
首先先配置好权限
注意:不能同时支持讯飞语音识别和百度语音识别,只可二选一
百度语音识别
在manifest.json文件"App模块配置"项的"Speech(语音输入,只能选一个)"下,勾选"百度语音识别"项,并输入从百度开放平台申请的参数:
- appid:
百度语音开放平台申请的AppID - apikey:
百度语音开放平台申请的API Key - secretkey:
百度语音开放平台申请的Secret Key
请到百度语音开放平台申请:https://console.bce.baidu.com/ai/
讯飞语音识别
在manifest.json文件"App模块配置"项的"Speech(语音输入,只能选一个)"下,勾选"讯飞语音识别"项:
注意:讯飞语音识别有识别次数限制,建议优先使用百度语音识别。
配置完成后Ctrl+S保存提交App云端打包生效。
不管你用哪一个,记住,都是有次数限制的,讯飞,uniapp官网支持,所以并不需要配置什么,但是你最好还是自己上讯飞官网申请创建一个语音识别应用,不然到时候你云打包的时候,真的不知道他在读什么鸟语,我猜测是次数用完限制了,不啰嗦,上代码
var receiver = plus.android.implements('com.iflytek.cloud.SynthesizerListener', {
onEvent: function(name) {
console.log("onEvent");
},
onSpeakBegin: function() {
console.log("开始阅读");
},
onSpeakPaused: function() {
console.log(" 暂停播放 ");
},
onSpeakResumed: function() {
console.log("继续播放");
},
onBufferProgress: function(percent, beginPos, endPos, info) {
console.log("合成进度" + percent);
},
onSpeakProgress: function(percent, beginPos, endPos) {
console.log("播放进度" + percent);
},
onCompleted: function(error) {
console.log("播放完毕");
}
});
var main = plus.android.runtimeMainActivity();
var SpeechUtility = plus.android.importClass('com.iflytek.cloud.SpeechUtility');
//这里的appid填你自己申请的
SpeechUtility.createUtility(main, "appid=xxxxx");
var SynthesizerPlayer = plus.android.importClass('com.iflytek.cloud.SpeechSynthesizer');
var play = SynthesizerPlayer.createSynthesizer(main, null);
// 开始合成
play.startSpeaking('生活就是海洋', receiver);
注意:如果要本地测试的话,一定要打自定义基座,不然无效
有兴趣可以关注一下公众号,会不定期分享一些东西,也欢迎各位投稿分享!谢谢

Original: https://blog.csdn.net/qq_37049128/article/details/108468717
Author: 菜鸟咸鱼一锅端
Title: uniapp-语音识别
相关阅读1
Title: Jetson xavier NX / ubuntu18.04 /ros melodic/python3安裝使用cv_bridge
最開始是出現問題:
from cv_bridge.boost.cv_bridge_boost import getCvType
ImportError: dynamic module does not define module export function (PyInit_cv_bridge_boost)
然後開始安裝cv_bridge
下面是安裝步驟:
1、相關依赖
sudo apt-get install python-catkin-tools python3-dev python3-catkin-pkg-modules python3-numpy python3-yaml ros-melodic-cv-bridge
2、創建工作空間,設置變量
注意架構,最好自己從路徑中確認一下
mkdir -p catkin_workspace/src
cd catkin_workspace
catkin config -DPYTHON_EXECUTABLE=/usr/bin/python3 -DPYTHON_INCLUDE_DIR=/usr/include/python3.6m -DPYTHON_LIBRARY=/usr/lib/aarch64-linux-gnu/libpython3.6m.so
3、指示catkin将内置包安装到安装位置,这一步不成功也没关系,可不用。
catkin config --install
4、在catkin_workspace工作空间中克隆 cv_bridge src
5、在存储库中查找cv_bridge的版本, 我是melodic
apt-cache show ros-melodic-cv-bridge | grep Version
6、在git repo中签出正确的版本,我是1.13.0
cd src/vision_opencv/
git checkout 1.13.0
cd ../../
7、開始編譯
catkin build 或者 catkin build cv_bridge
編譯的時候出現了新的問題:
/home/nvidia/software/catkin_workspace/src/vision_opencv/cv_bridge/src/module_opencv2.cpp:151:16:
