
基于PaddleGAN精准唇形合成实现持枪人讲电话已关机
基于PaddleGAN精准唇形合成实现持枪人讲电话已关机
宋代著名诗人苏轼「动起来」的秘密
就在上周,坐拥百万粉丝的 独立艺术家大谷Spitzer老师利用深度学习技术使 宋代诗人苏轼活过来,穿越千年,为屏幕前的你们亲自朗诵其著名古诗~ 点击量近百万,同时激起百万网友热议,到底是什么技术这么牛气?

; PaddleGAN的唇形迁移能力–Wav2lip
铛铛铛!!飞桨PaddleGAN 这就来给大家揭秘,手把手教大家如何实现唇型的迁移,学习过本项目的你们,从此不仅能让苏轼念诗,还能让蒙娜丽莎播新闻、新闻主播唱Rap... 只有你想不到的,没有PaddleGAN 做不到的!
本教程是基于PaddleGAN实现的视频唇形同步模型 Wav2lip, 它实现了人物口型与输入语音同步,俗称「对口型」。 比如这样:

不仅仅让静态图像会「说话」,Wav2lip还可以直接将动态的视频,进行唇形转换,输出与目标语音相匹配的视频,自制视频配音不是梦!
本次教程包含四个部分:
- Wav2lip原理讲解
- 下载PaddleGAN代码
- 唇形动作合成命令使用说明
- 成果展示
若是大家喜欢这个教程,欢迎到Github PaddleGAN主页 点击star呀!下面就让我们一起动手实现吧!
; Wav2lip模型原理
Wav2lip实现唇形与语音精准同步突破的关键在于,它采用了 唇形同步判别器,以强制生成器持续产生准确而逼真的唇部运动。
此外,该研究通过在鉴别器中,使用 多个连续帧而不是单个帧,并使用视觉质量损失(而不仅仅是对比损失)来考虑时间相关性,从而改善了视觉质量。
该wav2lip模型几乎是 万能的,适用于任何 人脸、 任何语音、 任何语言,对任意视频都能达到很高的准确率,可以无缝地与原始视频融合,还可以用于 转换动画人脸,并且导入合成语音也是可行的
下载PaddleGAN代码
%cd /home/aistudio/work
/home/aistudio/work
!git clone https://gitee.com/PaddlePaddle/PaddleGAN
!mkdir sndfile
%cd sndfile
!wget http://www.mega-nerd.com/libsndfile/files/libsndfile-1.0.28.tar.gz
!tar xzvf libsndfile-1.0.28.tar.gz
%cd libsndfile-1.0.28
!./configure --prefix=/home/aistudio/build_libs CFLAGS=-fPIC --enable-shared
!make
!make install
%cd /home/aistudio/work/PaddleGAN
!pip install -r requirements.txt
%cd applications/
唇形动作合成命令使用说明
重点来啦!!本项目支持大家上传自己准备的视频和音频, 合成任意想要的 逼真的配音视频!!
只需在如下命令中的 face参数和 audio参数分别换成自己的视频和音频路径,然后运行如下命令,就可以生成和音频同步的视频。
程序运行完成后,会在当前文件夹下生成文件名为 outfile参数指定的视频文件,该文件即为和音频同步的视频文件。本项目中提供了demo展示所用到的视频和音频文件。具体的参数使用说明如下:
- face: 原始视频,视频中的人物的唇形将根据音频进行唇形合成–通俗来说,想让谁说话
- audio:驱动唇形合成的音频,视频中的人物将根据此音频进行唇形合成–通俗来说,想让这个人说什么
!export PYTHONPATH=$PYTHONPATH:/home/aistudio/work/PaddleGAN && python tools/wav2lip.py --face /home/aistudio/work/meinv.mp4 --audio /home/aistudio/work/guanji.wav --outfile guanji.mp4
/home/aistudio/work/PaddleGAN/ppgan/models/base_model.py:52: DeprecationWarning: invalid escape sequence \/
"""
/home/aistudio/work/PaddleGAN/ppgan/modules/init.py:70: DeprecationWarning: invalid escape sequence \s
"""
/home/aistudio/work/PaddleGAN/ppgan/modules/init.py:134: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/work/PaddleGAN/ppgan/modules/init.py:159: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/work/PaddleGAN/ppgan/modules/init.py:190: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/work/PaddleGAN/ppgan/modules/init.py:227: DeprecationWarning: invalid escape sequence \m
"""
/home/aistudio/work/PaddleGAN/ppgan/modules/dense_motion.py:116: DeprecationWarning: invalid escape sequence \h
"""
Reading video frames...
Number of frames available for inference: 320
(80, 985)
Length of mel chunks: 305
W0130 11:44:24.694782 9610 device_context.cc:362] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1
W0130 11:44:24.700759 9610 device_context.cc:372] device: 0, cuDNN Version: 7.6.
