
活动地址:CSDN21天学习挑战赛
目录
(2条消息) tensorflow零基础入门学习_重邮研究森的博客-CSDN博客_tensorflow 学习![]() https://blog.csdn.net/m0_60524373/article/details/124143223 ;https://blog.csdn.net/m0_60524373/article/details/124143223>- 本文为365天深度学习训练营 中的学习记录博客
https://blog.csdn.net/m0_60524373/article/details/124143223 ;https://blog.csdn.net/m0_60524373/article/details/124143223>- 本文为365天深度学习训练营 中的学习记录博客
本文开发环境:tensorflowgpu2.5,经过验证,2.4也可以运行
1.跑通代码
我这个人对于任何代码,我都会先去跑通之和才会去观看内容,哈哈哈,所以第一步我们先不管37=21,直接把博主的代码复制黏贴一份运行结果。(PS:做了一些修改,因为原文是jupyter,而我在pycharm)
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) # 设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]], "GPU")
打印显卡信息,确认GPU可用
print(gpus)
from tensorflow.keras import layers, datasets, Sequential, Model, optimizers
from tensorflow.keras.layers import LeakyReLU, UpSampling2D, Conv2D
import matplotlib.pyplot as plt
import numpy as np
import sys,os,pathlib
img_shape = (28, 28, 1)
latent_dim = 200
def build_generator():
# ======================================= #
# 生成器,输入一串随机数字生成图片
# ======================================= #
model = Sequential([
layers.Dense(256, input_dim=latent_dim),
layers.LeakyReLU(alpha=0.2), # 高级一点的激活函数
layers.BatchNormalization(momentum=0.8), # BN 归一化
layers.Dense(512),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(1024),
layers.LeakyReLU(alpha=0.2),
layers.BatchNormalization(momentum=0.8),
layers.Dense(np.prod(img_shape), activation='tanh'),
layers.Reshape(img_shape)
])
noise = layers.Input(shape=(latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator():
# ===================================== #
# 鉴别器,对输入的图片进行判别真假
# ===================================== #
model = Sequential([
layers.Flatten(input_shape=img_shape),
