
抵扣说明:
1.余额是钱包充值的虚拟货币,按照1:1的比例进行支付金额的抵扣。
2.余额无法直接购买下载,可以购买VIP、C币套餐、付费专栏及课程。
Original: https://blog.csdn.net/GUANGZHAN/article/details/119805734
Author: 智享AI
Title: 三、自然语言处理研究内容
相关阅读1
Title: colmap的使用简介
colmap的三维重建使用简介,首先colmap的安装传送门在我另一篇中有记录。
本篇记录一下使用方法。
1.数据集获取
首先是数据集问题,可以下载自己想试着重建的数据集保存。
通过 colmap -h和 colmap gui打开colmap的界面。
; 2.新建项目
首先点击file新建项目 “New Project”,弹出窗口,首先建立database,命名为scan1,后缀的db是它自动带上的,然后在Image中选择自己想要重建的图像。

3.特征点提取
之后就可以进行特征点提取,点击processing中的 Feature extraction,其中可以什么都不动,使用默认项,也可以自己修改,比如相机模型一般选择针孔模型,也可以换别的。然后点击 Extract
选择相机模型为Pinhole
选择Parameters from EXIF:从EXIF中提取相机内参(一般采集到的影响都携带EXIF文件)其他参数暂且默认
然后点击Extract进行特征提取
; 4.特征点匹配
特征提取之后,需要进行特征匹配,点击processing中的 Feature matching,其中可以什么都不动,使用默认项,也可以自己修改,然后点击 run。
这个步骤结束之后会自动生成场景图和匹配矩阵(以不同视图之间同名特征数为权重,以不同视图为图节点的图结构)

5.稀疏点云重建
然后就是稀疏点云重建。这里点击"reconstruction"中的"start reconstruction"进行一键式重建,整个过程将会自动进行增量式重建,我们可以从旁边的log框内查询当前状态。
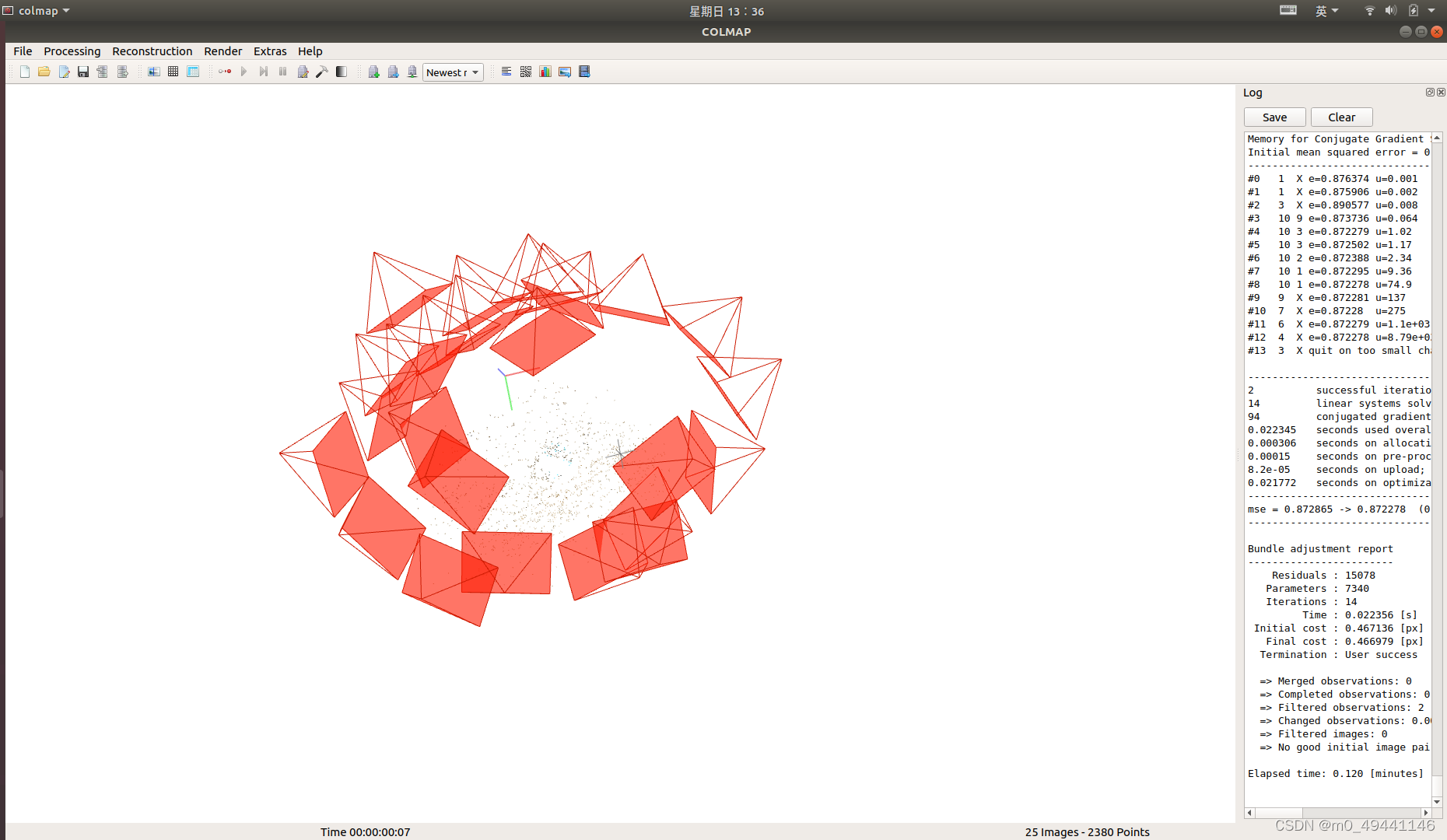

; 1.右侧显示中,可以看出,
Registering image #39(49) :当前正在新增第39个视角
=> Image sees 337 / 503 poin :当前影像可以看到已有点云的337个
Pose refinement report :姿态细化信息
Residuals:672
Parameters:8 //参数
Iterations:8 //迭代次数
time:0.0055149
Initial cost:0.62589
Final cost:0.55798
Termination:covergence
Continued observation:3 //继续观察
