
入坑TF较深,不同的算法需要版本不同,TF2.0向下不兼容,因此遇到很多问题
本人使用的是TF2.0
解决: tf.math.log 代替tf.log
解决: tf.random.shuffle 代替tf.random_shuffle
解决: 参考 https://blog.csdn.net/c20081052/article/details/80745969
我使用第二种方法解决
解决参考:https://blog.csdn.net/qq_36362060/article/details/80888949
————————————————
解决参考:开头添加 tf.compat.v1.enable_eager_execution()
————————————————
解决参考:https://blog.csdn.net/u013066730/article/details/109071869
————————————————
解决参考:https://blog.csdn.net/jiaxiaohui0409/article/details/109045857
Original: https://blog.csdn.net/xuxiaobei224/article/details/119001076
Author: Betty222233333333333
Title: Tensorflow 2.0和较低版本的兼容问题
相关阅读1
Title: SER 语音情感识别-论文笔记4
SER 语音情感识别-论文笔记4
《SPEECH EMOTION RECOGNITION WITH MULTISCALE AREA ATTENTION AND DATA AUGMENTATION》
2021年ICASSP
The code is released at github.com/lessonxmk/Optimized attention for SER
文章目录
前言
在语音情感识别(SER)中,情感特征往往以不同形式的能量模式出现在频谱图中。SER的典型注意神经网络分类器通常在固定的注意粒度上进行优化。在本文中,在深度卷积神经网络中应用多尺度区域注意来关注不同粒度的情感特征,因此分类器可以从不同尺度的注意集合中受益。为了解决数据稀疏性问题,使用声道长度扰动(VTLP)进行数据增强,以提高分类器的泛化能力。实验在交互式情绪二元运动捕捉(IEMOCAP)数据集上进行,实现了79.34%的加权精度(WA)和77.54%的未加权精度(UA)。
一、数据集
使用IEMOCAP数据集,它包含12个小时的情感演讲由10个演员从南加州大学戏剧系。根据演员是否按照固定的剧本表演,表演分为即兴和脚本两部分。这些话语被标记为9种情绪类型:愤怒、快乐、兴奋、悲伤、沮丧、恐惧、惊讶、其他和中性状态。
在本文中使用的是即兴数据集,使用即兴数据集的准确性高于脚本数据。
本文在IEMOCAP数据集中使用了四种情绪类型的即兴数据:中性状态,兴奋,悲伤,愤怒。
二、特征
使用Librosa音频处理库提取logMel谱图作为特征。
三、模型方法
在本文中,将多尺度注意力引入基于头部融合的深度卷积神经网络模型,以提高模型的精度。此外,数据扩充还可以解决数据稀疏的问题。

基于注意力的卷积神经网络中有5个卷积层,1个注意力层,1个完全连接层。
将log Mel spectrogram作为特征输入模型后,分别从时间轴和频率轴提取纹理。
; 1. 多尺度区域注意
注意力机制可以看作是一种软寻址操作,它使用键值对来表示存储在内存中的内容。
在自我注意中,查询,键和值都来自同一个输入,通过计算自我注意模型可以关注输入的不同部分之间的联系。
区域注意力允许模型以多种尺度和粒度参加,并学习最合适的粒度。

2. 数据扩充
鉴于IEMOC中的训练数量有限,我们使用声道长度扰动(VTLP)作为数据增强的手段。VTLP通过干扰声道的长度在增加说话者的数量。我们使用nlpaug库来生成原始数据的另外7个副本。VTLP中所考虑的说话人正规化技术,该技术的实施旨在减少说话人之间的差异。
四、实验
1. 评估指标
使用加权准确度(WA)和未加权准确度(UA)进行评估,考虑到WA和UA在同一个模型中可能不会达到最大值,因此本文计算WA和UA的平均值作为最终评估标准。
2. 实验设定
本文将数据集化为为8:2,采用5折交叉验证,每个话语被分为2s的片段,每个片段之间有1s(在训练中)或1.6s(在测试中)有重叠。
测试仍然基于话语,来自同一话语的预测结果被平均化为该话语的预测结果。
经验表示,较大的重叠可以使话语识别结果更加稳定。
3. 实验结果
- 最大面积选择
利用VTLP分别研究了原始数据和增强数据的最优最大面积。

