
根据自己最近的写的项目,总结整理了关于java语音播报功能的方法,可分为两种形式
- 一种是通过自己写出一个语音播报方法的工具类,然后从前端获取文本数据,最后跳到控制层进行语音播报方法的调用,但是这种方式需要外部导入jacob这个jar包以及dll文件的位置设置,主要是通过java工具类来实现;(但是这种导入Jacob包的方法只适合在window的开发环境使用,因为里面的dll文件只支持在Windows环境下的com组件运行,而Linux系统不适用)
- 另一种就是通过简单的JS来实现的语音播报,主要是用了SpeechSynthesisUtterance,它是HTML5中新增的API,用于将指定文字合成为对应的语音.也包含一些配置项,指定如何去阅读(语言,音量,音调)等
通过java工具类的实现方法:
解压jar包,将jacob.jar复制到工程目录,右键该文件→Build Path→Add to...
将jacob-1.17-M2-x86.dll添加到JDK的bin目录和Windows的system32目录(64位系统添加jacob-1.17-M2-x64.dll)
import com.jacob.activeX.ActiveXComponent;
import com.jacob.com.Dispatch;
import com.jacob.com.Variant;
import org.junit.jupiter.api.Test;
public class Voice2 {
public void strat(String content, int type) {
ActiveXComponent sap = new ActiveXComponent("Sapi.SpVoice");
Dispatch sapo = sap.getObject();
if (type == 0) {
try {
sap.setProperty("Volume", new Variant(100));
sap.setProperty("Rate", new Variant(1.3));
Variant defalutVoice = sap.getProperty("Voice");
Dispatch dispdefaultVoice = defalutVoice.toDispatch();
Variant allVoices = Dispatch.call(sapo, "GetVoices");
Dispatch dispVoices = allVoices.toDispatch();
Dispatch setvoice = Dispatch.call(dispVoices, "Item",
new Variant(1)).toDispatch();
ActiveXComponent voiceActivex = new ActiveXComponent( dispdefaultVoice);
ActiveXComponent setvoiceActivex = new ActiveXComponent(setvoice);
Variant item = Dispatch.call(setvoiceActivex, "GetDescription");
Dispatch.call(sapo, "Speak", new Variant(content));
} catch (Exception e) {
e.printStackTrace();
} finally {
sapo.safeRelease();
sap.safeRelease();
}
} else {
try {
Dispatch.call(sapo, "Speak", new Variant(content), new Variant(2));
} catch (Exception e) {
System.out.println(e.getMessage());
e.printStackTrace();
}
}
}
@Test
public void test()
{
strat("110千伏金华站", 0);
}
}
2.从前端拿数据的JS
function voice (text){
$.ajax({
async:true,
url:"th-robot/voice/Announcement",
data:{text:encodeURI(text)},
type:"get",
dataType:"json",
contentType:"text/json,charset=utf-8",
success:function(data){
mini.showTips({
content:"加载成功",
state:"success",
timeout:3000
});
},
error:function(msg){
mini.showTips({
content:"加载失败",
state:"fail",
timeout:3000,
});
}
});
};
3.后台控制层代码:
import com.jacob.activeX.ActiveXComponent;
import com.jacob.com.Dispatch;
import com.jacob.com.Variant;
@Controller
@RequestMapping(value="/voice")
public class VoiceAnnouncementController{
@RequestMapping(value="Announcement",produces={"application/json;charset-UTF-8"})
@ResponseBody
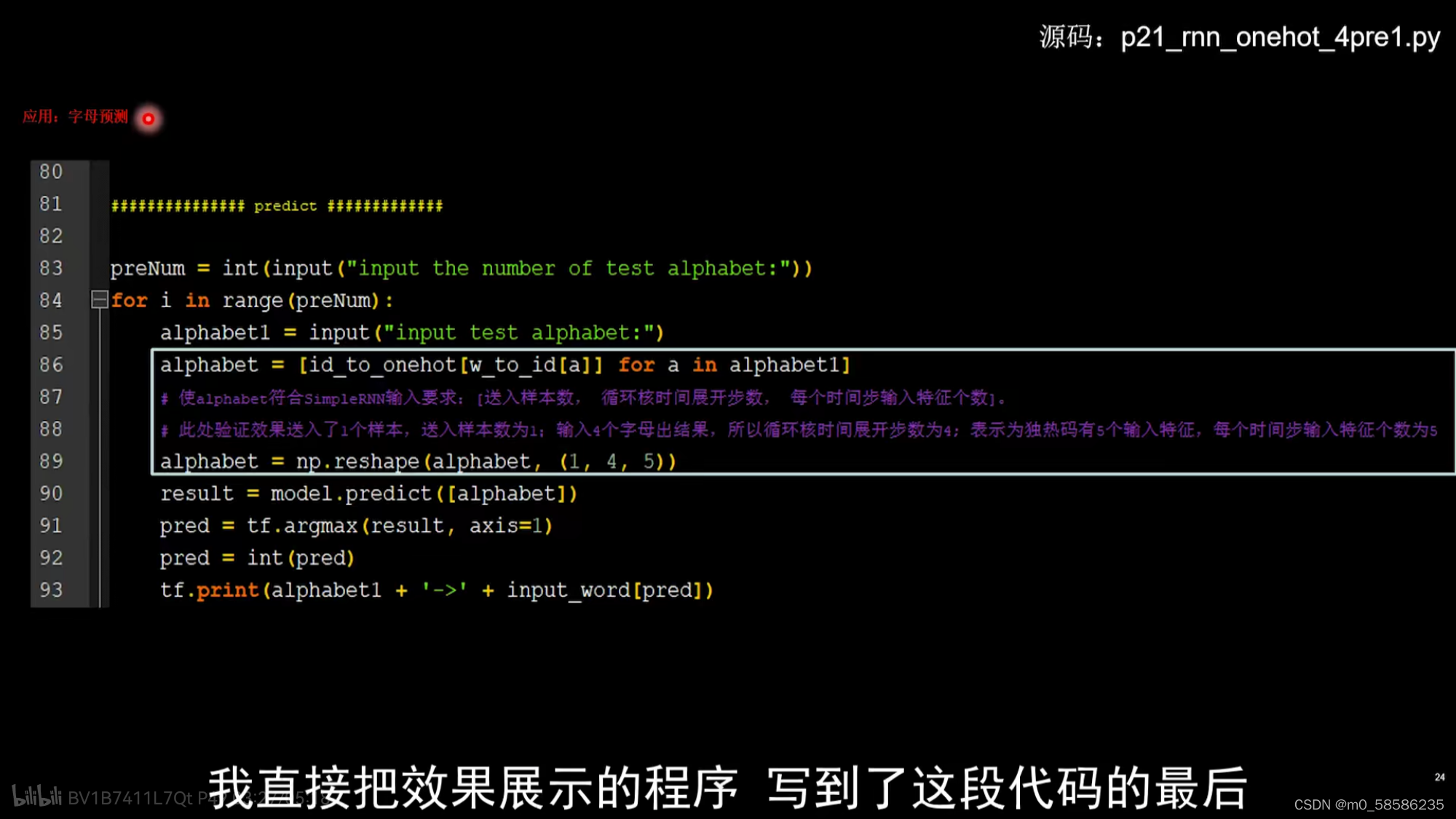
public void voice(HttpServletRequest request) throws ParseException{
String text = StringUyil.getNotNullStr(request.getParameter("text"));
try{
text = URLDecoder.decode(text,"utf-8");
}catch(UnsupportedEncodingException e){
e,printStackTrace();
}
System.out.println("语音播放内容为:"+text);
VoiceAnnouncement.strat(text,-1);
}
}
3.最后只需要在你想播报的那个JSP中使用vioce("你想播报的信息")即可,当然也可以根据实际情况做成动态数据。
利用JS方法代码
利用js的话就不需要导入jar包,也不需要工具类和控制层代码了,直接写一个js,直接放在想播报的页面,引用voice方法即可,原理和上面的一样。代码如下:如果是单独写的JS文件就不需要在用script标签了。
<script type="text/javascript">
var msg = new SpeechSynthesisUtterance("输入要朗读的文字");
window.speechSynthesis.speak(msg);
</script>
两种方法我都用过了,因为后面要把项目上传到服务器更新,而我的开发是在本地windows,所以开始踩了jar包的坑,当然如果jar包导入方式不对或者文件位置没有放对,那么也会报错的,后来我用了js的放啊,亲测两种方法都有效。如果使用jar包有问题可以网上搜一下错误原因,无非就是那么几种。
Original: https://blog.csdn.net/weixin_38359768/article/details/108689833
Author: 春眠不觉晓♞
Title: 功能案例----java实现语音播报功能
相关阅读1
Title: 深度学习理论向应用的过渡课程【北京大学_TensorFlow2.0笔记】学习笔记(十一)——RNN介绍及字母预测
循环核: 参数时间共享,循环层提取时间信息
具有记忆力,通过不同时刻的参数共享,实现了对时间序列的信息提取

yt :当前时刻循环核的输出特征——求解过程为一个全连接层
ht :记忆体当前时刻存储的状态信息
ht-1:记忆体上一时刻存储的状态信息
bh、by:偏置项
训练优化的就是这些参数矩阵,训练完成后,使用效果最好的参数矩阵执行前向传播,输出预测结果。
循环神经网络:借助循环核提取时间特征后,送入全连接网络
借助全连接网络,实现连续数据预测。

