
前言
在NER任务中,主要分为三类实体: 嵌套实体、 非嵌套实体、 不连续实体,今天分享方法以end-to-end的方式解决前两个问题,GlbalPointer,它利用全局归一化的思路来进行命名实体识别(NER),可以无差别地识别嵌套实体和非嵌套实体,在非嵌套(Flat NER)的情形下它能取得媲美CRF的效果,而在嵌套(Nested NER)情形它也有不错的效果。
核心思想
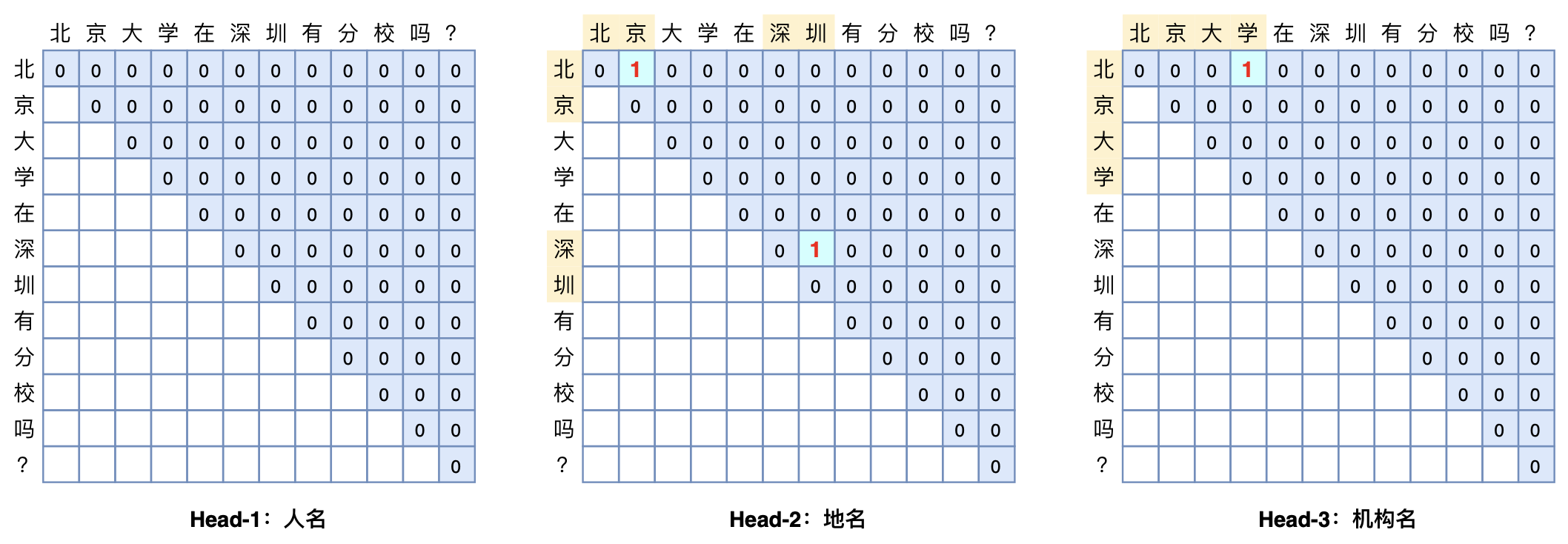
GlobalPointer是一种基于span分类的解码方法,它将首尾视为一个整体去进行判别,所以它更有"全局观"(更Global)。而且也保证了训练、预测、上线评估都是以实体级进行评测。
任务建模,按照实体类型数量和max_len的长度生成三维矩阵(ent_type_size, max_seq_len, max_seq_len),按照实体类型dix,实体start_idx, 实体end_idx填入三维矩阵中并赋值为1
import numpy as np
labels = np.zeros((3,12,12)) # 代表 3种实体类型 句子长度为12
labels[1][0][1] = 1 # 实体类型为1 (start_idx,end_idx)=(0,1)填写为1
模型架构
模型 torch代码如下:
class GlobalPointer(nn.Module):
def __init__(self, encoder, ent_type_size, inner_dim, RoPE=True):
super().__init__()
self.encoder = encoder
self.ent_type_size = ent_type_size
self.inner_dim = inner_dim
self.hidden_size = encoder.config.hidden_size
self.dense = nn.Linear(self.hidden_size, self.ent_type_size * self.inner_dim * 2)
self.RoPE = RoPE # 是否使用RoPE
def sinusoidal_position_embedding(self, batch_size, seq_len, output_dim):
position_ids = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(-1)
indices = torch.arange(0, output_dim // 2, dtype=torch.float)
indices = torch.pow(10000, -2 * indices / output_dim)
embeddings = position_ids * indices
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
embeddings = embeddings.repeat((batch_size, *([1]*len(embeddings.shape))))
embeddings = torch.reshape(embeddings, (batch_size, seq_len, output_dim))
embeddings = embeddings.to(self.device)
return embeddings
def forward(self, input_ids, attention_mask, token_type_ids):
self.device = input_ids.device
context_outputs = self.encoder(input_ids, attention_mask, token_type_ids)
# last_hidden_state:(batch_size, seq_len, hidden_size)
last_hidden_state = context_outputs[0]
batch_size = last_hidden_state.size()[0]
seq_len = last_hidden_state.size()[1]
# outputs:(batch_size, seq_len, ent_type_size*inner_dim*2)
outputs = self.dense(last_hidden_state)
outputs = torch.split(outputs, self.inner_dim * 2, dim=-1)
# outputs:(batch_size, seq_len, ent_type_size, inner_dim*2)
outputs = torch.stack(outputs, dim=-2)
# qw,kw:(batch_size, seq_len, ent_type_size, inner_dim)
qw, kw = outputs[...,:self.inner_dim], outputs[...,self.inner_dim:] # TODO:修改为Linear获取?
