
本文来自公众号"AI大道理"。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
单音子模型的假设是一个音素的实际发音与其左右的音素无关。
这个假设与实际并不符合。
由于单音子模型过于简单,识别结果不能达到最好,因此需要继续优化升级。
就此引入多音子的模型。
最为熟悉的就是三音子模型,即上下文相关的声学模型。
在YesNo实例中没有进行三音子的模型训练。
因此我们转向thchs30这个实例。
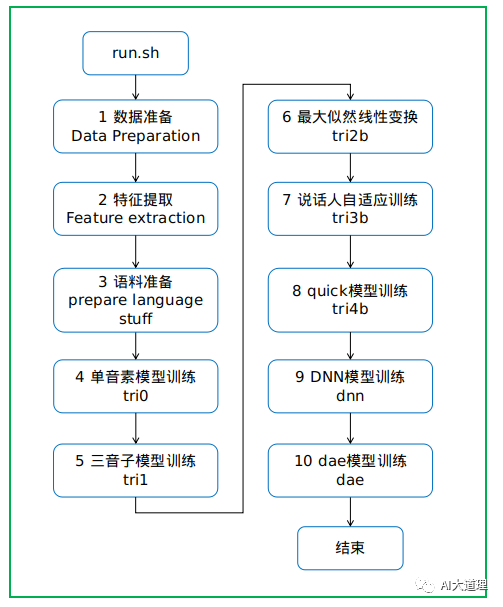
 0 总过程
0 总过程
1 数据准备
先下载thchs30数据集,然后进行数据准备。
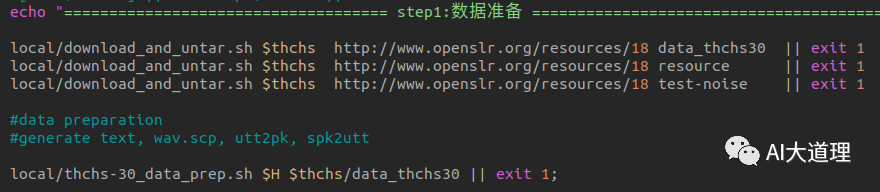
1.1 download_and_untar.sh
功能:
下载数据。
源码解析:
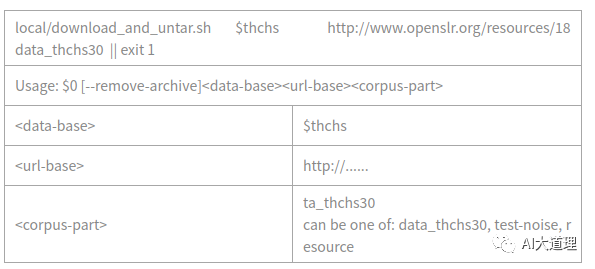
在egs/thchs30/s5下新建了一个文件夹thchs30-openslr,然后把三个文件解压在了该文件夹下。
这个数据集包含以下内容:

1.2 thchs-30_data_prep.sh
功能:
进入thchs30-openslr/data_thchs30/train、dev、test目录,它读取语料库并得到wav.scp和音标,生成文本text,wav.scp,uut3pk,spk2utt。
源码解析:

mkdir -p data/{train,dev,test} # 创建data目录。
在这三个目录下生成文件。
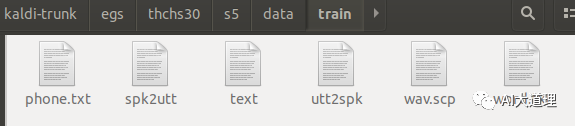
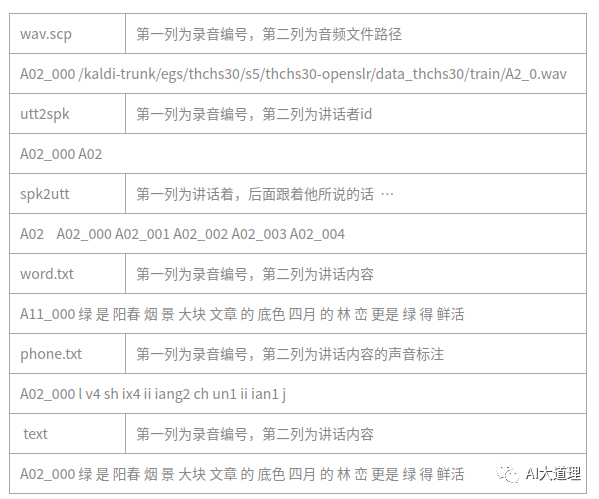
运行结果:
2 特征提取
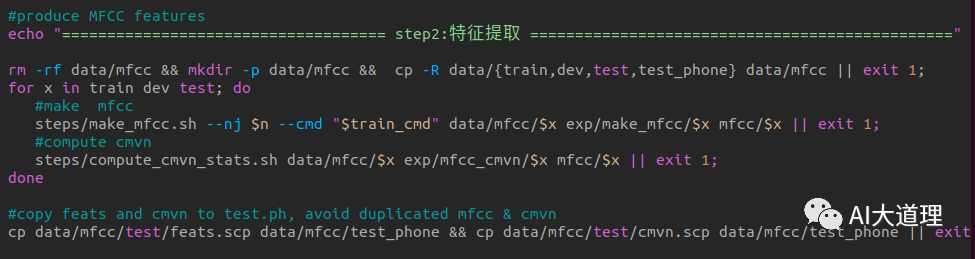
2.1 make_mfcc.sh
功能:
MFCC特征提取。
源码解析:

部分源码:
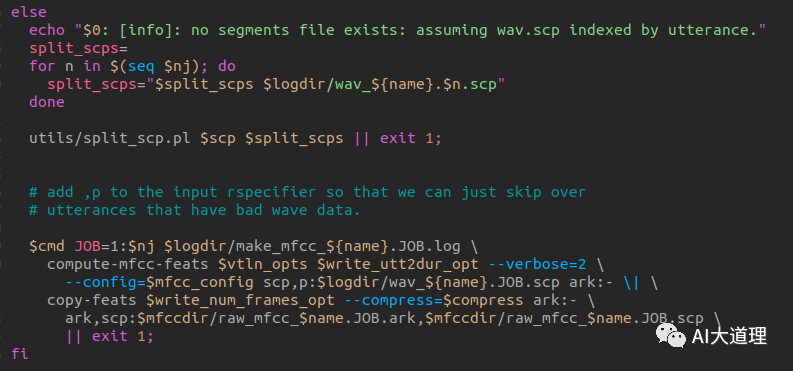
利用Kaldi的compute-mfcc-feats工具计算梅尔倒谱频率特征,然后利用copy-feats工具的参数—compress=true 压缩处理存储为两个文件类型ark和scp。
调用命令行工具compute-mfcc-feats,提取特征,创建feats.ark和feats.scp文件。
用法为:
compute-mfcc-feats [options...]
运行结果:
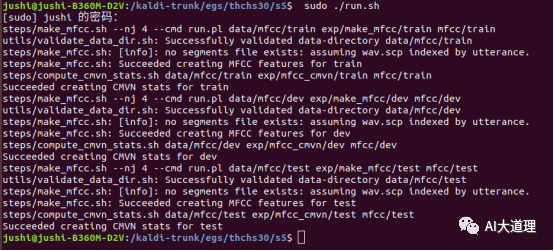
生成 mfcc特征,计算cmvn倒谱均值方差归一化完毕。
3 语料准备
准备发音词典和训练语言模型。
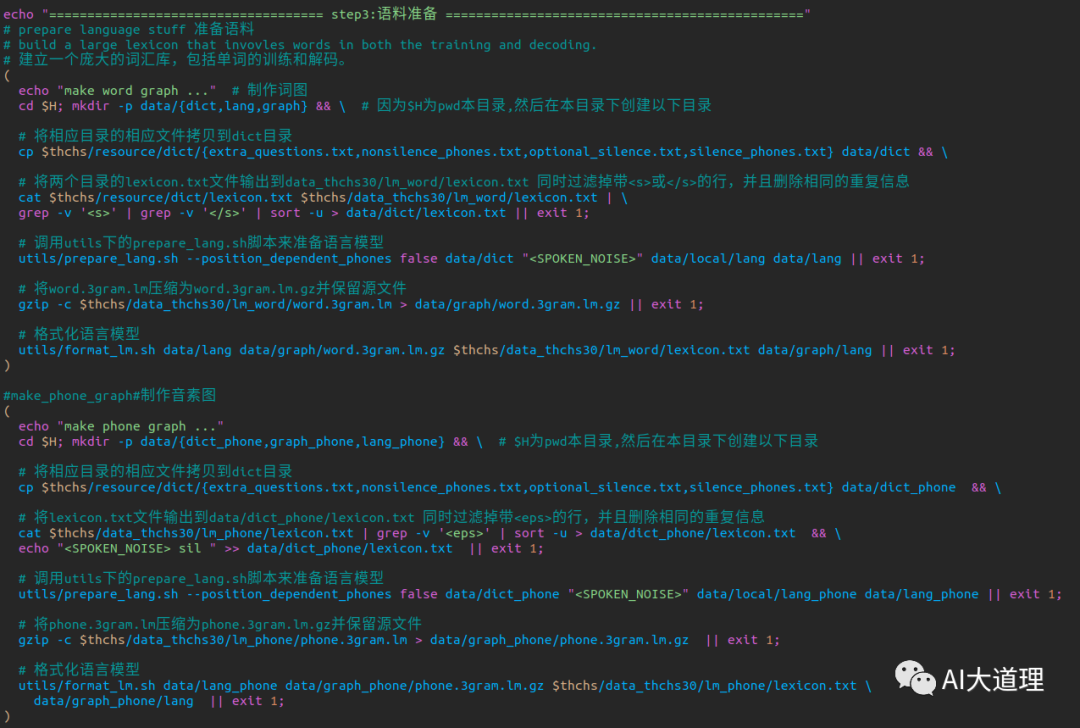
3.1 prepare_lang.sh
读取input的资源文件,生成data/lang目录,是Kaldi的标准语言文件夹。
3.2 format_lm.sh
格式化语言模型,就是把arpa的language model 转换成 FST格式。
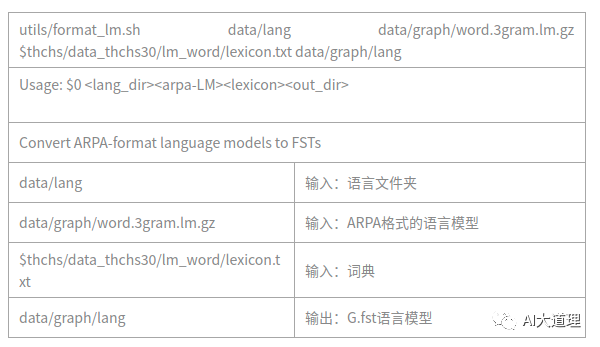
运行结果:
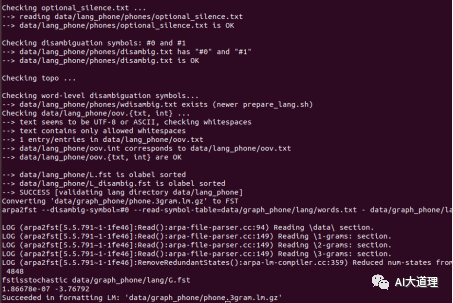
标准语言文件夹:

