
说明
依照官网的使用文档,pytorch下使用transformers进行fine-tuning。
我基本全部都是按照文档来的。
注意:官网的例子基本是直接将模型或者数据集通过一行代码存到本地缓存中,但是需要翻墙。
我们也可以先把模型和数据集下载到本地,之后再从本地加载。我使用的是这种方式。
加载数据集
我们使用huggingface里自带的数据集,加载数据的多种方式可见教程。
教程里使用的是glue下的mrpc数据集,我们也使用该数据集。
手动下载数据集
但是在huggingface里带的数据集中找到的mrpc很小(感觉是个样例),我就自己从网上下载了mrpc数据集,下载地址。
下载完毕后,我使用了后缀是train和test的txt文件作为训练集和测试集,没分验证集。
手动加载数据集
加载数据集教程可见地址。
from datasets import load_dataset
raw_datasets = load_dataset('text', data_files={'train': 'MRPC/msr_paraphrase_train.txt',
'test': 'MRPC/msr_paraphrase_test.txt'})
这样就把数据集加载完成了, MRPC/msr_paraphrase_train.txt这里写自己数据集的文件地址就行。
但是在加载时,报错:
ImportError: IProgress not found. Please update jupyter and ipywidgets.
See https://ipywidgets.readthedocs.io/en/stable/user_install.html
上网搜索,按照以下步骤解决:
conda install ipywidgets
jupyter nbextension enable --py widgetsnbextension
之后数据集成功加载完毕。数据集长这样:
DatasetDict({
train: Dataset({
features: ['text'],
num_rows: 4077
})
test: Dataset({
features: ['text'],
num_rows: 1726
})
})
但是,这数据集不是我们希望的样子 。这里应该是需要写一些分割数据集之类的脚本,但是没时间搜了。
由于服务器连不上外网,我电脑能连。我就先用电脑下载下来正确的数据集,再传到服务器上。具体过程如下:
- 现在笔记本上下载下来正确的数据集,并保存在磁盘上。
from datasets import load_dataset
old_datasets = load_dataset("glue", "mrpc")
old_datasets.save_to_disk('data')
- 然后,把下载下来的文件夹传到服务器。
- 最后,在服务器上,加载数据集,这就和教程完全一样了。
import datasets
raw_datasets = datasets.DatasetDict()
raw_datasets = raw_datasets.load_from_disk('data')
查看数据集
可以看看数据集里的数据长啥样:
raw_train_dataset = raw_datasets["train"]
raw_train_dataset[0]
结果:
{'sentence1': 'Amrozi accused his brother , whom he called " the witness " , of deliberately distorting his evidence .',
'sentence2': 'Referring to him as only " the witness " , Amrozi accused his brother of deliberately distorting his evidence .',
'label': 1,
'idx': 0}
可以看看数据集的特征:
print(raw_train_dataset.features)
结果:
{'sentence1': Value(dtype='string', id=None), 'sentence2': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=2, names=['not_equivalent', 'equivalent'], names_file=None, id=None), 'idx': Value(dtype='int32', id=None)}
加载分词器tokenizer
下载模型并加载tokenizer
tokenizer和我们想要使用的模型需要一致,tokenizer可以理解为把我们的原始文本转换成数字,从而能够输入网络,这种转换有多种模式,理论部分可以查看教程。
我们使用的模型为 bert-base-uncased,还是手动下载并加载。
下载地址,可以使用git把整个库都下载下来,也可以只下载需要的。我下载了:
- vacab.txt
- tokenizer_config.json
- tokenizer.json
- config.json
- pytorch_model.bin
下载的这些可能有部分文件用不到。下载之后将它们放入文件夹 bert-base-uncased中,并传给服务器。
通过以下代码加载tokenizer,py或者ipynb文件的同级目录下要有一个bert-base-uncased的文件夹,里面放着模型。
from transformers import BertTokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
可以试一下tokenizer的效果:
inputs = tokenizer("This is the first sentence.", "This is the second one.")