Added observations:47 //新增观察点
2.进行姿态估计(Pose Refinement Report),再进行BA优化
Bundle adjustment report :BA优化
Residuals:12142
Parameters:1082 //参数
Iterations:12 //迭代次数
time:0.167065
Initial cost:0.515275
Final cost:0.504027
Termination:covergence
Merged observations:110//合并观察? 整体稀疏点云融合测量点110个
Completed observations:XXX //完成观察
Filtered observation 41 //过滤观察 滤除测量点41个
Changed observation XXX
最后进行三角测量(Retriangulation)新增观测点111个。
上述过程结束后,进行迭代全局的BA优化,优化已有相机的姿态和三维稀疏点云坐标。
以第49张图像(39个视角)为例
已有点云576个首先进行姿态估计(Pose Refinement Report)再进行BA优化:整体稀疏点云融合测量点149个,滤除测量点32个再进行三角测量(Retriangulation)最后再进行迭代全局的BA优化,优化已有相机的姿态和三维稀疏点云坐标
6.稠密点云重建
 点击"reconstruction"中的"dense reconstruction",弹出稠密重建窗口,并点击"select"选择生成文件存放的目录,首先新建workspace的保存路径。
点击"reconstruction"中的"dense reconstruction",弹出稠密重建窗口,并点击"select"选择生成文件存放的目录,首先新建workspace的保存路径。
然后对窗口前三个选项一次点击。
Undistortion: 影像去畸变
注意:这里不要选择项目的根目录,拷贝图片的时候会报错路径已存在导致colmap gui闪退的;同时undistortion也只能点一次,第二次同样会因为路径已存在闪退
带有畸变的图像会导致边缘有较大的时差估计误差,因此在深度图估计之前,使用光学一致性和几何一致性联合约束构造代价匹配
dtu数据集和之前配置成针孔模型已经隐含无畸变 如果使用自采集数据集需要更改相机模型为带畸变参数的相机模型
stereo:深度估计
深度估计结束后,可以得到"photometric"和"geometric"下的深度图和法向量图。由之前提及的原理,COLMAP会利用光学一致性(photometric)同时估计视角的深度值和法向量值,并利用几何一致性(geometric)进行深度图优化,因此可以点击"Depth Map"和"Normal Map",即可得到对应视角的深度图和法向量图。
