
第一大步:切割音频
第二大步:合成音频
一、讲如何切割音频
1.软件下载网址http://qinzi.ren/ruanjian/2019/0327/1752.html,如图
2.打开Glodwave软件,出现如下界面。
3.单击左上角"打开"按钮,打开需要切割的音频文件。
4.点击软件顶部的放大镜按钮,放大波形文件。
5.根据书的内容,左键选取区域,按Ctrl+C拷贝
6.编辑--粘贴为新文件,
7.得到的文件保存为001.mp3,剩下的音频按照5-6步的方法,一段段完成切割保存完毕。
二、讲解合成音频
1.打开小达人点读笔客户端
2.点击"智能自制内容工具"
3.点击"新家项目"
4.名称最好为书名,保存位置自定义就好,点击"确定"
5.点击"批量添加",选择刚才导出音频的文件夹
6.在这个对话框中,稍微注意一下,标贴编号和选择普通自制教材,如果连接了小达人自动会安装到小达人里面
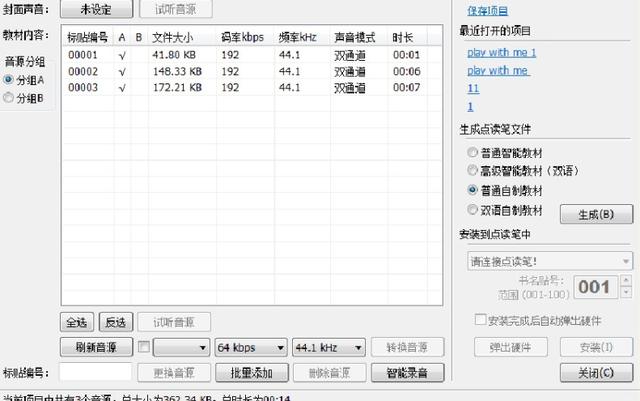
领干货V:longshaobin777
7.可以设置一下封面生硬,没有也没事
8.点击"生成"
9.打开生成的点读包,连接小达人,双击就可以安装了。
Original: https://blog.csdn.net/weixin_39831001/article/details/112451251
Author: weixin_39831001
Title: mac版小达人点读包怎么安装_教程|教你如何5分钟制作小达人点读包?
相关阅读1
Title: pandas中DataFrame重置设置索引
在pandas中,经常对数据进行处理 而导致数据索引顺序混乱,从而影响数据读取、插入等。
小笔总结了以下几种重置索引的方法:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.arange(20).reshape((5, 4)),columns=['a', 'b', 'c', 'd'])
#得到df:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
# 对其重排顺序,得到索引顺序倒序的数据
df2 = df.sort_values('a', ascending=False)
# 得到df2:
a b c d
4 16 17 18 19
3 12 13 14 15
2 8 9 10 11
1 4 5 6 7
0 0 1 2 3
下面对df2重置索引,使其索引从0开始
法一:
简单粗暴:
df2.index = range(len(df2))
# 输出df2:
a b c d
0 16 17 18 19
1 12 13 14 15
2 8 9 10 11
3 4 5 6 7
4 0 1 2 3
法二:
df2 = df2.reset_index(drop=True) # drop=True表示删除原索引,不然会在数据表格中新生成一列'index'数据
# 输出df2:
a b c d
0 16 17 18 19
1 12 13 14 15
2 8 9 10 11
3 4 5 6 7
4 0 1 2 3
法三:
df2 = df2.reindex(labels=range(len(df)) #labels是第一个参数,可以省略
# 输出df2
a b c d
0 16 17 18 19
1 12 13 14 15
2 8 9 10 11
3 4 5 6 7
4 0 1 2 3