print(inputs)
{
'input_ids': [101, 2023, 2003, 1996, 2034, 6251, 1012, 102, 2023, 2003, 1996, 2117, 2028, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
}
tokenizer效果的具体讲解可见教程。
预处理数据集中的数据
由于数据集中也是两个句子和label,我们需要把两个句子也像上面一样预处理一下。
完整的预处理代码如下:
from transformers import DataCollatorWithPadding
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenized_datasets是预处理后的数据集,而 DataCollatorWithPadding是将数据集处理成批的工具(应该是,具体可见链接),并且会将数据整理成统一的长度(也就是该批最长的数据的长度)。与将数据整理成整个数据集最长数据的长度相比,整理成该批数据最长数据的长度显然更好。
训练
定义TrainingArguments、加载模型
首先定义一个TrainingArguments类,这里可以定义一些训练用的超参数。我们可以只定义模型的保存地址。具体参数可见文档。
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
接下来加载模型:
from transformers import BertForSequenceClassification
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
这里还是从 本地文件里加载的模型。
加载Trainer
接下来就可以传递之前定义的很多参数,加载一个Trainer从而进行训练。
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset = tokenized_datasets["train"],
eval_dataset = tokenized_datasets["validation"],
data_collator = data_collator,
tokenizer = tokenizer,
)
之后就可以开始fine-tuning,也就是训练:
trainer.train()
引入评估
训练中只有loss的值,模型效果如何并不明显。因此我们需要为trainer引入能显示验证集准确率的东西。具体讲解可见文档,简单说就是定义一个计算验证集准确率的函数,并将其引入我们的trainer。
from datasets import load_metric
def compute_metrics(eval_preds):
metric = load_metric("glue", "mrpc", mirror="tuna")
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
training_args = TrainingArguments("test-trainer", evaluation_strategy="epoch")
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
metric = load_metric("glue", "mrpc", mirror="tuna")
这里还是需要翻墙,用了清华的镜像。或者还可以这样解决(我没试过)。
最后,开始训练:
trainer.train()
训练效果
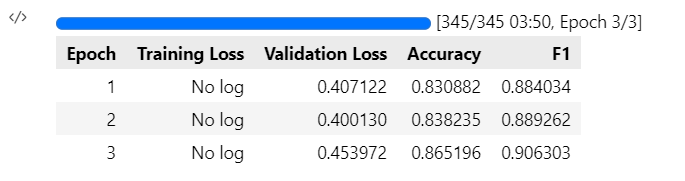
Original: https://blog.csdn.net/qq_43219379/article/details/123156368
Author: eecspan
Title: pytorch使用transformers库进行fine-tuning微调
相关阅读1
Title: Tensorflow自学__1.3张量生成 输出tensor的值
刚开始跟MOOC学习tensorflow,跟着视频写代码,才发现简简单单的代码也有各种小问题。
tensor的值无法显示,始终显示0
一开始输入
a=tf.constant([1,2,3])
print(a)
print(a.dtype)
输出:
Tensor("Const:0", shape=(3, 5), dtype=int64)
<dtype: 'int64'>
(3, 5)
可以看到输出的tensor const:0
为了解决这个问题,我查阅了资料,有两种办法。
第一种办法:
sess=tf.Sesson()
print(sess.run(a))
第二种办法:
with tf.Sesson()
print(a.eval())
输出的是:
[1 2 3 ]
设置tensor的固定输出
d=tf.zeros([2,3])
e=tf.ones(4)
f=tf.fill([2,3],9)
print(sess.run(d))
print(sess.run(e))
print(sess.run(f))
输出:
[[0. 0. 0.]
[0. 0. 0.]]
[1. 1. 1. 1.]
[[9 9 9]
[9 9 9]]
维度书写
1维:直接写个数
2维:[行,列]
多维:[n,m,j,k,...]
