
统计语言模型
统计语言模型是所有词序列上的一个概率分布
在语料库中计数,语料库分为训练集(training set),验证集/保留集(dev/held-out set),测试集(testing set)。保留集从训练集中分离,用于计算一些参数,例如插值模型中的插值系数。
我们以下面两句话为例介绍统计语言模型中常见的几个术语:
有声停顿(fillers/filled pauses): 如uh就是一个没有实际意义的有声停顿。
截断(fragment):表示没有说完整,如re-。
词目(lemma):词语主干(stem)相同,比如dogs和dog是一个词目。
词形(wordforms):完整的词语样子,比如dogs和dog是两个词形。
型(type):语料库或者字典中不同单词的数目,2中有5种型(我 是 不 老 了)。
例(token):语料中单词数目,2中有6例。
字典(vocabulary):语言模型的基本组件,规定了我们对哪些元素进行统计。
为了简化计算,我们采用N N N阶马尔可夫假设,即假定每个词出现的概率只和前N − 1 N-1 N −1个词有关,在此假设下的统计语言模型被称为N-gram语言模型。
当N = 1 N=1 N =1时,每个词出现的概率都与其他词无关,此时的语言模型被称为unigram。
当N = 2 N=2 N =2时,每个词出现的概率只与之前的1个词有关,此时的语言模型被称为bigram。
当N = 3 N=3 N =3时,每个词出现的概率只与之前的2个词有关,此时的语言模型被称为trigram。
实际中最常用的是3-gram语言模型,主要有两个原因:
(1)阶数越高,计算量越大,潜在的计算量呈指数增长;
(2)高阶模型会面临严重的数据稀疏问题。况且,更高阶的模型并不一定能够覆盖所有的语言现象。
通常使用最大似然估计来计算每个词序列出现的条件概率,这是对训练数据的最佳估计,N-gram语言模型用前N − 1 N-1 N −1个词估计第N N N个词,有
P ( w i ∣ w 1 i − 1 ) = P ( w i ∣ w i − N + 1 i − 1 ) = c o u n t ( w i − N + 1 i − 1 w i ) c o u n t ( w i − N + 1 i − 1 ) P(w_i|w_1^{i-1})=P(w_i|w_{i-N+1}^{i-1})=\frac{count(w_{i-N+1}^{i-1}w_i)}{count(w_{i-N+1}^{i-1})}P (w i ∣w 1 i −1 )=P (w i ∣w i −N +1 i −1 )=c o u n t (w i −N +1 i −1 )c o u n t (w i −N +1 i −1 w i )
我们以bigram语言模型为例,有
P ( w i ∣ w i − 1 ) = c o u n t ( w i − 1 w i ) c o u n t ( w i − 1 ) P(w_i|w_{i-1})=\frac{count(w_{i-1}w_i)}{count(w_{i-1})}P (w i ∣w i −1 )=c o u n t (w i −1 )c o u n t (w i −1 w i )
在语料库中统计词序列w i − 1 w i w_{i-1}w_i w i −1 w i 和w i − 1 w_{i-1}w i −1 的数量即可。
开头,结尾和未知词怎么处理?