layers.Dense(512),
layers.LeakyReLU(alpha=0.2),
layers.Dense(256),
layers.LeakyReLU(alpha=0.2),
layers.Dense(1, activation='sigmoid')
])
img = layers.Input(shape=img_shape)
validity = model(img)
return Model(img, validity)
创建判别器
discriminator = build_discriminator()
定义优化器
optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
创建生成器
generator = build_generator()
gan_input = layers.Input(shape=(latent_dim,))
img = generator(gan_input)
在训练generate的时候不训练discriminator
discriminator.trainable = False
对生成的假图片进行预测
validity = discriminator(img)
combined = Model(gan_input, validity)
combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def sample_images(epoch):
"""
保存样例图片
"""
row, col = 4, 4
noise = np.random.normal(0, 1, (row*col, latent_dim))
gen_imgs = generator.predict(noise)
fig, axs = plt.subplots(row, col)
cnt = 0
for i in range(row):
for j in range(col):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%05d.png" % epoch)
# fig.savefig(" E:/2021_Project_YanYiXia/AI/21/对抗网络(GAN)手写数字生成/images/%05d.png" % epoch)
plt.close()
def train(epochs, batch_size=128, sample_interval=50):
# 加载数据
(train_images, _), (_, _) = tf.keras.datasets.mnist.load_data()
# 将图片标准化到 [-1, 1] 区间内
train_images = (train_images - 127.5) / 127.5
# 数据
train_images = np.expand_dims(train_images, axis=3)
# 创建标签
true = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# 进行循环训练
for epoch in range(epochs):
# 随机选择 batch_size 张图片
idx = np.random.randint(0, train_images.shape[0], batch_size)
imgs = train_images[idx]
# 生成噪音
noise = np.random.normal(0, 1, (batch_size, latent_dim))
# 生成器通过噪音生成图片,gen_imgs的shape为:(128, 28, 28, 1)
gen_imgs = generator.predict(noise)
# 训练鉴别器
d_loss_true = discriminator.train_on_batch(imgs, true)
