
引言
本文主要介绍了SBERT作者提供的官方模块的使用实战。
通过Sentence-BERT了解句子表示
Sentence-BERT(下文简称SBERT)用于获取固定长度的句向量表示。它扩展了预训练的BERT模型(或它的变种)来获取句子表示。
SBERT常用于句子对分类、计算句子间的相似度等等任务。
在了解SBERT的细节之前,我们先看下如何使用预训练的BERT模型来计算句子表示。
计算句子表示
考虑句子 Paris is a beautiful city,假设我们要计算该句子的向量表示。首先,我们需要分词并增加特殊标记:
tokens = [ [CLS], Paris, is, a, beautiful, city, [SEP] ]
接着,我们把这些标记列表喂给预训练的BERT模型,它会返回每个标记的单词表示:
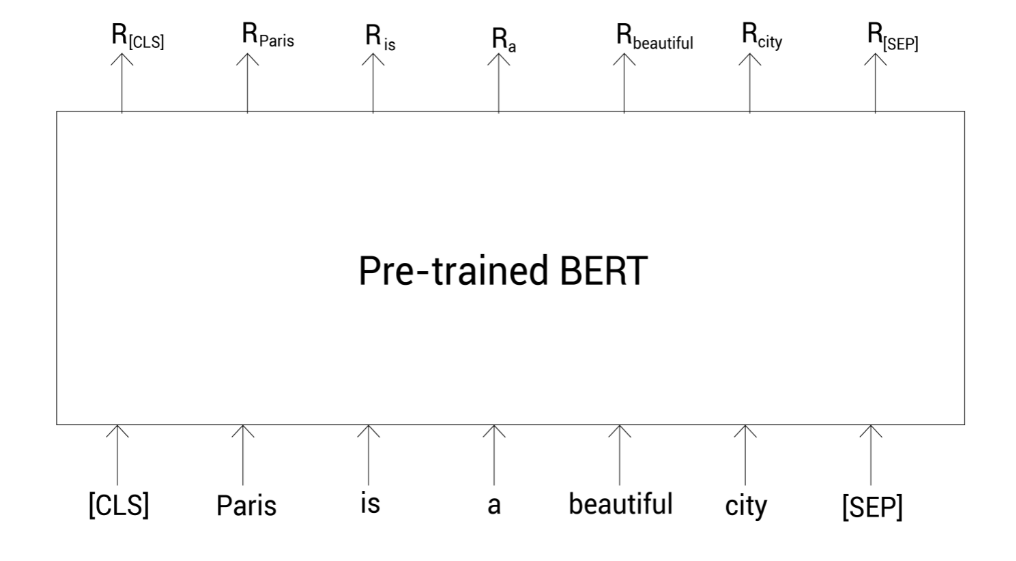
我们已经得到了每个单词的表示,那我们如何得到整个句子的表示呢?我们知道 [CLS]标记保存了整个句子的压缩表示。所以我们可以使用该标记对应的向量作为句子表示:
Sentence representation = R [ C L S ] \text{Sentence representation} = R_{[CLS]}Sentence representation =R [C L S ]
但是这样做会有一个问题,就是这种句子表示是不精确的,尤其是我们直接使用未经微调的预训练的BERT。所以,除了这种方式,我们可以使用池化策略。即,我们通过池化所有标记的表示来作为句子表示。
池化可分为平均池化和最大池化。平均池化就是取所有单词表示向量之和的均值,而最大池化则是取 [CLS]标记的输出来表示整个句子。
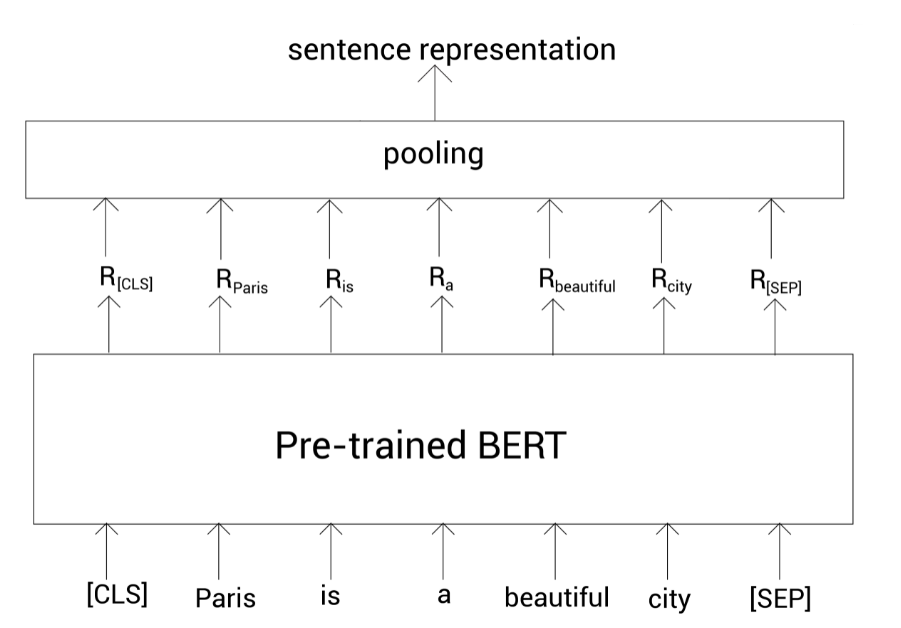
上面介绍的都是取最后一个编码器层的输出进行计算。其实还有其他方法,比如取第一个编码器和最后一个编码器输出之和、以及取倒数第二个编码器层的输出等。
下面我们来看下SBERT。
理解SBERT
SBERT也不是从头开始训练的,它是基于预训练的BERT模型(或变种),然后进行微调获取句子表示。
也就是说,SBERT基本上是一个预训练的BERT模型,并为获取句子表示而微调。
为了微调与训练的BERT模型来获得句子表示,SBERT使用孪生(Siamese)网络和三重态(Triplet)网络,其有助于微调得更快和获取精确的句子表示。
SBERT使用孪生网络来处理涉及句子对输入的任务。并且使用三重态网络来实现三重态损失目标函数。
带有孪生网络的SBERT
SBERT使用孪生网络架构来对句子对任务进行微调。
首先,我们会看到SBERT是如何完成句子对分类任务的,然后我们会学习SBERT是如何用于句子对回归任务的。
SBERT用于句子对分类任务
假设我们有一个数据集包含句子对以及二分类标签,该标签显示这两个句子是相似(1)还是不相似(0)。
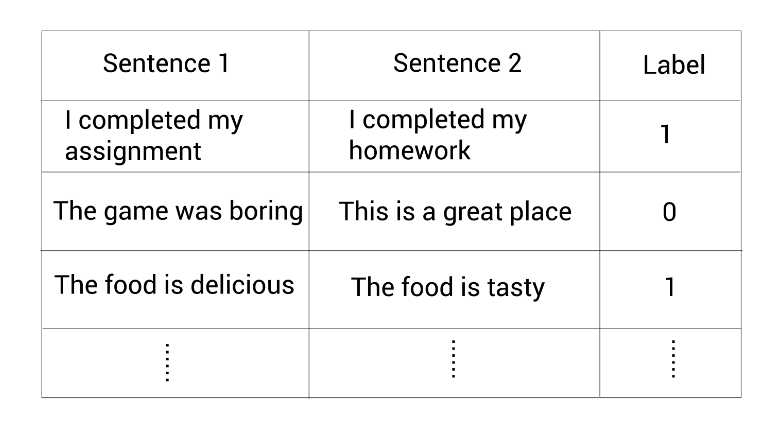
现在,我们看看如何用上面的数据集基于孪生网络来为句子对分类任务微调预训练的BERT模型。首先看看数据集中的第一对句子:
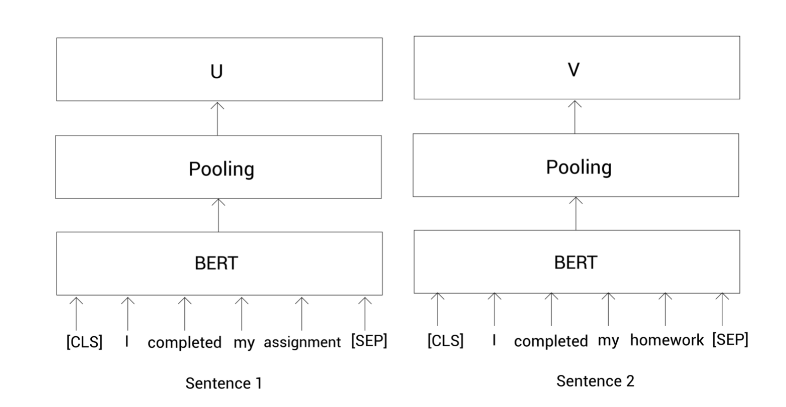
Sentence 1: I completed my assignment
Sentence 2: I completed my homework
我们需要判断给定的句子对是相似的(1)还是不相似的(0)。首先,还是老操作:
Tokens 1 = [ [CLS], I completed, my, assignment, [SEP]]
Tokens 2 = [ [CLS], I, completed, my, homework, [SEP]]
接着,我们把这些标记喂给预训练的BERT模型(后面如果没有特殊说明的话,简称为BERT模型)然后获得每个标记的向量表示。我们知道了SBERT使用孪生网络。孪生网络其实就是两个共享权重的相同的网络。所以这里我们使用两个完全相同的BERT模型。