# 注:df = df.reindex(index=[]),在原数据结构上新建行(index是新索引,若新建数据索引在原数据中存在,则引用原有数据),默认用NaN填充(使用fill_value=0 来修改填充值自定义,此处我设置的是0)。
df = df.reindex(columns=[]),在原数据结构上新建列,方法与新建行一样
法四:
df2 = df2.set_index(keys=['a', 'c']) # 将原数据a, c列的数据作为索引。
# drop=True,默认,是将数据作为索引后,在表格中删除原数据
# append=False,默认,是将新设置的索引设置为内层索引,原索引是外层索引
# 输出df2,注意a,c列是索引:
b d
a c
16 18 17 19
12 14 13 15
8 10 9 11
4 6 5 7
0 2 1 3
欢迎关注公众号,一起交流python技术。

Original: https://www.cnblogs.com/jaysonteng/p/12341468.html
Author: 邓安君
Title: pandas中DataFrame重置设置索引
相关阅读2
Title: 《FULLSUBNET: A FULL-BAND AND SUB-BAND FUSION MODEL FOR REAL-TIME SINGLE-CHANNEL SPEECH ENHANCEMENT》
《FULLSUBNET: A FULL-BAND AND SUB-BAND FUSION MODEL FOR REAL-TIME SINGLE-CHANNEL SPEECH ENHANCEMENT》
- abstract
- 1.introduction
- 2.method
* - 2.1. input
- 2.2. learning target
- 2.3 model architecture
- 4.experimental result
abstract
本文提出了一个全频带和子频带混合的模型,名为:FullSubNet,用于单通道实时信号语音增强。全频带以及子频带指模型输入为全频带以及子频带的噪声频域特征,输出全频带以及子频带的语音目标。子频带模型(sub-band model)单独处理每一个频率。它的输入包括一个频率以及多个内容频率。输出为对相关频率的去噪(clean)语音目标。这两种模型具有不同的属性。全频带模型(full-band model)可以捕捉全局频域内容以及长程跨带(cross-band)依赖(dependency)。然而它缺失了能力去建模信号平稳性以及加入局部频域模式。sub-band model恰好相反。我们依次连接了pure full-band model以及pure sub-band model,并且使用了切实的联合的训练来聚合这两种模型的优点。我们在DNS挑战数据集上进行了实验来验证提出的模型。实验结果显示full-band和sub-band信息是互补的,以及FullSubNet可以有效地聚合它们。FullSubNet的表现超过了DNS挑战中的top-ranked methods。
1.introduction
近年来,基于深度学习的单通道信号增强方法大大提升了语音增强系统的语音质量和可理解性。这些方法通常是有监督的并且可以被划分为时域和频域方法。时域方法使用神经网络将噪声信号波映射为clean信号波。而频域方法使用噪声频域特征(如:复杂波谱、量级波谱)作为神经模型的输入。学习目标是clean speech或者一个特定的mask of频域特征。通常地,由于时域信号的高维以及显式几何结构的缺失,频域信号方法仍然为语音增强方法的主流。在本文,我们关注于频域中的实时单通道信号增强。
一种我们之前提出的sub-band-based method:(1)它学习频率信号稳态来辨别语音和稳态噪声。(2)它关注于存在于当前和内容频域中的局部频域模式。局部频域模式被证明是信息丰富的用于辨别语音和其他信号。