error: cannot declare variable 'g_numpyAllocator' to be of abstract
type 'NumpyAllocator'
解決辦法:
In cv_bridge/src CMakeLists.txt line 35 change to if (OpenCV_VERSION_MAJOR VERSION_EQUAL 4)
In cv_bridge/src/module_opencv3.cpp change signature of two functions:
1:
UMatData* allocate(int dims0, const int* sizes, int type, void* data, size_t* step, int flags, UMatUsageFlags usageFlags) const
to
UMatData* allocate(int dims0, const int* sizes, int type, void* data, size_t* step, AccessFlag flags, UMatUsageFlags usageFlags) const
2:
bool allocate(UMatData* u, int accessFlags, UMatUsageFlags usageFlags) const
to
bool allocate(UMatData* u, AccessFlag accessFlags, UMatUsageFlags usageFlags) const
8、使用之前記得source
source install/setup.bash --extend
reference:
https://zhuanlan.zhihu.com/p/356441425
https://blog.csdn.net/weixin_42675603/article/details/107785376
https://www.guyuehome.com/34115Original: https://blog.csdn.net/qq_33980935/article/details/123132452
Author: 爱吃橙子的牧羊女
Title: Jetson xavier NX / ubuntu18.04 /ros melodic/python3安裝使用cv_bridge
相关阅读2
Title: TensorFlow梳理一
一、TensorFlow简介
TensorFlow是Google开源的第二代用于数字计算(numerical computation)的软件库。它是基于数据流图的处理框架,图中的节点表示数学运算(mathematical operations),边表示运算节点之间的数据交互
- TensorFlow使用Tensor来表示数据
- TensorFlow 在内部将张量表示为 *基本数据类型的n维数组
TensorFlow所有的数据都是一个n维的数组,张量(Tensor)
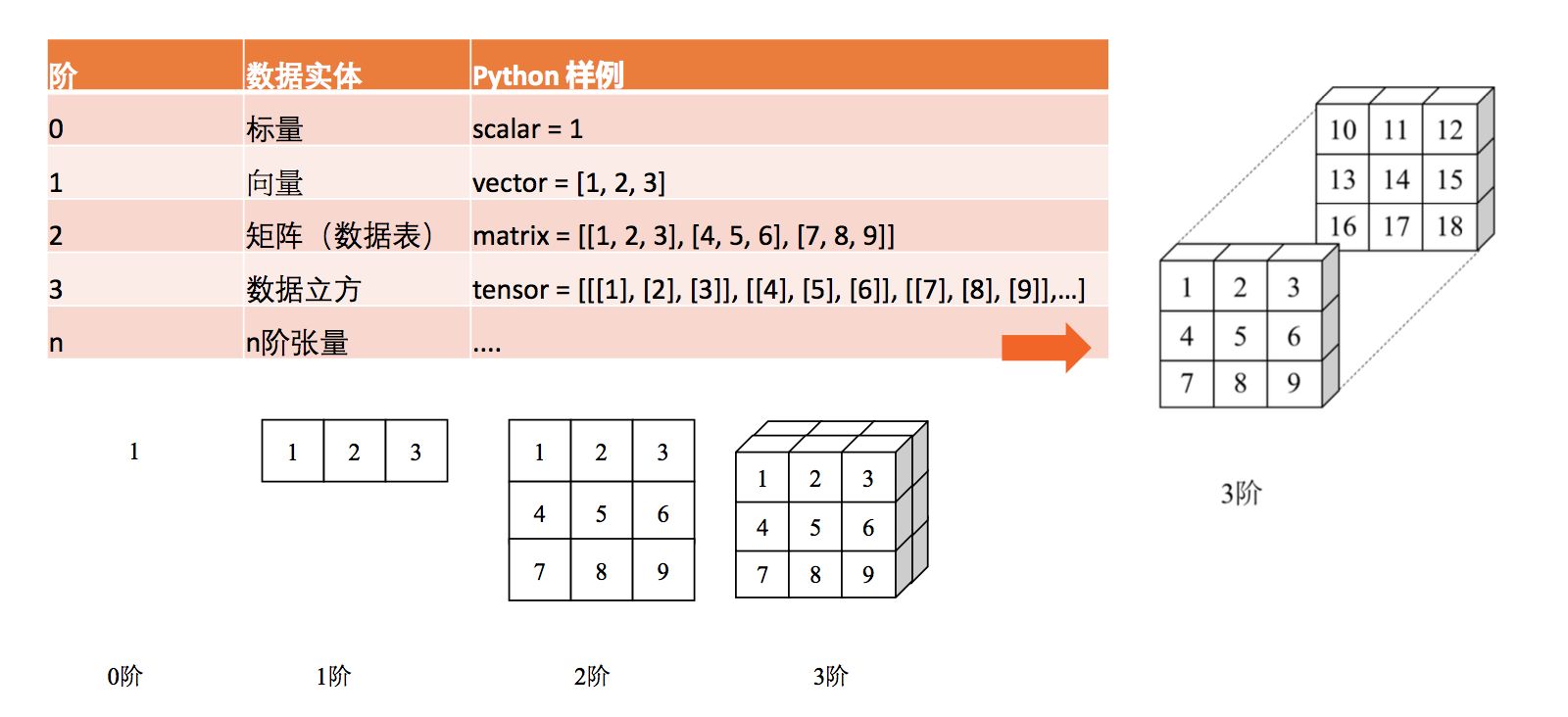
1.1Tensor的基础
Tensor(张量)实际上就是一个n维的数组。这就延伸了几个的术语:
- 阶(秩)
- 形状
其实上,阶就是平时我们所说的 维数。
- 比如我们有一个二维的数组,那么这个阶就是2
- 比如我们有一个三维的数组,那么这个阶就是3
张量的 形状可以让我们看到 每个维度中元素的数量。
1.2 Tensor数据类型
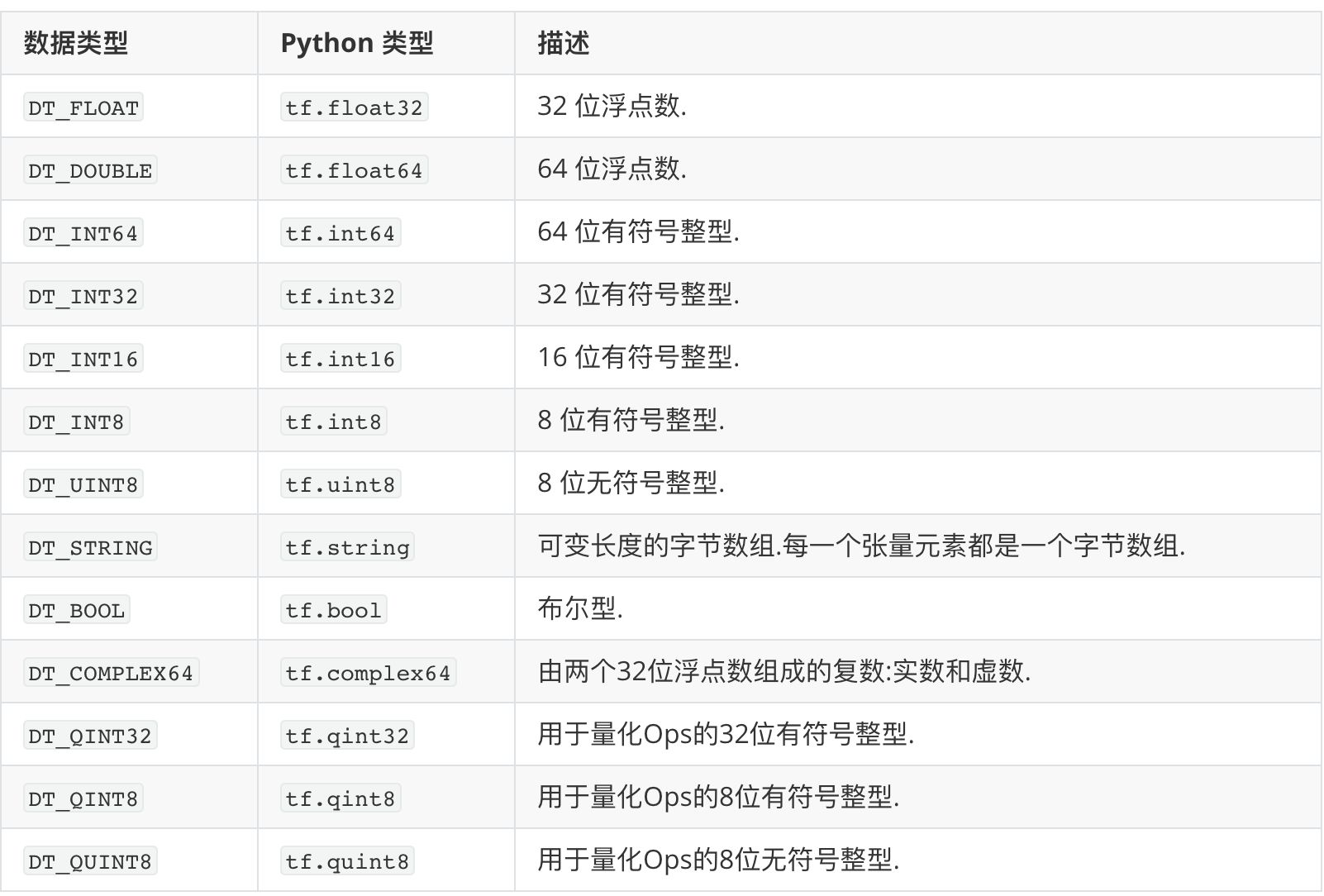
TensorFlow 在内部将张量表示为 基本数据类型的 n维数组,没错的。在一个数组里边,我们总得知道我们的存进去的数据究竟是什么 类型。
二、特殊的张量
特殊的张量由一下几种:
<a href="https://link.zhihu.com/?target=https%3A//www.tensorflow.org/api_docs/python/tf/Variable" title="tf.Variable">tf.Variable</a>— 变量<a href="https://link.zhihu.com/?target=https%3A//www.tensorflow.org/api_docs/python/tf/constant" title="tf.constant">tf.constant</a>— 常量<a href="https://link.zhihu.com/?target=https%3A//www.tensorflow.org/api_docs/python/tf/placeholder" title="tf.placeholder">tf.placeholder</a>—占位符<a href="https://link.zhihu.com/?target=https%3A//www.tensorflow.org/api_docs/python/tf/SparseTensor" title="tf.SparseTensor">tf.SparseTensor</a>—稀疏张量
这次,我们先来讲讲前三种(比较好理解),分别是变量、常量和占位符。
2.1 常量
常量就是常量的意思, 一经创建就不会被改变。(相信大家还是能够理解的)
在TensorFlow中,创建常量的方式十分简单:
a = tf.constant(2)
b = tf.constant(3)
2.2变量
变量也挺好理解的(就将编程语言的概念跟这里类比就好了)。一般来说,我们在 训练过程中的参数一般用变量进行存储起来,因为我们的参数会不停的变化。
在TensorFlow创建变量有 两种方式:
# 1.使用Variable类来创建
# tf.random_normal 方法返回形状为(1,4)的张量。它的4个元素符合均值为100、标准差为0.35的正态分布。
W = tf.Variable(initial_value=tf.random_normal(shape=(1, 4), mean=100, stddev=0.35), name="W")