点击这些就可以观察光学一致性photometric和几何一致性geometric后的depth map和normal map
Colmap会利用光学一致性同时估计视角的深度值和法向量值,并利用几何一致性进行深度图优化

参考图片
Fusion:稠密重建
 通过meshlab,可以更清晰的看到重建结果。meshlab需要自己安装。
通过meshlab,可以更清晰的看到重建结果。meshlab需要自己安装。
重建后会在dense中生成ply模型文件
; 7.匹配矩阵
通过点击"Extras"中的"Match Matrix"可以导出当前场景的匹配矩阵。
从匹配矩阵中看出数据集之间相机运动规律,若相机围绕物体呈圆周采样,匹配矩阵将有条带出现且若途中各个条带的平行关系越紧致,则说明相机的运动控制越严格。采集数据集的前期控制对重现效果有影响。
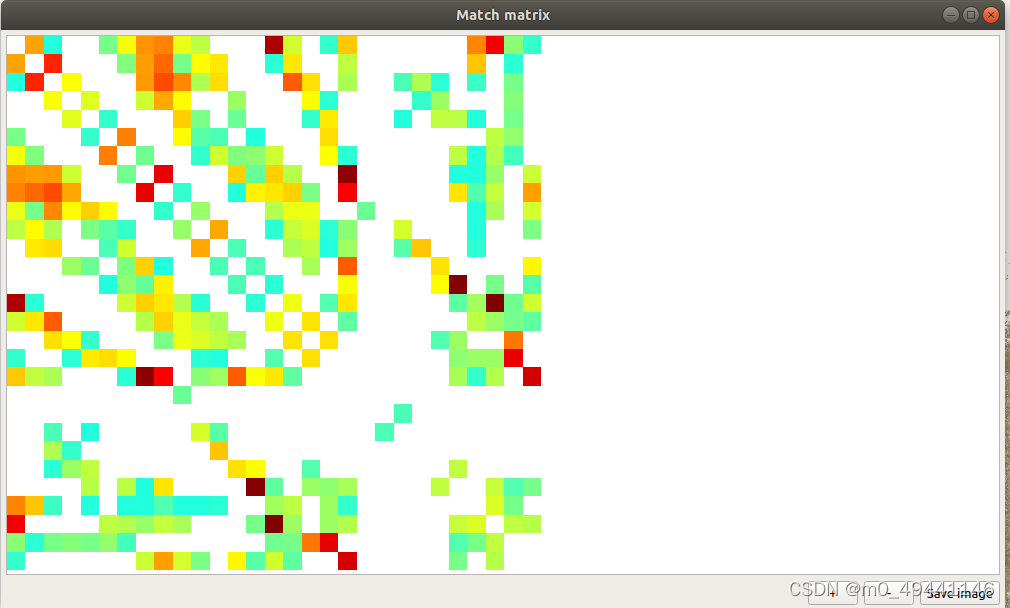
8.深度估计时间
表1 深度图估计运行时间对比(单位:分钟) 数据参考文章
 本实验28个图像用时约21分钟
本实验28个图像用时约21分钟

; 7.其中一些内容
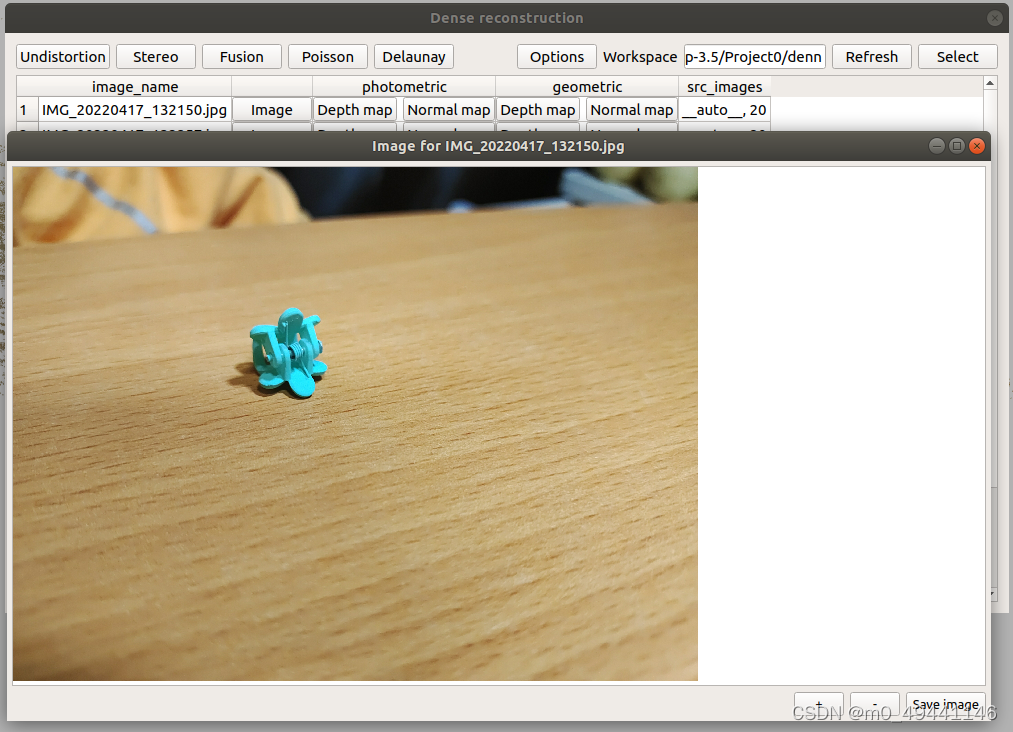
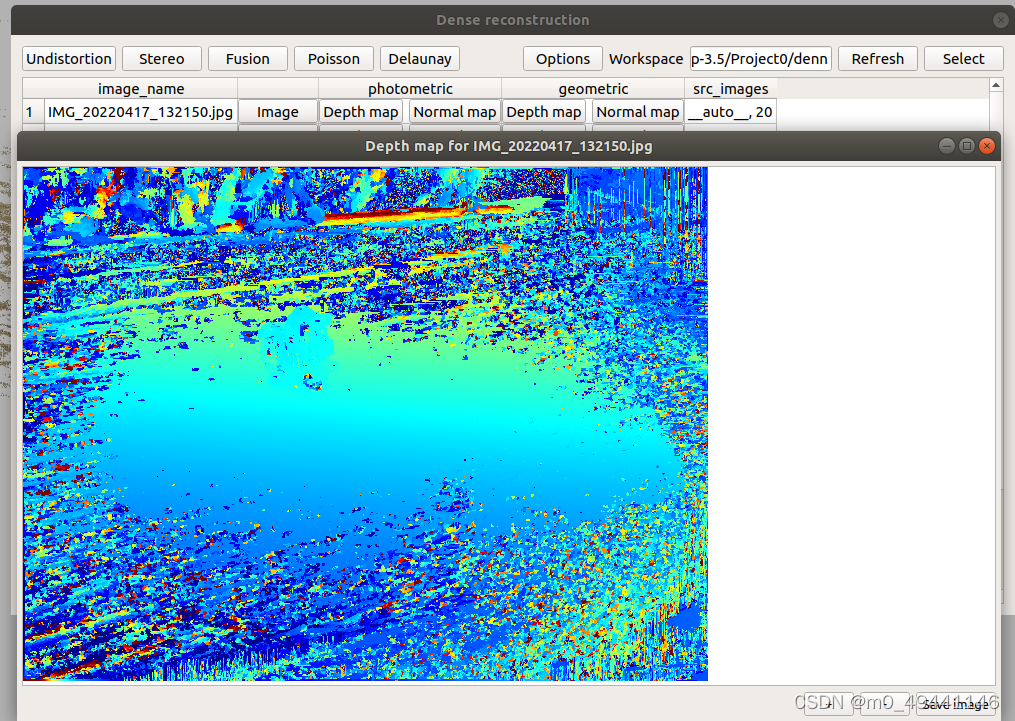
1.photometric光度
Depth map 深度图
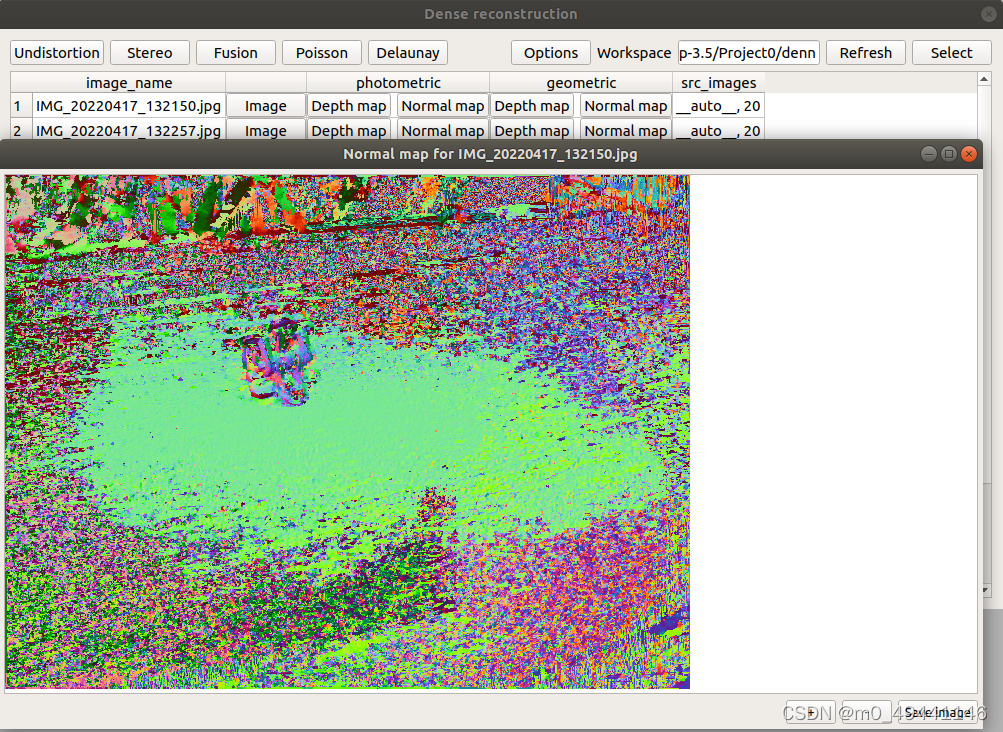
 normal map 法线图
normal map 法线图
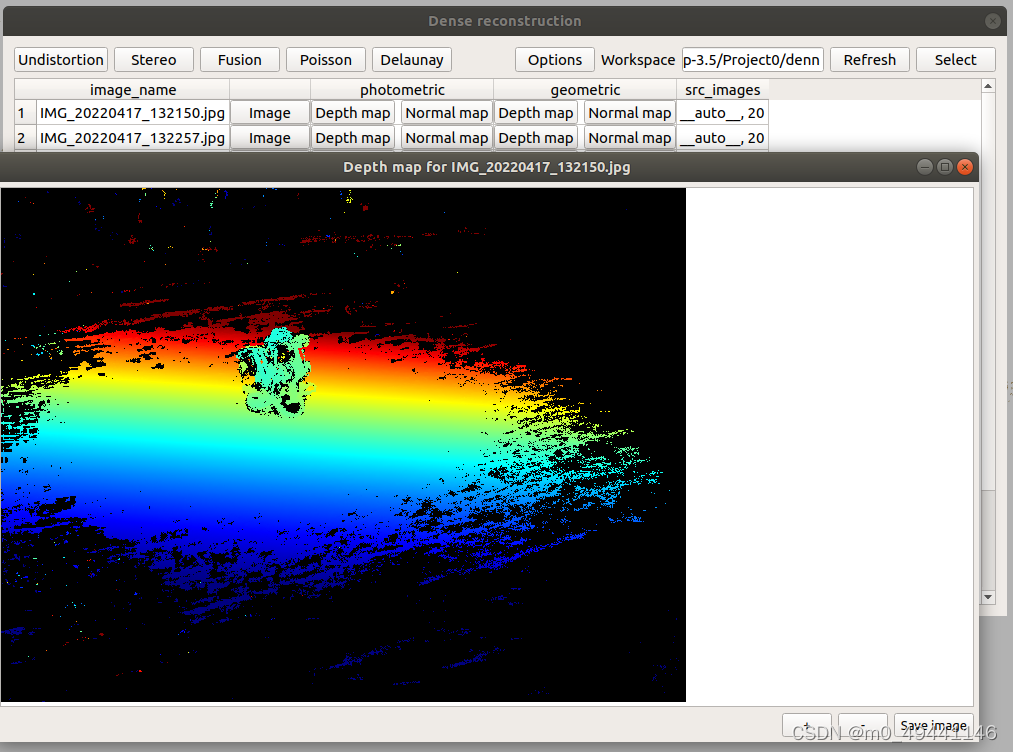
; 2.geometric几何
Depth map 深度图
normal map 法线图
COLMAP可以用于快速三维重建,代码封装良好。但缺点为深度图估计速度过慢,且在深度图估计精度上略低于深度学习的方法。
Original: https://blog.csdn.net/m0_49441146/article/details/124205223
Author: m0_49441146
Title: colmap的使用简介
相关阅读2
Title: java语音识别毕业设计_毕业论文_《语音识别系统的设计与实现》.doc
毕业设计(论文)题目:语音识别系统的设计与实现学院:信息工程与自动化学院专业:通信工程年级: 学生姓名: 指导教师单位:昆明理工大学通信息指导教师姓名: 指导教师职称:讲师
摘要V
AbstractI
前言I
第一章 绪论1
1.1 研究的目的和意义1
1.2 国内外研究历史与现状1
1.3 语音识别存在的问题4
1.4 论文主要研究内容及结构安排5
第二章 语音识别系统7
2.1 语音识别系统简介7
2.1.1 语音识别系统的结构7