100%|████████████████████████████████| 141910/141910 [00:02<00:00, 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 25 128 148 915 1364 1369 3072 4396 9651 12800 16300 23166 30032 37685 45230 48000 52864 60491 68019 75624 83203 90659 98068 109119 20160609 60080.20it s] model loaded 0%| | [00:00<?, ?it s][a 1%|▎ [00:00<00:11, 9070.79it 4%|█▎ [00:00<00:08, 11656.41it 9%|███ [00:00<00:06, 14779.74it 15%|████▉ [00:00<00:04, 19277.40it 21%|███████ [00:00<00:03, 24581.13it 28%|█████████ [00:00<00:02, 30444.36it 35%|███████████▍ [00:00<00:01, 37156.25it 41%|█████████████▋ 43829.62it 48%|███████████████▉ 50248.47it 55%|██████████████████▎ [00:01<00:00, 55976.44it 62%|████████████████████▌ 60635.65it 69%|██████████████████████▊ 64560.88it 76%|█████████████████████████▏ 67558.23it 83%|███████████████████████████▍ 69516.65it 90%|█████████████████████████████▋ 69695.64it 100%|████████████████████████████████| 64286.51it 5%|██▏ [00:02<00:41, 2.17s it][a 10%|████▍ [00:04<00:38, 2.12s 15%|██████▌ [00:06<00:35, 2.07s 20%|████████▊ [00:07<00:32, 2.01s 25%|███████████ [00:09<00:29, 1.97s 30%|█████████████▏ [00:11<00:27, 1.94s 35%|███████████████▍ [00:13<00:25, 1.93s 40%|█████████████████▌ [00:15<00:22, 1.91s 45%|███████████████████▊ [00:17<00:20, 50%|█████████████████████▌ [00:19<00:19, 1.90s 55%|███████████████████████▋ [00:21<00:17, 60%|█████████████████████████▊ [00:23<00:15, 65%|███████████████████████████▉ [00:25<00:13, 70%|██████████████████████████████ [00:26<00:11, 75%|████████████████████████████████▎ [00:28<00:09, 80%|██████████████████████████████████▍ [00:30<00:07, 85%|████████████████████████████████████▌ [00:32<00:05, 1.92s 90%|██████████████████████████████████████▋ [00:34<00:03, 95%|████████████████████████████████████████▊ [00:36<00:01, 100%|███████████████████████████████████████████| [00:36<00:00, 1.83s 100%|█████████████████████████████████████████████| [00:41<00:00, 13.73s it] ffmpeg version 2.8.15-0ubuntu0.16.04.1 copyright (c) 2000-2018 the developers built with gcc 5.4.0 (ubuntu 5.4.0-6ubuntu1~16.04.10) configuration: --prefix="/usr" --extra-version="0ubuntu0.16.04.1" --build-suffix="-ffmpeg" --toolchain="hardened" --libdir="/usr/lib/x86_64-linux-gnu" --incdir="/usr/include/x86_64-linux-gnu" --cc="cc" --cxx="g++" --enable-gpl --enable-shared --disable-stripping --disable-decoder="libopenjpeg" --enable-avresample --enable-avisynth --enable-gnutls --enable-ladspa --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libmodplug --enable-libmp3lame --enable-libopenjpeg --enable-libopus --enable-libpulse --enable-librtmp --enable-libschroedinger --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libwebp --enable-libx265 --enable-libxvid --enable-libzvbi --enable-openal --enable-opengl --enable-x11grab --enable-libdc1394 --enable-libiec61883 --enable-libzmq --enable-frei0r --enable-libx264 --enable-libopencv libavutil 54. 31.100 libavcodec 56. 60.100 libavformat 40.101 libavdevice 4.100 libavfilter 5. libavresample 2. 1. libswscale 3. 1.101 libswresample 2.101 libpostproc 53. 3.100 [0;33mguessed channel layout for input stream #0.0 : stereo [0minput #0, wav, from ' home aistudio work guanji.wav': duration: 00:00:12.30, bitrate: kb s #0:0: audio: pcm_f32le ([3][0][0][0] 0x0003), hz, channels, flt, #1, avi, 'temp result.avi': metadata: encoder lavf58.31.101 00:00:12.20, start: 0.000000, #1:0: video: mpeg4 (simple profile) (divx 0x58564944), yuv420p, 1094x614 [sar 1:1 dar 547:307], s, fps, tbr, tbn, tbc [1;36m[libx264 @ 0x1c25ea0] [0m[0;33m-qscale is ignored, -crf recommended. [0m[1;36m[libx264 [0musing sar="1/1" cpu capabilities: mmx2 sse2fast ssse3 sse4.2 avx fma3 avx2 lzcnt bmi2 [0mprofile high, level 3.1 [0m264 - core r2643 5c65704 h.264 mpeg-4 avc codec copyleft 2003-2015 http: www.videolan.org x264.html options: cabac="1" ref="3" deblock="1:0:0" analyse="0x3:0x113" me="hex" subme="7" psy="1" psy_rd="1.00:0.00" mixed_ref="1" me_range="16" chroma_me="1" trellis="1" 8x8dct="1" cqm="0" deadzone="21,11" fast_pskip="1" chroma_qp_offset="-2" threads="19" lookahead_threads="3" sliced_threads="0" nr="0" decimate="1" interlaced="0" bluray_compat="0" constrained_intra="0" bframes="3" b_pyramid="2" b_adapt="1" b_bias="0" direct="1" weightb="1" open_gop="0" weightp="2" keyint="250" keyint_min="25" scenecut="40" intra_refresh="0" rc_lookahead="40" rc="crf" mbtree="1" crf="23.0" qcomp="0.60" qpmin="0" qpmax="69" qpstep="4" ip_ratio="1.40" aq="1:1.00" output mp4, to 'guanji.mp4': lavf56.40.101 h264 (libx264) ([33][0][0][0] 0x0021), q="-1--1," lavc56.60.100 libx264 #0:1: aac ([64][0][0][0] 0x0040), stereo, fltp, mapping: #1:0> #0:0 (mpeg4 (native) -> h264 (libx264))
Stream #0:0 -> #0:1 (pcm_f32le (native) -> aac (native))
Press [q] to stop, [?] for help
frame= 305 fps=161 q=-1.0 Lsize= 579kB time=00:00:12.30 bitrate= 385.1kbits/s
