
1、简介
最近使用Bert实现了文本分类,模型使用的是bert的base版本。本文记录一下实现过程。
数据集:cnews,包含三个文件,分别是cnews.train.txt、cnews.test.txt、cnews.val.txt。类别包含10类,分别是:体育、娱乐、家居、房产、教育、时尚、时政、游戏、科技、财经。
代码参考:https://github.com/BeHappyForMe/Multi_Model_Classification,对代码的一些部分作了修改和注解。关注公众号"AI小浩",回复"bert实战",获取代码和数据集。
2、下载代码和数据集
数据集的地址:
链接:https://pan.baidu.com/s/1JKiaexp0oQeJF02UUX5eSw
提取码:2222
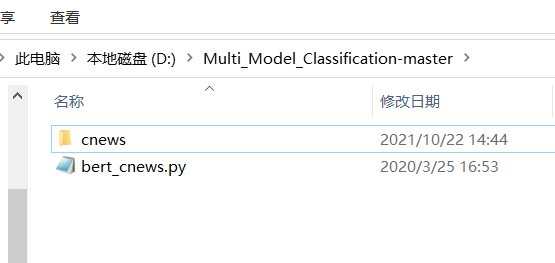
下载代码后,将代码解压到指定的目录,让后将数据集放进去。删除其他的模型只保留bert的。如下图:
安装transformers
pip install transformers
3、下载预训练模型。
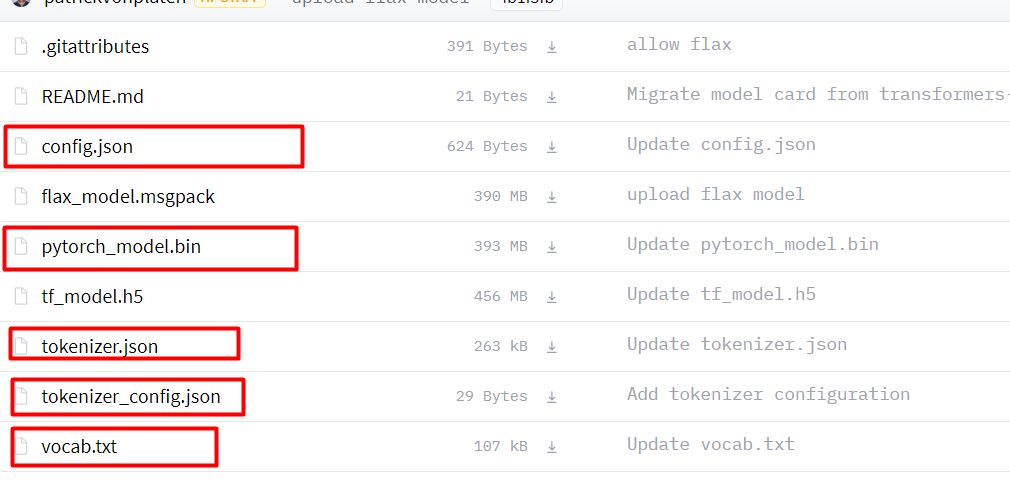
链接:bert-base-chinese at main (huggingface.co),将下图中,画红框的文件下载下来。在项目的根目录新建chinese_wwm_pytorch文件夹,将下载的文件放进去。
新建outs文件夹,将config.json、tokenizer.json、tokenizer_config.json和vocab.txt复制到outs文件夹中。
