
摘要
提出Multimodal End-to-end TransformER framework,即METER,通过这个框架研究如何以一个端到端的方式( in an end-to-end manner )设计和预训练一个完全基于transformer的视觉语言模型。
端到端指的是输入是原始数据,输出是最后的结果,整个模型过程相当于黑箱操作;相反,非端到端的方法,数据的预处理部分是单独的模块,需要人工处理(如人工标注数据,人工提取图片特征)(笔者注)
具体地,模型从多个维度被解剖(dissect)为:
视觉编码器/vision encoders;
文本编码器/text encoders;
多模态融合模块/multimodal fusion module;
结构设计/architectural design:encoder-only vs. encoder-decoder;
预训练目标/pre-training objectives。
introduction
- Vision Transformer在VLP(vision-and-language pretrained)中的地位比language transformer更重要
- cross-attention有益于多模态融合,在下游任务上的表现由于self-attention alone
- 在相同的设置下,对于VQA和zero-shot的图文检索任务上,encoder-only的VLP模型比encoder-decoder模型效果更好
- 在我们的设置下,在VLP中add masked image modeling loss并不会提升下游任务的性能

; METER框架
overview
给定一个文本I和一张图片V,
一个VLP模型首先通过一个文本编码器和一个图片编码器抽取文本特征和图片特征。
然后将文本特征和图片特征喂入一个多模态融合模块以获取跨模态表示。
在生成最终输出前,跨模态表示选择性地喂入一个解码器。
Model Architecture
Vision Encoder
在ViT(vision transformer)中,一个图片首先被分块,然后这些块被喂入transformer模型。
在这篇文章中,分析并比较了以下ViT:
the original ViT, DeiT, Distilled-DeiT, CaiT, VOLO, BEiT, Swin Transformer 和 CLIP-ViT.
Text Encoder
大部分的VLP模型仍然只使用BERT来初始化语言模型,在这篇文章中,分析并比较了以下BERT:
BER, RoBERTa, ELECTRA, ALBERT, DeBERTa
Multimodal Fusion
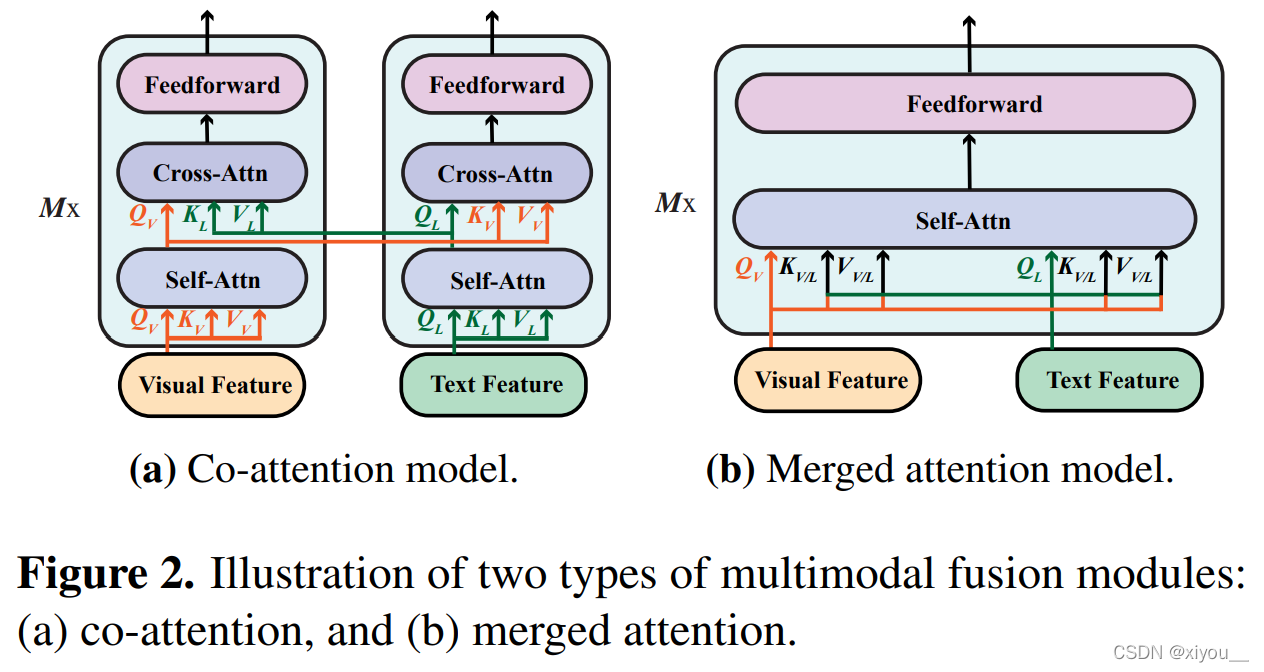
研究了两种融合方法:
- merged attention:文本和图片特征简单拼接,然后喂入一个单一的transformer模块
- co-attention:文本特征和图片特征分别喂入不同的transformer模块,并且使用cross-attention等技术实现跨模态交互
; architectural design
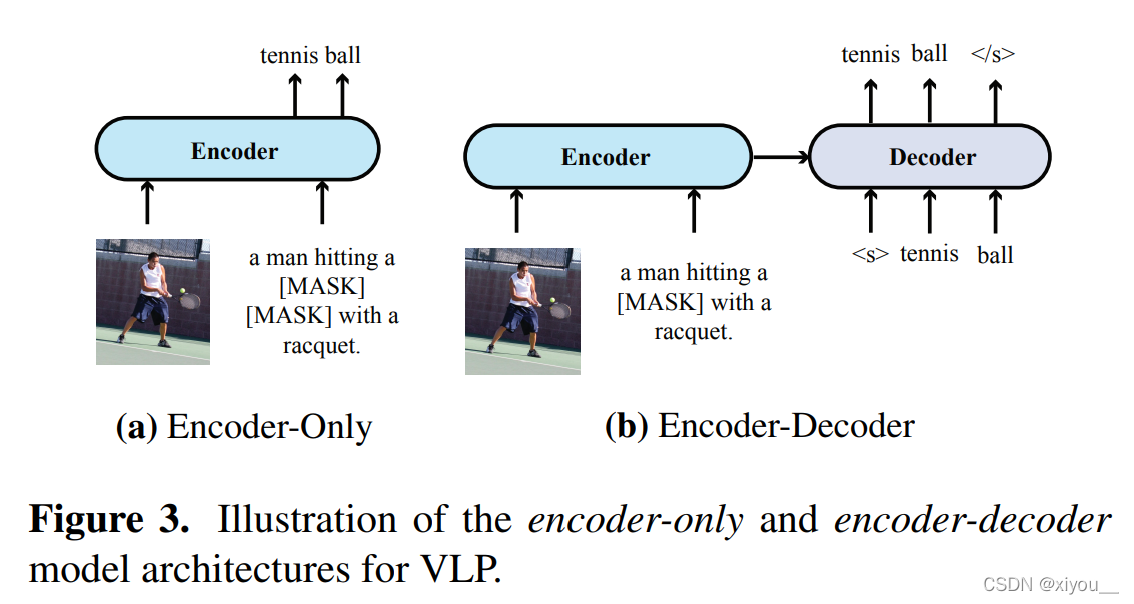
- encoder-only
- encoder-decoder
Pre-training Objectives