video:373kB audio:195kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 1.829867%
[1;36m[libx264 @ 0x1c25ea0] [0mframe I:2 Avg QP:17.00 size: 65208
[1;36m[libx264 @ 0x1c25ea0] [0mframe P:77 Avg QP:17.98 size: 2572
[1;36m[libx264 @ 0x1c25ea0] [0mframe B:226 Avg QP:24.89 size: 233
[1;36m[libx264 @ 0x1c25ea0] [0mconsecutive B-frames: 1.0% 0.7% 0.0% 98.4%
[1;36m[libx264 @ 0x1c25ea0] [0mmb I I16..4: 9.4% 86.0% 4.6%
[1;36m[libx264 @ 0x1c25ea0] [0mmb P I16..4: 0.1% 1.1% 0.0% P16..4: 10.5% 2.2% 2.1% 0.0% 0.0% skip:84.1%
[1;36m[libx264 @ 0x1c25ea0] [0mmb B I16..4: 0.0% 0.1% 0.0% B16..8: 5.9% 0.1% 0.0% direct: 0.0% skip:93.8% L0:49.8% L1:49.1% BI: 1.2%
[1;36m[libx264 @ 0x1c25ea0] [0m8x8 transform intra:86.9% inter:85.1%
[1;36m[libx264 @ 0x1c25ea0] [0mcoded y,uvDC,uvAC intra: 80.0% 88.4% 48.8% inter: 1.4% 2.1% 0.2%
[1;36m[libx264 @ 0x1c25ea0] [0mi16 v,h,dc,p: 40% 31% 20% 9%
[1;36m[libx264 @ 0x1c25ea0] [0mi8 v,h,dc,ddl,ddr,vr,hd,vl,hu: 35% 19% 27% 3% 2% 3% 2% 3% 6%
[1;36m[libx264 @ 0x1c25ea0] [0mi4 v,h,dc,ddl,ddr,vr,hd,vl,hu: 49% 27% 9% 3% 2% 3% 2% 3% 3%
[1;36m[libx264 @ 0x1c25ea0] [0mi8c dc,h,v,p: 32% 24% 34% 10%
[1;36m[libx264 @ 0x1c25ea0] [0mWeighted P-Frames: Y:0.0% UV:0.0%
[1;36m[libx264 @ 0x1c25ea0] [0mref P L0: 73.2% 5.9% 12.9% 8.0%
[1;36m[libx264 @ 0x1c25ea0] [0mref B L0: 79.9% 16.3% 3.8%
[1;36m[libx264 @ 0x1c25ea0] [0mref B L1: 92.7% 7.3%
[1;36m[libx264 @ 0x1c25ea0] [0mkb/s:249.97
[0m
</00:00,>
成果展示–让蒙娜丽莎播报新闻
视频比较长的话,运行时间会稍长,建议把视频下载到本地预览
import cv2
import imageio
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
import warnings
def display(driving, fps, size=(8, 6)):
fig = plt.figure(figsize=size)
ims = []
for i in range(len(driving)):
cols = []
cols.append(driving[i])
im = plt.imshow(np.concatenate(cols, axis=1), animated=True)
plt.axis('off')
ims.append([im])
video = animation.ArtistAnimation(fig, ims, interval=1000.0/fps, repeat_delay=1000)
plt.close()
return video
video_path = 'guanji.mp4'
video_frames = imageio.mimread(video_path, memtest=False)
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
HTML(display(video_frames, fps).to_html5_video())
基于PaddleGAN精准唇形合成实现持枪人讲电话已关机
总结
首先帮大家总结一波:让图片会说话、视频花式配音的魔法–Wav2lip的使用只用三步:
- 安装Paddle环境并下载PaddleGAN
- 选择想要「配音/对口型」的对象以及音频内容
- 运行代码并保存制作完成的对口型视频分享惊艳众人
贴心的送上项目传送门:PaddleGAN 记得点Star关注噢~~
; 除了嘴型同步,PaddleGAN还有哪些魔法?
PaddleGAN是只能做「对口型」的应用么?NONONO!当然不是!!
接下来就给大家展示下PaddleGAN另外的花式应用,如各类 图形影像生成、处理能力。
人脸属性编辑能力能够在人脸识别和人脸生成基础上,操纵面部图像的单个或多个属性,实现换妆、变老、变年轻、变换性别、发色等,一键换脸成为可能;