注:模型的类型在configuration_bert.py中查看。选择合适的模型很重要,比如这次是中文文本的分类。选择用bert-base-uncased只能得到86%的准确率,但是选用bert-base-chinese就可以轻松达到96%。
; 4、修改bert_cnews.py代码
对68行的代码做修改。原始代码如下:
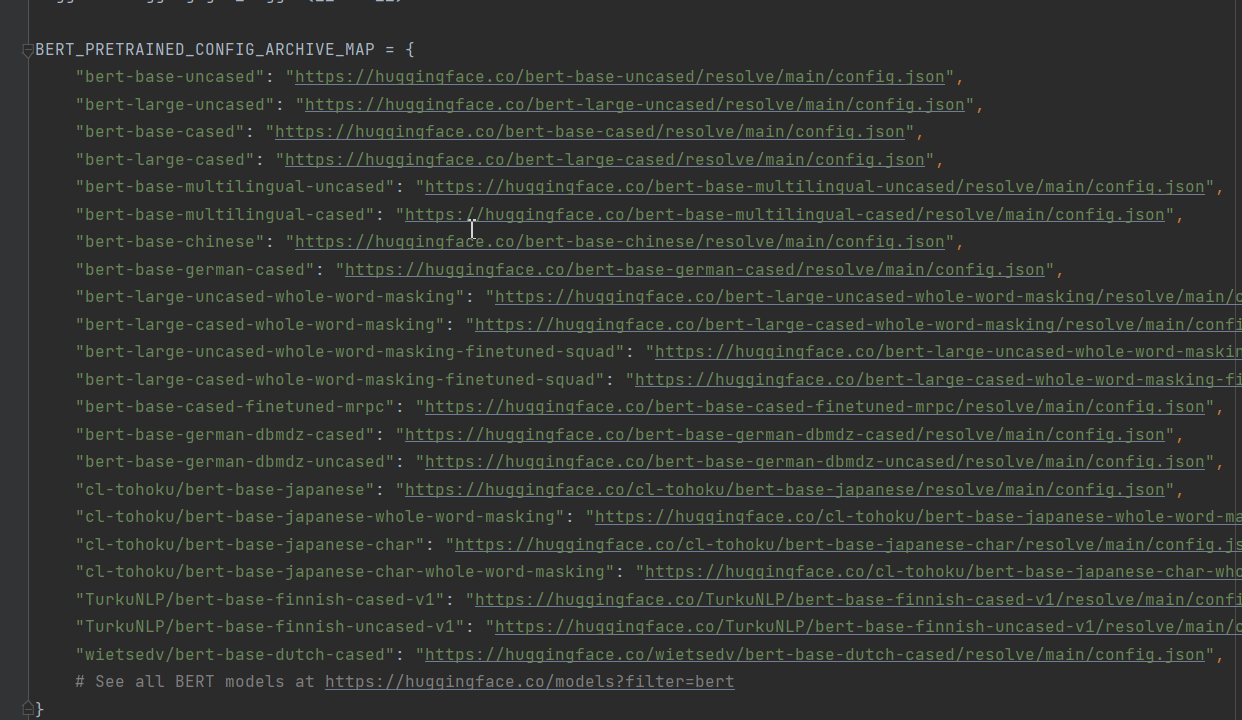
ALL_MODELS = sum((tuple(conf.pretrained_config_archive_map.keys()) for conf in (BertConfig, XLNetConfig, XLMConfig,
RobertaConfig, DistilBertConfig)), ())
修改为:
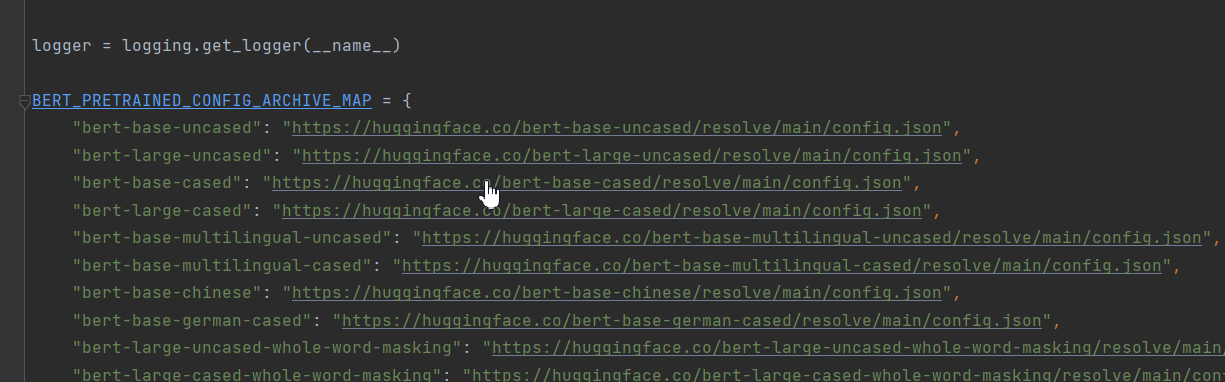
ALL_MODELS=tuple(BERT_PRETRAINED_CONFIG_ARCHIVE_MAP)
作者想把BertConfig、XLNetConfig、XLMConfig、RobertaConfig, DistilBertConfig等都导进来。可能是版本的升级pretrained_config_archive_map这个字段做了修改,以Bert为例,这个字段改为了'BERT_PRETRAINED_CONFIG_ARCHIVE_MAP'。本次案例只是对Bert的讲解,所以我只保留了Bert的字段。
5、修改main()方法中的参数。
data_dir:数据集的路径,改为"./cnews"。
parser.add_argument("--data_dir", default='./cnews', type=str, required=False,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.")