- Masked Language Modeling
- Image-Text Matching
- Masked Image Modeling
Original: https://blog.csdn.net/xiyou__/article/details/123134897
Author: xiyou__
Title: 论文阅读:An Empirical Study of Training End-to-End Vision-and-Language Transformers
相关阅读1
Title: Nvidia MX150安装Tensorflow-GPU版,Pycharm使用Keras
使用环境:Windows 10 Professional + Pycharm
需要使用:Tensorflow+keras
顺序安装:CUDA→CUDNN→Tensorflow
特别注意:版本与版本之间的对应
1.确定显卡目前支持的CUDA版本,下载对应CUDA版本,安装
英伟达官方CUDA下载地址: CUDA Toolkit Archive | NVIDIA Developer
2.根据安装的CUDA版本,找到对应支持的CUDNN版本文件,替换到安装好的CUDA文件夹中
英伟达官方CUDNN下载地址: cuDNN Archive | NVIDIA Developer
注意!CUDNN文件下载需要注册英伟达账户,右上角注册登陆后即可对应打开下载
3.根据安装好的CUDA和CUDNN版本,确定对应支持的Tensorflow版本后,再使用pip命令安装
安装过程:
一、 选择对应的CUDA、CUDNN文件,进行下载
1.确定CUDA版本,进入英伟达控制面板→帮助→系统信息→组件
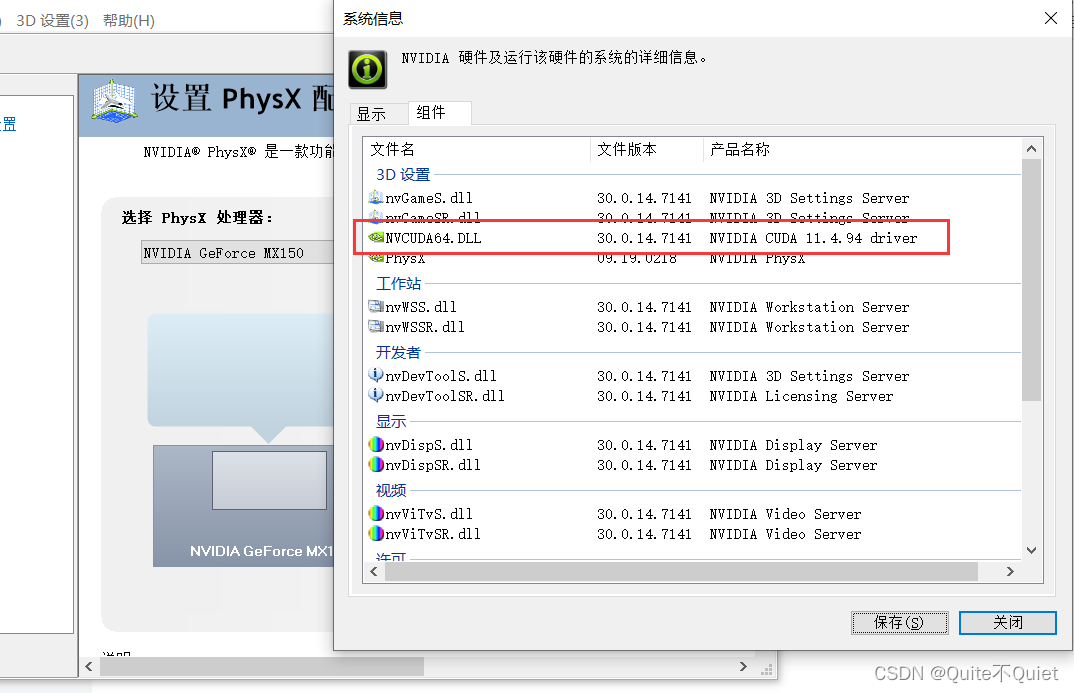
可以看到,支持CUDA11.4系的使用,接着进入英伟达CUDA下载页面

这里我选择最新2022年的11.4版本进行安装
2.进入英伟达CUDNN下载页,下载对应的CUDNN文件
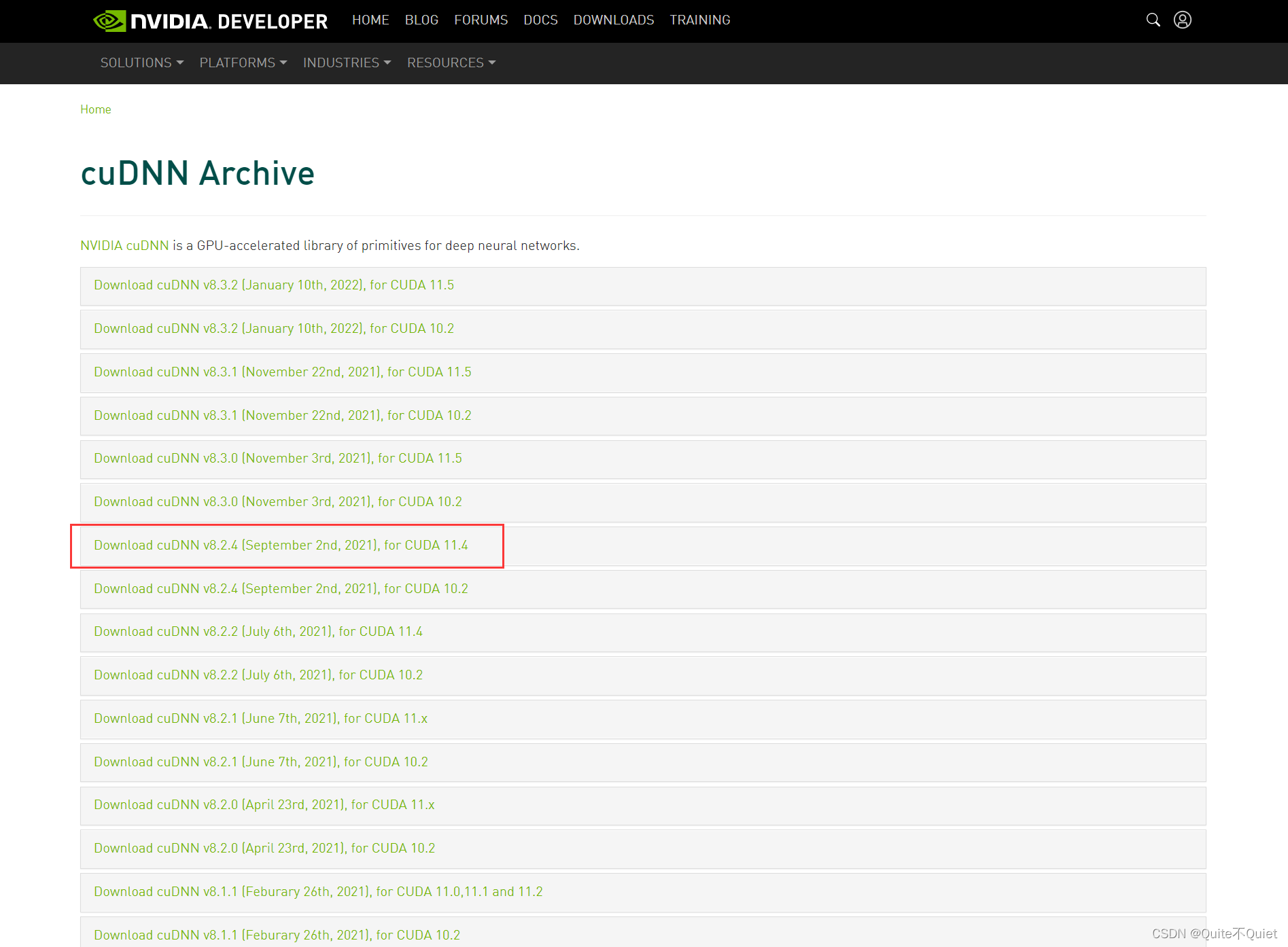
这里我选择2 1年9月的CUDNN for cuda11.4版本,选择下载Windows X64的文件格式
二、 再次确认下载的各个版本是否对应匹配
python版本、CUDA版本、CUDNN版本,是否都对应,特别注意前三个均要对应
最后确定tensorflow-gpu版本
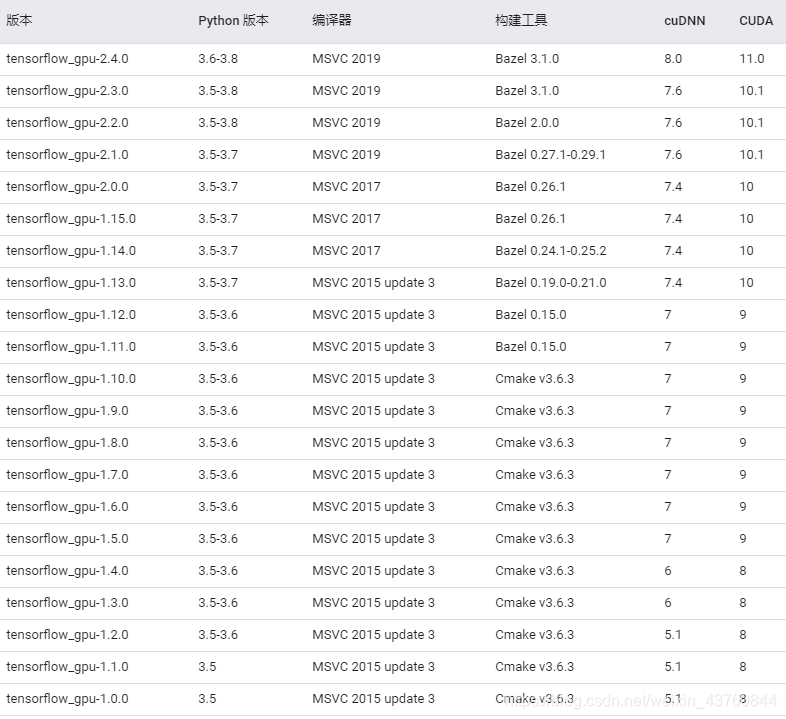
可以看到,我们可以对应安装的是 tensorflow-gpu 2.4.0的版本
三、 开始依次安装
1.安装CUDA
默认安装路径启动
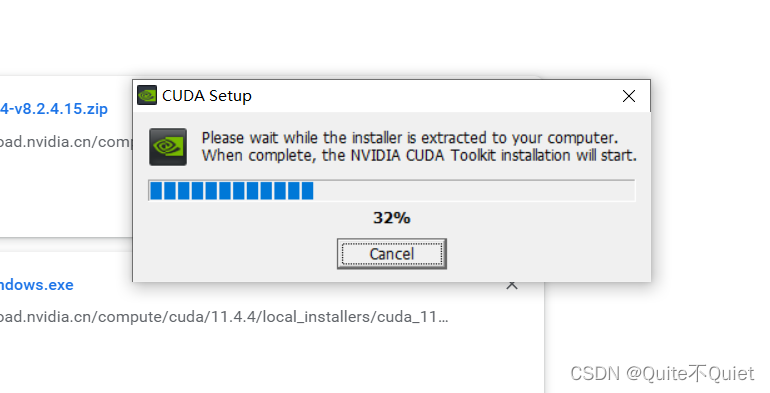
使用自定义安装,去勾选VS选项


安装完后,重启计算机
配置环境变量,将 CUDA下的 bin目录、lib\x64目录,配置到path中去
默认安装位置 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4
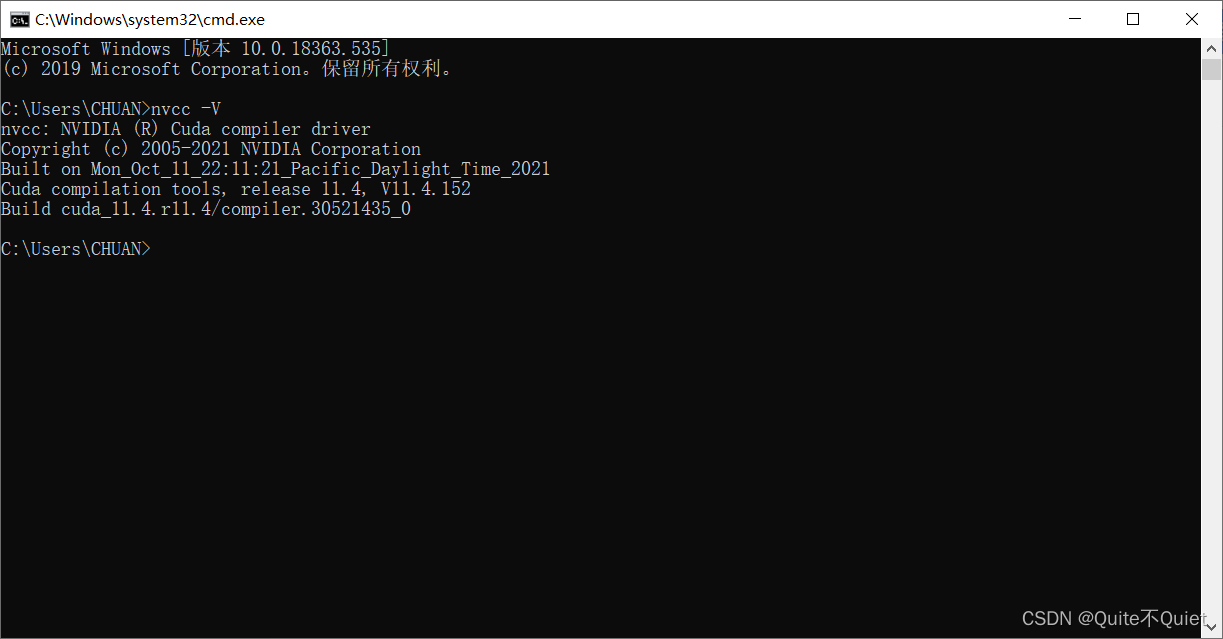
配置后,检查一下CUDA版本,cmd窗口下,输入 nucc -V
2.安装CUDNN
将下载好的CUDNN文件进行解压,得到一个名为 CUDA的文件夹
将CUDNN解压文件夹内的所有文件,复制粘贴到CUDA的安装位置