b = tf.Variable(tf.zeros([4]), name="b")
# 2.使用get_variable的方式来创建
my_int_variable = tf.get_variable("my_int_variable", [1, 2, 3], dtype=tf.int32,
initializer=tf.zeros_initializer)
值得注意的是: 当我们创建完变量以后,我们每次使用之前,都需要为其进行初始化!
tf.global_variables_initializer()
2.3占位符
我最早接触占位符这个概念的时候是在JDBC的时候。因为SQL 需要传入的参数才能确定下来,所以我们可能会写出这样的SQL语句: select * from user where id =?
同样地,在TensorFlow占位符也是这么一个概念,可能需要 等到运行的时候才把某些变量确定下来,于是我们就有了占位符。
在TensorFlow使用占位符也很简单:
# 文件名需要等到运行的时候才确定下来
train_filenames = tf.placeholder(tf.string, shape=[None])
# ..省略一堆细节
# 运行的时候,通过feed_dict将占位符具体的值给确定下来
feed_dict={train_filenames: training_filenames}
三、Flow 介绍图和节点
Flow翻译成中文: 流,所以现在是 Tensor流?
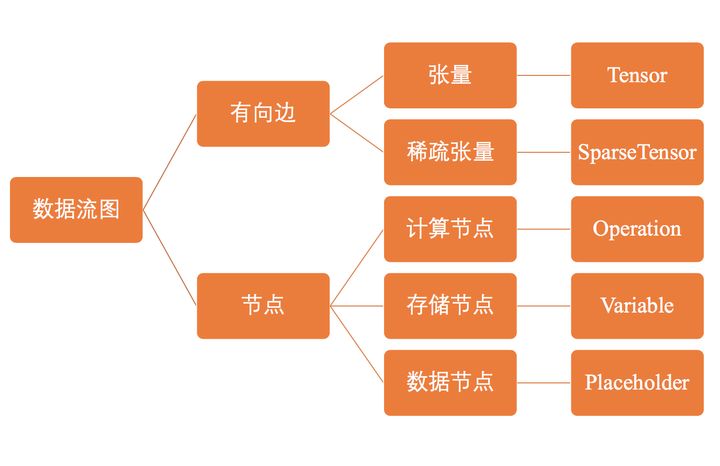
在TensorFlow中, 使用图 (graph) 来表示计算任务。其实TensorFlow默认会给我们一张空白的 图,一般我们会叫这个为" 数据流图"。数据流图由有向边和节点组成,在使用TensorFlow的时候我们会在图中创建各种的 节点,而Tensor会在这些节点中 流通。所以,就叫做TensorFlow
那有人就会好奇,我们执行什么操作会创建节点呢?在TensorFlow中,节点的类型可以分为三种:
- 存储节点:有状态的变量操作,通常用于存储模型参数
- 计算节点:无状态的计算和控制操作,主要负责算法的逻辑或流程的控制
- 数据节点:数据的占位符操作,用于描述图外输入的数据
看到这里的同学,可能就反应过来了:原来在上面创建的变量、常量和占位符在TensorFlow中都会生成一个节点!对于这类的操作Operation(行为)一般大家会简说成 op
所以,op就是在TensorFlow中所执行的一个操作 统称而已(有可能是创建变量的操作、也有可能是计算的操作)。在TensorFlow的常见的op有以下:

官方的给出数据流图的gif。
- TensorFlow使用数据流图来表示计算任务
- TensorFlow使用Tensor来表示数据,Tensor在数据流图中流动。
- 在TensorFlow中"创建节点、运算"等行为统称为op

会话 (Session):TensorFlow描述的计算流程图需要在Session中启动;Session将其与C++后端连接,为其分配计算设备(CPU 或 GPU)和提供计算方法,反复训练模型。
节点(Nodes):在图中表示数学操作,例如,数据输入(feed in)的起点或输出(push out)的终点;
线(edges):线输送节点间相互联系和不断变化的多维数据数组(即张量, tensor)。
TensorFlow 程序分为计算图构建和执行两个步骤;
计算图构建:除了起始和终止层外,每个操作的输入都是其它操作输出,操作的输出也是其它操作的输入。计算图构建就是将数据计算内容和过程用一个数据流图表示出来。
计算图执行:计算图构建之后,需要创建一个会话,然后才能启动图;当会话没有参数时,会话会启动默认图。
四、会话session
TensorFlow程序通常被组织成一个 构建阶段和执行阶段. 在构建阶段, op的 执行步骤被描述成一个图. 在执行阶段, 使用会话执行执行图中的op。
- 注意:因为是有向边,所以 只有等到之前的入度节点们的计算状态完成后,当前节点才能执行操作。
说白了,就是当我们在编写代码的时候,实际上就是在将TensorFlow给我们的 空白图描述成一张我们 想要的图。但我们想要运行出图的结果,那就必须通过session来执行。
import tensorflow as tf
# 创建数据流图:y = W * x + b,其中W和b为存储节点,x为数据节点。
x = tf.placeholder(tf.float32)
W = tf.Variable(1.0)
b = tf.Variable(1.0)
y = W * x + b
# 如果不使用session来运行,那上面的代码只是一张图。我们通过session运行这张图,得到想要的结果
with tf.Session() as sess:
tf.global_variables_initializer().run() # Operation.run
fetch = y.eval(feed_dict={x: 3.0}) # Tensor.eval
print(fetch) # fetch = 1.0 * 3.0 + 1.0
4.1 查看会话结果Fetch
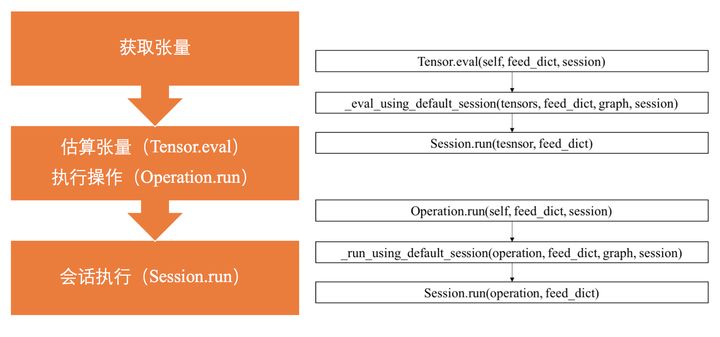
Fetch就时候可以在 session.run的时候 传入多个op(tensor),然后 返回多个tensor(如果只传入一个tensor的话,那就是返回一个tensor)
4.2tensor.eval()和Operation.run()
有的同学在查阅资料的时候,发现可能调用的不是 session.run,而是 tensor.eval()和Operation.run()。其实,他们 最后的调用的还是 session.run。不同的是 session.run可以 一次返回多个tensor(通过Fetch)。
总结
-
使用 tensor 表示数据.