model_type:模型的类型,MODEL_CLASSES的参数,本次使用bert。
parser.add_argument("--model_type", default='bert', type=str, required=False,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()))
model_name_or_path:预训练模型的存放路径,设置为'chinese_wwm_pytorch'。
parser.add_argument("--model_name_or_path", default='chinese_wwm_pytorch', type=str, required=False,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(
ALL_MODELS))
这个文件下面的文件详见下图:

task_name:任务名称。我写的cnews
parser.add_argument("--task_name", default='cnews', type=str, required=False,
help="The name of the task to train selected in the list: " + ", ".join(processors.keys()))
do_train:是否训练。需要训练则设置为true。
parser.add_argument("--do_train", default=True,action='store_true',
help="Whether to run training.")
do_eval:是否验证,如果设置为true,则将outs的模型一一验证。和do_train可以同时配置为true,这样训练完成后就开始验证。
parser.add_argument("--do_eval",default=True, action='store_true',
help="Whether to run eval on the dev set.")
evaluate_during_training:是否在训练期间验证。默认没有配置。如果需要配置,则将其设置为true。
parser.add_argument("--evaluate_during_training", action='store_true',
help="Rul evaluation during training at each logging step.")
do_lower_case:是否转小写。使用uncased模型时需要设置。
parser.add_argument("--do_lower_case",action='store_true',
help="Set this flag if you are using an uncased model.")
per_gpu_train_batch_size和per_gpu_eval_batch_size:batch_size大小,根据显卡合理设置。
parser.add_argument("--per_gpu_train_batch_size", default=4, type=int,
help="Batch size per GPU/CPU for training.")
parser.add_argument("--per_gpu_eval_batch_size", default=4, type=int,
help="Batch size per GPU/CPU for evaluation.")
learning_rate:学习率,默认设置即可。
parser.add_argument("--learning_rate", default=2e-5, type=float,
help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float,
num_train_epochs:epochs大小。
parser.add_argument("--num_train_epochs", default=50.0, type=float,
help="Total number of training epochs to perform.")
save_steps:迭代多少次保存一次模型。
parser.add_argument('--save_steps', type=int, default=12500,
help="Save checkpoint every X updates steps.")
