
普通麦克风是指单个的麦克风。或者说多个麦克风但是这些麦克风之间没有加入处理电路或芯片,
那么这些也是普通麦克风。
麦克风阵列是多个麦克风按一定方式排列在一起,由于加入芯片,像昆虫的复眼一个能够精确定位,
可以通过芯片,消除环境中各种干扰,比如回声,这就大提高了在恶劣环境中的音色识别性能,
也可以降低噪音,主要用在人工智能上,实现远距离识别有用信号,也就是提高清晰度。现版在在远程会议,
刑侦,庭审,录音笔上都有这种麦克风阵列。
当前成熟的麦克风阵列的主要包括:讯飞的2麦方案、4麦阵列和6麦阵列方案,思必驰的6+1麦阵列方案,云知声(科胜讯)的2麦方案,以及声智科技的单麦、2麦阵列、4(+1)麦阵列、6(+1)麦阵列和8(+1)麦阵列方案,其他家也有麦克风阵列的硬件方案,但是缺乏前端算法和云端识别的优化。由于各家算法原理的不同,有些阵列方案可以由用户自主选用中间的麦克风,这样更利于用户进行ID设计。其中,2个以上的麦克风阵列,又分为线形和环形两种主流结构,而2麦的阵列则又有Broadside和Endfire两种结构。
如此众多的组合,那么厂商该如何选择这些方案呢?首先还是要看产品定位和用户场景。若定位于追求性价比的产品,其实就不用考虑麦克风阵列方案,就直接采用单麦方案,利用算法进行优化,也可实现噪声抑制和回声抵消,能够保证近场环境下的语音识别率,而且成本绝对要低很多。至于单麦语音识别的效果,可以体验下采用单麦识别算法的360儿童机器人。
但是若想更好地去除部分噪声,可以选用2麦方案,但是这种方案比较折衷,主要优点就是ID设计简单,在通话模式(也就是给人听)情况下可以去除某个范围内的噪音。但是语音识别(也就是给机器听)的效果和单麦的效果却没有实质区别,成本相对也比较高,若再考虑语音交互终端必要的回声抵消功能,成本还要上升不少。2麦方案最大的弊端还是声源定位的能力太差,因此大多是用在手机和耳机等设备上实现通话降噪的效果。这种降噪效果可以采用一个指向性麦克风(比如会议话筒)来模拟,这实际上就是2麦的Endfire结构,也就是1个麦克风通过原理设计模拟了2个麦克风的功能。指向性麦克风的不方便之处就是ID设计需要前后两个开孔,这很麻烦,例如叮咚1代音箱采用的就是这种指向性麦克风方案,因此采用了周边一圈的悬空设计。
若希望产品能适应更多用户场景,则可以类似亚马逊Echo一样直接选用4麦以上的麦克风阵列。这里简单给个参考,机器人一般4个麦克风就够了,音箱建议还是选用6个以上麦克风,至于汽车领域,最好是选用其他结构形式的麦克风阵列,比如分布式阵列。
多个麦克风阵列之间的成本差异现在正在变小,估计明年的成本就会相差不大。这是趋势,新兴的市场刚开始成本必然偏高,但随着技术进步和规模扩张,成本会快速走低,因此新兴产品在研发阶段倒是不需要太过纠结成本问题,用户体验才是核心的关键。
Original: https://blog.csdn.net/peijian1998/article/details/109115998