生成G.fst语言模型:
语料准备完毕。
4 单音子模型训练

4.1 train_mono.sh
用来训练单音子隐马尔科夫模型,一共进行40次迭代,每两次迭代进行一次对齐操作。
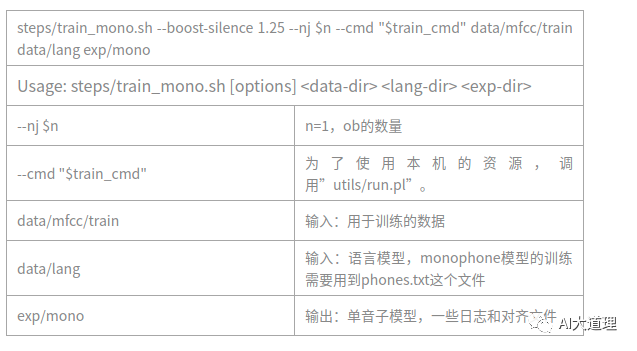
过程之道:
初始化模型->生成训练图HCLG.fst->对标签进行初始化对齐->统计估计模型所需的统计量->估计参数得到新模型->迭代训练->最后的模型final.mdl。
训练的模型:
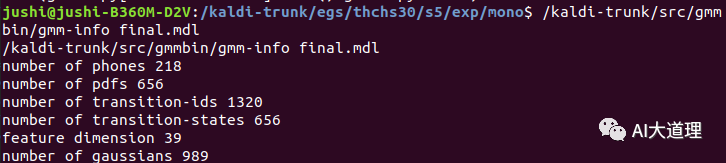
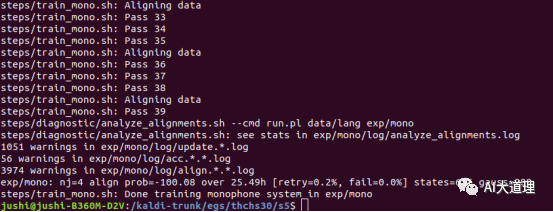
训练完毕。
4.2 thchs-30_decode.sh
测试单音素模型,实际使用mkgraph.sh建立完全的识别网络,并输出一个有限状态转换器,最后使用decode.sh以语言模型和测试数据为输入计算WER。

打开thchs-30_decode.sh
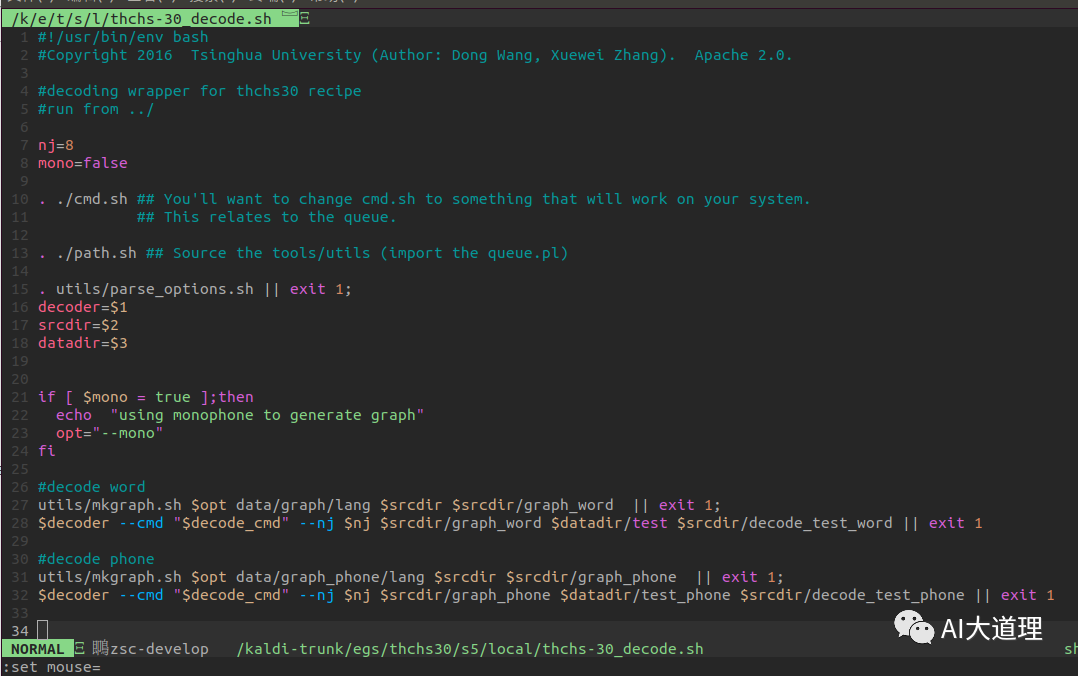
发现里面包含了构图和解码两个步骤。
mkgraph.sh构造出了HCLG.fst。
decode.sh进行解码识别测试模型识别率。
部分解码结果:
真正结果(标签):

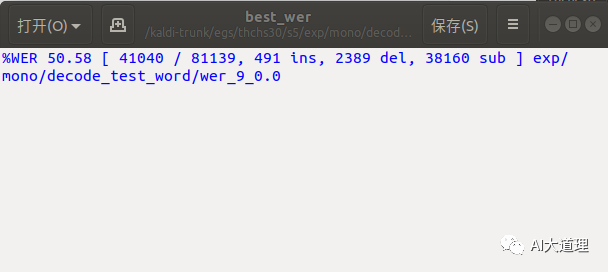
可见识别结果不是很理想,词错误率高达50.58%
4.3 align_si.sh
之前YesNo是没有这一步的。
这一步是为了三音子训练提供对齐基础
用指定模型对指定数据进行对齐,一般在训练新模型前进行,以上一版本模型作为输入,输出在

 真正进行对齐的地方。
真正进行对齐的地方。

4.4 compile-train-graphs
(在训练单音子模型的编译训练图中遇到过这个源码)
训练用每句话转换成一个FST结构,输入是音素,输出是整个句子。
输入:tree , transition_model ,L.fst(Lexicon),训练文件标注text。
输出:为图 HCLG.fst
标注文本text:

为了获得每一帧对应的状态号作为训练的标签,需要构建一个直线形的状态图。
在这个图上利用Viterbi算法求得最优路径,同时得到帧与状态的对齐。
源码解析:

4.5 gmm-align-compiled
对每一句话,根据这句话的特征和这句话的fst,生成对应的对齐状态序列。

对齐结果:
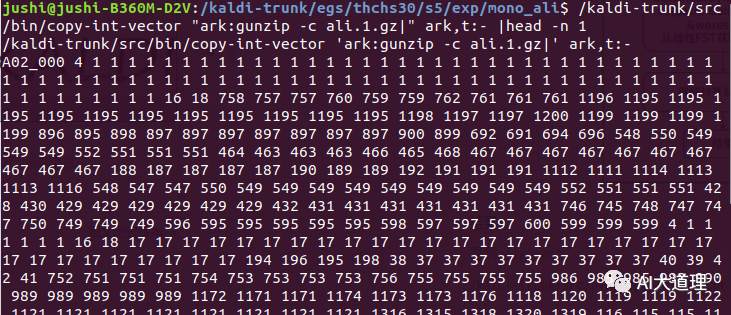
5 总结
训练好了单音素模型,得到一个对齐序列,接下来可以进行三音子模型的训练了。
三音子模型与单音素模型的主要差别在于三音子模型决策树状态的绑定。
单音素系统可以看成是上下文相关系统的一个特殊情况,窗的大小N=1和一个不做任何事情的树。

