
为什么需要编译?
编译器的作用便是把我们的高级编程语言通过一系列的操作转化成可被计算机执行的机器语言
编译器是一种计算机程序,负责把一种编程语言编写的源码转换成另外一种计算机代码,后者往往是以二进制的形式被称为目标代码(object code)。
解释器是一种计算机程序,它直接执行由编程语言或脚本语言编写的代码,并不会把源代码预编译成机器码。
预处理器:把存储在不同文件中的源程序聚合在一起。 把宏的缩写语句替换为源程序。
可重定位:汇编生成的机器代码,在内存中放的起始位置L 不固定.代码中的所有地址都是相对于L的相对地址。起始位置+相对地址= 绝对地址。
加载器:修改可重定位地址,将修改后的指令和数据放到内存中适当的位置
链接器:链接其他编译好的库文件或可重定位的目标程序,生成可执行代码。(外部内存地址的问题)
人工翻译语言的过程
人工英汉翻译:
识别出句子短语
语法分析,识别出句子短语,得到句子结构
确定词性
1、分析源语言
语义分析
分析核心的谓语动词 broke 入手(打,谁打,为什么打、打谁、打的结果等等)。 这些信息可以分析broke的上下文获得。找到 主语 he 动作的实施者,宾语window动作的受施。with a hammer 补语。 in the room,状语。
(四个实体与核心谓语动词的关系)
根据图的中间表示
中间表示不仅适应英语。所有语言都可以用这个中间表示来分析。
语义分析:1、划分句子成分 (语法分析)(主语&宾语 一般由名词短语构成 、状语&补语:介词短语构成) 2、识别短语 通过词性(词法分析)。(冠词a、名词window =>名词短语 ,介词with 、冠词a 、名词hummer =>名词短语 )
词法分析(确定词性)----> 语法分析(识别各类短语,得到句子的结构) ----> 语义分析(根据短语确定句子成分,各成分与谓语动词语义关系)
句子分析过程: 词法分析 --> 语法分 --> 语义分析
2、生成标语言,目标语言说出句子。
翻译成汉语 ==> 在房间里,他用锤子砸了一扇窗户。
编译器分析过程
在编译器的实现过程多个阶段可能放在一起实现。 语法制导翻译 (Syntax Directed Translation) :语法分析 和 语义分析结合在一起。
Xcode3 :以前: GCC;
Xcode3: 增加LLVM,GCC(前端) + LLVM(后端);
Xcode4.2: 出现Clang - LLVM 3.0成为默认编译器;
Xcode4.6: LLVM 升级到4.2版本;
Xcode5: GCC被废弃,新的编译器是LLVM 5.0,从GCC过渡到Clang-LLVM的时代正式完成
LLVM是构架编译器(compiler)的框架系统,以C++编写而成,用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。
LLVM计划启动于2000年,最初由美国UIUC(伊利诺伊)大学的Chris Lattner博士主持开展。2006年Chris Lattner加盟Apple Inc.并致力于LLVM在Apple开发体系中的应用。Apple也是LLVM计划的主要资助者。
LLVM 是一个总括项目,承载并开发了一组紧密结合的低级工具链组件(例如,汇编器,编译器,调试器等),这些组件被设计为兼容的。
尽管LLVM提供了一些独特的功能,并且以其一些出色的工具而闻名(例如,Clang编译器,C / C ++ / Objective-C编译器,它比GCC编译器具有许多优势),但它是LLVM与其他编译器不同的是其内部体系结构。
经典编译器设计
传统静态编译器(如大多数C编译器)最受欢迎的设计是三相设计,其主要组件是前端,优化器和后端
优化器负责进行各种转换以尝试改善代码的运行时间,例如消除冗余计算,并且通常或多或少地独立于语言和目标。然后,后端(也称为代码生成器)将代码映射到目标指令集。除了编写 _正确的_代码外,它还负责生成利用受支持体系结构异常功能的 _良好_代码。编译器后端的常见部分包括指令选择,寄存器分配和指令调度。
该模型同样适用于解释器和JIT编译器。Java虚拟机(JVM)也是该模型的实现,它使用Java字节码作为前端和优化器之间的接口。
此设计的含义
通过这种设计,移植编译器以支持新的源语言(例如Algol或BASIC)需要实现新的前端,但是现有的优化器和后端可以重用。
实现前端所需的技能与优化器和后端所需的技能不同。将它们分开可以使"前端人员"更轻松地增强和维护他们在编译器中的角色。
LLVM的代码表示形式:LLVM IR
LVM设计的最重要方面是LLVM中间表示(IR),它是用来在编译器中表示代码的形式。LLVM IR旨在承载您在编译器的"优化器"部分中找到的中级分析和转换。它的设计考虑了许多具体目标,包括支持轻量级运行时优化,跨功能/过程间优化,整个程序分析以及积极的重组转换等。LLVM IR是类似于RISC的低级虚拟指令集。像真正的RISC指令集一样,它支持简单的指令(如加,减,比较和分支)的线性序列
- LLVM 汇编语言中的 注解以分号 (;) 开始,并持续到行末。
- 全局标识符要以 @ 字符开始。所有的函数名和全局变量都必须以 @ 开始。
- LLVM 中的局 部标识符以百分号 (%) 开始。标识符典型的正则表达式是 [%@][a-zA-Z$._][a-zA-Z$._0-9]*。
- LLVM 拥有一个强大的类型系统,这也是它的一大特性。LLVM 将 整数类型定义为 i N,其中 N 是整数占用的字节数。您可以指定 1 到 223- 1 之间的任意位宽度。
- 您可以将 矢量或阵列类型声明为 [no. of elements X size of each element]。对于字符串 "Hello World!",可以使用类型 [13 x i8],假设每个字符占用 1 个字节,再加上为 NULL 字符提供的 1 个额外字节。 ///数组
- 您可以对 hello-world 字符串的全局字符串常量进行如下声明:@hello = constant [13 x i8] c"Hello World!\00"。使用 关键字 constant 来声明后面紧跟类型和值的常量。我们已经讨论过类型,所以现在让我们来看一下值:您以 c 开始,后面紧跟放在双引号中的整个字符串(其中包括 \0 并以 0 结尾)。不幸的是,关于字符串的声明为什么需要使用 c 前缀,并在结尾处包含 NULL 字符和 0,LLVM 文档未提供任何解释。如果您有兴趣研究更多有关 LLVM 的语法怪现象,请参阅 参考资料,获取语法文件的链接。
- LLVM 允许您声明和定义函数。而不是仔细查看 LLVM 函数的整个特性列表,我只需将精力集中在基本要点上即可。以 关键字 define 开始,后面紧跟返回类型,然后是函数名。返回 32 字节整数的 main 的简单定义类似于:define i32 @main() { ; some LLVM assembly code that returns i32 }。///私有方法
- 函数声明,顾名思义,有着重大的意义。这里提供了 puts 方法的最简单声明,它是 printf: declare i32 puts(i8) 的 LLVM 等同物。该声明以 关键字 declare*开始,后面紧跟着返回类型、函数名,以及该函数的可选参数列表。该声明必须是全局范围的。
- 每个函数均以返回语句结尾。有两种形式的 返回语句:ret。对于您简单的主例程,使用 ret i32 0 就足够了。
- *使用 call
创建Hello.c
编译此代码,请输入此命令 :