if self.RoPE:
# pos_emb:(batch_size, seq_len, inner_dim)
pos_emb = self.sinusoidal_position_embedding(batch_size, seq_len, self.inner_dim)
# cos_pos,sin_pos: (batch_size, seq_len, 1, inner_dim)
cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1)
sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1)
qw2 = qw2.reshape(qw.shape)
qw = qw * cos_pos + qw2 * sin_pos
kw2 = torch.stack([-kw[..., 1::2], kw[...,::2]], -1)
kw2 = kw2.reshape(kw.shape)
kw = kw * cos_pos + kw2 * sin_pos
# logits:(batch_size, ent_type_size, seq_len, seq_len)
logits = torch.einsum('bmhd,bnhd->bhmn', qw, kw)
# padding mask
pad_mask = attention_mask.unsqueeze(1).unsqueeze(1).expand(batch_size, self.ent_type_size, seq_len, seq_len)
# pad_mask_h = attention_mask.unsqueeze(1).unsqueeze(-1).expand(batch_size, self.ent_type_size, seq_len, seq_len)
# pad_mask = pad_mask_v&pad_mask_h
logits = logits*pad_mask - (1-pad_mask)*1e12
# 排除下三角
mask = torch.tril(torch.ones_like(logits), -1)
logits = logits - mask * 1e12
return logits/self.inner_dim**0.5
生成RoPE:
GlobalPoint核心思想是引入了RoPE(旋转式位置编码):
对于位置m m m,RoPE会计算出一个正交矩阵 R m R_{m}R m ,将 R m R_{m}R m 与 q q q相乘便实现对 q q q进行旋转,如果 q q q 是二维,有:
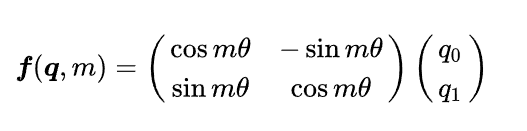
对于高阶偶数维的q q q ,有:
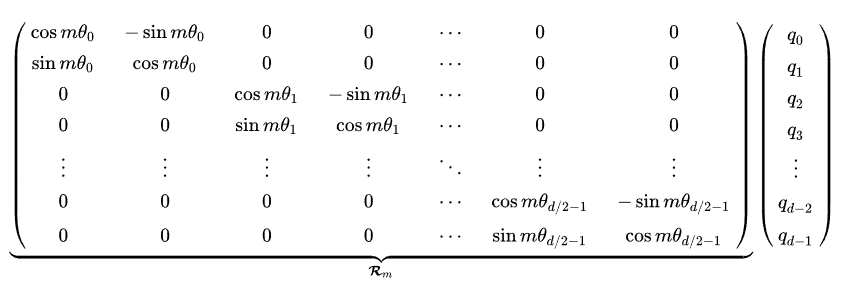
其中θ i \theta_i θi 是怎么得到的?
介绍一下Sinusoidal位置编码

RoPE在θi的选择上,采用了Sinusoidal位置编码的方案,即 θ i = 1000 0 ( − 2 i / d ) \theta _i = 10000^{(-2i/d)}θi =1 0 0 0 0 (−2 i /d ) 它可以带来一定的远程衰减性。
有关torch.stack可参考这篇文章
def sinusoidal_position_embedding(self, batch_size, seq_len, output_dim):
position_ids = torch.arange(0, seq_len, dtype=torch.float).unsqueeze(-1) # 生成绝对位置信息
