
很久以前科学家做过一个生物实验,发现视觉神经元同样可以被训练来作听觉神经元之用。受此启发,不少计算机研究者也在寻找着机器学习领域的大一统–将CV任务和NLP任务使用相同或者类似的结构进行建模。
随着transformer在nlp领域已经杀出了一片天,便有研究者想用它来进军cv领域。Vit,vision transformer正是在此道路上跨出的一大步。
transformer是世界上最好的结构!(误)
VIT整体结构

论文中的结构图还是十分简单易懂的,相信如果之前接触过Transformer系列,那么看懂这张图不是难事。
首先和在nlp领域中的应用一大不同,就是VIT只有encoder编码层,没有decoder。第二个不同可能就是输入从字符变成了切碎的图片。
其他的embedding(也就是linear projection)和position embedding,muti-head attention基本都是熟悉的配方。
; 输入转换
首先看输入,不同于cnn中滑动窗口式的卷积,VIT中直接采用了non-overlapping的分割方式,将一张图片分割成很多个大小一致的 patches。
transformer系列的输入都很有意思。即使patches在一开始的时候是一个个图片块,也就是矩阵,最后为了向nlp中的 词向量的表示看齐,都会被拉成条(flatten)。
即使图片有3通道,这三个通道也要被拉平后拼接。如下公式。
H × W × C → N × ( P 2 C ) H \times W \times C \rightarrow N \times (P^{2} C)H ×W ×C →N ×(P 2 C )
其中H,W,C分别是图片的高,宽,通道。N是patches的总数,( P , P ) (P,P)(P ,P )是patches的大小。
这个公式的意思就是每个三维的图片块最后都被拉成一条了。
之后经过linear projection层进行映射,就得到了一个N × D N \times D N ×D大小的输入,同样,此处省略了batchsize。
位置编码
NLP中的位置编码用来记住词语的上下文关系,VIT中的位置编码同样也是为了记住图片之间的相对位置关系。
值得一提的是,VIT中仿照BERT的做法,加了一个classification patch,作为额外的输入。其大小为1 × D 1\times D 1 ×D,和经过了linear projection的patch大小一致。这个patch加在了最前头。所以最终进入位置编码实际上有N + 1 N+1 N +1个patches。
论文中使用的是可学习的一维位置编码,其实就是初始化了一个可学习的随机变量,加到了原本的输入上。
attention
VIT的encoder基本可以说是完全照搬了NLP中encoder的结构了,堆叠了很多层,每层执行一次多头注意力机制。
MLP其实也只是换了一个名字,所做的也是先升维再降维。
具体的可以看我的上一篇文章,里面有注意力机制的详解。
【Transformer学习笔记】Transformer开山之作: Attention is All you Need
如果把每层都看作一个黑盒子,其实encoder做的就是信息的融合,把每个patches的表示和其他所有patches进行融合,达到全局视野的效果。每层的输入和输出大小不变。
分类头