这种sub-band model满足了DNS挑战的实时性要求,表现也不错。但是它不能建模全局频域模式并且利用长程跨频依赖。特别地,对于具有特别低信噪比(SNR)的sub-band,sub-band模型很难恢复clean speech,即使它辅助了full-band dependency。另一方面,full-band model学习了高纬输入和输出之间的回归,缺失了机制处理sub-band information,如信号平稳性。
本文提出了一个full-band和sub-band融合模型:FullSubNet来解决上述问题。基于很多之前的实验,FullSubNet被设计为full-band模型和sub-band 模型的一系列联系。简而言之,full-band模型的输出是sub-band模型的输入。通过有效的joint训练,这两种模型被同时优化。FullSubNet可以同时捕捉全局(full-band)内容以及保持能力来建模信号稳定性以及添加局部频域模式。就像sub-band 模型,FullSubNet仍然满足了实时性要求以及可以利用在合理延迟下的未来信息。
2.method
我们使用了语音信号在短时傅立叶变换(STFT,short-time Fourier transform)下的表征:
X ( t , f ) = S ( t , f ) + N ( t , f ) , X(t,f)=S(t,f)+N(t,f),X (t ,f )=S (t ,f )+N (t ,f ),
其中
X ( t , f ) , S ( t , f ) , N ( t , f ) X(t,f),S(t,f),N(t,f)X (t ,f ),S (t ,f ),N (t ,f )
分别代表了complex-valued time-frequency (T-F) bin of noisy speech,noisy-free speech(麦克风接收到的混响图像信号),在时间帧
t t t
和频率bin
f f f t = 1 , . . . , T , f = 0 , . . . , F − 1 t=1,...,T,f=0,...,F-1 t =1 ,...,T ,f =0 ,...,F −1
上的干扰噪声,
T 和 F T和F T 和F
代表了帧和频率bin的总数目。
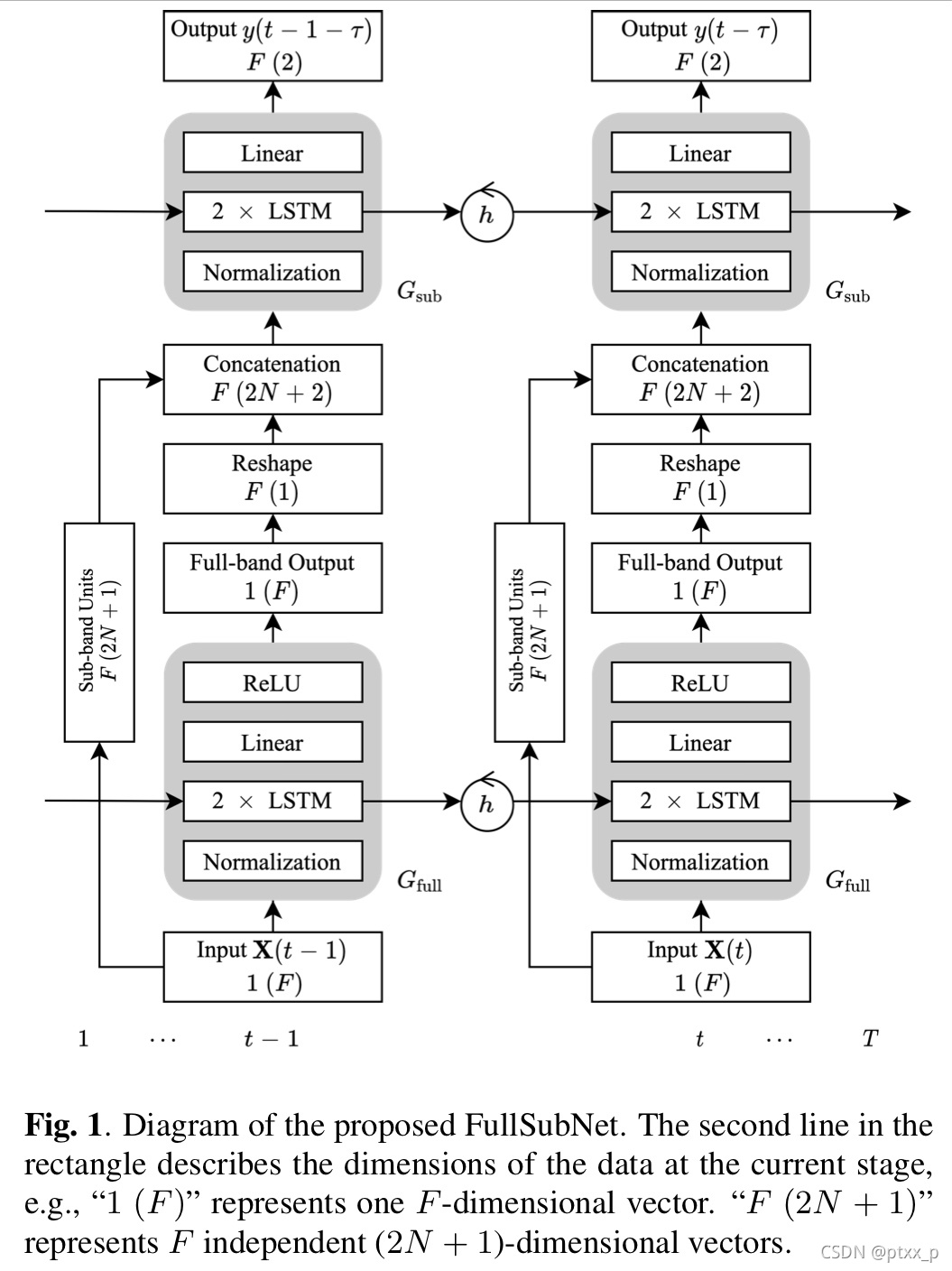
本文只关注于去噪任务,目标是去除噪声N ( t , f ) N(t,f)N (t ,f ),以及还原混响语音信号S ( t , f ) S(t,f)S (t ,f )。我们提出了一个full-band和sub-band 混合模型来完成这个任务,包括一个pure full-band model G f u l l G_{full}G f u l l 以及一个pure sub-band model G s u b G_{sub}G s u b 。下图展示了基础工作流。
; 2.1. input
之前的工作已经证明了幅度谱特征(magnitude spectral feature)可以提供关于在full-band上全局频域模式的重要线索以及在sub-band上的局部频域模式及信号稳定性。因此,我们使用noisy full-band magnitude spectral features:
X ( t ) = [ ∣ X ( t , 0 ) ∣ , . . . , ∣ X ( t , f ) ∣ , . . . , ∣ X ( t , F − 1 ) ∣ ] T ∈ R F . X(t)=[|X(t,0)|,...,|X(t,f)|,...,|X(t,F-1)|]^T \in \mathbb{R}^F.X (t )=[∣X (t ,0 )∣,...,∣X (t ,f )∣,...,∣X (t ,F −1 )∣]T ∈R F .
我们使用它的序列
X ~ = ( X ( 1 ) , . . . , X ( t ) , . . . , X ( T ) ) \tilde{X}=(X(1),...,X(t),...,X(T))X ~=(X (1 ),...,X (t ),...,X (T ))
作为full-band model
G f u l l G_{full}G f u l l
的输入。之后,
G f u l l G_{full}G f u l l
可以捕捉全局内容信息以及输出一个和
X ~ \tilde{X}X ~
相同大小的频域嵌入,用于为接下来的sub-band model
G s u b G_{sub}G s u b
提供互补信息。
sub-band model G s u b G_{sub}G s u b 根据信号稳定性以及在noisy sub-band signal中编码的局部频域模式以及full-band 模型的输出来预测frequency-wise clean-speech目标。具体来说,我们使用一个time-frequency 点∣ X ( t , f ) ∣ |X(t,f)|∣X (t ,f )∣以及它的邻接的2 × N 2\times N 2 ×N time-frequency points作为一个sub-band 单元。N N N是在每边考虑的邻居频率数目。对于边缘频率,f − N < 0 或 者 f + N > F − 1 f-N f −N <0 或者f +N >F −1,圆傅里叶频率被使用。我们拼接了sub-band unit以及full-band model的输出:G f u l l ( ∣ X ( t , f ) ∣ ) G_{full}(|X(t,f)|)G f u l l (∣X (t ,f )∣),作为sub-band model G s u b G_{sub}G s u b 的输入。
x ( t , f ) = [ ∣ X ( t , f − N ) ∣ , . . . , ∣ X ( t , f − 1 ) ∣ , ∣ X ( t , f ) ∣ , ∣ X ( t , f + 1 ) ∣ , . . . , ∣ X ( t , f + N ) ∣ , G f u l l ( ∣ X ( t , f ) ∣ ) ] T ∈ R 2 N + 2 . ( 4 ) x(t,f)=[|X(t,f-N)|,...,|X(t,f-1)|,|X(t,f)|,|X(t,f+1)|,...,|X(t,f+N)|,G_{full}(|X(t,f)|)]^T \in \mathbb{R}^{2N+2}.(4)x (t ,f )=[∣X (t ,f −N )∣,...,∣X (t ,f −1 )∣,∣X (t ,f )∣,∣X (t ,f +1 )∣,...,∣X (t ,f +N )∣,G f u l l (∣X (t ,f )∣)]T ∈R 2 N +2 .(4 )
对于固定频率
f f f G s u b G_{sub}G s u b
的输入序列为:
x ~ ( f ) = ( x ( 1 , f ) , . . . x ( t , f ) , . . . , x ( T , f ) ) . \tilde{x}(f)=(x(1,f),...x(t,f),...,x(T,f)).x ~(f )=(x (1 ,f ),...x (t ,f ),...,x (T ,f )).