-
使用图 (graph) 来表示计算任务.
-
在会话(session)中运行图
- 通过
变量 (Variable)维护状态.
TensorFlow 是一个编程系统, 使用图来表示计算任务. * _图中的节点被称之为_op (operation 的缩写). 一个 op 获得 0 个或多个
Tensor, 执行计算, 产生 0 个或多个Tensor. *每个 Tensor 是一个类型化的多维数组.
参考
- https://juejin.im/post/5b345a49f265da599c561b25
- 什么是TensorFlow - 知乎
- TensorFlow是什么? - 简书
- TensorFlow是什么
- TensorFlow学习笔记-feed与fetch_快乐成长吧的博客-CSDN博客
- 用 TensorFlow 可以做什么有意思的事情? - 知乎
- https://github.com/geektime-geekbang/tensorflow-101/tree/master/notebook-examples
Original: https://blog.csdn.net/weixin_42322206/article/details/123634252
Author: 王同学加油
Title: TensorFlow梳理一
相关阅读3
Title: ASR入门笔记
一些参数说明
https://www.kancloud.cn/anychat-doc/anychat_handbook_video/526462
音频、音频,故名声音的频率,指人耳可以听到的声音频率在20HZ~20kHz之间的声波,称为音频,那频率就有采用率和大小,我们大自然的声音都是物理现象,称为模拟音频信号。为了方便数字化存储和传输,我们采用数字音频信号处理技术,音频采样率是指录音设备在一秒钟内对声音信号的采样次数,采样频率越高。声音的还原越真实越自然。在当今的主流采集卡上,采样频率一般共分为22.05KHz、44.1KHz、48KHz三个等级。
sample rate,取样频率:指每秒钟取得声音样本的次数。采样频率越高,声音的质量也就越好,声音的还原也就越真实,但同时它占的资源比较多。由于人耳的分辨率很有限,太高的频率并不能分辨出来。
sample size,采样值大小:它是用来衡量声音波动变化的一个参数,也可以说是声卡的分辨率。它的数值越大,分辨率也就越高,所发出声音的能力越强。
每个采样数据记录的是振幅, 采样精度取决于采样位数的大小:1 字节(也就是8bit) 只能记录 256 个数, 也就是只能将振幅划分成 256 个等级;
2 字节(也就是16bit) 可以细到 65536 个数, 这已是 CD 标准了;
4 字节(也就是32bit) 能把振幅细分到 4294967296 个等级, 实在是没必要了.
声道:指声音在录制或播放时在不同空间位置采集或回放的相互独立的音频信号。
声道数:声音录制时的音源数量或回放时相应的扬声器数量。