因此,建议使用3x3的最大面积,并使用VTLP进行数据扩充。 - 区域特征选择
通过实验研究了使用各种区域特征的性能。对于key,本文选择了最大值、平均值和样本;对于Value,本文选择了最大值、平均值和最大值。样本指的是在训练时根据平均值添加与标准偏差成比例的扰动。
 可以观察到,样本最大值达到最高ACC,样本平均值达到最低ACC。在其他情况下,ACC几乎没有差异。我们推测这是因为训练中的干扰键引入了更大的随机性。
可以观察到,样本最大值达到最高ACC,样本平均值达到最低ACC。在其他情况下,ACC几乎没有差异。我们推测这是因为训练中的干扰键引入了更大的随机性。 - 扩充数据量
研究VTLP下的增强数据量对SER性能的影响,随着在训练中添加更多的增强数据副本,准确性会提高。

- 消融研究
在没有注意层(仅CNN)的模型和有原始注意层(相当于1x1最大面积)的模型上进行了消融实验。表2显示了结果。可以看出,区域注意和VTLP使模型达到最高精度。这清楚地表明,与具有更多局部表征的传统CNN相比,区域注意倾向于沿着时间轴覆盖广泛的背景,这是区域注意优于CNN的原因之一。同样从表2中可以看到,当模型变得更强时,VTLP带来的改善会略微减少。这是因为VTLP通过保持标签的扰动来提高分类器的鲁棒性。当模型因注意或多尺度区域注意而变得更强时,模型本身变得更健壮,这可能会在一定程度上抵消VTLP的影响。