在语音识别中,一般用< s > 表示句子的开头,< / s > 表示句子的结尾,vocabulary中没有的词用< U N K > 表示。
N-gram语言模型的评价方法主要有两种:
此处主要介绍第二种评价方法,对于句子s = ( w 1 , w 2 , ⋯ , w n ) \boldsymbol{s}=\left( w_1,w_2,\cdots,w_n\right)s =(w 1 ,w 2 ,⋯,w n ),困惑度就是用单词数归一化后的测试集概率:
P P ( s ) = P ( w 1 w 2 ⋯ w n ) − 1 N = 1 P ( w 1 w 2 ⋯ w n ) n = 1 ∏ i = 1 n P ( w i ∣ w i − N + 1 i − 1 ) n \begin{aligned} PP(\boldsymbol{s})&=P(w_1w_2 \cdots w_n)^{-\frac{1}{N}}\ &=\sqrt[n]{\frac{1}{P(w_1w_2 \cdots w_n)}}\ &=\sqrt[n]{\frac{1}{\prod_{i=1}^n P(w_i|w_{i-N+1}^{i-1})}}\ \end{aligned}P P (s )=P (w 1 w 2 ⋯w n )−N 1 =n P (w 1 w 2 ⋯w n )1 =n ∏i =1 n P (w i ∣w i −N +1 i −1 )1
注:通常在语音模型工具包中会给出PPL和PPL1两个值,其中PPL考虑词数和句子数,例如< s > ,而PPL1只考虑词数。
由于语料的稀疏性,有些词序列找不到,需要对数据进行平滑。
基本思想:将每个计数加一,从而使得任何词序列都有计数,以bigram为例:
P l a p l a c e ( w i ∣ w i − 1 ) = c o u n t ( w i − 1 w i ) + 1 c o u n t ( w i − 1 ) + v P_{laplace}(w_i|w_{i-1})=\frac{count(w_{i-1}w_i)+1}{count(w_{i-1})+v}P l a p l a c e (w i ∣w i −1 )=c o u n t (w i −1 )+v c o u n t (w i −1 w i )+1
其中v v v是vocabulary的大小。
优点:算法简单,解决了概率为0的问题。
缺点:原来计数量较高的词序列,概率削减严重,认为所有未出现的词序列概率相等也有点不合理。
基本思想:用你看见过一次的事情(Seen Once)估计你未看见的事件(Unseen Events),并依次类推,用看见过两次的事情估计看见过一次的事情等等。
对于任何出现r r r次的n元组,都假设它出现了r ∗ r^r ∗次:
r ∗ = ( r + 1 ) n r + 1 n r r^=(r+1)\frac{n_{r+1}}{n_r}r ∗=(r +1 )n r n r +1
其中n r n_r n r 是训练集中出现r r r次的N元组的数量,对这个统计数进行归一化得到概率为:
p r = r ∗ N p_r=\frac{r^*}{N}p r =N r ∗
其中N N N是总的token数量。
基本思想:从所有N-grams估计中,把所有的概率估计混合。例如,我们优化一个trigram模型,我们将统计的trigram,bigram和unigram计数进行插值,以trigram为例:
P ( w i ∣ w i − 2 w i − 1 ) = λ 1 P ( w i ∣ w i − 2 w i − 1 ) + λ 2 P ( w i ∣ w i − 1 ) + λ 3 P ( w i ) \begin{aligned} P(w_i|w_{i-2}w_{i-1})&= \lambda_1 P(w_i|w_{i-2}w_{i-1})+\lambda_2P(w_i|w_{i-1})+\lambda_3 P(w_i) \end{aligned}P (w i ∣w i −2 w i −1 )=λ1 P (w i ∣w i −2 w i −1 )+λ2 P (w i ∣w i −1 )+λ3 P (w i )
其中插值系数λ i \lambda_i λi 可以通过EM算法来估计,步骤如下:
基本思想: 若N阶语言模型存在,直接使用打折后的概率(常使用Good-turing算法进行打折);若高阶语言模型不存在(i.e. unseen events),将打折节省出的概率量,依照N-1阶的语言模型概率进行分配,依此类推。
ARPA Format是N-gram的标准存储格式,是一个ASCII表,在小标题后跟着一个表,列举出所有非零的N元语法概率。在每个N元语法的条目中,依次为:
折扣后的对数概率,
词序列,
回退权重。
例如:
l o g 10 P ∗ ( w i ∣ w i − 1 ) log_{10}P^*(w_i|w_{i-1})l o g 1 0 P ∗(w i ∣w i −1 ),
w i − 1 w i w_{i-1}w_i w i −1 w i ,
l o g α ( w i − 1 w i ) log\alpha(w_{i-1}w_i)l o g α(w i −1 w i )
总结下基于统计的 n-gram 语言模型的优缺点:
优点:
缺点:
RNN语言模型
Original: https://blog.csdn.net/qq_39354864/article/details/117400561
Author: sqli96
Title: 语音识别-浅谈语言模型
相关阅读1
相关阅读2
Title: 以NLP技术为核心,容联云对话式AI平台入选《2022中国对话式AI采购指南》
近日,专注数字化产品选型,提供数字化产品评级报告、采购指南的字母点评发布《2022中国对话式AI采购指南》。
容联云凭借以NLP技术为核心的对话式AI平台及智能客服应用,包括文本、导航、坐席辅助、陪练等丰富的对话式产品矩阵入选"中国对话式AI采购指南"核心供应商,并且入选金融行业典型应用案例。
对话式AI市场规模与供应商
中国对话式AI复合增速将达到25.4%容联云入选核心供应商
根据字母点评统计,2020年中国对话式AI市场规模达到32.3亿元,2021年达到50.5亿元,较2020年增长56.3%,呈现高速增长。
未来,企业级对话服务场景需求仍将保持快速增长,预计2021-2025年中国对话式AI复合增速将达到25.4%,2025年中国对话式AI市场规模将达到125.0亿元。
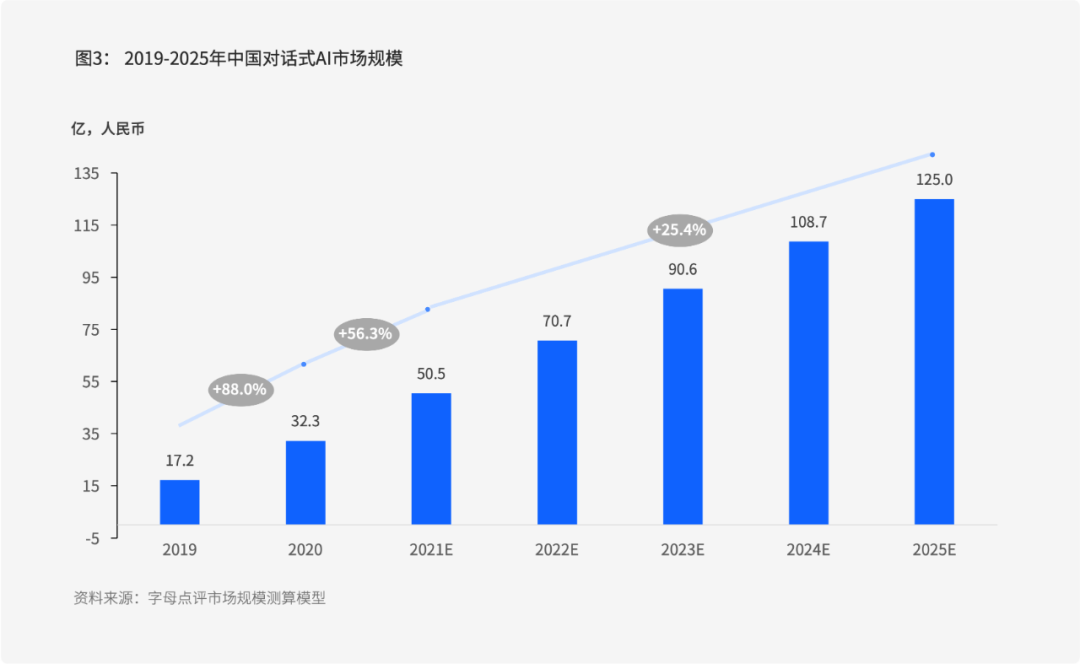
根据供应商旗下对话式AI产品在中国市场的收入情况,字母点评将对话式AI市场上的供应商分为两部分,容联云入选核心供应商。
• 核心供应商:对话式AI产品年收入超过1.5亿元人民币;
• 典型供应商:对话式AI产品年收入在2,000万至1.5亿元人民币。


对话式AI典型案例
容联云以对话式AI技术为核心, 推进某股份制银行智能化客服体系建设
近年来的新冠疫情,让银行业客服业务、客户服务等活动的开展都深受影响。疫情期间银行业务量暴增,客服中心人工坐席不能全员到岗,效率极低,成本居高不下。某股份制银行原有客服中心接待和扩展能力较弱,客服中心平台存在客户等待时间过长、业务受理不及时、智能化不足等问题,加上大部分系统的数字化和智能化能力薄弱,导致客户服务难以正常推进。
在金融机构大力推进数字化转型的背景下,该股份制银行以多渠道接入智能客服场景为核心目标,推进客服智能化体系建设、数据运营体系打造、动态的情绪分析等,全面提升银行在接待过程中的运营效率和客户服务效能,旨在释放AI在客服行业的技术潜能。