Hello World 程序的 LLVM 字节代码
LLVM IR实际上以三种同构形式定义:上面的文本格式,通过优化本身检查和修改的内存中数据结构以及高效且密集的磁盘上二进制"位码"格式。LLVM项目还提供了将磁盘上的格式从文本转换为二进制的工具
编译器优化有很多不同的类型,因此很难提供解决任意问题的方法。也就是说,大多数优化遵循简单的三部分结构:
- 寻找要转换的模式。
- 验证转换对于匹配的实例是安全/正确的。
- 进行转换,更新代码。
1、最简单的优化是对算术标识进行模式匹配,例如:对于任何整数X,X-X为0, X-0为X,(X*2)-X为X。
2、提供相关库优化
LLVM的编译三阶段设计
LLVM的编译器中,前端负责解析,验证和诊断输入代码中的错误,然后将解析的代码转换为LLVM IR(通常(但并非总是如此)是通过构建AST,然后将AST转换为LLVM IR)。可以选择通过一系列分析和优化过程来馈送该IR,以改进代码,然后将其发送到代码生成器中以生成本地机器代码
LLVM所需要的仅仅是一个统一的中间表示格式:LLVM IR 。你可以很轻易的抽取LLVM的组件(以库的形式)出来用于其它领域,如抽取LLVM JIT用于MapD这样的GPU数据库,或者抽取LLVM的整个后端(优化与CodeGen)用于TVM这样的深度学习推理框架。这样带来的好处就是LLVM不再仅仅是用于给Clang等编译器前端提供服务的编译器后端,而是可以为需要JIT / CodeGen 功能的所有领域服务,比如提到的GPU数据库、深度学习推理框架,还包括安全、区块链等应用领域。
所以,现在比较常见的开发模式变为: 各种各样的应用(DSL、GPU数据库、TVM、安全、区块链等)----> 生成 LLVM IR ----> LLVM的优化 ----> LLVM Code Gen ----> 目标代码(ARM、x86、Hexagon、NVPTX、AMDGPU、WebAssembly...)
这在LLVM出现之前,基本上是做不到的事情,不仅GCC,包括其它编译器都可以理解为"一坨",根本抽不出来。
eg : LLVM Core库提供了一个现代的独立于源和目标的优化器,以及对许多流行 CPU支持。
Clang.是一个"LLVM 原生" C/C++/Objective-C 编译器.
LLDB项目建立在 LLVM 和 Clang 提供的库之上,以提供一个很棒的本机调试器。它使用了 Clang AST 和表达式解析器、LLVM JIT、LLVM 反汇编器等
Libc++ 和 Libc++ ABI项目提供了 C++ 标准库的标准一致性和高性能实现,包括对 C++11 和 C++14 的完全支持。
LLVM Pass框架
pass框架是LLVM中的重要部分,多个pass一起完成了LLVM的优化与代码转换工作。每个pass都会完成指定的优化工作。在某些情况下,pass之间会有对应的依赖关系,即新的pass会与其他原有的pass产生关联
pass管理系统,它根据 pass 的依赖性自动对 pass 进行排序(包括分析、转换和代码生成 passes),并对它们进行管道传输以提高效率
快速的可定制化支持编写针对自己特定应用的优化Pass 。由于在LLVM中编写优化Pass非常方便,所以针对各种各样的应用,可以变为:
各种各样的应用(DSL、GPU数据库、TVM、安全、区块链等)----> 生成 LLVM IR ----> 编写针对自己特定应用的优化Pass ----> LLVM的优化 ----> LLVM Code Gen ----> 目标代码(ARM、x86、Hexagon、NVPTX、AMDGPU、WebAssembly
利用编译器,做编译器
可重定向LLVM代码生成器的设计
代码生成器的任务是把高级的、几乎机器无关的LLVM IR转换为低级的、机器相关的机器语言。指令选择是这样的过程,其中IR中的抽象操作被映射到目标机器架构的具体指令。
LLVM代码生成器负责将LLVM IR翻译为特定的目标机器码。代码生成器的另一个工作是 为一个给定的目标 生成一个尽可能最好的机器码。
与优化器中的方法相似,LLVM的代码生成器将代码生成问题划分为独立的pass——指令选择、寄存器分配、调度、代码布局优化和组装发射(assembly emission)——并且提供需要内建的、默认执行的pass。目标开发者有机会在默认的pass中选择、重写以及实现完全的用户目标pass。例如, 由于x86只有很少的寄存器, x86后端使用register-pressure-reducing调度。但是, 由于其有很多寄存器, PowerPC后端采用一个延迟优化调度。x86后端使用一个用户pass去操作x87浮点指针堆栈,并且ARM后端使用用户pass 在使用它们的函数中 摆放constant pool island。这种灵活性允许目标开发者无需为目标编写一个完整的代码生成器就可以生成良好的代码; 重复利用现有的工具
混合匹配(mix and match)方法允许目标开发者选择对他们的体系结构有用的选项以及在不同目标中复用 大量代码 。这带来另一种挑战:每一个共享的组件需要能够以一种通用方法推测目标专有特性。例如,一个共享的寄存器分配器需要知道每个目标的寄存器文件和指令和寄存器操作之间的约束关系。LLVM的解决方案是为每个目标提供以特定领域语言(.td文件)的目标描述,该语言用tblgen工具进行处理。对于x86目标的简单建立流程
1、第一件事是把IR转换为一个selection DAG
询问clang它将如何编译文件 hello.m
预处理阶段的过程和优化。参考
.d (dependencies )
.dia
1、LLVM特性 用于 C 和 C++ 的 LLVM 编译器系统包括以下内容:
- Front-end,用于C、C++、Objective-C、Fortran 等语言。它们支持 ANSI 标准的 C 和 C++ 语言,就像 GCC 支持它们一样。此外,还支持许多 GCC 扩展。
- LLVM 指令集的稳定实现,它同时有着在线和离线代码表示,以及汇编(ASCII)和字节码(binary)的 reader、writer 和 verifier。
- 一个功能强大的 pass 管理系统,它根据 pass 的依赖性自动对 pass 进行排序(包括分析、转换和代码生成 passes),并对它们进行管道传输以提高效率。
- 广泛的全局标量优化。
- 一个具有丰富的分析和转换集合的链接时过程间优化框架,包括复杂的全程序指针分析、调用图构造和对概要引导优化的支持。
- 一个易于重定向的代码生成器,目前支持 X86、X86-64、PowerPC、PowerPC-64、ARM、Thumb、SPARC、Alpha、CellSPU、MIPS、MSP430、SystemZ 和 XCore。
- 一个即时(JIT)代码生成系统,目前支持 X86、X86-64、ARM、AArch64、Mips、SystemZ、PowerPC 和 PowerPC-64。
- 支持生成 DWARF 调试信息。
- 一个 C back-end,用于测试和在上面列出的目标上生成本机代码。
- 一个类似 gprof 的分析系统。
- 一个包含许多基准代码和应用程序的测试框架。
- APIs 和调试工具简化了 LLVM 组件的快速开发。
LLVM平台,短短几年间,改变了众多编程语言的走向,也催生了一大批具有特色的编程语言的出现,不愧为编译器架构的王者,也荣获2012年ACM软件系统奖
问题: 有没有时间的切点,看到编译的过程中的时间节点。那一段比较耗时...