上面的参数是比较重要的参数,将这些参数配置好可以训练了。
5、验证
验证还有一步要做,config.json、tokenizer.json、tokenizer_config.json、vocab.txt。复制一份到outs文件夹。
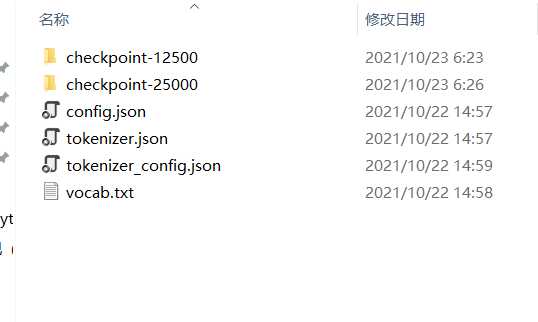
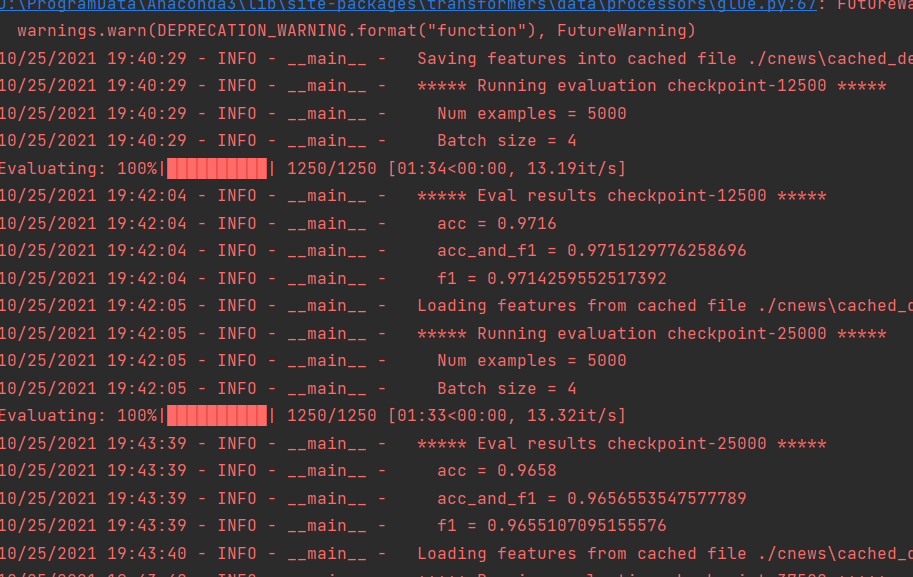
等训练完成就可以测试了。
关注公众号"AI小浩",回复'bert分类',获取代码、模型和数据。
Original: https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/120959018
Author: AI浩
Title: Bert实战:使用Bert实现文本分类。
相关阅读1
Title: Debiased Contrastive Learning of Unsupervised Sentence Representation无监督句子表示中的对比学习去偏
论文地址:https://arxiv.org/abs/2205.00656v1
Comments:11 pages, accepted by ACL 2022 main conferenceSubjects:Computation and Language (cs.CL)Cite as:arXiv:2205.00656 [cs.CL] (or arXiv:2205.00656v1 [cs.CL] for this version) https://doi.org/10.48550/arXiv.2205.00656

自己也是看了别人的讲解,来源:B站揣摩研习社 记录以学习回忆
研究背景
对比学习通过子监督的方式预训练,可以促使模型得到高质量的句子表示。
对比学习一般采用随机组成的batch内其它样本作为负例,这一采样方式可能会导致采样偏差。
batch内其他样本也不一定全是负样本。
由于PLM表示是各向异性的,只使用PLM的表示来优化是不充分的。
(自注:PLM是什么?这里指的是 与训练语言模型。这里它提到用PLM表示的空间像一个锥形空间,用这个锥形空间不充分)
对比学习概念 Contrastive learning
同一个样本经过两个不同的数据增强作为一个正样本对。
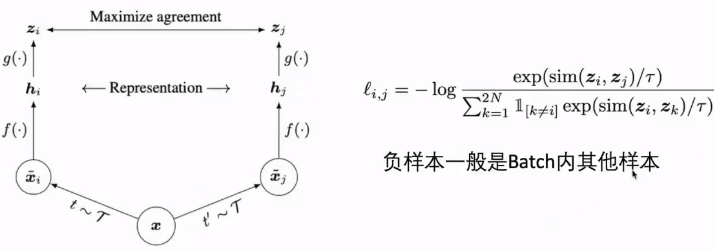
本文方法
提出了两种方法
1.基于噪声生成负例
缓解各向异性导致的优化不充分问题
2.设计负样本权重
缓解false negative问题(自注:这里false negative到底是什么问题 不太明确啊 难带是这个?False Negative (简称FN):判断为负,但是判断错了。(实际为正))
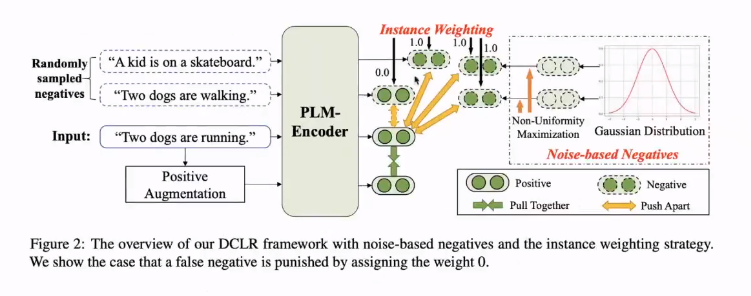
基于噪声生成负例