Author: 红尘-有梦
Title: 普通麦克风和多阵列麦克风的区别
相关阅读1
Title: win10+RTX3050ti+TensorFlow+cudn+cudnn配置深度学习环境
避坑1:RTX30系列显卡不支持cuda11.0以下版本,具体上限版本可自行查阅:
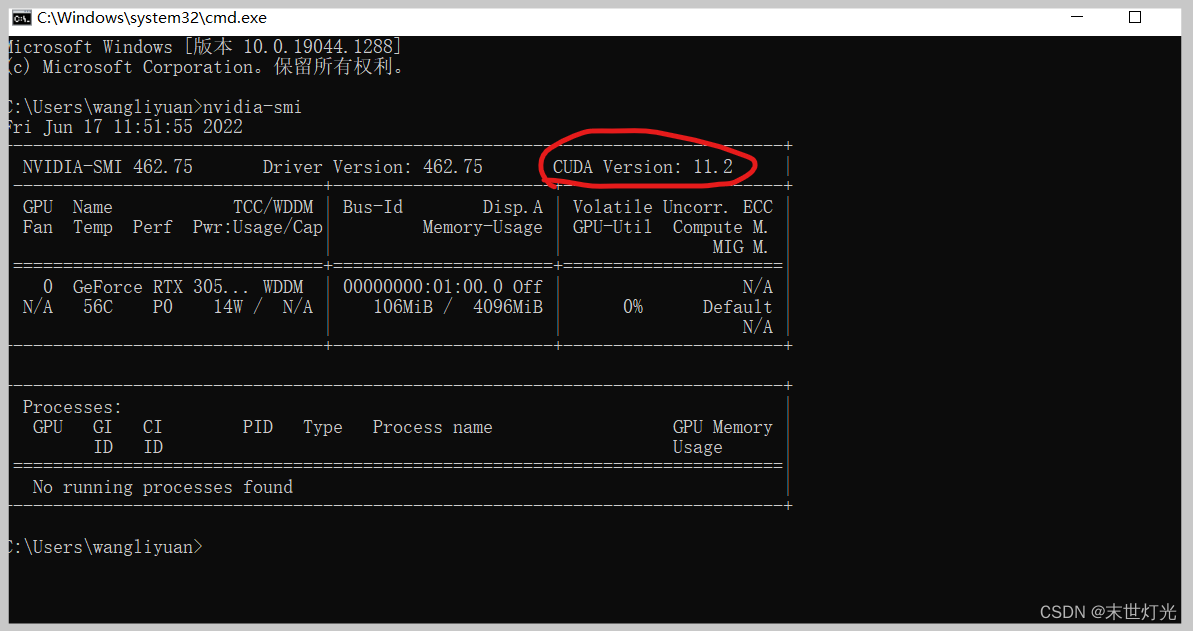
方法一,在cmd中输入nvidia-smi查看
方法二:
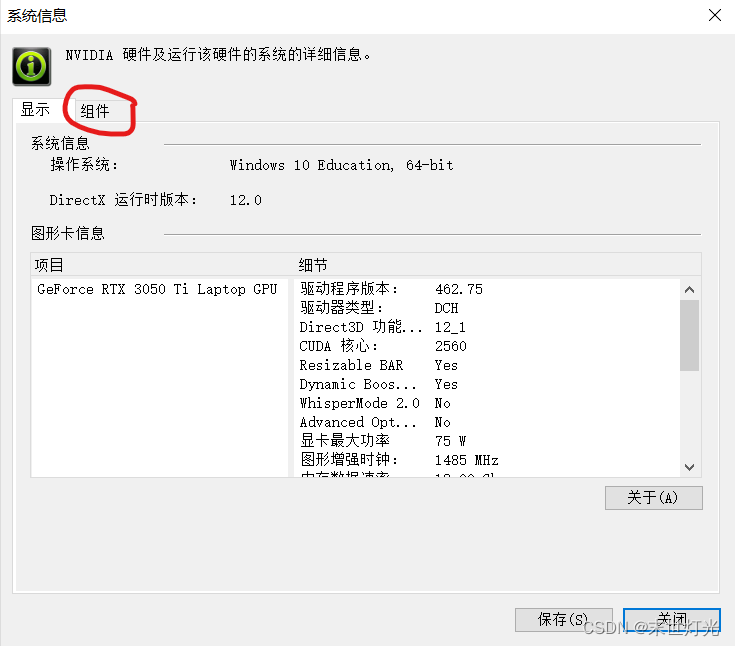
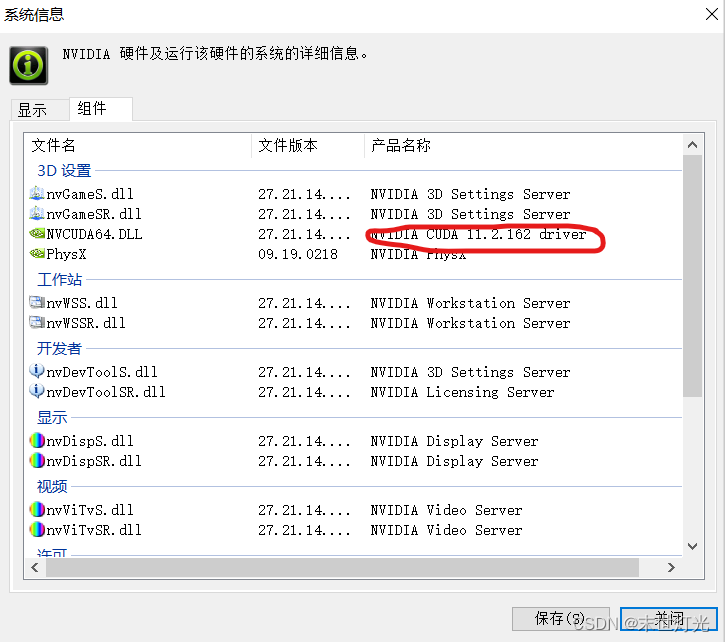
由此可以看出本电脑最高适配cuda11.2.1版本;
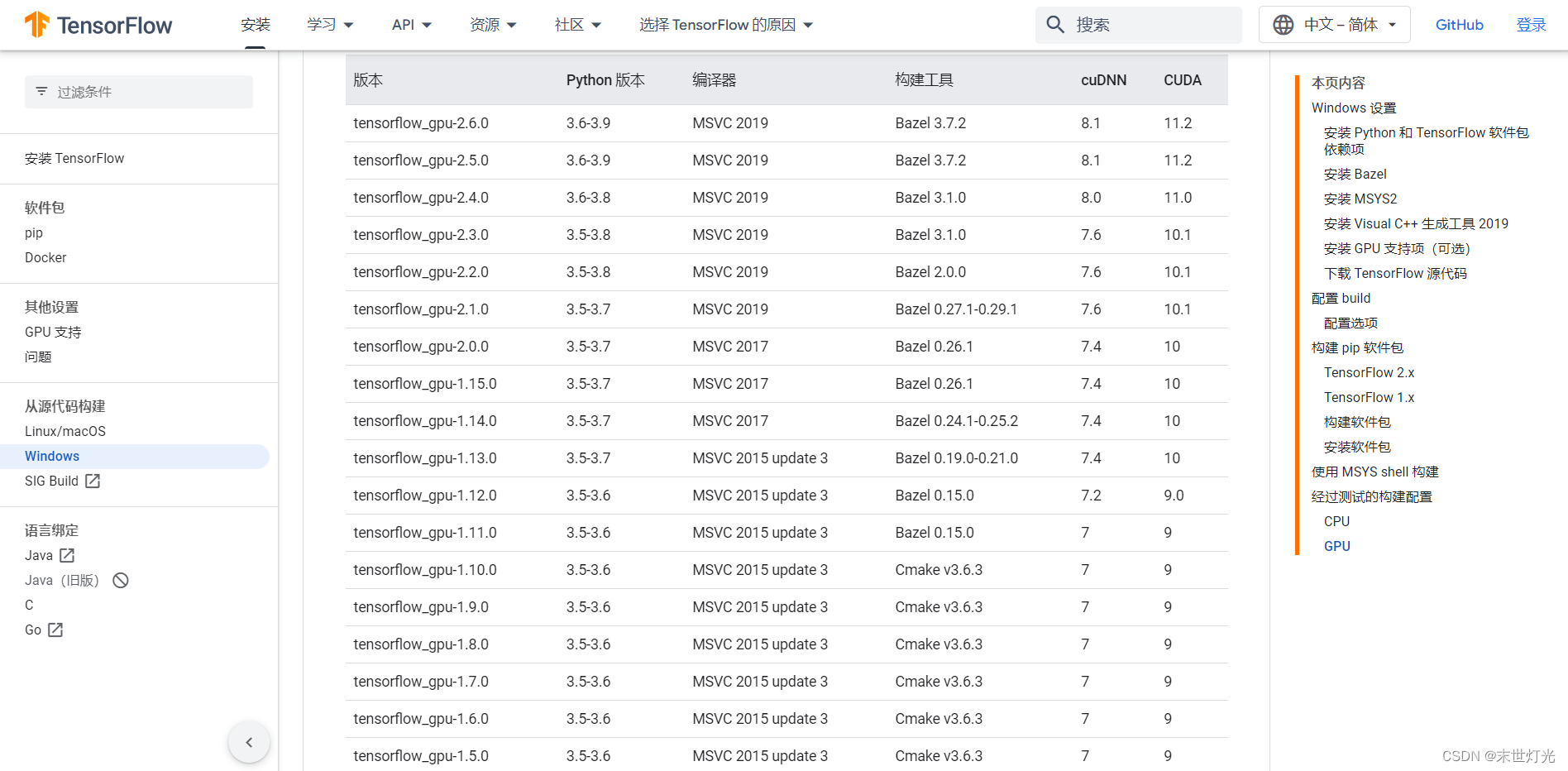
注意需要版本适配,这里我们选择TensorFlow-gpu = 2.5,cuda=11.2.1,cudnn=8.1,python3.7
接下来可以下载cudn和cundnn:
官网:https://developer.nvidia.com/cuda-toolkit-archive
下载对应版本exe文件打开默认安装就可;
验证是否安装成功:
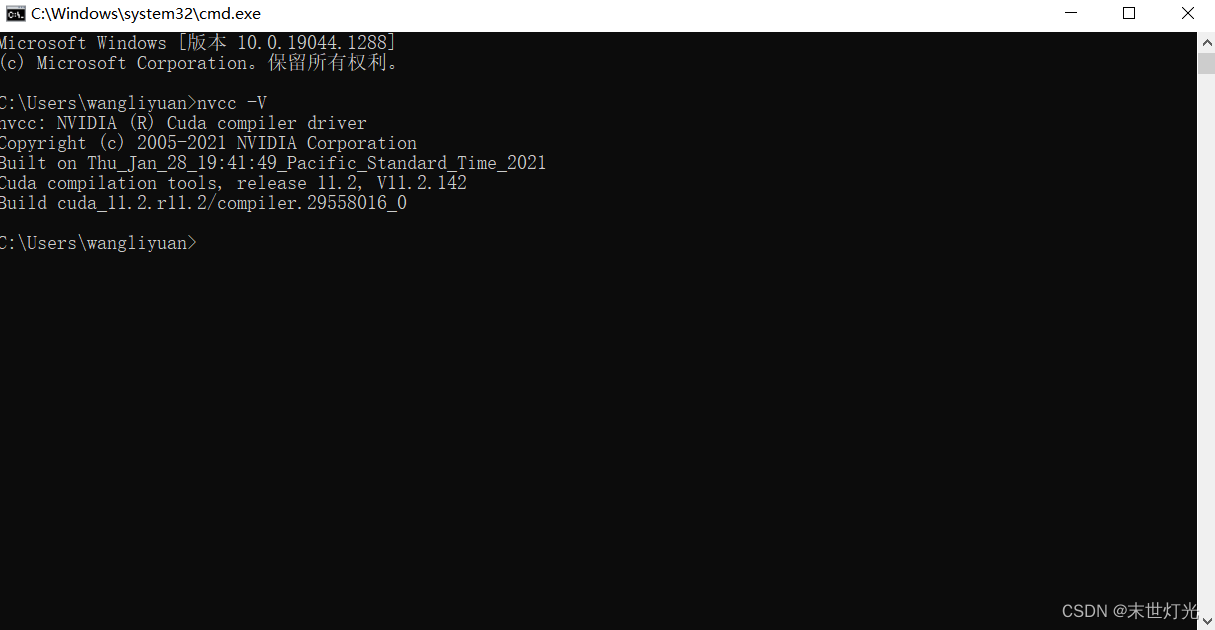
官网:cuDNN Archive | NVIDIA Developer
把下载文件进行解压把bin+lib+include文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2文件下;
进入环境变量设置(cuda会自动设置,如果没有的补全):
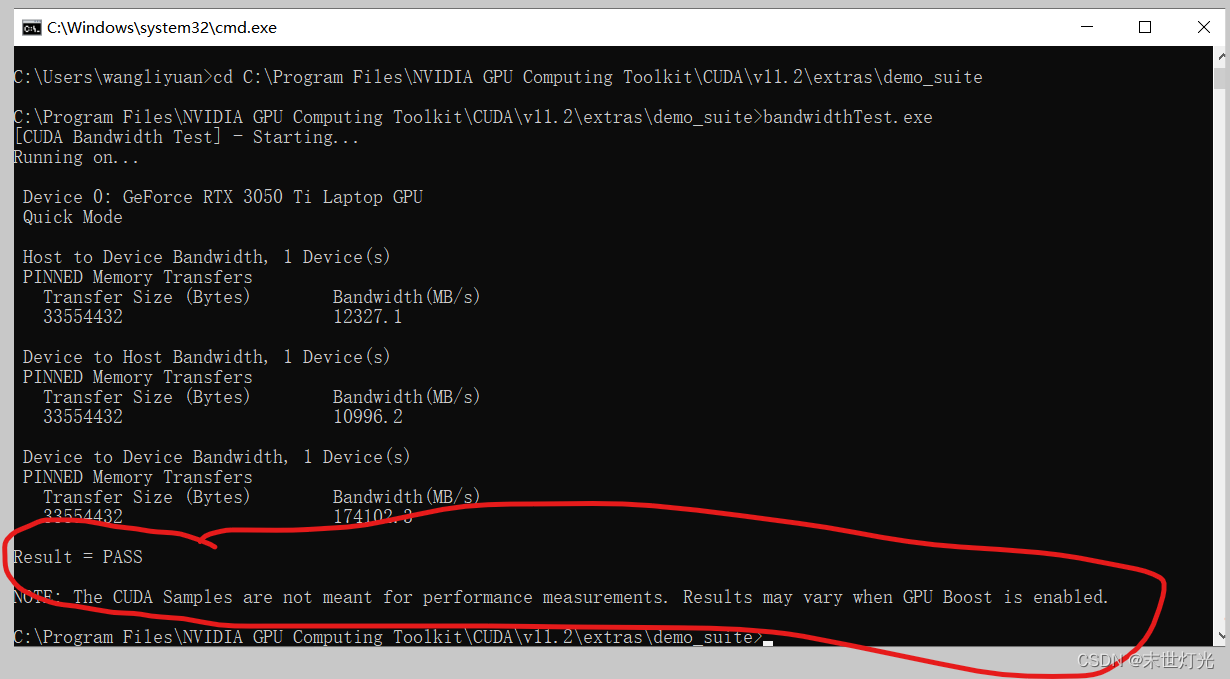
查看是否安装成功:
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.2\extras\demo_suite
bandwidthTest.exe
安装tensorflow-gpu:
pip install tensorflow-gpu==2.5
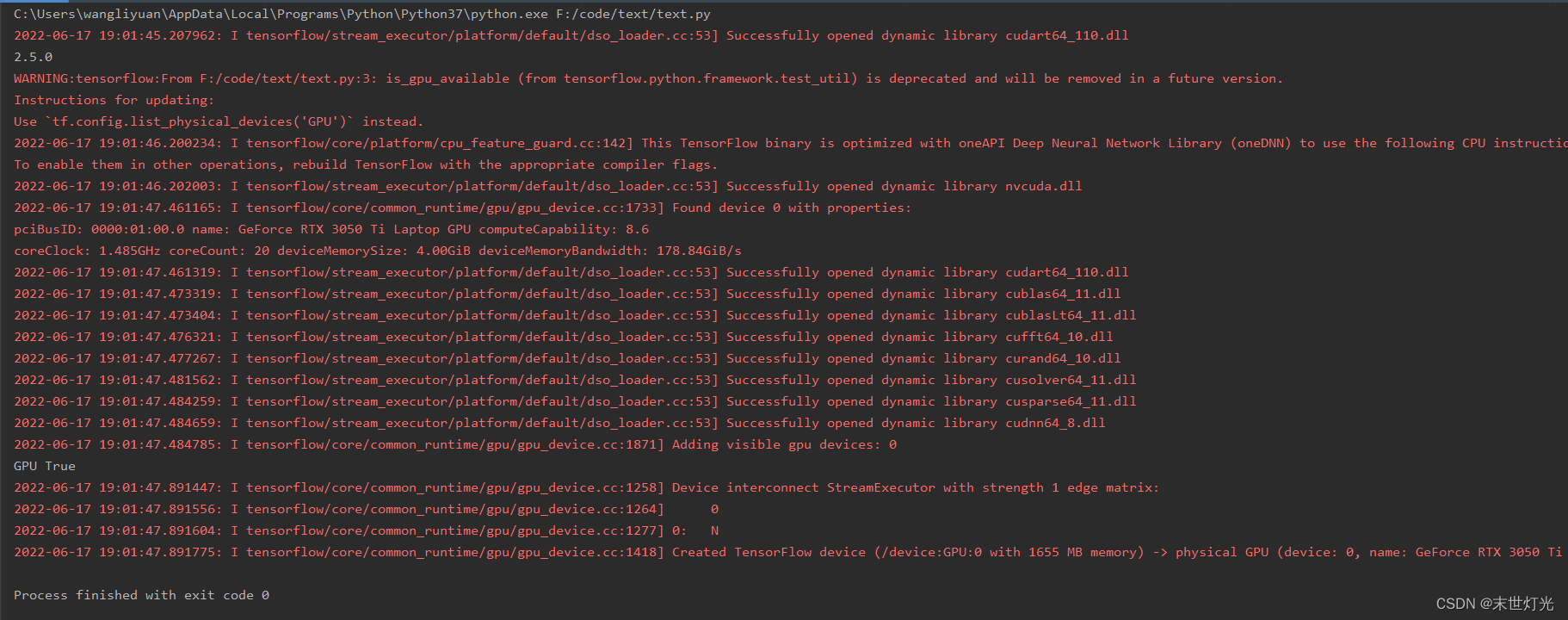
最后我们找相关程序来验证一下:
第一步:
import tensorflow as tf
print(tf.__version__)
print('GPU', tf.test.is_gpu_available())
第二步:
_*_ coding=utf-8 _*_
'''
@author: crazy jums
@time: 2021-01-24 20:55
@desc: 添加描述
'''
指定GPU训练
import os
os.environ["CUDA_VISIBLE_DEVICES"]="0" ##表示使用GPU编号为0的GPU进行计算
import numpy as np