动作迁移,能够实现肢体动作变换、人脸表情动作迁移等等等等。
强烈鼓励大家玩起来,激发PaddleGAN的潜能!
欢迎加入官方QQ群(1058398620)与各路技术高手交流~~
Original: https://blog.csdn.net/weixin_41450123/article/details/113426106
Author: AI小鸭学院
Title: 基于PaddleGAN精准唇形合成实现持枪人讲电话已关机
相关阅读1
Title: nodejs队列
nodejs队列
创建具有指定并发性的队列对象。添加到队列的任务以并行方式处理(直到并发性限制)。如果所有的worker都在进行中,任务就会排队,直到有一个worker可用。worker完成任务后,将调用该任务的回调。
priorityQueue对象,queue和priorityQueue对象有两个区别: push(任务,优先级,[回调])-优先级应该是一个数字。如果给定了一组任务,则所有任务将被分配相同的优先级。没有unshift 。
// create a queue object with concurrency 2
var q = async.queue(function(task, callback) {
console.log('hello ' + task.name);
callback();
}, 2);
// assign a callback
q.drain(function() {
console.log('all items have been processed');
});
// or await the end
// await q.drain()
// assign an error callback
q.error(function(err, task) {
console.error('task experienced an error');
});
// add some items to the queue
q.push({name: 'foo'}, function(err) {
console.log('finished processing foo');
});
// callback is optional
q.push({name: 'bar'});
// add some items to the queue (batch-wise)
q.push([{name: 'baz'},{name: 'bay'},{name: 'bax'}], function(err) {
console.log('finished processing item');
});
// add some items to the front of the queue
q.unshift({name: 'bar'}, function (err) {
console.log('finished processing bar');
});
//--------------------------
// create a queue object with concurrency 1
var q = async.priorityQueue(function(task, callback) {
console.log('Hello ' + task.name);
callback();
}, 1);
// assign a callback
q.drain = function() {
console.log('All items have been processed');
};
// add some items to the queue with priority
q.push({name: 'foo3'}, 3, function(err) {
console.log('Finished processing foo');
});
q.push({name: 'bar2'}, 2, function (err) {
console.log('Finished processing bar');
});
// add some items to the queue (batch-wise) which will have same priority
q.push([{name: 'baz1'},{name: 'bay1'},{name: 'bax1'}], 1, function(err) {
console.log('Finished processing item');
});
输出结果如下:
hello bar
finished processing bar
hello foo
finished processing foo
hello bar
hello baz
finished processing item
hello bay
finished processing item
hello bax
finished processing item
all items have been processed
Hello bay1
Finished processing item
Hello bax1
Finished processing item
Hello bar2
Finished processing bar
Hello foo3
Finished processing foo
参考:
https://github.com/caolan/async/blob/v1.5.2/README.md