indices = torch.arange(0, output_dim // 2, dtype=torch.float) # 由Sinusoidal公式可知 i的范围是 0 -> d/2
indices = torch.pow(10000, -2 * indices / output_dim) # 公式计算得到theta_i
embeddings = position_ids * indices # 生成带theta的embedding
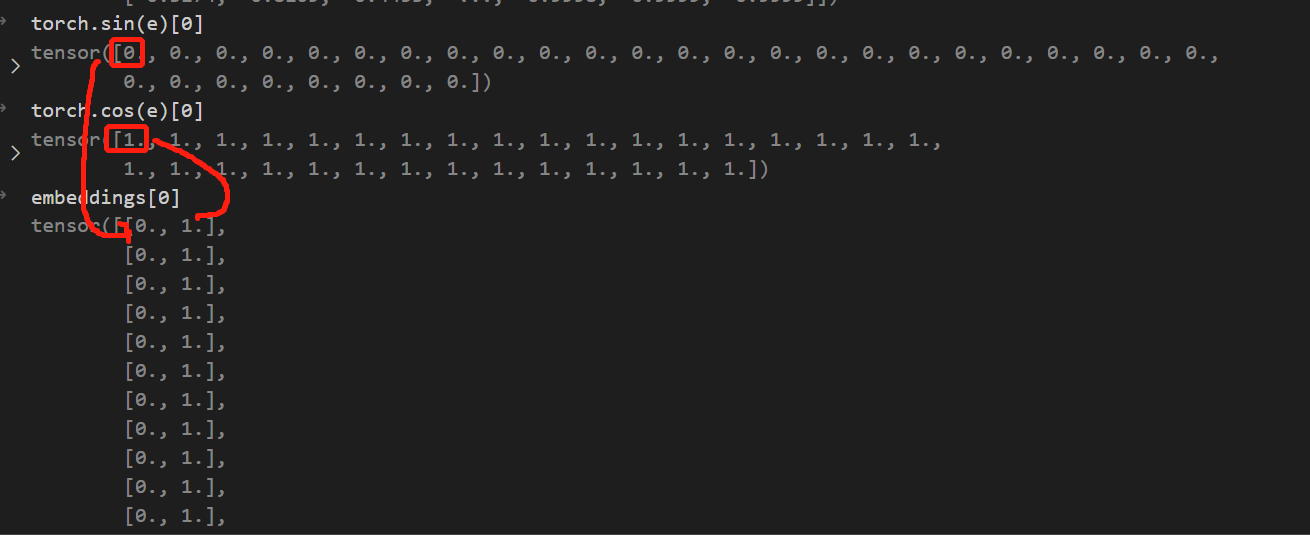
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1) # 引入cosm sinm 在最后维度进行堆叠
embeddings = embeddings.repeat((batch_size, *([1]*len(embeddings.shape)))) # 扩展到整个batch_size种
embeddings = torch.reshape(embeddings, (batch_size, seq_len, output_dim)) # 修改为输出维度
embeddings = embeddings.to(self.device)
return embeddings
其中stack操作如下图所示:
torch.repeat 操作 可以将1维信息扩展到多维信息中
x = torch.tensor([1, 2, 3])
> tensor([1, 2, 3])
(3, *([1]*len(x.shape)))
> (3, 1)
x = x.repeat((3, *([1]*len(x.shape))))
>tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
由苏神的讲解可知,RoPE的计算可以简化为如下图。

在q q q 和k k k 中融入RoPE:
于是以此类推,如果将 k k k 也乘上旋转位置编码,此时span的分数 s ( i , j ) s(i,j)s (i ,j ) 就会带有相对位置信息(也就是 R i − j R_{i-j}R i −j ):
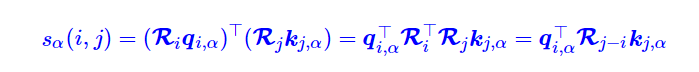
if self.RoPE:
# pos_emb:(batch_size, seq_len, inner_dim)
pos_emb = self.sinusoidal_position_embedding(batch_size, seq_len, self.inner_dim) # 上一步得到RoPE
# cos_pos,sin_pos: (batch_size, seq_len, 1, inner_dim)
cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1)
sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1)
qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1)
qw2 = qw2.reshape(qw.shape)
qw = qw * cos_pos + qw2 * sin_pos
kw2 = torch.stack([-kw[..., 1::2], kw[...,::2]], -1)
kw2 = kw2.reshape(kw.shape)
kw = kw * cos_pos + kw2 * sin_pos
有关切片操作可看这篇文章
其中:
... 操作表示自动判断其中得到维度区间
None 增加一维
::2 两个冒号直接写表示从所有的数据中隔行取数据。从0开始
1::2 两个冒号直接写表示从所有的数据中隔行取数据。从1开始