d_loss_fake = discriminator.train_on_batch(gen_imgs, fake)
# 返回loss值
d_loss = 0.5 * np.add(d_loss_true, d_loss_fake)
# 训练生成器
noise = np.random.normal(0, 1, (batch_size, latent_dim))
g_loss = combined.train_on_batch(noise, true)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100 * d_loss[1], g_loss))
# 保存样例图片
if epoch % sample_interval == 0:
sample_images(epoch)
#train(epochs=30000, batch_size=256, sample_interval=200)
import imageio
def compose_gif():
# 图片地址
data_dir = "E:/2021_Project_YanYiXia/AI/21/对抗网络(GAN)手写数字生成/images"
data_dir = pathlib.Path(data_dir)
paths = list(data_dir.glob('*'))
gif_images = []
for path in paths:
print(path)
gif_images.append(imageio.imread(path))
imageio.mimsave("test.gif", gif_images, fps=2)
compose_gif()
点击pycharm运行即可得到结果,此图为对抗网络生成的手写数字

2.代码分析
神经网络的整个过程我分为如下六部分,而我们也会对这六部分进行逐部分分析。那么这6部分分别是: 但是:这里是对抗网络,和传统方法有区别,因此六步法不适用了,我们将重新分析。
五步法:
1->import
2->设置生成器和判别器
3->创建生成器和判别器
4->训练模型
5->验证
2.1
导入:这里很容易理解,也就是导入本次实验内容所需要的各种库。在本案例中主要包括以下部分:
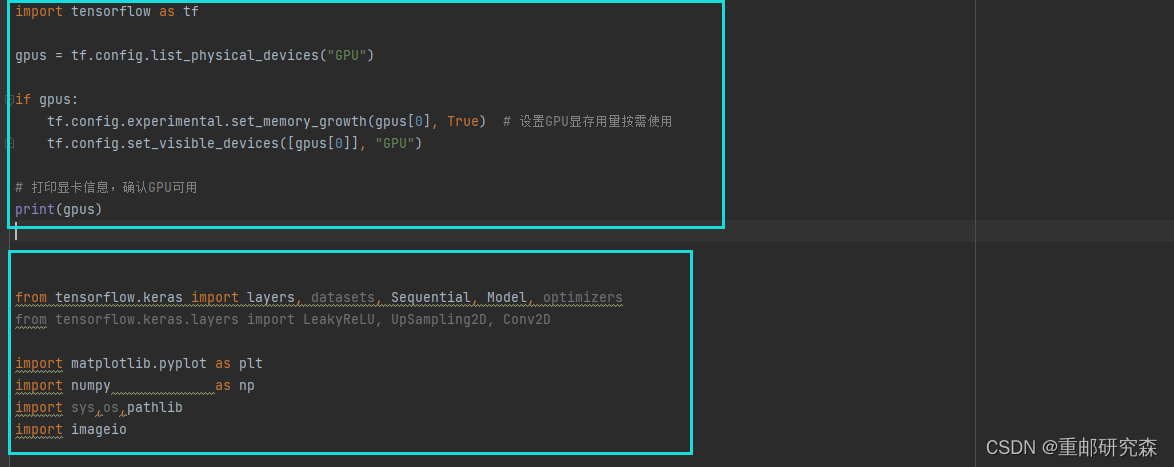
蓝框1:
设置电脑gpu工作,如果你的电脑没有gpu就不设置,或者你的gpu显存不够,训练时出问题了,那么就设在为cpu模式
蓝框2:
导入各种库
对于这里的话我们可以直接复制黏贴,当需要一些其他函数时,只需要添加对应的库文件即可。
2.2
这里是设置生成器和判别器。其中对于生成器和判别器的详细解释可以参考下面这个链接。
四天搞懂生成对抗网络(一)——通俗理解经典GAN - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/307527293 ;总之,我们需要清楚的一点是,对抗网络中:
https://zhuanlan.zhihu.com/p/307527293 ;总之,我们需要清楚的一点是,对抗网络中:
生成器:根据随机数生成一些"以假乱真"的数据集
判别器:对生成器"以假乱真"的数据集和真实的数据集进行判别
两者在训练过程中都会不断进行优化,生成器会不断生成更多"更真"的数据,判别器会"检测"的更仔细。
下面进行详细代码解释:
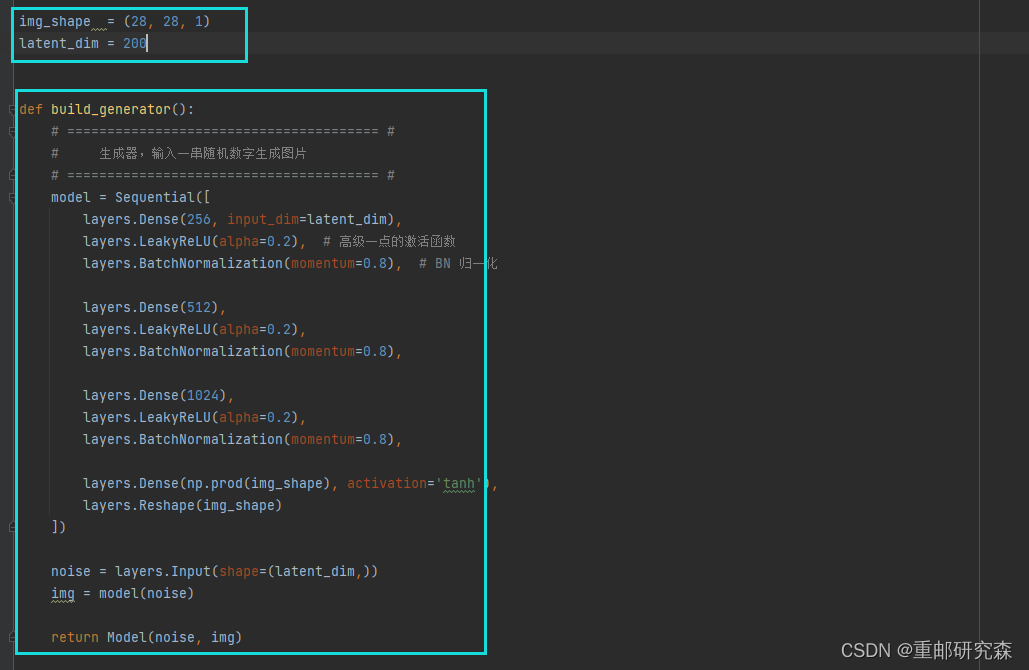
蓝框 1:
这里设置我们的图片格式和输入的维度
蓝框2:
这里引入了alpha激活函数,批标准化,prod函数。
先设置网络层,然后把噪音当作输入层,img当作输出层。
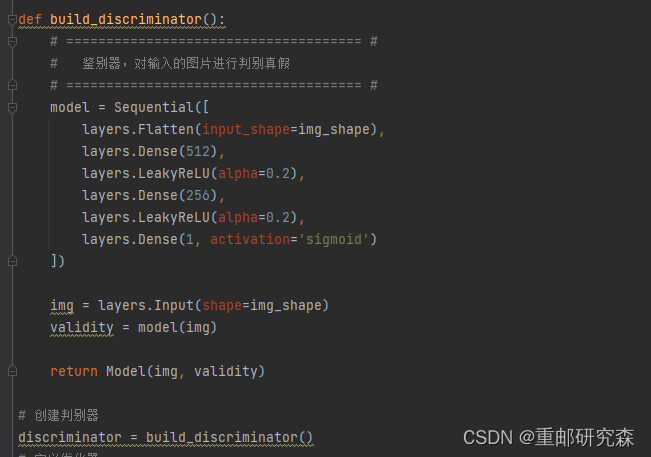
这部分为判别器。
输入是之前噪音生成的img,输出是真或者假
很有趣的一点,生成器和判别器的网络模型基本上是对折的!
2.3