从高斯分布采样k个噪声向量,作为PLM表示空间外的负例(自注:这里PLM表示空间外是什么意思,还得看看原文)
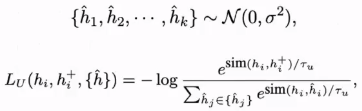
为了提高负例的质量,利用梯度提升来调整k个噪声负例

设计负样本权重
利用预训练好的SimSCE计算样本表示的相似度,根据相似度设定权重。
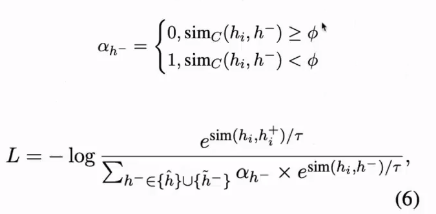
自注:小于阈值 就说明是个负样本。这里好奇怪啊,你这个本来就是生成更好的句向量,怎么还用到了别人的句向量模型SimCSE
模型方法
实验部分
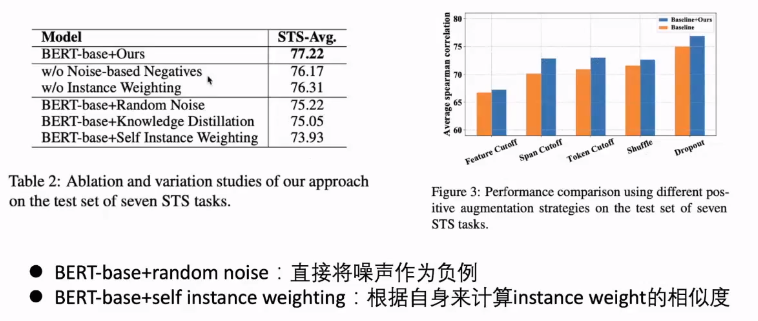
数据集:STS-语义相似度
预训练模型 :BERT RoBERTa
评价方式:语义相似度:余弦相似度于groud truth相似度的Sperman相关洗漱
消融实验
Original: https://www.cnblogs.com/nlpers/p/16298493.html
Author: nlp如此迷人
Title: Debiased Contrastive Learning of Unsupervised Sentence Representation无监督句子表示中的对比学习去偏
相关阅读2
Title: 回声消除性能评判指标
为了反映回声消除中自适应滤波器r 1 ( n ) r_1(n)r 1 (n )对真实回声路径r(n)的逼近程度。系统距离,定义为:
D I S T ( n ) = 10 l g ∣ ∣ r 1 ( n ) − r ( n ) ∣ ∣ 2 ∣ ∣ r ( n ) ∣ ∣ 2 DIST(n) = 10lg \frac{||r_1(n)-r(n)||^2}{||r(n)||^2}D I S T (n )=1 0 l g ∣∣r (n )∣∣2 ∣∣r 1 (n )−r (n )∣∣2
其中DIST值越低,表明自适应滤波器的收敛性能越好
为了衡量回声消除效果,因为单讲和双讲场景对输出信号e(n)要求不一样,只有近端单讲时要求e(n)与麦克风采集信号d(n)尽量一致,只有远端单讲时需要对e(n) 尽量抑制,双讲时需要保持近端语音尽量一致同时抑制回声,所以我们对单讲双讲部分需要使用不同指标进行评价。
1,ERLE(Echo Return Loss Enhancement,回声返回衰减增益):
E R L E = 10 l g E [ d 2 ( n ) ] E [ e 2 ( n ) ] ERLE = 10lg \frac{E[d^2(n)]}{E[e^2(n)]}E R L E =1 0 l g E [e 2 (n )]E [d 2 (n )]
ERLE值越大,则表明回声抵消效果越好。由于双讲或只有近端单讲时,e(n)中包含近端语音,导致很多情况下e(n)的能量远大于回声y(n)的能量,从而ERLE为负值,同时也无法衡量回声部分的消除情况。
对于优秀的回声消除器,返回衰减增益必须不低于6dB.
