
最近自己写的一个软件需要在持续监测T-box的信号强度值时,领导提出在信号低于阈值时给出警报或指示,之前的想法是在软件界面上加一个指示灯,但这样还是需要Tester去盯着屏幕,这样不友好,所以索性在通过声音的方式给出警示,这样就不用一直盯着屏幕了,网上搜索了几个PYQT播放音频的例程,都没法直接运行,在这里记录一下吧
直接上代码:
from PyQt5 import QtMultimedia
from PyQt5.QtCore import QUrl
import time # 需要导入时间模块设置延时
file = QUrl.fromLocalFile('11612.wav') # 音频文件路径
content = QtMultimedia.QMediaContent(file)
player = QtMultimedia.QMediaPlayer()
player.setMedia(content)
player.setVolume(50.0)
player.play()
time.sleep(2) #设置延时等待音频播放结束
值得注意的是,音频时间比较长时,最好另起一个线程专门来播放音频,否则延时会造成进程阻塞
Original: https://blog.csdn.net/m0_37811342/article/details/108741505
Author: O98K
Title: PyQT5播放音频
相关阅读1
Title: 自编码器(Auto-encoder)的概念和应用
文章目录
*
- 1. 基本概念
- 2. 应用
-
+ 2.1 de-noising auto-encoder
+ 2.2 feature disentangle
+ 2.3 discrete representation
+ 2.4 text as representation
+ 2.5 Tree as representation
+ 2.6 generator
+ 2.7 compression
+ 2.8 anomaly detection
1. 基本概念
Auto-encoder包含一个encoder和一个decoder,encoder将原始图片转化为一个低维度的vector,并且期望vector能够尽可能地保留输入图片的特征,这样decoder可以将Vector还原为原始图像,和输入图像越接近越好。

为什么vector可以还原为原始图像呢?假设原始图像为3 × 3 3\times3 3 ×3大小,在有些情况下,输入图像可能只包含下图所示的两种类型,那么就可以用2维的向量表示原始图像。这样一来,就可以降低维度,减少运算量。

; 2. 应用
2.1 de-noising auto-encoder
de-noising auto-encoder为auto-encoder的一种用法,利用auto-encoder去除噪声。

; 2.2 feature disentangle
因为auto-encoder得到的向量具有原始输入信号的一些信息(图像的纹理、颜色;音频的内容、银色等),feature disentangle利用auto-encoder的向量中的这些信息提取出来,用于下游任务。

例如,如果想要做变声器,就可以将提取的向量中代表音色的维度替换,代表内容的维度保留。

2.3 discrete representation
discrete representation希望通过对vector进行一些限制,使得其可以解决特定的任务。例如生成的vector是one-hot向量,那么就可以使得其传递的信息是分类的结果。

; 2.4 text as representation
text as representation将原本的输入和输出从向量变成文字,encoder和decoder用seq2se1代替,通过这样的方式得到摘要。
但是由于机器生成的"摘要"不满足正常的文本(无法阅读),因此需要添加额外的discriminator来进行鉴别。生成的摘要要尽量骗过discriminator。

2.5 Tree as representation

; 2.6 generator
Auto-encoder的decoder部分可以用作generator

2.7 compression
Auto-encoder还可以用作压缩。

; 2.8 anomaly detection
auto-encoder还可以用作异常检测,如果输入和输出相差较大,则认为输入是异常的,是训练的时候没有见过的图片。