——————
浅谈则止,细致入微AI大道理
扫描下方"AI大道理",选择"关注"公众号
—————————————————————

—————————————————————
Original: https://blog.csdn.net/qq_42734492/article/details/112385262
Author: AI大道理
Title: AIBigKaldi(十)| Kaldi的thchs30实例(源码解析)
相关阅读1
Title: MASS | 广义线性模型(四)——负二项回归
本篇是"广义线性模型"系列推文的最后一篇,来介绍另外一种重要的广义线性模型:负二项回归。
同泊松回归一样,负二项回归也是计数模型。由于泊松回归的内在要求是因变量的数学期望和方差相等,而当数据序列出现"过度离散"(方差比理论值大)时,可有两种方式进行模型修正:
- 使用准泊松分布族;
- 改用负二项回归。
前者已经介绍过了,本篇来介绍后者——负二项回归。
模型形式
负二项回归的模型形式与泊松回归十分相似。
泊松回归:
负二项回归:
泊松分布与负二项分布有着内在的联系。当泊松分布的参数 不再是一个确定的数值,而是服从伽马分布进行变化时,此时的分布形式称为 伽马-泊松混合分布,负二项分布是伽马-泊松混合分布的特例。
《Modern Applied Statistics with S-PLUS》[1]上有关于负二项分布与泊松分布关系的描述:
负二项分布的方差恒大于数学期望,并受参数 的影响。从模型形式上看,负二项回归比泊松回归多了一个随机项 :
- 为伽马分布的记号。
负二项分布
泊松分布的概率函数如下:
伽马分布 的概率密度函数如下:
为形状参数, 为逆尺度参数。数学期望 ,方差 。
伽马-泊松混合分布的概率密度函数如下:
负二项分布的概率函数如下:
对比伽马-泊松混合分布和负二项分布的概率(密度)函数,令 , ,则二者相等。
负二项分布的意义:随机事件刚好第 次发生(不发生)时所经历的不发生(发生)的次数。
模型的R代码
负二项回归虽然属于广义线性模型,但在 stats工具包中并没有定义负二项分布族函数。
MASS工具包的 glm.nb函数可以进行负二项回归,并自动确定 参数的取值。
glm.nb(formula, data, weights,
subset, na.action,
start = NULL, etastart, mustart,
control = glm.control(...),
method = "glm.fit",
model = TRUE, x = FALSE, y = TRUE,
contrasts = NULL, ...,
init.theta, link = log)
MASS工具包的名称即上面提到的《Modern Applied Statistics with S-PLUS》的首字母缩写;glm.nb函数专门用于负二项回归,因此无需family参数。
library(MASS)
model.nb |z|)
## (Intercept) 2.89458 0.22842 12.672
MASS工具包还定义可以在 glm函数中使用的负二项分布族函数 negative.binomial:
negative.binomial(theta = stop("'theta' must be specified"),
link = "log")
使用 negative.binomial函数时需指定 参数。根据《Modern Applied Statistics with S-PLUS》中的方法,可以使用 MASS工具包中的 logtrans函数大致确定 的取值:
logtrans(Days ~ Eth + Sex + Age+ Lrn,
data = quine)
根据上图, 的最佳取值约等于2。
model.nb2 |t|)
## (Intercept) 2.88658 0.22715 12.708
相关阅读:
[1]
Venables, W. N. and Ripley, B. D. (1999) Modern Applied Statistics with S-PLUS. Third Edition. Springer .
Original: https://blog.csdn.net/weixin_54000907/article/details/117915956
Author: R语言学堂
Title: MASS | 广义线性模型(四)——负二项回归
相关阅读2
Title: Tensoflow c++ so编译 基于bazel
每日一歌,分享好心情:叶卡捷琳娜战歌
一、起点
- 为什么编译tensorfflow?
nvidia 2020年发布的Ampere架构gpu支持TF32,为了比对TF32、FP32推理速度,而公司现在用的Tensorflow版本太老,不支持TF32, so,升级TF。
2. 编译环境怎么选?
由于我需要编译支持GPU的tensorflow,所以需要在cuda环境编译。一般是选择nvidia官方devel镜像(关于这方面有很多有趣的话题,在以后的文章中聊吧),结合我的GPU硬件情况,选择nvidia/cuda:11.4.2-cudnn8-devel-ubuntu18.04, 编译过程都在此docker中进行(话说,在企业中离了docker真过不了~~)
二、环境准备
- 下载tf源码
没什么可说的,clone吧 ,附上github源码地址: https://github.com/tensorflow/tensorflow
我使用最新的2.8.0版本(2022-04-29)。 - 安装编译工具bazel
这里有个小坑,不同版本的tf对bazel版本要求不同。
下载完源码后,在源码顶层目录configure.py文件中有对bazel的要求,
_TF_MIN_BAZEL_VERSION = '4.2.1'
_TF_MAX_BAZEL_VERSION = '4.99.0'
本次编译选择 4.2.1版本,bazel安装过程嘛,可以按照tf官方给的教程https://www.tensorflow.org/install/source#install_bazel,其实,直接下载bazel可执行程序更简单,下载地址(https://github.com/bazelbuild/bazel/releases/download/4.2.1/bazel-4.2.1-linux-x86_64),下载完成后加入PATH路径,再ln一下,ok~~

; 三、编译配置
- 配置build
在源码顶层目录下,运行
./configure
配置过程中最重要的步骤是开启GPU支持以及设置计算能力
ps:计算能力这个被nvidia造出来的概念也会在后续文章中聊聊,比如怎么识别gpu的计算能力、计算能力一般用在哪里、怎样在计算能力是7.5的环境中编译出支持8.0的库...。
- 选择python版本:

- 开启gpu支持:

- 开启TF-TRT支持:
如果需要的话就开启,一般是需要滴...毕竟TRT是老黄的嫡系呀,加速真是杠杠的...
这里需要提前下载好TensorRT 官方build包(晕,坑有点多,还需要去nvidia官网注册个会员),附上地址https://developer.nvidia.com/nvidia-tensorrt-8x-download
下载好,我直接解压到根目录了,毕竟咱是在自己的docker中嘛,随便折腾...
后面编译需要用到TRT,那就得让TF知道TRT在哪儿呀,so,设置环境变量
export TENSORRT_INSTALL_PATH=/TensorRT-8.2.1.8/
ps: 感兴趣的话,你可以在源码里可以看一下这个环境是什么时候起作用的,,我就不说了,说多了都是泪呀
- 设置计算能力:
这一步需要根据自己编译出来的库的gpu运行环境设置,我这里因为需要运行在安培架构的GPU上,需要额外设置,不能用默认的,其实也可以,只不过inference速度会慢一丢丢,具体设置步骤参考: 《计算能力那些事儿》。

