
自然语言处理(NLP)
主要研究人与计算机之间,使用自然语言进行有效通信的各种理论和方法。
自然语言处理的主要技术范畴
1、语义文本相似度分析
语义文本相似度分析是对两段文本的意义和本质之间的相似度进行分析的过程。
2、信息检索
信息检索是指将信息按一定的方式加以组织,并通过信息查找满足用户的信息需求的过程和技术。
3、 信息抽取
信息抽取是指从非结构化/半结构化文本(如网页、新闻、 论文文献、微博等)中提取指定类型的信息(如实体、属性、关系、事件、商品记录等),并通过信息归并、冗余消除和冲突消解等手段将非结构化文本转换为结构化信息的一项综合技术。
4、文本分类
文本分类的任务是根据给定文档的内容或主题,自动分配预先定义的类别标签。
5、文本挖掘
文本挖掘是信息挖掘的一个研究分支,用于基于文本信息的知识发现。文本挖掘的准备工作由文本收集、文本分析和特征修剪三个步骤组成。目前研究和应用最多的几种文本挖掘技术有:文档聚类、文档分类和摘要抽取。
6、文本情感分析
情感分析是一种广泛的主观分析,它使用自然语言处理技术来识别客户评论的语义情感,语句表达的情绪正负面以及通过语音分析或书面文字判断其表达的情感等。
7、问答系统
自动问答是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。不同于现有搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案。
8、机器翻译
机器翻译是指利用计算机实现从一种自然语言到另外一种自然语言的自动翻译。被翻译的语言称为源语言(source language),翻译到的语言称作目标语言(target language)。
机器翻译研究的目标就是建立有效的自动翻译方法、模型和系统,打破语言壁垒,最终实现任意时间、任意地点和任意语言的自动翻译,完成人们无障碍自由交流的梦想。
9、自动摘要
自动文摘(又称自动文档摘要)是指通过自动分析给定的一篇文档或多篇文档,提炼、总结其中的要点信息,最终输出一篇长度较短、可读性良好的摘要(通常包含几句话或数百字),该摘要中的句子可直接出自原文,也可重新撰写所得。
根据输入文本的数量划分,文本摘要技术可以分为单文档摘要和多文档摘要。 在单文档摘要系统中,一般都采取基于抽取的方法。而对于多文档而言,由于在同一个主题中的不同文档中不可避免地存在信息交叠和信息差异,因此如何避免信息冗余,同时反映出来自不同文档的信息差异是多文档文摘中的首要目标,而要实现这个目标通常以为着要在句子层以下做工作,如对句子进行压缩,合并,切分等。另外,单文档的输出句子一般是按照句子在原文中出现的顺序排列,而在多文档摘要中,大多采用时间顺序排列句子,如何准确的得到每个句子的时间信息,也是多文档摘要需要解决的一个问题。
10、语音识别
语言识别指的是将不同语言的文本区分出来。其利用语言的统计和语法属性来执行此任务。语言识别也可以被认为是文本分类的特殊情况
分词(切词)
分词是自然语言处理的基础,分词准确度直接决定了后面的词性标注、句法分析、词向量以及文本分析的质量。
前向最大匹配算法
分词的目的是将一段中文分成若干个词语,前向最大匹配就是从前向后寻找在词典中存在的词。
例子:
假设 Max_len = 5,即假设单词的最大长度为5。 再假设我们现在 词典中存在的词有: ["我们", "经常","常有", "有意见","有意", "意见", "分歧", "我","们","经","常","有","意","见"]
现在,用 前向最大匹配算法来划分 我们经常有意见分歧 这句话。
我们经常有意见分歧(max_len = 5)
第一轮:取子串 "我们经常有",正向取词,如果匹配失败,每次去掉匹配字段 最后面 的一个字。
- "我们经常有",扫描词典中的5字单词,没有匹配,子串长度减 1 变为"我们经常"。
- "我们经常",扫描词典中的4字单词,没有匹配,变为"我们经"。
- "我们经",扫描词典中的3字单词,没有匹配, 变为"我们"。
- "我们",扫描词典中的2字单词,匹配成功,输出"我们",输入变为 "经常有意见分歧" 。
第二轮:取子串"经常有意见"
- "经常有意见",扫描词典中的5字单词,没有匹配,子串长度减 1 变为"经常有意"。
- "经常有意",扫描词典中的4字单词,没有匹配,子串长度减 1 变为"经常有"。
- "经常有",扫描词典中的3字单词,没有匹配,子串长度减 1 变为"经常"。
- "经常",扫描词典中的2字单词,有匹配,输出"经常",输入变为"有意见分歧"。
以此类推,直到输入长度为0时,扫描终止。 最终,前向最大匹配算法得出的结果为: 我们 / 经常 / 有意见 / 分歧
N-gram算法
朴素贝叶斯:
- 朴素贝叶斯法是贝叶斯定理与特征条件独立性假设的分类方法。
- 最为广泛的两种分类模型是决策树模型和朴素贝叶斯模型。
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
整个朴素贝叶斯分类分为三个阶段:
第一阶段:准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段:分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段:应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
比如:

朴素贝叶斯模型就是要衡量这句话属于垃圾短信敏感句子的概率。

朴素贝叶斯将句子处理为一个 词袋模型(Bag-of-Words, BoW),以至于不考虑每个单词的顺序。
N-gram模型就是考虑句子中单词之间的顺序。
N-gram
N-gram模型是一种语言模型(Language Model,LM),语言模型是一个基于概率的判别模型,它的输入是一句话(单词的顺序序列),输出是这句话的概率,即这些单词的联合概率(joint probability)。
N-gram本身也指一个由N个单词组成的集合,各单词具有先后顺序,且不要求单词之间互不相同。常用的有 Bi-gram (N = 2) 和 Tri-gram (N = 3)
例如: I love deep learning

- 用途 1、词性标注
N-gram可以实现词性标注。例如"爱"这个词,它既可以作为动词使用,也可以作为名词使用。不失一般性,假设我们需要匹配一句话中"爱"的词性。
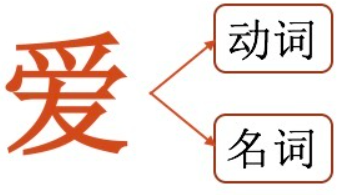

我们可以将词性标注看成一个 多分类问题,按照Bi-gram计算每一个词性概率:

选取概率更大的词性(比如动词)作为这句话中"爱"字的词性。
2、垃圾短信分类
- 步骤一:给短信的每个句子断句。
- 步骤二:用N-gram判断每个句子是否垃圾短信中的敏感句子。
- 步骤三:若敏感句子个数超过一定阈值,认为整个邮件是垃圾短信。
3、分词器
用N-gram可以实现一个简单的分词器(Tokenizer)。同样地,将分词理解为多分类问题:X表示有待分词的句子,Y 表示该句子的一个分词方案。

4、机器翻译和语音识别

词向量(Word Embedding)
词向量是表示自然语言里单词的一种方法,即把每个词都表示为一个N维空间内的点,即一个高维空间内的向量。通过这种方法,实现把自然语言计算转换为向量计算。
如何把词转换为向量
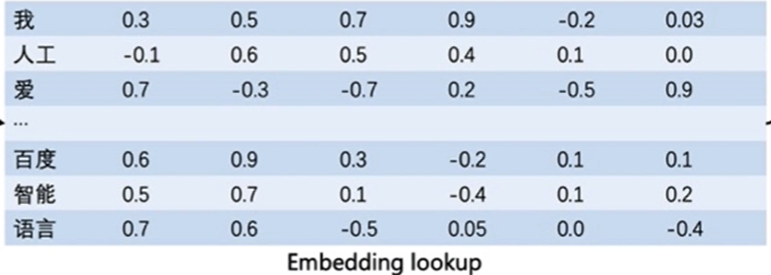
- 通常情况下,我们可以维护一个如图所示的查询表。
- 表中每一行都存储了一个特定词语的向量值,每一列的第一个元素都代表着这个词本身,以便于我们进行词和向量的映射。
- (如"我"对应的向量值为 [0.3,0.5,0.7,0.9,-0.2,0.03] )
- 给定任何一个或者一组单词,我们都可以通过查询这个excel,实现把单词转换为向量的目的,这个查询和替换过程称之为Embedding Lookup。
- 在进行神经网络计算的过程中,需要大量的算力,常常要借助特定硬件(如GPU)满足训练速度的需求。
- GPU上所支持的计算都是以张量(Tensor)为单位展开的。
- 因此在实际场景中,我们需要把Embedding Lookup的过程转换为张量计算。