from tensorflow.keras.models import Sequential # 采用贯序模型
from tensorflow.keras.layers import Dense, Dropout, Conv2D, MaxPool2D, Flatten
from tensorflow.keras.datasets import mnist
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import TensorBoard
import time
def create_model():
model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu', input_shape=[28, 28, 1])) # 第一卷积层
model.add(Conv2D(64, (5, 5), activation='relu')) # 第二卷积层
model.add(MaxPool2D(pool_size=(2, 2))) # 池化层
model.add(Flatten()) # 平铺层
model.add(Dropout(0.5))
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
def compile_model(model):
model.compile(loss='categorical_crossentropy', optimizer="adam", metrics=['acc'])
return model
def train_model(model, x_train, y_train, batch_size=32, epochs=10):
tbCallBack = TensorBoard(log_dir="model", histogram_freq=1, write_grads=True)
history = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, shuffle=True, verbose=2,
validation_split=0.2, callbacks=[tbCallBack])
return history, model
if __name__ == "__main__":
import tensorflow as tf
print(tf.__version__)
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
(x_train, y_train), (x_test, y_test) = mnist.load_data() # mnist的数据我自己已经下载好了的
print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test))
x_train = np.expand_dims(x_train, axis=3)
x_test = np.expand_dims(x_test, axis=3)
y_train = to_categorical(y_train, num_classes=10)
y_test = to_categorical(y_test, num_classes=10)
print(np.shape(x_train), np.shape(y_train), np.shape(x_test), np.shape(y_test))
model = create_model()
model = compile_model(model)
print("start training")
ts = time.time()
history, model = train_model(model, x_train, y_train, epochs=2)
print("start training", time.time() - ts)
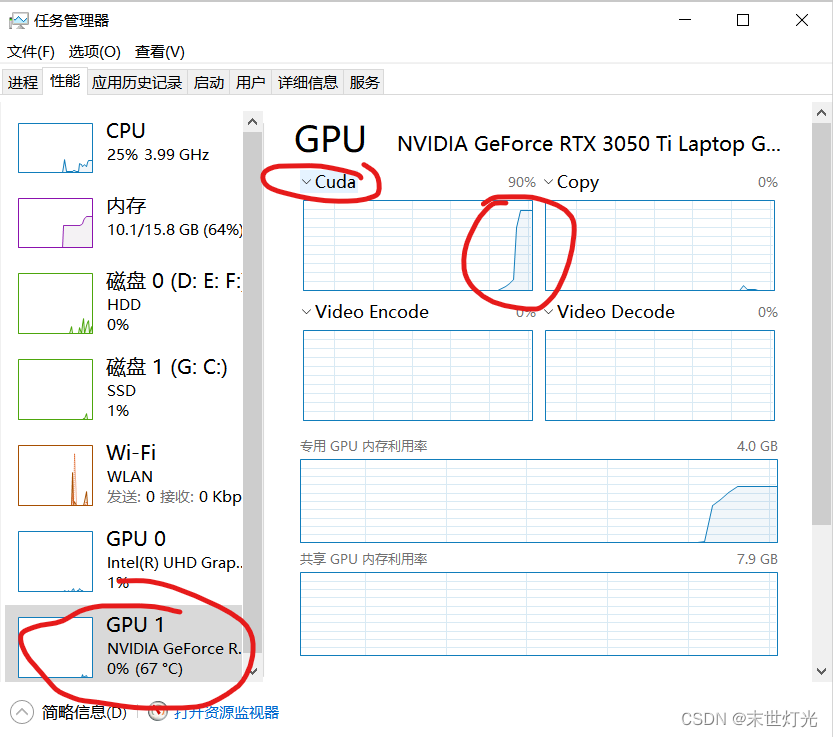
验证成功。

这些资料请关注微信公众号:小王搬运工,后台回复22617,获取百度网盘链接。

Original: https://blog.csdn.net/qq_25368751/article/details/125331026
Author: 末世灯光
Title: win10+RTX3050ti+TensorFlow+cudn+cudnn配置深度学习环境
相关阅读2
Title: 基于GMM-HMM的语音识别系统
本文介绍GMM-HMM语音识别系统,虽然现在主流端到端系统,但是传统识别系统的学习是很有必要的。阅读本文前,需要了解语音特征提取、混合高斯模型GMM、隐马尔科夫模型HMM的基础知识(可以参考我的前几篇文章)。笔者能力有限,如有错误请指正!
GMM-HMM语音识别系统的框架:
语音识别的几个概念:
- 对齐:音频和文本的对应关系
- 训练:已知对齐,迭代计算模型参数
- 解码:根据训练得到的模型参数,从音频推出文本
基于孤立词的GMM-HMM语音识别
问题简化,我们考虑(0-9)数字识别。整体思路:
- 训练阶段,对于每个词用不同的音频作为训练样本,构建一个生成模型P ( X ∣ W ) P(X|W)P (X ∣W ),W是词,X是音频特征(MFCC、Fbank参考这篇博客)
- 解码阶段:给定一段音频特征,经过训练得到的模型,看哪个词生成这段音频的概率最大,取最大的那个词作为识别结果。
X t e s t \mathbf{X}_{test}X t e s t 测试特征,P w ( X ) P_w(\mathbf{X})P w (X )是词w w w的概率模型,v o c a b vocab v o c a b是词表:
a n s w e r = arg max w ∈ vocab P w ( X test ) answer =\underset{w \in \text { vocab }}{\arg \max } P_{w}\left(\boldsymbol{X}_{\text {test }}\right)a n s w e r =w ∈vocab ar g max P w (X test )
假设我们给每个词建立了一个模型:P o n e ( X ) , P t w o ( X ) . . . P_{one}(X),P_{two}(X)...P o n e (X ),P t w o (X )...,计算在每个词上的概率,选择所有词中概率最大的词作为识别结果。这样会有几个问题:用什么方法进行建模:DNN,GMM?这些够可以进行建模,但是语音任务的特点是 序列性,不定长性,很难使用DNN、GMM直接进行建模。为了解决这些问题,我们可以利用HMM来进行序列建模。
语音是一个序列,P w ( X ) P_w(X)P w (X )可以用HMM的概率问题来描述,并且其中的观测是连续概率密度分布,我们可以为每个词建立一个GMM-HMM模型。
语音识别中的GMM,采用 对角GMM(协方差为对角阵),因为一般我们使用MFCC特征,MFCC特征各维之间已经做了去相关处理,各维之间相互独立,直接使用对角阵就可以描述,而且对角GMM参数量小。
语音识别中的HMM,采用3状态,左右模型的HMM:
- 为什么采用3状态?这是前人大量实验给出的经验值;
- 左右模型的HMM:对于每个状态,它只能跳转到自身或者下一个状态。类似于人的发音过程,连续不可逆。
HMM、GMM语音识别中如何结合?
对于每个状态有一个GMM模型,对于每个词有一个HMM模型,当一段语音输入后,根据Viterbi算法得到一个序列在GMM-HMM上的概率,然后通过Viterbi回溯得到每帧属于HMM的哪个状态(对齐)。
GMM-HMM模型参数:
- 初始化参数(左右HMM):这参数没必要
- 转移参数:自跳或者跳向下一个(两个参数)
- 观测参数:混合系数、均值、方差
如何初始化GMM-HMM模型的参数?把语音进行均等切分,给每个状态分配对应的特征,然后去估计初始化的参数。
Viterbi和Baum-Welch学习算法的详细内容参考我之前的文章。
输入:各个词的GMM-HMM模型,未知的测试语音特征。
输出:哪个词。
主要关键点:对所有的词,如果计算P w ( X t e s t ) P_w(X_{test})P w (X t e s t )。可以通过:前向后算法,或者Viterbi算法(可以回溯到最优的状态序列),一般采用Viterbi算法。
解码主要在图上做,我们现在看one two两个数字识别问题:
构建HMM模型的拓扑图,下图是紧凑的解码图:
通过Viterbi算法,找过最优的路径得到最终输出的词。那么如果我们需要对连续的多个词识别,需要如何建模?