2,SuppFactor(能量衰落因子):
AEC后输出能量与对应麦克风信号能量的比值。
S u p p F a c t o r = E [ ∣ e ∣ 2 ( n ) ] E [ ∣ x ∣ 2 ( n ) ] SuppFactor = \frac{E[|e|^2(n)]}{E[|x|^2(n)]}S u p p F a c t o r =E [∣x ∣2 (n )]E [∣e ∣2 (n )]
3,cohde(输出信号e(n)与麦克风信号d(n)的频谱相关性):
该值越接近1,说明输出信号中保留的麦克风信号频谱越多。考虑到麦克风信号d(n)主要由回声信号y(n)和近端语音v(n)构成,因此只有近端单讲情况下cohde的值才能接近1,双讲情况下cohde的值在0.5~0.9(取决于回声信号在该帧的占比),当cohde接近0时说明输出信号几乎不包含任何近端语音和回声的频谱成分。其计算公式如下:
S d = D ( ω ) D ∗ ( ω ) S_d = D(\omega)D*(\omega)S d =D (ω)D ∗(ω)
S e = E ( ω ) E ∗ ( ω ) S_e = E(\omega)E*(\omega)S e =E (ω)E ∗(ω)
S d e = D ( ω ) E ∗ ( ω ) S_{de} = D(\omega)E*(\omega)S d e =D (ω)E ∗(ω)
C o h d e = ∣ S d e ∣ 2 ∣ S d ∗ S e ∣ Cohde=\frac{|S_{de}|^2}{|S_d*S_e|}C o h d e =∣S d ∗S e ∣∣S d e ∣2
4,cohxe(输出信号e(n)与远端参考信号x(n)的频谱相关性):
该值越接近0,说明输出信号中残留的远端参考信号频谱越少,回声消除越彻底,其计算公式如下:
S x = X ( ω ) X ∗ ( ω ) S_x = X(\omega)X*(\omega)S x =X (ω)X ∗(ω)
S e = E ( ω ) E ∗ ( ω ) S_e = E(\omega)E*(\omega)S e =E (ω)E ∗(ω)
S x e = X ( ω ) E ∗ ( ω ) S_{xe} = X(\omega)E*(\omega)S x e =X (ω)E ∗(ω)
C o h x e = ∣ S x e ∣ 2 ∣ S x ∗ S e ∣ Cohxe=\frac{|S_{xe}|^2}{|S_x*S_e|}C o h x e =∣S x ∗S e ∣∣S x e ∣2
不同通话状态对应的参数指标:
1,近端单讲(最大程度保持输出与麦克风信号一致):
cohde:越接近1说明输出与麦克风信号越相似,越接近0说明两者差异越大,近端单讲时理想值为1。
cohxe:越接近1说明输出与远端参考信号越相似,越接近0说明两者差异越大,即残留的远端参考信号频谱成分越少,理想值为0。
SuppFactor:越接近1说明输出与麦克风信号的能量越接近,越接近0说明AEC造成能量衰落越严重,近端单讲时理想值为1。
2. 远端单讲( 最大程度抑制回声):
ERLE:值越大越好,则表明残留回声的能量相对值越小,回声抵消效果越好。
cohde:越接近1说明输出与麦克风信号越相似,越接近0说明两者差异越大,远端单讲时理想值为0。
cohxe:越接近1说明输出与远端参考信号越相似,越接近0说明两者差异越大,即残留的远端参考信号频谱成分越少,理想值为0。
SuppFactor:越接近1说明输出与麦克风信号的能量越接近,越接近0说明AEC造成能量衰落越严重,远端单讲时理想值为0。
3. 双讲( 尽量抑制回声同时保留近端语音)
cohde:越接近1说明输出与麦克风信号越相似,保留的近端语音频谱成分也越多;越接近0说明两者差异越大,保留的近端语音频谱成分也越少,双讲时理想值为0.5~0.9(取决于回声信号在该帧的占比)。
cohxe:越接近1说明输出与远端参考信号越相似,越接近0说明两者差异越大,即残留的远端参考信号频谱成分越少,双讲时理想值为0。
SuppFactor:越接近1说明输出与麦克风信号的能量越接近,越接近0说明AEC造成能量衰落越严重,双讲时理想值为1。
Original: https://blog.csdn.net/qq_44085437/article/details/123504211
Author: 王二黑_Leon
Title: 回声消除性能评判指标
相关阅读3
Title: Faster R-CNN,TensorFlow版本训练过程中出现:keep_inds = np.append(fg_inds, bg_inds) (Pdb)
Faster R-CNN,TensorFlow版本训练过程中出现:keep_inds = np.append(fg_inds, bg_inds) (Pdb)
> /data/sam.yi/Image_manipulation_detection/lib/layer_utils/proposal_target_layer.py(139)_sample_rois()
-> keep_inds = np.append(fg_inds, bg_inds)