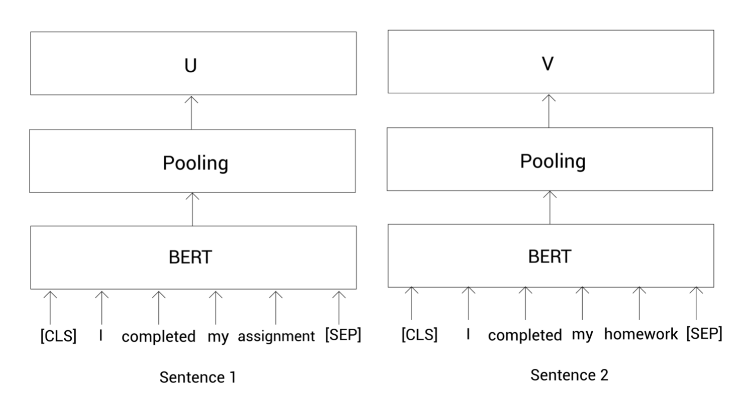
我们把句子1的那些标记列表喂给第一个BERT,把句子2的那些表示列表喂给另一个BERT,然后计算这两个句子的表示向量。
为了计算一个句子的表示向量,我们这里使用平均或最大池化。在SBERT中默认使用平均池化。在应用池化策略之后,我们有了给定句子对的句子表示,如下所示:
u u u代表句1的句子表示;v v v代表句2的句子表示。现在,我们把它们以及它们的元素之差的结果拼接起来,然后乘以一个权重W W W,如下:
( W t ( u , v , ∣ u − v ∣ ) ) (W_t(u,v,|u-v|))(W t (u ,v ,∣u −v ∣))
注意权重W W W的维度是n × k n \times k n ×k,其中n n n是句子嵌入的维度;k k k是类别数量。下面,我们把这个结果输入一个Softmax函数,返回给定句子对相似的概率:
Softmax ( W t ( u , v , ∣ u − v ∣ ) ) \text{Softmax}(W_t(u,v,|u-v|))Softmax (W t (u ,v ,∣u −v ∣))
上面的过程可以用下图描述。首先呢,我们把句子对输入到BERT模型,然后通过池化策略得到句子表示,接着拼接这两个句子表示并乘以一个全球你在W W W,最后经过Softmax函数得到相似概率。
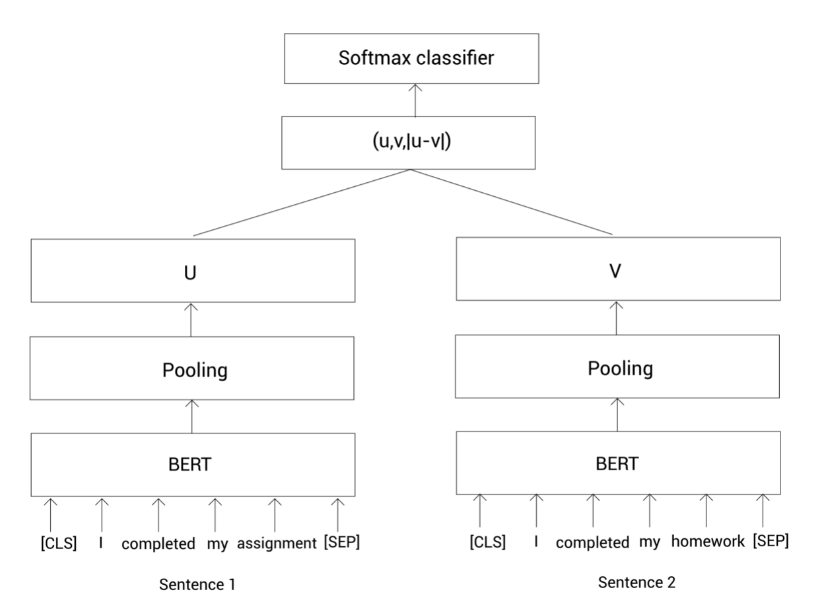
我们通过最小化交叉熵损失来训练上面的网络,同时更新权重W W W。这样,我们就可以使用SBERT来完成句子对的分类任务。
SBERT用于句子对回归任务
假设我们有一个数据集包含句子对以及它们的相似度值:
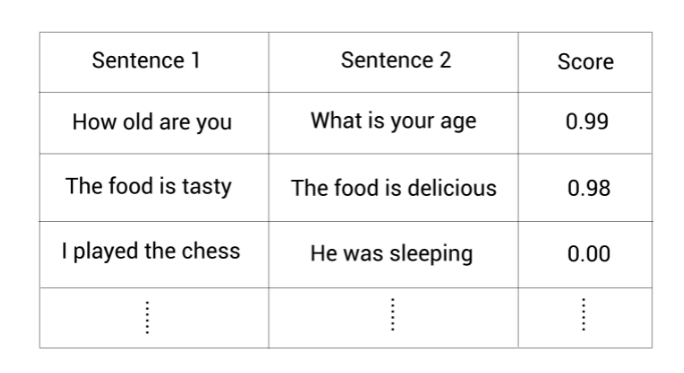
我们看看如何基于上面的数据集使用孪生网络来为句子对回归任务微调BERT模型。在该任务中,我们的目标是预测两个给定句子间的语义相似度。同样看看数据集中第一对句子:
Sentence 1: How old are you
Sentence 2: What is your age
现在我们需要计算这两个句子之间的相似度。我们对句子进行一些预处理:
Tokens 1 = [ [CLS], How, old, are, you, [SEP]]
Tokens 2 = [ [CLS], What, is, your, age, [SEP]]
然后把这些标记列表输入到BERT模型,并获得每个标记的向量表示。此任务也是基于孪生网络,所以我们有两个一样的BERT模型。我们把句子1喂给第一个BERT模型,把句子2喂给第二个BERT模型,然后计算模型输出的标记表示的均值(池化)。
令u u u代表句子1的表示;v v v代表句子2的表示。然后我们通过余弦相似计算这两个向量表示的相似度:
Similarity = cos ( u , v ) \text{Similarity}=\cos(u,v)Similarity =cos (u ,v )
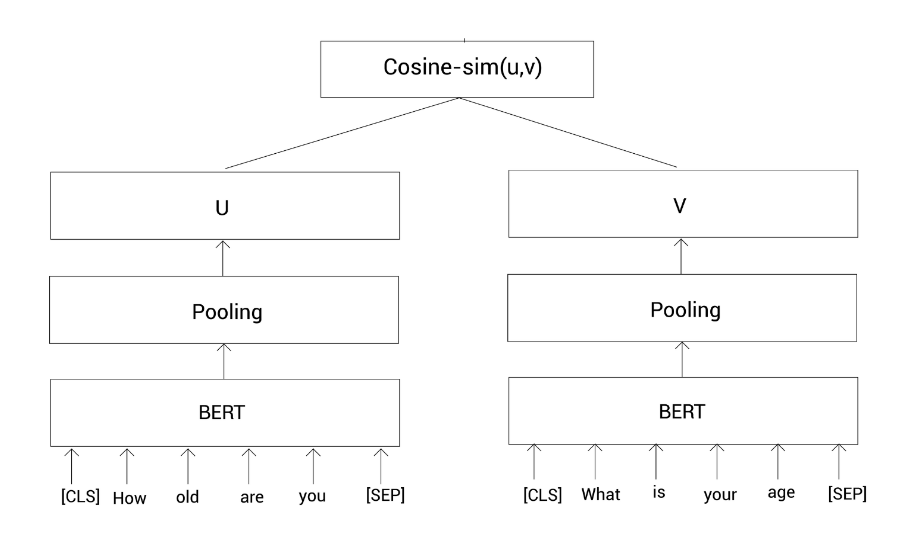
整个过程如上图所示。这里我们通过最小化均方误差损失来训练该网络。这样,我们就可以使用SBERT来做句子对的回归任务。
带有三重态网络的SBERT
假设我们有三个句子,一个Anchor句子,一个正(positive)样本和一个负(negative)样本句子:
- Anchor句子: Play the game
- Positive 句子: He is playing the game
- Negative 句子: Don't play the game
我们的任务是一个表示让Anchor句子和正样本句子之间的相似度很高,同时Anchor句子和负样本之间的相似度很低。因为我们有三个句子,此时,SBERT使用三重态网络架构。
首先,还是对句子进行预处理,然后喂给三个BERT模型,并通过池化得到每个句子的表示:
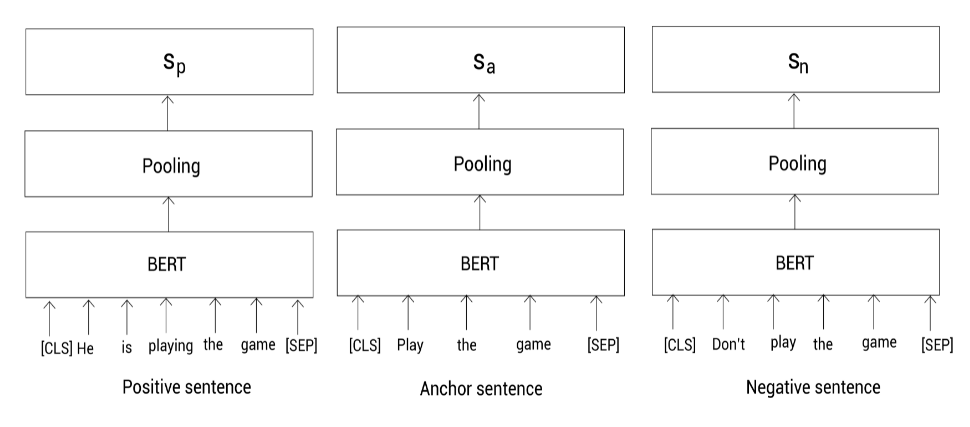