; 总结
本文将多尺度区域注意应用于SER,设计了一个基于注意的卷积神经网络,并在带有VTLP增强的IEMOCAP数据集上进行了实验,获得了79.34%的WA和77.54%的UA。其结果是最先进的。
Original: https://blog.csdn.net/ZLYLCG/article/details/123743892
Author: 绿叶今天写代码了吗
Title: SER 语音情感识别-论文笔记4
相关阅读2
Title: 推荐系统如何用TensorFlow实现经典的深度学习模型(Embedding+MLP)
文章目录
*
- Embedding+MLP模型的结构
-
+ 最经典的模型Deep Crossing
- Embedding+MLP模型的实战
-
+ 特征选择和模型设计
+ 基于TensorFlow的模型实现
Embedding+MLP模型的结构
- MLP(Multilayer Perceptron)是多层感知机的缩写。感知机是神经元的另外一种叫法,所以多层感知机就是多层神经网络。
最经典的模型Deep Crossing
- 微软在2016年提出的深度学习模型Deep Crossing,将其应用于广告推荐这个业务场景。它是一个经典的Embedding+MLP模型结构,我们可以看到,Deep Crossing从下到上可以分为5层:Feature层、Embedding层、Stacking层、MLP层和Scoring层。
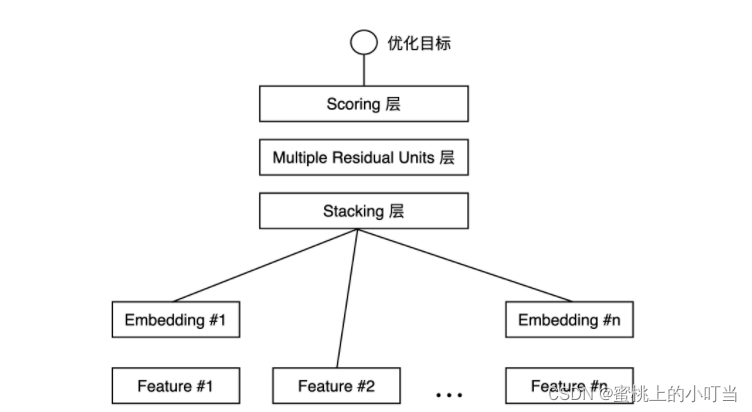
- Feature层也叫特征输入层(最底层),作为整个模型的输入。Feature有两种情况第一种是连接Embedding层、第二种是直接连接Stacking层,主要区别在于:Feature #1代表的是类别型特征经过One-hot编码后生成的特征向量,而Feature #2代表的是数值型特征。One-hot特征由于稀疏性,不能直接输入到后续的神经网络中进行训练,所以需要通过连接到Embedding层的方式,将其转换成比较稠密的Embedding向量。
- Embedding层是为了把稀疏的One-hot向量转换成稠密的Embedding向量而设置的,需要注意的是Embedding层并不是全部连接起来的,而是每一个特征对应一个Embedding层,不同Embedding层之间互不干涉。
- Stacking层中文名堆叠层也叫连接(Concatenate)层,作用是把不同的Embedding特征和数值型特征拼接在一起,形成新的包含全部特征的特征向量。
- MLP层就是我们开头提到的多层神经网络层,图中的Deep Crossing采用的是Multiple Residual Units层,也叫做多层残差网络。Deep Crossing针对特定的问题选择了残差神经元,其实还有很多种例如Relu、tanh、sigmoid。MLP层的特点是全连接,不同层的神经元两两之间都有连接。
- Scoring层也叫输出层。深度学习最终要预测的目标就是一个分类的概率。如果是点击率预估就是一个二分类问题,那我们就可以采用逻辑回归作为输出层神经元,而如果是类似图像分类这样的多分类问题,我们往往在输出层采用softmax这样的多分类模型。
- 总结: 对于类别特征,先利用Embedding层进行特征稠密化,再利用Stacking层连接其他特征,输入MLP的多层结构,最后用Scoring层预估结果。
; Embedding+MLP模型的实战
特征选择和模型设计
- 特征选择表格:
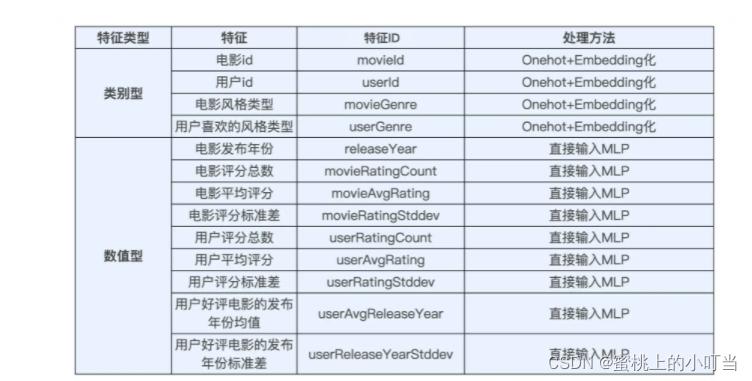
- 接下来就是MLP部分的模型设计了。选择一个三层的MLP结构,其中前两层是128维的FC层。采用好/差评标签作为样本标签,因此要解决的是一个类CTR预估的二分类问题,对于二分类问题,我们最后一层采用单个Sigmoid神经元作为输出层就可以了。
; 基于TensorFlow的模型实现
- 第一步导入TensorFlow包,相关代码:
import tensorflow as tf
TRAIN_URL = "file:///e:/SparrowRecSys/src/main/resources/webroot/sampledata/trainingSamples.csv"
TEST_URL = "file:///e:/SparrowRecSys/src/main/resources/webroot/sampledata/testSamples.csv"
training_samples_file_path = tf.keras.utils.get_file("trainingSamples.csv", TRAIN_URL)
test_samples_file_path = tf.keras.utils.get_file("testSamples.csv", TEST_URL)
- 第二步是载入训练数据,相关代码:
def get_dataset(file_path):
dataset = tf.data.experimental.make_csv_dataset(
file_path,
batch_size=12,
label_name='label',
na_value="0",
num_epochs=1,
ignore_errors=True)
return dataset
train_dataset = get_dataset(training_samples_file_path)
test_dataset = get_dataset(test_samples_file_path)
- 第三步是载入类别型特征,相关代码:
genre_vocab = ['Film-Noir', 'Action', 'Adventure', 'Horror', 'Romance', 'War', 'Comedy', 'Western', 'Documentary',
'Sci-Fi', 'Drama', 'Thriller',
'Crime', 'Fantasy', 'Animation', 'IMAX', 'Mystery', 'Children', 'Musical']
GENRE_FEATURES = {
'userGenre1': genre_vocab,
'userGenre2': genre_vocab,
'userGenre3': genre_vocab,