如何让向量具有语义信息
得到每个单词的向量表示后,我们需要思考下一个问题:比如在多数情况下,"香蕉"和"橘子"更加相似,而"香蕉"和"句子"就没有那么相似;同时,"香蕉"和"食物"、"水果"的相似程度可能介于"橘子"和"句子"之间。那么如何让存储的词向量具备这样的语义信息呢?
word2vec
是一个将单词转换成向量形式的工具。
通过上下文来学习语义信息
包含两个经典模型 CBOW 和 Skip-gram
CBOW
通过上下文的词向量推理中心词。
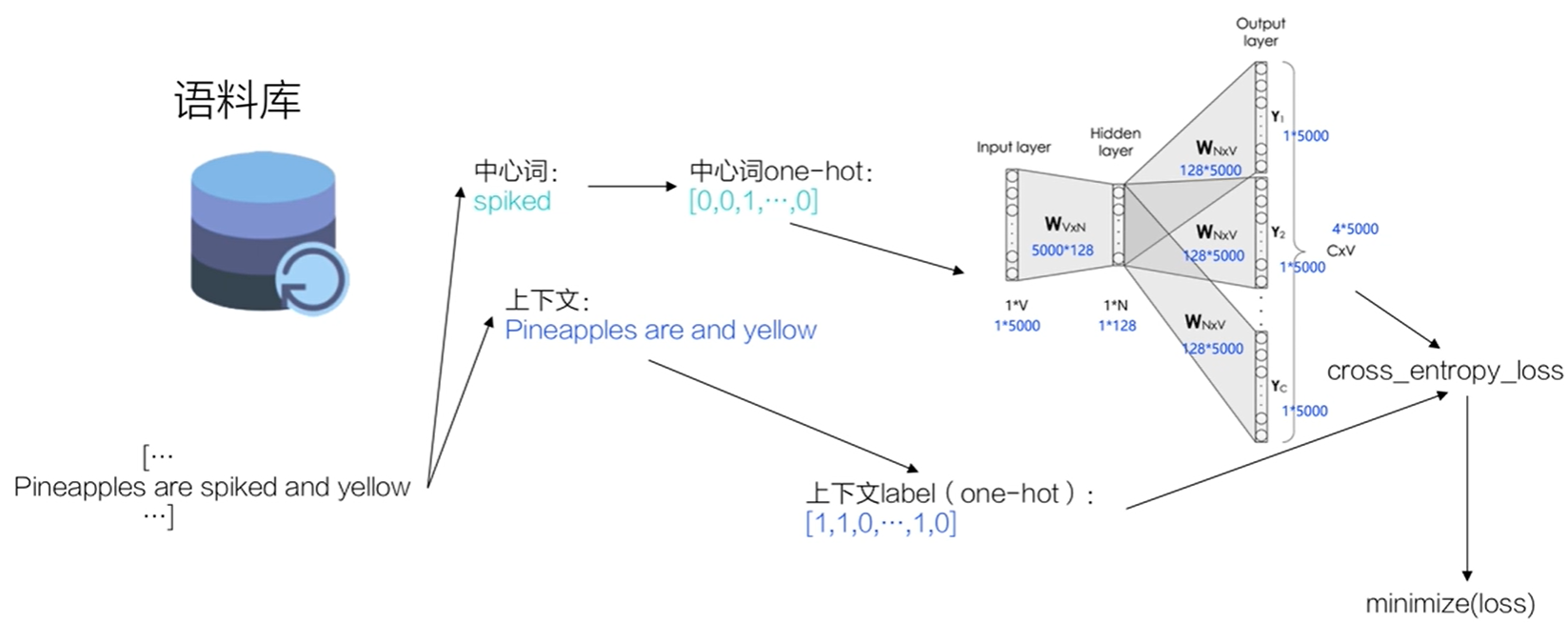
- 假设有一个句子"Pineapples are spiked and yellow"
- 先在句子中选定一个中心词,并把其它词作为这个中心词的上下文。
- 把"Spiked"作为中心词,把"Pineapples、are、and、yellow"作为中心词的上下文。
- 使用上下文的词向量推理中心词,这样中心词的语义就被传递到上下文的词向量中,如"Spiked → pineapple",从而达到学习语义信息的目的。

Skip-gram
根据中心词推理上下文。
- 假设有一个句子"Pineapples are spiked and yellow"
- 先选定一个中心词,并把其他词作为这个中心词的上下文。
- 把"Spiked"作为中心词,把"Pineapples、are、and、yellow"作为中心词的上下文。
- 使用中心词的词向量去推理上下文,这样上下文定义的语义被传入中心词的表示中,如"pineapple → Spiked", 从而达到学习语义信息的目的。