在上图中,我们用s a , s p , s n s_a,s_p,s_n s a ,s p ,s n 分别表示anchor,positive和negative句子的句向量。下面,我们通过最小化下面的三重态目标函数来训练该网络:
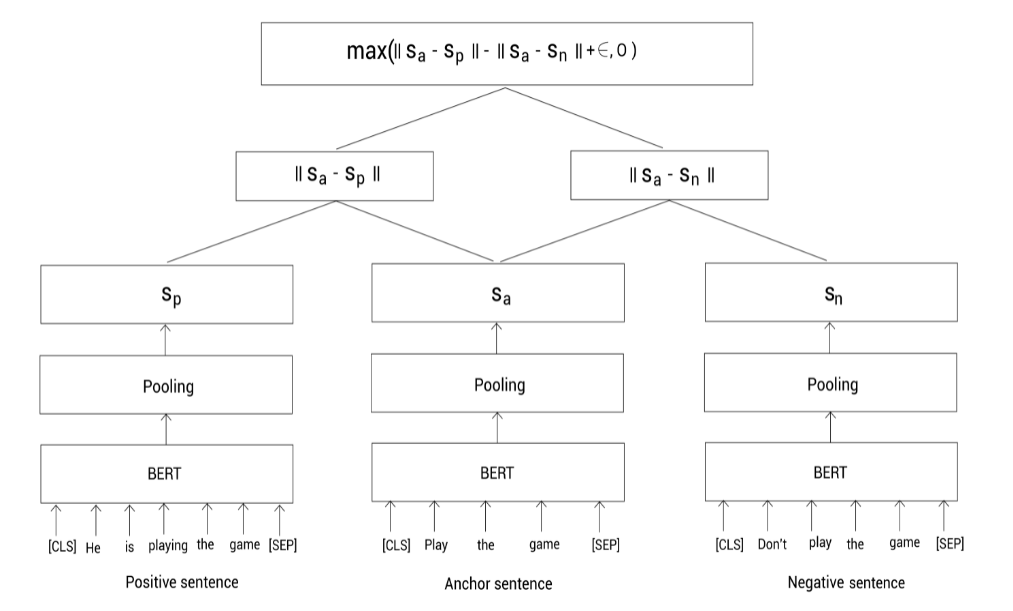
max ( ∣ ∣ s a − s p ∣ ∣ − ∣ ∣ s a − s n ∣ ∣ + ϵ , 0 ) \max(||s_a - s_p|| - ||s_a - s_n|| + \epsilon, 0)max (∣∣s a −s p ∣∣−∣∣s a −s n ∣∣+ϵ,0 )
其中,∣ ∣ ⋅ ∣ ∣ ||\cdot||∣∣⋅∣∣表示距离指标,我们使用欧几里得距离。ϵ \epsilon ϵ表示间隔margin,用于保证正样本句向量s p s_p s p 至少比负样本句向量距离Anchor句向量要近ϵ \epsilon ϵ。
如下图所示,我们分别输入anchor,positive,negative句子到BERT模型,并通过池化得到句向量。然后,训练模型去最小化三重态损失函数。最小化该损失函数确保anchor和positive的相似度要大于和negative的相似度。
SBERT的作者提供了 sentence-transformers包来开源他们的代码。
; 探索sentence-transformers包
理论千遍不如实操一遍。
首先我们通过下面的命令安装这个工具:
pip install -U sentence-transformers
SBERT的作者发布了他们预训练的SBERT模型。所有预训练的模型可以在这里找到:https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/v0.2/ ,可惜没有中文版的。
我们可以返现这些预训练的模型以 bert-base-nli-cls-token, bert-base-nli-mean-token, roberta-base-nli-max-tokens, distilbert-base-nli-mean-tokens这样的方式命名。我们来看下是啥意思:
bert-base-nli-cls-token是以预训练BERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用[CLS]标记的输出作为句子表示bert-base-nli-mean-token是以预训练BERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示roberta-base-nli-max-tokens是以预训练RoBERTa-base模型在NLI数据集进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示distilbert-base-nli-mean-tokens是以预训练DistilBERT-base模型在NLI数据集上进行微调的SBERT模型,并且该模型使用均值池化策略计算句子表示
这样,我们说预训练的SBERT模型,其实基本就是说我们有一个预训练的BERT模型然后使用孪生/三重态网络架构微调它。
那么下面我们就来看看如何使用预训练的SBERT模型。
使用SBERT计算句子表示
首先,我们从 sentence_transformers中引入 SentenceTransformer模块:
from sentence_transformers import SentenceTransformer
下载并加载预训练的SBERT:
model = SentenceTransformer('bert-base-nli-mean-tokens')
定义我们需要计算句子表示的句子:
sentence = 'Peking is a beautiful city'
使用预训练的SBERT模型的 encode函数计算句子表示:
sentence_representation = model.encode(sentence)
现在,我们来看看该句子表示的维度:
print(sentence_representation.shape)