循环计算层:向输出方向生长
每个循环核构成一层循环计算层
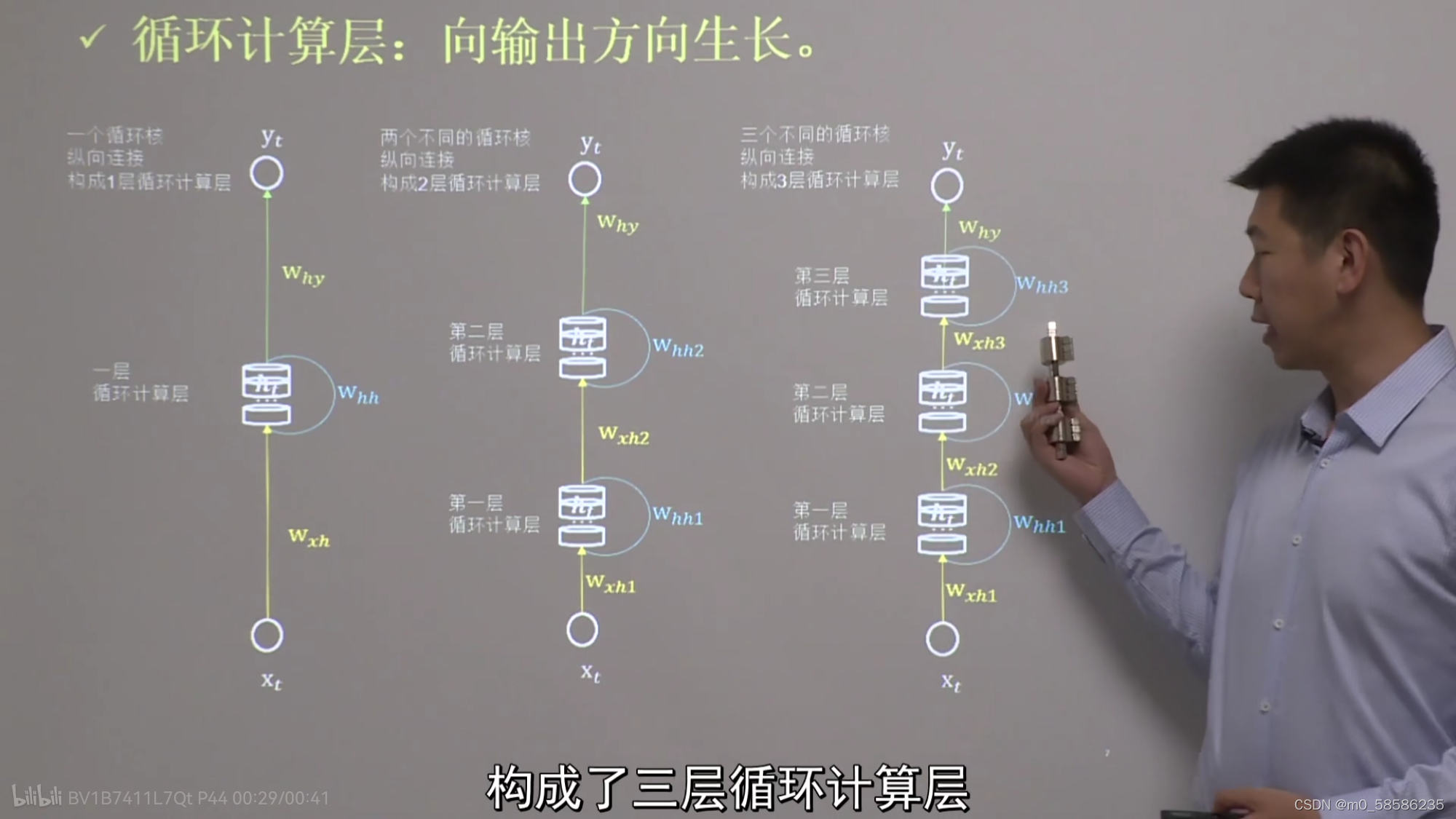
TF描述循环计算层
tf.keras.layers.SimpleRNN(记忆体个数, activation='激活函数',
return_sequences = 是否每个时刻输出ht到下一层)
activation = '激活函数' #不写默认tanh
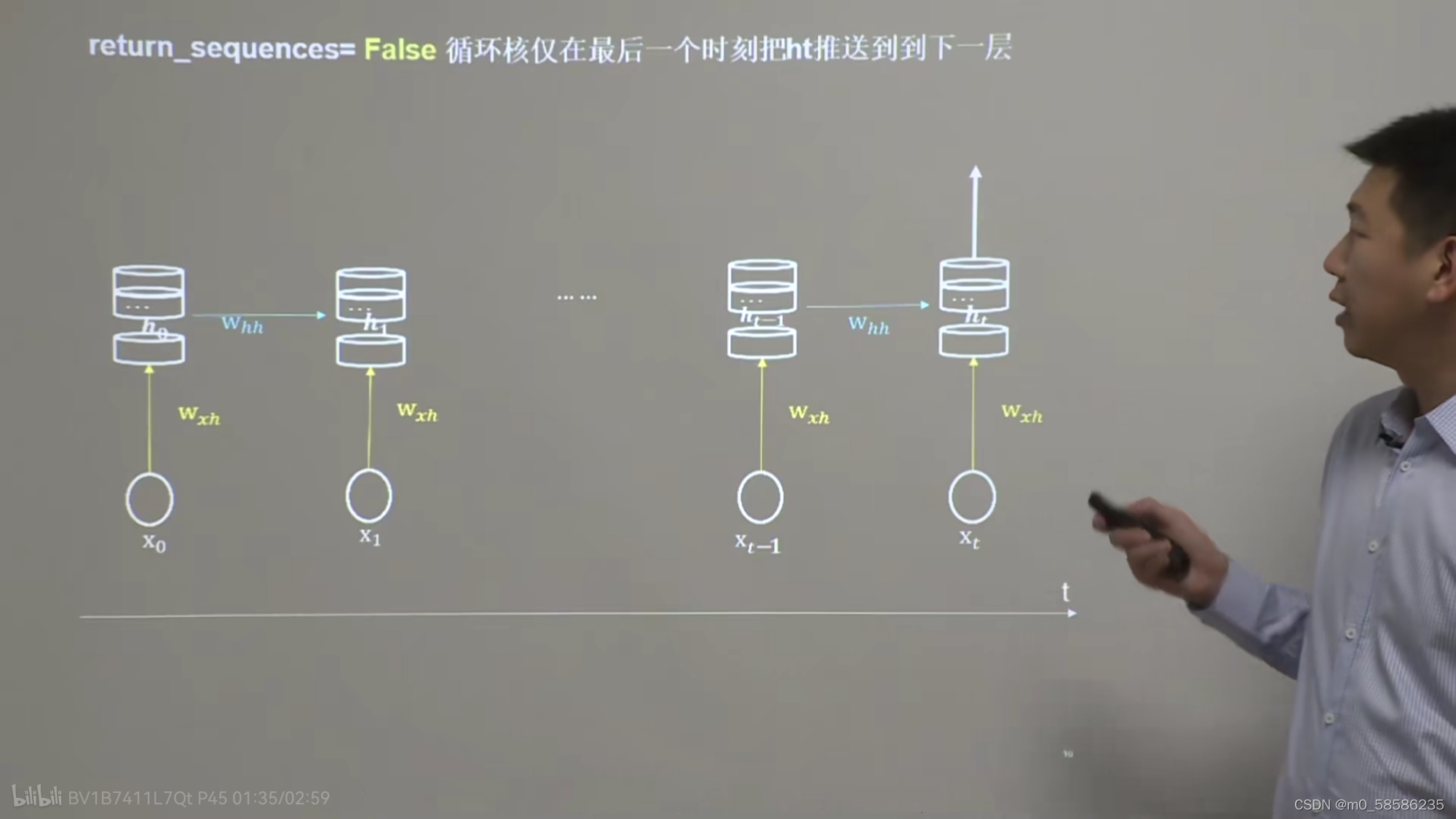
return_sequences = True #各时间步输出ht,常在中间层循环核使用
return_sequences = False #仅最后时间步输出ht(默认),常在最后一层循环核使用
例如:SimpleRNN(3, return_sequence=True)
循环核在每个时间步输出ht可用下图表示

循环核仅在最后一步输出ht
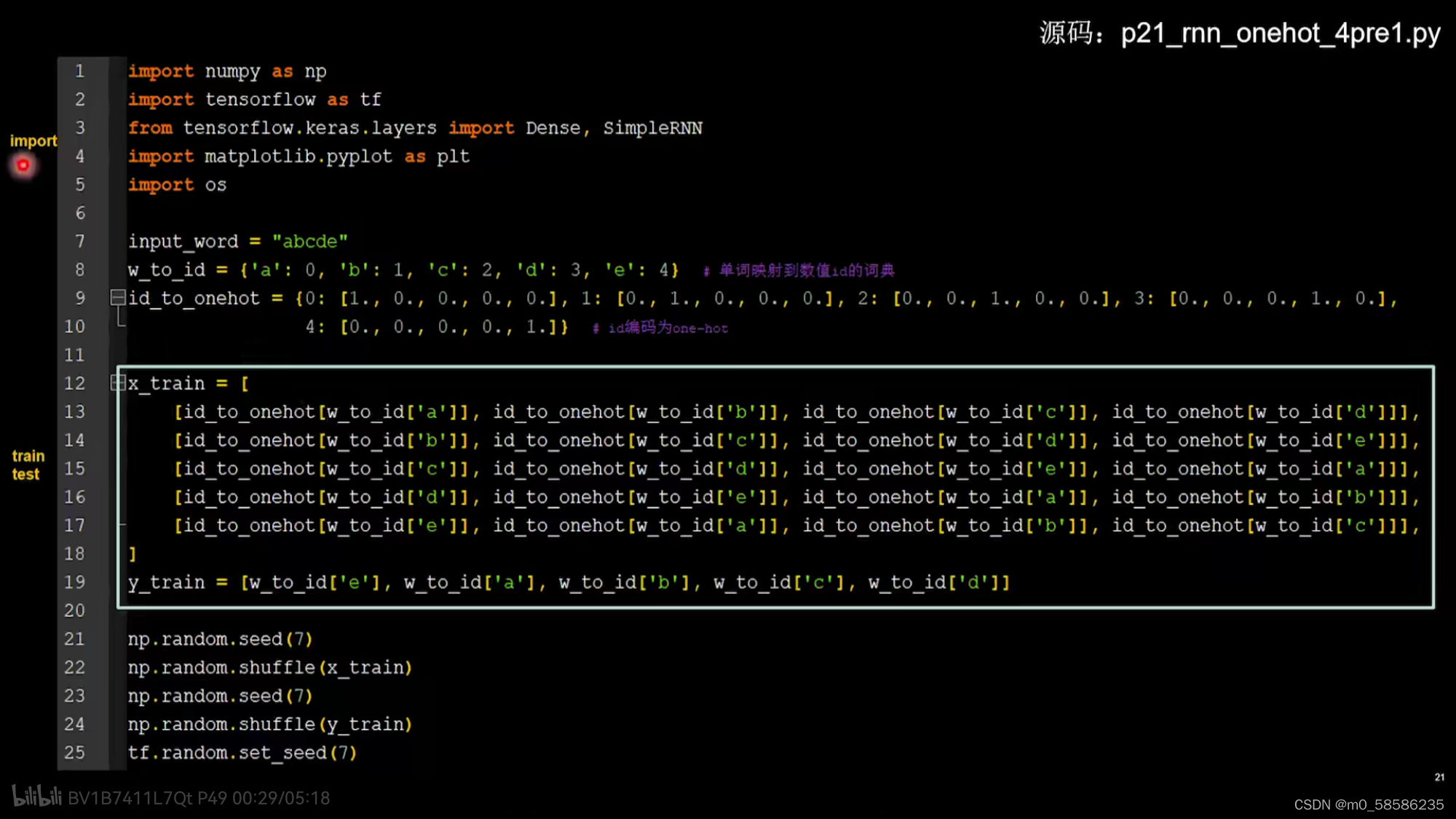
API对送入循环层的数据维度有要求, 送入循环层的数据是三维的,即x_train维度:
[送入样本数,循环核时间展开步数,每个时间步输入特征个数]
(1时间步=1循环核个数)
例如下图