在生成器和判别器都定义好之后,我们可以创建它们
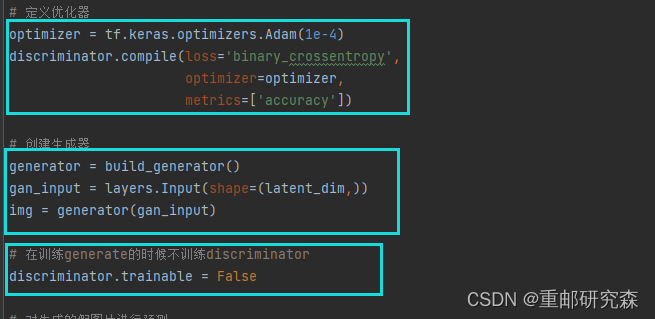
蓝框1:
设置优化器,关于优化器的参数设置可以参考文章开头我之前写的一篇基础文章
蓝框2:
创建生成器,生成器输入为噪音维度的数,输出是图片数据
蓝框3:
在训练生成器的时候不训练判别器
2.4
在完成基础准备工作之后,就可以开始训练了

重点!!!
现在我们来对如何对生成器和判别器训练进行代码解读!!!
蓝框1:
这里就是我们之前文章调用minist数据集制作datset的方法,包括加载数据,数据处理,归一化,修改维度。 同时这里的区别是:在标签方面,1为真,0为假,都是根据batch_size来生产的一个列表。
蓝框2:
返回一个随机整型数,范围从低0(包括)到高 train_images.shape[0](不包括).另外输出随机数的尺寸为batch_size
总结:这里就是随机获取官方数据集中任意一组图片
蓝框3:
从正态(高斯)分布中抽取随机样本。其中样本尺寸为(batch_size, latent_dim)
根据噪音的随机情况可以生成随机的一个图片数据
蓝框4:
discriminator.train_on_batch(imgs, true)的意思是,输入为img,输出为true,返回结果为loss
把真实数据和假数据的loss计算出来为总loss
蓝框5
从正态(高斯)分布中抽取随机样本。其中样本尺寸为(batch_size, latent_dim)
根据噪音的随机情况然后利用 combined.train_on_batch(noise, true)的意思是,输入为noise,输出为true,返回结果为loss
蓝框6
打印每轮的损失函数信息
蓝框7
执行训练
2.5
训练结束后,我们可以观察训练的结果
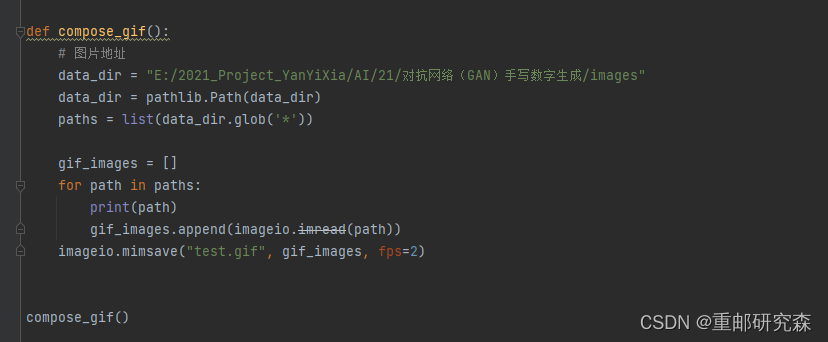
上面是生成tif动图代码
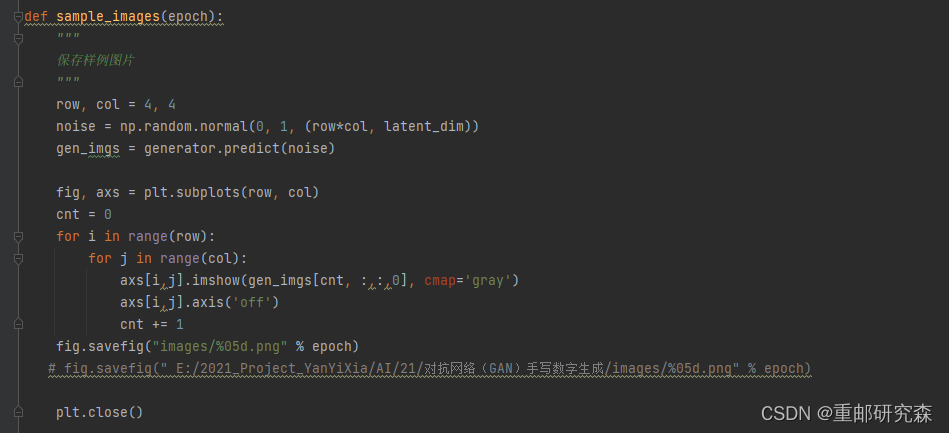 上面是保存样例图片代码
上面是保存样例图片代码
Original: https://blog.csdn.net/m0_60524373/article/details/126341959
Author: 重邮研究森
Title: 对抗网络(GAN)手写数字生成
相关阅读1
Title: Anaconda下的tensorflow-gpu2.6.0安装使用
引言:本次安装全部是在window下安装的虚拟环境,电脑显卡为1650ti,给相同配置的朋友一点参考,也给自己记录一下整体过程。
1.创建虚拟环境
- 在已经安装anaconda的情况下,搜索点开anaconda prompt
- 创建python版本为3.9.0的虚拟环境用于搭建tensorflow框架 ,命令格式conda create -n name python=x.x.x,我的命令conda create -n tensorflow2.6.0 python=3.9.0 ,这里安装其他版本的python也可以只要和tensorflow安装版本兼容即可。
activate tensorflow2.6.0 激活,要进入到tensorflow里去下载包。
2.虚拟环境配置
- 接下来需要根据你自己电脑配置选择合适的包安装。 tensorflow官方安装问题该网址可以查看什么cuda对应什么cudnn对应什么版本的tensorflow。 怎么选择cuda版本可以参考《主博客 Win10安装Anaconda3、Python、TensorFlow(GPU和CPU版本)、Keras(特别是版本选择)》这篇博客,里面教你如何通过指数值选择合适自己的cuda。

- 我的cuda是11.2 ,cudnn是8.1,tensorflow是2.6.0
- 在安装包之前可以导入一些镜像源方便快速下载工具包。
- 接下来是安装cuda和cudnn工具包,记住在安装tensorflow之前安装!!!