一般来说,CBOW比Skip-gram训练快且更加稳定一些,然而,skip-gram比CBOW更好的处理生僻字(出现频率低的字),原因也正是因为skip-gram不会刻意回避生僻字。
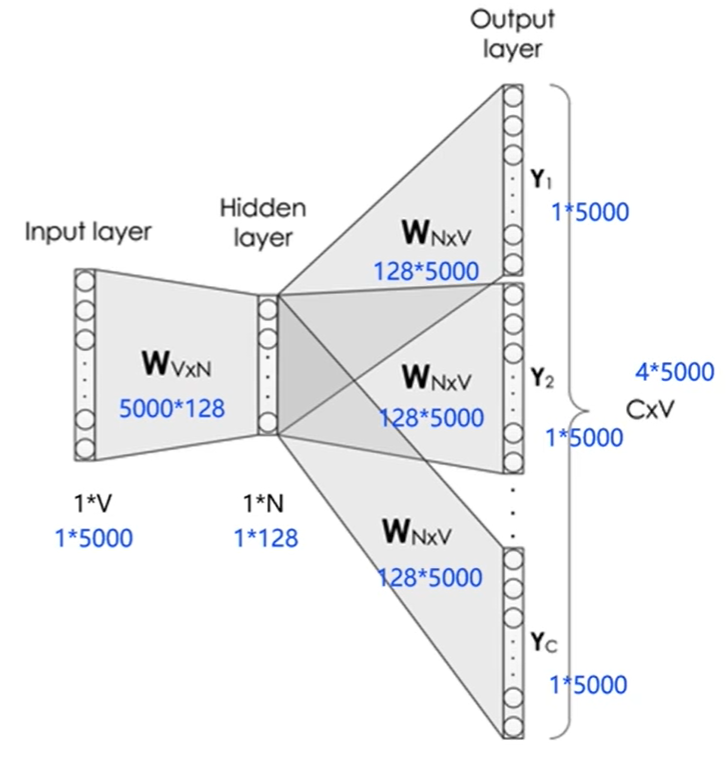
用神经网络实现CBOW
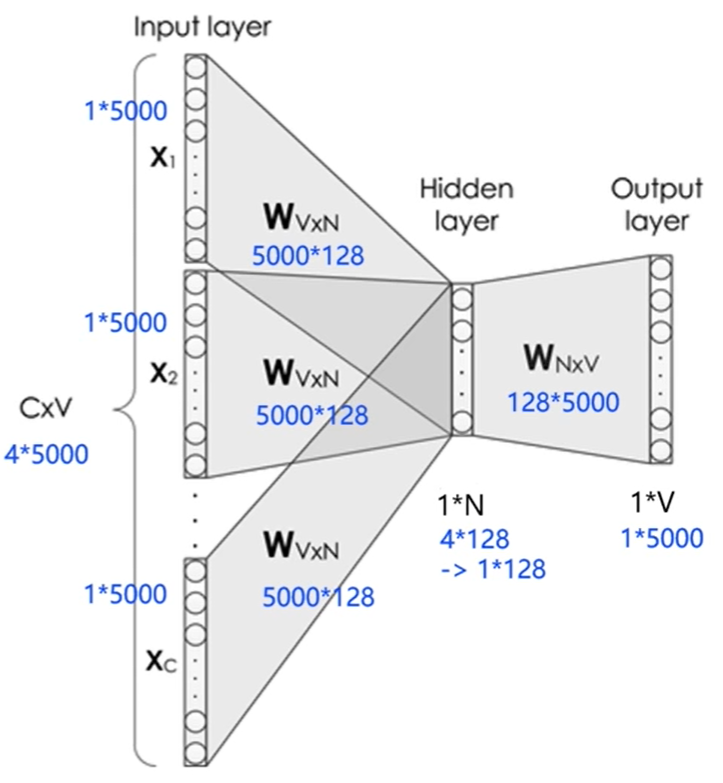
- 给定一句话 " Pineapples are spiked and yellow" , C = 4 , V = 5000 , N = 128
- 模型分为3层
- 输入层: 一个形状为 C×V 的 one-hot 张量,其中C代表上下文中词的个数,通常是一个偶数,我们假设为4;V表示词表大小,我们假设为5000,该张量的每一行都是一个上下文词的 one-hot 向量表示,比如"Pineapples, are, and, yellow"。
- 隐藏层: 一个形状为V×N的参数张量 W1 ,一般称为word-embedding,N表示每个词的词向量长度,我们假设为128。
- 输入张量和word embedding W1进行矩阵乘法,就会得到一个形状为C×N的张量。综合考虑上下文中所有词的信息去推理中心词,因此将上下文中 C 个词 相加 得一个 1×N 的向量,是整个上下文的一个隐含表示。
- 输出层(预测中心词): 创建另一个形状为N×V的参数张量,将隐藏层得到的1×N的向量乘以该N×V的参数张量,得到了一个形状为1×V的向量。最终,1×V的向量代表了使用上下文去推理中心词,每个候选词的打分,再经过 softmax 函数的归一化,即得到了对中心词的推理概率:
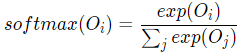
用神经网络实现Skip-gram
- 给定一句话 " Pineapples are spiked and yellow" , C = 4 , V = 5000 , N = 128
- 模型分为3层
- 输入层:一个形状为 1*V的 one-hot 向量,代表中心词
- 隐藏层:一个形状为 V*N 的参数向量 W1,一般称为 word-embedding , N表示每个词的向量表示长度。将输入向量和参数向量 W1 进行矩阵乘法,得到一个形状为 1×N的张量,即词语的向量表示。
- 输出层:创建另一个形状为 N*V 的参数张量 W2 ,将隐藏层输出的 1×N 的向量乘以 W2的张量,得到一个形状为 1 ×V 的向量。代表每个候选词的打分,使用 softmax 函数,对这些打分进行归一化,即得到中心词的预测概率。
用二分类实际实现Skip-gram
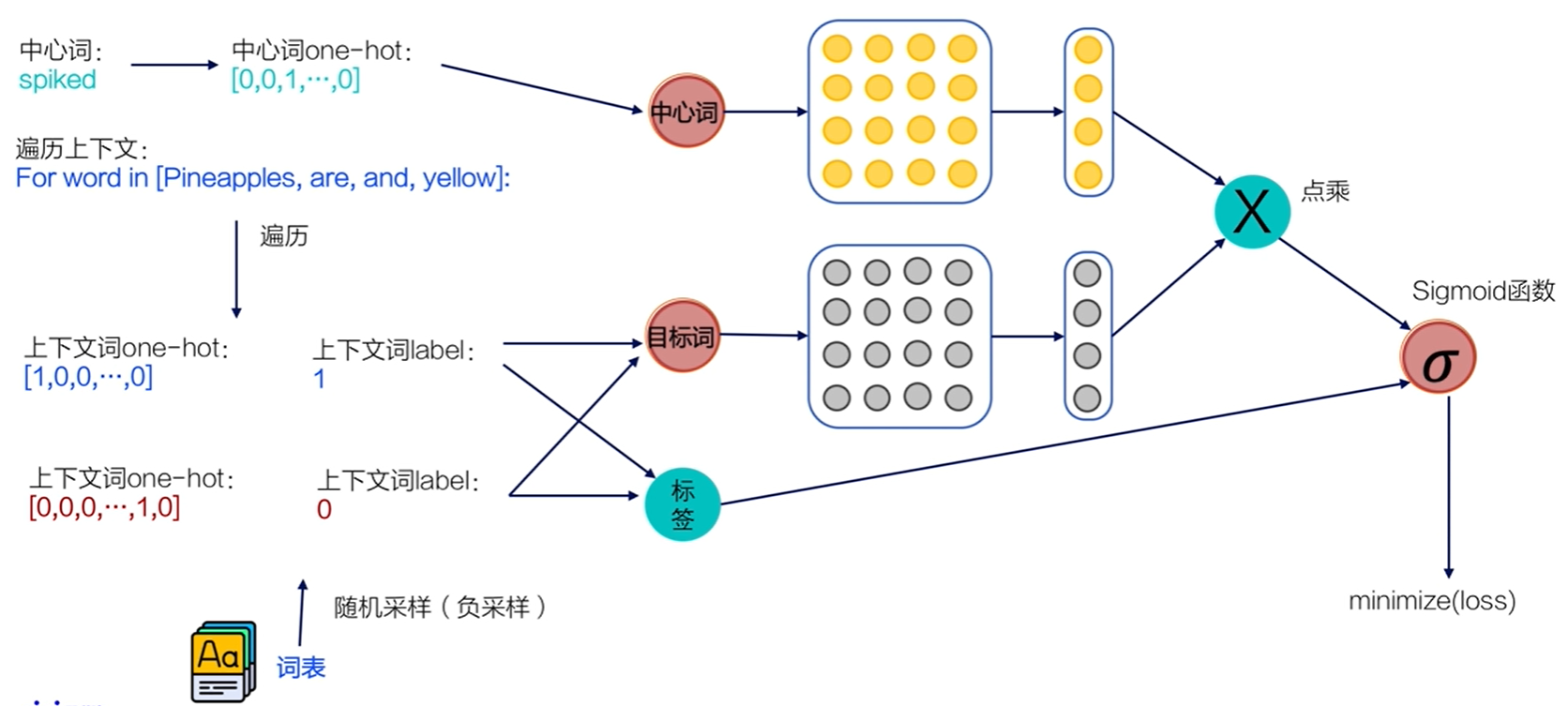
因为在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W0 W1也会非常大。所参与的矩阵运算并不是通过一个矩阵乘法实现,而是通过指定ID,对参数W0获取。对W1一个非常大的矩阵运算
随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。
负采样 :比如,先指定一个 中心词(如"人工")和一个 目标词正样本(如"智能"),再 随机 在词表中采样几个 目标词负样本(如"日本","喝茶"等)。有了这些内容,我们的skip-gram模型就变成了一个 二分类任务。对于目标词正样本,我们需要 最大化它的预测概率;对于目标词负样本,我们需要 最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为 负采样。
使用飞桨实现Skip-gram
找到一个合适的语料用于训练word2vec模型。
使用text8数据集,这个数据集里包含了大量从维基百科收集到的英文语料。
数据处理
- 下载语料
- 把下载的语料读取到程序里
- 切词(分词)
对语料进行预处理(分词)
def data_preprocess(corpus):
# 由于英文单词出现在句首的时候经常要大写,所以我们把所有英文字符都转换为小写,
# 以便对语料进行归一化处理(Apple vs apple等)
corpus = corpus.strip().lower()
corpus = corpus.split(" ")
return corpus
corpus = data_preprocess(corpus)
4、在经过切词后,需要对语料进行统计,为每个词构造ID。
一般来说,可以根据每个词在语料中出现的频次构造ID,频次越高,ID越小,便于对词典进行管理。
word_freq_dict = sorted(word_freq_dict.items(), key = lambda x:x[1], reverse = True)
5、构造3个不同的词典,分别存储
每个词到id的映射关系:word2id_dict
每个id出现的频率:word2id_freq
每个id到词的映射关系:id2word_dict
word2id_dict = dict()
word2id_freq = dict()
id2word_dict = dict()
6、按照频率,从高到低,开始遍历每个单词,并为这个单词构造一个独一无二的id
7、得到 word2id 词典后,把每个词替换成对应的ID,便于神经网络进行处理
8、需要使用 二次采样法处理原始文本。
二次采样法的主要思想是 降低高频词在语料中出现的频次。方法是 随机将高频的词抛弃,频率越高,被抛弃的概率就越大;频率越低,被抛弃的概率就越小。 标点符号或冠词这样的高频词就会被抛弃,从而优化整个词表的词向量训练效果。
使用二次采样算法(subsampling)处理语料,强化训练效果
def subsampling(corpus, word2id_freq):
# 这个discard函数决定了一个词会不会被替换,这个函数是具有随机性的,每次调用结果不同
# 如果一个词的频率很大,那么它被遗弃的概率就很大
def discard(word_id):
return random.uniform(0, 1) < 1 - math.sqrt(
1e-4 / word2id_freq[word_id] * len(corpus))
corpus = [word for word in corpus if not discard(word)]
return corpus
corpus = subsampling(corpus, word2id_freq)
print("%d tokens in the corpus" % len(corpus))
print(corpus[:50])
9、构造训练数据,使用一个滑动窗口对语料从左到右扫描,在每个窗口内,中心词需要预测它的上下文,并形成训练数据。
- 给定一个中心词和一个需要预测的上下文词,把这个上下文词作为正样本。
- 通过词表随机采样的方式,选择若干个负样本。
- 把一个大规模分类问题转化为一个2分类问题,通过这种方式优化计算速度。
negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
附
sorted()
1、先创建一个列表a
2、直接使用sorted方法,返回一个列表就是排序好的
a = [1,5,3,6,2]
sorted(a)
>>[1,2,3,5,6]
3、假如a是一个由元组构成的列表,需要用到参数key,也就是关键词。
lambda是一个隐函数,是固定写法,不要写成别的单词;x表示列表中的一个元素,在这里,表示一个元组,x只是临时起的一个名字,你可以使用任意的名字;x[0]表示元组里的第一个元素,当然第二个元素就是x[1];所以这句命令的意思就是按照列表中第一个元素排序。
x:x[] 字母可以随意修改,排序方式按照中括号 [] 里面的维度进行排序,[0]按照第一维排序,[1]按照第二维排序
a = [('b',4),('a',0),('c',2),('d',3)]
sorted(a,key = lambda x:x[0])
>>[('a',0),('b',4),('c',2),('d',3)]
# 按照第二个元素排序
sorted(a,key = lambda x:x[1])
>>[('a',0),('c',2),('d',3),('b',4)]
4、还可以使用 reverse 参数实现倒序排列
a = [1,5,3,6,2]
sorted(a,reverse = True)
>>[6,5,3,2,1]
Original: https://blog.csdn.net/frcbob/article/details/121857958
Author: oogogogogo
Title: 自然语言处理(NLP)
相关阅读1
Title: windows下VS安装CUDA环境配置
CUDA安装见:https://blog.csdn.net/Ang_go/article/details/122329715
本文内容均在已安装VS和CUDA情况下,如需安装教程,请自行搜索。
windows下VS安装CUDA环境配置
一.CUDA环境配置
1.此电脑->属性->高级系统设置->环境变量->系统变量
在系统变量中新建5个新内容(如图所示):
1.变量名: CUDA_SDK_PATH
变量内容:C:\ProgramData\NVIDIA Corporation\CUDA Samples\v10.2
v10.2指下载版本文件夹,请导航至自己下载版本的文件夹中,下同
2.变量名: CUDA_LIB_PATH
变量内容:%CUDA_PATH%\lib\x64
3.变量名: CUDA_BIN_PATH
变量内容:%CUDA_PATH%\bin
4.变量名: CUDA_SDK_BIN_PATH
变量内容:%CUDA_SDK_PATH%\bin\win64
5.变量名: CUDA_SDK_LIB_PATH
变量内容:%CUDA_SDK_PATH%\common\lib\x64
2.在用户变量的 path中新建4个新内容(如图所示):
%CUDA_LIB_PATH%
%CUDA_BIN_PAHT%
%CUDA_SDK_BIN_PAHT%
%CUDA_SDK_LIB_PATH%
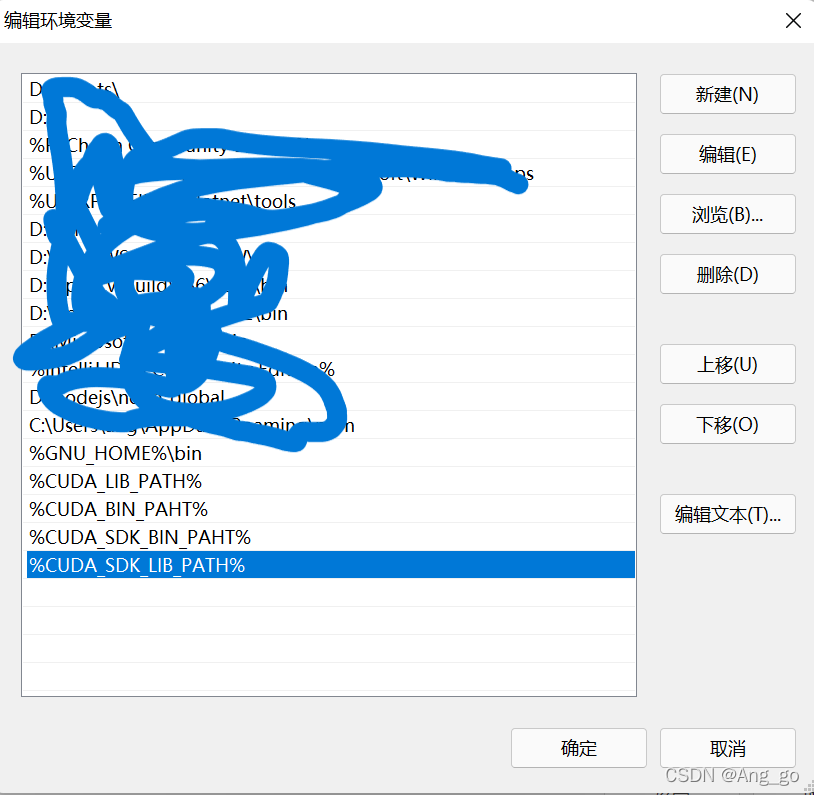
3.测试:win+R,输入cmd,打开命令行,输入 set cuda,显示如下内容,若无显示,请重启,显示如下内容即为1,2步成功,才可进行此步
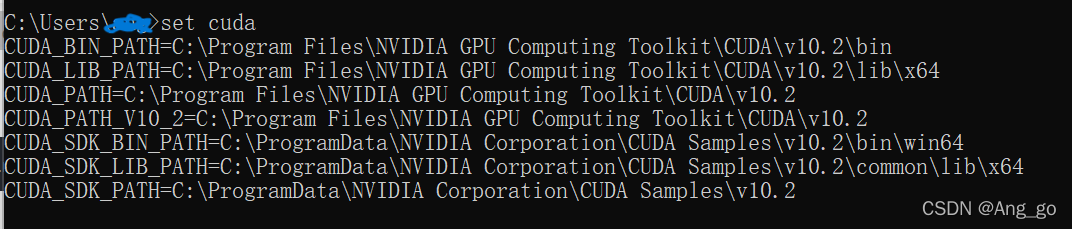
切换如下目录, v10.2指下载版本文件夹,请导航至自己下载版本的文件夹中,下同
cd C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\extras\demo_suite
运行deviceQuery.exe
deviceQuery.exe