循环计算过程举例
1、使用一个字母预测下个字母
初始时ht中为全零

在输入字母b的向量经过计算后更新ht。可理解为脑中记忆因当前输入事物而更新了。


输出yt,就是把提取到的时间信息,通过全连接进行识别预测的过程,是整个网络的输出层。
用RNN实现输入一个字母,预测下一个字母(one-hot编码)
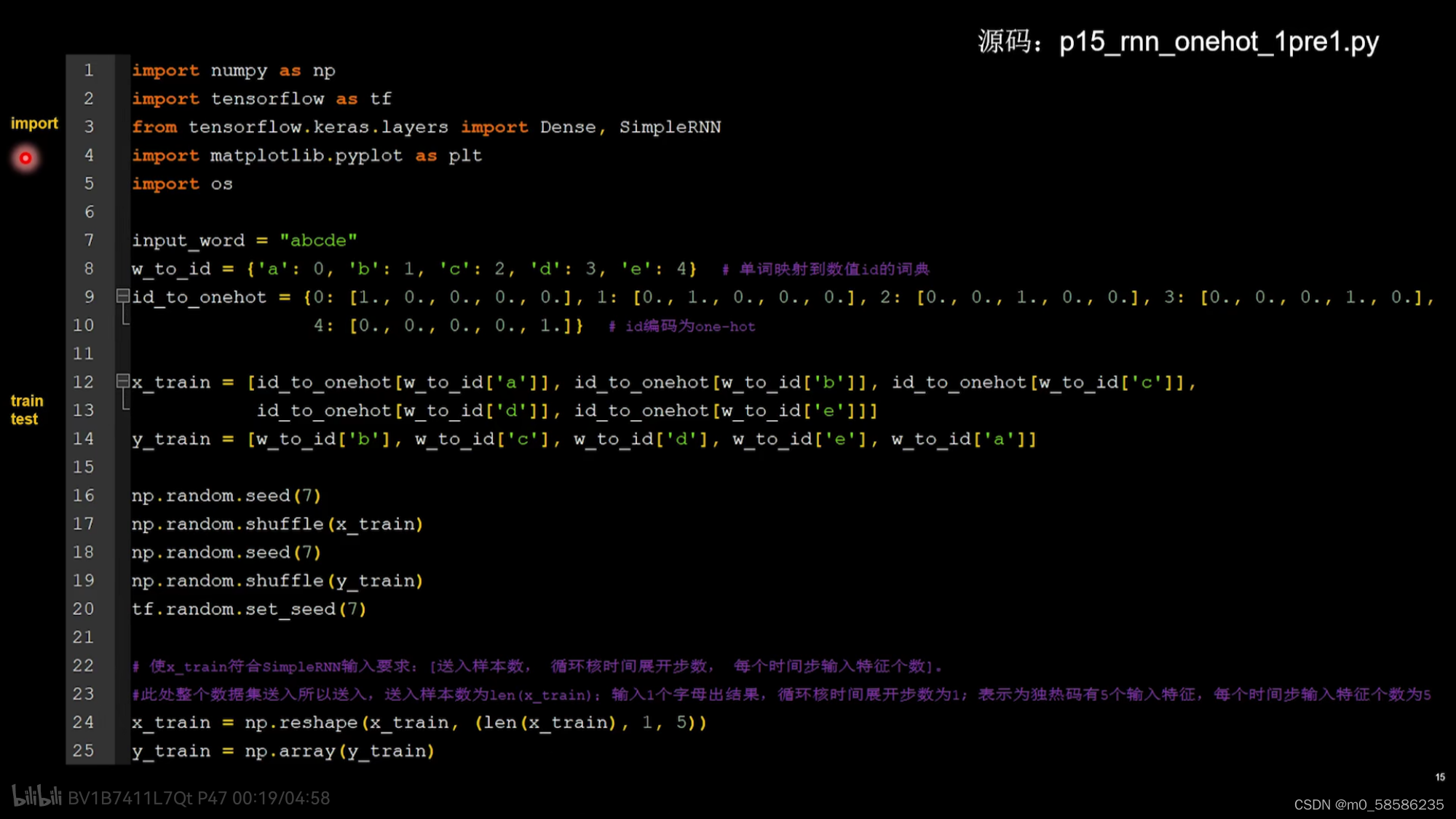

搭建具有三个记忆体的循环层,3为超参数。记忆体个数越多,记忆力越好,但占用的资源更多。

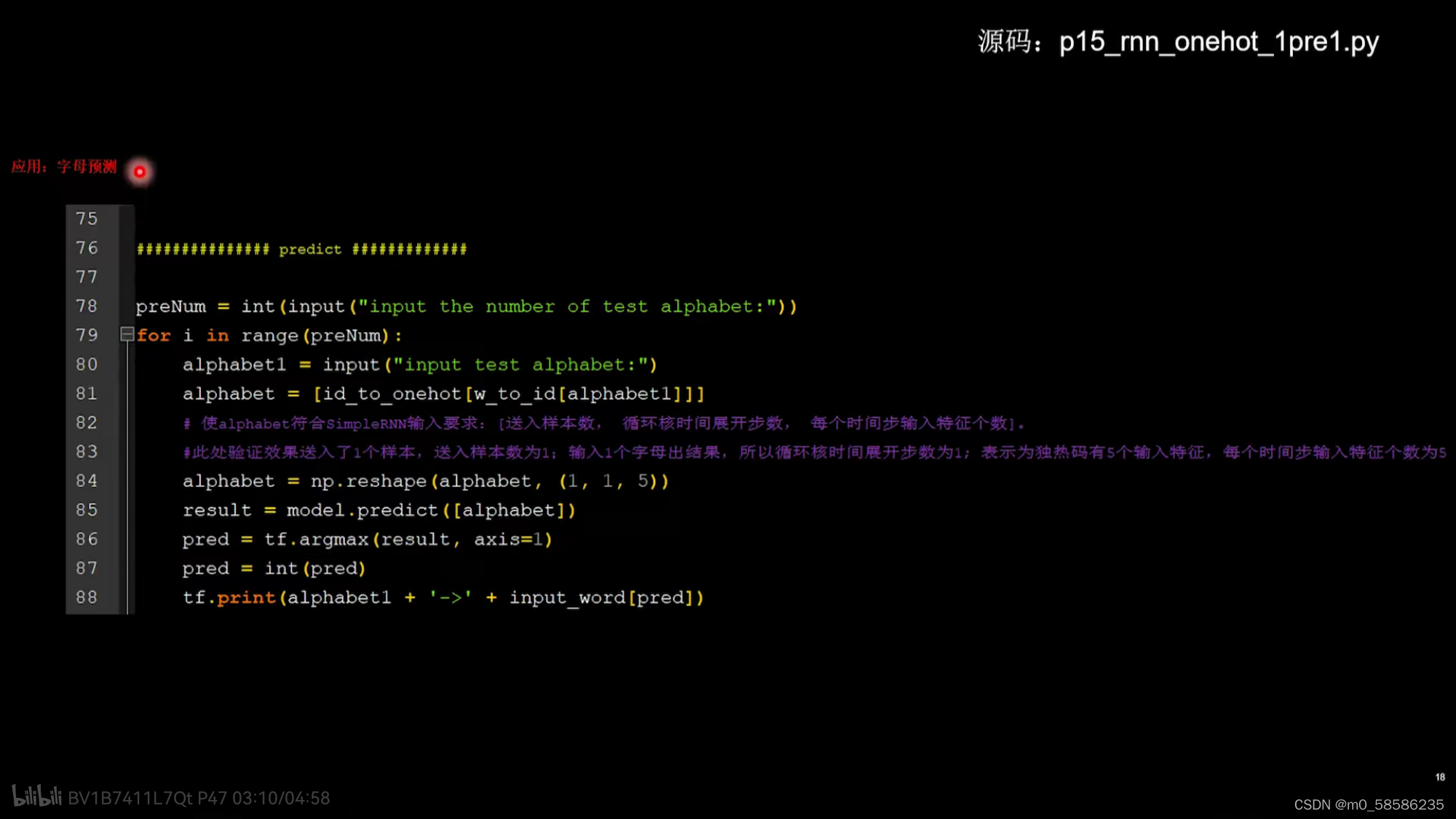
2、使用四个字母预测下个字母

在四个时间步中用到的参数矩阵wxh、偏置项bh数值相同
用RNN实现输入连续四个字母,预测下一个字母(one-hot编码)
即abcd->e bcde->a cdea->b deab->c eabc->d


Original: https://blog.csdn.net/m0_58586235/article/details/123589260
Author: m0_58586235
Title: 深度学习理论向应用的过渡课程【北京大学_TensorFlow2.0笔记】学习笔记(十一)——RNN介绍及字母预测
相关阅读2
Title: 基于Anaconda、wIN10的TensorFlow-GPU环境安装
一、配置
Win10+显卡NVIDIA GeForce GT730
Pycharm:2021版本(假设已经安装)
Anaconda:2020版本(假设已经安装)
二、环境要求
Tensorflow1.12-GPU
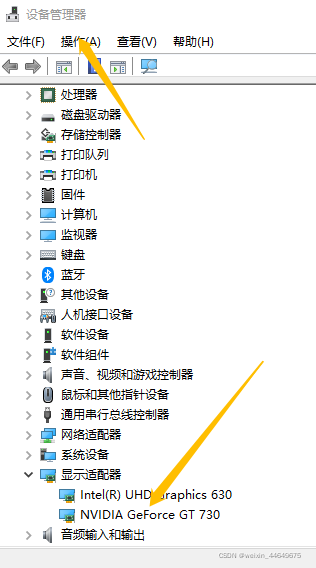
1.检查你的电脑是否支持CUDA
步骤如下:打开电脑设备管理器–显示适配器(如下图)
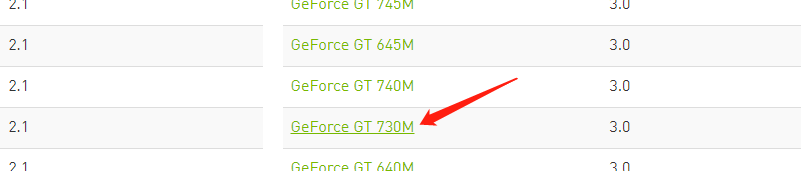
在网址查看自己的显卡是否支持CUDA下载(网址:https://developer.nvidia.com/cuda-gpus)比如我的算力是3.0就可以

; 2.根据你需要的Tensorflow环境下载对应的CUDA以及cuDNN
2.1查看Tensorflow对应的CUDA及cuDNN(https://blog.csdn.net/weixin_44222014/article/details/105552244)
例:比如我要下载的是Tensorflow1.12,所以我对应的版本应该是CUDA9.0以及cuDNN7
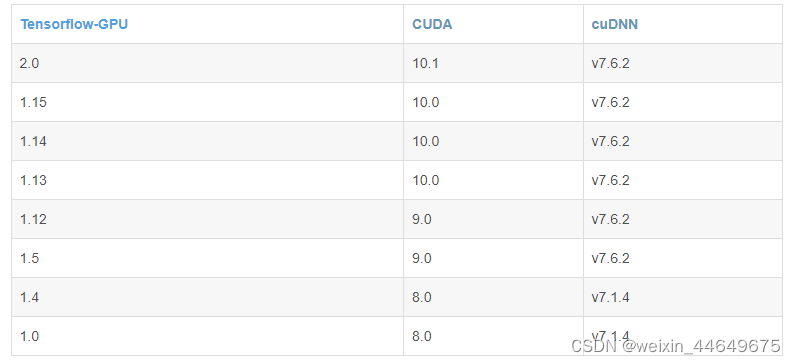
2.2打开CUDA官网进行下载安装(https://developer.nvidia.com/cuda-toolkit-archive)