2.1.2 语音识别的系统类型8
2.1.3 语音识别的基元选择9
2.2 语音识别系统的应用10
2.2.1 语音识别系统的应用分类10
2.2.2 语音识别系统应用的特点11
2.2.3 语音识别系统的应用所面临的问题12
2.3 语音识别的算法简介13
2.3.1 基于语音学和声学的方法13
2.3.2 模板匹配的方法14
2.3.3神经网络的方法16
第三章 语音识别系统的理论基础18
3.1 语音识别系统的基本组成18
3.2 语音预处理19
3.2.1 预加重19
3.2.2 加窗分帧19
3.2.3 端点检测19
3.2.4 语音特征参数提取20
3.2.5 语音训练和识别23
第四章 特定人孤立词语音识别系统的设计方案28
4.1 基于VQ语音识别系统的模型设计28
4.2 语音识别系统特征参数提取提取29
4.2.1 特征参数提取过程29
4.2.2 特征提取matlab实现31
4.3 VQ训练与识别32
4.3.1 用矢量量化生成码本33
4.3.2 基于VQ的说话人识别34
4.4 设计结果分析36
总结与体会40
谢辞41
参考文献42
本文主要介绍了语音识别系统的基础知识,包括语音识别系统的应用、结构以及算法。重点阐述了语音识别系统的原理以及相关算法,通过参考查阅资料,为recognition systems base 借助MATLAB工具,设计基于VQ码本训练程序和识别程序,识别特定人的语音。
系统主要包括训练和识别两个阶段。实现过程包括对原始语音进行预加重、分帧、加窗等处理,提取语音对应的特征参数。在得到了特征参数的基础上,采用模式识别理论的模板匹配技术进行相似度度量,来进行训练和识别。在进行相似度度量时,采用VQ算法对特征参数序列重新进行时间的对准。
VQ在孤立词语音识别系统中得到很好的应用,特别是有限状态矢量量化技术,对于语音识别更为有效。基于VQ的孤立词语音识别系统具有分类准确,存储数据少,实时响应速度快等综合性能好的特点。
关键字 语音识别 MFCC参数 矢量量化
Abstract
With the appearances of information era based on digital techniques,peopleoften interact with kinds of machines more and more in order to receive,transactand transfer information.Today since computers are widely used,so that it is becoming true that the natural communication between people and machines without using keyboard or mouse,which is