在这个序列中,在时间维度上的时间转变反映了信号平稳性,这是一个分辨语音和相关的平稳噪声的重要线索。noisy sub-band spectra(由
2 N + 1 2N+1 2 N +1
的频率构成)以及它的时间动态提供了局部频域模式,可以通过专用的sub-band model学习得到。尽管信号平稳性和局部模式存在于full-band model
G f u l l G_{full}G f u l l
的输入,但是没有被
G f u l l G_{full}G f u l l
学习到。于是sub-band model学习了full-band model的附加信息。同时,full-band model的输出也为sub-band model提供了互补的信息。
因为full-band 频域特征X ( t ) X(t)X (t )包括F特征,我们最终生成F个维度为2 N + 2 2N+2 2 N +2的独立的输入序列给G s u b G_{sub}G s u b 。
2.2. learning target
毫无疑问,精确的相位估计可以提供更多的听觉感知质量改善,尤其是在
低信噪比 (SNR) 条件下。但是落在− π ∼ π -\pi \sim \pi −π∼π的相位具有复杂的数据分布,使得相位估计变得困难。于是我们不对相位进行准确估计而是将complex idel ratio mask (cIRM)作为我们模型的学习目标。我们使用
双曲正切在训练中压缩 cIRM 并且在推理过程中对未压缩的mask使用逆函数(K = 10,C = 0.1)。我们对cIRM的一个T-F bin定义为y ( t , f ) ∈ R 2 y(t,f) \in \mathbb{R}^2 y (t ,f )∈R 2。sub-band model将for f的序列x ~ ( f ) \tilde{x}(f)x ~(f )作为输入,之后预测cIRM序列:
y ~ ( f ) = ( y ( 1 , f ) , . . , y ( T , f ) ) . \tilde{y}(f)=(y(1,f),..,y(T,f)).y ~(f )=(y (1 ,f ),..,y (T ,f )).
2.3 model architecture
在FullSubNet中的full-band和sub-band模型具有相同的模型架构,包括两个堆叠的无向LSTM层以及一层FC。full-band model的LSTM包括512隐藏单元,ReLU为激活函数。full-band模型在每个时间步上输出一个F维的向量,每个频率一个向量。sub-band unit和每个频域进行拼接来形成F个独立的输入样本(见公式4)。经过之前的实验,sub-band model不需要和full-band model一样大,因此在LSTM的每一层中就采用了384个隐藏单元,sub-band model的输出没有采用激活函数。需要说明的是,所有的频率共享一个sub-band network(以及它的参数)。在训练过程中,考虑限制的LSTM内存容量,输入-目标序列对通过一个固定长度的sequence生成。