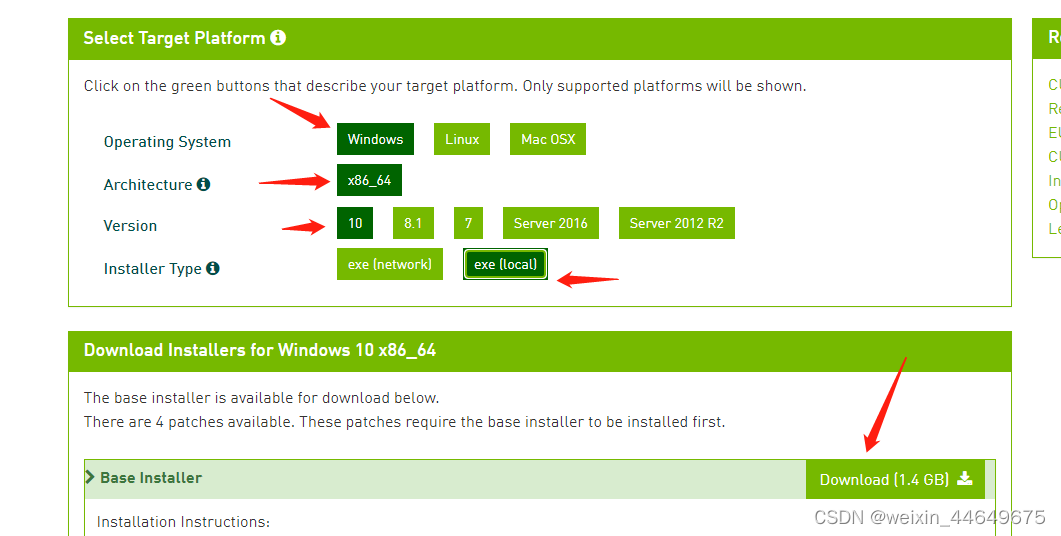
根据你电脑的配置进行选择,最后一项选择Local,下载第一个就可以。下载之后直接进行安装,一直点确定即可。(有的浏览器会不信任这个安装包,不用担心,找到文件下载地址,将后缀改为.exe进行安装即可)
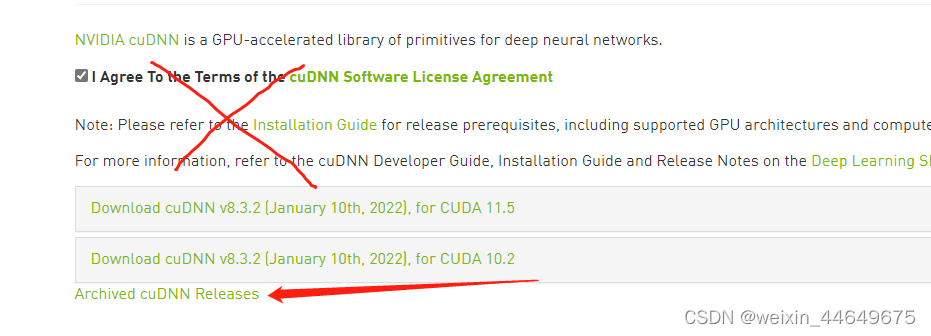
2.3下载cuDNN()
这一步比较麻烦,需要你先进入官网注册一个账号,然后填写一个下载调查文件。重新进去官网进行下载。有点耐心就可以啦~但是注意直接进去会是这个界面你不小心就把版本下错了,记得点开这个按钮,找到你想要的版本。我的环境对应版本是7,但是官网里没有7.0因此大家可以忽略小数点后的位数,只需要for CUDA你的CUDA版本号就可以。比如我就是for CUDA9.0

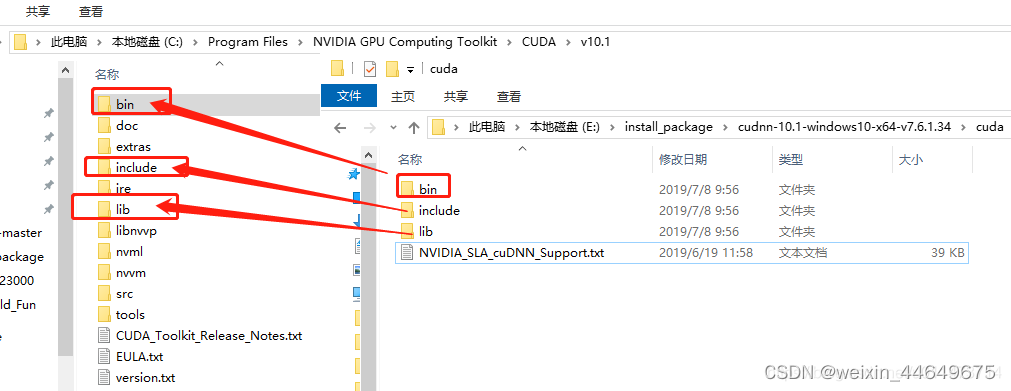
下载完成后进行解压,将文件中的bin、lib、include文件放入CUDA的安装目录中。(CUDA默认的安装路径C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0)注意:你可以直接输入到搜索框去查找。
2.4配置环境变量
完成以上操作后我们打开环境变量我们会发现多了两个系统变量路径。打开方式:计算机上点右键,打开属性->高级系统设置->环境变量
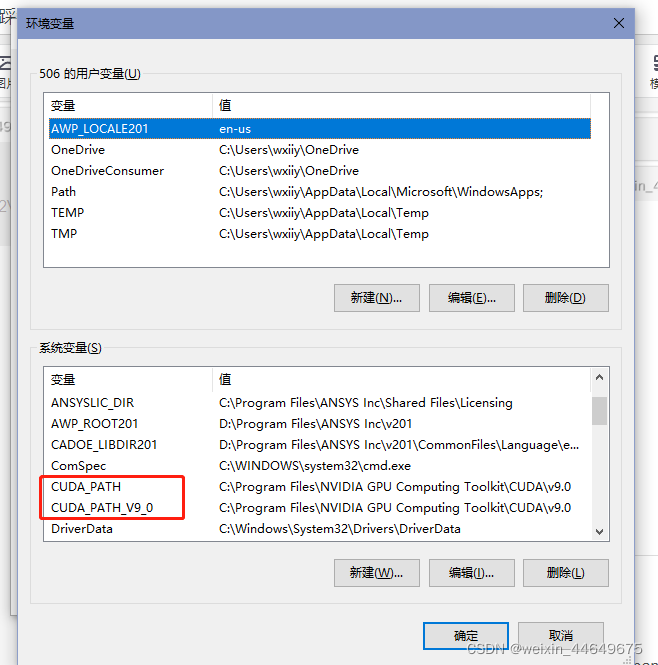
接下来,还要在系统中添加以下几个环境变量:
CUDA_SDK_PATH = C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0(你也可以自定义)
CUDA_LIB_PATH = %CUDA_PATH%\lib\x64
CUDA_BIN_PATH = %CUDA_PATH%\bin
CUDA_SDK_BIN_PATH = %CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH = %CUDA_SDK_PATH%\common\lib\x64
然后打开PATH路径,新建
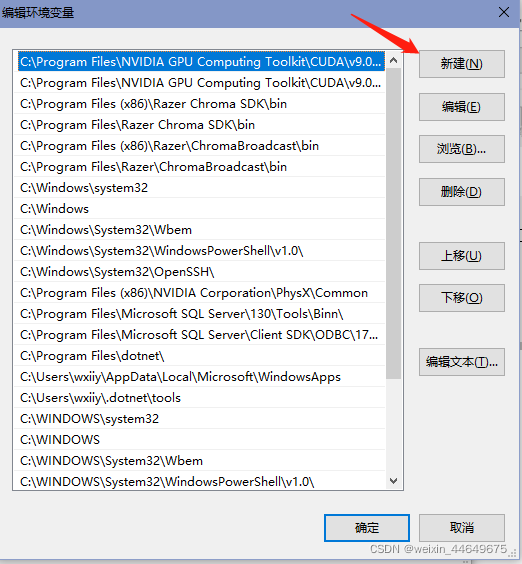
再添加如下4条(默认安装路径):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\lib\x64;
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\bin;
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0\common\lib\x64;
C:\ProgramData\NVIDIA Corporation\CUDA Samples\v9.0\bin\win64;
如果你选用了自定义路径,上述这些默认路径都应该相应替换为你的自定义路径
2.5测试是否安装成功
首先win+R启动cmd,cd到安装目录下的 ...\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe,应该得到下图:(注意一定要切到安装目录下哦,找不到可以直接在搜索框搜索)