(768,)
嗯,768维。这样我们就使用预训练的SBERT模型得到了固定长度的句子表示。
计算句子相似度
首先引入需要的包:
import scipy
from sentence_transformers import SentenceTransformer, util
下载并加载预训练的SBERT模型:
model = SentenceTransformer('bert-base-nli-mean-tokens')
定义一个句子对:
sentence1 = 'It was a great day'
sentence2 = 'Today was awesome'
计算该句子对中每个句子的句子表示:
sentence1_representation = model.encode(sentence1)
sentence2_representation = model.encode(sentence2)
接着计算这两个句子表示之间的余弦相似度:
cosin_sim = util.pytorch_cos_sim(sentence1_representation,sentence2_representation)
print(cosin_sim)
tensor([[0.9313]])
我们可以看到相似度有0.93。
加载自定义模型
除了使用官方预定义的模型外,我们也可以使用我们自己的模型。假设我们有一个预训练的ALBERT模型。现在,我们看看如何使用该预训练的ALBERT模型来获得句子表示。
首先,导入必要的模块:
from sentence_transformers import models,SentenceTransformer
现在,定义我们的词嵌入模型,它可以返回输入句子中每个标记的表示向量。我们使用预训练的ALBERT作为词嵌入模型:
word_embedding_model = models.Transformer('albert-base-v2')
接下来,我们定义池化模型来对所有标记表示进行池化操作。
我们首先设置池化策略, pooling_mode_mean_tokens = True表示我们使用均值池化来计算定长的句子表示:
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False)
好,下面我们使用词嵌入和池化模型来定义SBERT:
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
我们可以像下面这样使用该模型计算句子表示:
model.encode('Transformers are awesome')
该段代码会返回一个768维的向量,代表这个句子的句向量。
通过SBERT查找相似句子
假设我们有一个电子商务网站,假设在我们的数据库中有很多订单相关的问题,比如 How to cancel my order?, Do you provide a refund?等等。现在当新问题进来时,我们的目标是找到与新问题最相似的问题。
我们看看如何基于SBERT实现这个需求。
首先,导包:
from sentence_transformers import SentenceTransformer, util
import numpy as np
加载预训练的SBERT模型:
model = SentenceTransformer('bert-base-nli-mean-tokens')
定义我们的问题数据库:
master_dict = [
'How to cancel my order?',
'Please let me know about the cancellation policy?',
'Do you provide refund?',
'what is the estimated delivery date of the product?',
'why my order is missing?',
'how do i report the delivery of the incorrect items?'