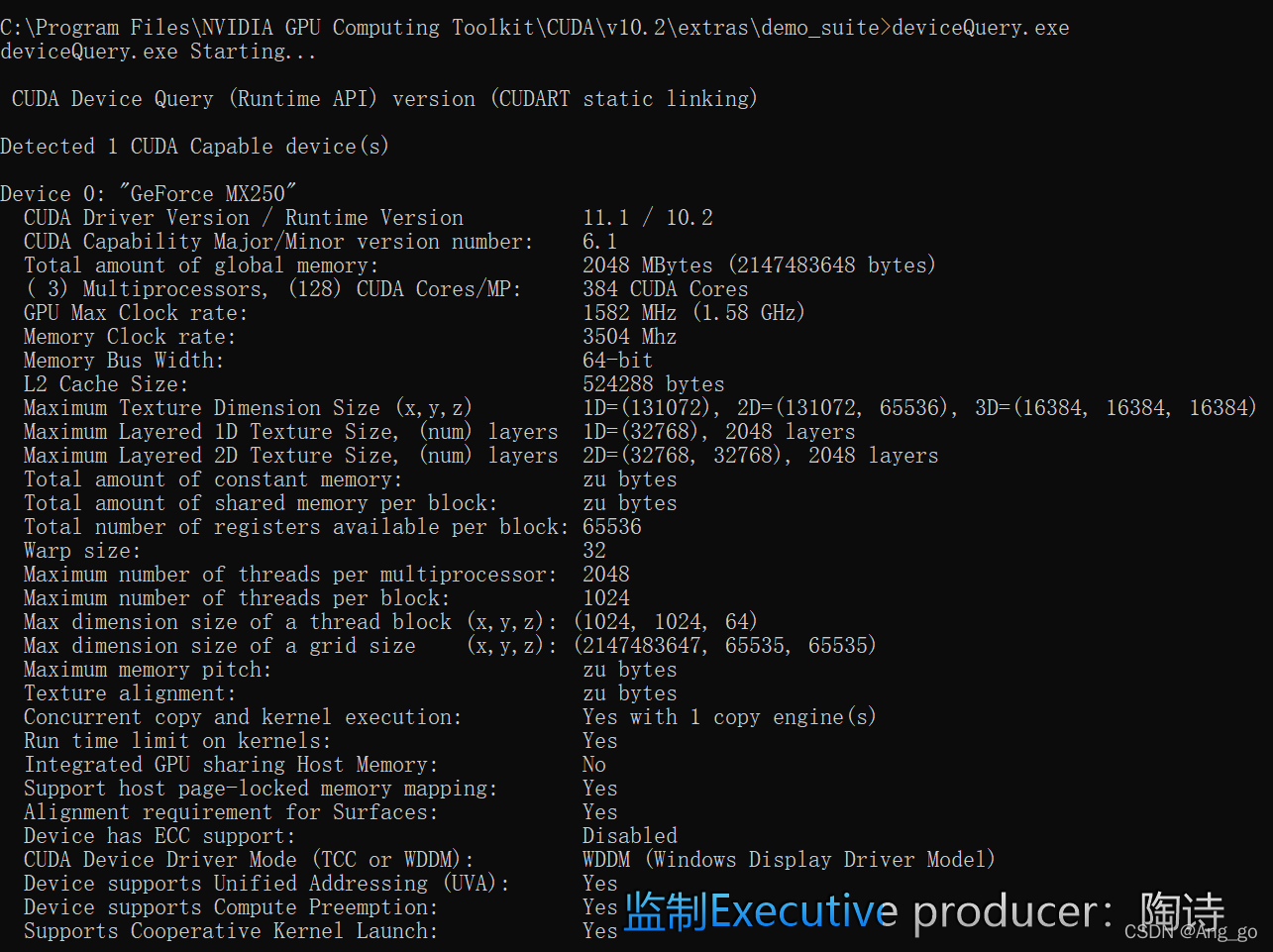
显示如下结果,最后显示Result=PASS,即为成功!