例如:多维 tf.fill( [3,2,3,4],9)
3:[]内部产生3块
2:倒数第二层产生2块
3:倒数第三层产生3块
4:最里层4块(也就是4个数字9)
如图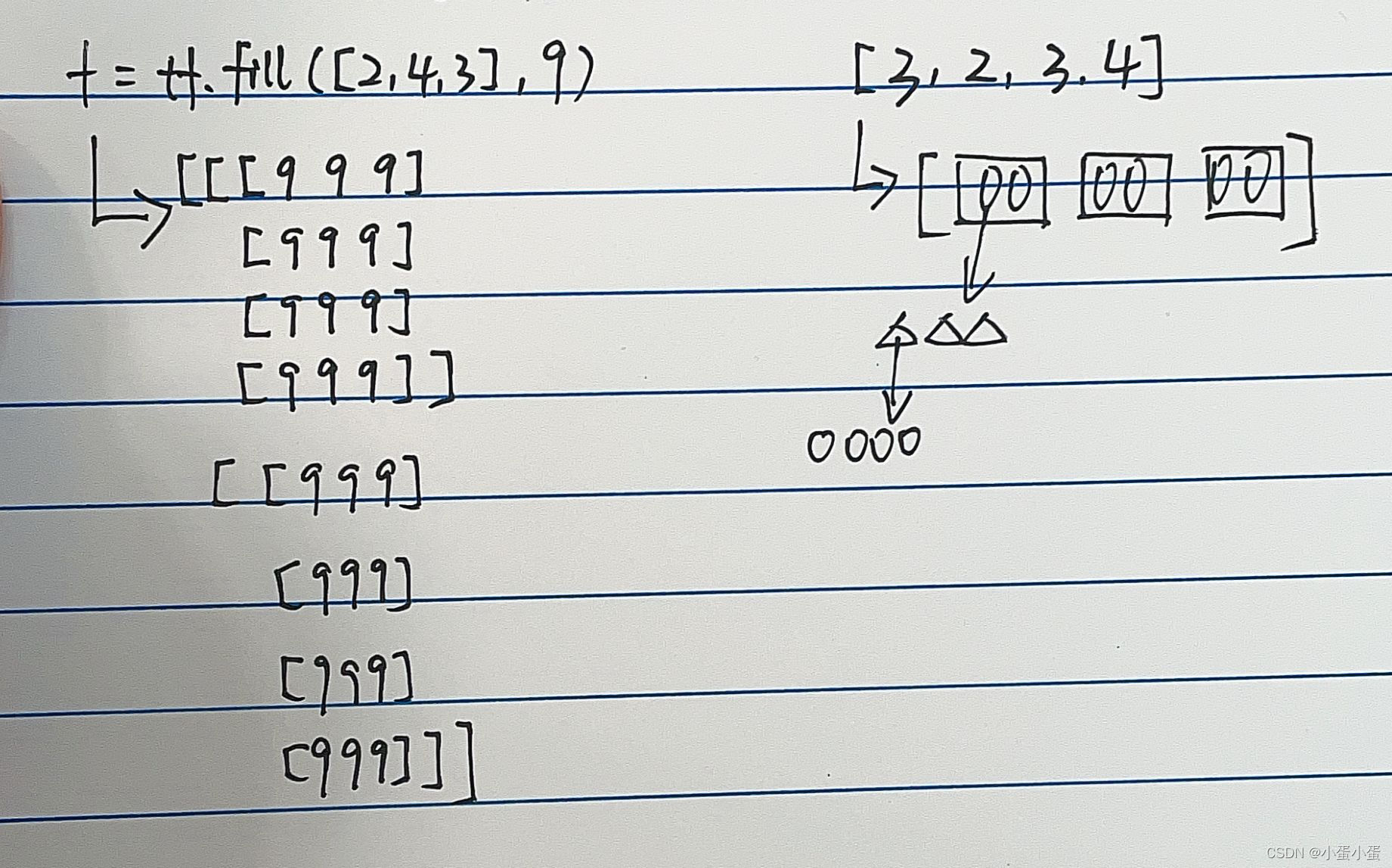
tensor随机生成
1.生成正态分布的随机数:
g=tf.random_normal([2,3],mean=0.5,stddev=1)
print(sess.run(g))
2.生成截断式正态分布的随机数:
h=tf.random_truncated_normal([2,3],mean=0.5,stddev=1)
print(sess.run(h))
!!!!!!!!!! 出现了BUG!!!!!待解决!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!