Original: https://blog.csdn.net/zjh467545737/article/details/122826297
Author: 悠悠悠哉e
Title: LLVM 编译器
相关阅读1
Title: linux下的opencv-4.5.5 及 opencv_contrib 扩展模块安装
适用于ubuntu(20.04)下安装opencv-4.5.5 以及opencv_contrib 扩展模块 一并安装,如果已经安装了opencv-4.5.5,需要安装扩展模块的话,跳过第3步opencv的源码下载。(屡试不爽,超级简单)
目录
1.更换下载源
点击Linux自带的 软件和更新,将 下载自:这一项换成上海交大的下载源。如下图:
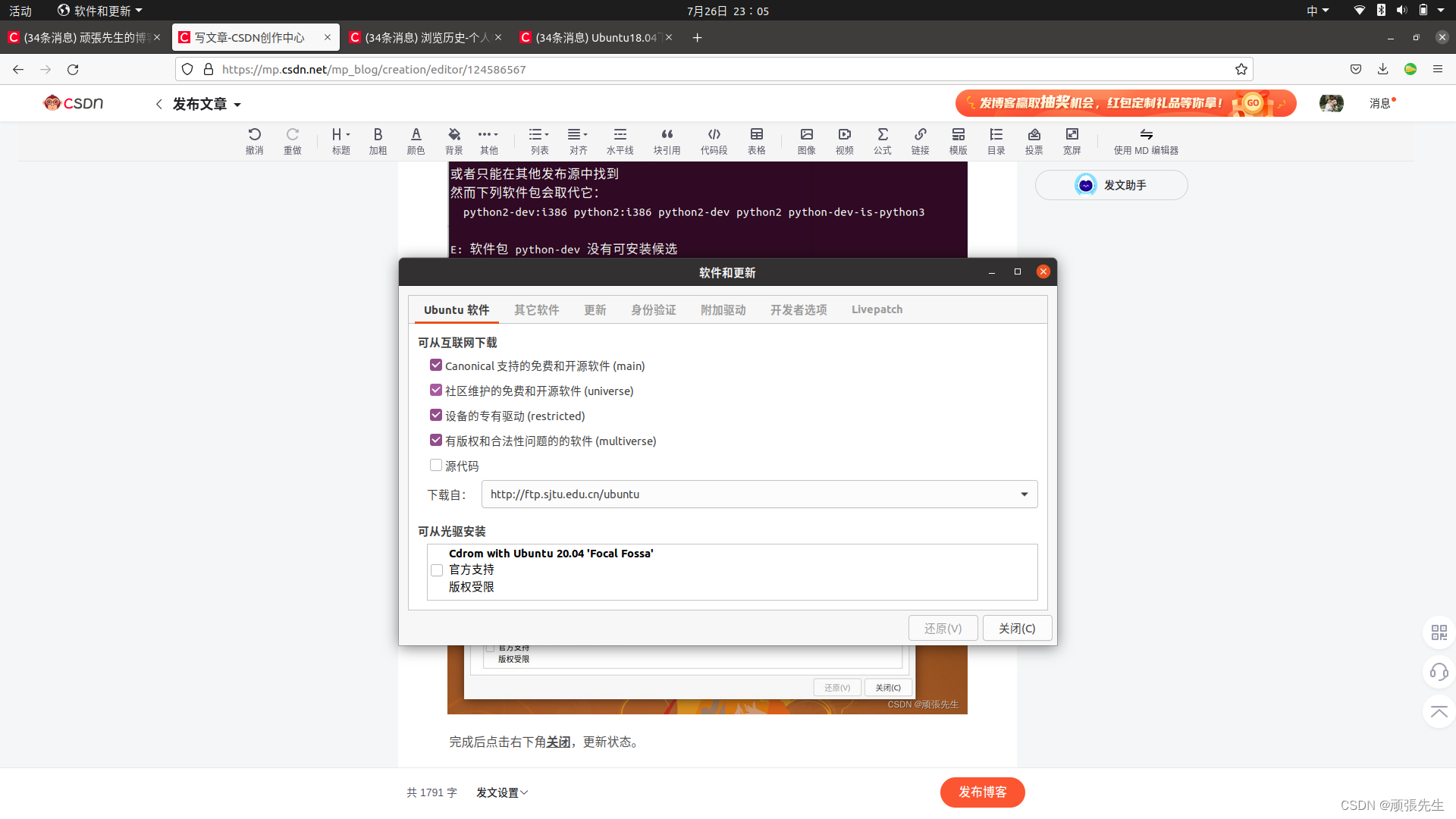
完成后点击右下角 关闭,更新状态。
2.安装依赖
打开终端 输入下列代码
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
sudo apt update
sudo apt install libjasper1 libjasper-dev
sudo apt-get install build-essential
sudo apt-get install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install python-dev-is-python2 python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
3.下载源代码
opencv-4.5.5 源代码下载:下方链接传送门 ,点击进入官网
拉到最下方,出现如图
点击Releases
点击Sourcces下载opencv源码
opencv_contrib 源代码下载:下方链接传送门
https://github.com/opencv/opencv_contrib
下载完成后会得到两个压缩文件,一并解压,然后将opencv_contrib-4.x文件夹放入opencv-4,5,5文件夹中。
4.编译opencv
# 进入opencv源代码目录
cd opencv-4.5.5
# 创建一个build文件夹,用于存放生成的代码
mkdir build
cd build
# 链接
cmake cmake -D CMAKE_BUILD_TYPE=RELEASE \
-DINSTALL_PYTHON_EXAMPLES=ON \
-DINSTALL_C_EXAMPLES=ON \
-DOPENCV_EXTRA_MODULES_PATH=../opencv_contrib-4.x/modules \
-DBUILD_EXAMPLES=ON ..