]
定义新问题:
inp_question = 'When is my product getting delivered?'
计算新问题的句子表示:
inp_question_representation = model.encode(inp_question, convert_to_tensor=True)
然后计算数据库中所有问题的句子表示(实际应该事先计算好):
master_dict_representation = model.encode(master_dict, convert_to_tensor=True)
现在,计算新问题和数据库中所有问题的余弦相似度:
similarity = util.pytorch_cos_sim(inp_question_representation, master_dict_representation)
打印最相似的问题:
print('The most similar question in the master dictionary to given input question is:',master_dict[np.argmax(similarity)])
The most similar question in the master dictionary to given input question is: what is the estimated delivery date of the product?
这样,我们就可以基于预训练的SBERT模型尝试各种有趣的任务。我们也可以为下游任务继续微调。
参考
- Getting Started with Google BERT
Original: https://blog.csdn.net/yjw123456/article/details/120464742
Author: 愤怒的可乐
Title: Sentence-BERT实战
相关阅读1
Title: Tensorflow安装踩坑记录
Tensorflow安装踩坑记录
前段时间购置了3070ti,我欢天喜地地以为我的深度学习之旅就要顺利开始了,但我完全没意识到,这是我漫漫踩坑之路的开始。
如无特殊提示,以下均使用使用anaconda+python3.7进行安装
Tensorflow安装版本选取
- 参阅官网,根据GPU型号选择合适的CUDA和CUDnn版本
- 要注意如果在安装CUDA的时候提示:you have installed a higher version of frameview SDK,那么要到控制面板里面卸载frameview SDK(这个软件实际上是在安装显卡驱动的时候顺带安装的,用来检测游戏进行时的显卡性能,所以放心卸载即可),写在完成后CUDA便能顺利安装。
我的显卡是3070ti,因此选取了CUDA11.2和cudnn8.2,cudnn的压缩包下载之后解压到下图列出的文件夹中即可

- 选择CUDA和CUDnn版本之后,要参考
在 Windows 环境中从源代码构建 | TensorFlow (google.cn)
选择tensorflow的gpu版本。在安装tensorflow之类的环境时,往往面临着库的版本冲突,旧版本缺失之类的问题,一定要记住创建虚拟环境来安装你做每个项目需要的库。
创建虚拟环境:
Conda create -n your_env_name(你的虚拟环境的名称) python = 3.x(版本号自己选取,我选的是3.7)
然后再激活虚拟环境:(一定要记得激活,要不然会安装在外部环境里面,删除起来又是好多功夫)
conda activate your_env_name
在虚拟环境中安装,在激活虚拟环境之后,pip install即可
如果下载速度较慢,记得换下载的镜像源:
​
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --set show_channel_urls yes
​
- 如果在安装完成之后提示:
1.依赖的库缺失,即cuda64——110、101.dll缺失,首先明确一点,CUDA和CUDnn都是没问题的,其次检查是不是安装了多个tensorflow的版本,删除掉多余的版本,然后重装tensorflow能最快解决此类问题
2.tensorflow在使用时提示,tensorflow没有session、constant之类的attribute(我不确定attribute用中文怎么表述成术语),这是因为安装的tensorflow版本过高,在tensorflow2.x版本中已经没有这些属性了,因此要使用tensorflow.compat.v1.session来使用session之类的attribute
但是这样子就导致了我们原本使用tensorflow1.x版本时只需要打一个tf就能使用的attribute变得很冗长,可以考虑使用(12条消息) tensorflow.compat.v1_qwertylffFrieda的博客-CSDN博客 的方法:
Import tensorflow as tf2
tf = tf2.compat.v1 来使用tensorflow version1的attribute
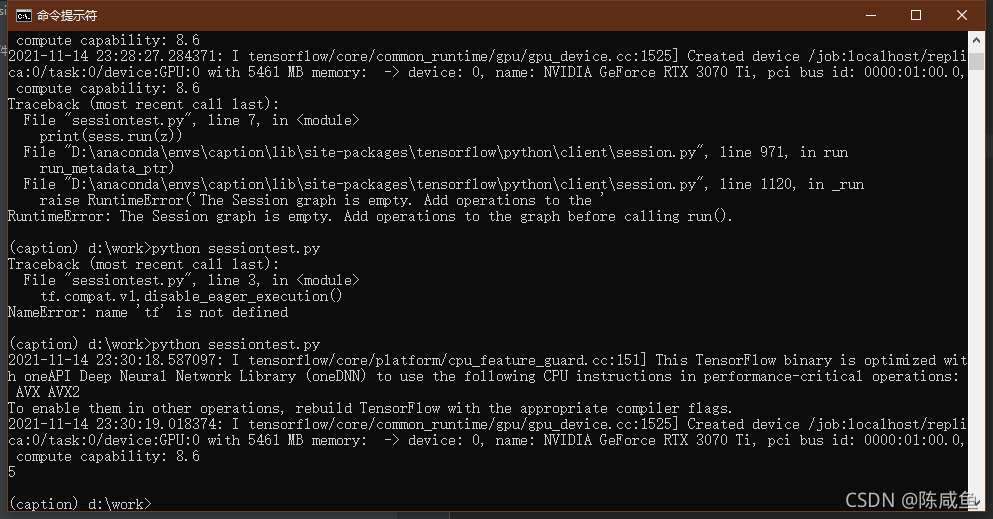
之后,在终端中测试的时候,出现了上图中的错误,session graph is empty
这是由于v1中没有构建图就无法运行,所以要禁用tf2中的eager_execution模块,上面的session就能正常运行了
此外,在使用vscode的过程中,出现了虚拟环境选择正确却无法识别tensorflow库的问题,而可以看见在上图中tensorflow是正确安装在虚拟环境下的,这一问题暂未找到完美的解决方案,改用pycharm这一编译器之后规避了这种问题。
Original: https://blog.csdn.net/saltfishcqk/article/details/121265640
Author: 陈咸鱼
Title: Tensorflow安装踩坑记录
相关阅读2
Title: Google Colab升/降级TensorFlow以及cudnn的正确姿势
Google Colab升/降级TensorFlow以及cudnn的正确姿势
背景
跑leaf-audio论文的时候,代码用到了lingvo库,当前lingvo库的最新版本是0.10.0,并且与tensorflow-gpu版本强依赖(2.6,而colab是2.7)。
直接按要求pip tensorflow-gpu 2.6后,又发现cudnn版本不对。也就是说,tensorflow 2.6版本是基于cudnn 8.1编译的,需要8.1以上的cudnn才行。但是系统里面的cudnn是8.0.5。
经过n天的摸索,试了各种方法...最终确定了只有一种方案可行:升级系统内部的cudnn。
下载cudnn
到Nvidia官网下载cudnn即可。我这里下载的是ubuntu 18.04的cudnn的xz包(deb包安装后感觉没用)。
我这里下载好了一份8.5的cudnn,可以到这里下载,或者直接link到自己的Google Drive即可。