https://medium.com/velotio-perspectives/understanding-node-js-async-flows-parallel-serial-waterfall-and-queues-6f9c4badbc17
作者:
iTech
微信公众号: cicdops
github:
https://github.com/cicdops/cicdops

Original: https://www.cnblogs.com/itech/p/13253505.html
Author: iTech
Title: nodejs队列
相关阅读2
Title: [异常检测] Graph Embedded Pose Clustering for Anomaly Detection
Graph Embedded Pose Clustering for Anomaly Detection
会议:CVPR 2020
单位:Tel-Aviv University, Alibaba Group
论文:arxiv
代码:code
创新
从输入视频序列计算得到 人体姿态图,之后通过 时空图卷积自编码器和 聚类将这些姿态图映射到隐空间
提出了两种粒度的异常检测
- 粗粒度,指定某类行为是正常其余为异常行为(ShanghaiTech Campus数据集上)
- 细粒度,指定某类行为为异常其余非异常行为 (NTU-RGB+D、Kinetics 400数据集上)
人体姿态图的好处
- 使得问题更抽象,算法只关注人体姿态不受无关特征的影响比如光照,视角
- 人体姿态图更紧凑,使得推理、训练和测试更快
网络结构
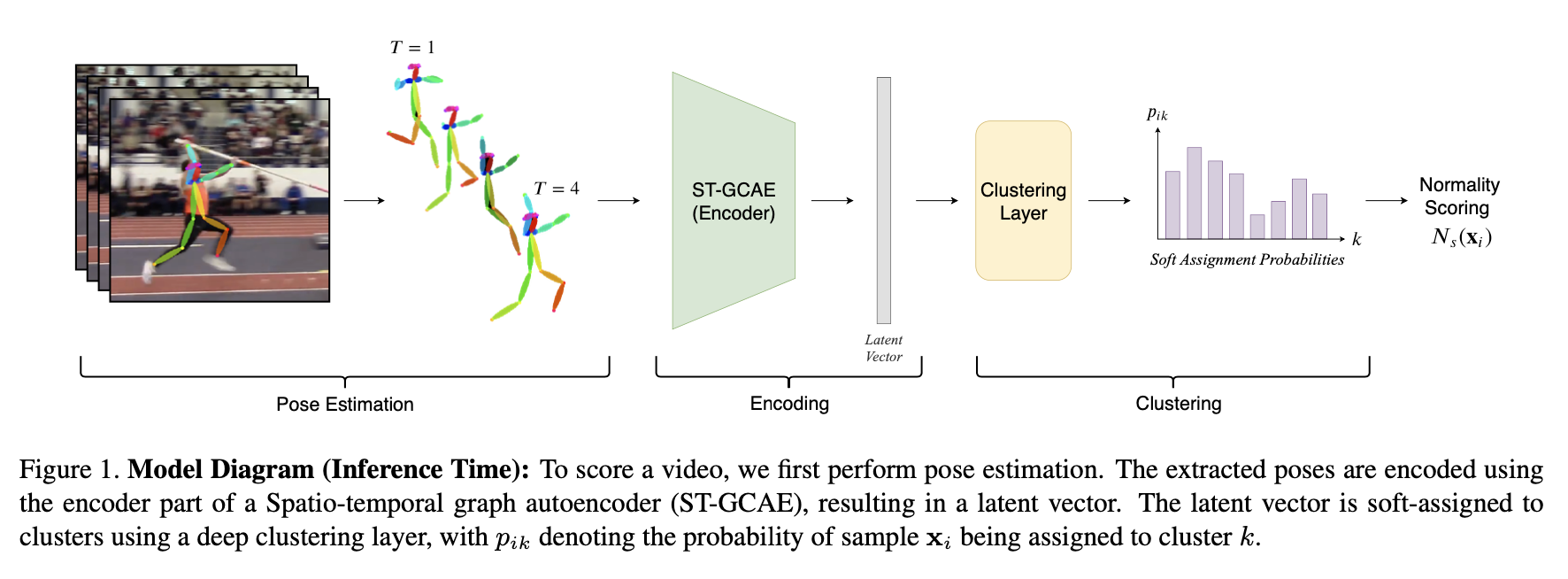
; 时空图卷积自编码
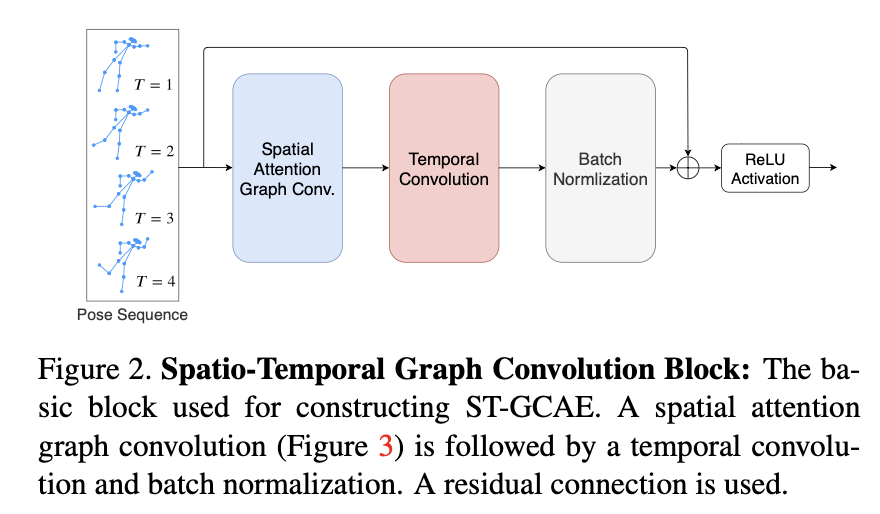
使用ST-GCN块(GCN算子由空间注意力图卷积替换)来构造时空图卷积自编码器(ST-GCAE)
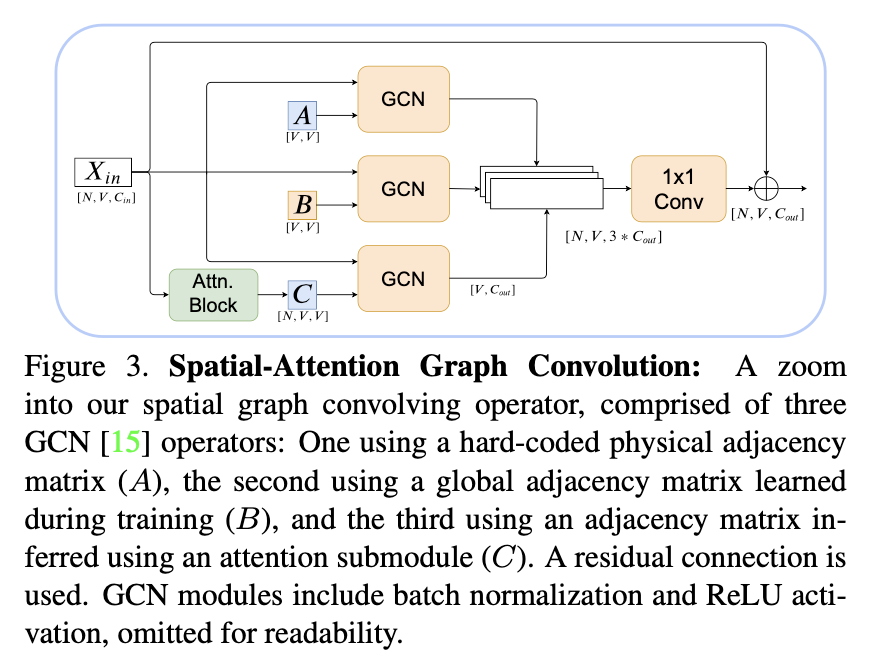
三种类型的邻接矩阵
- 身体部位物理邻接矩阵
- 数据集相关的关键点关系(训练中学习得到)
- 自注意力模块推理得到(特定于样本)
聚类
对于每个输入样本x i \mathbf{x}{i}x i 用z i \mathbf{z}{i}z i 表示编码器的隐向量,y i \mathbf{y}{i}y i 计算软聚类,Θ \Theta Θ表示聚类层参数,p i k p{i k}p i k 表示第i i i个样本分配到第k k k簇的概率
p i k = Pr ( y i = k ∣ z i , Θ ) = exp ( θ k T z i ) ∑ k ′ = 1 K exp ( θ k ′ T z i ) p_{i k}=\operatorname{Pr}\left(y_{i}=k \mid \mathbf{z}{i}, \Theta\right)=\frac{\exp \left(\boldsymbol{\theta}{k}^{T} \mathbf{z}{i}\right)}{\sum{k^{\prime}=1}^{K} \exp \left(\boldsymbol{\theta}{k^{\prime}}^{T} \mathbf{z}{i}\right)}p i k =P r (y i =k ∣z i ,Θ)=∑k ′=1 K exp (θk ′T z i )exp (θk T z i )
聚类的目标函数是最小化当前模型预测分布P和目标分布Q之间的KL散度
L c l u s t e r = K L ( Q ∥ P ) = ∑ i ∑ k q i k log q i k p i k L_{c l u s t e r}=K L(Q \| P)=\sum_{i} \sum_{k} q_{i k} \log \frac{q_{i k}}{p_{i k}}L c l u s t e r =K L (Q ∥P )=i ∑k ∑q i k lo g p i k q i k
其中
q i k = p i k / ( ∑ i ′ p i ′ k ) 1 2 ∑ k ′ p i k ′ / ( ∑ i ′ p i ′ k ′ ) 1 2 q_{i k}=\frac{p_{i k} /\left(\sum_{i^{\prime}} p_{i^{\prime} k}\right)^{\frac{1}{2}}}{\sum_{k^{\prime}} p_{i k^{\prime}} /\left(\sum_{i^{\prime}} p_{i^{\prime} k^{\prime}}\right)^{\frac{1}{2}}}q i k =∑k ′p i k ′/(∑i ′p i ′k ′)2 1 p i k /(∑i ′p i ′k )2 1
Normality Scoring
狄利克雷过程混合模型(Dirichlet Process Mixture Model, DPMM)是一种非参数贝叶斯模型,它可以理解为一种聚类方法,但是不需要指定类别数量,它可以从数据中推断簇的数量
实验
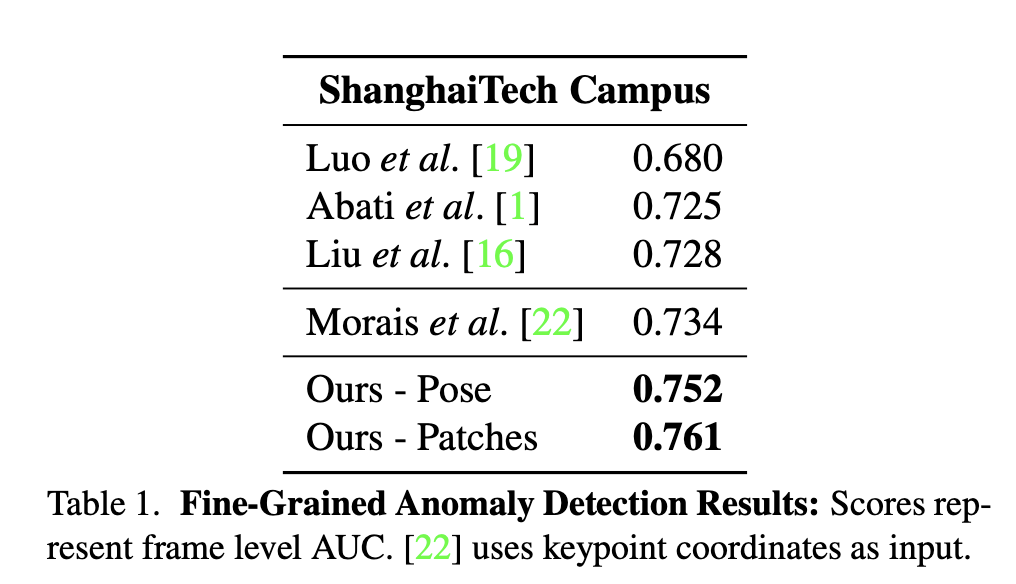
ShangHaiTech数据集 细粒度异常检测
关节点坐标作为输入特征没有关节点小图做特征效果好
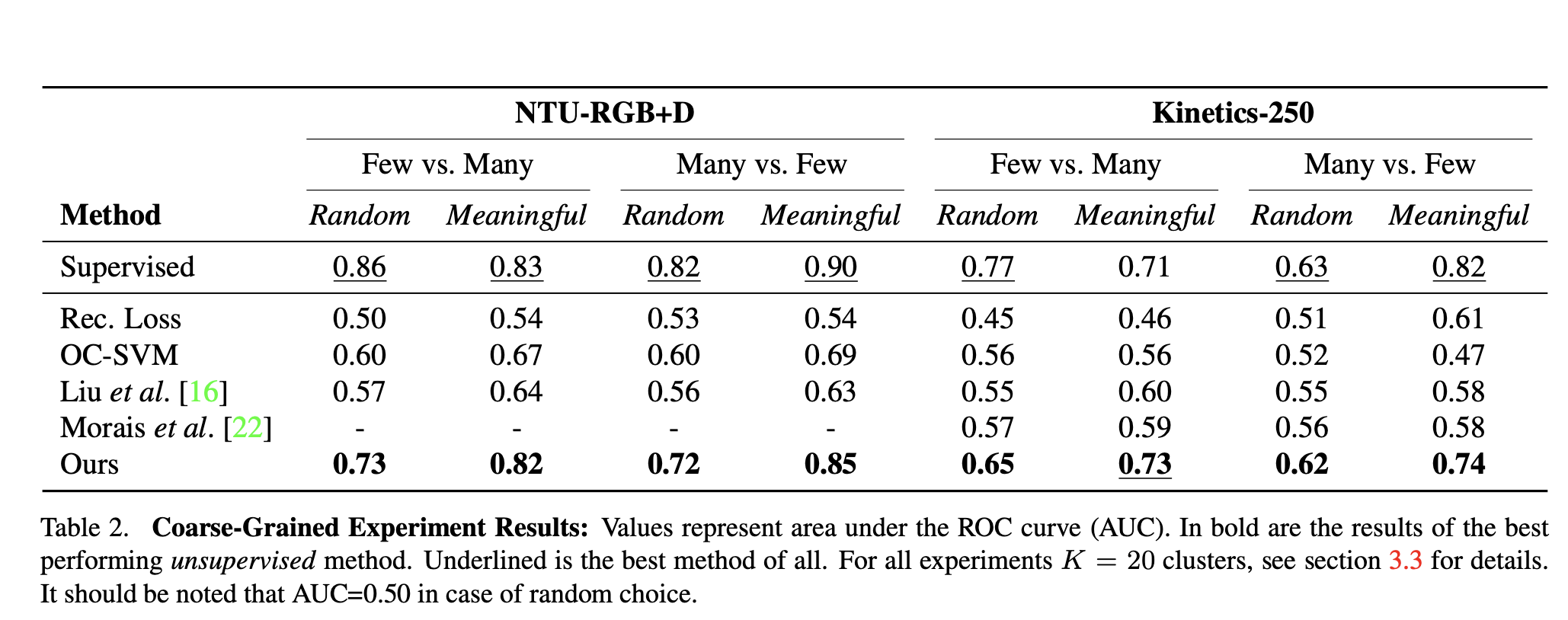
; NTU-RGB+D、Kinetics 400 粗粒度异常检测
使用10个随机和10个有意义的分割来评估每个数据集
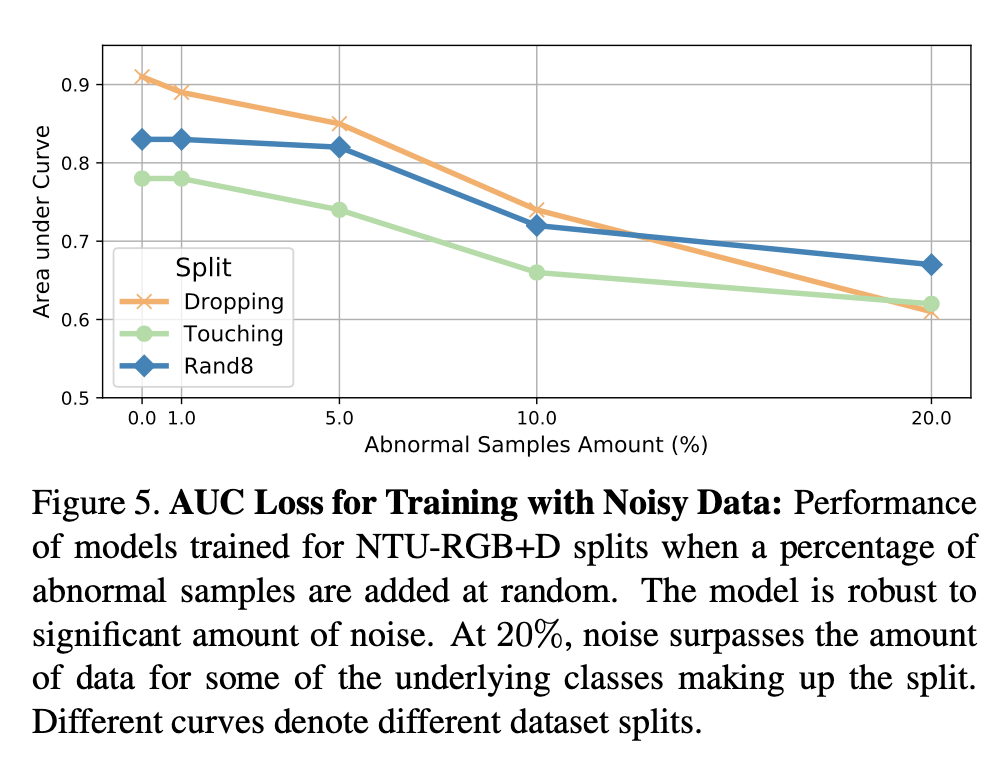
消融实验