其他选项使用默认即可。
其实,./configure程序会根据我们的输入产生一个叫.tf_configure.bazelrc的配置文件(如果你是大牛或者疯子,直接编辑这个文件也可以).
以下是此次生成的文件内容:
build --action_env PYTHON_BIN_PATH="/usr/bin/python3"
build --action_env PYTHON_LIB_PATH="/usr/lib/python3/dist-packages"
build --python_path="/usr/bin/python3"
build --config=tensorrt
build --action_env CUDA_TOOLKIT_PATH="/usr/local/cuda-11.4"
build --action_env TENSORRT_INSTALL_PATH="/TensorRT-8.2.1.8/"
build --action_env TF_CUDA_COMPUTE_CAPABILITIES="6.1,7.0,7.5,8.0,8.6"
build --action_env LD_LIBRARY_PATH="/workspace/third_party/source/w16/third_party/prebuilt/tensorrt8_install/linux-x64-cuda114/lib:/workspace/third_party/source/w16/third_party/prebuilt/openvino_install/linux-x64-cuda114/lib/intel64:/workspace/third_party/source/w16/third_party/prebuilt/caffe_install/linux-x64-cuda114/lib:/workspace/third_party/source/w16/third_party/prebuilt/pytorch_install/linux-x64-cuda114/lib:/workspace/third_party/source/w16/third_party/prebuilt/onnx_install/linux-x64-cuda114/lib:/workspace/third_party/source/w16/third_party/prebuilt/ncnn_install/linux-x64-cuda114/lib"
build --action_env GCC_HOST_COMPILER_PATH="/usr/bin/x86_64-linux-gnu-gcc-7"
build --config=cuda
build:opt --copt=-Wno-sign-compare
build:opt --host_copt=-Wno-sign-compare
test --flaky_test_attempts=3
test --test_size_filters=small,medium
test --test_env=LD_LIBRARY_PATH
test:v1 --test_tag_filters=-benchmark-test,-no_oss,-no_gpu,-oss_serial
test:v1 --build_tag_filters=-benchmark-test,-no_oss,-no_gpu
test:v2 --test_tag_filters=-benchmark-test,-no_oss,-no_gpu,-oss_serial,-v1only
test:v2 --build_tag_filters=-benchmark-test,-no_oss,-no_gpu,-v1only
四、开始真正的编译
提前说好,这是一个漫长的过程
在tensorflow源码顶层目录,运行
bazel build --config=opt --config=cuda --verbose_failures //tensorflow:libtensorflow_cc.so //tensorflow:install_headers
如果你不了解bazel编译的话,这个命令乍看起来可能有点晕,这里只简单介绍以下,后续文章再详谈bazel编译系统。
- –config=cuda: 指定编译配置,至于cuda都包含哪些配置,可以查看.bazelrc
- –verbose_failures: 你懂的
- //tensorflow:libtensorflow_cc.so:指定编译/tensorflow目录下的libtensorflow_cc.so目标(因为我需要tf的c++接口嘛)
- //tensorflow:install_headers: 指定编译/tensorflow目录下的install_headers目标
让bazel飞一会儿...耐心等待...
编译过程是真的慢,用到了很多第三方库,我大胆预测,这将是你程序猿生丫编译程序最long的一次~~
下面是我的编译日志,贴出来吧,没啥用,就是为了纪念这次编译。
Starting local Bazel server and connecting to it...
WARNING: The following configs were expanded more than once: [cuda]. For repeatable flags, repeats are counted twice and may lead to unexpected behavior.
INFO: Options provided by the client:
Inherited 'common' options: --isatty=0 --terminal_columns=80
INFO: Reading rc options for 'build' from /workspace/tf/tensorflow-2.8.0/.bazelrc:
Inherited 'common' options: --experimental_repo_remote_exec
INFO: Reading rc options for 'build' from /workspace/tf/tensorflow-2.8.0/.bazelrc:
'build' options: --define framework_shared_object=true --java_toolchain=@tf_toolchains//toolchains/java:tf_java_toolchain --host_java_toolchain=@tf_toolchains//toolchains/java:tf_java_toolchain --define=use_fast_cpp_protos=true --define=allow_oversize_protos=true --spawn_strategy=standalone -c opt --announce_rc --define=grpc_no_ares=true --noincompatible_remove_legacy_whole_archive --enable_platform_specific_config --define=with_xla_support=true --config=short_logs --config=v2 --define=no_aws_support=true --define=no_hdfs_support=true --experimental_cc_shared_library
INFO: Reading rc options for 'build' from /workspace/tf/tensorflow-2.8.0/.tf_configure.bazelrc:
'build' options: --action_env PYTHON_BIN_PATH=/usr/bin/python3 --action_env PYTHON_LIB_PATH=/usr/lib/python3/dist-packages --python_path=/usr/bin/python3 --config=tensorrt --action_env CUDA_TOOLKIT_PATH=/usr/local/cuda-11.4 --action_env TENSORRT_INSTALL_PATH=/TensorRT-8.2.1.8/ --action_env TF_CUDA_COMPUTE_CAPABILITIES=3.5,6.1,7.0,7.5,8.6 --action_env LD_LIBRARY_PATH=/usr/local/nvidia/lib:/usr/local/nvidia/lib64:/TensorRT-8.2.1.8/lib:/opt/aibee/protobuf/lib/ --action_env GCC_HOST_COMPILER_PATH=/usr/bin/x86_64-linux-gnu-gcc-7 --config=cuda
INFO: Reading rc options for 'build' from /workspace/tf/tensorflow-2.8.0/.bazelrc:
'build' options: --deleted_packages=tensorflow/compiler/mlir/tfrt,tensorflow/compiler/mlir/tfrt/benchmarks,tensorflow/compiler/mlir/tfrt/jit/python_binding,tensorflow/compiler/mlir/tfrt/jit/transforms,tensorflow/compiler/mlir/tfrt/python_tests,tensorflow/compiler/mlir/tfrt/tests,tensorflow/compiler/mlir/tfrt/tests/analysis,tensorflow/compiler/mlir/tfrt/tests/jit,tensorflow/compiler/mlir/tfrt/tests/lhlo_to_tfrt,tensorflow/compiler/mlir/tfrt/tests/tf_to_corert,tensorflow/compiler/mlir/tfrt/tests/tf_to_tfrt_data,tensorflow/compiler/mlir/tfrt/tests/saved_model,tensorflow/compiler/mlir/tfrt/transforms/lhlo_gpu_to_tfrt_gpu,tensorflow/core/runtime_fallback,tensorflow/core/runtime_fallback/conversion,tensorflow/core/runtime_fallback/kernel,tensorflow/core/runtime_fallback/opdefs,tensorflow/core/runtime_fallback/runtime,tensorflow/core/runtime_fallback/util,tensorflow/core/tfrt/common,tensorflow/core/tfrt/eager,tensorflow/core/tfrt/eager/backends/cpu,tensorflow/core/tfrt/eager/backends/gpu,tensorflow/core/tfrt/eager/core_runtime,tensorflow/core/tfrt/eager/cpp_tests/core_runtime,tensorflow/core/tfrt/fallback,tensorflow/core/tfrt/gpu,tensorflow/core/tfrt/run_handler_thread_pool,tensorflow/core/tfrt/runtime,tensorflow/core/tfrt/saved_model,tensorflow/core/tfrt/saved_model/tests,tensorflow/core/tfrt/tpu,tensorflow/core/tfrt/utils
INFO: Found applicable config definition build:short_logs in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --output_filter=DONT_MATCH_ANYTHING
INFO: Found applicable config definition build:v2 in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --define=tf_api_version=2 --action_env=TF2_BEHAVIOR=1
INFO: Found applicable config definition build:tensorrt in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --repo_env TF_NEED_TENSORRT=1
INFO: Found applicable config definition build:cuda in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --repo_env TF_NEED_CUDA=1 --crosstool_top=@local_config_cuda//crosstool:toolchain --@local_config_cuda//:enable_cuda
INFO: Found applicable config definition build:opt in file /workspace/tf/tensorflow-2.8.0/.tf_configure.bazelrc: --copt=-Wno-sign-compare --host_copt=-Wno-sign-compare
INFO: Found applicable config definition build:cuda in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --repo_env TF_NEED_CUDA=1 --crosstool_top=@local_config_cuda//crosstool:toolchain --@local_config_cuda//:enable_cuda
INFO: Found applicable config definition build:linux in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --copt=-w --host_copt=-w --define=PREFIX=/usr --define=LIBDIR=$(PREFIX)/lib --define=INCLUDEDIR=$(PREFIX)/include --define=PROTOBUF_INCLUDE_PATH=$(PREFIX)/include --cxxopt=-std=c++14 --host_cxxopt=-std=c++14 --config=dynamic_kernels --distinct_host_configuration=false --experimental_guard_against_concurrent_changes
INFO: Found applicable config definition build:dynamic_kernels in file /workspace/tf/tensorflow-2.8.0/.bazelrc: --define=dynamic_loaded_kernels=true --copt=-DAUTOLOAD_DYNAMIC_KERNELS
Loading: (1 packages loaded)
Loading: 1 packages loaded
Analyzing: 2 targets (2 packages loaded, 0 targets configured)
Analyzing: 2 targets (68 packages loaded, 218 targets configured)
Analyzing: 2 targets (149 packages loaded, 4788 targets configured)
Analyzing: 2 targets (215 packages loaded, 13237 targets configured)
Analyzing: 2 targets (241 packages loaded, 28753 targets configured)
INFO: Analyzed 2 targets (241 packages loaded, 28758 targets configured).
INFO: Found 2 targets...
[0 / 7] [Prepa] BazelWorkspaceStatusAction stable-status.txt
[376 / 3,292] checking cached actions
[624 / 3,584] Linking external/nsync/libnsync_cpp.so; 0s local
[791 / 3,589] Linking external/nsync/libnsync_cpp.so; 2s local ... (2 actions, 1 running)
[1,069 / 3,761] Linking external/nsync/libnsync_cpp.so; 6s local ... (2 actions running)
[1,315 / 3,888] Linking external/nsync/libnsync_cpp.so; 8s local ... (2 actions running)
[1,636 / 6,949] Linking external/com_google_absl/absl/base/libmalloc_internal.so; 1s local
[2,051 / 9,341] checking cached actions
[2,612 / 10,002] checking cached actions
[11,328 / 15,022] [Prepa] Writing file tensorflow/core/kernels/mlir_generated/libminimum_gpu_i8_i8_kernel_generator.so-2.params
[13,148 / 17,690] checking cached actions
[16,206 / 22,395] checking cached actions
[20,075 / 28,871] Linking external/llvm-project/mlir/libX86VectorToLLVMIRTranslation.so; 0s local ... (2 actions running)
[22,736 / 30,167] checking cached actions
[24,208 / 30,167] checking cached actions
[25,739 / 30,167] checking cached actions
[26,947 / 30,167] Linking tensorflow/core/kernels/linalg/libmatrix_set_diag_op_gpu.so; 0s local ... (2 actions, 1 running)
[28,002 / 30,167] Linking tensorflow/compiler/mlir/tfr/libgraph_decompose_pass.so; 0s local ... (6 actions, 5 running)
[30,165 / 30,167] [Prepa] Executing genrule //tensorflow:libtensorflow_cc.so.2_sym
INFO: Elapsed time: 284.425s, Critical Path: 156.23s
INFO: 6111 processes: 4073 internal, 2038 local.
INFO: Build completed successfully, 6111 total actions
INFO: Build completed successfully, 6111 total actions
五、整理库目录
编译完了,我们需要将编译成功的库拷贝出来给别人用,
下面将so及头文件整理一下
mkdir -p tf_install/include/
mkdir -p tf_install/lib/
cp -rd bazel-bin/tensorflow/include/* tf_install/include/
cp -rd bazel-bin/tensorflow/libtensorflow* tf_install/lib/
include 目录:

lib目录:

ok,万事大吉~~干饭
六、题外话
如果漂亮国真禁用github或者限个龟速,吾辈休矣!
Original: https://blog.csdn.net/wohenibdxt/article/details/123557428
Author: 小白龙呢
Title: Tensoflow c++ so编译 基于bazel
相关阅读3
Title: Interactive Speech and Noise Modeling for Speech Enhancement
文章目录
- 0. 摘要
- 1. Introduction
* - 2. Related work
- - 3. Proposed Method
* - 3.1 Overview
- 3.2 Encoder and Decoder
- 3.3 RA Block
- 3.4 Interaction Module
- 3.5 Merge Branch
- 4. Experiments
* - 4.1 Datasets
- 4.2 Evaluation Metrics
- 4.3 Implementation Details
- 4.4 Ablation Study
- - 4.5 Comparison with the state-of-the-art

; 0. 摘要
AAAI2021paper
当前大多数模型都是对语音进行建模,而不是对噪声。本文提出了一种在两分支卷积神经网络(SN-NET)中同时对语义和噪声进行建模的方法,两个分支分别对语音和噪声进行预测。不仅仅是在最终输出层进行信息融合,本文模型在两个分支之间的几个中间特征域中引入交互模块to benefit each other. 这种交互可以利用从一个分支学到的特征来抵消不需要的部分并恢复另一份分支的缺失部分,从而增强两个分支的辨别能力。此外,本文还设计了一个特征提取模块——残差卷积注意力模块(residual-convolution and attention, RA),以获取语音和噪声沿时间和频率维度的相关性。对公共数据集的评估结果表明,交互模块在同步建模中起到了关键作用,SN-Net模型在多项评估指标中获得了STOA性能,该模型同样能够应用到说话人分离领域。
- Introduction
主流的基于深度学习语音信号预测方法采用有监督学习的策略,如图1(a)所示:
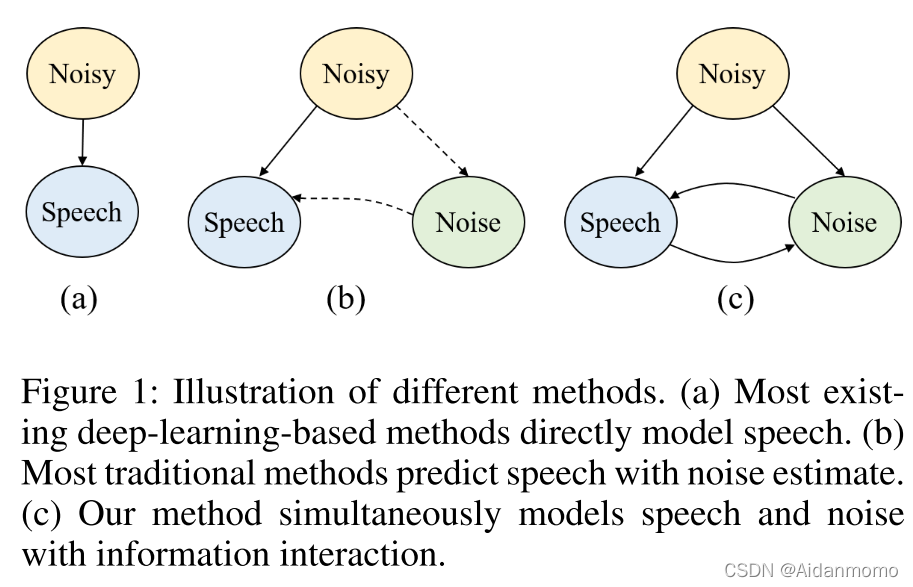
多数科研工作在时频域对信号进行处理,预测noisy和clean信号之间的mask或者直接对干净语音的频谱进行估计。同样有一些方法直接在时域上进行处理,采用端到端的方法预测语音信号。 虽然这些方法相较于传统方法在语音增强性能方面取得了很大的提升,但是增强后的语音仍然存在语音失真和残留噪声的问题,这就说明,预测语音和残留噪声之间依然存在相关性。
与当前基于深度学习的方法有所不同,传统的语音信号处理和基于模型的方法中,大多采用其他策略,如图1(b)所示,例如:通过估计噪声或者构建噪声模型的方式进行语音增强。但是当其不能满足先验噪声假设或者干扰信号没有结构化时,这些方法往往不能很好的发挥作用。在深度学习领域,有两项工作【Odelowo and Anderson 2017, 2018】直接对噪声进行预测,其主要考虑噪声在低信噪比条件下占主导地位,但是方法取得效果有限。
Odelowo, B. O.; and Anderson, D. V. 2017. A noise prediction and time-domain subtraction approach to deep neural network based speech enhancement. In 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), 372–377. IEEE.
Odelowo, B. O.; and Anderson, D. V. 2018. A study of training targets for deep neural network-based speech enhancement using noise prediction. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 5409–5413. IEEE
预测语音和噪声之间依然存在的相关性,促使本文探索语音和噪声之间的信息流,如图1(c)所示。由于和语音相关信息可能存在于预测的噪声中,反之亦然,因此在它们之间添加信息通信可能有助于恢复一些缺失的信息,并从对方的信息中去除不需要的内容。在本文中,作者提出了一种双分支卷积神经网络-SN-Net,同时对语音和噪声信号进行预测。分支之间使用信息交互模块,通过信息交互,达到相互促进和抵消的目的。通过该方法,模型的辨别能力得到了有效提升。两个分支共享网络结构,采用基于encoder-decoder的模型架构,中间有几个参加卷积和注意力块(RA)用于分离。本文在每个RA块内结合实践自注意力和频率自主利益,以可分离的方式捕获延时间和频率维度的全局依赖性。
; 2. Related work
2.1 Deep learning-based speech enhancement
主要分为时频域方法和时域信号处理方法。前者主要使用经过STFT变换后的T-F表示作为网络输入,可以是复数信息,也可以是幅度谱信息,通常估计出一个实数或者复数mask,或者直接对干净语音的频谱表示进行预测。后者直接使用时域波形信息作为网络输入,通过encoder提取隐层特征表示,并通过decoder重建增强后的语音。
2.2 Noise-aware speech enhancement
针对噪声信息的处理通常出现在传统的信号处理方法中,这些方法通常会使用语音和噪声的先验分布假设。然而,对非平稳噪声的噪声功率谱密度进行估计是非常困难的,因此通常假设噪声为平稳信号。一些基于模型的方法显示出更有前景的结果,这些方法同时为语音和噪声进行建模。例如基于codebook的方法【Srinivasan, Samuelsson, and Kleijn 2005b,a】和基于非负矩阵分解的方法【Wilson et al. 2008; Mohammadiha, Smaragdis, and Leijon 2013】。但是这些方法或者需要噪声类型的先验知识【codebook方法】,或者只对结构化噪声有效【NMF方法】。因此基于模型的方法泛化性能较差。
基于深度学习的方法能够应用于各种噪声条件中,当前已经有一些工作尝试考虑噪声信息,例如,通过损失函数加以约束【Fan et al. 2019; Xu, Elshamy, and Fingscheidt 2020; Xia et al. 2020】,或者直接对噪声进行预测,而不是预测语音【Fan et al. 2019; Xu, Elshamy, and Fingscheidt 2020; Xia et al. 2020】。前者没有对噪声进行建模,同时也没有利用噪声的特性。后者丢掉了语音信息,甚至在低信噪比和unseen noise 条件下取得的性能要差于其他方法。【Sun et al. 2015】曾利用两个深度自编码器(DAEs)对语音和噪声进行估计。该方法首先训练一个DAE对语音频谱进行重构,之后利用另外一个DAE对噪声进行建模,约束条件的是两个DAE的输出之和等于噪声频谱。