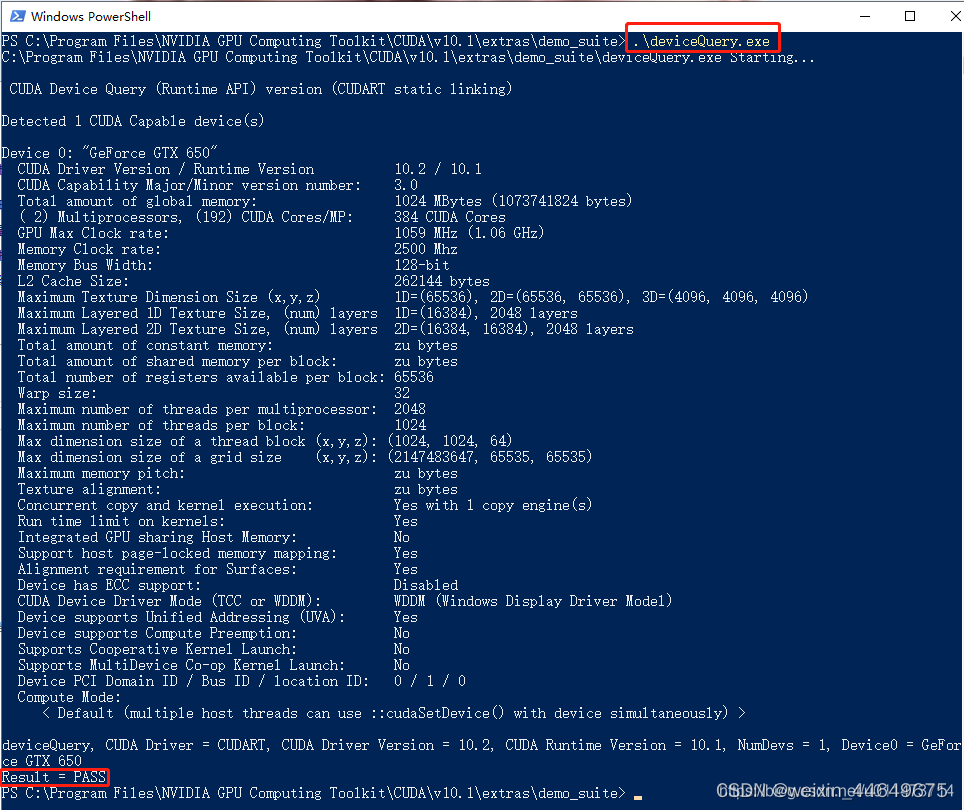
如果出现以上结果,那恭喜你,CUDA和cuDNN你已经安装成功了。
3、创建环境安装Tensorflow
3.1创建环境
打开Anaconda prompt
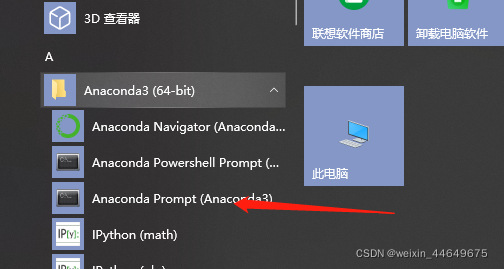
(base) C:\Users\wxiiy>conda create -n name python=3.6
(base) C:\Users\wxiiy>activate name
(name) C:\Users\wxiiy>
创建一个名字叫name的python3.6版本的环境,当然名字你可以随便起,创建成功后激活该环境.(本人踩的坑:因为电脑里已经有3.6版本,所以我先下载了3.5版本,但是Tensorflow一直有一个包装不上,后来查了一下原因是3.5版本现在已经不维护了,所以会导致有些包无法下载,建议大家直接下3.6+)
3.2装Tensorflow
我用的是清华的镜像语句如下
(name) C:\Users\wxiiy>pip install tensorflow==1.12.0 -i https://pypi.douban.com/simple
tensorflow后面是你需要的版本号,-i后面是镜像网址。
安装成功。
3.4测试是否安装成功
import tensorflow as tf
>>> x=tf.constant(1)
>>> y=tf.constant(2)
>>> z=x+y
>>> sess=tf.Session()
print(sess.run(z))
3
如果可以成功输出就没有问题了,可以安全放心的跑代码了
总结
以上就是我安装tensorflow-gpu的整个过程,借鉴了许多前辈的经验,也很感谢大家的辛苦奉献,希望我的总结能给大家一些帮助。
参考:https://blog.csdn.net/weixin_44222014/article/details/105552244
https://blog.csdn.net/u011473714/article/details/95042856
Original: https://blog.csdn.net/weixin_44649675/article/details/123523303
Author: weixin_44649675