查阅了一下官方文档
h=tf.truncated_normal([2,3],mean=0.5,stddev=1)
print(sess.run(h))
这样子就可以运行了,没有报错了,应该是tensorflow2.0很多函数改变了。。
输出:

3.生成均匀分布

运行一下

Original: https://blog.csdn.net/qq_39072370/article/details/124325890
Author: 小蛋小蛋
Title: Tensorflow自学__1.3张量生成 输出tensor的值
相关阅读2
Title: 将tf1训练的模型导入tf2进行推理
最近做比赛遇到一个问题,tf1训练的模型提交后因为环境问题导致线上无法运行,故尝试线上用tf2进行推理。
步骤需要1.将tf1的.pd模型结构和ckpt存档导出。2.将模型结构和ckpt存档转化为.pd静态图(frozen graph)。3.使用tf2读取.pd静态图(frozen graph)进行推理
首先定义基于tf1的模型
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
with tf.Session() as sess:
a = tf.placeholder(tf.float32, [1])
b = tf.placeholder(tf.float32, [1])
c = tf.get_variable("w", [1])
d = a*c
out = tf.add(d, b)
# 初始化变量
sess.run(tf.variables_initializer(tf.global_variables()))
# 保存图结构
tf.train.write_graph(sess.graph_def, './', 'graph_define.pb', as_text=True)
# 保存参数存档
saver = tf.train.Saver()
saver.save(sess, 'checkpoint.ckpt')
之后转化模型为静态图(frozen graph)
import tensorflow as tf
from tensorflow.python.tools import freeze_graph
# 转化模型
with tf.compat.v1.Session() as sess:
freeze_graph.freeze_graph(
input_graph='./graph_define.pb',
input_saver='',
input_binary=False,
input_checkpoint='./checkpoint.ckpt',
output_node_names='Add',
restore_op_name='save/restore_all',
filename_tensor_name='save/Const:0',
output_graph='./frozen_model.pb',
clear_devices=False,
initializer_nodes=''
)
其中input_graph是图结构文件,input_checkpoint是参数文件,output_node_names是输出节点名
需要注意的是模型训练时必须是基于原生tf1的,如果训练时使用tf.compat.v1而不引入tf.disable_v2_behavior(),会在转换时报错。
最后使用tf2加载静态图进行推理
import tensorflow as tf
def wrap_frozen_graph(graph_def, inputs, outputs):
def _imports_graph_def():
tf.compat.v1.import_graph_def(graph_def, name="")
wrapped_import = tf.compat.v1.wrap_function(_imports_graph_def, [])
import_graph = wrapped_import.graph
return wrapped_import.prune(
tf.nest.map_structure(import_graph.as_graph_element, inputs),
tf.nest.map_structure(import_graph.as_graph_element, outputs))
def load_pb(filename):
# Load frozen graph using TensorFlow 1.x functions
with tf.io.gfile.GFile(filename, "rb") as f:
graph_def = tf.compat.v1.GraphDef()
loaded = graph_def.ParseFromString(f.read())
# Wrap frozen graph to ConcreteFunctions
frozen_func = wrap_frozen_graph(
graph_def=graph_def,
inputs=['Placeholder:0', 'Placeholder_1:0'], # input tensor name of your model
outputs="Add:0" # output tensor name of your model
)
return frozen_func
model = load_pb('frozen_model.pb')
print(model(tf.constant(3, tf.float32), tf.constant(4, tf.float32)))
实测比赛代码也可以在线上运行了
参考资料:
Original: https://blog.csdn.net/luanshaotong/article/details/121669902
Author: luanshaotong
Title: 将tf1训练的模型导入tf2进行推理
相关阅读3
Title: tf2 一机多卡训练
文章目录
前言