Original: https://blog.csdn.net/weixin_44579633/article/details/124618636
Author: 蓝鲸鱼BlueWhale
Title: 自编码器(Auto-encoder)的概念和应用
相关阅读2
Title: 手把手解决module ‘tensorflow‘ has no attribute ‘placeholder
1、问题背景:构建神经网络在加入卷积层时出现报错
face_recigntion_model.add(Conv2D(32,3,3,input_shape=(IMAGE_SIZE,IMAGE_SIZE,3),activation='relu'))
AttributeError: module 'tensorflow' has no attribute 'placeholder'
2、报错原因:可能是由于tf.placeholder的版本问题,tf.placeholder是tensorflow1.x版本的东西,tensorflow2.0就不能用了
查看自己的TensorFlow版本print(tf.version)
我的为2.8.0,需要降版本
3、解决方法:
方法1:
修改import tensorflow as tf为
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
方法2:
修改import tensorflow as tf为
import tensorflow.compat.v1 as tf
tf.compat.v1.disable_eager_execution()
方法3:我采用上述两种方式都不行,需要手动降TensorFlow的版本,方式为将高版本python改变成低版本python以安装低版本tensorflow.
1、先卸载已有的TensorFlow,在终端中输入:
pip uninstall tensorflow进行卸载
2、将编译环境降为python3.6
由于python3.7以上安装tensorflow只有2.x的版本,所以需要将编译环境也降到python3.6
安装python3.6,在终端中输入:
conda create --name py36 python=3.6 anaconda
重启pycharm,激活python3.6,在终端中输入:
activate py36
验证环境,在终端中输入:
python –version
输出为:
Python 3.6.13 :: Anaconda, Inc.
如果还是原来的版本,需要重新启动下pycharm在检查版本。
3、安装低版本TensorFlow
安装TensorFlow1.4.0,在终端中输入:
pip install tensorflow==1.4.0 -i Simple Index
安装成功
PS:新的编译环境中可能会缺少很多需要用的包,需要采用pip install 下载相关包
4、后续问题补充:
缺少cv2、sklearn... 在终端通过pip安装
pip install opencv-python -i Simple Index
pip install scikit-learn -i https://pypi.douban.com/simple
继续报错:cannot import name 'tf2'
原因:keras的版本和tensorflow的版本不匹配,终端输入:
pip list找到TensorFlow的版本
tensorflow 1.4.0
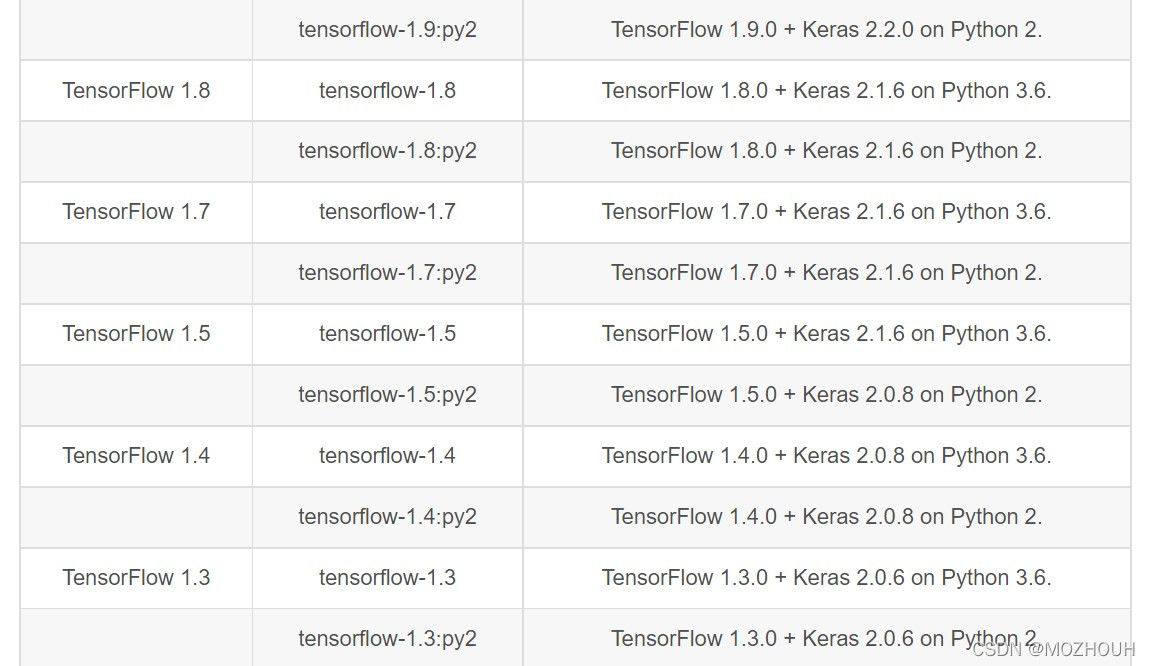
在对应表格中找到对应的keras版本,通过pip安装
pip install keras==2.0.8 -i https://pypi.douban.com/simple
每解决一个问题就运行下程序,遇到新的问题解决新的问题,直至程序能够运行下去不报错。
5、个人心得
如果网络上提供的方法不能解决问题,不要一直找新的答案,要先清楚问题的原因是什么,再去解决。譬如本次报错的主要问题主要是TensorFlow的版本不对,所以输入什么代码以及有没有用不重要,重要的是需要寻找并完成TensorFlow低版本的替代工作。
如果我解决了你的问题,请点赞给我加油 ,也谢谢在解决问题过程中参考的诸位大佬们。。
,也谢谢在解决问题过程中参考的诸位大佬们。。
主要参考:
将高版本py与tensorflow改变成低版本python以安装低版本tensorflow_树顶上的橙子的博客-CSDN博客_安装低版本tensorflow
Original: https://blog.csdn.net/MOZHOUH/article/details/124250715
Author: 日拱一卒不慌忙
Title: 手把手解决module ‘tensorflow‘ has no attribute ‘placeholder
相关阅读3
Title: Python:如何实现提取文本关键词、摘要、短语、无监督文本聚类
我们在使用Python对文本数据进行处理时,通常会遇到提取文本关键词、提取摘要、提取短语或者进行无监督文本聚类等需求。本文将向大家推荐一个非常实用的包pyhanlp,使用这个包中的函数通过几行代码就可以完成以上所有的操作。
一、提取文本关键词
from pyhanlp import *
content = "随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。"
# 提取文本关键词
print(HanLP.extractKeyword(content, 2))
输出结果:

注意:如果大家想获取准确度更高的关键词推荐大家使用另一种办法:通过jieba进行中文分词,然后去停用词,再用TF-IDF算法进行提取关键词。
二、提取文本摘要
from pyhanlp import *
content = "随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。"
# 提取文本摘要
print(HanLP.extractSummary(content, 4))
输出结果:

三、提取本文短语
from pyhanlp import *
content = "随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。"
# 提取文本短语
print(HanLP.extractPhrase(content,10))
输出结果:

四、无监督文本聚类
在进行无监督文本聚类前,需要大家可以对文本进行预处理。
首先是中文分词,推荐大家使用jieba分词器。利用jieba分词对文本进行分词后,文本中的句子会被划分成单个的词语,但是其中部分词语并无实际意义。如果不对这些无实际意义的词语进行处理,那么后续提取关键词时,这些词语也会被统计,这将使工作量增加,且可能导致结果无效。
最后就是将词语以逗号分割,组成字符串。这样我们就把数据处理好了,然后使用pyhanlp包中的函数就可以完成无监督文本聚类。
from pyhanlp import *
ClusterAnalyzer = JClass('com.hankcs.hanlp.mining.cluster.ClusterAnalyzer')
if __name__ == '__main__':
analyzer = ClusterAnalyzer()
analyzer.addDocument("1", "流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 流行, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 蓝调, 摇滚, 摇滚, 摇滚, 摇滚")
analyzer.addDocument("2", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲")
analyzer.addDocument("3", "古典, 古典, 古典, 古典, 民谣, 民谣, 民谣, 民谣")
analyzer.addDocument("4", "爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 爵士, 金属, 金属, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲, 舞曲")
analyzer.addDocument("5", "流行, 流行, 流行, 流行, 摇滚, 摇滚, 摇滚, 嘻哈, 嘻哈, 嘻哈")
analyzer.addDocument("6", "古典, 古典, 古典, 古典, 古典, 古典, 古典, 古典, 摇滚")
print(analyzer.repeatedBisection(3)) # 重复二分聚类
print(analyzer.repeatedBisection(1.0)) # 自动判断聚类数量k
输出结果:

需要注意:
1、路径不要出现中文,不然会导致找不到相关文件!
2、如果包下载的很慢的话,可以在网上找到包,下载好后放入相关文件夹内!
3、analyzer.addDocument(index1,index2)的作用是往聚类数据库中添加数据。第一个参数是最后显示的结果,也就是说第一个参数是代表第二个参数的。第二个参数是预处理完毕后的数据,一个以逗号分割的词语组成的字符串。
4、analyzer.repeatedBisection(3)是重复二分聚类,参数是最后聚类的类簇个数。
5、analyzer.repeatedBisection(1.0)有时候自己无法确定最终的类簇个数,就可以使用这个函数,它可以实现自动判断聚类的数量。
Original: https://blog.csdn.net/m0_52625549/article/details/124635618
Author: 浩栋丶
Title: Python:如何实现提取文本关键词、摘要、短语、无监督文本聚类