'userGenre4': genre_vocab,
'userGenre5': genre_vocab,
'movieGenre1': genre_vocab,
'movieGenre2': genre_vocab,
'movieGenre3': genre_vocab
}
categorical_columns = []
for feature, vocab in GENRE_FEATURES.items():
cat_col = tf.feature_column.categorical_column_with_vocabulary_list(
key=feature, vocabulary_list=vocab)
emb_col = tf.feature_column.embedding_column(cat_col, 10)
categorical_columns.append(emb_col)
movie_col = tf.feature_column.categorical_column_with_identity(key='movieId', num_buckets=1001)
movie_emb_col = tf.feature_column.embedding_column(movie_col, 10)
categorical_columns.append(movie_emb_col)
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
categorical_columns.append(user_emb_c
- 第四步是数值型特征的处理,相关代码:
numerical_columns = [tf.feature_column.numeric_column('releaseYear'),
tf.feature_column.numeric_column('movieRatingCount'),
tf.feature_column.numeric_column('movieAvgRating'),
tf.feature_column.numeric_column('movieRatingStddev'),
tf.feature_column.numeric_column('userRatingCount'),
tf.feature_column.numeric_column('userAvgRating'),
tf.feature_column.numeric_column('userRatingStddev')]
- 第五步是定义模型结构,相关代码:
model = tf.keras.Sequential([
tf.keras.layers.DenseFeatures(numerical_columns + categorical_columns),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid'),
])
- 第六步是定义模型训练相关的参数,相关代码:
model.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
- 第七步是模型的训练和评估,相关代码:
model.fit(train_dataset, epochs=10)
test_loss, test_accuracy = model.evaluate(test_dataset)
print('\n\nTest Loss {}, Test Accuracy {}'.format(test_loss, test_accuracy)
Original: https://blog.csdn.net/sinat_31854967/article/details/124018562
Author: 蜜桃上的小叮当
Title: 推荐系统如何用TensorFlow实现经典的深度学习模型(Embedding+MLP)
相关阅读3
Title: 【论文笔记】Nonparallel Emotional Speech Conversion Using VAE-GAN 基于VAE-GAN的非平行情感语音生成
Nonparallel Emotional Speech Conversion Using VAE-GAN
from INTERSPEECH 2020 - Ping An Technology
关键字:语音生成、语音情感、生成对抗网络、自编码器
摘要
概括: 采用GAN模型生成情感语音
主要内容: 本文采用的是VAE-GAN框架,采用encoder提取内容相关表示,采用监督的方式提取情感相关信息,利用CycleGAN来进行语音情感域间的转换。最后将内容表示和情感表示结合生成目标情感语音。
简介
- 介绍了什么是VC(Voice Conversion)和ESC(Emotional Speech Conversion)
- 有很多ESC的方法,包括两种:基于 规则的方法和基于 神经网络的方法,但是需要精准对齐的平行语料库
为什么语音生成需要平行语料库,为什么要对齐? 这里有对平行语库的解释知乎-语音转换综述,意思是必须样例和结果说话的内容相同才可以 - VAE(Variational AutoEncoder)将模型的表征分离,过程分为编码和解码过程
- 对抗学习能够使得转换出的语音更加自然,CycleGAN不再使用平行语料
本文的创新点
- 将VAE-GAN结构和CycleGAN结合
- 提出了一个更加可靠提取情感相关特征的监督学习策略
相关工作
- VAE(Variational AutoEncoder)介绍:变分自编码器,具体介绍在:知乎-VAE 知乎-自编码器
- CycleGAN2:相关内容:CycleGAN-知乎李宏毅视频笔记
其中3个LOSS:Adversarial Loss(用于两阶段对抗生成,其中提到oversmoothing,一般发生在图卷积网络中)、Cycle-consistency Loss(用于提升生成语音的连续性)、Identity Mapping Loss(保留身份信息) - VAE-GAN:将VAE和GAN进行结合,AVE产生的是正常但是模糊的样本,GAN产生的是怪异但是清晰的样本,将两者结合能够取其优点、去其糟粕
- 本文中采用F0基音频率、aperiodicity与频谱特征作为转换模型所需的特征
方法