我们只需要再拓扑图上加一个循环连接,对于孤立词,如果达到了识别状态就结束了,对于连续词,如果达到了结束状态,就继续识别下一个词。每个HMM内部还是采用Viterbi算法,在每个时刻对于每个状态选择一条最大概率的路径。因为是并行的,在某个时刻,可能同时会有多个词达到结束状态,分别对应着一段路径,然后又要同时进行下一个词的识别,那么为了避免多余的计算,采用和Viterbi一样的思路,只选取最大概率的路径,扔掉其他。
基于单音素的GMM-HMM语音识别系统
孤立词系统的缺点:
- 建模单元数、计算量和词典大小成正比
- OOV(out of Vocabulary)问题,训练中没有这个词,测试中存在这个词;
- 词的状态数对每个词不用,长词使用的状态数更多
为了克服上边的问题,采用音素建模。每个音素使用3状态结构:
简化问题:假设一句话中包含一个单词,比如one(W AA N),我们可以很容易得到三个音素的HMM状态图,将状态图进行平滑连接得到one的一整个HMM,然后进行和上述孤立词相同的过程。
问题:如果一句话中包含多个单词?
这个采用和上述相同的方法,加入循环结构,当到达结束状态时进行下一个词的识别。
基于三音素的GMM-HMM语音识别系统
单音素缺点:
- 建模单元数少,一般英文系统的音素数30-60个,中文的音素数100个左右;
- 音素的发音受上下文影响,比如:连读、吞音。
可以考虑音素的上下文,一般考虑前一个/后一个,称为三音素,表示为A-B+C。比如:KEEP K IY P => #-K+IY, K-IY+P, IY-P+#。
问题1:假设有N个音素,一共有多少个三音素?N 3 N^3 N 3
问题2:有的三音素训练数据少或者不存在,怎么办?
问题3:有的三音素在训练中不存在,但在测试中有怎么办?
问题2和问题3通过参数共享解决,下文将介绍决策树。
共享可以在不同层面:
- 共享高斯模型:所有状态都用同样的高斯模型,只是混合权重不一样;
- 共享状态:允许不同的HMM模型使用一些相同的状态;
- 共享模型:相似的三音素使用同样的HMM模型。
笔者主要介绍共享状态,可以采用自顶向下的拆分,建立决策树来聚类。
决策树是一个二叉树,每个非叶子节点上会有一个问题,叶子节点是一个绑定三音素的集合。绑定的粒度为状态(A-B+C和A-B+D的第1个状态绑定在一起,并不表示其第二第三个状态也要绑定在一起),也就是B的每个状态都有一颗小的决策树。
问题集
常见的有:
-
元音 AA AE AH AO AW AX AXR AY EH ER ...
-
爆破音 B D G P T K
- 鼻音 M N NG
- 摩擦音 CH DH F JH S SH TH V Z ZH
- 流音 L R W Y
问题集的构建:语言学家定义,Kaldi中通过自顶向下的聚类自动构建问题集。
初始条件类似图中的根节点,"-zh+",从问题集中选择合适的问题,分裂该节点,使相近的三音素分类到相同的节点上。假设根节点所有三音素对应的特征服从一个多元单高斯分布,可以计算出该单高斯分布的均值和方差,则可以计算出该节点任意一个特征在高斯上的似然。
模型:假设其服从单高斯分布,并且各维独立,也就是对角GMM
Pr [ x ] = 1 ∏ k = 1 N ( 2 π σ k 2 ) 1 / 2 ∏ k = 1 N exp ( − 1 2 ( x k − μ k ) 2 σ k 2 ) \operatorname{Pr}[x]=\frac{1}{\prod_{k=1}^{N}\left(2 \pi \sigma_{k}^{2}\right)^{1 / 2}} \prod_{k=1}^{N} \exp \left(-\frac{1}{2} \frac{\left(x_{k}-\mu_{k}\right)^{2}}{\sigma_{k}^{2}}\right)P r [x ]=∏k =1 N (2 πσk 2 )1 /2 1 k =1 ∏N exp (−2 1 σk 2 (x k −μk )2 )
似然
L ( S ) = − 1 2 ∑ i = 1 m [ ∑ k = 1 N log ( 2 π σ k 2 ) + ∑ k = 1 N ( x i k − μ k ) 2 σ k 2 ] = − 1 2 [ m ∑ k = 1 N log ( 2 π σ k 2 ) + m ∑ k = 1 N σ k 2 σ k 2 ] = − 1 2 [ m N ( 1 + log ( 2 π ) ) + m ∑ k = 1 N log ( σ k 2 ) ] \begin{aligned} L(S) &=-\frac{1}{2} \sum_{i=1}^{m}\left[\sum_{k=1}^{N} \log \left(2 \pi \sigma_{k}^{2}\right)+\sum_{k=1}^{N} \frac{\left(x_{i k}-\mu_{k}\right)^{2}}{\sigma_{k}^{2}}\right] \ &=-\frac{1}{2}\left[m \sum_{k=1}^{N} \log \left(2 \pi \sigma_{k}^{2}\right)+m \sum_{k=1}^{N} \frac{\sigma_{k}^{2}}{\sigma_{k}^{2}}\right] \ &=-\frac{1}{2}\left[m N(1+\log (2 \pi))+m \sum_{k=1}^{N} \log \left(\sigma_{k}^{2}\right)\right] \end{aligned}L (S )=−2 1 i =1 ∑m [k =1 ∑N lo g (2 πσk 2 )+k =1 ∑N σk 2 (x i k −μk )2 ]=−2 1 [m k =1 ∑N lo g (2 πσk 2 )+m k =1 ∑N σk 2 σk 2 ]=−2 1 [m N (1 +lo g (2 π))+m k =1 ∑N lo g (σk 2 )]
假设通过某个问题将该节点的三音素对应的特征分成两部分(l 和 r),则这两部分的似然和为:
L ( S l ) + L ( S r ) = − 1 2 m N ( 1 + log ( 2 π ) ) − 1 2 [ m l ∑ k = 1 N log ( σ l k 2 ) + m r ∑ k = 1 N log ( σ r k 2 ) ] L\left(S_{l}\right)+L\left(S_{r}\right)=-\frac{1}{2} m N(1+\log (2 \pi))-\frac{1}{2}\left[m_{l} \sum_{k=1}^{N} \log \left(\sigma_{l k}^{2}\right)+m_{r} \sum_{k=1}^{N} \log \left(\sigma_{r k}^{2}\right)\right]L (S l )+L (S r )=−2 1 m N (1 +lo g (2 π))−2 1 [m l k =1 ∑N lo g (σl k 2 )+m r k =1 ∑N lo g (σr k 2 )]
分裂前后的似然变化(增益)为:
L ( S l ) + L ( S r ) − L ( S ) L\left(S_{l}\right)+L\left(S_{r}\right)-L(S)L (S l )+L (S r )−L (S )
似然增益越大,说明分裂后两部分数据之间的差异越大,则应该使用两个单独的GMM分别建模,则选择似然增益最大的问题进行划分(最优问题)。根节点一份为2后,递归执行该算法直至达到一定终止条件,通常是分裂达到一定数量的叶子节点或者似然增益已经低于一定阈值。
基于GMM-HMM语音识别系统流程
问题:为什么先做单音素训练?