#编译
make -j4
5 经过漫长的等待
6 安装
sudo make install
7 配置环境变量
输入:
sudo gedit /etc/ld.so.conf.d/opencv.conf
会弹出一个文档,添加如下内容,并保存:
/usr/local/lib
配置库
sudo ldconfig
8 添加修改环境变量
sudo gedit /etc/bash.bashrc
在末尾添加如下内容
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
9 重启电脑 安装完毕
成功的话帮忙点个赞吧!💐💐💐
最后:感谢奇点师兄的指导
感谢博主:丰色木夕
本文参考:新OpenCV 4.2.0 + opencv_contrib安装 (ubuntu16.04)_丰色木夕的博客-CSDN博客_opencv_contrib-4.2.0
本文为踩坑后的避坑笔记,后段(5-10)搬运博主:丰色木夕 文章,如有侵权,联系删除。
Original: https://blog.csdn.net/zooo520/article/details/124586567
Author: 顽張先生
Title: linux下的opencv-4.5.5 及 opencv_contrib 扩展模块安装
相关阅读2
Title: Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
Bert通过双向LM处理语言理解问题,GPT则通过单向LM解决生成问题,那如果既想拥有BERT的双向理解能力,又想做生成嘞?成年人才不要做选择!这类需求,主要包括seq2seq中生成对输入有强依赖的场景,例如翻译,生成式问答,文本摘要等等
最初Transformer的Encoder+Deocder结构是在机器翻译领域,Encoder的部分通过双向LM来抽取输入的全部上下文信息,Decoder通过单向LM在Encoder抽取信息的基础上完成生成任务。但后续的预训练模型,Bert和GPT各自选取了Transformer的一部分来实现各自的目标。Bert只用了Encoder,核心是基于AutoEncoding reconstruction loss的双向LM,适用于NLU任务。GPT只用了Decoder,核心是基于AutoRegression perplexity loss的单向语言模型,适用于NLG任务。那想要兼顾双向理解和生成能力,就要探索如何能让AE和AR在训练过程进行梦幻联动,以下分别介绍3种不同的方案
UNILM 1.0
UNILM完美诠释了MASK在手,要啥都有的极简设计原理。通过三种不同的attention MASK,使用Multitask的训练方式在相同的Transformer backbone里面实现了三种任务的融合,分别是双向LM(BERT),单向LM(GPT),seq2seqLM(transformer)。管你是Encoder还是Decoder本质只是Attention计算中可见信息的差异,那调整MASK就完事了~
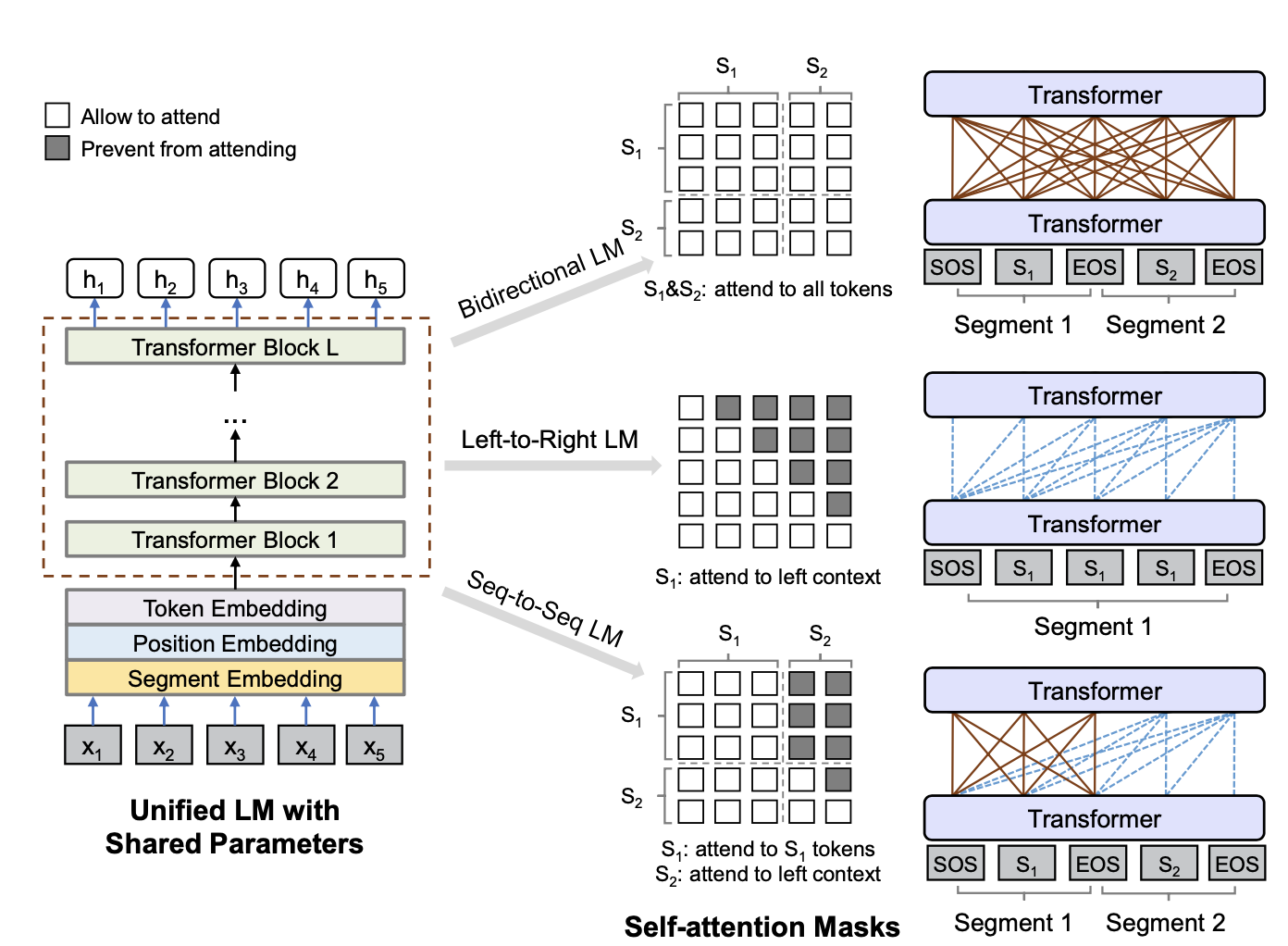
预训练任务
UNILM的预训练任务,都是基于AE的reconstruction任务,和Bert相同的是,都是随机MASK15%的token,其中80%会被MASK替换,10%保留原始token,10%随机token。 不同的是UNILM在80%的情况下会MASK1个token,剩余情况下会随机遮盖bigran或者trigram。
那同样是AE,UNILM是如何做到学到AR相关的信息的呢?这和UNILM的训练方式有关,它采用了Multitask的训练方式,在一个batch的样本中,采用三种不同的attention mask,让相同的模型参数分别学习单向,双向,seq2seq的语言信息,包括