repeat_interleave操作:复制指定维度的信息
x = torch.tensor([1, 2, 3])
>tensor([1, 2, 3])
x.repeat_interleave(2)
>tensor([1, 1, 2, 2, 3, 3])
y = torch.tensor([[1, 2], [3, 4]])
>tensor([[1, 2],
[3, 4]])
torch.repeat_interleave(y, 2)
>tensor([1, 1, 2, 2, 3, 3, 4, 4])
torch.repeat_interleave(y, 3, dim=1)
>tensor([[1, 1, 1, 2, 2, 2],
[3, 3, 3, 4, 4, 4]])
让我们再次看一遍这个计算公式:
这时可以发现:
cos_pos = pos_emb[..., None, 1::2].repeat_interleave(2, dim=-1) # 是将奇数列信息抽取出来也就是cosm 拿出来并复制
sin_pos = pos_emb[..., None,::2].repeat_interleave(2, dim=-1) # 是将偶数列信息抽取出来也就是sinm 拿出来并复制
qw2 = torch.stack([-qw[..., 1::2], qw[...,::2]], -1) # 奇数列加上负号 得到第二个q的矩阵
qw = qw * cos_pos + qw2 * sin_pos # 最后融入位置信息
计算kw 也是同理步骤
## 最后计算初logits 结果
logits = torch.einsum('bmhd,bnhd->bhmn', qw, kw) # 相等于先对qw做转置 然后qw与kw做矩阵乘法
torch.einsum :
可以简单实现向量内积,向量外积,矩阵乘法,转置和张量收缩(tensor contraction)等张量操作
可参考这篇文章
torch.expand
参考这篇文章
以上就是对GlobalPoint模型主要的要点进行解析,如果你还有什么问题,可以留言,一起讨论啊
参考代码链接:https://github.com/gaohongkui/GlobalPointer_pytorch
Original: https://blog.csdn.net/qq_36287702/article/details/123567764
Author: 桐原因
Title: 【代码复现】NER之GlobalPointer解析
相关阅读1
Title: PWA学习笔记(二)
APP Shell:
1、应用从显示内容上可粗略划分为内容部分和外壳部分,App Shell 就是 外壳部分,即页面的基本结构
2、它不仅包括用户能看到的 页面框架部分,还包括用户看不到的 代码逻辑
3、页面能够展现所需的 最小资源集合,即支持用户界面所需的最小的 HTML、CSS 和 JS 等静态资源集合
4、采用 App Shell 的站点,每个页面都会 先加载 App Shell 的内容,
再由 App Shell 根据当前页面 URL 渲染对应的主体内容
正确地使用 APP Shell:
1、使用 Service Worker 预缓存 App Shell 的静态资源
2、用户访问 Web 站点时,通过 Service Worker 拦截请求
3、Service Worker 返回缓存中的 App Shell 给浏览器
4、App Shell 根据当前的 URL 再去 请求对应的数据来渲染
骨架屏:
1、快速渲染的静态图片/样式/色块进行 占位,让用户对后续会渲染的内容有一定的预期
2、从架构上来说分为 前端渲染(CSR)和后端渲染(SSR)两种,骨架屏适用于前端渲染的页面
3、骨架屏的 HTML 和 CSS 内联,从而使骨架屏能更快地展示出来