conda install cudatoolkit=11.2
conda install cudnn=8.1
- 完成环境安装之后可以安装tensorflow了,pip install tensorflow-gpu==2.6.0 这里使用pip进行安装。
- 输入代码测试
python
import tensorflow as tf
tf.__version__
import keras
依然可以参考之前《主博客 Win10安装Anaconda3、Python、TensorFlow(GPU和CPU版本)、Keras(特别是版本选择)》这篇博客
3.pycharm测试
pycharm中file->setting可以打开设置表,右边一个设置按钮,点击可以添加或者显示全部环境,我们添加环境->conda环境->现有环境->...,选择anaconda文件夹->envs文件夹->你的虚拟环境->python.exe,最后全部确定就可以在pycharm上使用该环境了。


我们找个代码测试一下是否有效。
import tensorflow as tf
print(tf.test.is_gpu_available())
print('tf.version:\n',tf.__version__)
测试结果为true说明tensorflow-gpu可用,2.6.0显示tensorflow版本号

4.其他问题
1.首先2.0版本以上的tensorflow里面已经自带keras了,我们可能会在深度学习的过程中遇到tensorflow.python.keras 和keras版本不兼容的问题,这个时候统一使用tensorflow内嵌的keras ,一致使用 from tensorflow.python.keras代替from keras部分。
2.还有可能是导入的库里面没有所需类,这个时候可以去site-packages里面找到具体路径之后再写,比如
from tensorflow.python.keras.optimizer_v2.adam import Adam
5.常用命令
conda info -e(查看_所有的虚拟 _环境)activate -name(虚拟 _环境_名字)(进入到该虚拟 _环境_中)conda deactivate选择退出环境conda remove -n yourenvname --all删除环境
镜像源
- 显示镜像源
conda config --show channels - 添加新镜像源
conda config --add channels [urls…] - 删除镜像源
conda config --remove-key channels删除所有的镜像源,恢复到默认
conda config --remove channels [urls]删除指定的镜像源 - 设置搜索时显示通道地址
conda config --set show_channels_urls yes
- 国内常用源镜像地址:
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学: https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:https://pypi.hustunique.com/
山东理工大学:https://pypi.sdutlinux.org/
豆瓣:https://pypi.douban.com/simple/
- conda 安装指定的源
conda install -c urls lib_name
- 我使用的镜像源为:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
(该镜像网址很快很好用>_
Original: https://blog.csdn.net/qq_45156353/article/details/124713124
Author: 硕棋
Title: Anaconda下的tensorflow-gpu2.6.0安装使用
相关阅读2
Title: 使用Pytorch中的Dataset类构建数据集的方法及其底层逻辑
1 前言
我们在用Pytorch开发项目的时候,常常将项目代码分为数据处理模块、模型构建模块与训练控制模块。数据处理模块的主要任务是构建数据集。为方便深度学习项目构建数据集,Pytorch为我们提供了Dataset类。那么,假如现在已经有训练数据和标签,该怎么用Dataset类构建一个符合Pytorch规范的数据集呢?在刚开始学的时候,或许我们会上网找一些代码来参考。不过,有时我们找到的代码可能与自己的数据格式不一样,以至于在模仿着写的时候,不确定自己写的代码对不对。本人起初也有这样的体会,为此,本文就来说说我的领悟过程。我首先是学习在Pytorch中构建数据集的步骤。学会之后的感觉是,明白了在Pytorch中创建数据集的套路,但是不了解为什么要这么做。后来当我明白了其底层逻辑之后,写代码更有信心了。为此,本文将从两个方面进行介绍。首先介绍在Pytorch中构建数据集的步骤,然后介绍用Dataset类构建数据集的底层逻辑。
2 在Pytorch中构建数据集的步骤
下面用一个具体实例来说明拿到数据后,如何根据模型训练的需要来构建数据集。
- .实例一:图像二分类训练任务,识别1元纸币和100元纸币
如下图所示,现已有1元和100元纸币图像样本分别存放在"1"和"100"两个文件夹中。
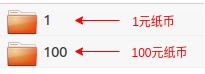
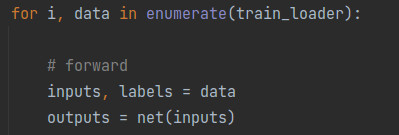
在构建数据集前,我们要先明确模型需要哪些输入数据,除了模型所需的输入数据,在训练时还需要哪些数据。在本例中,模型需要图像数据作为输入。除了图像数据,还需要与图像数据相对应的类别标签,以用它来计算loss。所以,如下图所示,inputs和labels分别是从列表data中得到的图像数据序列和类别标签序列。也就是说,我们构建数据集的应该包含这两部分数据。
明确了需要构建什么数据后,下一步就是通过继承Pytorch的dataset类来编写自己的dataset类。Pytorch的dataset类是一个抽象类,继承dataset,需要实现它的__getitem__()方法和__len__()方法,下图是Pytorch官方文档中关于dataset类的说明。
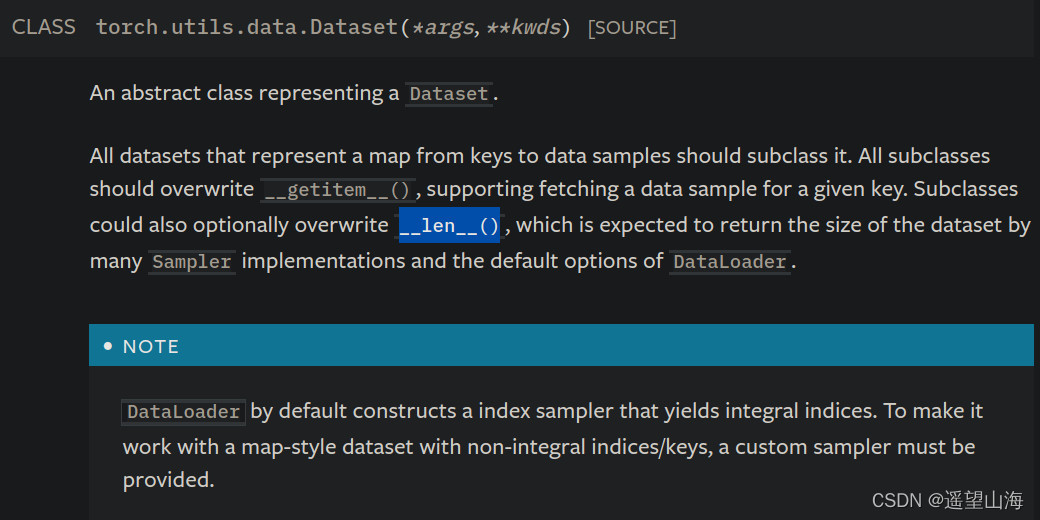