VS中配置CUDA
1.VS新建一个空项目,打开属性管理器
下图1位置,新建一个*.props文件,命名为CUDA_debug_x64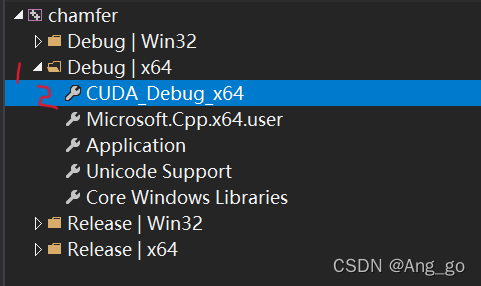
2.右键 刚建的CUDA_debug_x64->属性,如下图
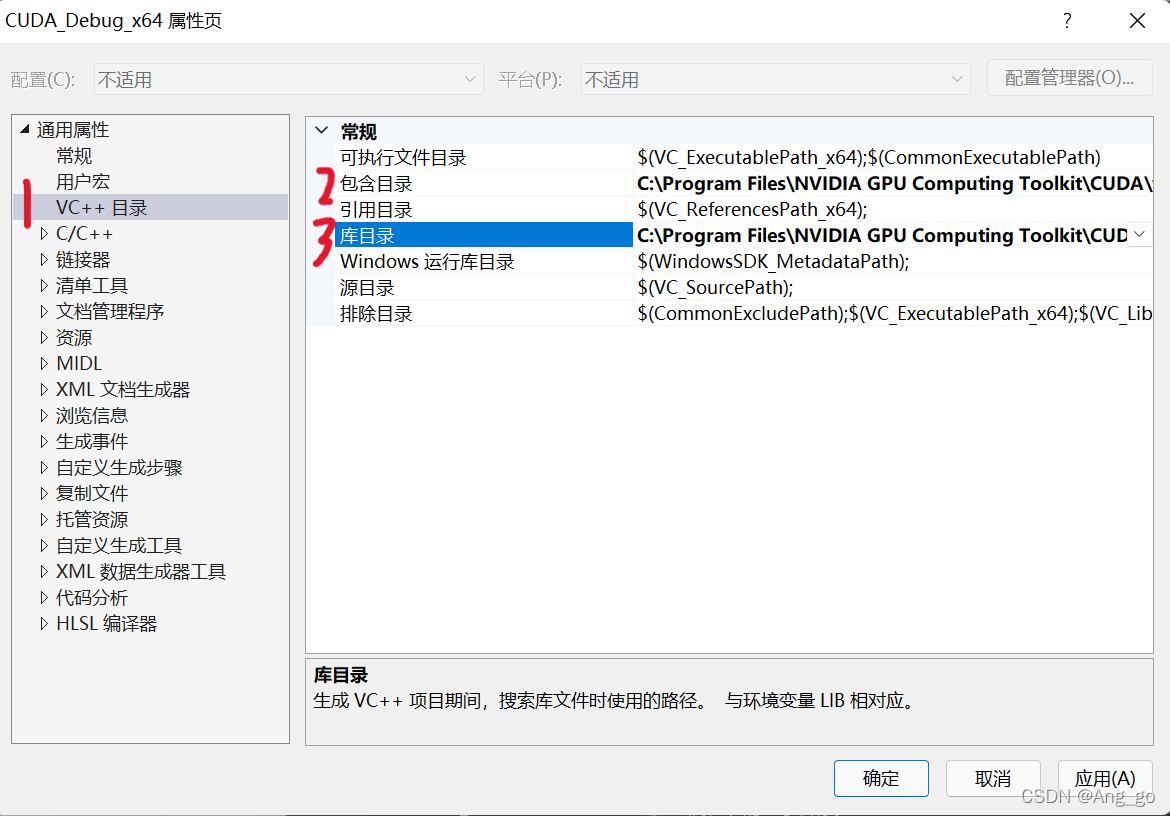 3.VC++目录->包含目录中添加
3.VC++目录->包含目录中添加
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\include
VC++目录->库目录中添加
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1\lib\x64

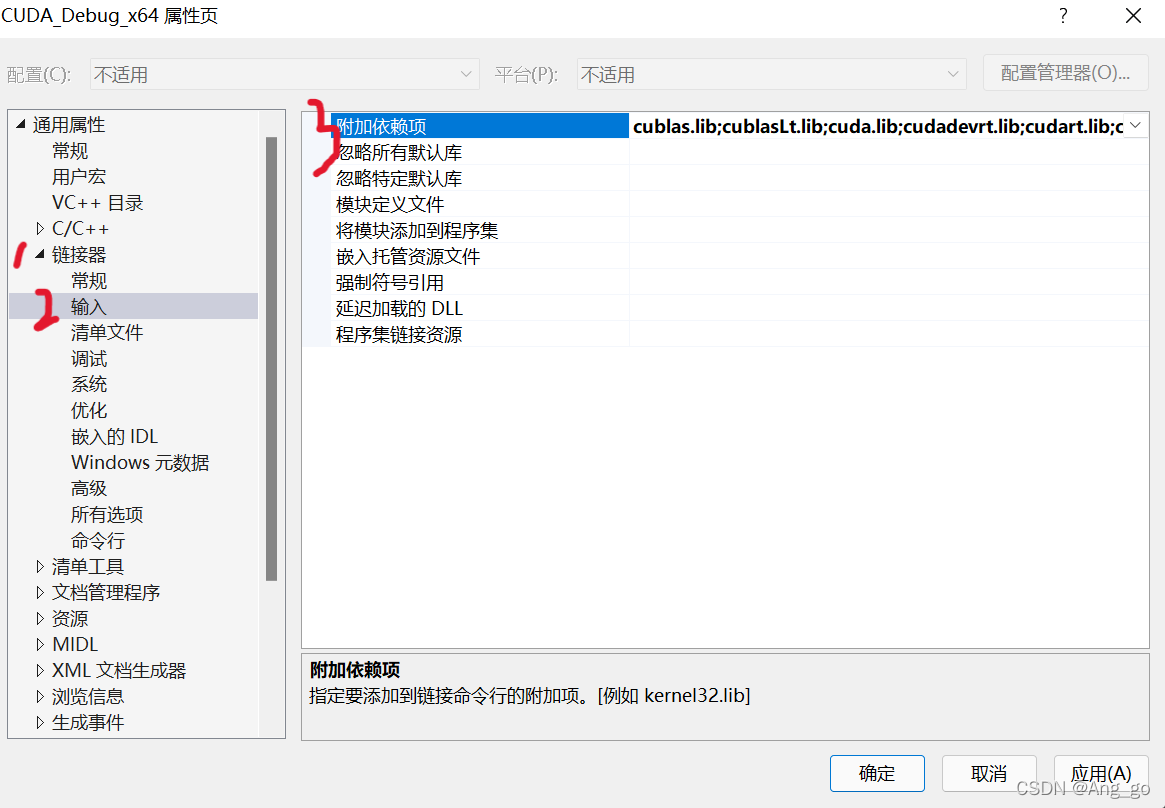
4.仍然是上一步属性中 ->链接器->输入->附加依赖项,添加下述内容(见图)
cublas.lib
cublasLt.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppicom.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvgraph.lib
nvml.lib
nvrtc.lib
OpenCL.lib
🆗!!
Original: https://blog.csdn.net/Ang_go/article/details/122734873
Author: Ang_go
Title: windows下VS安装CUDA环境配置
相关阅读2
Title: 语音识别中代价函数_【语音算法系列】声纹识别助力身份认证
声纹识别,也称为说话人识别(speaker recognition),是一种基于语音中能表征说话人的信息,来判别说话人身份的生物特征识别技术,相比其他生理特征在远程身份认证中具有先天优势。
拨云见日--初识声纹
生活中对于声纹最直观认识就是:我们在打电话时,一声"喂?"就能分辨出接电话的人是谁。从直觉上来讲,说话人语音的差异并不如人脸、指纹的差异那么直观,但是由于每个人的声道、口腔、鼻腔都各具差异,这些个体差异可以直接反映到人们的发音上。
人脸识别和指纹识别都是基于图像的二维信号,而语音是一种时变的一维信号,其表现形态简单,但蕴含的语音信息非常丰富。以下图为例,展示的是贝壳的唤醒词"hey,小贝"的时域波形图,其承载的首先是语意信息,即唤醒词,其次它还可以包含语种(中文、英文)信息,性别信息,情感信息(高兴、悲伤......)等等,而在这成百上千的语音信息背后只对应了一个唯一不变的身份信息。