4、外链样式文件会阻塞骨架屏渲染所需的样式和 HTML 的渲染,可以将外联样式的 rel 设置为 preload
5、由于使用预加载来加载样式文件,所以我们无法保证浏览器会先应用样式再运行 JavaScript 渲染内容。
所以,在样式文件加载完成前,即使 JavaScript 已渲染好了内容,也先不要替换掉骨架屏, 等待样式文件
加载完成后,再触发 JavaScript 进行挂载。如果样式文件在 JavaScript 文件之前加载,则mount 函数
还没有声明,执行会出错,导致主体内容没有渲染到页面上, 需增加标记告诉 JavaScript 样式是否加载完成
Data URL:
1、允许我们使用内联(inline-code)的方式在网页中包含数据,目的是将一些小的数据,
直接嵌入到网页中,从而不用再从外部文件载入
2、格式规范
3、制作 base64 的 Data URL:
(1)使用二进制方式(rb)打开图片文件
(2)用 Python 的 base64 库来给比特流图片进行编码
4、适用场合:
(1)当访问外部资源很麻烦或受限时
(2)当图片是在服务器端用程序动态生成,每个访问用户显示的都不同时
(3)当图片的体积太小,占用一个HTTP会话不是很值得时
5、不适用场合:
(1)编码后可能会增加数据的体积
(2)Data URL形式的图片不会被浏览器缓存,这意味着每次访问这样页面时都被下载一次,但可优化
页面从加载到展现的大致顺序如下:
1、加载 HTML 文件
2、解析 DOM
3、 并行加载 CSS/JS 资源
4、如果 head 中存在外链的样式,则 阻塞渲染等待样式文件加载并解析完成
5、如果 head 中存在外链的 script,则 阻塞渲染等待 script 文件加载并执行完成
像素:
1、图像中 最小的单位,一个不可再分割的点,在计算机屏幕上一般指屏幕上的一个 光点
2、设备像素对应屏幕上 光点的数量
3、 虚拟像素,也可以叫 CSS 像素(CSS Pixels)或逻辑像素,在 Android 开发中可以叫设备无关像素
注:在 iPhone X 上,设备像素是 1125x2436,而 CSS 像素是 375x812,则一个 CSS 像素对应长和宽各 3 个设备像素
比值 3 就是我们平时所说的设备像素比(Device Pixel Ratio),简称 DPR ,它并不是一个单位,而是一个 比值
EM 和 REM:
1、EM 是相对单位,相对于元素自身的 font-size,它会从 继承父元素的字体大小,若父元素没有设置字体大小,会一直找到根元素
2、REM = Root EM,顾名思义就是相对于 根元素的 EM,是根据根元素来计算出CSS 像素点的大小,默认为 16px
3、EM 对于 模块化的页面元素比较好,而 方便是 REM 最大的好处(只需要知道 html 标签的字体大小即可)
vw、vh 和百分比:
1、vw:viewport width, 视口宽度,1vw = 1% 视口宽度
2、vh:viewport height, 视口高度,1vh = 1% 视口高度
3、百分比:根据 父元素来决定,如父元素高 100px,则 50% == 50px
弹性框:
1、不是单位,而是一种 布局方式,里面的元素可 弹性伸缩、定义 排版方向、指定 flex 元素的顺序
2、容器样式属性(display: flex 的元素):
(1)flex-direction:定义主轴方向,即子元素的排列方向,取值为
row、row-reverse、column 和 column-reverse,默认 row
(2)flex-wrap:默认情况下,弹性布局会将所有元素都压缩到一行,可以通过设置 flex-wrap 告诉
浏览器在适当时候换行取值为 nowrap、wrap、wrap-reverse