经过一系列深度调研,该股份制银行最终选择容联云助力其探索客户服务的数字化转型。容联云以对话式AI技术为支撑,为该银行打造智能在线与智能语音导航IVR,同时提供三大中心一平台(机器人中心、AI中心、知识库中心、多渠道智能客服平台),提升客服中心效率,降低人工成本。
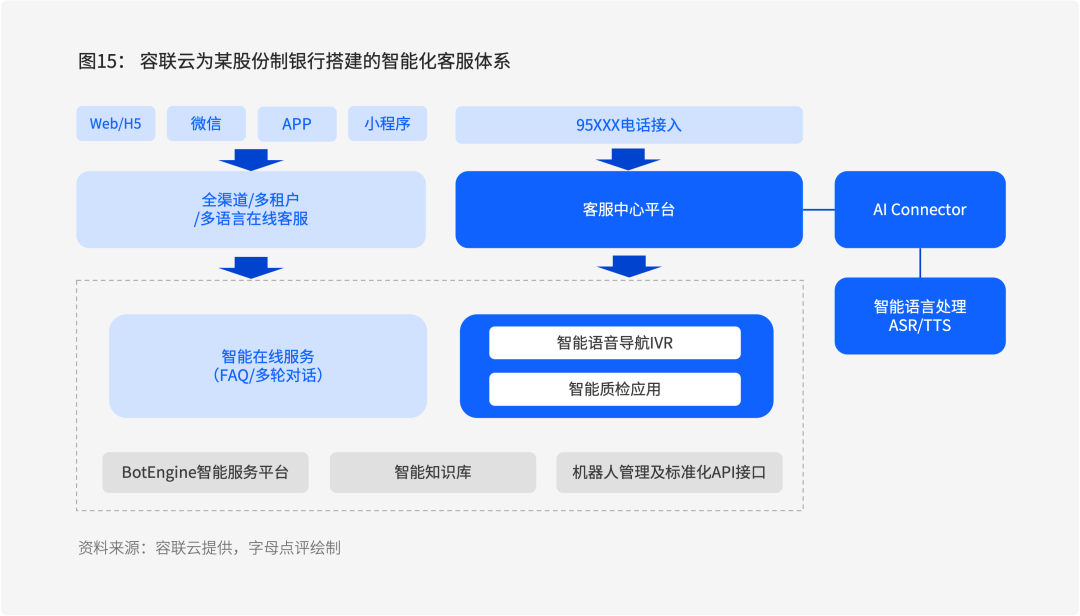
具体来看,容联云为该银行实现如下智能服务:
智能文本:文本交互上,容联云将该银行客服中心在线客服升级为多渠道智能在线客服,支持获取多渠道用户信息,对用户信息进行实时语义理解,识别用户意图,再通过智能知识库推荐或转人工的方式,自动回应客户。
智能导航:语音交互上,容联云智能导航智能IVR,以语音交互方式提供智能导航服务,支持自定义导航任务,智能识别用户意图,自动提供用户所需信息与服务直接语音触达。
智能陪练:智能陪练机器人利用实时语音识别、语音合成、语音质检、知识图谱、语义理解等人工智能技术创造了学习场景与真实业务场景高度融合的"人机对练"模式。随时随地利用碎片化时间,一对一专属陪练,真实场景模拟人机对练,降低培训工作强度,快速掌握业务知识。
智能辅助:智能坐席辅助在用户与坐席进行语音交互的同时,AI进行语音识别、语义理解、对话管理,通过AI应用进行智能填单、金牌话术推荐、话术导航,实时质检,提升管理效率与风险预警能力,降低话后时长,增强业务耦合。

在容联云的赋能下,某股份制银行客户服务实现如下价值与效果:
第一,文本机器人和智能IVR导航,实现7x24小时不间断值班,毫秒级响应,智能识别用户意图,自动提供用户所需信息与服务直接语音触达。
第二,容联智能语音+文本机器人从通话质量、轮次时长、交互轨迹、数据积累、模型评测效果、情绪监测等多维度,对业务数据及会话数据展开统计和分析,帮助企业监控AI应用使用情况,语音质检实现2%到100%的覆盖率。
第三,对内客服训练上,原来的岗前通关考试需组长配合模拟客户角色进行口试,每月2-3批次线下培训,总计10-15天培训时长,通过智能陪练机器人的赋能后,培训周期缩短至4-6天。
第四,在坐席辅助上,通过实时话术推荐,回复问题0延迟,提高客户满意度;关键信息的抽取环节,录单效率提升2倍+。
对话式AI发展趋势
容联云:更理解人、懂得共情更人性化的表达、懂得说话策略
从技术上看,随着企业越来越重视客户体验,注重为用户提供更好的交互感受,对话式AI未来将融合文本、语音和视觉等多模态技术,捕捉同一事物不同维度的细节和信号,提升理解能力或识别准确率,使用户享受更好的客户服务。
随着AI的进步,计算智能、感知智能、认知智能的演进,使得沟通与认知智能的关系发生变化。对话式AI落地到商业场景与产品中,有四种技能:
更理解人:CDP+面向多元谓词逻辑的精细化实体关系抽取方法,融合知识图谱,解决"通过客户的一两句话可迅速感知客户的状态和需求"这一客服最大的挑战。
懂得共情:针对语言数据含有细粒度情感要素,提出双向阅读理解框架+面向多尺度知识结构的自适应表征学习方法,让客服可理解用户对不同"事情/事物"的态度,判断用户未说出口的隐藏意图。
更人性化的表达:让智能客服具有流利表达的基础上不止于描述性的表达,更是始于解决用户的需求和问题。
懂得说话策略:对话策略是话语表达的更高层的结构化运用,根据用户的上下文语义,选择最适配企业经营价值和用户需求的话语逻辑来服务不同场景,比如劝说、协商等。
本报告将对话式AI平台定义为以NLP技术为核心,融合ASR、TTS、机器学习、知识图谱等技术,使机器完成识别、理解和反馈。通过对话式AI平台,企业用户可以构建对话机器人相关产品组合,以实现对话服务场景下的人机交互。
Original: https://blog.csdn.net/xhlylxhl/article/details/123711747