基于docker,使用两个GPU训练自定义模型(Keras子类)。
镜像分布式策略 MirroredStrategy
分布式策略有很多,这里只介绍一种,方便快速上手,实践证明一机多卡可行
其它分布式策略详见:https://blog.csdn.net/u010099177/article/details/106074932
tf.distribute.MirroredStrategy 支持在 单机多GPU上的同步分布式训练。 它在每个GPU设备上创建一个副本. 模型中的每个变量都将在所有副本之间进行镜像。这些变量一起形成一个称为MirroredVariable的概念上的变量。通过应用 相同的更新,这些变量彼此保持同步。
高效的归约算法用于在设备之间传递变量更新。全归约通过对不同设备上的张量相加进行聚合, 并使他们在所有设备上可用。这是一种融合算法,非常有效,可以大大减少同步的开销。根据设备之间可用的通信类型,有许多归约算法和实现可用,默认使用NVIDIA NCCL。您可以从我们提供的其他选项中进行选择,也可以自己编写。
这是创建 MirroredStrategy 最简单的方法:
strategy = tf.distribute.MirroredStrategy()
这会创建一个 MirroredStrategy 实例,将会使用TensorFlow所有可见的GPU, 使用NCCL进行跨设备通信。
如果您只想使用计算机上的某些GPU,可以这样做:
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
我们已经将 tf.distribute.Strategy 集成到 tf.keras 中。 tf.keras 是一个构建和训练模型的高级API。通过集成到 tf.keras 后端, 用Keras训练框架写的程序可以无缝进行分布式训练。
您需要对代码中进行以下更改:
- 创建一个
tf.distribute.Strategy实例 - 将Keras模型的创建和编译过程挪到
strategy.scope中 - 支持各种类型的Keras模型:顺序模型、函数式模型和子类模型
下面是一个非常简单的Keras模型示例:
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])
model.compile(loss='mse', optimizer='sgd')
只需要将你的 模型创建部分、 编译部分放到 strategy.scope()里即可
实现代码
关键代码如下,使用0卡和1卡:
callbacks = [tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=1e-8, patience=0, verbose=2)]
opt = optimizers.SGD(learning_rate=0.001, )
strategy = tf.distribute.MirroredStrategy(devices=["/gpu:0", "/gpu:1"])
with strategy.scope():
model = FCINN(dense_feature_columns, sparse_feature_columns, len(dense_features), hidden_units=(512, 256, 128), activation='relu', dropout=(0.3, 0.2, 0.2),
k_vector=8, w_reg=0.01, v_reg=0.01, mode='inner',
filters=[16, 18, 22, 24], kernel_with=[7, 7, 7, 7], dnn_maps=[3, 3, 3, 3], pooling_width=[2, 2, 2, 2]
)
model.compile(
optimizer=opt,
loss='binary_crossentropy',
metrics=['AUC', 'Precision', 'Recall', 'accuracy']
)
model.fit(
train_dataset,
validation_data=val_dataset,
epochs=2,
verbose=2,
callbacks=callbacks,
)
docker run -d --gpus '"device=0,1"' \
--rm -it --name ctr_tf_tmp \
-v /data/wangguisen/ctr_note/new_thought:/ad_ctr/new_thought \
-v /data/wangguisen/ctr_note/data:/ad_ctr/data \
ad_ctr:3.0 \
sh -c 'python3 -u /ad_ctr/new_thought/moreGPU.py 1>>/ad_ctr/new_thought/log/moreGPU.log 2>>/ad_ctr/new_thought/log/moreGPU.err'
成功运行
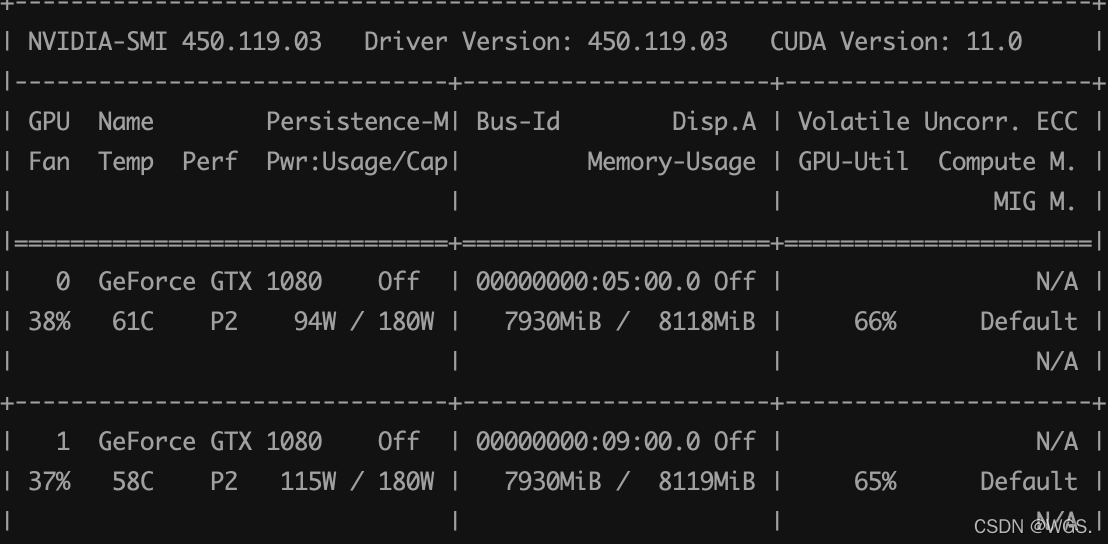
看使用率和内存占用,说明一机双卡成功运行。
一机单卡:

一机多卡:

参考:
docker指定使用某几张显卡:
https://blog.csdn.net/qq_21768483/article/details/115204043
tf2 Dataset使用:
https://blog.csdn.net/u012513618/article/details/109671774
使用 TensorFlow 2.0 进行分布式训练:
https://blog.csdn.net/u010099177/article/details/106074932
https://www.cnblogs.com/xiximayou/p/12690709.html
Original: https://blog.csdn.net/qq_42363032/article/details/122880645
Author: WGS.
Title: tf2 一机多卡训练