Title: 基于Anaconda、wIN10的TensorFlow-GPU环境安装
相关阅读3
Title: TensorFlow 2.8.0安装 + Miniconda + GPU支持
Title: TensorFlow 2.8.0安装 + Miniconda + GPU支持
目录
- 一、为啥要写本文捏?
- 二、基础环境安装
* - 1.安装Miniconda
- 2.visual C++的安装
- 3.查看我们安装的miniconda是否有用
- 三、TensorFlow安装
- 四、TensorFlow GPU支持
一、为啥要写本文捏?
之前照着b站上的某个tensorflow教程装了个tensorflow2.0 + Anaconda + CUDA10.0,发现好多东西跑不起来。
因此就将一整套tensorflow包括其对应需要的conda(python环境)、CUDA(NVIDIA显卡对tensorflow支持的工具包)升级一下,其实是重装一遍。
一方面,我将能够回顾安装过程,另一方面,为网友提供参考。
[En]
On the one hand, I will be able to review the installation process, on the other hand, to provide reference for netizens.
系统版本:windows10 64位
显卡: NVIDIA GTX1050
python:3.8.2
tensorflow:2.8.0
二、基础环境安装
1.安装Miniconda
首先下载好Miniconda
Miniconda下载页
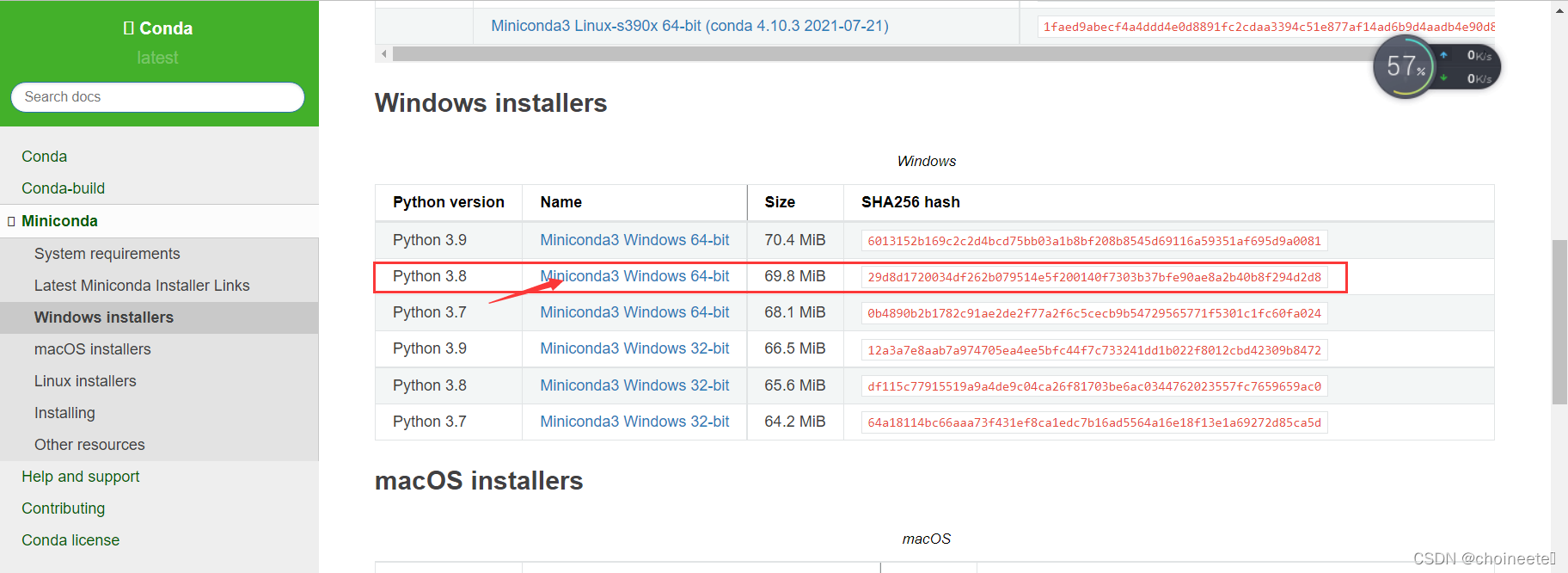
我选的是与windows python3.8 对应的miniconda
下载后,解压安装即可
; 2.visual C++的安装
也不知道是啥有用没用,照着视频来的,装了再说呗
visual C++官网下载页
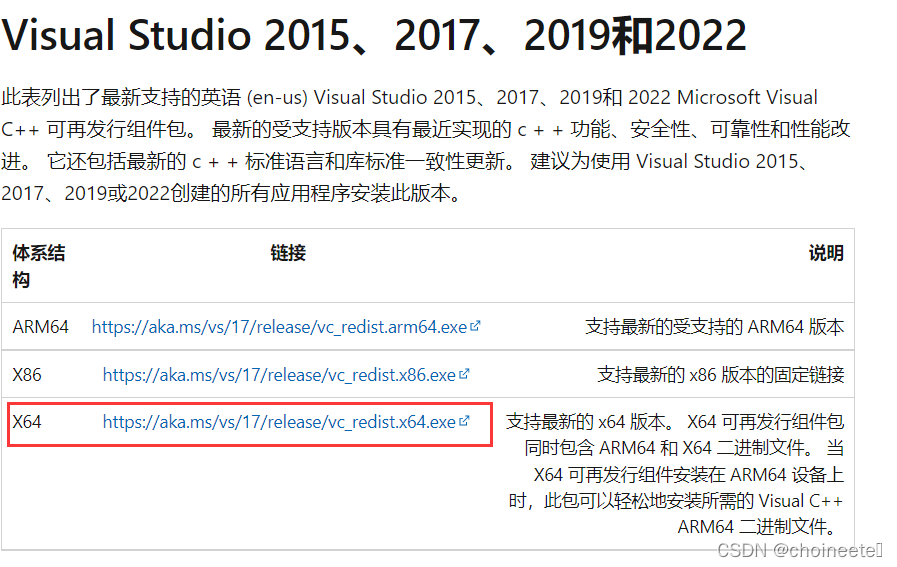
下载之后安装,重启
; 3.查看我们安装的miniconda是否有用
打开Anaconda Prompt
输入python,可查看python版本
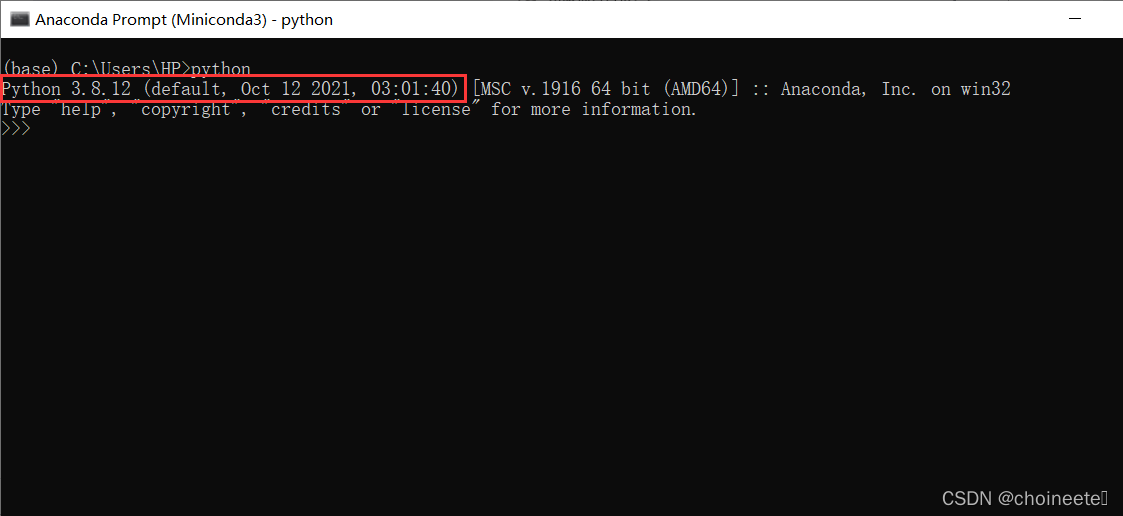
三、TensorFlow安装
打开Anaconda Prompt,安装tensorflow包