Xu, Z.; Elshamy, S.; and Fingscheidt, T. 2020. Using Separate Losses for Speech and Noise in Mask-Based Speech Enhancement. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7519–7523. IEEE.
Xia, Y.; Braun, S.; Reddy, C. K.; Dubey, H.; Cutler, R.; and Tashev, I. 2020. Weighted Speech Distortion Losses for Neural-Network-Based Real-Time Speech Enhancement. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 871– 875. IEEE.
2.3 Two-Branch neural network
双分支网络已在多种任务中得到应用,捕获跨模态信息【Wang et al. 2019】或者不同级别【Wang et al. 2020】的信息。在语音增强领域,【Yin et al. 2020】利用双分支网络分别预测增强信号的幅度和相位。本文利用双分支网络对语音和噪声进行建模,并通过交互模块实现更好的区分。
Wang, H.; Zha, Z.-J.; Chen, X.; Xiong, Z.; and Luo, J. 2020. Dual Path Interaction Network for Video Moment Localization. In Proceedings ofthe 28th ACM International Conference on Multimedia, 4116–4124.
Wang, L.; Li, Y.; Huang, J.; and Lazebnik, S. 2019. Learning two-branch neural networks for image-text matching tasks. IEEE transactions on pattern analysis and machine intelligence 41(2): 394–407.
2.4 Self-Attention model
自注意力机制同样在多种任务中得到了广泛应用,包括机器翻译、图像生成、视频问答等。在视频领域,空间注意力机制用于学习空间和时间维度上的长期依赖性。语音相关的任务同样采用了自注意力机制,包括语音识别,语音增强【Kim, El-Khamy, and Lee 2020; Koizumi et al. 2020】。但是这些任务中仅仅在时间维度上学习长期以来,忽略了频率之间的全局依赖性。
Kim, J.; El-Khamy, M.; and Lee, J. 2020. T-GSA: Transformer with Gaussian-Weighted Self-Attention for Speech Enhancement. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 6649–6653. IEEE.
Koizumi, Y.; Yaiabe, K.; Delcroix, M.; Maxuxama, Y.; and Takeuchi, D. 2020. Speech enhancement using selfadaptation and multi-head self-attention. In ICASSP 20202020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 181–185. IEEE.
- Proposed Method
3.1 Overview
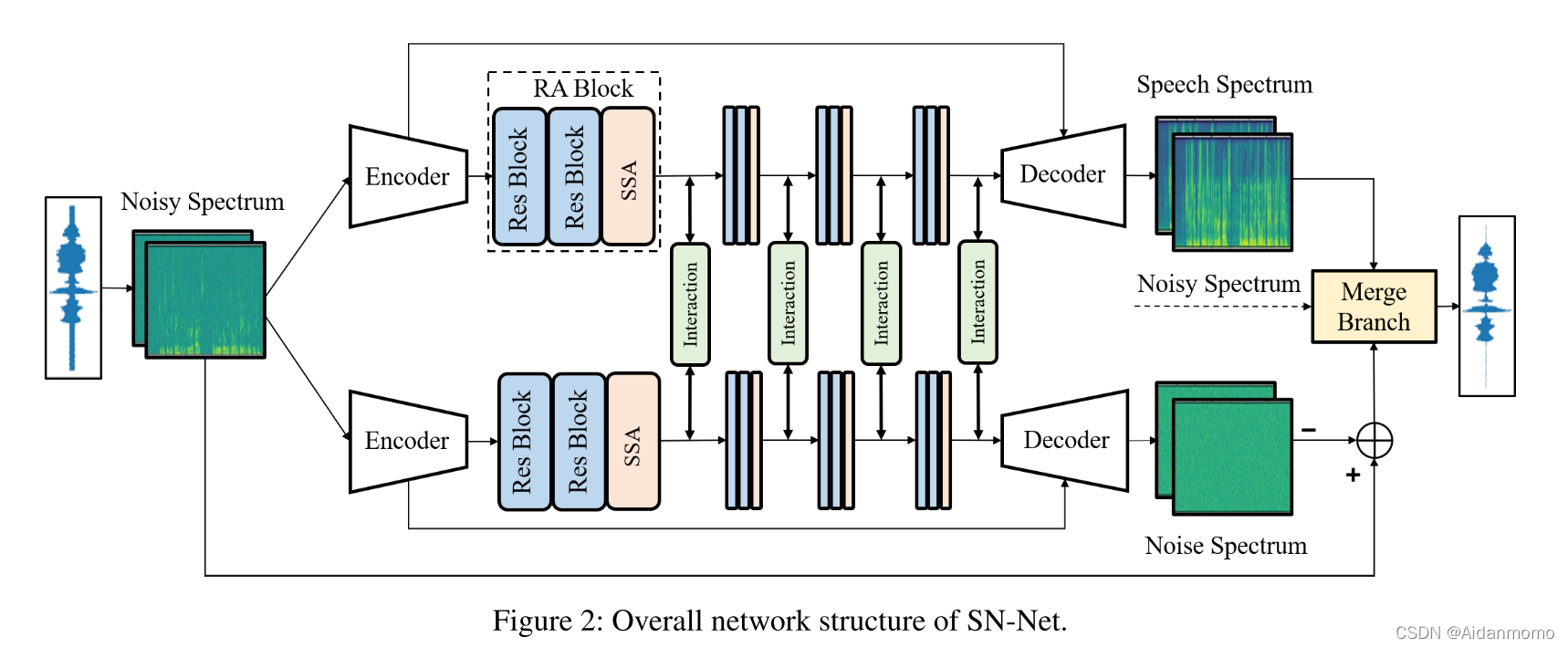
网络的输入为复数T-F频谱X I ∈ R T × F × 2 X^I \in R^{T \times F \times 2}X I ∈R T ×F ×2,其中T表示时间帧数,F表示频率点数。SN-Net的两个分支共享相同的网络结构,但是采用不同的网络参数。网络分支采用基于encoder-decoder的架构,中间嵌入RA模块。两个分支之间通过interaction模块传输和共享信息。最后通过Merge Branch合并输出信息,得到最终的增强语音。
; 3.2 Encoder and Decoder
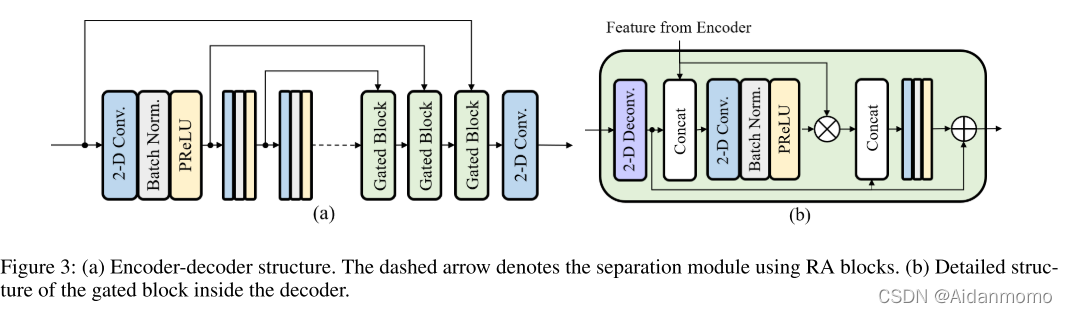
如图3(a)所示,encoder包含三个二维卷积层,卷积核大小为(3, 5),第一个卷积层的步长为(1,1),后面两层的步长为(1, 2)。通道数分别为16,32,64。因此可得到encoder的输出为F k E ∈ R T × F ′ × C F^E_{k} \in \mathbb{R}^{T \times F^{'} \times C}F k E ∈R T ×F ′×C,其中F ′ = F 4 F^{'}=\frac{F}{4}F ′=4 F ,C=64,k ∈ { S , N } k \in {S, N}k ∈{S ,N }。S和N分别表示语音和噪声分支。
Decoder部分包含三个Gated blocks和一个二维卷积层。重构得到的输出信号为F D ∈ R T × F × 2 F^D \in \mathbb{R}^{T \times F \times 2}F D ∈R T ×F ×2。如图3(b)所示,门控模块从编码器的响应特征中学习乘法掩码,用于抑制不需要的部分。mask 后的编码器特征与反卷积的特征融合到一起(concatenated),输入另一个二维卷积层中生成残差特征表示。经过三个门控模块后,最终的卷积层学习用于语音重构的幅度增益和相位信息。所有二维反卷积层的卷积核大小为(3, 5),前两个门控模块反卷积层的步长为(1, 2),最后一个为(1, 1)。通道数分别为32, 16, 2。所有二维卷积层的卷积核大小为(1, 1), 步长为(1, 1),通道数与对应的反卷积层通道数相同。
encoder和decoder的所有卷积层后都会进行batch normalization和parametric ReLU(PReLU)。时间维度不进行下采样,从而保持时间分辨率。
3.3 RA Block
RA模块用于提取特征,对语音和噪声分支进行分离。本文采用可分离的自注意力机制(SSA, separable self-attention)捕获沿时间和频率维度的全局依赖性。分别对两个维度使用注意力机制是值得尝试的方法,因为人们倾向于更多地关注音频信号的某些部分(例如语音部分),而较少关注周伟部分(例如噪声),并且语音和噪声在不同频率上的感知也是不同的。在本文提出的SN-Net网络中,语音和噪声分支中的SSA模块对信号的感知不同,本文将在ablation实验中进行测试评估。