默认安装位置 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4
复制粘贴后如下图
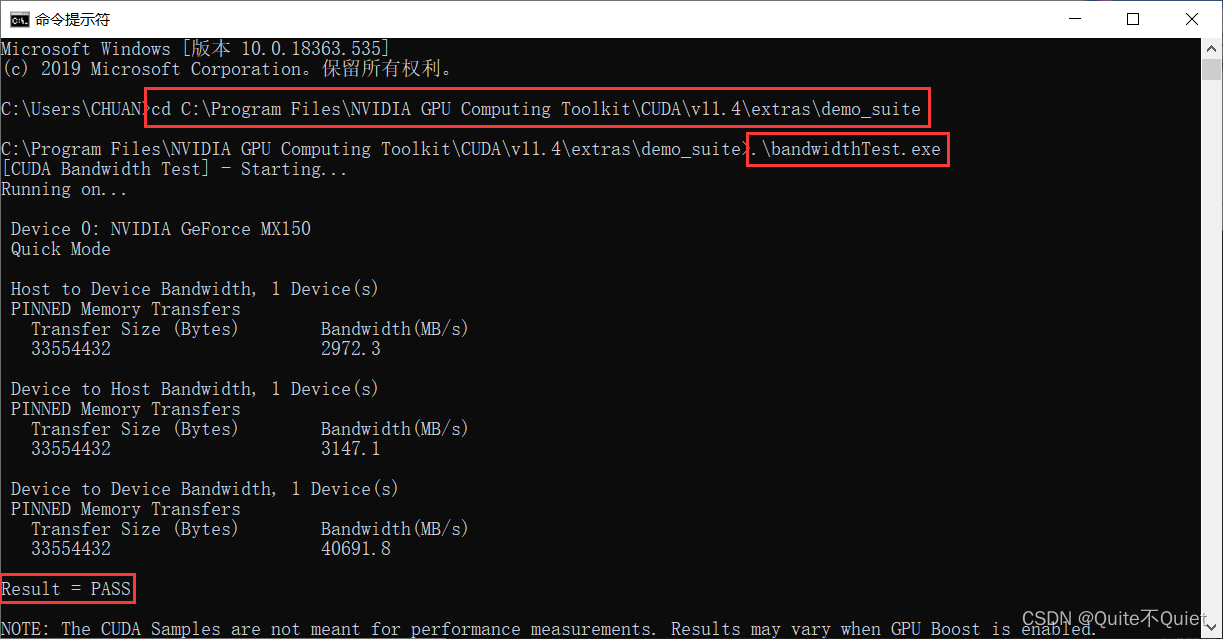
最后,检验CUDNN是否安装成功,进入CMD窗口,切到CUDA目录
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\extras\demo_suite
使用bandwidthtest检测,显示为PASS,即为安装成功
3.安装Tensorflow
创建一个虚拟环境,在虚拟环境下安装Tensorflow

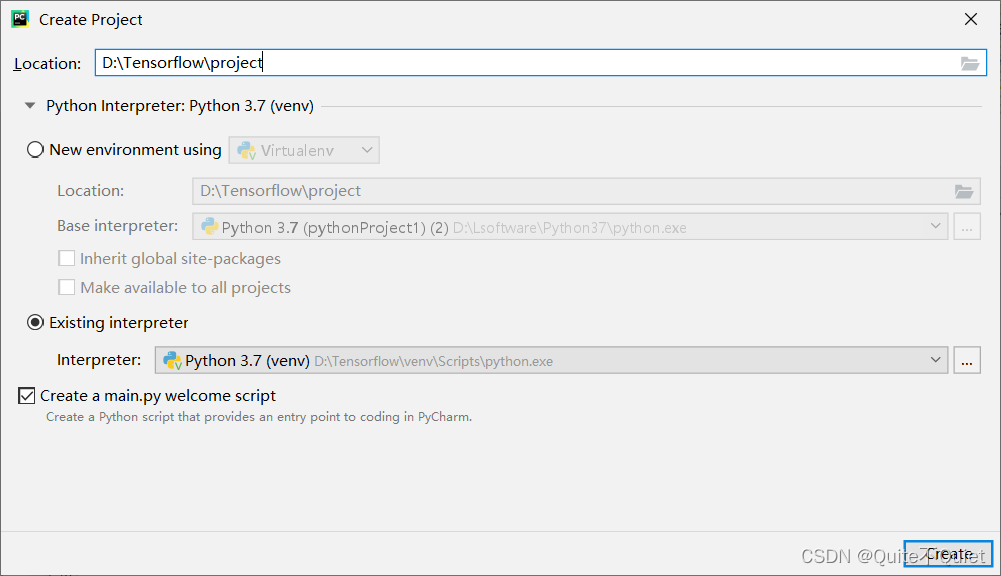
 创建一个新的项目在Tensorflow目录下, 项目名为project,选择我们刚才创建的虚拟环境解释器
创建一个新的项目在Tensorflow目录下, 项目名为project,选择我们刚才创建的虚拟环境解释器
在CMD窗口下,CD至我们创建的Tensorflow路径下,pip list,可以看到是一个新的环境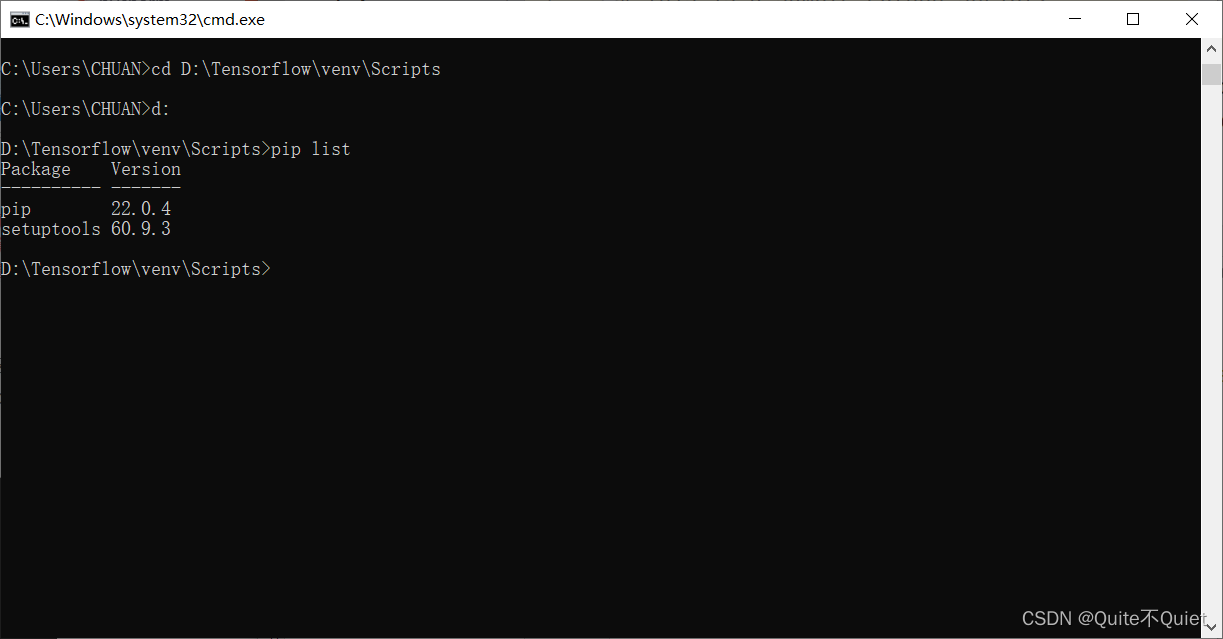
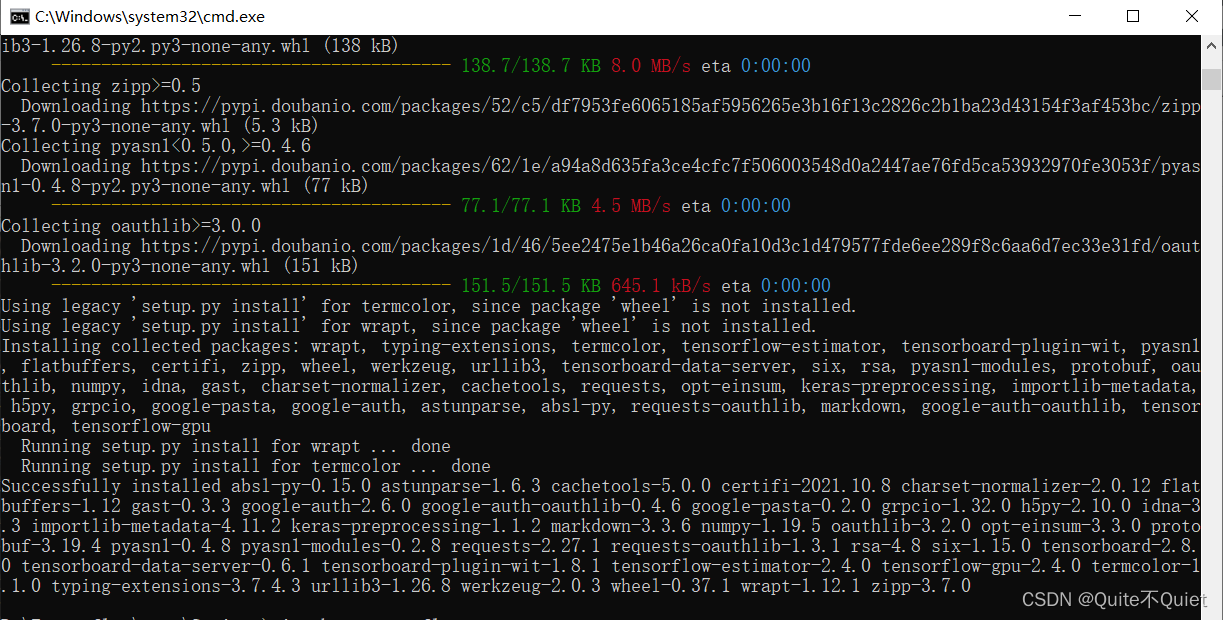
然后我们在该环境下,进行pip安装Tensorflow 2.4.0版本 (我们所对应的版本)
pip install tensorflow-gpu==2.4.0 -i https://pypi.douban.com/simple/
 安装完如下图所示
安装完如下图所示
最后我们验证一下,Tensorflow是否安装成功
CMD命令窗口进入虚拟环境,pip show tensorflow-gpu

显示版本信息为2.4.0,正常导入,均无报错,即安装成功!
以上即全部安装步骤, Tensorflow从2.0后,已内置了Kears ,导入即可使用!
在我们安装好后,运行Pycharm时,可能会出现的一些问题,另外写了一个记录,在此不作赘述
Tensorflow-GPU2.4.0,使用中出现的问题_Quite不Quiet的博客-CSDN博客
附:CUDA算力表
CUDA算力,MX系列为6.1,与GTX10系算力相同,使用Tensorflow-GPU版能大幅度提高效率
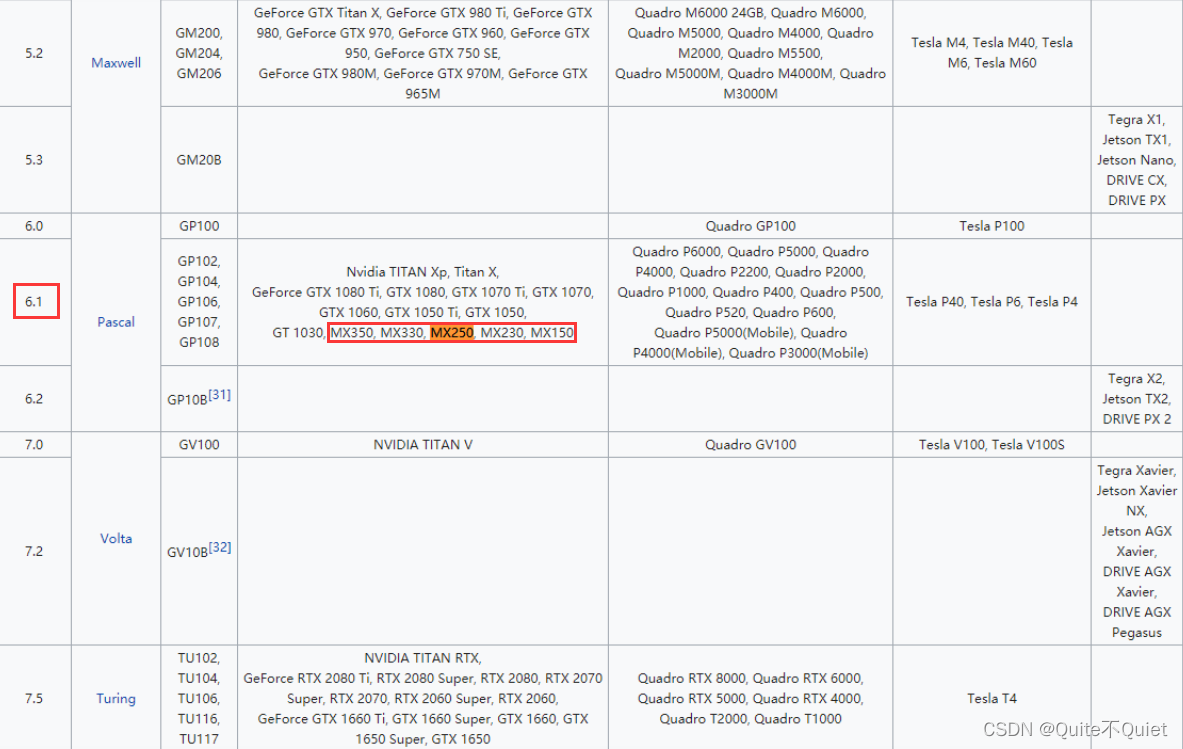
GTX、RTX系,安装TF-GPU版,同理。
Original: https://blog.csdn.net/weixin_53062121/article/details/123418837
Author: Quite不Quiet
Title: Nvidia MX150安装Tensorflow-GPU版,Pycharm使用Keras
相关阅读2
Title: 记录::Opencv调用tensorflow2.x-Keras模型
需要用C++调用tensoeflow模型,但我发现现在的tensorflow2.x的版本都是用keras搭建的,不想用动态库,决定直接用Opencv调用模型。
库版本:
tensorflow 2.2.0
opencv 4.2.0.32
参考:OpenCV使用Tensorflow2-Keras模型_风翼冰舟的博客-CSDN博客_opencv调用keras模型