采用WORLD提取F0、Spectral Features和Aperiodicity特征,这三个特征采用不同模型进行转换,F0采用logarithm Gaussian Normalized Transformation:
f t r g = e x p ( ( l o g f s r c − μ s r c ) ∗ δ t r g δ s r c + μ t r g ) f_{trg}=exp((log{f_{src}-\mu_{src}})*\frac{\delta_{trg}}{\delta_{src}}+\mu_{trg})f t r g =e x p ((l o g f s r c −μs r c )∗δs r c δt r g +μt r g )
其中aperiodity并没有改变,因为其对语音情感转换影响不大。
对于频谱特征采用VAE-GAN进行转换,其核心思想是通过非监督方式提取内容特征,通过监督方法提取情感特征。本文在训练和转换的过程中使用了情感标签,如图中所示。转换模型有三部分:编码器、解码器和判别器。编码器将声谱特征转换为内容相关的表征,频谱特征片段的情感标签作为情感相关表征,这两种表征随后进入一个解码器,输出结果再输入到判别器分辨是否为假。解码器和判别器部分可以看作一种CycleGAN2的变形。
LOSS设计部分:

这个部分对于不了解CycleGAN的读者来说并不是很清楚,看不出训练的过程。

; 实验
数据库: INEMOCAP,4种情感:Happy、Angry、Sad、Neutral
训练集: 随机从每个语者的每种情感中随机抽取30个样本
cycle loss和identity loss的权重分别设为10和5,这里的权重是如何进行选择的?
网络结构: 其中IN(instance normalization)层,用来做归一化去除说话人的情感信息,只关注于内容相关特征的提取。
优化器: Adam
Batch-Size: 1
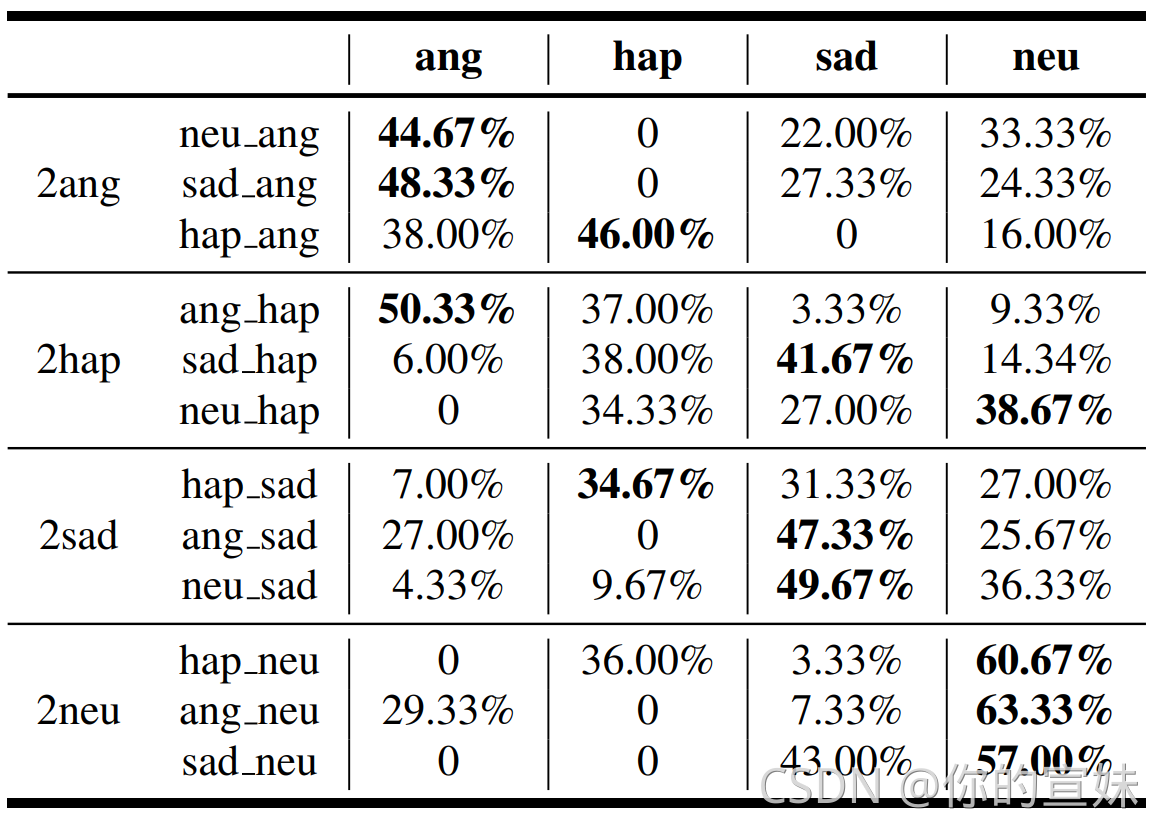
评估的三个方面是: 生成音质、 说话人相似度和 情感转换能力
- 生成音质和说话人相似度: MOS方法,是一种主观人工评分的方法,每个情感转换为其他情感共4*3=12组实验,30个评判者,180条测试语音。结果显示在95%的置信区间之内,语音质量和说话人相似度都有较好效果,语音质量的提升可能归因于两步的adversarial loss,说话人相似度可能提升较少。

- 情感转换能力: 采用的依然是人工评分的方法,12种情感转换,每种随机抽取10句话作为测试集,结果表明监督学习的方式能够更多提取情感相关表征。
问题
- 文中仅仅提到利用了类似CycleGAN的原理和loss,但未在图中描述训练过程。
- 文中所说的情感相关特征提取是监督学习,意思是采用了情感标签结合模型进行训练,这算监督吗?其实是必须要输入的情感标签作为情感转换信息。
- 人工评分是否不可靠,可以进行修改?一般来说人工评分后会进行显著性测试,以保证结果的分布可靠?
- 情感转换那里用的数据那么少,还是人工标注,结果真的可靠吗?
Original: https://blog.csdn.net/cherreggy/article/details/121335611
Author: 你的宣妹
Title: 【论文笔记】Nonparallel Emotional Speech Conversion Using VAE-GAN 基于VAE-GAN的非平行情感语音生成