在SN-Net中,encoder和decoder之间包含四个RA模块。每个块包含两个残差块和一个SSA模块,用于信号中的局部和全局依赖性,如图4所示。每个残差块包含两个二维卷积层,卷积核大小为(5, 7),步长(1,1),输出通道数与输入通道相同。两个残差块的输出特征并行输入到时间自注意力块和频率自注意力块中,可以表示为F i R e s ∈ R T × F ′ × C F^{Res}_i \in \mathbb{R}^{T \times F^{'} \times C}F i R e s ∈R T ×F ′×C,其中i ∈ { 1 , 2 , 3 , 4 } i \in {1,2,3,4}i ∈{1 ,2 ,3 ,4 },i t h i^{th}i t h表示第i个RA块。两个自注意力块的输出表示为F T e m p , F F r e q ∈ R T × F ′ × C F^{Temp}, F^{Freq} \in \mathbb{R}^{T \times F^{'} \times C}F T e m p ,F F r e q ∈R T ×F ′×C。三部分特征F R e s , F T e m p , F F r e q F^{Res}, F^{Temp}, F^{Freq}F R e s ,F T e m p ,F F r e q融合之后输入到二维卷积层中,得到RA模块的输出F R A ∈ R T × F ′ × C F^{RA} \in \mathbb{R}^{T \times F^{'} \times C}F R A ∈R T ×F ′×C。
本文使用缩放点积自注意力机制。考虑到计算复杂度问题,SSA内部的通道数减少了一半,时间自注意力机制可以表示为:
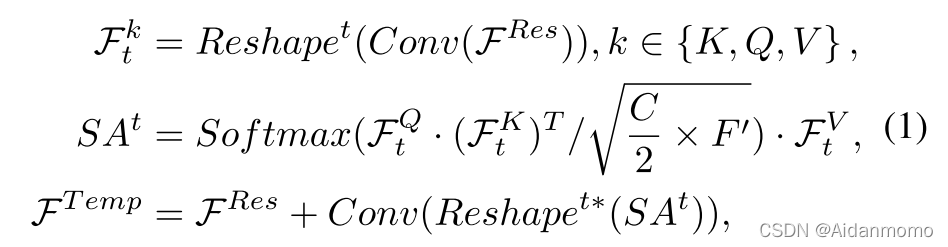
其中F t k ∈ R T × ( C 2 × F ′ ) F^k_t \in \mathbb{R}^{T \times (\frac{C}{2} \times F^{'})}F t k ∈R T ×(2 C ×F ′) ,S A t ∈ R T × ( C 2 × F ′ ) SA^t \in \mathbb{R}^{T \times (\frac{C}{2} \times F^{'})}S A t ∈R T ×(2 C ×F ′),F T e m p ∈ R T × F ′ × C F^{Temp} \in \mathbb{R}^{T \times F^{'} \times C}F T e m p ∈R T ×F ′×C。( ⋅ ) (\cdot)(⋅)表示矩阵乘法。R e s h a p e t ( ⋅ ) Reshape^t(\cdot)R e s h a p e t (⋅)表示对矢量进行reshape,从R T × ( F ′ × C 2 ) \mathbb{R}^{T \times (F^{'} \times \frac{C}{2})}R T ×(F ′×2 C )到R T × ( C 2 × F ′ ) \mathbb{R}^{T \times (\frac{C}{2} \times F^{'})}R T ×(2 C ×F ′),R e s h a p e t ∗ ( ⋅ ) Reshape^{t*}(\cdot)R e s h a p e t ∗(⋅)表示反向reshape。
频率自注意力机制可以表示为:
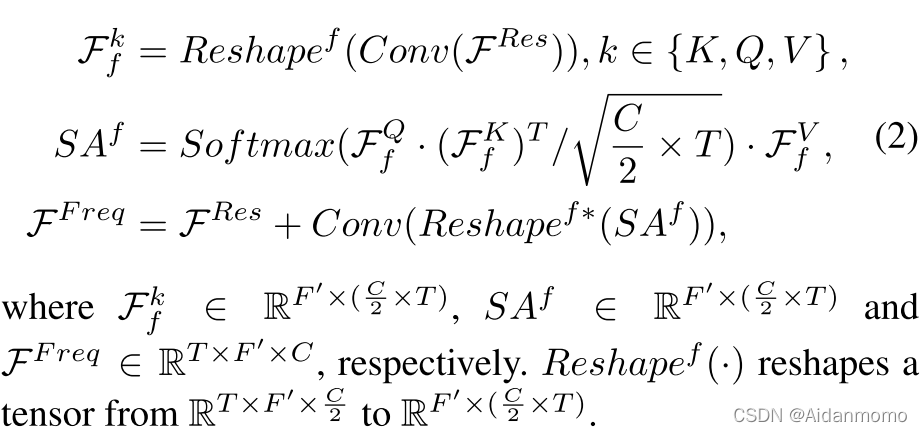
上面的公式中,Conv表示卷积层、BN和PReLU。所有的卷积层核大小为(1,1),步长为(1,1)。
; 3.4 Interaction Module
在SN-Net中,语音和噪声分支共享相同的输入信号,这就表明两个分支的内部特征存在关联性。因此,本文设计了交互模块用于实现分支之间的信息交换。通过该模块,从噪声分支传输到语音分支的信息用于对语音部分进行增强,并抵消语音分支内的噪声特征,反之亦然。
交互模块的网络结构如图5所示。
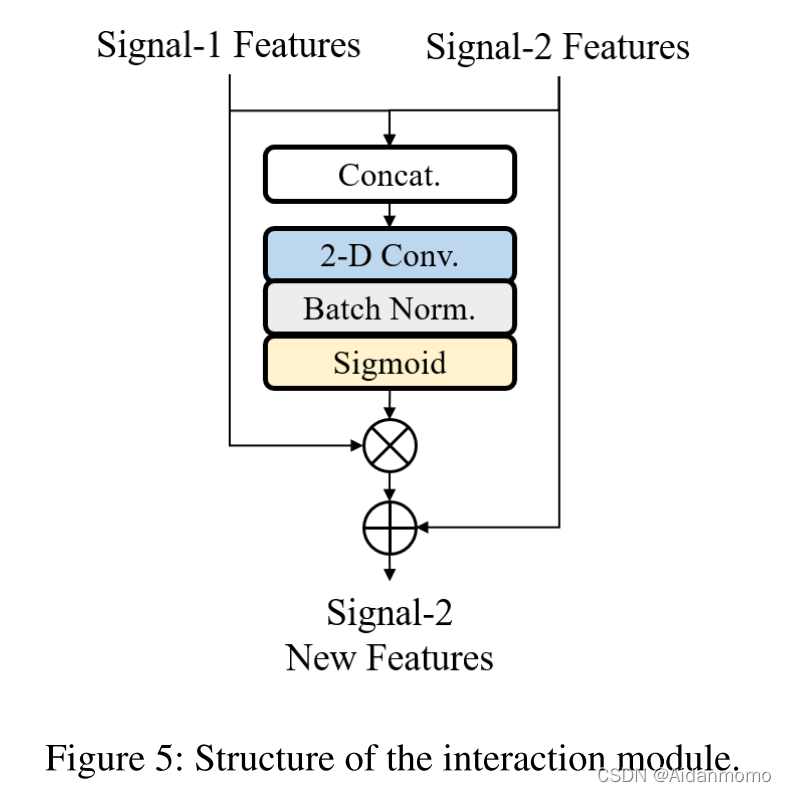
以语音分支为例,来自噪声分支的特征F N R A F^{RA}_N F N R A 首先与来自语音分支的特征F S R A F^{RA}_S F S R A 进行融合,之后输入到一个二维卷积层中,得到一个乘法掩码M N M^N M N,用于预测F N R A F^{RA}_N F N R A 的抑制和保留区域。通过将F N R A F^{RA}_N F N R A 与M N M^N M N相乘,得到残差表示H N 2 S H^{N2S}H N 2 S。最后模块将F S R A F^{RA}_S F S R A 与H N 2 S H^{N2S}H N 2 S相加得到语音特征经过"过滤"的版本,该特征将会输入到下一个RA模块。