the goal pursued by people for a long time.As people have understood physiological mechanics and features of human speech signals,they expect and hope more and more to communicate with computers by speech instead of clicking mouse or typing keyboard.This man-machine communication is an important research problem. Multimedia era intensively requests speech recognition system to put
Original: https://blog.csdn.net/weixin_34223354/article/details/114505939
Author: Jalon Brieuc
Title: java语音识别毕业设计_毕业论文_《语音识别系统的设计与实现》.doc
相关阅读3
Title: 知识图谱学习笔记 4
今天学习使用ChatterBot来做一个问答系统。
关于ChatterBot的安装问题可以看这篇博文。
程序结构如图:
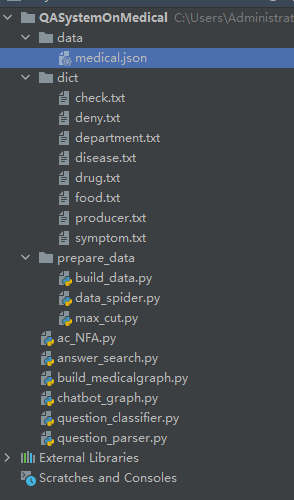
medical.json是网上爬取的一个医药相关的包,然后需要通过运行build_medicalgraph在neo4j服务器上建立一个医药图谱。
首先打开neo4j服务,运用以下指令清空之前的图:
MATCH(n)
DETACH DELETE n
运行build_medicalgraph,这个时候程序报错:
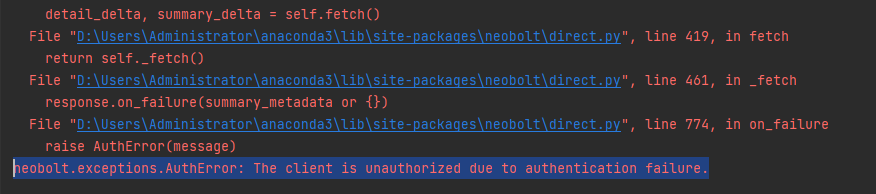
打开neo4j.conf,搜素dbms.security.auth_enabled=false,将前面的井号键#去掉,重新打开neo4j服务,运行build_medicalgraph就可以了。
下面对build_medicalgraph做一个简单的说明。
定义一个MedicalGraph类,创建它的对象,然后用create_graphnodes()函数创建节点,用create_graphrels()函数创建关系。
if __name__ == '__main__':
handler = MedicalGraph()
handler.create_graphnodes()
handler.create_graphrels()
# handler.export_data()
接下来看MedicalGraph类内部:
在构造函数中,定义了需要读取的json文件地址,以及一个本机的neo4j的数据5-8行为默认数据:
def __init__(self):
cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])
self.data_path = os.path.join(cur_dir, 'data/medical.json')
self.g = Graph(
host="127.0.0.1", # neo4j 搭载服务器的ip地址,ifconfig可获取到
http_port=7474, # neo4j 服务器监听的端口号
user="neo4j", # 数据库user name,如果没有更改过,应该是neo4j
password="123456")
下面的代码是对知识图谱的节点的一个建立过程,这里的代码只创建了药、食物、检查结果和疾病信息等,其他的节点添加方式相同:
'''创建知识图谱实体节点类型schema'''
def create_graphnodes(self):
Drugs, Foods, Checks, disease_infos = self.read_nodes()
self.create_diseases_nodes(disease_infos)
self.create_node('Drug', Drugs)
# print(len(Drugs))
self.create_node('Food', Foods)
# print(len(Foods))
self.create_node('Check', Checks)
# print(len(Checks))
return
'''创建知识图谱中心疾病的节点'''
def create_diseases_nodes(self, disease_infos):
count = 0
for disease_dict in disease_infos:
node = Node("Disease", name=disease_dict['name'], desc=disease_dict['desc'],
prevent=disease_dict['prevent'] ,cause=disease_dict['cause'])
self.g.create(node)
count += 1
# print(count)
return
'''建立节点'''
def create_node(self, label, nodes):
count = 0
for node_name in nodes:
node = Node(label, name=node_name)
self.g.create(node)
count += 1
# print(count, len(nodes))
return