评估模型对噪声的鲁棒性,即在训练集中存在一定百分比的异常动作
Original: https://blog.csdn.net/qq_32815807/article/details/122094629
Author: BENULL
Title: [异常检测] Graph Embedded Pose Clustering for Anomaly Detection
相关阅读3
Title: DQN算法&流程图&代码实现(Tensorflow2.x / Keras)
一、DQN详解
1) Qlearning --> DQN
- 对于 离散状态空间,若智能体所处的状态成千上万,用Qlearning表格法存储状态很不实际,对于连续状态空间同理。
- 为了在 连续状态空间下应用类似Qlearning的学习方式,需要对值函数进行逼近,故出现了DQN算法。
2) DQN实现流程
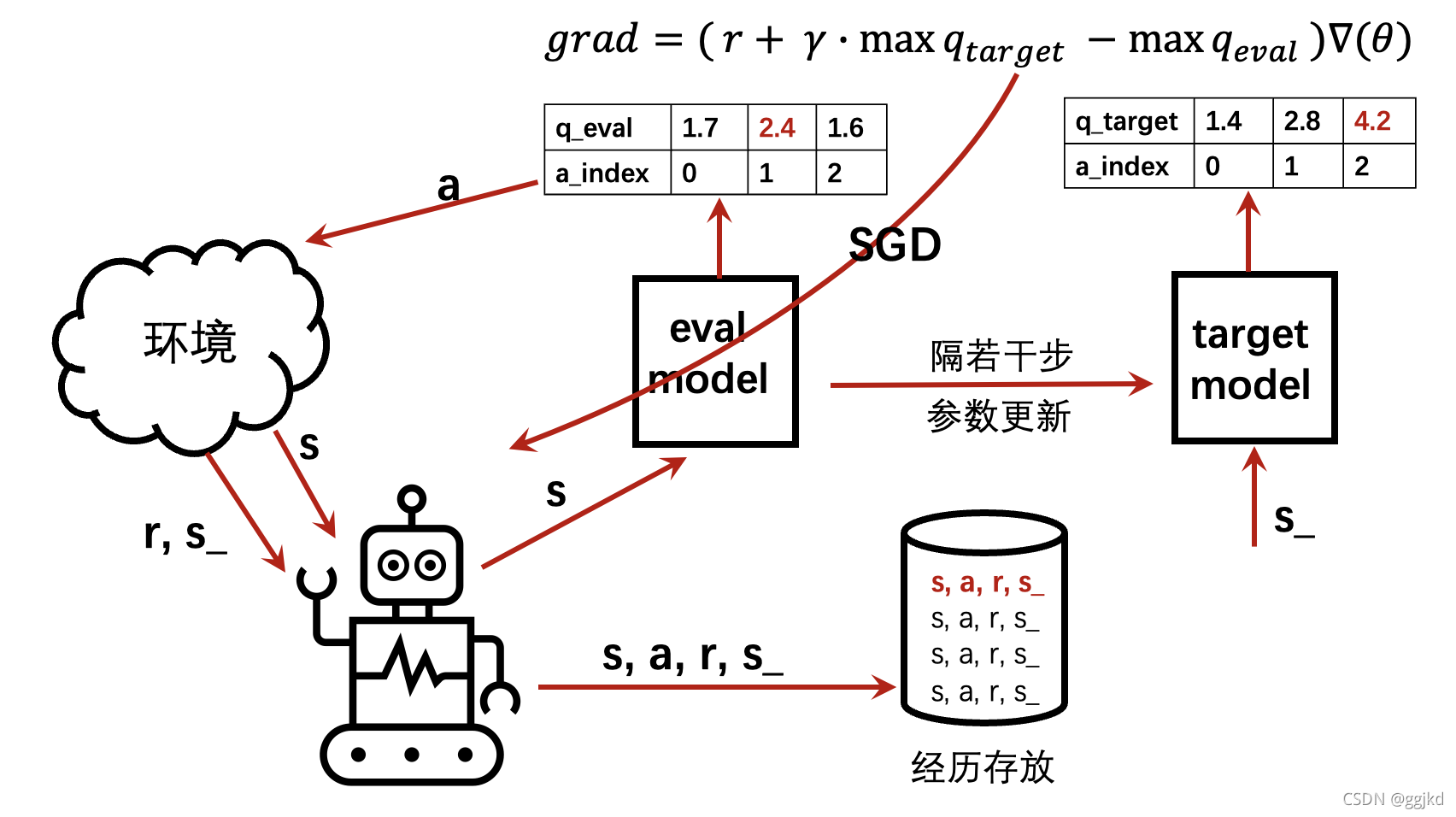 s : 当前状态
s : 当前状态
a : 当前s下,智能体根据策略(eval_model)给出决策a
r, s_ : 当前s下,做出行为a,环境给出奖励r,并跳转状态至s_
具体步骤:
1)初始化状态s;
2)初始化eval_model 和 target_model,其中eval_model为决策网络,后续 算法主动更新的是eval_model;target_model为目标网络,主要生成 TD_error,作为更新算法中的一部分,eval_model和eval_model:结构相同、参数相同;
3)初始化记忆容器memory
4) s --> eval_model --> a ,遵循epsilon-greedy
5) 环境根据动作a反馈奖励r和下一个状态s_
6) 将(s,a,r,s_)存储在记忆容器memory中, 新经历覆盖旧记忆
7) memory中经历足够多时进行算法更新,主动更新eval_model的参数:
每隔若干步就进行一次eval_model参数更新,从经历库中随机提取batch进行训练更新,更新依据梯度grad,其中:
grad = r + y * max q_target矩阵(batch nums_action)- max q_eval(batch * nums_action)
⚠️矩阵相减的时候, 需要保证q_target矩阵的最大值和q_eval矩阵的最大值在同一个位置。*
8)每隔若干步,将eval_model的参数assign至 target_model
; 3) 实例(基于Tensorflow2.x / Keras):
基于 Keras实现机器玩迷宫游戏。
其中网络建立部分:
from keras import layers, Model, Input
from keras.optimizers import RMSprop
import numpy as np
import matplotlib.pyplot as plt
class DQN:
def __init__(self, n_features, n_actions):
self.n_features = n_features
self.n_actions = n_actions
self.lr = 0.01
self.gamma = 0.9
self.replace_target_iter = 300
self.memory_size = 5000
self.batch_size = 60
self.epsilon_max = 0.99
self.epsilon_increment = 0.05
self.epsilon = 0 if self.epsilon_increment is not None else self.epsilon_max
self.learn_step_counter = 0
self.memory = np.zeros((self.memory_size, n_features*2+2))
self.model_eval = self.create_eval(n_actions, n_features)
self.model_target = self.create_target(n_actions, n_features)
self.model_eval.compile(optimizer=RMSprop(lr=self.lr), loss='mse')
self.cost_his = []
def create_eval(self, n_actions, n_features):
input_tensor = Input(shape=(n_features,))
x = layers.Dense(32, activation='relu')(input_tensor)
x = layers.Dense(32, activation='relu')(x)
output_tensor = layers.Dense(n_actions)(x)
model = Model(input_tensor, output_tensor)
model.summary()
return model
def create_target(self, n_actions, n_features):
input_tensor = Input(shape=(n_features,))
x = layers.Dense(32, activation='relu', trainable=False)(input_tensor)
x = layers.Dense(32, activation='relu', trainable=False)(x)