通过单音素模型上Viterbi算法得到与输入对应的最佳状态序列(对齐)。
参考:
https://blog.csdn.net/Magical_Bubble/article/details/90408095
https://zhuanlan.zhihu.com/p/63753017Original: https://blog.csdn.net/weixin_39529413/article/details/117367913
Author: 栋次大次
Title: 基于GMM-HMM的语音识别系统
相关阅读3
Title: 论文阅读《LoFTR: Detector-Free Local Feature Matching with Transformers》
论文地址:https://arxiv.org/pdf/2104.00680.pdf
代码地址:https://github.com/zju3dv/LoFTR
背景
本文提出了一种新的局部图像特征匹配方法,通过先在粗层次上建立像素级密集匹配,然后在更细的层次上进行细化,并利用transformer的自注意层和交叉注意力层来获取基于两幅图像的特征描述符。本文的创新点在于Transformer提供的全局感受野使得该方法能够在低纹理区域产生密集匹配。
模型结构

基于特征检测器的检测方法可以减少进行匹配时的搜索空间,而在无纹理或重复纹理地区,特征检测器难以检测出有效的特征,这回极大影响后续的匹配过程的效率;

无检测器(Detector free)的方法通过建立像素级别的密集匹配来解决这个问题,通过从密集匹配中保留置信度较高的匹配来避免特征检测。然而使用CNN来提取的密集特征的感受野有限,在无纹理区域的效果较差。而人类在这些区域会同时考虑局部信息与全局信息;
基于此,本文提出一个Local Feature Transformer(LoFTR):先在低分辨率的特征图上进行密集匹配,然后保留置信度较高的匹配,然后将其细化到高分率的密集匹配;同时使用自注意力与交叉注意力来得到更加具有特异性的匹配特征;LoFTR可以在弱纹理、运动模糊与重复纹理区域产生较高质量的匹配;
; 局部特征提取
使用权值共享的FPN结构的CNN特征提取模块从两幅图像中得到 1 8 \frac{1}{8}8 1 原图大小的低分辨率的特征图 F ~ A 与 F ~ B \tilde{F}^{A} 与 \tilde{F}^{B}F ~A 与F ~B,同时得到 1 2 \frac{1}{2}2 1 原图大小的高分辨率的特征图 F ^ A 与 F ^ B \hat{F}^{A} 与 \hat{F}^{B}F ^A 与F ^B ;CNN的局部空间不变性较适合用于局部特征提取;
局部特征转换(LoFTR)模块
得到低分辨率的特征图 F ~ A 与 F ~ B \tilde{F}^{A} 与 \tilde{F}^{B}F ~A 与F ~B 后,将其与位置送进局部特征转换模块得到具有特异性的匹配特征F ~ t r A 与 F ~ t r B \tilde{F}{t r}^{A} 与\tilde{F}{t r}^{B}F ~t r A 与F ~t r B ,局部特征转换模块包含 位置编码模块、 自注意力与交叉注意力特征增强模块;
位置编码模块
受到DETR的启发,采用sin函数进行位置编码,将位置信息编码成特定的向量,与输入的 F ~ A 与 F ~ B \tilde{F}^{A} 与 \tilde{F}^{B}F ~A 与F ~B 展开后的特征进行融合,融合后的特征既同时包含位置信息与深度特征信息;
自注意力模块与交叉注意力模块
此处不再赘述,可以参考博主上一篇博客"论文阅读《SuperGlue: Learning Feature Matching with Graph Neural Networks》"中的GNN模块的解读,此处简单讲讲Transformer;

Transformer:
Transformer 由顺序连接的注意力层组成,其核心是注意力模块的使用,Transformer的输入为query、key、value,与数据检索的过程类似,数据库的的数据为value,对于每一条数据 V 其对应的索引键值为向量K,先由查询向量与键值向量求相似度,再由相似矩阵来对value中的V向量加权求和,得到最后的输出,这个过程也被称为图神经网络中的"消息传递"。如式1所示:
Attention ( Q , K , V ) = softmax ( Q K T ) V (1) \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(Q K^{T}\right) V\tag{1}A t t e n t i o n (Q ,K ,V )=s o f t m a x (Q K T )V (1 )

Linear Transformer:
若查询向量 Q 与键值 K 均拥有N条,且每个特征的长度为 D ,则求相似性矩阵时候的计算复杂度为 O ( N 2 ) O(N^{2})O (N 2 ),这时候需要使用Linear Transformer来降低计算相似度,将计算复杂度降低到了 O ( N ) O(N)O (N ), 其中 e l u ( . ) elu(.)e l u (.) 表示核函数:
s i m ( Q , K ) = ϕ ( Q ) ⋅ ϕ ( K ) T ϕ ( . ) = e l u ( . ) + 1 (2) sim(Q, K) = \phi(Q) \cdot \phi(K)^{T}\ \ \ \phi(.)=elu(.)+1 \tag{2}s i m (Q ,K )=ϕ(Q )⋅ϕ(K )T ϕ(.)=e l u (.)+1 (2 )

; 粗粒度(低分辨率)匹配
经过L层自注意力模块与交叉注意力模迭代特征增强,得到的输出匹配特征可以用于匹配,可以参考SuperGlue中的将其转换为可微的最优传输问题来处理,也可以使用dual-softmax来处理,由输出向量计算匹配得分矩阵:
S ( i , j ) = 1 τ ⋅ ⟨ F ~ t r A ( i ) , F ~ t r B ( j ) ⟩ (3) \mathcal{S}(i, j)=\frac{1}{\tau} \cdot\left\langle\tilde{F}{t r}^{A}(i), \tilde{F}{t r}^{B}(j)\right\rangle\tag{3}S (i ,j )=τ1 ⋅⟨F ~t r A (i ),F ~t r B (j )⟩(3 )