进入CoLab Jupyter
我们需要一些操作,这里直接列举出来,方便大家copy。
切换到tmp分区
import os
os.chdir('/tmp')
解压并复制cudnn文件到指定目录
如果是你自己准备的文件,这里根据你自己的cudnn的路径,改一下/tmp/xxx/lib中间的xxx即可。
!tar -xvf "/content/drive/MyDrive/cuda11.5.tar.xz" -C /tmp/
!sh -c "mv /tmp/cudnn-linux-x86_64-8.3.1.22_cuda11.5-archive/lib/* /usr/local/cuda/lib64/"
!sh -c "mv /tmp/cudnn-linux-x86_64-8.3.1.22_cuda11.5-archive/include/* /usr/local/cuda/include/"
给文件赋权
!sudo chmod a+r /usr/local/cuda/include/cudnn*.h
!sudo chmod a+r /usr/local/cuda/lib64/libcudnn*
刷新系统链接设置(重要!!)
一定要使用ldconfig刷新系统链接配置,否则无效
!ldconfig
到这里所有的配置都OK了。
我不知道为什么,网上配置这些环境要如此复杂,甚至写长篇论文一样讲述自己的过程。
其实在我看来,只有两种原因:
- 语言不够精炼,突出不了重点,废话太多
- 凑字数或者装X
效果
直接执行自己的代码,在TensorFlow降级到2.6.2时,成功启动了cuda+cudnn

; 题外话
Windows 10现在可以联合wsl2使用CUDA了,效果还不错,有兴趣的小伙伴可以尝试一下。
步骤:
- 下载Windows 10的wsl cuda的专版显卡驱动
- 进入wsl2,按照n卡官网wsl文档,下载特制的cuda和公版的cudnn,配置即可。
Original: https://blog.csdn.net/jtjljy/article/details/121550904
Author: Kingtous
Title: Google Colab升/降级TensorFlow以及cudnn的正确姿势
相关阅读3
Title: 知识库问答KB-QA——深度学习(2)
本文介绍一篇利用深度学习对语义解析方法进行提升的论文,来自Microsoft公司的Semantic Parsing via Staged Query Graph Generation:Question Answering with Knowledge Base(文章发表于2015年的ACL会议,是当年的Outstanding Paper)。
该文章分析了传统语义解析方法的不足,受信息抽取和向量建模方法的启发,将语义解析过程转化成查询图(Query graph)分阶段生成的过程,使用了卷积神经网络来提升自然语言到知识库关系的映射。该方法在WebQuestion数据集上测试,取得了52.5的F1-score,该性能远超当时的所有方法。
一、语义解析方法的再思考
把自然语言问题转化为逻辑形式,通过逻辑形式转化为查询语句,在知识库中查询得出最终答案。在进行语义解析生成逻辑形式的过程中,主要是在提取自然语言问题中的信息和利用训练好的语法解析器进行解析,这一过程 几乎没有使用到知识库里的信息。而在向量建模和信息抽取方法中,我们不仅对问题进行了特征提取,还借助知识库确定了候选答案范围(相比语义解析中的词汇映射要在大范围的知识库实体关系中寻找映射,这样的方式使得搜索范围大大减小),并将候选答案在知识库中的信息作为特征。相比之下,可以看出传统的语义解析方法和知识库本身的联系是 不够紧密的(Decoupled from KB),也就是说, 传统语义解析方法对知识库的利用还不够。
再看看语义解析的第一步,词汇映射(Lexicon)。要将自然语言中的谓语关系映射到知识库中的实体关系,是一件很困难的事情,仅仅通过 统计方式进行映射,效果并不好。如果我们能考虑知识库的信息,是不是能将词汇映射的范围缩小?使用深度学习的办法通过分布式表达来代替基于统计方法的词汇映射,会不会取得更好的效果?
二、查询图
考虑这样一个问句"Who first voiced Meg on Family Guy?" (谁是第一个为Family Guy里的MegGriffin角色配音的人,注:Family Guy是美国的一部动画片,MegGriffin是其中的一个角色,有两个人先后为其配音过)
可以看出,这个问题是有难度的,对于深度学习的向量建模法来说,first这种时序敏感(Time-Aware)词常常会被模型忽略而得出错误答案。语义解析方法可以将first解析为逻辑形式的聚合函数(arg min),但它又难以将问题中的Meg这一缩写词通过词汇表映射为知识库中的MegGriffin。
想一想人如果给定知识库会怎么去寻找答案?首先我们也许不知道Meg具体是指哪个角色,但是可以先去知识库里搜Family Guy,在它对应的知识库子图中搜索和Meg很接近的实体,也就是说一开始就借助知识库,缩小了范围,这样就很容易找到Meg其实对应的是MegGriffin。我们可以借助这样的思想来对语义解析进行改进。
为了更好的去利用知识库,我们用一种图的形式来代替语法解析树表示逻辑形式,这个图被称为查询图(query graph)。
问句"Who first voiced Meg on Family Guy?"对应的查询图如下图所示:

查询图可以分为以下四个部分:
知识库实体,在图中用圆角矩形表示。中间变量,在图中用白底圆圈表示。聚合函数,用菱形表示。lambda变量(答案),在图中用灰底圆圈表示。图中实体节点到答案变量的路径可以转化为一系列join操作,不同路径可以通过intersection操作结合到一起,因此,该查询图在不考虑聚合函数argmin的情况下可以转化为一个lambda表达式,即:λ x . ∃ y . cast ( Family G u y , y ) ∧ actor ( y , x ) ∧ character ( y , MegGrif fin ) \lambda x . \exists y . \text { cast }(\text { Family } G u y, y) \wedge \text { actor }(y, x) \wedge \text { character }(y, \text { MegGrif fin })λx .∃y .cast (Family G u y ,y )∧actor (y ,x )∧character (y ,MegGrif fin )
上述 lambda 表达式表示:要寻找x,使得在知识库中存在实体y,满足:
- y和FamilyGuy存在cast关系;
- y和x存在actor关系;
- y和MegGriffin存在character关系。
这里我们可以把y想象成是一个中间变量,通过对它增加约束来缩小它的范围,通过它和答案x的关系来确定答案x
有了查询图,通过将其转化为lambda表达式就可以在知识库中查询得到答案。那么,如何去构造查询图呢?