json文件中的每个疾病节点结构如图,根据文件结构,我们读取文件的代码大致如下,这段代码大概的操作就是将json文件中的内容读入到相应的节点中:
'''读取文件'''
def read_nodes(self):
# 几类节点
foods = [] # 食物
diseases = [] #疾病
# 构建节点实体关系
rels_noteat = [] # 疾病-忌吃食物关系
rels_doeat = [] # 疾病-宜吃食物关系
count = 0
for data in open(self.data_path, encoding='utf-8'):
disease_dict = {}
count += 1
# print(count)
data_json = json.loads(data)
disease = data_json['name']
disease_dict['name'] = disease
diseases.append(disease)
if 'not_eat' in data_json:
not_eat = data_json['not_eat']
for _not in not_eat:
rels_noteat.append([disease, _not])
foods += not_eat
do_eat = data_json['do_eat']
for _do in do_eat:
rels_doeat.append([disease, _do])
foods += do_eat
recommand_eat = data_json['recommand_eat']
disease_infos.append(disease_dict)
return set(drugs), set(foods), set(diseases), disease_infos
接下来我们创建实体的关系边,在第4行,我们可以看到,Disease是一个节点,Food是另一个节点,他们之间的关系是no_eat:
'''创建实体关系边'''
def create_graphrels(self):
Foods, Diseases, rels_noteat, rels_doeat, rels_recommandeat = self.read_nodes()
self.create_relationship('Disease', 'Food', rels_recommandeat, 'recommand_eat', '推荐食谱')
self.create_relationship('Disease', 'Food', rels_noteat, 'no_eat', '忌吃')
self.create_relationship('Disease', 'Food', rels_doeat, 'do_eat', '宜吃')
