分搜索(2)大整数乘法(3)Strassen矩阵乘法(4)棋盘覆盖(5)合并排序(6)快速排序(7)线性时间选择
(8)最接近点对问题(9)循环赛日程表(10)汉诺塔
七、依据分治法设计程序时的思维过程
实际上就是类似于数学归纳法,找到解决本问题的求解方程公式,然后根据方程公式设计递归程序。
1、一定是先找到最小问题规模时的求解方法2、然后考虑随着问题规模增大时的求解方法3、找到求解的递归函数式后(各种规模或因子),设计递归程序即可。
Original: https://www.cnblogs.com/cs-markdown10086/p/15056628.html
Author: NEU_ShuaiCheng
Title: 编程思想与算法leetcode_分治算法详解
相关阅读3
Title: AttributeError: module ‘tensorflow_core.compat.v1‘ has no attribute ‘contrib‘
由于tensorflow版本问题,在tensorflow2.x版本里没有contrib组件,因此无法使用LSTMRNN实例中的sequence_loss_by_example函数。
AttributeError: module 'tensorflow_core.compat.v1' has no attribute 'contrib'
解决办法:找到自己运行代码的环境下的Lib\site-packages\tensorflow_core,在我的机器上是如下:
C:\Users\Dell\anaconda3\envs\tf_gpu\Lib\site-packages\tensorflow_core
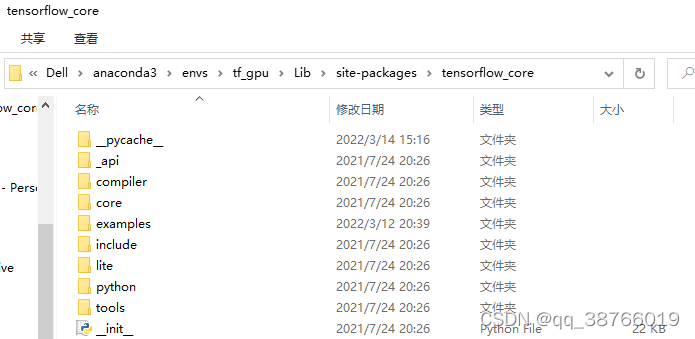
然后在这个文件夹下创建一个新的.py文件,即seq_loss.py文件,里面代码为
from six.moves import xrange # pylint: disable=redefined-builtin
from six.moves import zip # pylint: disable=redefined-builtin
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import ops
from tensorflow.python.ops import array_ops
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.ops import embedding_ops
from tensorflow.python.ops import math_ops
from tensorflow.python.ops import nn_ops
from tensorflow.python.ops import rnn
from tensorflow.python.ops import rnn_cell_impl
from tensorflow.python.ops import variable_scope
from tensorflow.python.util import nest
def sequence_loss_by_example(logits,
targets,
weights,
average_across_timesteps=True,
softmax_loss_function=None,
name=None):
if len(targets) != len(logits) or len(weights) != len(logits):
raise ValueError("Lengths of logits, weights, and targets must be the same "
"%d, %d, %d." % (len(logits), len(weights), len(targets)))
with ops.name_scope(name, "sequence_loss_by_example",
logits + targets + weights):
log_perp_list = []
for logit, target, weight in zip(logits, targets, weights):
if softmax_loss_function is None:
TODO(irving,ebrevdo): This reshape is needed because
sequence_loss_by_example is called with scalars sometimes, which
violates our general scalar strictness policy.
target = array_ops.reshape(target, [-1])
crossent = nn_ops.sparse_softmax_cross_entropy_with_logits(
labels=target, logits=logit)
else:
crossent = softmax_loss_function(labels=target, logits=logit)
log_perp_list.append(crossent * weight)
log_perps = math_ops.add_n(log_perp_list)
if average_across_timesteps:
total_size = math_ops.add_n(weights)
total_size += 1e-12 # Just to avoid division by 0 for all-0 weights.
log_perps /= total_size
return log_perps
这里怎么创建.py文件呢?如下步骤:
然后进去之后
然后把这个文件复制粘贴到C:\Users\Dell\anaconda3\envs\tf_gpu\Lib\site-packages\tensorflow_core下面即可。
然后再LSTMRNN实例代码添加头文件
from tensorflow_core import seq_loss
并且将计算损失调用函数语句
losses = tf.contrib.legacy_seq2seq.sequence_loss_by_example
改为
losses = seq_loss.sequence_loss_by_example
即可。
这时候运行的时候可能还有问题是
TypeError: ms_error() got an unexpected keyword argument 'labels'
这是因为
; def ms_error(self, y_target, y_pre):
return tf.square(tf.sub(y_target, y_pre))
这里定义传入参数的错误,改为
def ms_error(self,labels,logits):
return tf.square(tf.subtract(labels,logits))
应该就好了。
Original: https://blog.csdn.net/qq_38766019/article/details/123480243
Author: qq_38766019
Title: AttributeError: module ‘tensorflow_core.compat.v1‘ has no attribute ‘contrib‘