tensorflow Frozen-Graph-TensorFlow/TensorFlow_v2 at master · leimao/Frozen-Graph-TensorFlow · GitHub
主要保存模型部分
# Convert Keras model to ConcreteFunction
full_model = tf.function(lambda x: model(x))
full_model = full_model.get_concrete_function(
x=tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype))
# Get frozen ConcreteFunction
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
# Save frozen graph from frozen ConcreteFunction to hard drive
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir="./frozen_models",
name="simple_frozen_graph.pb",
as_text=False)
用的github里面的例子1测试
训练模型,用的mnist数据集,下载数据集部分,如果报错(url无效什么的)可以手动下载后放在C:\Users\Administrator.keras\datasets\fashion-mnist 里面
def wrap_frozen_graph(graph_def, inputs, outputs, print_graph=False):
def _imports_graph_def():
tf.compat.v1.import_graph_def(graph_def, name="")
wrapped_import = tf.compat.v1.wrap_function(_imports_graph_def, [])
import_graph = wrapped_import.graph
return wrapped_import.prune(
tf.nest.map_structure(import_graph.as_graph_element, inputs),
tf.nest.map_structure(import_graph.as_graph_element, outputs))
训练以及保存模型
def trainmodel2():
tf.random.set_seed(seed=0)
# Get data
(train_images, train_labels), (test_images,
test_labels) = get_fashion_mnist_data()
# Create Keras model
model = keras.Sequential(layers=[
keras.layers.InputLayer(input_shape=(28, 28), name="input"),
keras.layers.Flatten(input_shape=(28, 28), name="flatten"),
keras.layers.Dense(128, activation="relu", name="dense"),