output_tensor = layers.Dense(n_actions)(x)
model = Model(input_tensor, output_tensor)
model.summary()
return model
def store_transition(self, s, a, r, s_):
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
transition = np.hstack((s, [a, r], s_))
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def choose_action(self, observation):
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
action_value = self.model_eval.predict(observation)
action = np.argmax(action_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def _replace_target_params(self):
for eval_layer, target_layer in zip(self.model_eval.layers, self.model_target.layers):
target_layer.set_weights(eval_layer.get_weights())
def learn(self):
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
batch_memory = self.memory[sample_index, :]
q_next = self.model_target.predict(batch_memory[:, -self.n_features:])
q_eval = self.model_eval.predict(batch_memory[:, :self.n_features])
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
eval_act_index = batch_memory[:, self.n_features].astype(int)
reward = batch_memory[:, self.n_features + 1]
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
if self.learn_step_counter % self.replace_target_iter == 0:
self._replace_target_params()
cost = self.model_eval.train_on_batch(batch_memory[:, :self.n_features], q_target)
self.cost_his.append(cost)
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('mse')
plt.xlabel('training steps')
plt.show()
代码风格主要参考莫凡,完整代码详见github
https://github.com/huafeng97/DQN.git
二、 DQN变种:Double_DQN和Duel_DQN
DDQN:我们知道,DQN在基于target_model进行状态评估的过程中,首先要基于eval_model先选择最大Q(s_)对应的action,然后把这个action对应的最大Q(s_)值赋给eval_model要优化的action位置上,显然前后涉及的两个Q(s_)是相等的。这使得传统DQN在值函数估计上与真实值偏差较大。
DDQN稍作改变,将状态评估过程中,先根据ANN1选择最大Q(s_)对应的action,然后再根据选定的action的位置索引到target_model的Q(s_,a)对上,从而选出Q值(实际这个Q值在target_model这边可能并不是最大值)。这种操作,可以获得更准确地估计Q值。
Duel_DQN:将值函数分解成价值和优势,值函数在不同状况下对价值和优势的敏感程度不同,例如自动驾驶,在无其他汽车的路面上,价值对值函数的影响较大;若汽车靠近其他车辆,则优势对值函数的影响较大。它不像DoubleDQN改变的是算法,它改变的是网络结构,将原来的单Q输出,变成了双输出(价值和优势)
三、 为什么不打破数据相关性,DQN神经网络的训练效果就不好
智能体对值函数很敏感,直接影响智能体的决策,而一个连续相关的数据集会使得智能体一直朝着该数据集建议的方向(R值较大)进行探索,若此时另一个数据集出现,智能体又不得不向着另一个方向探索。于是,数据间前后的相互依赖性会对智能体学习、更新策略造成严重的波动,最后很难学到真正的最优策略,也就是难以收敛。还有一个问题就是连续数据段变化带来的可能的值函数突变,将导致神经网络反向传播时梯度爆炸,导致神经网络无法收敛,所以才要用经历回放并随机采样,从一开始反向传播的过程中,就解决梯度瞬间增大的问题。
Original: https://blog.csdn.net/ggjkd/article/details/114802685
Author: ggjkd
Title: DQN算法&流程图&代码实现(Tensorflow2.x / Keras)