为了使得模型更加容易被优化,输入序列必须和输入等级相等。对于full-band 模型,我们实验地计算了在full-band序列X ~ \tilde{X}X ~上的振幅频域特征均值μ f u l l \mu_{full}μf u l l 并且归一化了输入序列x ~ μ f u l l \frac{\tilde{x}}{\mu_{full}}μf u l l x ~。sub-band模型独立地处理这些频率。对于频率f f f,我们计算输入序列x ~ ( f ) \tilde{x}(f)x ~(f )的均值μ s u b ( f ) \mu_{sub}(f)μs u b (f )并且归一化输入序列x ~ ( f ) μ s u b ( f ) \frac{\tilde{x}(f)}{\mu_{sub}(f)}μs u b (f )x ~(f )。
在实时的推理过程中,我们通常使用累计归一化方法,也就是说,用于归一化的均值使用所有的frames进行计算。然而,在实际的实时语音增强系统中,最开始的语音信号往往invalid。在本次工作中,为了更好地展示FullSubNet的表现而忽略归一化问题,我们直接使用在整个test clip上计算得到的μ f u l l \mu_{full}μf u l l 和μ s u b ( f ) \mu_{sub}(f)μs u b (f )来在推理过程中使用归一化。
我们的方法支持输出延迟,使得模型可以在合理的小时延下探索未来信息。为了推理y ( t − τ ) y(t-\tau)y (t −τ),未来的time step ,也就是说x ( t − τ + 1 ) , . . . , x ( t ) x(t-\tau+1),...,x(t)x (t −τ+1 ),...,x (t )作为输入序列(就像图1中所示)。
4.experimental result
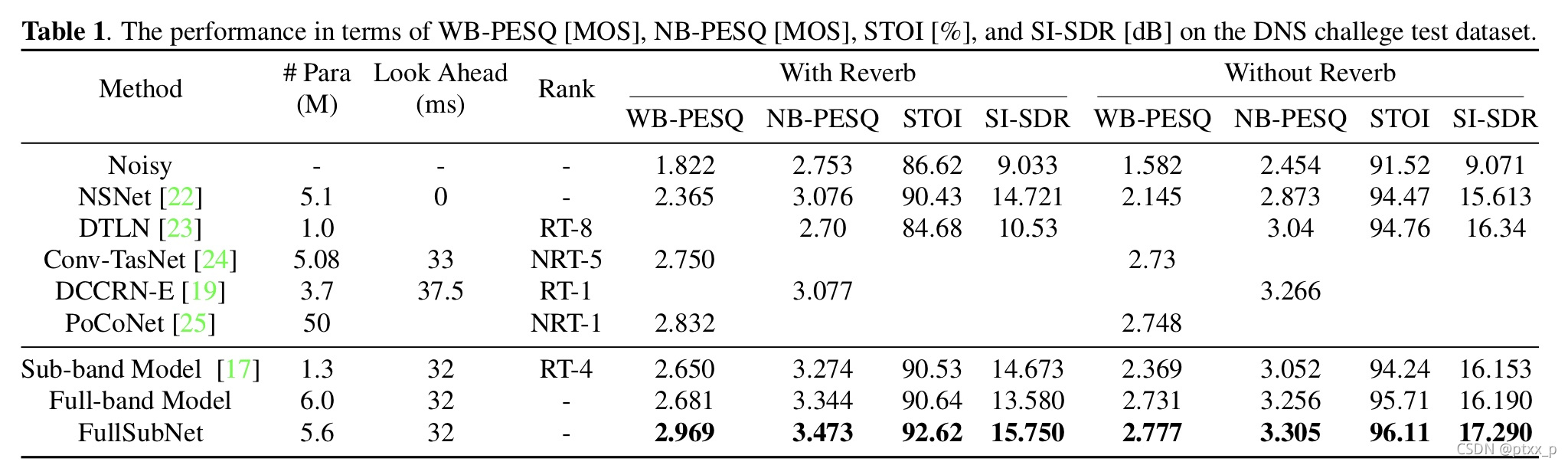
full band模型的表现普遍优于sub-band model,因为full-band模型使用更大的网络来利用宽频信息。很有趣的现象是:sub-band model在"with reverb"数据上更加有效,full-band model则相反。这表明了sub-band model通过关注在narrow-band 频带上的时间演化有效地建模了回响效果。
Original: https://blog.csdn.net/ptxx_p/article/details/120481017
Author: ptxx_p
Title: 《FULLSUBNET: A FULL-BAND AND SUB-BAND FUSION MODEL FOR REAL-TIME SINGLE-CHANNEL SPEECH ENHANCEMENT》
相关阅读3
Title: Python + OpenCV一步一步地实现图像拼接(原理与代码)
图像拼接可以理解为三大步:
- 按顺序读取多幅图像,并保证图像按照从左到右的顺序。
- 发现这些图像像素之间的相关性(涉及到 单应性)。
- 将这些图像拼接成为一张全景图像。
首先,需要了解如下几个概念。
SIFT特征提取
图像匹配
计算单应矩阵
假设我们使用同一部相机,用不同视角拍了两张照片,那么如何对这两张图片视角变换进行建模,将相邻的两张图片联系起来,就成为了一个问题。
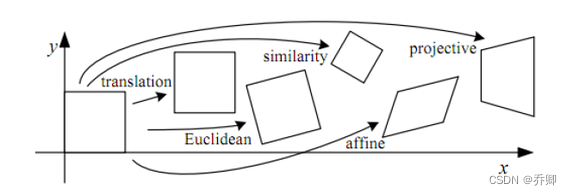
上图展示了一些几何变换。单应矩阵的作用在于,将图像平面P1转换为另一个图像平面P2。下面是一个例子:

上面的projective(射影变换)可以表示为: I_1= _H× _I_2
其中H即为单应矩阵。单应矩阵保持图像中的直线,因此,唯一可能的变换是平移、仿射等。H矩阵可以表示为:
h11 h12 h13