keras.layers.Dense(10, activation="softmax", name="output")
], name="FCN")
# Print model architecture
model.summary()
# Compile model with optimizer
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])
# Train model
model.fit(x={"input": train_images}, y={"output": train_labels}, epochs=1)
# Save model to SavedModel format
tf.saved_model.save(model, "./frozen_models/simple_model")
#tf.model.save((model, "./frozen_models/simple_model"))
# Convert Keras model to ConcreteFunction
full_model = tf.function(lambda x: model(x))
full_model = full_model.get_concrete_function(
x=tf.TensorSpec(model.inputs[0].shape, model.inputs[0].dtype))
# Get frozen ConcreteFunction
frozen_func = convert_variables_to_constants_v2(full_model)
frozen_func.graph.as_graph_def()
# Save frozen graph from frozen ConcreteFunction to hard drive
tf.io.write_graph(graph_or_graph_def=frozen_func.graph,
logdir="./frozen_models",
name="simple_frozen_graph.pb",
as_text=False)
tensorflow调用测试
def tftest():
# Load frozen graph using TensorFlow 1.x functions
with tf.io.gfile.GFile("./frozen_models/simple_frozen_graph.pb", "rb") as f:
graph_def = tf.compat.v1.GraphDef()
loaded = graph_def.ParseFromString(f.read())
# Wrap frozen graph to ConcreteFunctions
frozen_func = wrap_frozen_graph(graph_def=graph_def,
inputs=["x:0"],
outputs=["Identity:0"],
print_graph=True)
print("-" * 50)
print("Frozen model inputs: ")
print(frozen_func.inputs)
print("Frozen model outputs: ")
print(frozen_func.outputs)