继续观察"hey,小贝"的波形特征,比较不同人说话之间的差异。图1是说话人A对应的"贝",图2是说话人B对应的"贝",图3是说话人A对应的"小"。
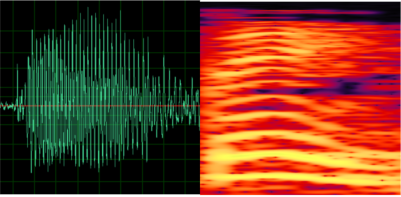
图1
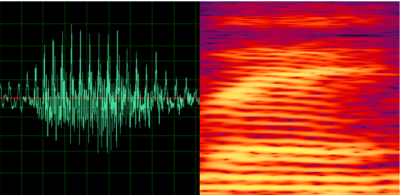
图2
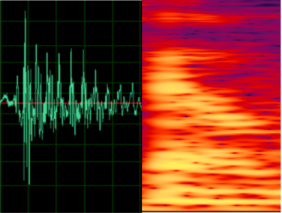
图3
如果左侧的语音波形图不够直观,我们也可以观察右侧对应的语音频谱图。从图片上看,似乎图1和图2更相似一点,但实际上图1和图3来自同一个人,因为图3承载了不同的语义信息,所以图3和图1,图2有了明显的差异。在语音识别中声纹特征有助于语音识别,而在声纹识别中语义信息反而会影响声纹特征的提取,因此在这句话的声纹识别中干脆不要比较"小"和"贝",直接都比较同一个字"贝"好了,这样更容易分析出声纹的差异。所以,根据声纹识别是否比较同一批字也可以将声纹识别进行应用上的分类,将在下一节进行详细介绍。
声纹识别的应用分类
从发音是否受限上来区分,声纹识别可以分为文本无关识别与文本相关识别。
文本无关:顾名思义就是声纹识别系统对用户的输入语音内容不做限制,识别系统需要克服用户发音的多变性和差异性,从中挖掘出用户唯一的身份信息,对发音背后的身份做出准确判断。
文本相关:识别时会限制发音词典,要求说特定文本,往细了分,文本相关又可以分为文本全相关和文本半相关。文本全相关就是固定识别口令,比如在我们的唤醒系统中,只有用户说"小贝,小贝"或者"hey,小贝",系统才会去识别声纹,而说其它词,则概不识别;而文本半相关就是将发音限制在有限的集合中,一般使用在账户登录、支付等场景,在这些种场景中,系统会随机搭配一些数字,用户需要根据字符顺序正确的念出内容才可以进行声纹判断,这种随机性的引入无疑提升了系统的安全性,保障了用户的安全,杜绝了仿冒、窃取、复制用户声纹信息的可能性。
除了从发音是否受限来区分声纹应用外还可以从识别场景上来分类声纹应用,具体可以分为以下两类:说话人确认(Speaker Verification,SV)、说话人辨认(Speaker Identification,SI):
说话人确认:是一种1对1的二分类问题。系统需要接收到一段待识别语音和该段语音的说话人编号,然后计算出该段语音的声纹特征并与数据库中对应的声纹特征进行比对,如果比对分数高于预设阈值则通过,否则拒绝。这方面典型的应用就是手机端的声纹锁和唤醒系统等。
说话人辨认:是一种1对多的判别问题。系统需要接收到一段未知说话人的待测语音,然后将这段语音与声纹库中的一系列声纹信息进行比对。如果比对分数均高于预设阈值,则输出比对分数最高的那个说话人,如果比对分数均低于预设阈值,则说明该声纹库中暂未录入该说话人信息。
说话人辨认的典型应用有刑侦、智能推荐、风控管理等。在贝壳的经纪人业务指标考量体系中,为了防止经纪人私下作弊,互相刷业绩,引入了说话人辨认系统,贝壳声纹系统可以对语音中客户的录音进行声纹辨认,通过建立的经纪人声纹库并结合说话人辨认系统的检索功能,及时发现经纪人冒充客户的情况,加强了对经纪人工作的管控及对客户身份的有效辨别。
声纹识别的性能评价指标
初步了解完声纹的表象特征和其应用场景后,本小结开始逐步深入声纹内部,介绍一下声纹识别的主要性能指标。
首先,声纹识别系统最重要的两个性能指标: 错误拒绝率(False Rejection Rate,FRR)和 错误接受率(False Acceptance Rate, FAR)。这是说话人确认系统中的两种错误情况。
错误拒绝率:分类问题中,若两个样本为同类(同一个人),却被系统误认为异类(非同一个人),则为错误拒绝。错误拒绝率为错误拒绝案例在所有同类匹配案例的比例。
错误接受率:分类问题中,若两个样本为异类(非同一个人),却被系统误认为同类(同一个人),则为错误接受。错误接受率为错误接受案例在所有异类匹配案例的比例。
为了直观的说明这两种错误情况可以用贝壳的唤醒系统来举例:假设唤醒系统的错误拒绝率为3%,就是当真实用户唤醒100次时会出现3次设备不被唤醒的情况;假设错误接受率为0.3%,就是当1000个人假冒用户唤醒设备时会有三个人唤醒成功。
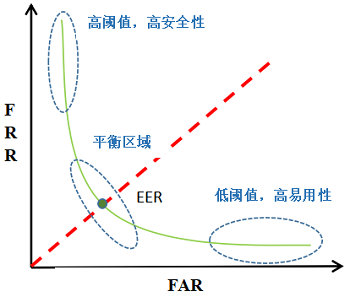
等错误率(Equal Error Rate, EER):声纹系统中会设置一个判断阈值,该阈值与FRR和FAR都相关。当系统中阈值固定,FRR与 FAR也会相应固定。当阈值降低时,会有更多的测试通过,此时FAR增大,FRR减小;反之,阈值增大,测试更不易通过,FRR增大,FAR减小。随着阈值的变化,如图所示,EFR和EFA将会绘制出两条曲线,我们将两条曲线的交点的错误率定义为等错误率EER,此时EER = FRR= FAR,EER是说话人确认系统中最常用的性能评价指标。