- (\frac{1}{3})的时间训练双向LM: 和BERT相同使用self-attention MASK,并且在以上的MLM任务上,同时也加入了NSP任务
- (\frac{1}{3})训练seq2seq LM:segment1使用self-attention MASK, segment2使用Future MASK,同样是对MASK进行还原
- (\frac{1}{6})的时间训练从左->右单向LM,(\frac{1}{6})的时间训练从右->左单向LM:只不过这里没有使用对整个sequence进行还原的perplexity loss,而同样是对MASK进行还原,只不过只使用单向信息
这里感觉虽然UNLIM实现了单向的信息传递,但和AR之间还是有本质差异的,因为并不是对连续token进行递归预测,而依旧条件独立的对MASK token进行还原,虽然引入了bigram和trigram的MASK,但是效果有限,感觉这里限制了生成的效果。所以有没有可能在共享参数的前提下,直接引入perplexity loss进行训练呢?🤔️🤔️🤔️
针对以上三种任务的输入略有差异,其中单向LM只有1个segment "[SOS] s1 [EOS]",双向LM和seq2seq LM都是2个segment "[SOS] s1 [EOS] s2 [EOS]"
这里会发现以上EOS token,除了和BERT相同起到分割两个segment的作用,在单向LM任务中还会起到停止符的作用,所以其实在不同LM任务中EOS的作用不同,所以这里作者在不同的LM任务中采用了不同的segment Embedding。
预训练阶段, UNILM的参数使用了Bert Large进行初始化,在以上的三个任务重参数是共享的
下游任务Finetune
在下游fientune中,针对NLU任务,迁移方式和Bert相同,例如对分类任务,UNILM会输出[SOS]token对应的Embedding,后接softmax。针对NLG任务,会随机MASK第二个segment中的token进行还原。
整体效果GLUE Benchmark比Bert略好一丢丢,在生成式问答和摘要上提升更大。哈哈具体数值就不贴了,因为马上就要被下面会提到的BART超越,可以直接在下面BART的对比结果中看UNILM的效果了。。。
MASS
MASS则完美诠释了世界是个圈,Bert和GPT费劲吧啦把Encoder和Decoder拆开,MASS又给拼了回来。所以MASS的模型结构就是经典的Encoder+Decoder的Transformer。MASS通过改良MASK机制和训练目标增强了Encoder和Decoder在预训练阶段的交互
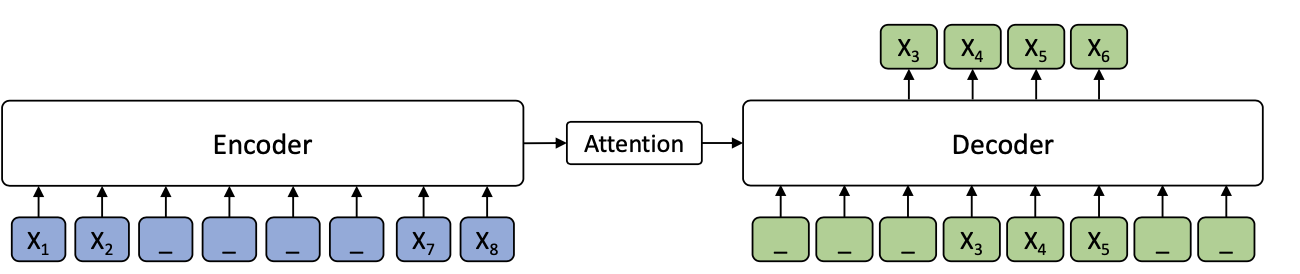
预训练任务
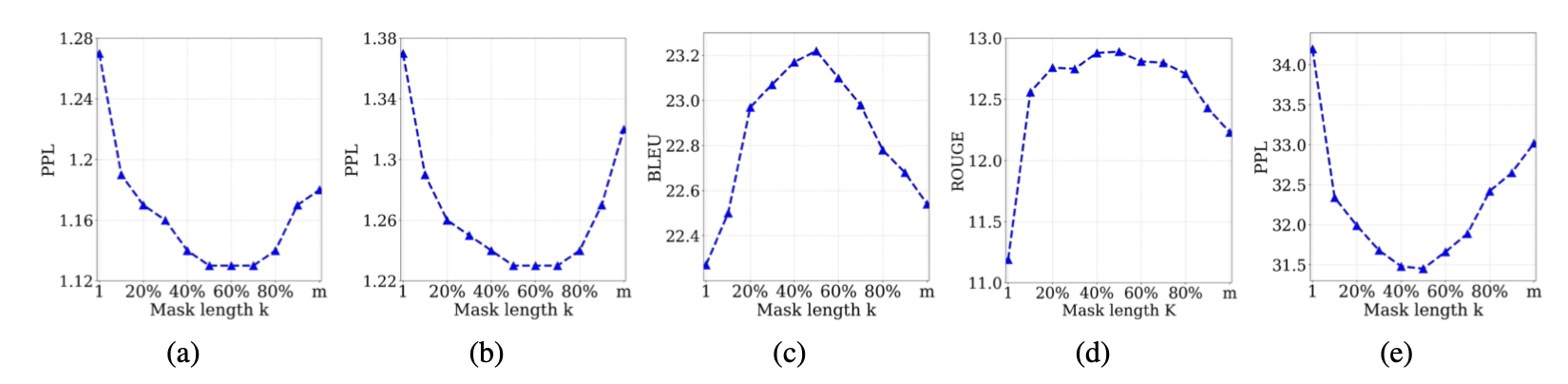
MASS创新了预训练目标,结合了生成和掩码。在Encoder侧随机选取连续K个token,这里k是MASS的超参数, Decoder侧采用互补MASK,遮盖所有在Encoder侧未遮盖的token,使用Auto Regression递归预测这k个token。这种互补掩码的方式,有效增强了Decoder对Encoder的信息依赖,避免Decoder直接依赖上文信息进行预测,进而也推动了Encoder部分去学习上下文双向信息。
都是对连续token进行MASK,和SpanBert不同的是MASS采用的是固定长度,作者测试了k的不同取值对模型效果的影响。整体上K的取值是总长度的50%左右的时候效果最好。哈哈其实感觉如果用一个均值=50%的分布来采样,可能也有效果提升???