#调用测试
test_x = cv2.imread("1.png",0)
test_x=cv2.resize(test_x,(28,28))
pred_y = frozen_func(x=tf.constant(test_x,dtype=tf.float32))[0]
print(pred_y[0].numpy())
python-opencv调用测试
def opencvtest():
test_x = cv2.imread("1.png",0)
test_x = cv2.dnn.blobFromImage(image=test_x, scalefactor=1.0, size=(28, 28))
net = cv2.dnn.readNetFromTensorflow("./frozen_models/simple_frozen_graph.pb")
net.setInput(test_x)
pred = net.forward()
print(pred)
c++opencv调用测试
int main() {
Mat test_x = imread("1.png", 0);
test_x = cv::dnn::blobFromImage(test_x,1.0,Size(28, 28));
dnn::Net net = cv::dnn::readNetFromTensorflow("simple_frozen_graph.pb");
net.setInput(test_x);
Mat pred = net.forward();
cout << pred << endl;
return 0;
}
更多完整代码参考:
GitHub - ziyaoma/Opencv-Tensorflow2.x: 用opencv调用tensorflow2.x的keras训练的模型
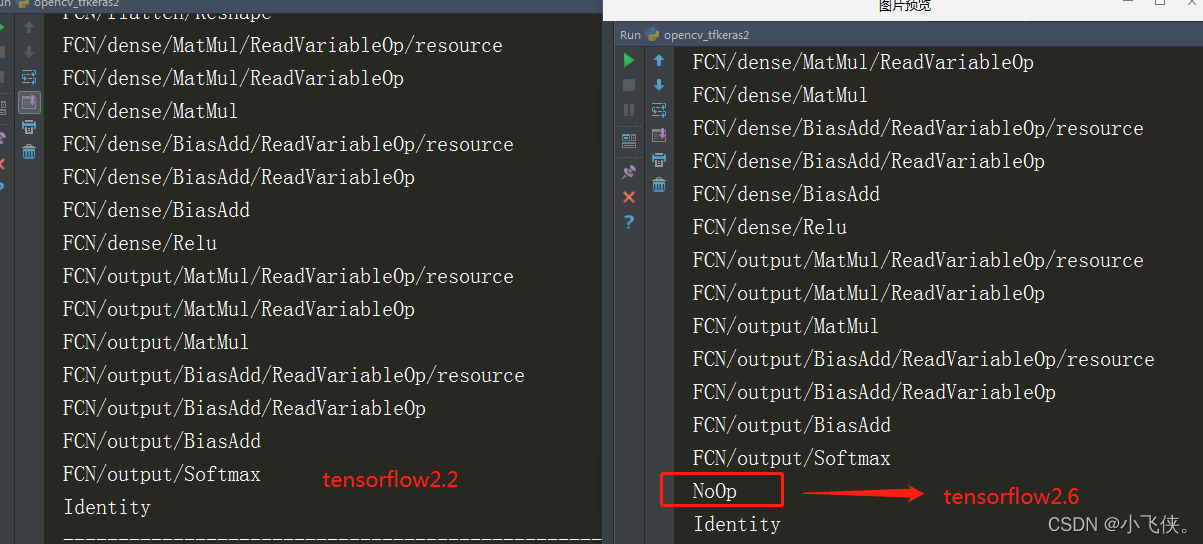
问题:
用tensorflow2.6版本出现opencv调动报错,
error: (-2:Unspecified error) Can't create layer "NoOp" of type "NoOp" in function 'cv::dnn::dnn4_v20191202::LayerData::getLayerInstance'
解决:
估计是版本不匹配吧,降到了2.2就可以了,
对比发现输出多了一层,不知道怎么解决,有知道的大佬求告知
Original: https://blog.csdn.net/qq_40242410/article/details/124337666
Author: 小飞侠。
Title: 记录::Opencv调用tensorflow2.x-Keras模型
相关阅读3
Title: 内存溢出+CPU占用过高:问题排查+解决方案+复盘(超详细分析教程)
内存溢出+CPU占用过高:问题排查+解决方案+复盘(超详细分析教程)
原文地址
https://zhanghan.blog.csdn.net/article/details/109255980
前言
最近刚上线了一款社交项目,运行十多天后(运营持续每天推量),发现问题:
系统OOM(资源不能被释放)导致服务器频繁且长时间FGC导致服务器CPU持续飚高
日志中内存溢出:java.lang.OutOfMemoryError: Java heap space