; 三、查询图的阶段生成
查询图的构成成分:
问题中的主题词(可以看作是一个根节点)到答案变量的这条路径(如Family Guy - y - x)包含了所有的中间变量,这条路径可以看作是从问题到答案的一个核心推导过程,我们将其称作核心推导链(core inferential chain)。
而对于核心推导链里的中间变量,可以对它加一些约束(要求它与其他实体具有一定的关系,如 y - character -> Meg Griifin)和聚合函数(如 y - from -> arg min)。
因此查询图的生成,可以分为以下几个步骤:
- 确定主题词
- 确定核心推导链
- 是否增加约束和聚合
整个过程可以用下面的这个有限状态机自动机表示:

其中状态集合 S = { ϕ , S e , S p , S c } S=\left{\phi, S_{e}, S_{p}, S_{c}\right}S ={ϕ,S e ,S p ,S c } 分别表示空集、仅含主题词节点、含核心推导链、含约束节点。而动作集合 A = { A e , A p , A a , A c } A=\left{A_{e}, A_{p}, A_{a}, A_{c}\right}A ={A e ,A p ,A a ,A c } 分别表示选择主题词节点、选择核心推导链、加入聚合函数、加入约束。
因此查询图可以分阶段生成,这个生成的过程实质上是一个搜索。依照有限状态自动机,根据图所处的状态 s s s,可以确定在该状态下可以采取的动作的集合 Π ( s ) \Pi(s)Π(s )(比如当前我们处在状态 ϕ \phi ϕ ,根据有限自动机我们的动作为选择主题词节点,假设检测出来问句中有3个主题词候选,那么动作集合大小为3)。因此,查询图生成实际上是一个搜索过程,如果对这个搜索不加任何限制,那么这个搜索是指数级复杂度的。因此对于每一个状态 s s s ,可以用==奖励函数(reward function)==对它进行评估,奖励函数 γ 得分越高表示这个状态对应的查询图和正确的语义解析表达越接近。用一个对数线性(log-linear)模型来学习奖励函数(类似增强学习)。有了奖励函数,用best-first的策略利用优先队列进行启发式搜索,算法流程如下:

其中 T ( s , a ) T(s,a)T (s ,a ) 代表在 s s s 状态下采取动作 a a a 后得到的新状态,我们将优先队列的大小 N N N 限制为1000。上述算法可以简单概括为:每次从队列中取出得分最高的状态分别执行动作集中的每一个动作生成一批新的状态并压入优先队列,始终记录得分最高的状态,最终将得分最高的状态作为最后的查询图。
接下来,我们来看看每一种动作是怎么执行的,以及如何去构造奖励函数。我们依旧以问题"Who first voiced Meg on Family Guy?"为例。
1 主题词链接
第一种动作(action),就是从问题中确定主题词,这个操作称为主题词链接(Linking Topic Entity)。作者使用了S-MART作为实体链接系统,该系统是针对带噪音的短文本设计的,适合用于对问句提取主题词,它会为相应的 实体-自然语言短语 链接对 给出链接得分(Linking Score)。最多保留得分最高的10个实体作为候选,第一步如图所示:

; 2 核心推导链
确定核心推导链。对于每一个候选的主题词,将它在知识库中对应的实体节点周围长度为1的路径(如下图 s 5 s_{5}s 5 )和长度为2且包含CVT节点的路径(如下图 s 3 , s 4 s_{3},s_{4}s 3 ,s 4 )作为核心推导链的候选(CVT,即复合值类型 Compound Value Types,是freebase中用于表示复杂数据而引入的概念)。如下图:

核心推导链其实就是将自然语言问题映射为一个谓语序列(如cast-actor),因此我们可以用卷积神经网络来对这个映射进行打分,如下图所示:

将自然语言和谓语序列分别作为输入,分别经过两个不同的卷积神经网络得到一个300维的分布式表达,利用表达向量之间的相似度距离(如cosine距离)计算自然语言和谓语序列的语义相似度得分。需要注意的是,这里的输入采用的是字母三元组(letter-trigram) 的方式,这是一个非常有趣的方式,类似于character-CNN。每个单词都将它拆分成几个 字母三元组,作为CNN的输入。比如单词who可以拆为#-w-h,w-h-o,h-o-#。每个单词通过前后添加符号#来区分单词界限(并且单词最短只含一个字母,添加两个#可以保证能形成至少一个字母三元组) 。
采用 字母三元组的好处在于:
- 减小输入维度,这样输入维度可以稳定在字母集大小+1(#号)的三次方,即2 7 3 27^{3}2 7 3,而不是字典大小(同时可以处理一些字典中不存在的词和一些低频词,如缩写词等等)。
- 相同语义的词语可能因为词根等缘故,前缀或者后缀会比较相似,这样能更好的提取单词语义的特征。
- 对于现实生活中的用户,有时候可能会发生单词拼写错误,但错误拼写不会对这种输入方式造成太大影响。
3 增加约束和聚合函数
通过增加约束和聚合函数的方式扩展查询图,缩小答案的范围,以增加准确率,如下图:

作者采用了基于一些简单规则的方式,比如当实体链接检测到句子中出现其他实体,那么可以增加一个约束。又比如句子中出现了first等时序敏感词,可以增加聚合节点。具体来说,根据以下规则确定 是否要为CVT节点添加约束节点或者聚合节点:
- 约束实体出现在问句中
- 约束谓词表示事件的结束时间,但没有值(这表示它是当前事件)
- 问题中出现约束实体名称的一些单词
- 谓语是people.marriage.type_of_union(这说明关系是否是家庭伴侣关系、婚姻关系还是民事关系)
- 问句中包含单词 first 或者 oldest,并且谓语是from形式的谓语(表明事件的起始时间)
- 问句中包含单词 last, latest 或 newest ,并且谓语是to形式的谓语(表明事件的结束时间)
- 而对于答案节点,如果包含以下之一的谓语,会添加一个约束节点:
people.person.gender / common.topic.notable types / common.topic.notable_for
; 4 奖励函数的特征定义