检测误差权衡曲线(Detection Error Trade-off, DET) :DET曲线也是声纹识别中常用的评价方法,如图所示,DET曲线建立对数刻度下FAR与FRR的关系,曲线与45°线的交点即为 EER 点,曲线上的不同点对应不同的阈值。曲线离原点越近,FAR与 FRR越小,系统性能越好。
最小检测代价(Minimum Detection Cost Function, minDCF):DCF是NIST SRE(声纹识别技术评测)中定义且常用的一种性能评定方法。其定义为:
公式中CFR和CFA分别代表错误拒绝和错误接受的惩罚代价,Ptarget和1 − Ptarget分别为真实说话测试和假冒测试的先验概率。可以根据不同的应用场景来设定它们的值。当 CFR、CFA、Ptarget和1−Ptarget取定后,EFR与 EFA的某一组取值使得DCF最小,此时的DCF为minDCF。在NIST SRE 2008中设定CFR=10,CFA=1,Ptarget=0.01为准。minDCF不仅考虑了两类错误的不同代价,还考虑了两种测试情况的先验概率,比EER更合理。
动中取静-从语音信号到声纹特征
第一章中提到了,声音之所以能被用于说话人识别,是因为每个人的口腔、鼻腔与声道都存在着个体差异,但这些差异既看不到也摸不着,更要命的是,声音还是一个时刻变化同时包含成百上千信息的一维信号,正是这些特点使声纹识别具有极强的安全性的同时也具有巨大的挑战性。那么,如何从语音中提取纯粹的声纹特征呢?
从离散信号到语音特征
对于语音信号,我们只能通过各种录音设备采集到它的离散信号,间接的分析发声器官的差异。虽然语音一直在变,但是其具备了一个良好的性质--短时平稳性,即在20-50毫秒的范围内,音频可以近似看作一段良好的周期信号。
这种短时平稳性为语音信号的分析提供了极大的便利,在音频的音调,响度和音色这些基本属性中,音色是最能反映身份信息的(当产品经理向你提需求的时候,响度和音调都可以快速飙升,但音色是不大会剧烈变化的)。音色的差异在信号层面可以表示为音频在频域不同频段能量的差异,因此我们选取音频不同频段上的能量值,表示这个短时语音的特征属性。
一般我们根据人耳的听觉属性(人耳对1000~4000Hz的声音最敏感),均衡不同频段的能量差异,设计一个合适的短时声学特征,通过一系列复杂的信号处理,将一段20-50毫秒长度的语音以映射为一段13-80维的向量。同时为了保留语音信息又不增加计算量,通常会以10-20ms的间隔依次取短语音,然后提取特征。
在声纹识别方面,传统的声学特征包括梅尔倒谱系数MFCC、感知线性预测系数PLP等,都是可选的并具有良好表现的声学特征。
通过以上方法,输入系统的语音段就被映射成为一组向量集合,这部分特征集合再通过一些规整化(CMVN、LDA)操作后,就可以成为反映发音特性的语音特征集合。但仅靠这些语音特征集合还难以直接表达声纹特征,这时就需要各种建模方法来抽取特征中有关声纹的信息了。
从语音特征到声纹特征
声纹识别系统是一个典型的模式识别的框架,系统会对目标用户的一段语音提取语音特征,然后将其映射为用户的声纹特征。因此,声纹识别性能的好坏的关键在于系统对语音中身份信息的建模能力与区分能力,同时对身份无关信息的抗干扰能力和鲁棒性。
按照时间先后,声纹识别技术的发展可以大致分为:模板匹配 -> GMM-UBM -> GMM-SVM -> JFA -> I-Vector PLDA -> DNN I-Vector PLDA -> E2E。以下简单介绍三个经典的声纹识别算法。
GMM-UBM:高斯混合模型(GMM)是一系列的高斯分布函数的线性组合,理论上GMM可以拟合出任意类型的分布。一个充分训练的GMM模型,可以比较好的表征说话人的空间。通用背景模型(UBM)实际上是一个表征大量非特定说话人语音特征分布的GMM。UBM的训练通常采用大量的与特定说话人无关、信道无关的语音数据,因此它只是拟合人的语音特征分布,而并不代表某个具体的说话人。在进行声纹特征提取时,通常利用少量的说话人信息和一个UBM,通过自适应算法(如大后验概率MAP、最大似然线性回归MLLR等)得到声纹特征。
I-Vector:在实际应用中,由于说话人语音中说话人信息和各种干扰信息掺杂在一起,不同的采集设备的信道之间也具有差异性,会使我们收集到的语音中掺杂信道干扰信息。这种干扰信息会引起说话人信息的扰动。传统的GMM-UBM方法,没有办法克服这一问题,导致系统性能不稳定。联合因子分析(Joint Factor Analysis, JFA)可以对说话人差异和信道差异分别建模,从而可以很好的对信道差异进行补偿,提高系统表现。但由于JFA需要大量不同通道的训练语料,获取困难,并且计算复杂,所以难以投入实际使用。基于I-Vector因子分析技术,提出了全新的解决方法。JFA方法是对说话人差异空间以与信道差异空间分别建模,而基于I-Vector的方法是对全局差异进行建模,将其二者作为一个整体进行建模,这样处理放宽了对训练语料的限制,并且计算简单,性能也相当。
X-Vector:利用深度神经网络可以比I-Vector更好的利用大数据,在大数据集下训练的神经网络模型的性能已经超越了I-Vector。其中X-Vector是这类神经网络模型的代表,其声纹特征提取流程如下:
Layerlayer contextotal contexinput*outputframe1{t-2,t+2}5120x512frame2{t-2,t,t+2}91536x512frame3{t-3,t,t+3}151536x512frame4{t}15512x512frame5{t}15512x1500stats-pooling[0,T]T1500Tx3000segment6{0}T3000x512segment7{0}T512x512
声纹特征提取的前5层为TDNN层,输入帧级别语音特征,到了第四和五层时,每1帧实际包含上下文15帧的信息,由于输入神经网络的语音通常具有不同的长度,在统计池化层(stats pooling)神经网络会计算所有输入帧的均值和方差,并将这两个统计量拼接起来作为segment6的输入,segment6和segment7为全连接层,负责输出说话人对应的声纹特征。通常我们会在segment6和segment7中进行比较并选择其中表现更好的作为最后输出的声纹特征。
声纹特征后处理
由于声纹特征中不仅包含说话人差异信息,同时也存在信道差异信息,此时需要信道补偿技术来消除声纹特征的信道干扰,主要有以下两种信道补偿方法:
线性鉴别分析(LDA):LDA的主要作用是最大化类间距离,最小化类内距离,体现在声纹识别中就是:当一个说话人有很多语音时,这些语音在说话人空间中聚集为一簇,如果这些语音的输入设备或输入方式不同,就会受到信道的影响,那么该说话人这些语音方差会很大。此时,LDA尝试着找到一个新的方向,将原来的所有数据投影到这个方向,使得在这个方向中同一说话人的数据具有最小的类内方差,同时不同说话人之间的距离尽量大,这样,就可以减小信道差异的影响了。同时LDA也是一种降维方法。它尽量移除特征中不需要的方向,最小化类内方差信息量,也就是,LDA寻找一个新的方向去更好地对不同的类做出分类。
概率线性判别分析(PLDA):又称为概率形式的LDA,其信道补偿能力比LDA更好,目前已成为主流信道补偿算法。
贝壳的声纹识别
目前,虽然已经有许多成熟的算法使声纹识别的准确率得到了显著的提高,但相对于其它的生物特征(人脸,指纹),声纹识别仍需要很多努力才能达到相同的水准。在贝壳的声纹识别算法中,我们使用了百万人级别的训练数据对声纹系统进行训练,相较于小数量级的系统,性能得到明显提升,即使在万人级别的测试集中,EER仍可以降低到1%以下。除此之外我们还通过以下方法改善了声纹引擎在实际使用中的体验。
多算法结合
根据声纹发展历程,总结各类声纹算法的优缺点后,我们在声纹识别系统中集成了多种声纹技术,可以针对场景使用不同的声纹技术。例如:在唤醒系统上,虽然唤醒词是短语音,但是其发音集有限,是一种文本相关的声纹识别,在实验中I-Vector的效果比X-Vector更好,因此在唤醒系统上我们选择I-Vector模型;而在风控领域,声纹识别主要应用在说话人辨认的场景,对声纹引擎有比较高的准确率要求,因此系统融合多种声纹算法计算出的声纹特征,输出更准确的声纹信息。
抗噪音
在贝壳声纹的应用场景中,面临的最大问题就是噪音场景下的声纹识别。最然声纹模型可以通过加噪训练去改善噪声环境下声纹识别准确率,但是每种技术都有一定的局限性,不能无限制的使用在任何场景。因此,我们在系统中集成了环境语音检测系统,该系统可以监测输入语音长短、音量和信噪比,将不符合声纹识别的语音隔离在系统之外。这套系统中使用了结合能量和神经网络的端点检测算法(端点检测相关算法及原理请关注下一期语音算法系列公众号),该算法可以有效排除噪音、背景人声、环境音等不利于声纹识别的语音,使噪声场景下声纹识别的准确率得到进一步提升。
抗时变
人的发声器官并不是一个一成不变的系统,随着时间的推移,人的声音也会产生一定的变化,这些发音变化直接导致了其语音中声纹信息的变化。模型训练时如果不把这些变化考虑进去,那么一段时间后,系统的准确率将会下降。因此,我们持续采集了一批人不同时间段的语音,构建了时变语音库,基于此语音库我们找到声纹随时间变化的一些信息,训练出针对时变更具鲁棒性的模型。同时,我们的声纹引擎中也专门设计了声纹更新算法,可以定时挑选用户符合条件的近期语音更新声纹特征库。
总结
声纹特征作为生物特征中的行为特征,可以做到对用户无感核身,提升系统安全性的同时减少用户身份验证时间,这是其他生物特征难以替代的优势。当然,任何技术都有一定的局限性,只有通过结合声纹和其他生物特征组成多因子身份认证,才能更好地提升身份认证的安全性。
作者介绍
颜瑞,2020年1月毕业于北京科技大学自动化学院,毕业后加入贝壳找房语言智能与搜索部语音交互团队,主要从事语音识别等相关工作。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面 最上方"AINLP",进入公众号主页。
(2)点击 右上角的小点点,在弹出页面点击" 设为星标",就可以啦。
感谢支持,比心 。
。
欢迎加入语音技术交流群 进群请添加AINLP小助手微信 AINLPer(id: ainlper),备注语音技术
推荐阅读
这个NLP工具,玩得根本停不下来
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
从数据到模型,你可能需要1篇详实的pytorch踩坑指南
如何让Bert在finetune小数据集时更"稳"一点
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的"不完全"心得总结番外篇——submodular函数优化
Node2Vec 论文+代码笔记
模型压缩实践收尾篇——模型蒸馏以及其他一些技巧实践小结
中文命名实体识别工具(NER)哪家强?
学自然语言处理,其实更应该学好英语
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧?
Original: https://blog.csdn.net/weixin_32047681/article/details/112415288
Author: 科学火箭叔
Title: 语音识别中代价函数_【语音算法系列】声纹识别助力身份认证
相关阅读3
Title: 重磅!公开基于“内心对话”的EEG脑机接口数据集,助力语音意念控制研究

脑电图是一种标准的、无创的测量脑电活动的方法。人工智能的最新进展让大脑模式的自动检测得到显著改进,允许越来越快、更可靠和可访问的脑-机接口。很多的范式已被用于实现人机交互。在过去的几年里,对解释和描述"内心声音"现象的兴趣有了广泛的增加。这种被称为"内在言语"的范式,提高了仅通过思考来执行命令的可能性,允许以一种"自然"的方式控制外部设备。由于缺乏公开可用的脑电图数据集,限制了内部语音识别新技术的发展。
本项研究给出了在此模式下采集的10个参与者数据集,以及另外两种相关模式下采集的136个通道数据集。本项工作的主要目的是为科学界提供一个开放访问的内部语音命令的多类脑电图数据库,可以用来更好地理解相关的大脑机制。