程序十分卡顿,严重影响用户使用
从以下方面,为大家分享此次问题解决流程
问题出现现象
临时解决方案
复现问题
定位问题发生原因
优化代码
优化后进行压测,上线
复盘
学完本博文,你的收获
排查内存溢出的思路
排查内存溢出过程中用到的命令及工具(Linux命令,Eclipse Memory Anaylzer[MAT])
定位系统内存溢出的代码,并进行优化
此次内存溢出问题复盘
解决方案流程图
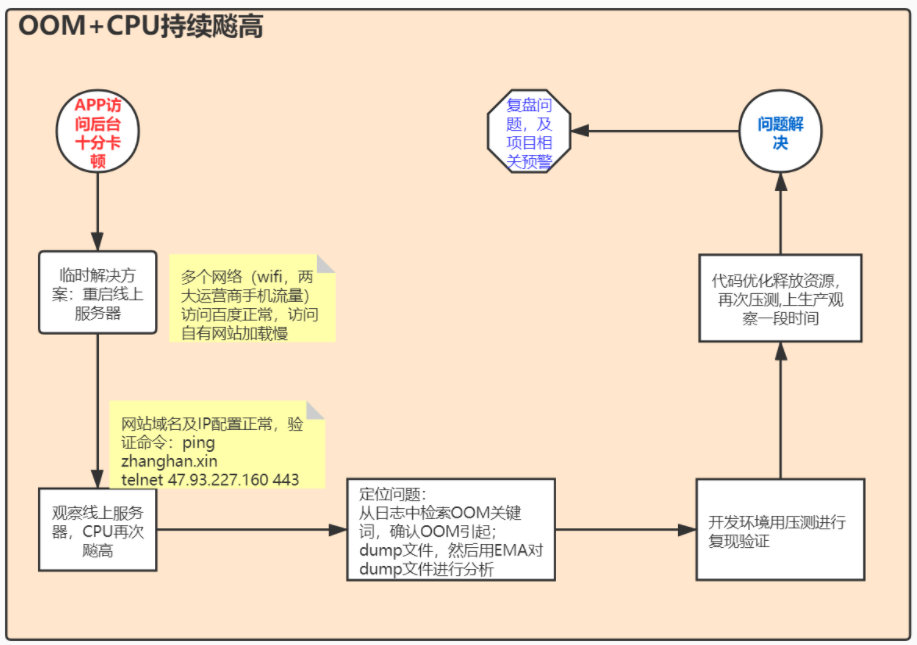
问题&临时解决方案&定位问题&最终解决方案
问题:
业务反馈程序用的十分卡,同时测试自己测的也十分卡
从ELK收集的请求日志发现确实存在问题,线上是两台部署:两台机器上都是,一次请求耗时由原来的几毫秒变为10几秒
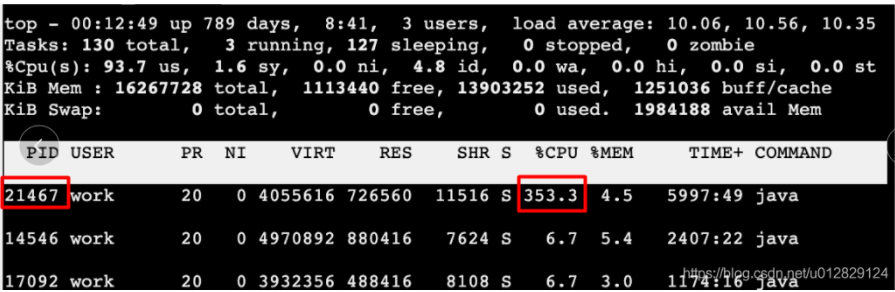
CPU跑的过高,当时是4核,CPU持续飙到350%+;
当时一台服务器CPU截图:
临时解决方案
当时为了减少对业务影响,直接将生产两台服务器上的项目进行重启
项目启动参数中没有加内存溢出日志输出(后续博客为大家介绍JVM调优时讲解启动命令中加内存溢出日志输出),重启后出问题时项目的JVM信息丢失了
复现问题方式:在开发环境对程序进行持续压测;压测相关服务器配置:
服务器配置:8核,16G
项目启动内存:136M
Jmeter持续(循环)压发消息接口10分钟
定位问题
top命令查看最耗CPU的进程(进程:17038;CPU持续飙到595%+)
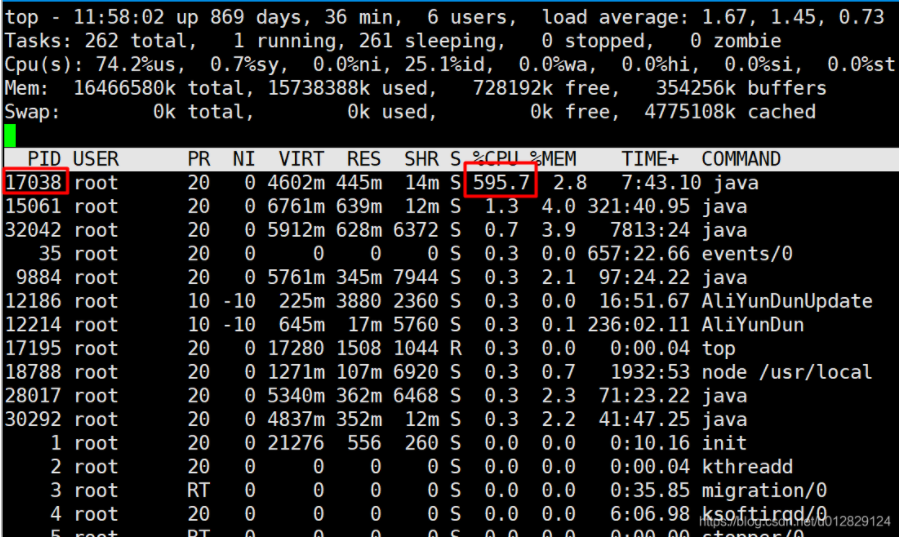
top -H pid号,查看该进程中最耗CPU的线程(发现有一些线程占用CPU较高)
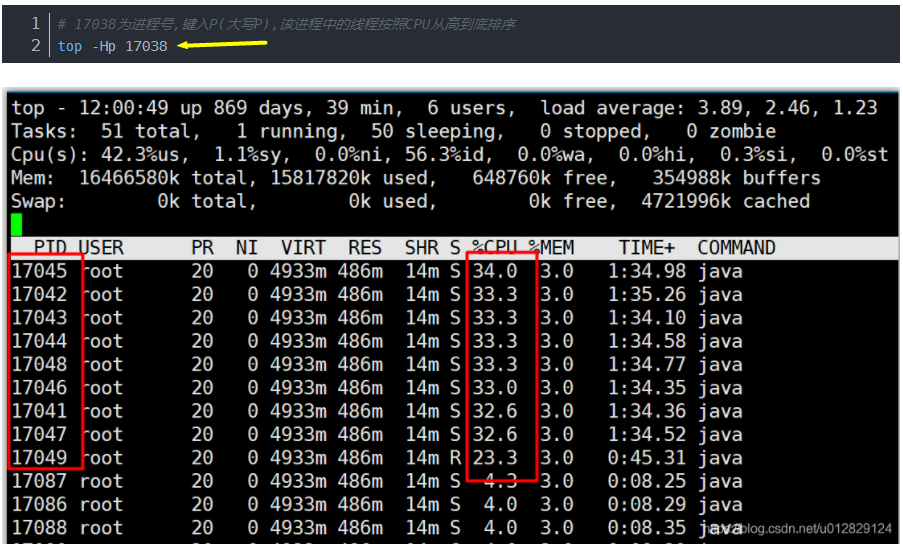
将线程号转为16进制,同时查看这些线程当前正在干什么(在此以17045线程为例)
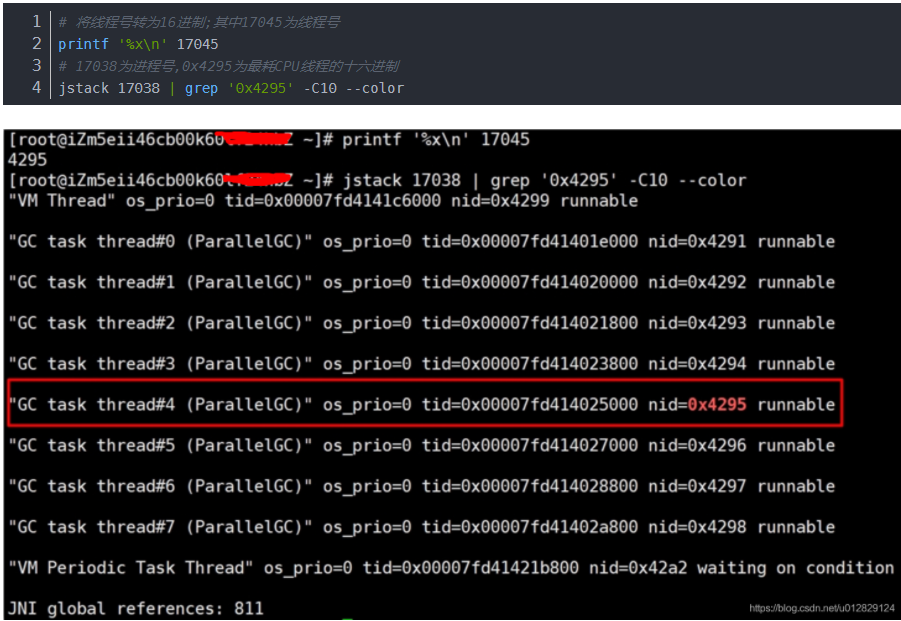
可以看到最耗CPU的线程都是在进行GC
注意:
在FGC的时候会引起STW,所有应用都会短暂暂停,但是此时CPU仍然很忙,因为CPU在忙着进行FGC清理内存
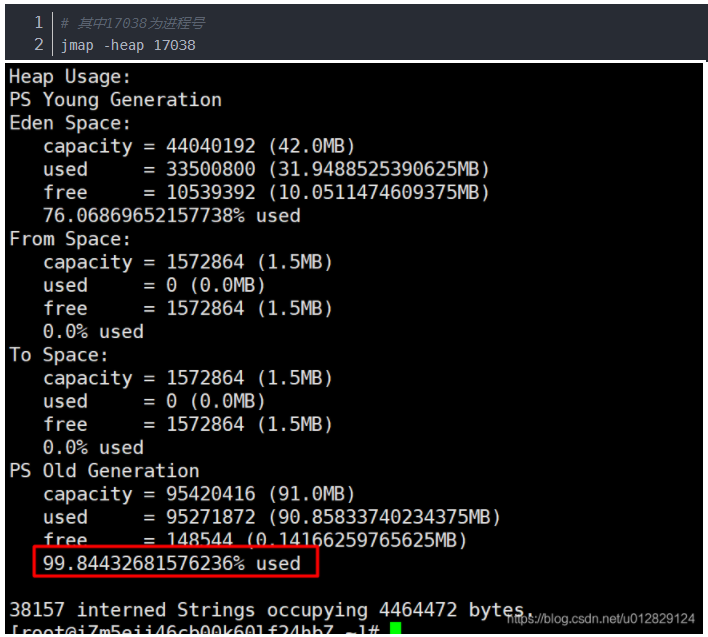
用Jmap命令查看当前堆的使用情况(发现老年代现在已占用99.8%+)
查看gc 频率的命令(其中O代表老年代占用率,FGC是FullGC次数,FGCT是fullGC时间;可以看出在频繁FullGC但是老年代有资源一直释放不掉)
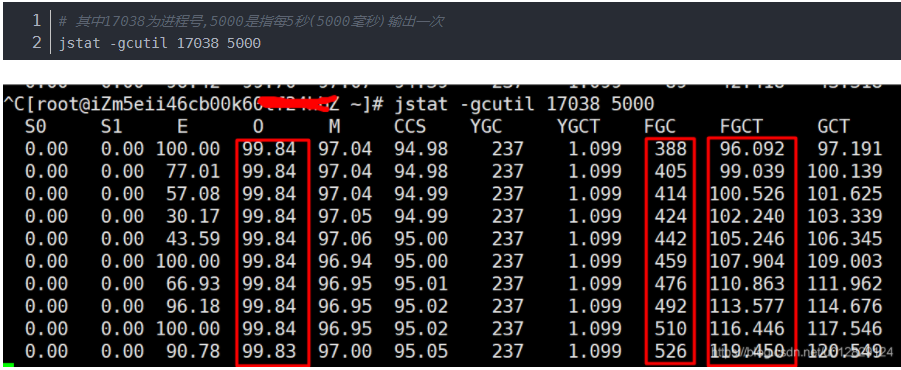
通过分析出问题时线上日志发现内存溢出;至此定位到问题根源是内存溢出导致(有未释放资源堆积,导致老年代被占满,然后频繁的FullGC但是资源一直释放不了)

分析问题产生原因
由于线上当时直接重启,未能保留当时的JVM内存文件;在开发环境进行循环压测,复现线上问题,然后导出dump文件进行分析找到原因
生成dump文件命令
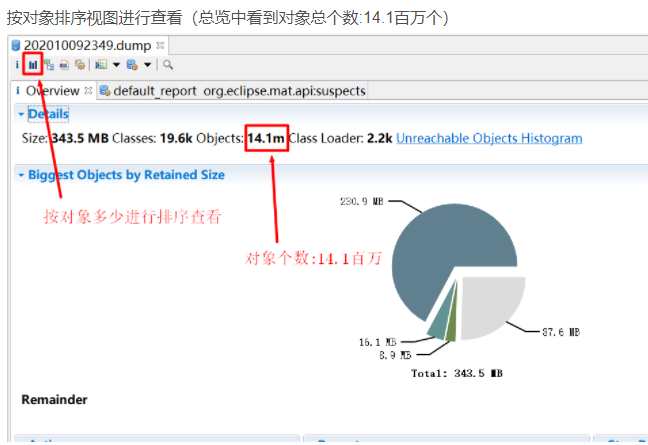
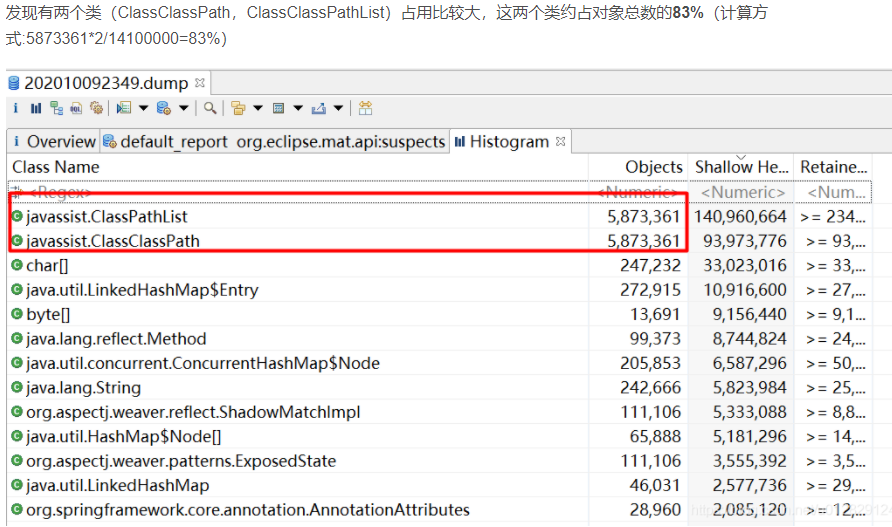
分析代码
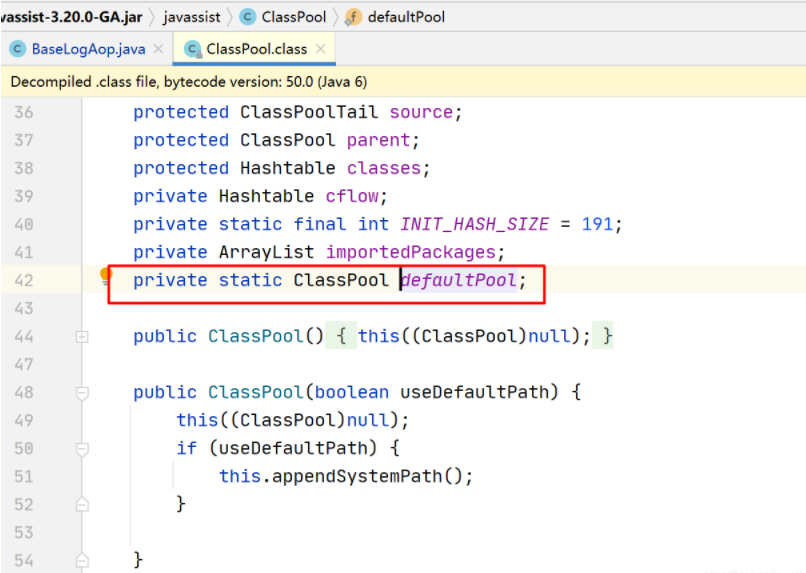
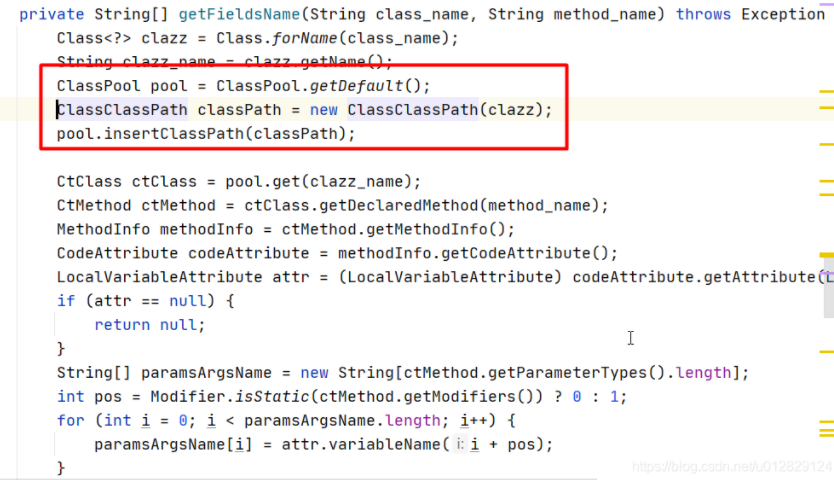