除了实现上述两个方法外,我们还需写一个静态方法,用来构建数据列表,因为__getitem__( )要用到这个数据列表。
先上一份创建dataset的实例代码
class CashDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
纸币分类任务的Dataset
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {"1": 0, "100": 1}
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB')
if self.transform is not None:
img = self.transform(img)
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
undefined
上面代码中的静态方法get_img_info(data_dir)就是用来构建数据列表的,它返回数据列表data_info,data_info中的元素由元组(图像路径,图像标签)构成。
在__getitem__(self, index)方法中,通过data_info中存储的文件路径去读取图像数据,最后返回索引下标为index的图像数据和标签。这里返回哪些数据主要是由训练代码中需要哪些数据来决定。也就是说,我们根据训练代码需要什么数据来重写__getitem__(self, index)方法并返回相应的数据。
最后还要重写__len__(self)方法。实现__len__(self)方法比较简单,只需一行代码,也就是返回数据列表的的长度,即数据集的样本数量。
下面对构建CashDataset类做个小结,主要步骤如下:
1) 确定训练代码需要哪些数据;
2) 重写__getitem__(self, index)方法,根据index返回训练代码所需的数据;
3) 编写静态方法,构建并返回数据列表data_info;
4) 重写__len__(self)方法,返回数据列表长度;
看到这里,也许会有两个困惑:
困惑1:在训练代码中是怎么调用到__getitem__( )的,是编写代码手动调用,还是Pytorch函数内部自动调用?
困惑2:getitem( )返回的数据是单个 (图像, 标签),为什么在训练代码中得到的数据格式不是[(图像1, 标签1), (图像2, 标签2),, ..., (图像n, 标签n)]这种格式,而是[图像1, 图像2, ..., 图像n]、[标签1, 标签2, ..., 标签n] 这种格式?
要想知道这两个答案,就需要了解Pytorch调用CashDataset的底层逻辑。
3 用Dataset类构建数据集的底层逻辑
先上代码
# 构建CashDataset实例
train_data = CashDataset(data_dir=train_dir, transform=train_transform)
valid_data = CashDataset(data_dir=valid_dir, transform=valid_transform)
# 构建DataLoder
train_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)
如上面代码第六行所示,在创建DataLoader对象时,将数据集train_data作为参数传入DataLoader中。所以,我们大概能猜到应该是在DataLoader内部直接或间接地调用了__getitem__( )。DataLoader是Pytorch的数据加载器,下面让我们深入其内部看看它是怎样一步一步执行,最终调用到__getitem__( )。
在Pytorch官网可以查到Dataloader的构造方法有很多参数,我们这里主要关注其中四个,如下图所示。
DataLoader(dataset, batch_size=1, num_workers=0, shuffle=False)
dataset:需要载入的数据集
batch_size:批大小,即迭代器一次加载多少个样本
num_workers:使用多少个子进程来加载数据,0表示只在主进程中加载数据。Pytorch会根据此参数来判断是创建单进程SingleProcessDataLoaderIter类对象,还是创建多进程MultiProcessingDataLoaderIter类对象
shuffle:是否在每个epoch训练前打乱数据集中的样本顺序
为了能弄清dataloader的整个执行过程,需通过打断点、步进的方式进入到dataloader类内部。

如上图所示,在for循环处打个断点,然后点击步进按钮,可以得到大致的执行流程,如下图所示。下图中冒号左侧是类名,冒号右侧是类方法,方框中只列出类方法中的主要代码。
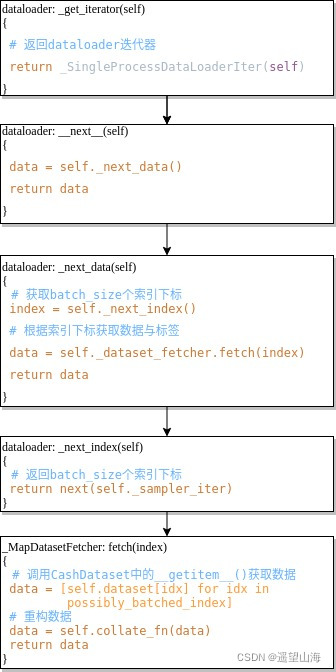
如上图最后一步所示,在_MapDatasetFetcher类中的fetch( )方法中,执行self.dataset[idx]会去调用_getitem__( )方法,以获取train_data中的数据。经过batch_size次循环得到数据列表data,再通过self.collate_fn( )方法重构data。也就是将 [(图像1, 标签1), (图像2, 标签2),, ..., (图像n, 标签n)] 这种格式,变换为 [图像1, 图像2, ..., 图像n]、[标签1, 标签2, ..., 标签n] 这种格式。
4 总结
关于Pytorch如何调用CashDataset以获取训练数据的底层逻辑,可以概括为三点:Ⅰ) 由Dataloader创建一个迭代器dataloaderIter;Ⅱ) dataloaderIter通过调用sampler_iter得到一个batch_size的索引下标序列;Ⅲ) 在_MapDatasetFetcher类的fetch( )方法中调用__getitem__( ),以获取数据与类标签,再通过collate_fn( )重构数据列表。
Original: https://blog.csdn.net/rowevine/article/details/123631144
Author: 遥望山海
Title: 使用Pytorch中的Dataset类构建数据集的方法及其底层逻辑
相关阅读3
Title: 都要2022年了,你还在纠结pytorch还是tensorflow?