(Pdb)
(Pdb)
(Pdb)
(Pdb)
(Pdb)
解决方法:
x1 = float(bbox.find('xmin').text) - 1
y1 = float(bbox.find('ymin').text) - 1
x2 = float(bbox.find('xmax').text) - 1
y2 = float(bbox.find('ymax').text) - 1
x1 = float(bbox.find('xmin').text)
y1 = float(bbox.find('ymin').text)
x2 = float(bbox.find('xmax').text)
y2 = float(bbox.find('ymax').text)
if fg_inds.size > 0 and bg_inds.size > 0:
fg_rois_per_image = min(fg_rois_per_image, fg_inds.size)
fg_inds = npr.choice(fg_inds, size=int(fg_rois_per_image), replace=False)
bg_rois_per_image = rois_per_image - fg_rois_per_image
to_replace = bg_inds.size < bg_rois_per_image
bg_inds = npr.choice(bg_inds, size=int(bg_rois_per_image), replace=to_replace)
elif fg_inds.size > 0:
to_replace = fg_inds.size < rois_per_image
fg_inds = npr.choice(fg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = rois_per_image
elif bg_inds.size > 0:
to_replace = bg_inds.size < rois_per_image
bg_inds = npr.choice(bg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = 0
else:
raise Exception()
并修改train.py:
try:
rpn_loss_cls, rpn_loss_box, loss_cls, loss_box, total_loss = self.net.train_step(sess, blobs, train_op)
except Exception:
print('image invalid, skipping')
continue
分析:
我最终使用的是第一种方法。
出错的代码是:
if fg_inds.size > 0 and bg_inds.size > 0:
fg_rois_per_image = min(fg_rois_per_image, fg_inds.size)
fg_inds = npr.choice(fg_inds, size=int(fg_rois_per_image), replace=False)
bg_rois_per_image = rois_per_image - fg_rois_per_image
to_replace = bg_inds.size < bg_rois_per_image
bg_inds = npr.choice(bg_inds, size=int(bg_rois_per_image), replace=to_replace)
elif fg_inds.size > 0:
to_replace = fg_inds.size < rois_per_image
fg_inds = npr.choice(fg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = rois_per_image
elif bg_inds.size > 0:
to_replace = bg_inds.size < rois_per_image
bg_inds = npr.choice(bg_inds, size=int(rois_per_image), replace=to_replace)
fg_rois_per_image = 0
else:
import pdb
pdb.set_trace()
keep_inds = np.append(fg_inds, bg_inds)
自己的数据集是小目标,所以会导致ROI全是背景,导致进入else语句中。
Original: https://blog.csdn.net/White_yn/article/details/121529827
Author: White_yn
Title: Faster R-CNN,TensorFlow版本训练过程中出现:keep_inds = np.append(fg_inds, bg_inds) (Pdb)