有意思的点在于,这里k的取值其实反映了MASS对Bert和GPT的融合权重,当K=1的时候,MASS其实等同于每次只MASK1个token的BERT模型,这时Decoder全部被MASK没有任何信息,而Encoder包含除MASK的一个token之外其余上下文信息。当K=seq_len的时候,MASS其实等同于GPT,这时Encoder没有任何信息,而Decoder部分就是传统的AR。在开头看到MASS的掩码还觉得有些摸不着头脑,看到这里感觉如果从loss function融合的角度来看,MASS的预训练目标其实可以类比Loss融合,和Huber Loss融合RMSE和MAE,以及Generalized Cross Entropy融合Cross Entropy和MAE,有着同一个世界同一个味道~~~

预训练和迁移细节这里就不多说了,因为MASS本身是为NMT翻译任务设计的,所以不管是评估还是训练都是for翻译任务的,和其他两个模型无法直接比较。不过AR和AE的融合思路设计的很巧妙,而且也不局限于NMT任务
BART
BART的模型结构和MASS相同也是Encoder+Decoder的配置,但是和MASS探索的方向不同,BART主要针对reconstruction任务中对输入信息扰动方式的探索,BERT使用的MASK本身也是一种扰动方式。
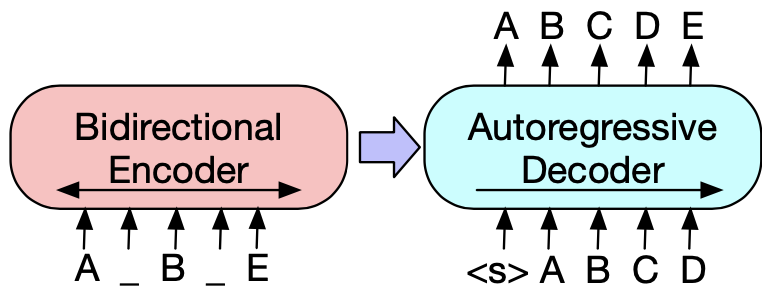
预训练任务
BART的预训练目标是reconstruction loss,通过对输入进行扰动,Encoder的输入是corrupted Sentence,然后Decoder的部分负责还原真实文本,这里只对Decoder的预测计算reconstruction loss。于是当Encoder侧的扰动是删除全部token时,BART->GPT
BART训练策略的设计和MASS相比,对Encoder和Decoder的信息交互要求并不严格,如果Deocder依赖单向信息就能很好完成任务的话,感觉Encoder部分信息会不会变得不太重要???
扰动方式作者尝试了以下方案
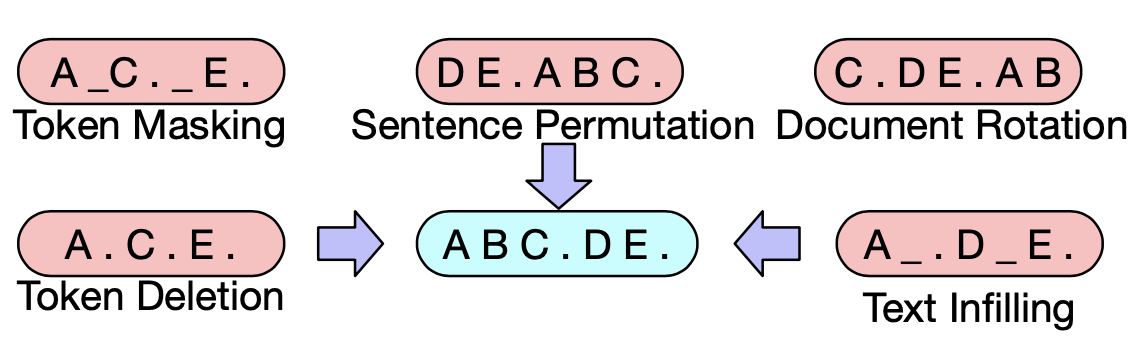
- Token Masking: 和Bert一样对token进行随机Mask,模型需要判断根据上下文还原MASK部分的语义信息
- Token Deletion:随机删除部分token,和MASK的区别在于模型需要去判断哪些位置丢失了信息
- Token Infilling:随机采样0~n个token,用一个MASK进行替换,模型除了学习MASKing部分缺失的语义,还要学习缺失token的数量,其实一定程度上是MASKing和Deletion的组合
- Token Rotation:对句子顺序进行rotate
- Token Shuffling :对句子顺序进行随机shuffle
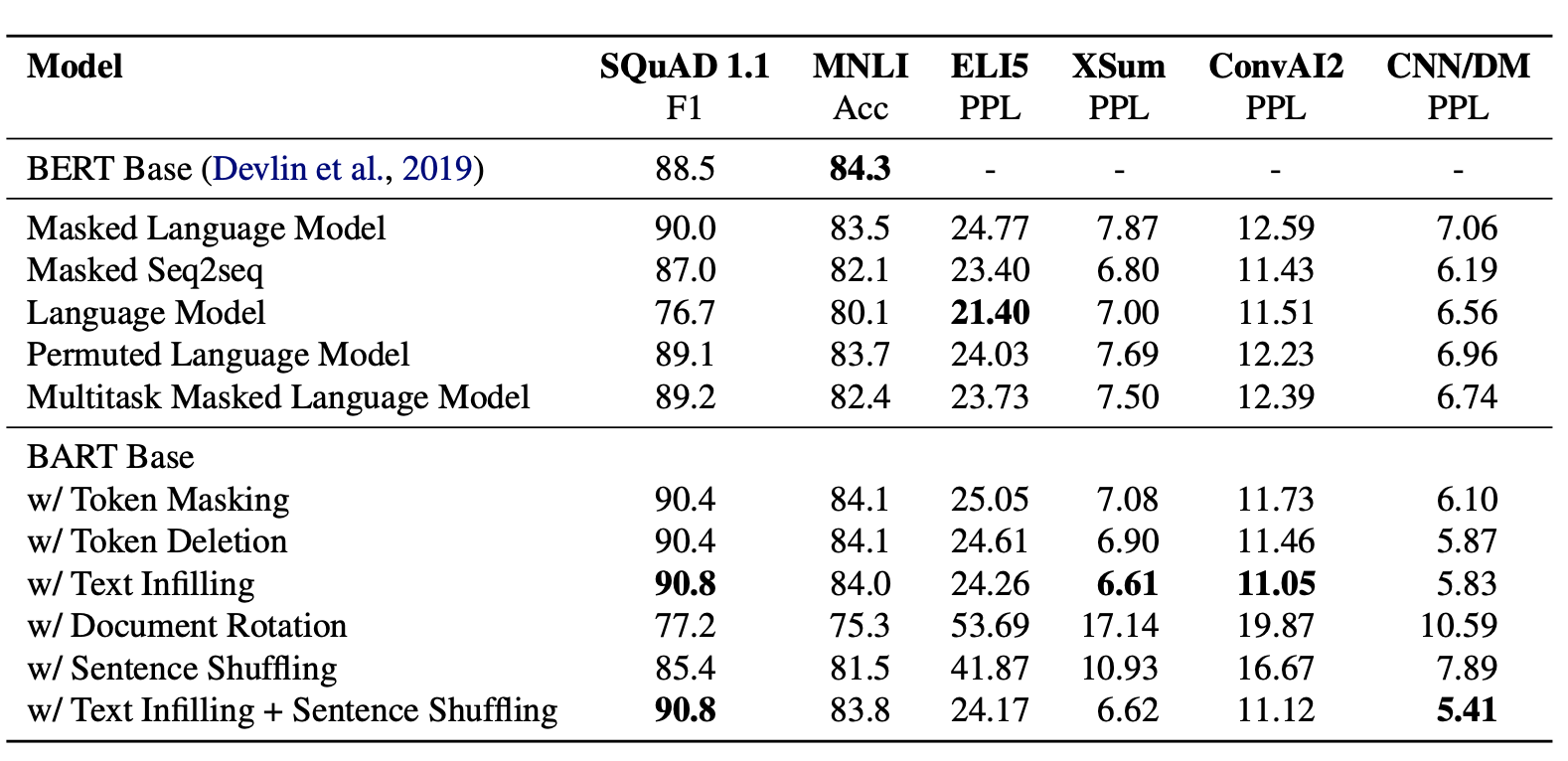
整体评估如下,rotation和shuffling的表现最差,这个也在预料之中如果对所有语料都完全改变顺序,模型其实就不知道正常文本顺序是什么样子的了。而Deletion比Masking在生成任务上的表现更好,一定程度上是Deletion推进模型更多focus在位置信息上,综合各个任务单一扰动机制,Infilling的效果最优。最终作者选择了Infilling+Shuffling相结合的扰动机制,Infilling会MASK30%的token,并同时对整个句子进行随机打乱。
作者还对比了不同的预训练目标的影响,注意这里和原始的模型存在出入,作者只是使用了训练目标的部分,得到以下几点结论
- 不同训练目标在不同任务下差异较大,多数任务上BART表现略好
- 在生成任务上,尤其是输入和输出关联性较低的ELI5,单向语言模型一骑绝尘
- 对阅读理解,推理任务,MASK策略对应的双向语言模型表现显著更好
训练细节参考了Roberta,更大的Batch Size训练更多steps,不过因为BART本身是Encoder+Decoder所以参数量级基本上翻了一倍
下游任务迁移
BART同样可以灵活迁移到下游包括分类,序列标注,文本生成等诸多任务,微调方式各有不同。
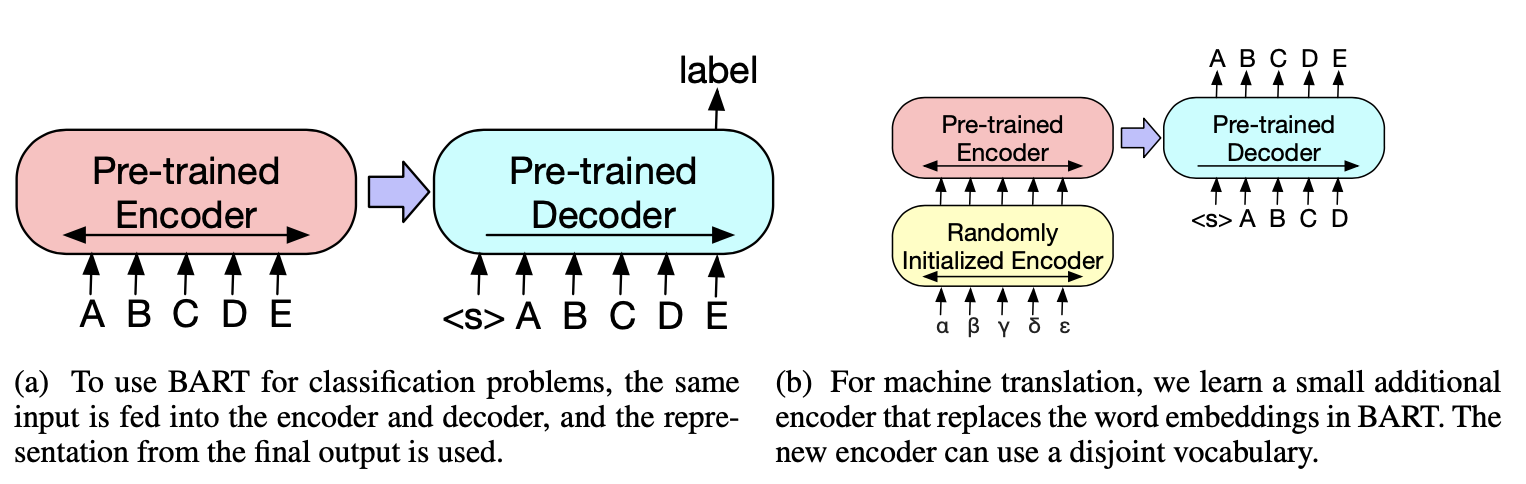
- 分类任务:Encoder输入,Decoder递归,用BART在Decoder的末尾加入了[END]token的Embedding作为文本表征
- 序列标注任务:Encoder输入,Decoder每个位置的输出作为序列标注任务的输入
- 生成任务:Encoder输入,直接使用Decoder部分进行递归生成
- 翻译任务:翻译任务略有差异,是把BART的Embedding输入替换成一个随机初始化的Encoder,这个Encoder使得翻译任务可以使用和原始BART模型Vocab不同的输入。当然random init的部分需要先进行独立训练,再和BART一同已经微调。不过感觉这部分的调整其实和BART没啥非常紧密的联系~