为了在用户和设备之间建立通信,已经使用了不同的范式被应用于脑机接口,比如P300、稳态视觉诱发电位(SSVP)和运动想象。虽然这些范式被应用于 BCI 系统中取得了很大进步,但对于某些应用来说,它们仍然不能带来有效的控制设备的方法。这主要是因为它们速度太慢或者需要用户付出很大的努力,从而限制了BCIs在现实生活和长期应用中的适用性。
而基于语音相关范式(无声、想象或内部语音)的 BCI 寻求解决上述限制的方法,因为它们为控制外部设备提供了一种更自然的方式。大多数语言模型和理论一致认为,语音涉及听觉处理、语义和句法处理以及运动规划和发音过程。尽管上述三种范式之间存在重大而明显的理论差异,但它们在文献中经常被不一致和误导地提及。在本文中,我们介绍了这三种范式中每一种范式的主要特征。
无声讲话是指正常讲话时产生的发音,但不发出声音。通常使用运动捕捉设备、成像技术或通过测量肌肉活动来测量,而不仅仅是通过大脑信号。此外,Cooney等人提出了一个类似的范式,称为"预期语音",要求没有发声能力的参与者进行语音。
想象言语类似于无声言语,但它是在没有任何发音动作的情况下产生的,就像说话的运动想象一样。在这里,参与者必须感觉自己好像在讲话,主要集中在不同的发音手势。该范式被广泛应用于EEG、ECoG信号和脑磁图。在DaSalla等人中,元音/a/和/u/是经过仔细挑选的,因为它们有最不同的发音过程。要求的动作是:对于元音/a/,"想象张口和想象发声";对于元音/u/,"想象圆唇和想象发声"。在Pressel等人中,要求的动作是:"想象这个发音,或者把给出的单词发音作为提示。"最后,Zhao等人所使用的类(提示)被选为具有不同发音,正如作者所提到的:"这些提示被选为保持鼻音、爆破音、元音以及浊音和清音的数量相对均匀"。
内在言语被定义为人以纯意义思维的内化过程,通常与自己内心"声音"的听觉意象相关联。它也被称为言语思维、内心对话、隐秘的自我谈话、内心独白、内心说话。不像想象的和无声的讲话,外部对话的音韵特征和话轮转换特征都没有保留。与运动系统中的大脑信号相比,语言处理似乎更加复杂,涉及不同皮层区域的神经网络,这些区域参与语音或语义分析、语音产生和其他过程。
为了提高对内部语音及其在真实BCI 系统中的应用的理解,我们构建了一个多语音相关的 BCI 数据集,在三种不同的条件下执行四项心理任务:内部语音、发音言语和视觉状态。该数据集将允许未来的用户探索内部语音是否激活与发音相似的机制,或者它是否更接近于可视化空间位置或运动。每个参与者在一天的记录中进行了 475 到 570 次试验,获得了一个包含超过 9 小时连续 EEG 数据记录的数据集,超过 5600 次试验。
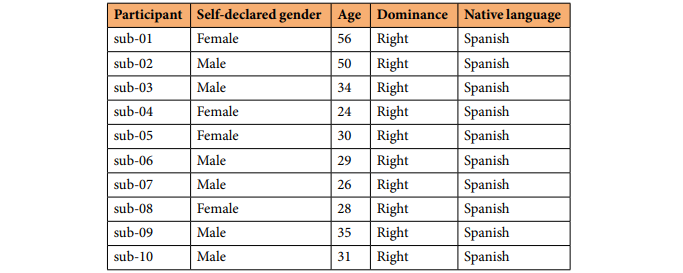
数据采集
下图为参与者信息:
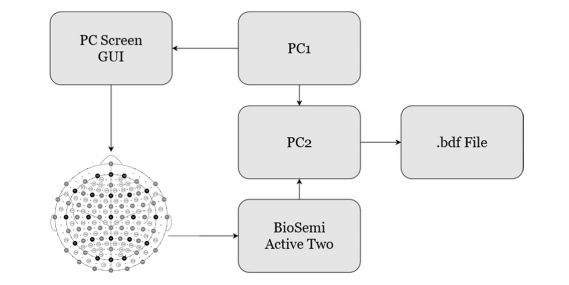
上图为实验设置。两台计算机 PC1 和 PC2 都位于采集室外。PC1 运行刺激协议,同时与 PC2 通信显示的每个提示。PC2 从采集系统接收采样的 EEG 数据,并使用从 PC1 接收到的信息标记事件。录制结束时,创建并保存了 a.bdf 文件。
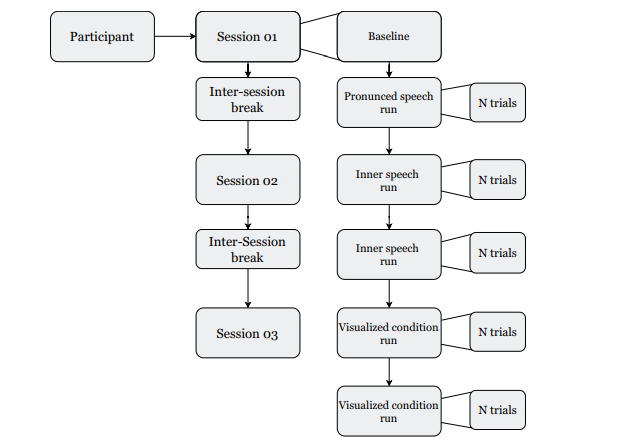
为每个参与者安排记录日。
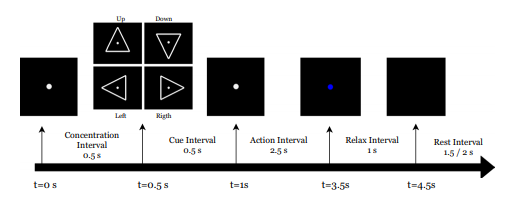
工作流程。在每个时间间隔内呈现给参与者的屏幕被绘制在图的顶部箭头上。相对时间和全局时间分别绘制在箭头上方和下方。
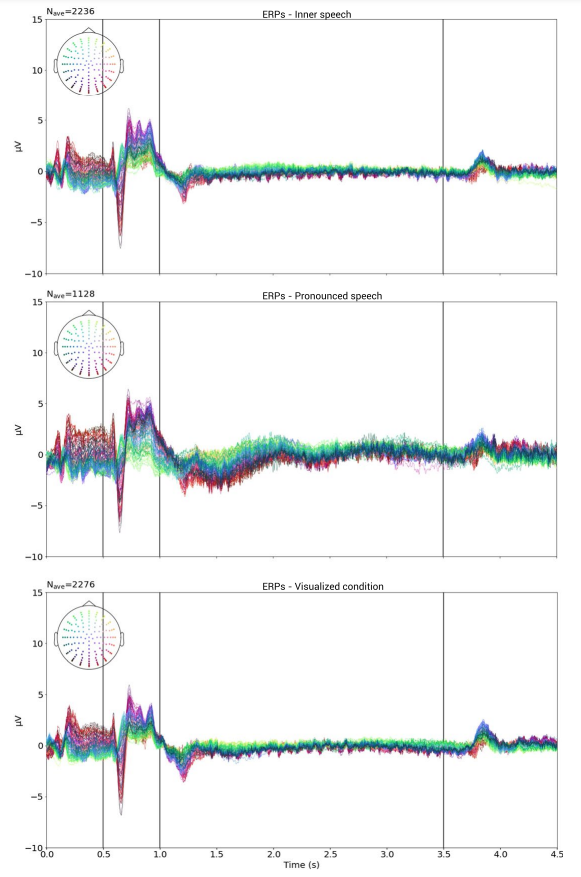
每个类别的全局平均试验。垂直的黑线对应区间边界,如上图所示。顶行:内部语音,中间行:发声语音。底行:可视化条件。
文件结构:
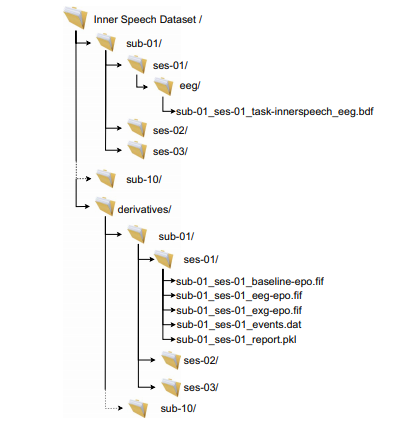
数据集地址:
https://openneuro.org/datasets/ds003626/versions/2.1.0
参考
Nieto, N., Peterson, V., Rufiner, H.L. et al. Thinking out loud, an open-access EEG-based BCI dataset for inner speech recognition. Sci Data 9, 52 (2022). https://doi.org/10.1038/s41597-022-01147-2
仅用于学术交流,不用于商业行为,若有侵权及疑问,请后台留言,管理员即时删侵!

更多阅读



点个在看祝你开心一整天!
Original: https://blog.csdn.net/zyb228107/article/details/122974971
Author: 脑机接口社区
Title: 重磅!公开基于“内心对话”的EEG脑机接口数据集,助力语音意念控制研究