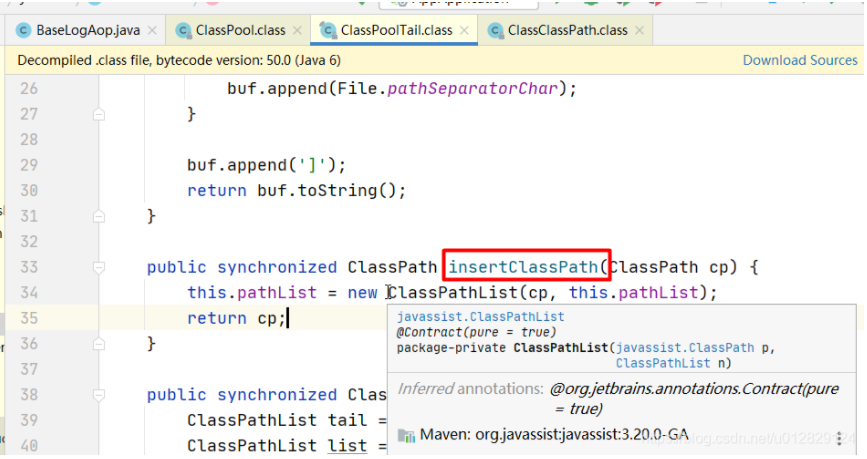
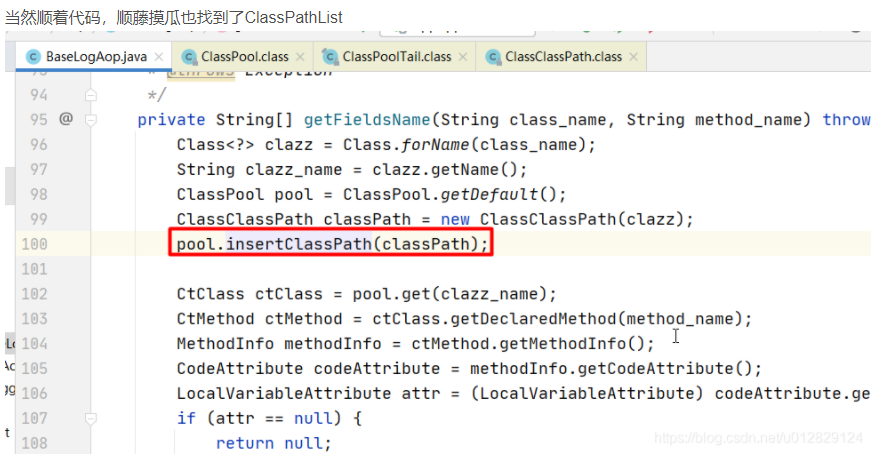
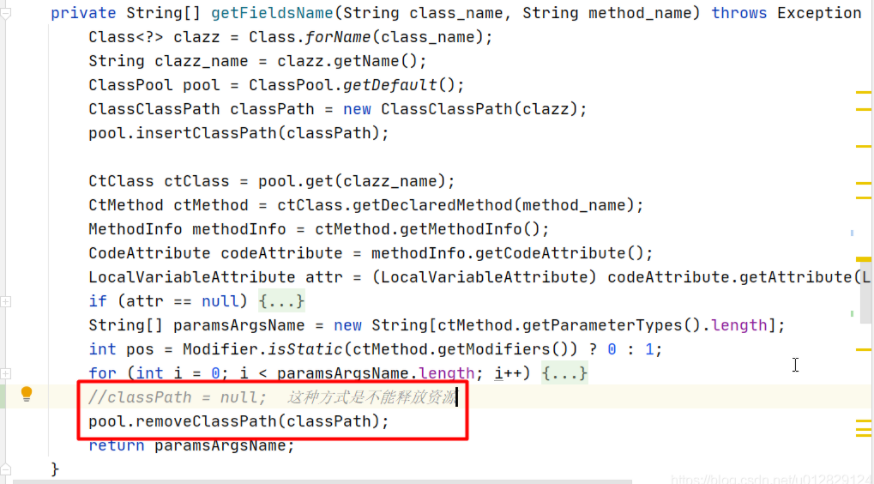
去代码中全局搜这两个类,发现只有在打日志的时候用到ClassClassPath类
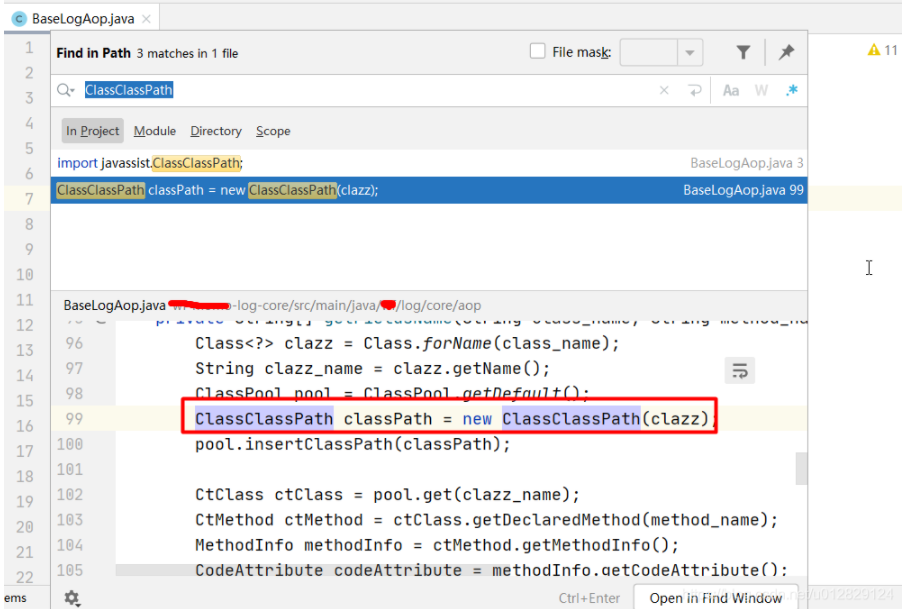
分析ClassClassPath相关代码:
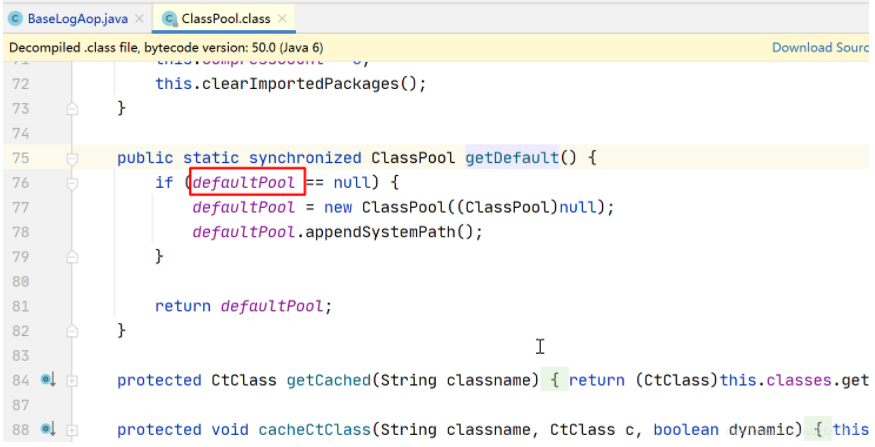
用到ClassClassPath对象是一个静态的ClassPool;
问题原因:classPath一直被静态的全局pool所持有,导致GC一直释放不掉;
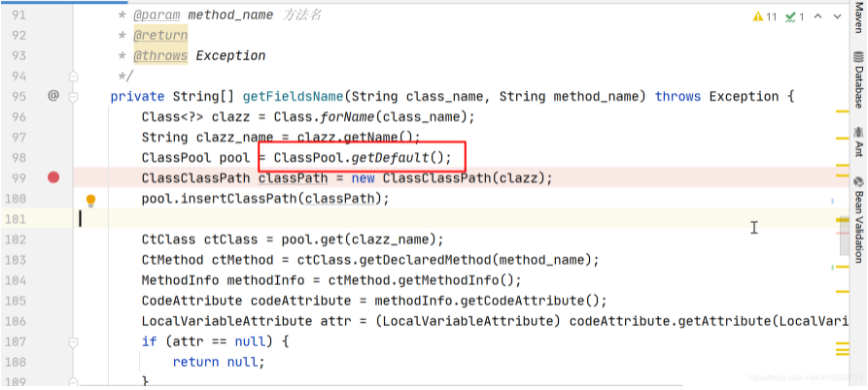
优化代码:每次用完ClassClassPath后将其释放
每次对象使用完后从静态pool中移除
注意:classPath=null这种方式是不能释放掉的
优化后再次进行验证
开发环境循环压测,用MAT分析dump文件,发现内存中已不再堆积ClassClassPath类;优化前后接口吞吐量也提升8.2%
进行线上发布,观察一周后,对内存分析发现正常
复盘:
项目比对:
为快速开发,社交的代码从原来金融项目基础上改造而来;
原来金融项目没有内存溢出,而社交项目为什么内存溢出?
通过ELK统计一段时间的访问量结果:
社交目前日访问后台量65w+
金融项目只有4.5W+
社交和金融项目业务类型不一样,所呈现出的特点也不同
去生产的金融项目中dump内存文件,用MAT工具分析,发现也存在ClassClassPath类堆积释放不掉,只不过由于访问量少,堆积量未占满老年代而已;果断在金融项目迭代时将其优化;
程序预警:为减少业务影响,增加接口耗时的预警(后续博文为大家共享);实现方式:
- 在每次程序处理完进行预警(比如本次请求>阈值);缺点:消耗性能影响正常业务
- 在ELK清洗时用相关插件进行预警;优点:和业务解耦,对业务无影响
服务器预警:运维增加CPU内存,日志内存溢出监控
总结
解决内存溢出过程总结:
不同的项目导致内存溢出原因是不同的;
重要的是排查思路
经过不断的耐心的去观察,测试,分析才能定位到问题并最终解决问题
在这次分析内存溢出过程中,我们也针对我们项目的JVM启动参数进行了调优,在接下来的博文中为大家分享JVM调优
注意:
1,在FGC的时候会引起STW,所有应用都会短暂暂停,但是此时CPU仍然很忙,因为CPU在忙着进行FGC清理内存
2,使用jvisualvm来分析dump文件:
jvisualvm是JDK自带的Java性能分析工具,在JDK的bin目录下,文件名就叫jvisualvm.exe。
jvisualvm可以监控本地、远程的java进程,实时查看进程的cpu、堆、线程等参数,对java进程生成dump文件,并对dump文件进行分析。
原文地址
https://zhanghan.blog.csdn.net/article/details/109255980
Original: https://www.cnblogs.com/111testing/p/15847604.html
Author: 清风软件测试
Title: 内存溢出+CPU占用过高:问题排查+解决方案+复盘(超详细分析教程)