整体效果,在生成任务包括摘要生成和生成式问答上BART的效果都要显著超过之前的模型。
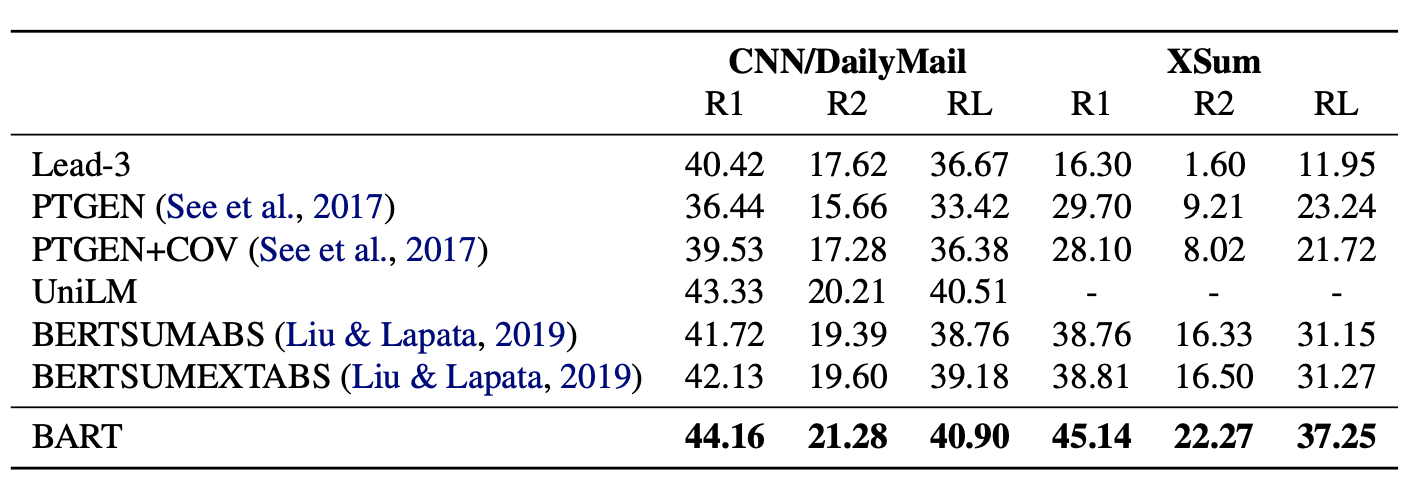
再来关注下阅读理解任务,整体上BART和Roberta效果不相上下,所以BART在生成能力上的提高并没有以牺牲双向理解能力为代价

效果上BART自然是力压群雄,但是Encoder+Decoder的设计不管是训练还是推理都比较沉重,相比之下UNILM共享参数的设计感觉更加巧妙,所以如果能进一步在UNILM上提升效果,感觉就完美了~~
BERT手册相关论文和博客详见BertManual
Ref
- MASS: Masked Sequence to Sequence Pre-training for Language Generation, 2019
- UNLIM, Unified Language Model Pre-training for Natural Language Understanding and Generation, 2019
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, 2019
- 苏剑林. (Sep. 18, 2019). 《从语言模型到Seq2Seq:Transformer如戏,全靠Mask 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6933
- https://www.jiqizhixin.com/articles/2020-09-24
Original: https://www.cnblogs.com/gogoSandy/p/15996974.html
Author: 风雨中的小七
Title: Bert不完全手册2. Bert不能做NLG?MASS/UNILM/BART
相关阅读3
Title: ROS点云话题sensor_msgs::PointCloud2转pcl::PointCloud的两种方式
在ROS中订阅点云话题的时候,需要先将数据类型转换成PCL格式之后再做操作。
方式一:
直接调用pcl自带的函数
pcl::fromROSMsg(const sensor_msgs::PointCloud2 &cloud, pcl::PointCloud<t> &pcl_cloud)</t>
需要添加头文件 #include <pcl_conversions pcl_conversions.h></pcl_conversions>
使用举例:
void callback(const sensor_msgs::PointCloud2ConstPtr & in_cloud_ptr)
{
pcl::PointCloud<pcl::PointXYZ>::Ptr colorcloud(new pcl::PointCloud<pcl::PointXYZ>);
pcl::fromROSMsg(*in_cloud_ptr, *colorcloud);
}
这个方式使用比较简单,一般都使用方式一。
方式二:
目前我使用realsense相机遇到一个问题,订阅得到的初始点云话题数据量过大,有307200个点云,使用pcl::fromROSMsg转成pcl点云,再进行降采样,这两步会用去大量的时间,在对程序运算速度有要求的时候并不好用。
因此采用mencpy的方式,直接从地址提取部分点云,可以有效节省时间。
memcpy函数用法:
void *memcpy(void *dest, const void *src, size_t n);
第一个参数是接收数据的参数,第二个参数是数据的地址,第三个参数是数据的大小。关键就在于第二和第三个参数,先看ros话题的消息格式:

再查看几个重要的参数:
sensor_msgs::PointCloud2 output_pc;
pcl::toROSMsg(cloud,output_pc);
std::cout<<"width: "<<(int)output_pc.width<<std::endl;
std::cout<<"height: "<<(int)output_pc.height<<std::endl;
std::cout<<"point_step: "<<(int)output_pc.point_step<<std::endl;
std::cout<<"row_step: "<<(int)output_pc.row_step<<std::endl;
std::cout<<"fields_size: "<<(int)output_pc.fields.size()<<std::endl;