PyTorch 和 TensorFlow近几年一直是深度学习领域的两大热门框架。PyTorch 和 TensorFlow都拥有丰富的API、广阔的用户群体,目前也都广泛用于学术研究和商业应用。我们在学习工作中到底应该选择哪个,这可能是很多初学者与从业者要问的问题。
今天我们将从以下几点来帮你更好的进行选择。
- PyTorch和 TensorFlow有什么区别
- 如何根据实际选择 *最适合的框架
我们将从TensorFlow1.X 开始首先仔细介绍这两个框架,然后介绍一些可以帮助您确定哪种选择最适合您的框架的注意事项。
TensorFlow 由 Google 开发并于 2015 年作为开源发布。它源于 Google 的自主机器学习软件,该软件经过重构和优化以用于生产。
"TensorFlow"这个名字描述了你如何组织和执行数据操作。TensorFlow 和 PyTorch 的基本数据结构都是张量。当您使用 TensorFlow 时,您通过构建有状态的流程图对这些张量中的数据执行操作,有点像记住过去事件的流程图。
谁在使用 TensorFlow?
TensorFlow 以生产级深度学习库而闻名。它拥有庞大而活跃的用户群,以及大量用于训练、部署和服务模型的官方和第三方工具和平台。
2016 年 PyTorch 发布后,TensorFlow 的受欢迎程度有所下降。但在 2019 年底,谷歌发布了TensorFlow 2.0,这是一项重大更新,简化了库并使其更加用户友好,重新引起了机器学习社区的兴趣。
代码风格和功能
在 TensorFlow 2.0 之前,TensorFlow 要求您通过调用 API将图手动拼接在一起,构成流程图。然后通过编译模型来传递一组输出张量,并利用session.run()来调用输入张量。
Session 对象在运行时负责对数据流图进行监督,并且是运行数据流图的主要接口。Session拥有并管理Tensorflow运行时的所有资源,一般可以使用python的上下文管理器来使用Session。
在 TensorFlow 2.0 中,您仍然可以通过这种方式构建模型,但使用Eager Execution更容易,这是 Python 通常的工作方式。可立即评估操作,无需构建图:操作会返回具体的值,而不是构建以后再运行的计算图,因此您可以使用 Python 控制流而不是图形控制流来编写代码。
要查看差异,让我们看看如何使用每种方法将两个张量相乘。这是使用旧的 TensorFlow 1.0 方法的示例:
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
x = tf.compat.v1.placeholder(tf.float32, name = "x")
y = tf.compat.v1.placeholder(tf.float32, name = "y")
multiply = tf.multiply(x, y)
with tf.compat.v1.Session() as session:
m = session.run(
multiply, feed_dict={x: [[2., 4., 6.]], y: [[1.], [3.], [5.]]}
)
print(m)
[[ 2. 4. 6.]
[ 6. 12. 18.]
[10. 20. 30.]]
上面的代码代码使用 TensorFlow 2.x 中的tf.compat API 来访问 TensorFlow 1.x 的方法并禁用 Eager Execution。
首先声明输入张量x并使用tf.compat.v1.placeholder创建张量对象。然后定义要对它们执行的操作。接下来,使用tf.Session对象作为上下文管理器,创建一个容器来封装运行时环境,并通过将带有实际值的feed_dict输入到placeholder. 最后,还是在 session 里面,打印我们的结果。
使用 TensorFlow 2.0 中的 Eager Execution,只需tf.multiply()就可以达到相同的结果:
import tensorflow as tf
x = [[2., 4., 6.]]
y = [[1.], [3.], [5.]]