其中M a s k ( ⋅ ) Mask(\cdot)M a s k (⋅)表示concatenation、卷积和sigmoid操作的缩写。( ∗ ) (*)(∗)表示逐像素相乘。
3.5 Merge Branch
通过Merge Branch模块对重建的语音分支和噪声分支的信号进行融合,融合过程在时域内完成。本文使用与STFT相同的窗口长度将两个解码器的输出并转换为时域上,用重叠帧的形式表示为s ~ ∈ R T × K , n ~ ∈ R T × K \tilde{s} \in \mathbb{R}^{T \times K}, \tilde{n} \in \mathbb{R}^{T \times K}s ~∈R T ×K ,n ~∈R T ×K,其中K表示帧大小。两个分支的输出与带噪语音x同时输入到merge branch模块。融合网络包含一个二维卷积层,一个时序自注意力模块(捕获全局时序依赖性),最后是两个卷积层学习逐元素掩码m ∈ R T × K m \in \mathbb{R}^{T \times K}m ∈R T ×K。三个卷积层的核大小为(3, 7),通道数为3,3,1。前两个卷积后会进行BN和PReLU操作,最后一个卷积层后使用Sigmoid激活层。最终获得增强后的语音:
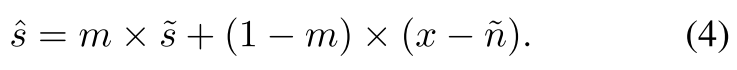
最后通过overlap and add从s ^ \hat{s}s ^重建一维信号。
; 4. Experiments
4.1 Datasets
- DNS2020 Challenge数据集:包含2150个说话人的500个小时的干净语音,Audioset和Freesound的包含150个类别的60000条噪声片段。本文合成了500个小时的带噪语音用于训练,信噪比为-5,0,5,10,15dB。合成了150个小时的带噪语音用做验证集,不含混响,信噪比为0到20dB之间的随机数。
- Voice Bank + DEMAND:28个说话人的语音用做训练集,另外两个unseen说话人的语音用做测试集。10个类别的噪声数据用做训练集,五种额外的噪声用做测试集。训练集信噪比:{0,5,15,20},测试集信噪比:{2.5,7.5,12.5,17.5dB}
- TIMIT Corpus:该数据集用于验证语音分离实验。
4.2 Evaluation Metrics
SSNR, SDR, PESQ, CSIG, CBAK, COVL。
4.3 Implementation Details
- 输入:所有喜好重采样为16kHz,小段长度2s,使用复数STFT变换(汉宁窗,窗长20ms,hop_length为10ms,频率点数320)。
- 损失函数:L = L s p e c h + α L N o i s e + β L M e r g e L = L_{spech}+\alpha L_{Noise}+\beta L_{Merge}L =L s p e c h +αL N o i s e +βL M e r g e ,分别表示三个分支的损失。所有项都使用幂律压缩(power-law compressed) STFT 频谱上的均方误差 (MSE) 损失【Ephrat et al.2018】。在计算损失之前,对语音和噪声分支进行逆STFT和前向STFT,以确保STFT的一致性【Wisdom et al. 2019】。
- 网络训练:adam 优化器,学习率0.0002,通过Xavier进行初始化。网络模型训练分为两个阶段,首先对两个分支进行训练,损失函数参数设置为α = 1 , β = 0 \alpha=1, \beta=0 α=1 ,β=0。然后使用前两个固定的参数训练融合分支,仅仅使用L M e r g e L_{Merge}L M e r g e 损失函数。batch_size大小为32,DNS数据集训练了60个周期,Voice Bank + DEMAND数据集训练了400个周期。
Ephrat, A.; Mosseri, I.; Lang, O.; Dekel, T.; Wilson, K.; Hassidim, A.; Freeman, W. T.; and Rubinstein, M. 2018. Looking to listen at the cocktail party: A speaker-independent audio-visual model for speech separation. arXiv preprint arXiv:1804.03619 .
Wisdom, S.; Hershey, J. R.; Wilson, K.; Thorpe, J.; Chinen, M.; Patton, B.; and Saurous, R. A. 2019. Differentiable consistency constraints for improved deep speech enhancement. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 900– 904. IEEE.
4.4 Ablation Study
4.4.1 Objective Quality

首先通过DNS数据集评估网络不通部分的有效性,结果如上图所示。将不含SSA模块的网络模型作为baseline。将SSA模块加入到单分支网络后,模型在SDR和PESQ得分方面都有提升。然后评估了是否使用信息交互模块(interaction)对网络的影响,增加interaction模块对网络模型的性能提升有很大的帮助。
; 4.4.2 Visualization of information flow

对比a和c能够看出,经过信息交互后,语音区域能够很好的从噪声中分离出来。对于噪声分支,从f中可以看出,语音部分已经从噪声中去除。
4.4.3 Visualization of separable self-attention
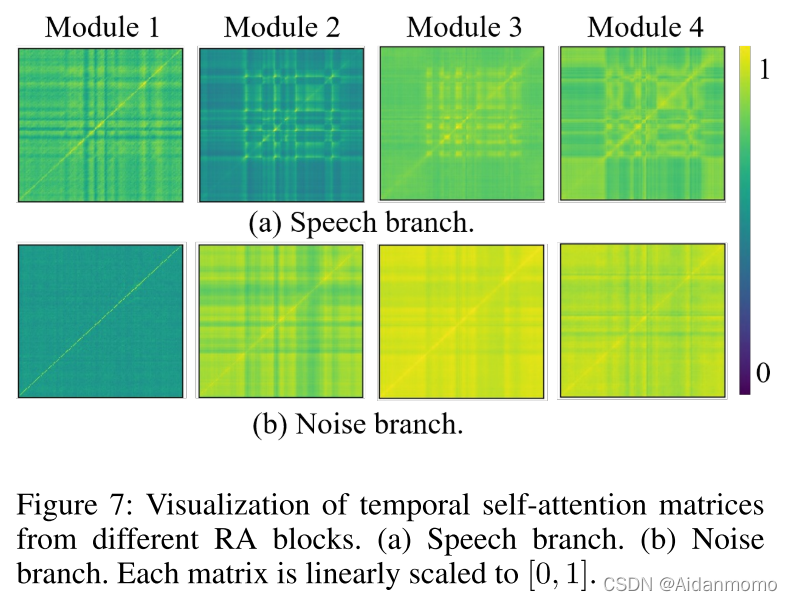
从图7中可以看到,除了对角线之外,每一帧都表现出对其他帧的强烈关注,并且每个RA模块的语音和噪声分支表现不同。对于噪声分支,随着网络的深入,注意力从局部转移到全局。噪声分支比语音分支表现出更广泛的注意力,因为白噪声在所有帧中传播,而语音信号仅在某个时间出现。
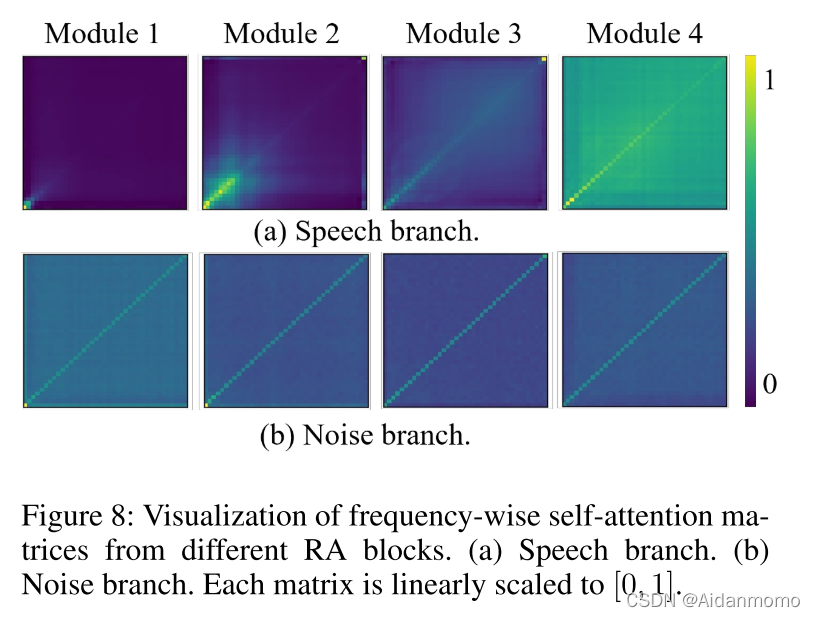
图8给出了频率维度自注意力机制的可视化矩阵图。对于语音分支,注意力从低频部分的局部逐渐扩展到全局频率,表明随着网络的深入,频率方向的自注意力倾向于沿着频率维度捕获全局依赖性。
; 4.5 Comparison with the state-of-the-art
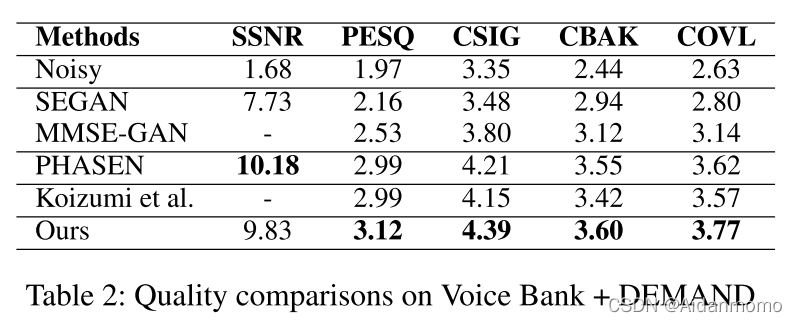
在Voice Bank + DEMAND数据集进行了模型对比验证,实验结果表2所示。
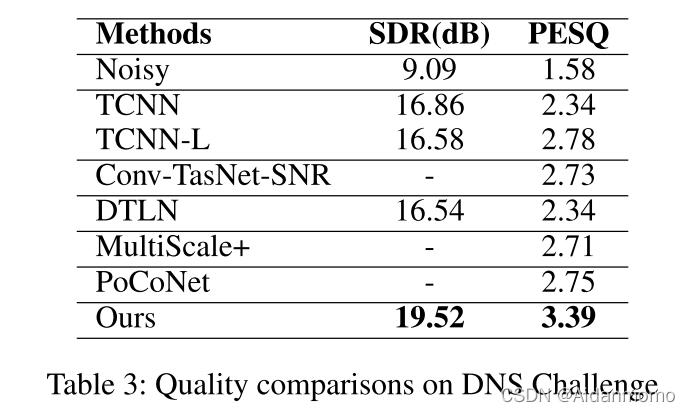
表3比较了不同的模型在DNS2020数据集上的表现。
Original: https://blog.csdn.net/aidanmo/article/details/122246744
Author: Aidanmomo
Title: Interactive Speech and Noise Modeling for Speech Enhancement