输入:
pip install tensorflow -i https://pypi.doubanio.com/simple/
默认安装最新版本,当前为2.8.0
也可指定版本
如:
pip install tensorflow==2.8.0 -i https://pypi.doubanio.com/simple/
大小大概400多MB,下载完成之后。
此时咋们可以在Anaconda Prompt中输入: where ipython
查看ipython是否存在,ipython为python的交互式窗口工具,比较美观。
如果控制台打印了ipython的路径,直接在控制台输入ipython,弹出交互式窗口。
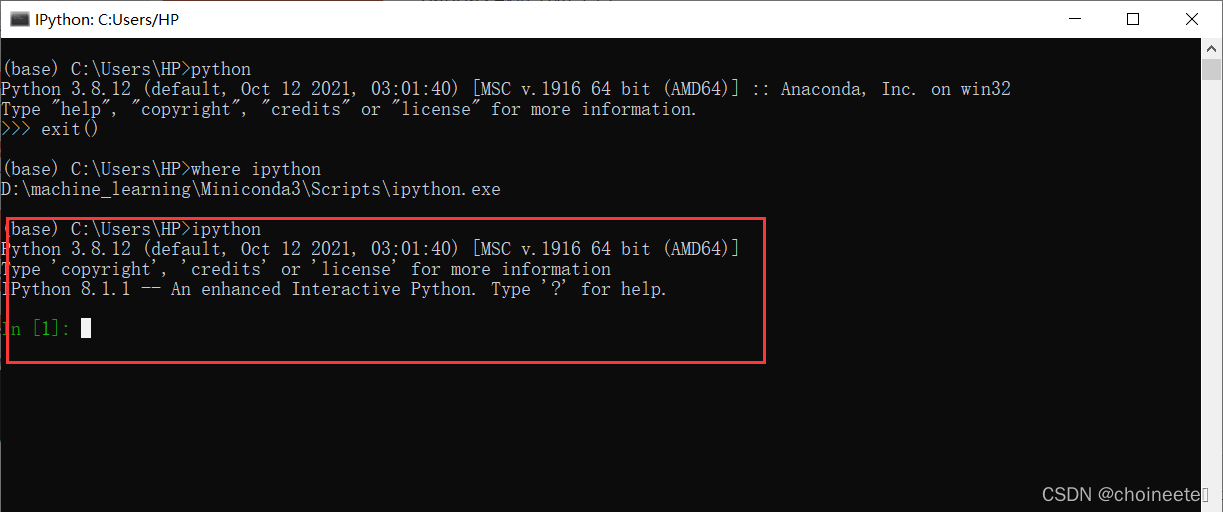
在ipython中输入以下代码
import tensorflow as tf
print(tf.__version__)
可以打印当前,tensorflow的版本号,检验tensorflow是否安装成功。
到此为止,tensorflow的CPU版本安装成功,如果你想让tensorflow支持GPU的话也可以参考下面的内容
四、TensorFlow GPU支持
首先,你要有一个NVIDIA显卡,且其算力不应该低于3.5-NVIDIA算力查看
具体GPU算力查看网站
个人电脑显卡,一般在这个目录下
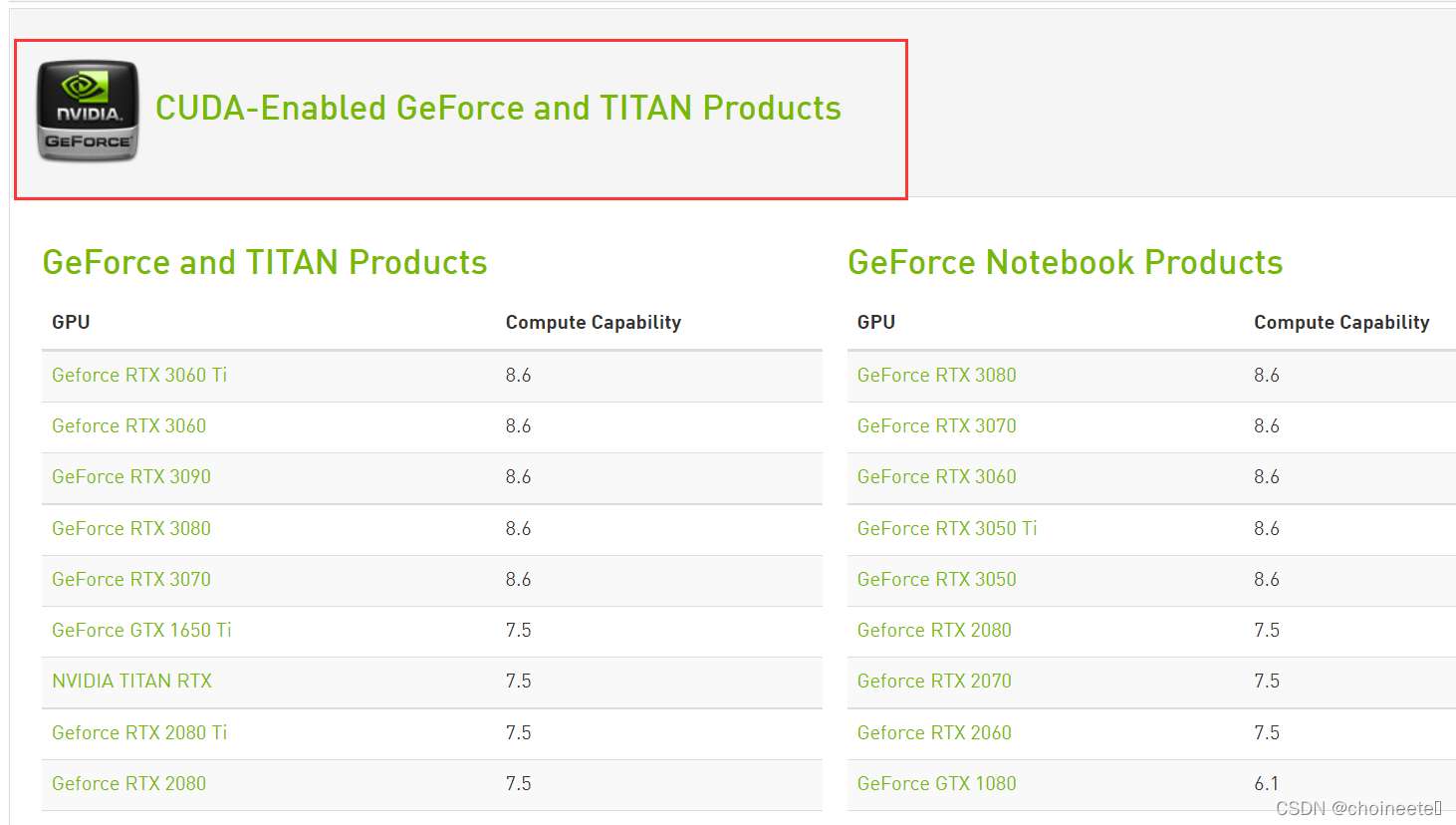
NVIDIA驱动版本要求:
450.80.02或更高版本
NVIDIA驱动程序对应的CUDA驱动版本必须:
CUDA Version 11.2或更高版本
两个配置是相互对应的,在Anaconda Prompt中输入 nvidia-smi命令
查看对应的NVIDIA驱动版本和其cuda驱动版本
如果命令没用,可以在NVIDIA控制面板,查看对应的信息
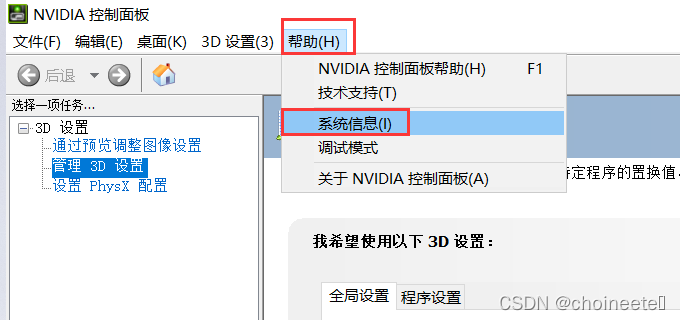
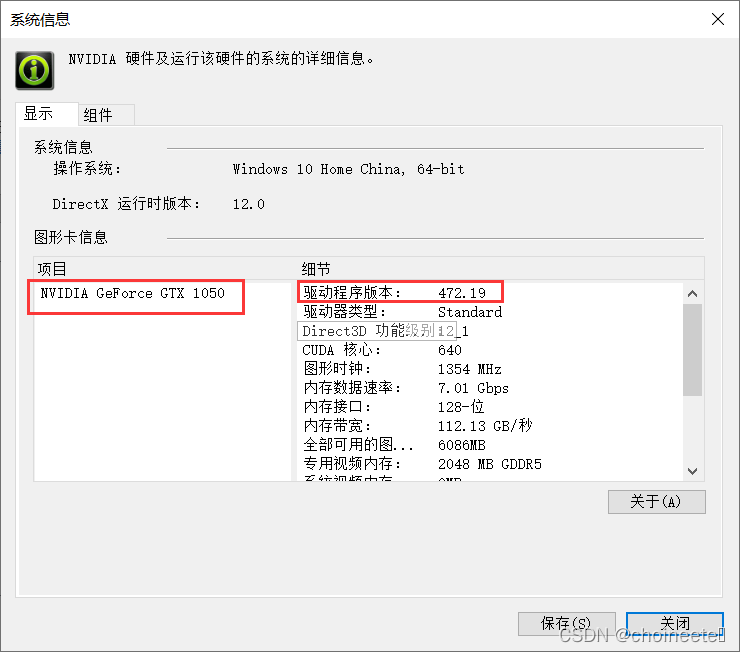
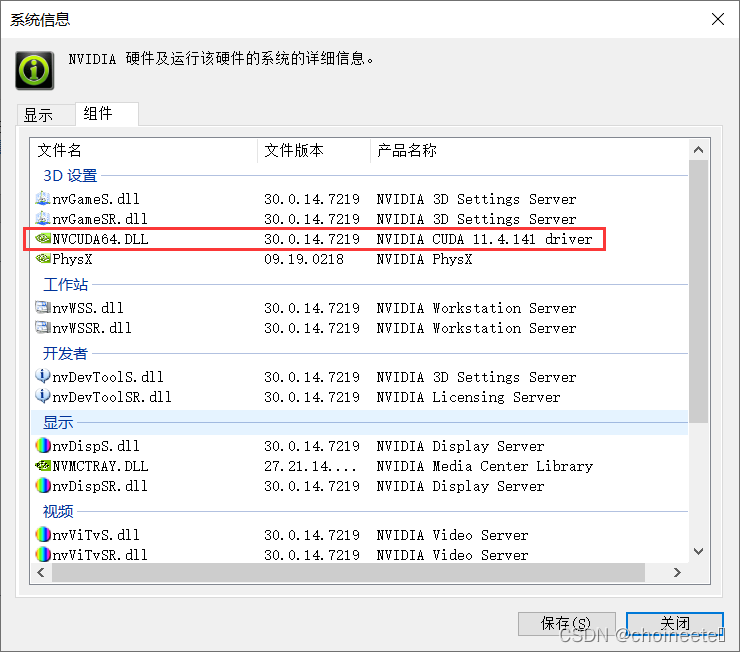
查到自己显卡对应的CUDA版本之后就可以去官网下载相应的东西了,有两个东西需要下载并配置
1.CUDA Toolkit,网址 CUDA Toolkit Archive