Author: 科技互联
Title: 以NLP技术为核心,容联云对话式AI平台入选《2022中国对话式AI采购指南》
相关阅读3
Title: 【已解决】将CentOS7系统安装至U盘(七):Python3.6虚拟环境安装Tensorflow 1.15和Tensorflow 2.6
建立空文件夹,例如PyVenv,使用Python3.6建立虚拟环境:
cd /home/pyengine/PyVenv
python3 -m venv tensorflow2.6
默认不安装系统库,若需要,可换作以下命令:
python3 -m venv tensorflow2.6 --system-site-packages
激活该虚拟环境:
source ./tensorflow2.6/bin/activate
当虚拟环境处于有效状态时,shell 提示符带有 (tensorflow2.6) 前缀。
在不影响主机系统设置的情况下,在虚拟环境中安装软件包。首先升级 pip:
pip install --upgrade pip
从官网上查看Python3.6支持的Tensorflow版本,并复制网址,使用以下命令安装:
pip install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-2.6.0-cp36-cp36m-manylinux2010_x86_64.whl
安装完成后,按以下方法测试,如不报错说明安装成功:
[pyengine@localhost ~]$ source /home/pyengine/PyVenv/tensorflow2.6/bin/activate
(tensorflow2.6) [pyengine@localhost ~]$ python
Python 3.6.8 (default, Mar 10 2022, 22:41:33)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import tensorflow as tf
>>> exit()
(tensorflow2.6) [pyengine@localhost ~]$
退出虚拟环境:
deactivate
之所以在开发时选择虚拟环境,除了避免库之间的冲突,还有重要的原因是方便部署,因为虚拟环境是独立的,仅包含了项目相关的依赖库,所以部署的效率更高,风险更小
一般部署流程是:
开发完成后,使用 pip freeze > requirements.txt 命令将项目的库依赖导出,作为代码的一部分
将代码上传到服务器
在服务器上创建一个虚拟环境
激活虚拟环境,执行 pip install -r requirements.txt,安装项目依赖
依赖包版本不合适引起,例如版本过高。
按以上方法可安装Tensorflow1.15,
pip install https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow_cpu-1.15.0-cp36-cp36m-manylinux2010_x86_64.whl
若使用命令pip install pandas后,使用时报pandas模块导入错误,原因是pandas版本过高,需使用以下命令安装低版本:
pip uninstall pandas
pip install pandas==0.23.0
Original: https://blog.csdn.net/baidu_41764522/article/details/123444840
Author: pyengine
Title: 【已解决】将CentOS7系统安装至U盘(七):Python3.6虚拟环境安装Tensorflow 1.15和Tensorflow 2.6