m = tf.multiply(x, y)
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[ 2., 4., 6.],
[ 6., 12., 18.],
[10., 20., 30.]], dtype=float32)>
TensorFlow 拥有庞大且完善的用户群和大量工具来帮助生产机器学习。对于移动开发,它具有适用于JavaScript和 Swift 的API ,并且TensorFlow Lite可以压缩和优化物联网设备的模型。
由于Google 和第三方提供的大量数据、预训练模型等功能,可以快速上手并使用TensorFlow。
许多流行的机器学习算法和数据集都内置在 TensorFlow 中并且可以立即使用。除了内置数据集,您还可以访问Google Research 数据集或使用 Google 的数据集搜索来查找更多数据。
当然,目前tensorflow还有一个缺点是从 TensorFlow 1.x 到 TensorFlow 2.0 的更新改变了太多功能,对于长期使用TensorFlow1.X。升级代码既乏味又容易出错。许多资源(如教程)可能并没有及时的实现tensorflow2.X的更新。
而PyTorch 没有这样向后兼容性问题,这可能是选择它而不是 TensorFlow 的一个原因。
Tensorflow 生态系统
TensorFlow 的 API、扩展和有用工具的一些亮点包括:
由于 Python 程序员发现它使用起来非常自然,PyTorch 迅速获得了大量用户,这促使 TensorFlow 团队在 TensorFlow 2.0 中采用了许多 PyTorch 最受欢迎的功能。
PyTorch 以在研究中的使用比在生产中的使用更广泛而闻名。然而,自从在 TensorFlow 之后的一年发布以来,PyTorch 的专业开发人员使用量急剧增加。
PyTorch在研究领域中用户较为广泛,像斯坦福大学等都已经用PyTorch来教授深度学习。
PyTorch 将相同的 C 后端包装在 Python 接口中。但它不仅仅是一个包装器。开发人员从头开始构建它,使 Python 程序员可以轻松编写模型。底层的低级 C 和 C++ 代码针对运行 Python 代码进行了优化。由于这种紧密集成,使得PyTorch具有以下的优点:
- 更好的内存和优化
- 更合理的错误信息
- 模型结构的细粒度控制
- 更透明的模型行为
- 与 NumPy 更好的兼容性
这意味着我们可以直接在 Python 中编写高度自定义的神经网络组件,而无需使用大量低级函数。
PyTorch 的 Eager execution可以立即动态地实现张量操作,并且tensorflow2.X也参造了这一点,因此两者的 API 看起来很相似。
将NumPy对象转换为张量被写入PyTorch的核心数据结构中。这意味着你可以轻松地来回切换torch.tensor对象和numpy.array对象。
例如,你可以创建两个numpy.array对象,使用 PyTorch 的原生支持torch.from_numpy()将 NumPy 数组转换为张量,然后获取它们的元素乘积:
import torch
import numpy as np
x = np.array([[2., 4., 6.]])
y = np.array([[1.], [3.], [5.]])
m = torch.mul(torch.from_numpy(x), torch.from_numpy(y))
m.numpy()
array([[ 2., 4., 6.],
[ 6., 12., 18.],
[10., 20., 30.]])
使用torch.tensor.numpy()可以打印出矩阵乘法的结果,可以将一个tensor对象作为一个numpy数组打印出来。
torch和numpy之间最重要的区别是torch类中有不同的方法和属性,比如计算梯度的backward()和CUDA兼容性。
PyTorch在Torch后端添加了一个c++模块用于自微分。自微分可以实现torch神经网络反向传播时自动计算梯度的功能。
默认情况下,PyTorch使用eager模式计算。所以我们可以在构建神经网络时逐行运行它,这使得调试更容易。它也使一些需要条件判断的神经网络构建成为可能。这种动态执行对于大多数Python程序员来说更加直观。
PyTorch 生态系统
PyTorch 扩展的 API、扩展和有用工具的一些亮点包括:
那么到底该如何选择这两种深度学习框架呢?使用哪个库取决于我们自己的编码风格、数据、模型以及我们的最终需求。
代码风格
如果你是Python程序员,那么使用PyTorch会很容易。它就像你期望的那样,开箱即用。
另一方面,TensorFlow比PyTorch支持更多的编码语言,比如c++ API。同样你也可以在JavaScript和Swift中使用TensorFlow。同时Keras中已经封装了很多现成的模块与工具,你可以拿来直接用,非常的方便。
数据与模型
当我们在上手一个项目时,可以了解下这两种框架中是否能找到我们需要的预训练模型,如BERT或DeepDream。同时,可能我们在GitHub上找模型的时候,可以关注下别人是用哪种框架进行模型构建的。并且有些时候,PyTorch和TensorFlow数据处理的库也不尽相同,你可以根据你自己的数据,来选择一个更方便的框架。
我们在选择框架的过程中也要根据自己的最终目标来进行综合考量。
就例如在部署模型时,TensorFlow与Google Cloud紧密集成,PyTorch集成到AWS上的TorchServe中,但TensorFlow的TensorFlow Lite和它的Swift API可以方便帮我们在移动设备上部署模型。
今天我们介绍了PyTorch和TensorFlow的选择,对于刚入门的新手,现在可能推荐PyTorch的人会多一些,但TensorFlow在2.X重大改版之后,感觉对新手也很友好。当然,不论是什么框架,只要选择了,我们就应该认真的学下去,而不是把时间浪费在纠结使用哪个框架上。
Original: https://blog.csdn.net/weixin_44095417/article/details/121533909
Author: deepython
Title: 都要2022年了,你还在纠结pytorch还是tensorflow?