(3)flex-flow: 这个属性值是 flex-direction 和 flex-wrap 的简写
(4)justify-content: 定义子元素在主轴上对齐方式,
取值为flex -start、flex-end、center、space-between 和 space-around
(5)align-items:定义子元素在垂直于主轴的交叉轴的排列方式,
取值为flex -start、flex -end、center、baseline 和stretch
(6)align-content:定义了子元素在多条轴线上的对齐方式,如果只使用了一条轴线,那该属性不起作用,
取值为flex -start、flex -end、center、space -between、space -around 和 stretch
Original: https://www.cnblogs.com/lemonyam/p/11931506.html
Author: 贵志
Title: PWA学习笔记(二)
相关阅读2
Title: 【聚类算法】带你轻松搞懂K-means聚类(含代码以及详细解释)
文章目录
一:K-means聚类算法
聚类是一个将数据集中 在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为 无监督学习。
k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目k,k由用户指定,k均值算法根据某个距离函数反复把数据分入k个聚类中。
二:实例分析
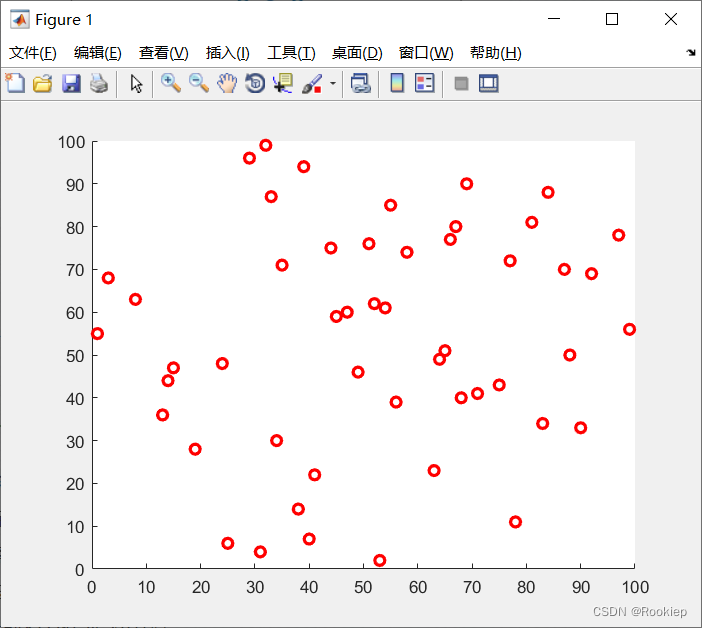
现有50个二维数据点如下图,使用K-Means算法将以下数据实现聚类。
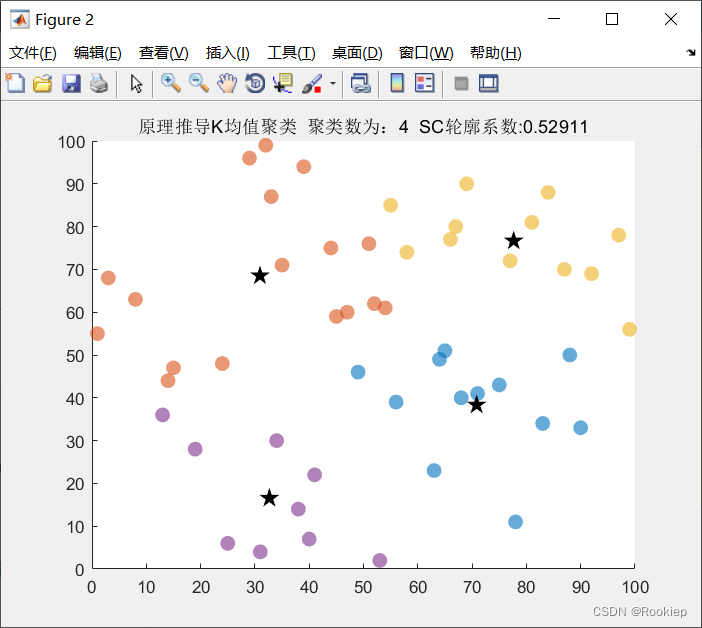
结果展示:
; 三:原理与步骤
K-means算法是典型的基于距离(欧式距离、曼哈顿距离)的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。
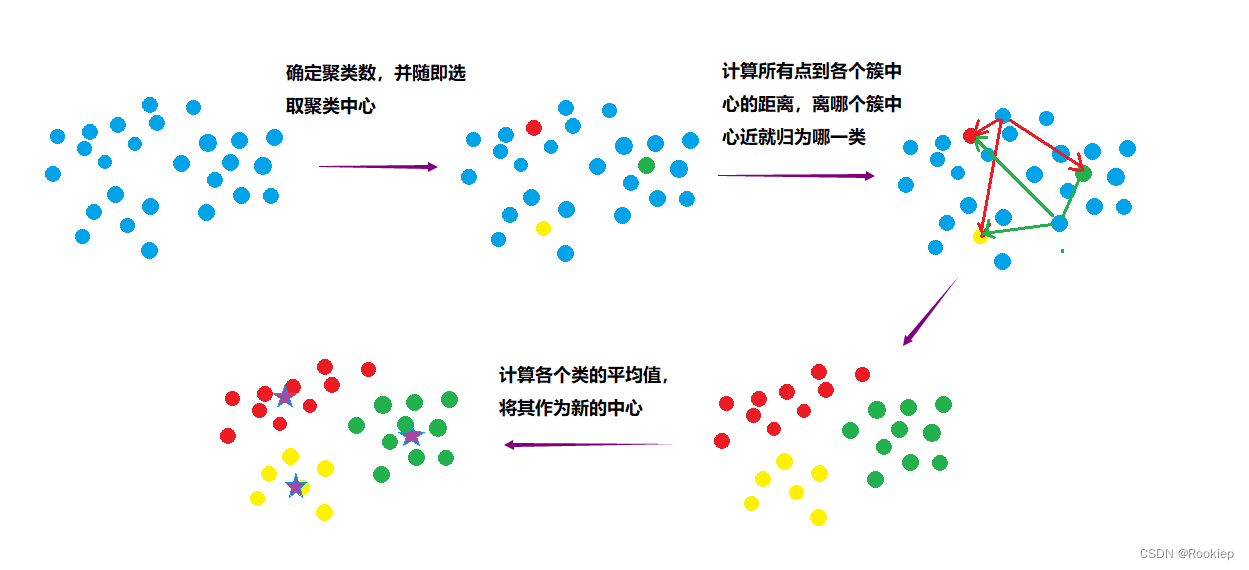
K-mean算法步骤如下:
- 先定义总共有多少个簇类,随机选取K个样本为簇中⼼。
- 分别计算所有样本到随机选取的K个簇中⼼的距离。
- 样本离哪个中⼼近就被分到哪个簇中⼼。
- 计算各个中⼼样本的均值(最简单的⽅法就是求样本每个点的平均值)作为新的簇心。
- 重复2、3、4直到新的中⼼和原来的中⼼基本不变化的时候,算法结束。
算法结束条件:
- 当每个簇的质心,不再改变时就可以停止k-menas。
- 当循环次数达到事先规定的次数时,停止k-means
原理示意图:
简单小实例:
有以下6个点,初始随机选取两个点作为两个簇的簇中心(这里假设选取的是A3,A4),求最后的簇所属情况。
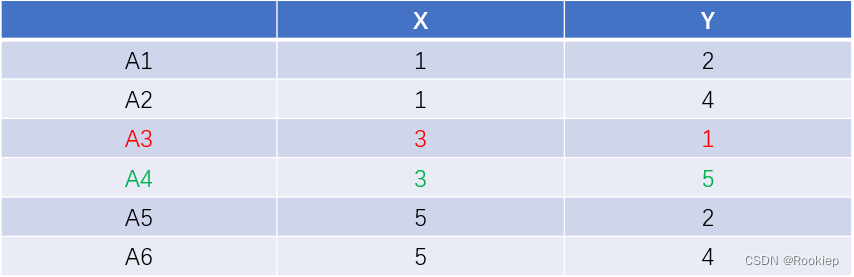
1️⃣:计算每个点到簇心的距离,将距离近的归为一类。
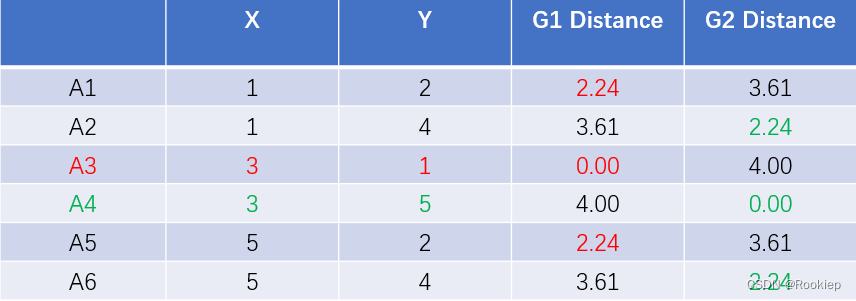
2️⃣:将红色对应的点和绿色对应的每个点分别求X,Y平均值,最为新的簇心。

3️⃣:计算每个点到新簇心的距离,继续将对应距离近的点归为一类。
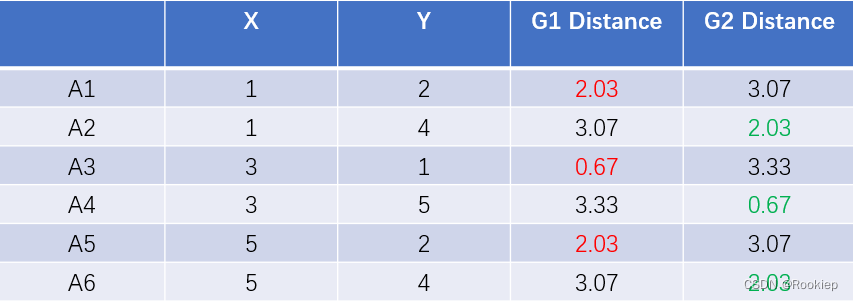
4️⃣:由于关联点没有发生变化,所以之后的结果不会发生变化。停止计算
5️⃣:得结果红色簇:A1,A3,A5,紫色簇:A2,A4,A6。
四:Matlab代码以及详解
clc;clear;close all;
data(:,1)=[90,35,52,83,64,24,49,92,99,45,19,38,1,71,56,97,63,...