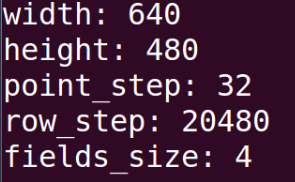
以我这个为例,我是从深度图像转换成的点云,所有是640*480,point_step代表每个点存储了32个字节,
row_step就是width×point_step的大小,
fields_size表示每个点中有几个数据。
再查看fields里面的具体内容:
std::cout<<"fields0: "<<(int)output_pc.fields[0].datatype<<" "<<output_pc.fields[0].name<<std::endl;
std::cout<<"fields1: "<<(int)output_pc.fields[1].datatype<<" "<<output_pc.fields[1].name<<std::endl;
std::cout<<"fields2: "<<(int)output_pc.fields[2].datatype<<" "<<output_pc.fields[2].name<<std::endl;
std::cout<<"fields3: "<<(int)output_pc.fields[3].datatype<<" "<<output_pc.fields[3].name<<std::endl;
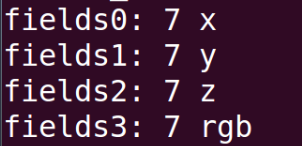
datatype是7,对应的是float32。也就是说每个点都有x,y,z,rgba四个数据,数据类型都是float32,占四个字节。这四个数据的存储方式如下图所示:
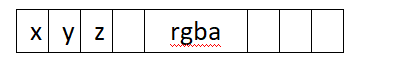
上面提到point_step是32,也就是4字节✖8,x,y,z占用前面12个字节,再空出4个字节后,存储rgba,再空出12个字节。
所有点云的数据是保存在 uint8[] data中的,我们只要每隔32个字节,把其中对应的数据取出,就完成了ROS话题转换pcl话题:
void callback(const sensor_msgs::PointCloud2ConstPtr & in_cloud_ptr)
{
pcl::PointCloud<pcl::PointXYZRGBA>::Ptr pclcloud(new pcl::PointCloud<pcl::PointXYZRGBA>);
for(int i=0;i<in_cloud_ptr->width*in_cloud_ptr->height;i++)
{
pcl::PointXYZRGBA p;
std::memcpy(&p.x,&in_cloud_ptr->data[32*i],4);
std::memcpy(&p.y,&in_cloud_ptr->data[32*i+4],4);
std::memcpy(&p.z,&in_cloud_ptr->data[32*i+8],4);
std::memcpy(&p.rgba,&in_cloud_ptr->data[32*i+16],4);
pclcloud->points.push_back(p);
}
}
这样就实现了从地址中读取ros点云数据。
为了省去之后的降采样的工作,可以只读取部分点云的数据:
void callback(const sensor_msgs::PointCloud2ConstPtr & in_cloud_ptr)
{
pcl::PointCloud<pcl::PointXYZRGBA>::Ptr pclcloud(new pcl::PointCloud<pcl::PointXYZRGBA>);
for(int i=0;i<in_cloud_ptr->width*in_cloud_ptr->height;i+=4)
{
if((i/in_cloud_ptr->width)%4!=0)
{
continue;
}
pcl::PointXYZRGBA p;
std::memcpy(&p.x,&in_cloud_ptr->data[32*i],4);
std::memcpy(&p.y,&in_cloud_ptr->data[32*i+4],4);
std::memcpy(&p.z,&in_cloud_ptr->data[32*i+8],4);
std::memcpy(&p.rgba,&in_cloud_ptr->data[32*i+16],4);
pclcloud->points.push_back(p);
}
}
这样就减少了原始的数据量,加快了ROS话题转换成PCL格式的速度。
Original: https://blog.csdn.net/luyuhangGray/article/details/122634340
Author: 陆宇杭
Title: ROS点云话题sensor_msgs::PointCloud2转pcl::PointCloud的两种方式