分为单声道、双声道、多声道。
1. 输入音频处理

从waveform到MFCC逐步加深,log十分重要
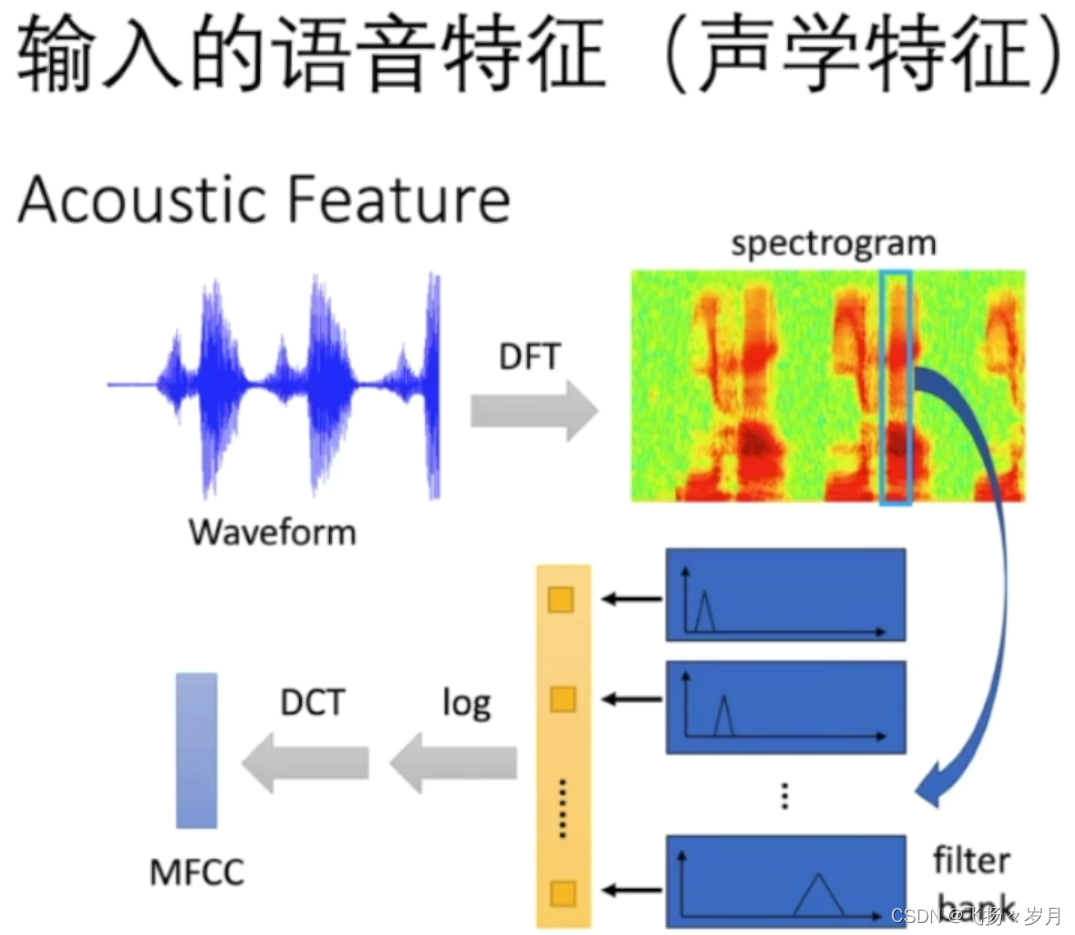
最终得到的MFCC特征,就是用24维特征系数来代表一帧的声音。
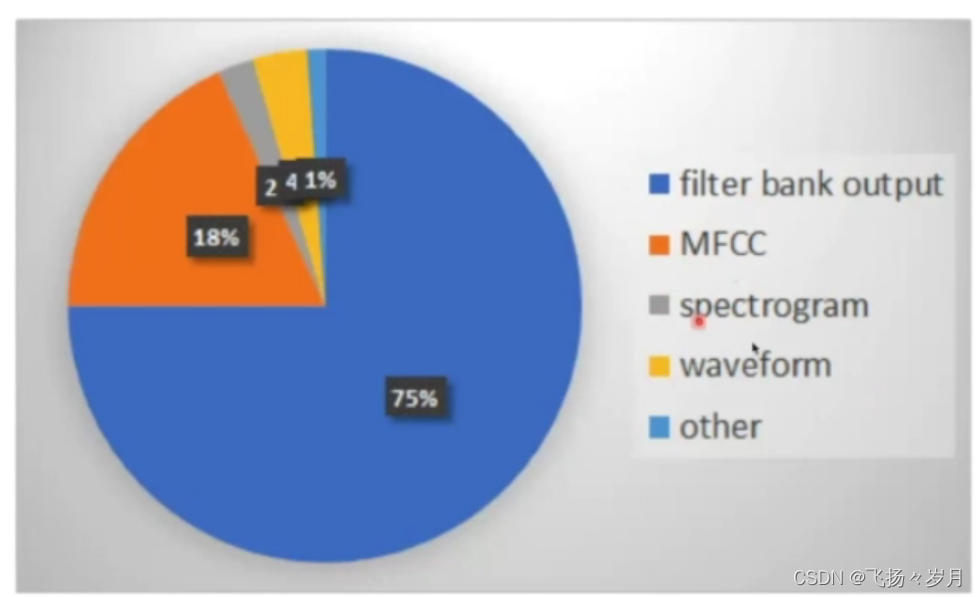
; 2. 输出token
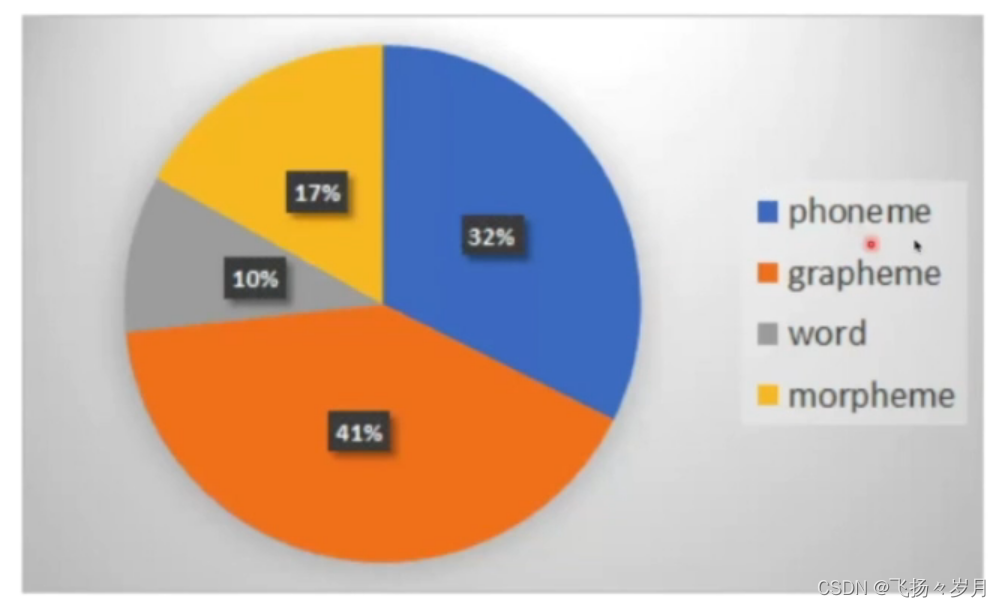
(1)Phoneme:最小的发音单元 https://en.wikipedia.org/wiki/Vowel
(2)Grapheme:最小的书写单元。中文=字,英文=字母
(3)word:中文=词,英文=word
(4)Morpheme:最小的有意义的单元。适用英文,例如:
unbreakable=un break able,类似于子词
(5)拼音
训练时英文按空格分词,中文复杂:

主流模型
1、seq2seq+attention +beam search
例如:LAS模型(Listen, Attend, and Spell
)
缺点: not streaming
2、Sequence labeling
(1)CTC

CTC模型就是先将一段声音信号x作为输入输入到encoder中,输出h,再经过一个classifier产生token distribution,最后经过一个softmax输出最后结果。但是如果只是以上这种模型,并不能有很好的结果,因为如果token只是一个大小为V的矩阵的话,不一定每一段x会有输出,于是就会有一个Ø(NULL)便可以有效处理这种情况。