32,3,34,33,55,75,84,53,15,88,66,41,51,39,78,67,65,25,40,77,...
13,69,29,14,54,87,47,44,58,8,68,81,31];
data(:,2)=[33,71,62,34,49,48,46,69,56,59,28,14,55,41,39,...
78,23,99,68,30,87,85,43,88,2,47,50,77,22,76,94,11,80,...
51,6,7,72,36,90,96,44,61,70,60,75,74,63,40,81,4];
%50 * 1
figure(1)
scatter(data(:,1),data(:,2),'MarkerEdgeColor','r','LineWidth',2)
%% 原理推导K均值
[m,n]=size(data);%m = 50,n = 1;
cluster_num=4;%4个初始中心
cluster=data(randperm(m,cluster_num),:);%randperm(m,cluster_num)在前m中随机选取cluster_num个 %随机选取中心
%data函数 取数据用
epoch_max=1000;%最大次数
therad_lim=0.001;%中心变化阈值
epoch_num=0;
while(epoch_num<epoch_max)
epoch_num=epoch_num+1;
for i=1:cluster_num
distance=(data-repmat(cluster(i,:),m,1)).^2;% 50 * 2 repmat扩展矩阵
%.^2是矩阵中的每个元素都求平方,^2是求矩阵的平方或两个相同的矩阵相乘,因此要求矩阵为方阵
distance1(:,i)=sqrt(sum((distance),2));%求行和
%distance1(:,i)=sqrt(sum(distance'));% 默认求列和 1表示每一列进行求和,2表示每一行进行求和;
%sqrt(sum(distance')) == 1 * 50
%distance1 50 * 4 表示每个点距离第i个点的距离
end
[~,index_cluster]=min(distance1');%distance1' = 4 * 50,min 求列最值 index_cluster = 最小值所在行号 index_cluster = 1 * 50
for j=1:cluster_num
cluster_new(j,:)=mean(data(find(index_cluster==j),:));% 4 * 2 找到距离对应中心最近的点 横纵坐标各取平均值
end
if (sqrt(sum((cluster_new-cluster).^2))>therad_lim)
cluster=cluster_new;
else
break;
end
end
%% 画出聚类效果
figure(2)
%subplot(2,1,1)
a=unique(index_cluster); %找出分类出的个数
C=cell(1,length(a));%1 * 4的元胞
for i=1:length(a)
C(1,i)={find(index_cluster==a(i))};
end
for j=1:cluster_num
data_get=data(C{1,j},:);%从data中取每个类的点
scatter(data_get(:,1),data_get(:,2),80,'filled','MarkerFaceAlpha',.6,'MarkerEdgeAlpha',.9);
hold on
end
plot(cluster(:,1),cluster(:,2),'kp','LineWidth',2);%画出4个聚类中心
hold on
sc_t=mean(silhouette(data,index_cluster'));
title_str=['原理推导K均值聚类',' 聚类数为:',num2str(cluster_num),' SC轮廓系数:',num2str(sc_t)];
title(title_str)
Original: https://blog.csdn.net/qq_43727529/article/details/126813321
Author: Rookiep
Title: 【聚类算法】带你轻松搞懂K-means聚类(含代码以及详细解释)
相关阅读3
Title: AirSim(五)---理解篇: Airsim世界坐标系、NED坐标系、机体坐标系以及控制相关API接口函数
目录
- 1. 坐标系 coordinate system
* - (1) AirSim API的坐标系:NED 坐标系 with SI unit
- (2) Unreal Engine的坐标系
- (3)AirSim全局坐标系=NED坐标系=世界坐标系
- (4) AirSim的机体坐标系:Body Frame
- 2. AirSim APIs for 车辆和无人机的状态
1. 坐标系 coordinate system
本部分源自:Using AirSim>>Core APIs>> AirSim APIs 官网
(1) AirSim API的坐标系:NED 坐标系 with SI unit
该坐标系也是世界坐标系,world frame。
- 所有AirSim API使用NED坐标系统,即+X是北North,+Y是东East,+Z是下Down。这意味着Z值越高越负:如果原点在地面上,z值是零,地面以上是负的!