创建实体关联边的函数create_relationship结构如下:
'''创建实体关联边'''
def create_relationship(self, start_node, end_node, edges, rel_type, rel_name):
count = 0
# 去重处理
set_edges = []
for edge in edges:
set_edges.append('###'.join(edge))
all = len(set(set_edges))
for edge in set(set_edges):
edge = edge.split('###')
p = edge[0]
q = edge[1]
query = "match(p:%s),(q:%s) where p.name='%s'and q.name='%s' create (p)-[rel:%s{name:'%s'}]->(q)" % (
start_node, end_node, p, q, rel_type, rel_name)
try:
self.g.run(query)
count += 1
# print(rel_type, count, all)
except Exception as e:
print(e)
return
将上述程序运行后,即可以将json文件整个加载到neo4j服务器上,因为json文件比较大,所以这个过程非常慢。
之后可以再写一个文件做一个应答系统,主要代码如下,这个程序主要是构造了一个类,分别完成了对提出问题的解析,和对回答的检索:
def __init__(self):
self.classifier = QuestionClassifier()
self.parser = QuestionPaser()
self.searcher = AnswerSearcher()
def chat_main(self, question):
answer = '您好,我是医药智能助理“小医”,希望可以帮到您。'
res_classify = self.classifier.classify(question)
if not res_classify:
return answer
res_sql = self.parser.parser_main(res_classify)
final_answers = self.searcher.search_main(res_sql)
if not final_answers:
return answer
else:
return '\n'.join(final_answers)
Original: https://blog.csdn.net/m0_60976461/article/details/119729628
Author: 落霞孤雾
Title: 知识图谱学习笔记 4