详情参见:https://blog.csdn.net/qq_45866407/article/details/105975320
缺点:条件独立,会反复生成相同的词。生成的token不能超过sample数量。
优点,可以做streaming
(2)RNN Transducer
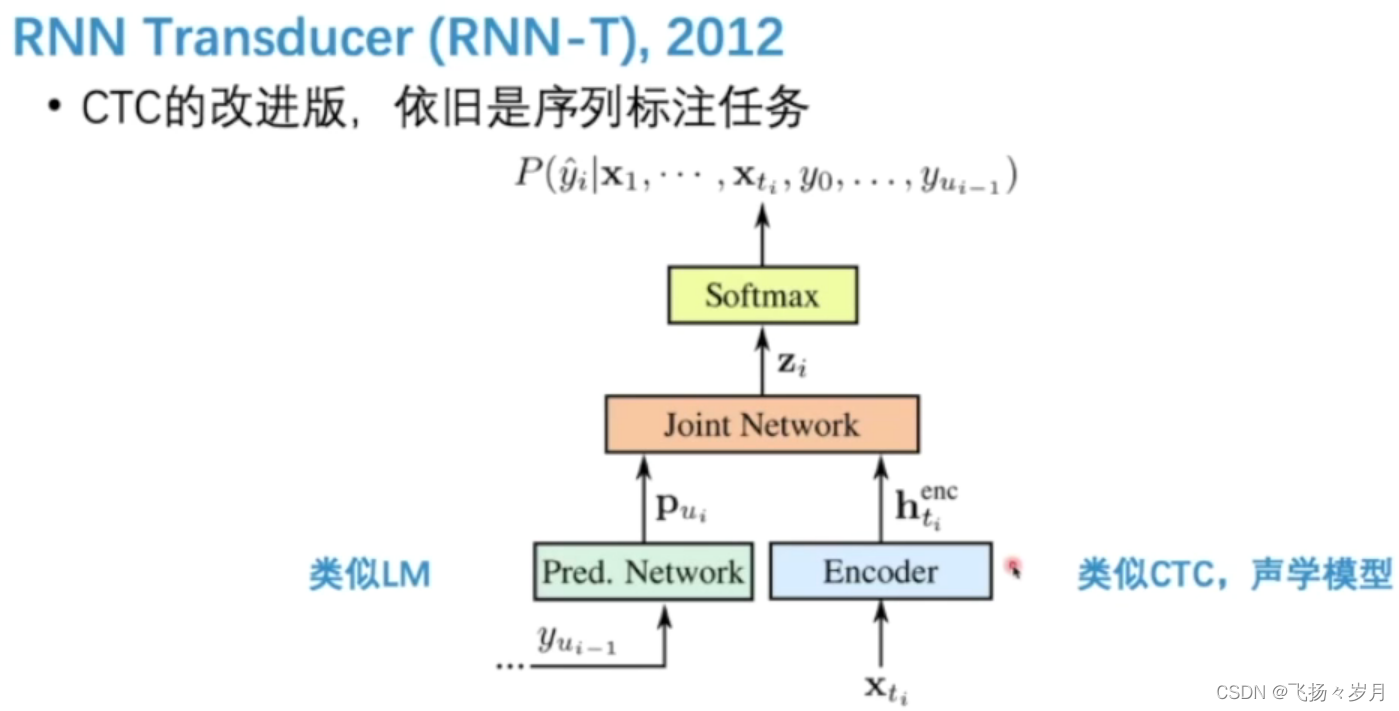
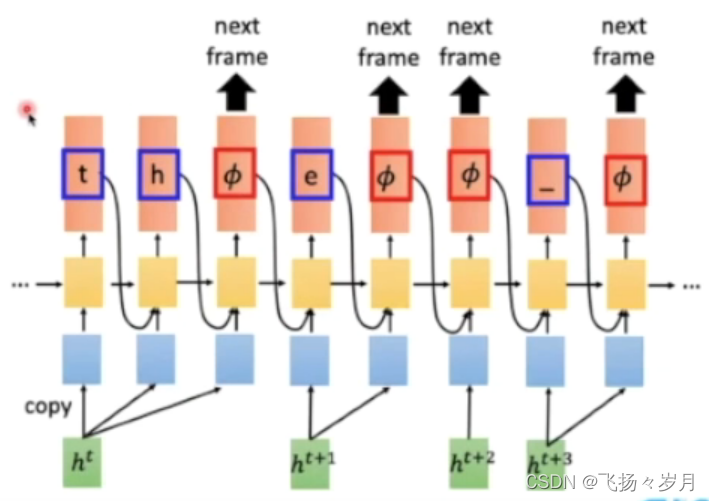
优点:在encoder改进了RNN,一个h0可以用多个step,使得模型能输出超过sample数量的token。考虑了LM,支持streaming。
缺点:训练困难。
(3)Neural Transducer
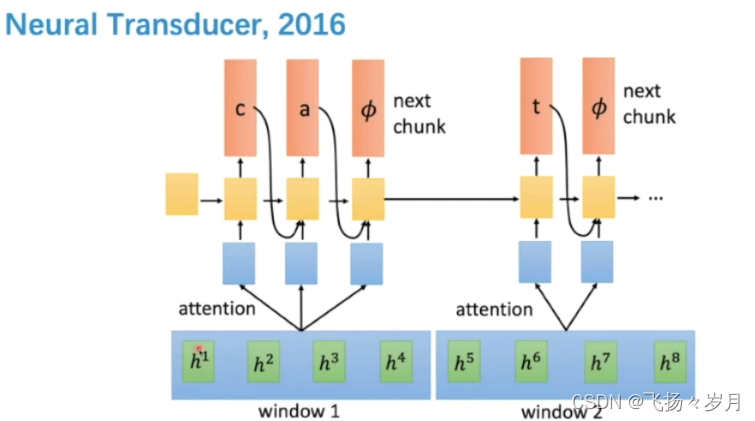
(4) Monotonic Chunkwise Attention
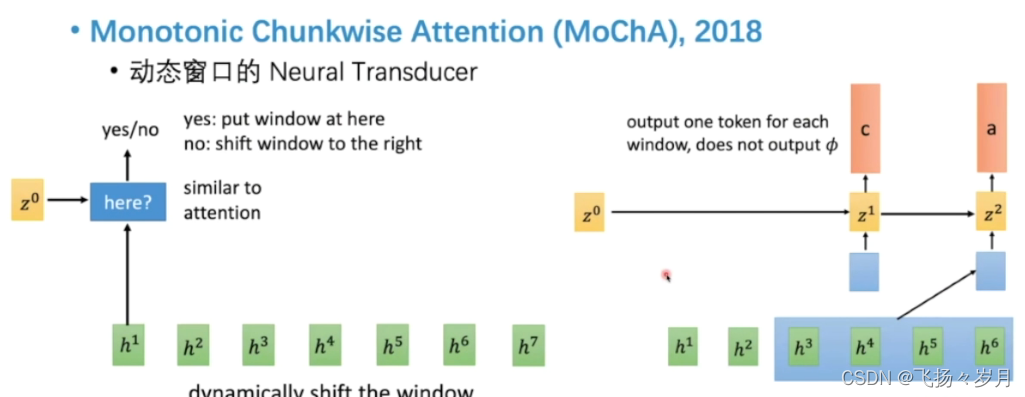
总结:
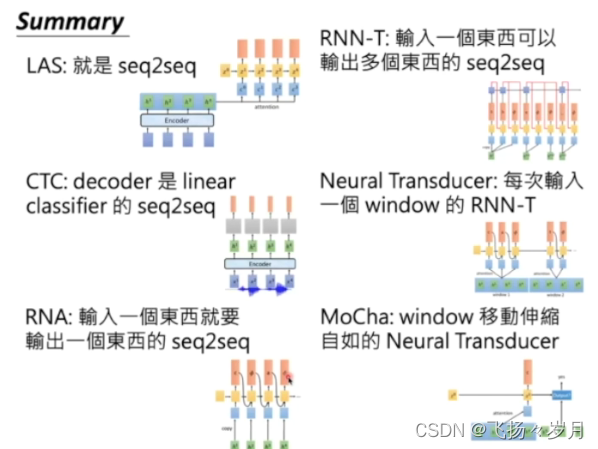
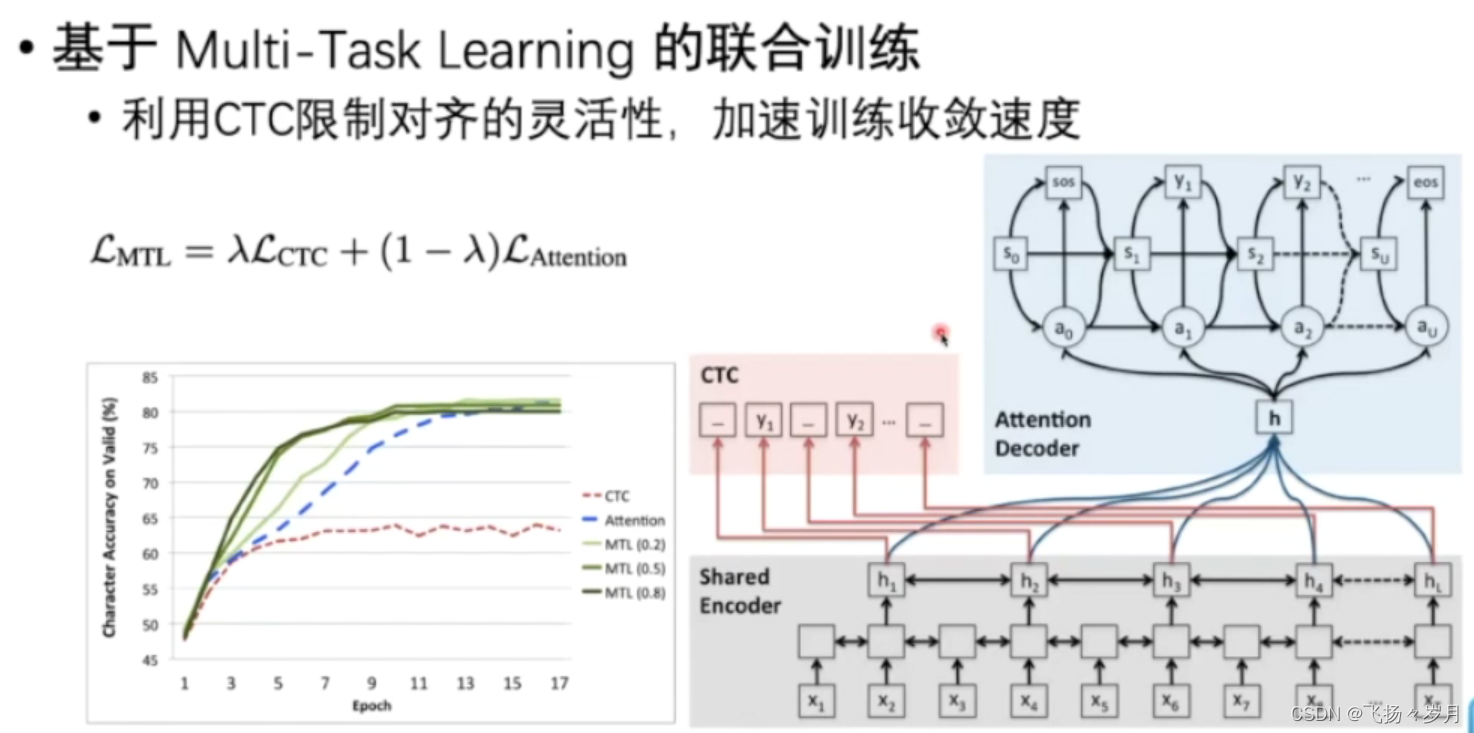
; 3、Multi-task learning
核心理念:
CTC模型训练快,但是有token长度对应得限制,并且容易结巴连续生成某个token。