h21 h22 h23
h31 h32 h33
在图像拼接这一问题中,我们一旦获得了图像之间的匹配,下一步就是计算单应矩阵。单应矩阵将使用这些匹配的关键点估计图像之间的相对方向变换。
那么,对于全景拼接过程中两张图像相邻的情况,怎样计算单应矩阵呢?我们注意到,这涉及到 RANSAC算法,在OpenCV中,调用findHomography()方法时指定cv2.RANSAC参数。
给定原始图像与目标图像,则相应的单应矩阵可以用OpenCV中的findHomography()方法求得。
# pts_src与pts_dst都是numpy arrays
h, status = cv2.findHomography(pts_src, pts_dst, cv2.RANSAC)
给定原始图像与单应矩阵,则转换后的图像可以用OpenCV中的warpPerspective()方法求得。
# im_src是numpy arrays
# size的格式:(width,height)
im_dst = cv2.warpPerspective(im_src, h, size)
拼接(warping)
单应矩阵告诉了我们:两张图片的角度之间有什么关系。基于这一点,我们可以把两张图像转换到同一个空间中,这一过程称为warping。warping分为如下三种:
- 平面:其中每个图像是一个平面表面的元素,经过平移和旋转。
- 圆柱形:其中每个图像都表示为圆柱形的坐标系。图像绘制在圆柱体的曲面上。
- 球面:上述的附加物为球面,而非圆柱体,作为参考模型。
由于时间有限,这里仅先实现平面扭曲。由于已经计算出单应矩阵,可以使用该矩阵将第一张图像转换到第二张图像的平面上。对于在同一平面上的两张图像,一个很直观的思路是,迭代两幅图像,发现匹配的区域则覆盖,否则置为0。
def stitch(image_left_path, image_right_path):
# 读取图像
image_left = cv2.imread(image_left_path)
image_right = cv2.imread(image_right_path)
# 提取SIFT特征
kp1, des1 = sift_algorithm(image_left)
kp2, des2 = sift_algorithm(image_right)
# 匹配关键点
matches, H, status = bf_match(image_left, image_right, kp1, kp2, des1, des2)
# 拼接
result = cv2.warpPerspective(image_right, H, (image_right.shape[1] + image_left.shape[1], image_right.shape[0]))
result[0: image_left.shape[0], 0: image_left.shape[1]] = image_left
# plt.imshow(result)
# plt.show()
cv2.imwrite('step_by_step_result.jpg', result)
return result
Original: https://blog.csdn.net/qq_41112170/article/details/125848973
Author: 乔卿
Title: Python + OpenCV一步一步地实现图像拼接(原理与代码)