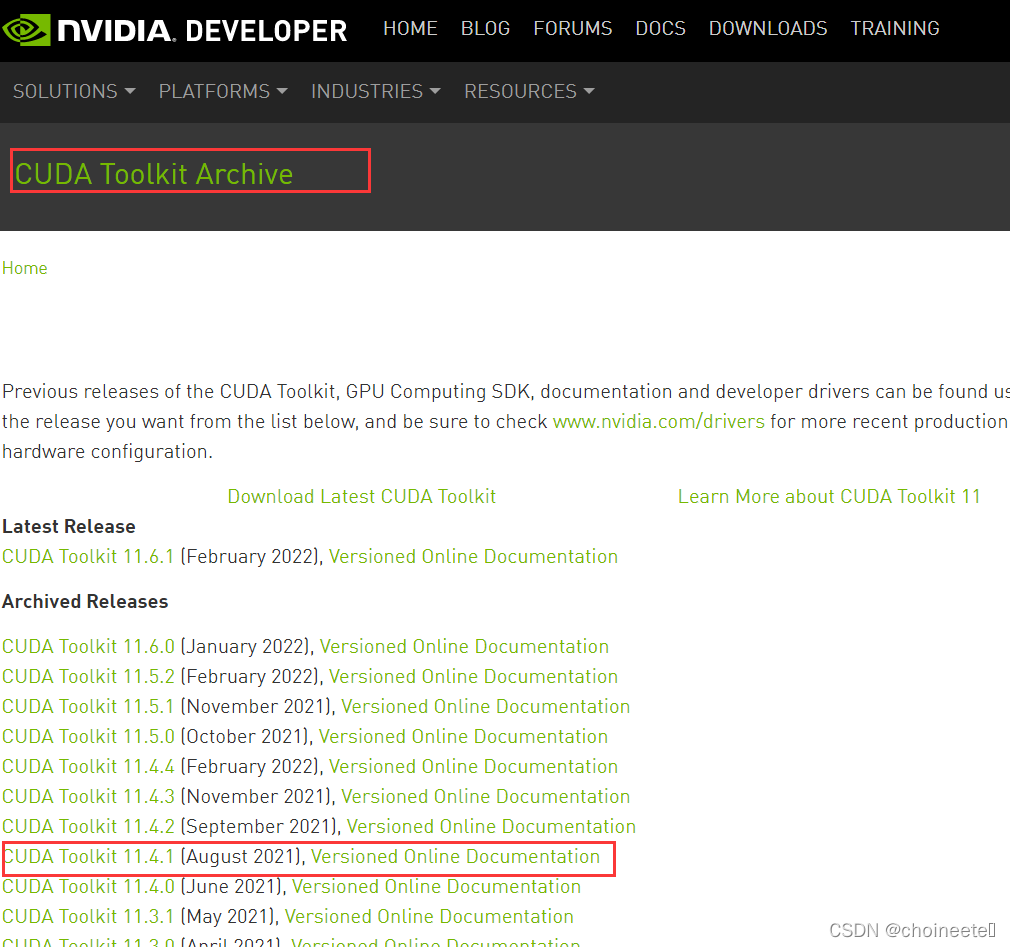
建议直接下载local版本的exe文件,网络版本非常麻烦
下载完成之后,如果想简单,一路默认即可
电脑C盘空间不够,建议自定义安装,改下安装位置
2.接下来是cudnn的下载
cudnn的版本需要和CUDA版本对应,例如11.4的CUDA对应8.2.4的cudnn
cudnn下载页
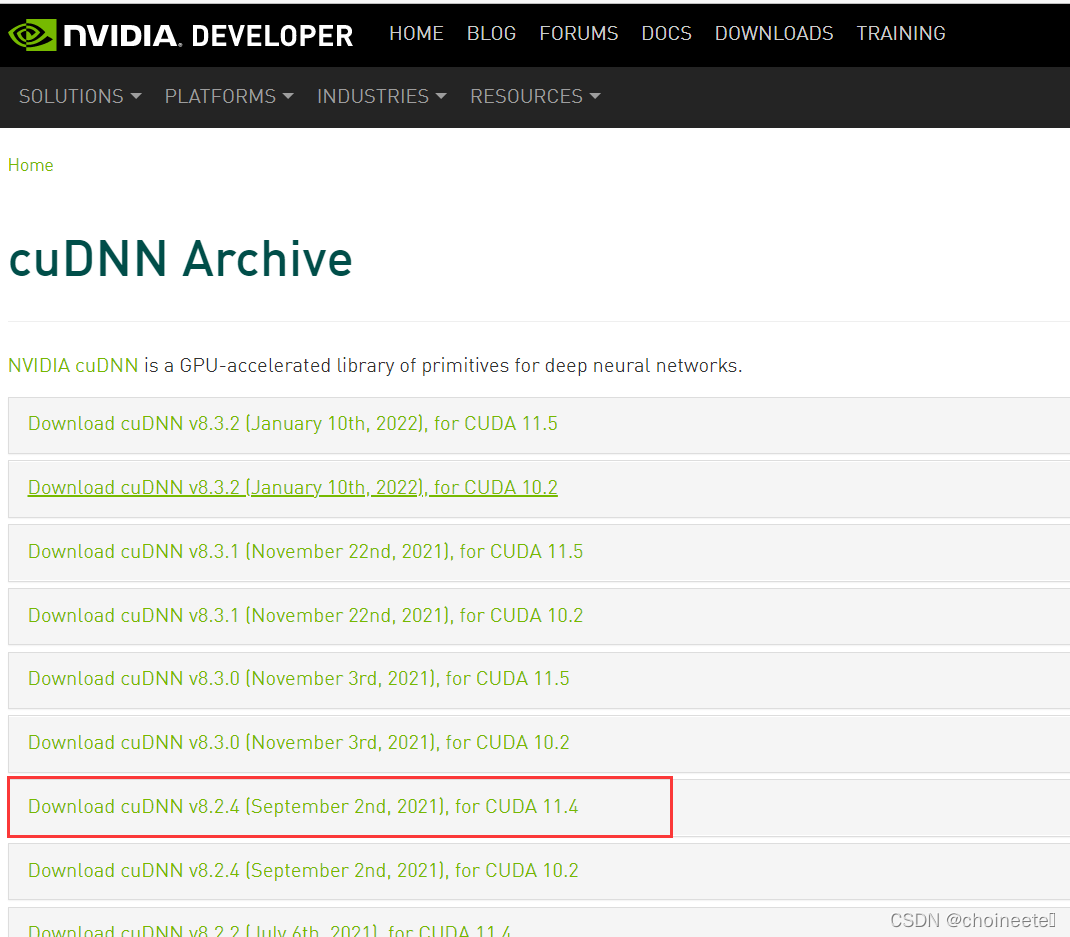
cudnn下载完毕之后无需安装,解压之后打开文件夹进入到含有cuda文件夹的目录
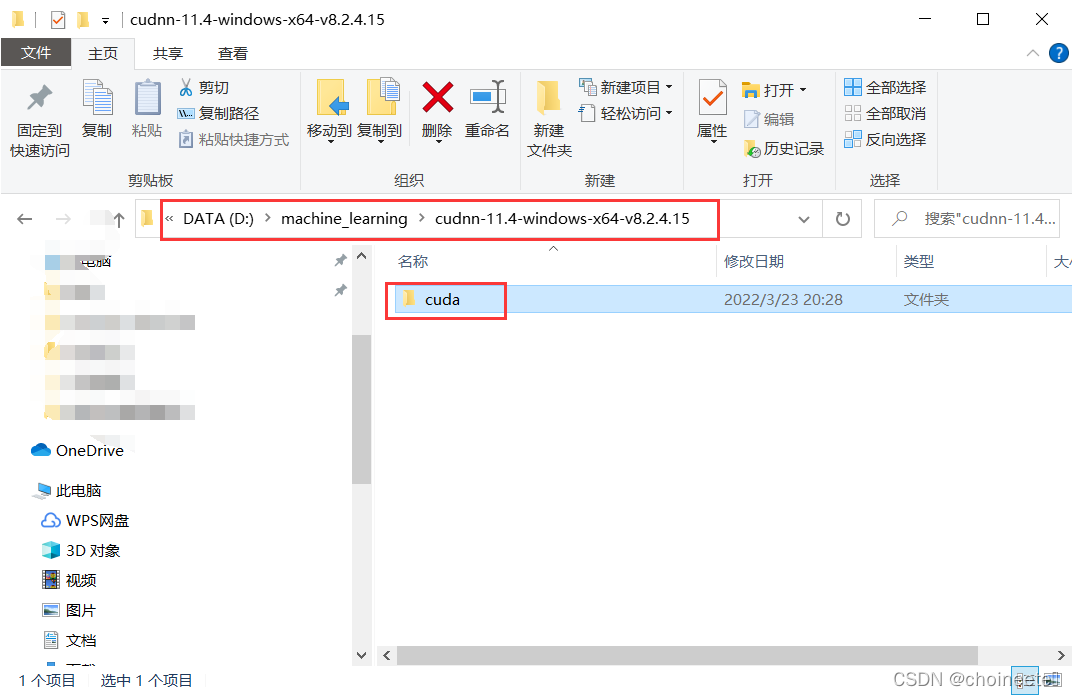
将其复制到,CUDA安装目录下,与bin目录同级,并改名为cudnn,这一步比较重要
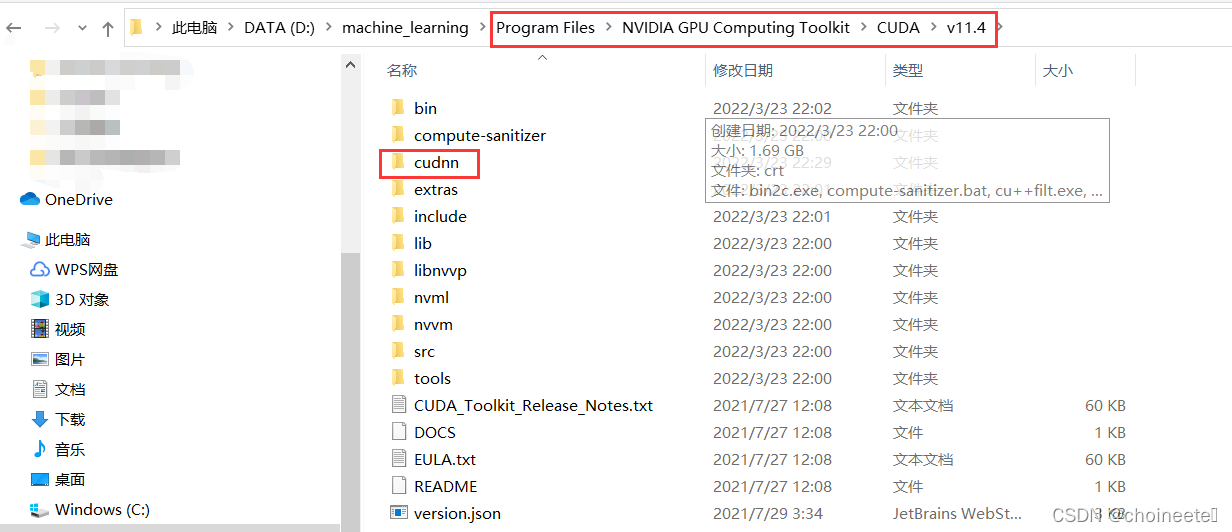
接下来,需要配置环境变量
11.4版本的CUDA,会将环境变量自动配置,也不一定,总之自己需要检查一下,没有的话需要自己配置一下,
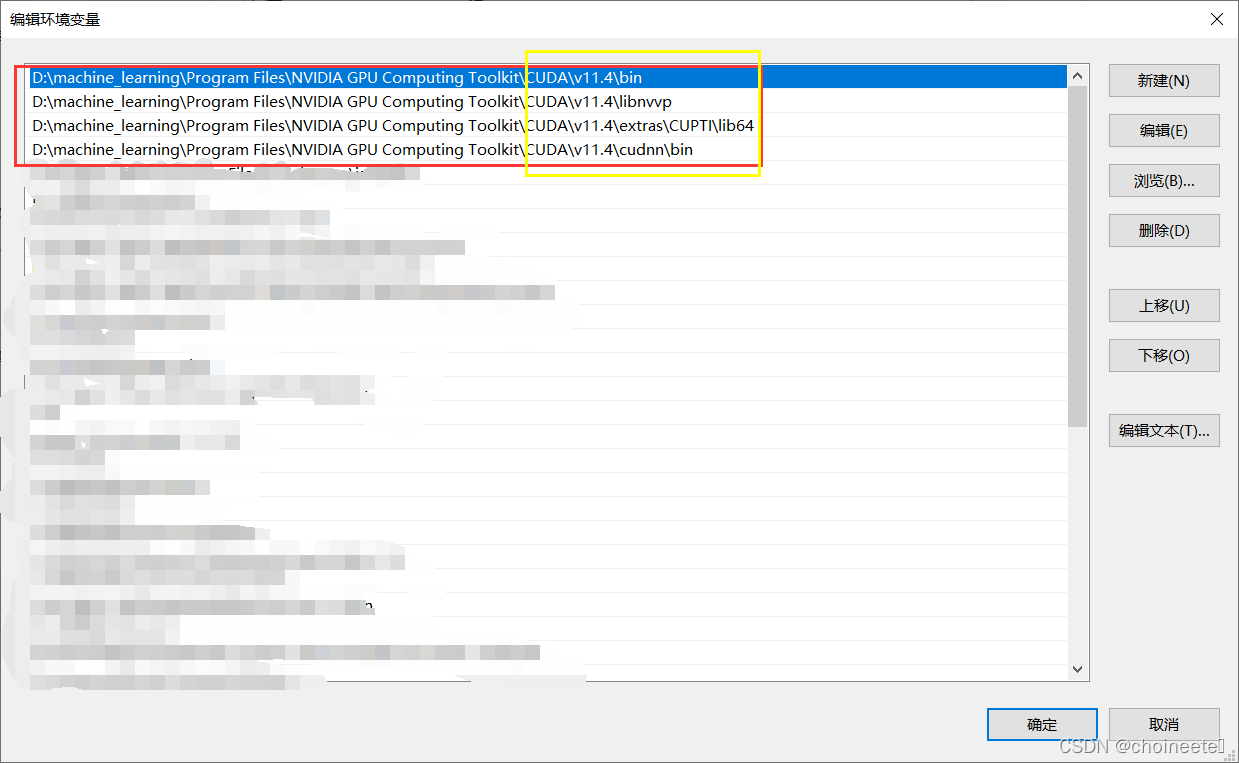
最好将这四项按顺序放到一起(系统会顺序搜索)
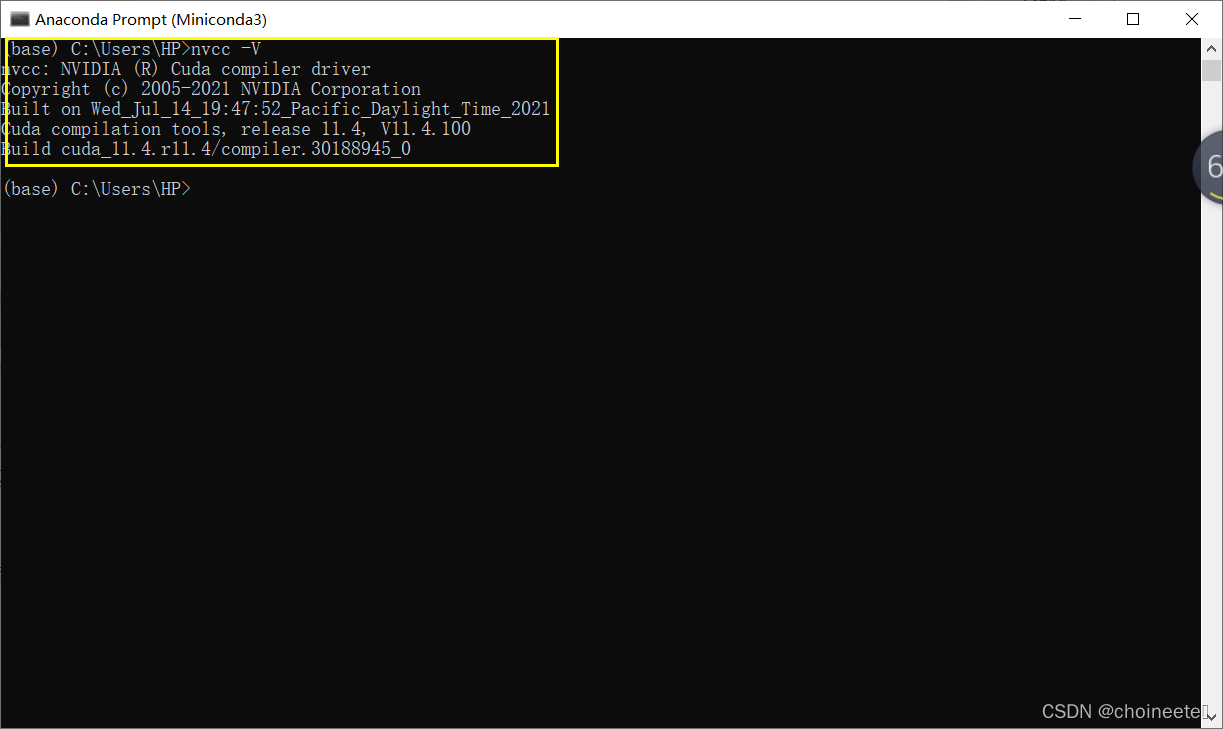
配置完毕后,可以使用 nvcc -V 查看CUDA版本,
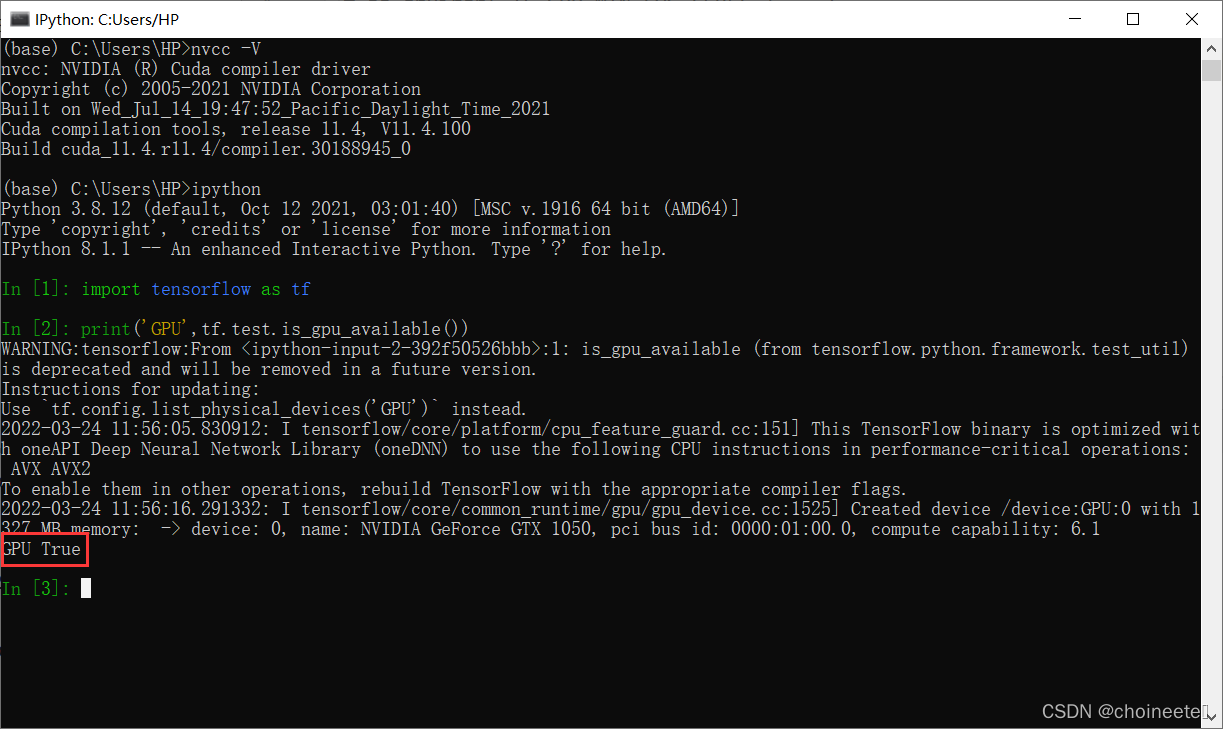
安装完毕后可以,在ipython中输入
import tensorflow as tf
print('GPU',tf.test.is_gpu_available())
会打印,GPU是否可用
测试过程中可能会出现找不到的错误,该文件在CUDA的bin目录下
将该文件复制到下面目录下即可

至此,tensorflow的GPU支持也完成了
Original: https://blog.csdn.net/encbkakw1/article/details/123702213
Author: choineete♛
Title: TensorFlow 2.8.0安装 + Miniconda + GPU支持Original: https://blog.csdn.net/encbkakw1/article/details/123702213
Author: choineete♛
Title: TensorFlow 2.8.0安装 + Miniconda + GPU支持