- 所有单位都是国际单位制。
- 请注意,不同于Unreal Engine (UE)内部使用的坐标系统。在Unreal Engine中,+Z是向上Up而不是向下Down,长度单位是厘米cm而不是米m。
- AirSim API来完成从Unreal Engine的NEU坐标系到AirSim的NED坐标系的适当转换。在AirSim NED系统中,车辆的起始点总是坐标(0,0,0)。因此,当从UE坐标系转换到AirSim NED坐标系时,我们首先减去起始点偏移量,然后缩放100实现cm到m的转换。
- 在UE环境中,车辆由Player Start component放置的地方生成或衍生而来,在 Settings.json_配置文件中有一个设置项元素为 _OriginGeopoint,可以将地理经度、纬度和海拔分配给Player Start Component
OriginGeoPoint这指定了放置在Unreal环境中的Player Start Component的纬度、经度和高度。车辆的原点(home point)是用这个变换计算出来的。请注意,所有通过API采用的坐标都使用了以SI单位表示的NED坐标系统,这意味着每辆车在NED系统中都从(0,0,0)开始启动。
—《OriginGeopoint》官网资料
(2) Unreal Engine的坐标系
- AirSim不同于Unreal Engine (UE)内部使用的坐标系统。在Unreal Engine中,+Z是向上Up而不是向下Down,长度单位是厘米cm而不是米m。
- 用户不必特别关系UE坐标系,因为AirSim已经处理好了这个问题,即只需要按照AirSim坐标系设置即可,包括Settings.json中的OriginGeopoint元素,AirSim会帮用户自动转换。
(3)AirSim全局坐标系=NED坐标系=世界坐标系
(4) AirSim的机体坐标系:Body Frame
本部分参考:airsim document
根据Airsim文档提供的说明, 机体坐标系body frame遵循Front Left Up (FLU),右手法则。


Note:图片来源:GAAS
Note2: 上述FLU坐标系为右手坐标系。判断绕某个旋转轴i 的旋转正方向的方法为:右手坐标系:
右手握拳,大拇指伸直指向旋转轴i的正方向(箭头方向),其余四指指尖所朝向的方向即为正方向(等效于从旋转轴i正方向箭头端逆向看过去,或者旋转轴i正方向箭头射进你的眼睛,这时看到的逆时针旋转方向为绕i轴的正方向)。

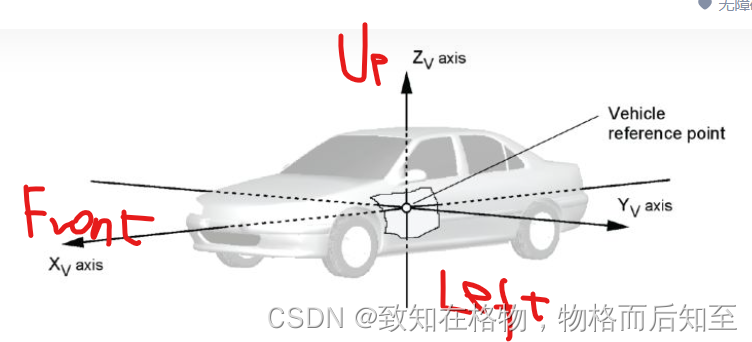
Note:也有说法是认为FLU坐标系不对,应该是FRD坐标系。即机体坐标系的原点在机体的重心位置,x,y,z三个坐标轴的方向分别指向机体的前方、右方、下方. 点击此。
; 2. AirSim APIs for 车辆和无人机的状态
本部分内容:Using AirSim>>Core APIs: APIs for Car
Airsim提供了两个API函数来进行车辆的控制、获取车辆状态
设置车辆控制参数setCarControlsset throttle, steering, handbrake and auto or manual gear.获取车辆状态参数getCarState获取如下的状态信息: speed, current gear,6 kinematics quantities: position, orientation, linear and angular velocity, linear and angular acceleration.设置无人机控制参数move* APIs1 Multirotor can be controlled by specifying angles, velocity vector, destination position or some combination of these.
2 当进行position control时, 需要path following算法,其中AirSim 默认采用carrot following algorithm,这部分通常被认为是 "high level control" ,因为只需要指定 high level goal,the firmware会自动完成其余功能。
3 当前AirSim提供的底层控制 lowest level control 是API函数: moveByAngleThrottleAsync API.获取无人机状态参数getMultirotorState1 这个API在一个调用中返回车辆的状态。
2 状态包括:collision、estimated kinematics(即通过融合传感器计算的运动学)和timestamp(自每个epoch以来的纳秒时间)。3. 这里的kinematics运动学指的是6个量:position, orientation, linear and angular velocity, linear and angular acceleration。
4请注意,simple_slight目前不支持state estimator,这意味着simple_flight模式下估计运动学值和地面真实运动学值是相同的获取真实vehicle和环境状态simGetGroundTruthEnvironment
(vehicle_name=''
一般是Ground Truth值)该函数返回class airsim.types.EnvironmentState,包含环境状态:
-大气密度air_density;
-大气压air_pressure;
-PlayerStart的起始地理信息geo_point;
-重力gravity;
-无人机位置in NED position;
-温度temperature.
Note
:gravity是环境的重力,NED坐标系中为z轴正方向一致,因此可得到类似9.8的结果。获取vehicle估计的运动学状态simGetGroundTruthKinematics
(vehicle_name='')
指的是kinematics估计值
该函数返回airsim.types.KinematicsState,包含信息:
-
角加速度:angular_acceleration
-
角速度:angular_velocity
-
加速度:linear_acceleration
-
速度:linear_velocity
-
姿态四元数:orientation
-
位置:position
Note:1-2: body frame; 3-6: NED frame
Note:
- 上述状态量中,只有角速度和加速度的值(angular velocity and accelerations )是定义在Body frame中,其余状态量是在NED坐标系中,并且采用SI单位制。
- kinematics输出的位置信息和simGetGroundTruthEnvironment()接口的位置信息不一定完全相同,kinematics的结果是通过动力学物理引擎计算得到的,具体可以参考AirSim论文
Original: https://blog.csdn.net/kuvinxu/article/details/124467529
Author: 致知在格物,物格而后知至
Title: AirSim(五)---理解篇: Airsim世界坐标系、NED坐标系、机体坐标系以及控制相关API接口函数