若采用求解最优传输的方式来进行匹配,则依然参考博主上一篇博客"论文阅读《SuperGlue: Learning Feature Matching with Graph Neural Networks》"中的 最优匹配模块的解读,再次不再赘述;
此外,还可以在得分矩阵 S 的两个维度上进行softmax得到匹配概率矩阵 P c \mathcal{P}{c}P c
P c ( i , j ) = softmax ( S ( i , ⋅ ) ) j ⋅ softmax ( S ( ⋅ , j ) ) i (4) \mathcal{P}{c}(i, j)=\operatorname{softmax}(\mathcal{S}(i, \cdot)){j} \cdot \operatorname{softmax}(\mathcal{S}(\cdot, j)){i}\tag{4}P c (i ,j )=s o f t m a x (S (i ,⋅))j ⋅s o f t m a x (S (⋅,j ))i (4 )
筛选匹配对:
基于置信度来筛选置信度高于 θ c \theta_{c}θc 的匹配点,并使用相互最近邻准则(左右一致性检查+最优与次优有一定距离)来剔除外点,如式5所示:
M c = { ( i ~ , j ~ ) ∣ ∀ ( i ~ , j ~ ) ∈ MNN ( P c ) , P c ( i ~ , j ~ ) ≥ θ c } (5) \mathcal{M}{c}=\left{(\tilde{i}, \tilde{j}) \mid \forall(\tilde{i}, \tilde{j}) \in \operatorname{MNN}\left(\mathcal{P}{c}\right), \mathcal{P}{c}(\tilde{i}, \tilde{j}) \geq \theta{c}\right}\tag{5}M c ={(i ~,j ~)∣∀(i ~,j ~)∈M N N (P c ),P c (i ~,j ~)≥θc }(5 )
从粗糙到精细的优化模块

在建立了粗粒度的匹配后,使用一种基于相关性的方法来完成从粗粒度到细粒度的转换;
- 首先将粗匹配点对i ~ 与 j ~ \tilde{i} 与 \tilde{j}i ~与j ~ 投影回细粒度的特征图上F ^ A \hat{F}^{A}F ^A 得到点i ^ \hat{i}i ^ 与F ^ B \hat{F}^{B}F ^B 上得到点j ^ \hat{j}j ^;
- 在细粒度特征图的特征点处裁剪一个w × w w\times w w ×w 的局部窗口;再将这个局部窗口输入到LOFTR模块(位置编码+自注意力+交叉注意力)中得到一对局部特征图F ^ t r A ( i ^ ) 与 F ^ t r B ( j ^ ) \hat{F}{t r}^{A}(\hat{i}) 与 \hat{F}{t r}^{B}(\hat{j})F ^t r A (i ^)与F ^t r B (j ^);
- 计算局部窗口特征图F ^ t r A ( i ^ ) 与 F ^ t r B ( j ^ ) \hat{F}{t r}^{A}(\hat{i}) 与 \hat{F}{t r}^{B}(\hat{j})F ^t r A (i ^)与F ^t r B (j ^) 的相关性得分矩阵;
- 通过计算概率分布上的期望,得到i ^ \hat{i}i ^ 在图I B I_{B}I B 上亚像素精度的匹配特征点的位置j ^ ′ \hat{j}^{\prime}j ^′。
; 损失函数
损失函数包含粗粒度损失与细粒度损失:
L = L c + L f (6) \mathcal{L}=\mathcal{L}{c}+\mathcal{L}{f}\tag{6}L =L c +L f (6 )
其中粗粒度损失对匹配概率矩阵求负对数似然:L c = − 1 ∣ M c g t ∣ ∑ ( i ~ , j ~ ) ∈ M c g t log P c ( i ~ , j ~ ) (7) \mathcal{L}{c}=-\frac{1}{\left|\mathcal{M}{c}^{g t}\right|} \sum_{(\tilde{i}, \tilde{j}) \in \mathcal{M}{c}^{g t}} \log \mathcal{P}{c}(\tilde{i}, \tilde{j})\tag{7}L c =−∣∣M c g t ∣∣1 (i ~,j ~)∈M c g t ∑lo g P c (i ~,j ~)(7 )
细粒度损失采用 L 2 L_{2}L 2 损失,对于每个点 i ^ \hat{i}i ^ 在局部窗口的方差 σ 2 ( i ^ ) \sigma^{2}(\hat{i})σ2 (i ^) 来对每个匹配点进行加权,从而得到损失函数:
L f = 1 ∣ M f ∣ ∑ ( i ^ , j ^ ′ ) ∈ M f 1 σ 2 ( i ^ ) ∥ j ^ ′ − j ^ g t ′ ∥ 2 (8) \mathcal{L}{f}=\frac{1}{\left|\mathcal{M}{f}\right|} \sum_{\left(\hat{i}, \hat{j}^{\prime}\right) \in \mathcal{M}{f}} \frac{1}{\sigma^{2}(\hat{i})}\left\|\hat{j}^{\prime}-\hat{j}{g t}^{\prime}\right\|{2}\tag{8}L f =∣M f ∣1 (i ^,j ^′)∈M f ∑σ2 (i ^)1 ∥∥∥j ^′−j ^g t ′∥∥∥2 (8 )
其中 j ^ g t ′ \hat{j}{g t}^{\prime}j ^g t ′ 是通过使用相机内外参与深度图,将 I A I_{A}I A 的 i ^ \hat{i}i ^ 点的特征warp到 I B I_{B}I B 的 j ^ g t ′ \hat{j}{g t}^{\prime}j ^g t ′ 点,与 j ^ ′ \hat{j}^{\prime}j ^′ 点的特征向量求 L 2 L{2}L 2 损失;
实验结果

Original: https://blog.csdn.net/weixin_40957452/article/details/123759483
Author: CV科研随想录
Title: 论文阅读《LoFTR: Detector-Free Local Feature Matching with Transformers》