SL模型,没有长度限制,不会结巴。但是速度慢。
因此,考虑两个任务联合起来,加快模型收敛速度。
Transformer系列
(1)Conformer Transducer
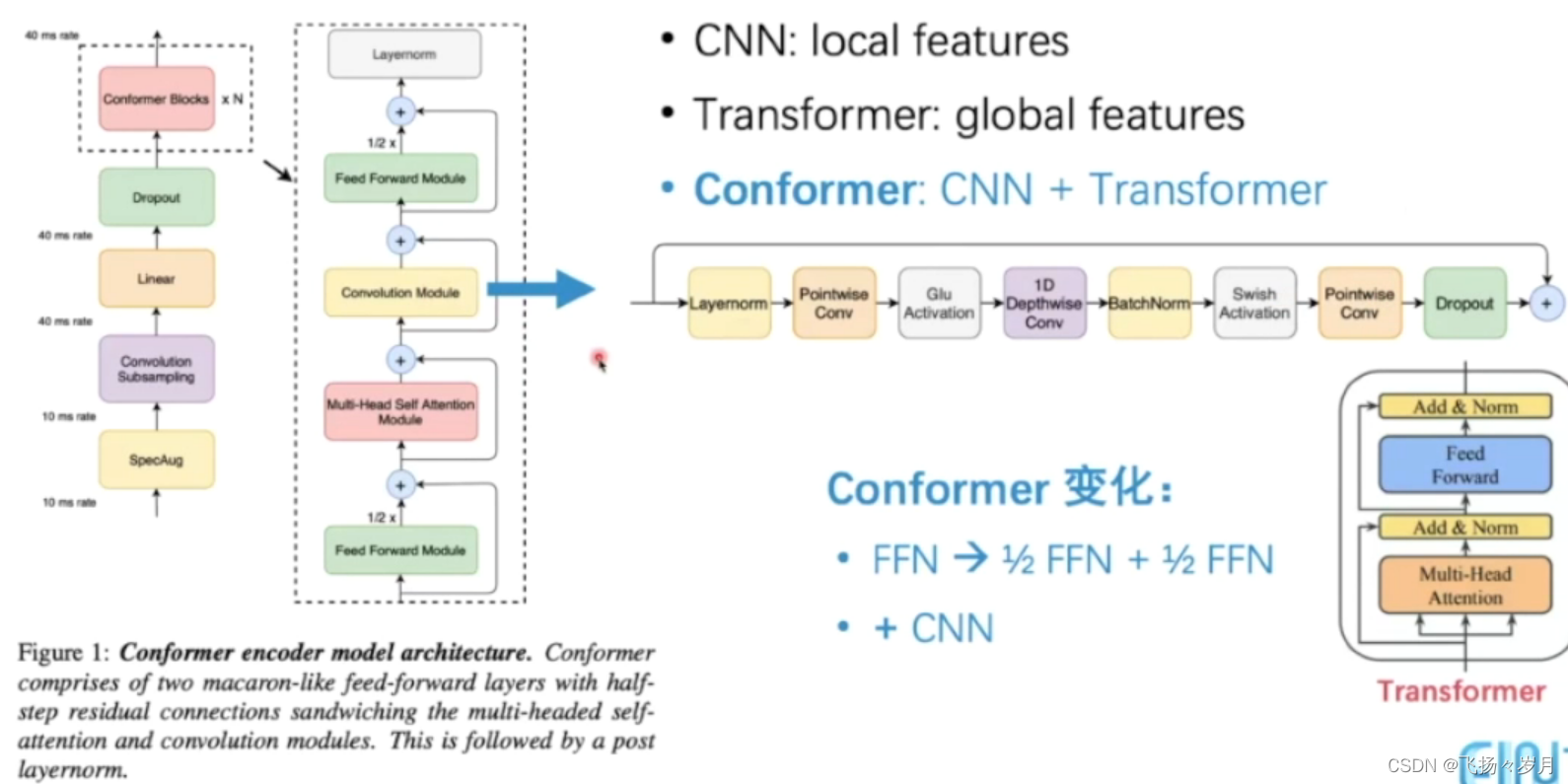
把FFN分为两个步骤,同时用CNN来捕获局部特征
; 关于Streaming
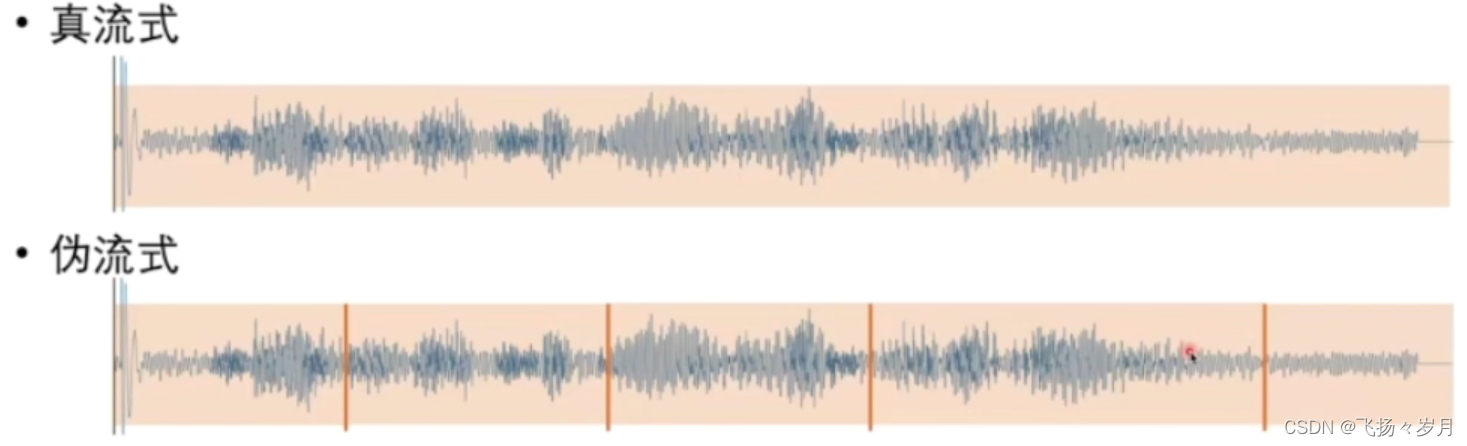
Transfoemer结构怎么实现Streaming
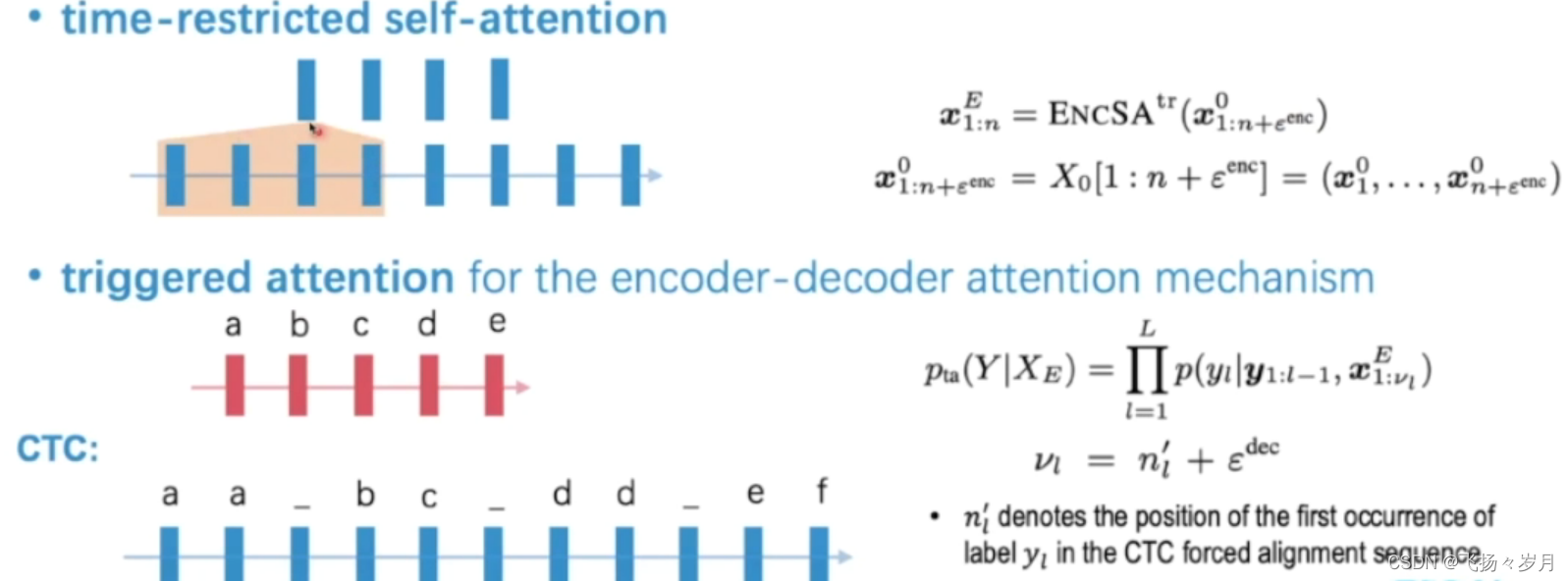
triggered attention:每个节点只看当前节点之前的节点。也可以往后看一定数量的节点,主要防止要预测'我们',当前时间只听到'我',所以向后多听一点。
在CTC模型中,每个字只关注这个字第一次出现前的序列
; ASR相关技术:EP__EndPointer.端点检测
VAD: Voice Activity Detector.
判断是否有人说话
EOQ: End of Query.
找到对话结束点
SD: Speaker Diarization
在多人对话中将对话按人划分。
常用工具

Original: https://blog.csdn.net/weixin_42264992/article/details/125319325
Author: 飞扬々岁月
Title: ASR入门笔记