用对数线性模型训练奖励函数,因此要确定输入向量,和信息抽取以及传统语义解析方法一样,手工定义一个特征向量来表征整个查询图的信息,将它作为对数线性模型的输入。我们先来对特征有个主观上的感受,例如问题"Who first voiced Meg on Family Guy?" 对应的查询图,它的特征如下图所示:

具体来说,我们从 主题词链接、核心推导链、增加约束聚合三个方面定义特征。
a.主题词链接特征:实体链接得分(EntityLinkingScore),由实体链接系统给出。
如 EntityLinkingScore(FamilyGuy,"Family Guy")=0.9
b.核心推导链特征:
- PatChain:将问句中的主题词替换为实体符号,和谓语序列同时输入两个不同的CNN,根据CNN输出的表达求语义相似度作为特征。
如: PatChain("Who first voiced Meg on < e >", cast-actor) =0.7 - QuesEP:将谓语序列和主题词的规范名称(canonical name)连接(concatenate)起来作为输入,和问题求语义相似度。
如: QuesEP(q,"family guy cast-actor") = 0.6 - ClueWeb:用ClueWeb来训练一个更加in-domain的模型。如果一句话包含两个实体和谓语,那么就把这句话和谓语作为一组数据对 输入模型进行训练。注意:ClueWeb的输入和PatChain是一样的,但是其模型是用不同数据训练的。
从这定义的三个特征可以看出,这其实是一个ensemble模型,将三种模型的输出结果进行了一个log-linear组合。
c.约束聚合特征:
对于CVT节点有以下特征:
- 约束实体是否出现在问句中 如ConstraintEntityInQ("Meg Griffin",q)=1
- 是否是当前发生的事件
- 是否是当前发生的事件,且问句中包含关键词"currently", "current", "now", "present" 和"presently"
- 约束实体单词出现在问句中的百分比 如ConstraintEntityWord("Meg Griffin",q)=0.5
- 约束谓语的类型是people.marriage.type_of_union
- 问题中是否包含"first" 或 "oldest" ,谓语是from形式谓语,并且CVT节点按该from性质排序是第一
- 问题中是否包含"last", "latest" 或 "newest" ,谓语是to形式谓语,并且CVT节点按该to性质排序是最后
对于答案节点有以下特征:
- 性别一致性(男性):约束谓语是gender,并且问句中出现了以下男性关键词中的一个{"dad", "father", "brother", "grandfather", "grandson", "son", "husband"}
- 性别一致性(女性):约束谓语是gender,并且问句中出现了以下女性关键词中的一个{"mom", "mother", "sister", "grandmother", "granddaughter", "daughter", "wife"}
- 当约束谓语是 notable_types 或 notable_for 时,约束实体单词出现在问题中的百分比
d.总体特征
查询图对应的答案数量NumAns和查询图的节点数NumNodes。
5 模型学习
在信息抽取中,模型是在进行二分类(根据特征向量判定候选答案是否是正确答案),而在本文中,我们对模型不进行二分类,而是根据查询图对应的实体和真实答案的F1-score进行排名。基于lambda-rank算法对一个一层的神经网络进行训练。这样做的好处是,有些查询图虽然查询得到的答案和真实答案不完全相同,但根据它的相同程度(F1-score)也可以说它比完全错误的查询图要好。
四、论文实验与总结
在训练数据上,通过实体链接系统确定候选实体,候选实体到正确答案的知识库路径(长度限制为2)作为核心推导链的正样本,错误查询图中的路径作为负样本。根据训练数据,作者生成了17,277个F1-score不为0的查询图(正样本)和1.7M完全错误的查询图(负样本)对卷积神经网络进行训练。
对于奖励函数的训练,为每个问题生成了4000个样例(包含所有正确的查询图和随机选择的负样本)以F1-score作为排名标准来训练排名器(ranker)。
该方法与当时的所有baseline进行了比较,效果如下:

可以看出该方法取得了相当大的提升,也因此获得了当年的Outstanding paper。
本方法使用到了外部的实体链接系统,作者也比较了使用Freebase Search API时的性能,F1-score会下降约4.1。同时,作者也对核心推导链所涉及的三个特征的性能进行了比较,核心推导链三个特征的性能如下表:

可以发现,其实只使用PatChain的性能就已经很好了(达到了惊人的49.6),原因是WebQuestion里50%的问题可以只是用核心推导链就可以得出正确答案。
最后作者进行了错误分析,随机选择100个答错的问题,发现35%的错误来自核心推导链构建错误,23%来自约束错误,8%来自实体链接错误,剩下34%的错误来自于标签错误、不完整及问题中的实体有歧义等。也就是说有34%的错误是数据的问题,再一次显示出了该方法的强大。
; 五、本文内容快速回顾
- 考虑到传统语义解析与KB结合 不够紧密,作者提出了 查询图的概念
- 查询图的构造由 实体链接系统 确定主题词, 核心推导链,增加 约束和 聚合这几种操作构成
- 对于查询图的每一个状态,我们都用一个 奖励函数对它进行评价,使用 优先队列进行 启发式搜索构建查询图
- 通过查询图的 实体链接得分、 核心推导链三个特征、约束聚合手工特征以及 全局特征作为输入向量,训练单层神经网络作为 排名器得到奖励函数
- 核心推导链使用 卷积神经网络(letter-trigram作为输入)进行训练,并且 ensemble了三个不同数据训练的模型
总的来说,可以看出,该方法几乎融合了传统语义解析、深度学习、信息抽取等方法的优点,还使用了部分手工特征(对数据进行了仔细观察和分析),确实是一个很令人惊叹的方法。
参考文献
Original: https://blog.csdn.net/strivequeen/article/details/109458180
Author: StriveQueen
Title: 知识库问答KB-QA——深度学习(2)