最后面的classification层中,并没有取所有的patches作为输入,因为在多头注意力机制中,每个patch其实都已经融合了所有的patches的信息,因此此处只取了一个,也就是前面提到的classification patch映射到物体种类数量进行分类。
; 总结
VIT将transformer引入了CV领域,并且对比现有的CNN方法,也在各类数据集上取得了不错的成果。
但是VIT只在分类work的比较好,因为它虽然有全局性,但是图片的平移不变形和尺度不变形它基本就没办了。
此外,它的计算复杂度也是比较惊人的,因为它的编码是像素级的,所以计算量会随着图片大小二次方地增长。
Original: https://blog.csdn.net/sjflsahfisaojfsa/article/details/121870005
Author: 不想写代码不想秃头
Title: 【Transformer学习笔记】VIT解析
相关阅读1
Title: win11+RTX3060搭建tensorflow深度学习环境
cuda简介:
CUDA是NVIDIA发明的一种并行计算平台和编程模型。
它可以通过利用图形处理器(GPU)的能力来显著提高计算性能。
CUDA的开发有以下几个设计目标:
1.为标准编程语言(如C)提供一小组扩展,以实现并行算法的直接实现。
2.使用CUDA C/ c++,程序员可以专注于算法的并行化,而不是把时间花在算法的实现上。
3.支持异构计算,应用同时使用CPU和GPU。
应用程序的串行部分运行在CPU上,并行部分被卸载到GPU上,
这样CUDA就可以增量地应用到现有的应用程序上。
CPU和GPU被视为具有各自内存空间的独立设备。
这种配置还允许在CPU和GPU上进行同步计算,而无需争夺内存资源。
cuda支持的GPU有数百个内核,这些内核可以同时运行数千个计算线程。
这些核心拥有共享的资源,包括一个寄存器文件和一个共享的内存。
片上共享内存允许运行在这些核心上的并行任务共享数据,而无需通过系统内存总线发送数据
安装步骤:双击一直下一步就行
测试:打开cmd,执行命令 nvcc -V和 nvidia-sim 查看对应信息
cudnn简介:
1.cuDNN 8 的新功能
cuDNN 8 针对 A100 GPU 进行了优化,可提供高达 V100 GPU 5 倍的开箱即用性能,并且包含适用于对话式 AI 和计算机视觉等应用的新优化和 API。
它已经过重新设计,可实现易用性和应用集成,同时还能为开发者提供更高的灵活性。
2.cuDNN 8 的亮点包括
已针对 NVIDIA A100 GPU 上的峰值性能进行调优,包括全新 TensorFloat-32、FP16 和 FP32
通过重新设计的低级别 API,可以直接访问 cuDNN 内核,从而实现更出色的控制和性能调优
向后兼容性层仍然支持 cuDNN 7.x,使开发者能够顺利过渡到新版 cuDNN 8 API
针对计算机视觉、语音和语言理解网络作出了新优化
已通过新 API 融合运算符,进而加速卷积神经网络
cuDNN 8 现以六个较小的库的形式提供,能够更精细地集成到应用中。开发者可以下载 cuDNN,也可从 NGC 上的框架容器中将其提取出来。
3.主要特性
3.1 为所有常用卷积实现了 Tensor Core 加速,包括 2D 卷积、3D 卷积、分组卷积、深度可分离卷积以及包含 NHWC 和 NCHW 输入及输出的扩张卷积
3.2 为诸多计算机视觉和语音模型优化了内核,包括 ResNet、ResNext、SSD、MaskRCNN、Unet、VNet、BERT、GPT-2、Tacotron2 和 WaveGlow
3.3 支持 FP32、FP16 和 TF32 浮点格式以及 INT8 和 UINT8 整数格式
3.4 4D 张量的任意维排序、跨步和子区域意味着可轻松集成到任意神经网络实现中能为任意 CNN 架构上融合的运算提速
3.5 数据中心采用 Ampere、Turing、Volta、Pascal、Maxwell 和 Kepler GPU 架构以及配备移动 GPU 的 Windows 和 Linux 支持 cuDNN。
安装:解压后将各文件夹下的文件复制到cuda安装路径下的对应文件夹里
# 相关配置
# conda配置国内清华源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
# 显示下载源
conda config --set show_channel_urls yes
# 查看conda的配置
conda config --show
# pip配置国内清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 创建并激活环境
conda create tf2_6 python=3.9
conda activate tf2_6
# 安装tf-gpu-2.6.2
pip install tensorflow-gpu==2.6.2
import tensorflow as tf
print(tf.__version__) #2.6.2
print(tf.test.is_gpu_available()) # 为True表示安装成功
注意:目前没有手动配置环境变量,如果后续代码有问题可能需要配一下
https://blog.csdn.net/qq_33534428/article/details/125337424?spm=1001.2014.3001.5502
- https://cloud.tencent.com/developer/article/1914694
- https://tensorflow.google.cn/install/gpu
- https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/
- https://docs.microsoft.com/en-us/windows/ai/directml/gpu-accelerated-training
Original: https://blog.csdn.net/qq_33534428/article/details/122235888
Author: 凌陨心
Title: win11+RTX3060搭建tensorflow深度学习环境
相关阅读2
Title: 机器学习各种小问题
1 机器学习相关安装问题
1.1 pytorch安装慢问题
- 问题描述
要安装pytorch包时,因为包源在国外,所以下载很缓慢,甚至出现直接卡死的情况,下面就是快速安装pytorch等包的方法 - 解决方法
(1)安装anaconda,它可以配置多个python环境,方便以后使用,如切换环境等。
进入官网https://www.anaconda.com/,对应操作系统下载即可。
(2)然后创建一个自己的环境,使用命令conda create -n 你的环境名字 python=你想要安装的python版本即可。
eg:conda create -n jayden python=3.7
(3)conda配置国内的镜像操作(关键的一步)
首先在conda的config文件中添加镜像地址源。在命令行中添加如下代码
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/menpo/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/fastai/
然后让conda使用这些镜像,为了确认是从哪里下载的,设置搜索时显示通道地址,执行下面命令
conda config --set show_channel_urls yes
(4)在进入pytorch官网https://pytorch.org/后,将安装推荐代码最后的 -c pytorch去掉,如果不去掉,它就会去conda国外官网去下载,配置的国内镜像没有被使用。

(5)执行代码查看安装计划,里面有对应安装的源地址,结果发现安装都是从国内镜像安装的,至此成功!


; 1.2 conda安装失败并且显示An unexpected error has occurred. Conda has prepared the above report.
(1)原因1:由于一开始安装的时候发生了错误,但是由于缓存一直没有解决,所以导致运行后面的conda命令失败
- 解决方法
在你的环境下使用以下代码:
conda clean -i
(2)在配置了国内源镜像地址之后发生了某些错误
- 解决方法
将所有的镜像地址去掉即可
conda config --remove-key channels
补充:查看conda配置的镜像源
conda config --show channels
2 预处理各种小问题
2.1 读取文件显示Non-UTF-8 code starting with '\xe8' in file
2.2 或者出现UnicodeDecodeError: 'gbk' codec can't decode byte 0x93 in position 6325: illegal multibyte sequence
- 解决方法
在程序的开头加上如下代码即可:
2.2 运行多线程的程序时异常
- 问题描述:运行程序后显示如下错误
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
- 原因:因为没有在main函数中写,所以程序没法给你生成多线程程序
- 解决方法:在有多线程运行的地方用main方法运行即可
if __name__=='__main__':
Original: https://blog.csdn.net/qq_34516746/article/details/124044363
Author: jaydenStyle
Title: 机器学习各种小问题
相关阅读3
Title: 小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现
上一章我们聊了聊通过一致性正则的半监督方案,使用大量的未标注样本来提升小样本模型的泛化能力。这一章我们结合FGSM,FGM,VAT看下如何使用对抗训练,以及对抗训练结合半监督来提升模型的鲁棒性。本章我们会混着CV和NLP一起来说,VAT的两篇是CV领域的论文,而FGM是CV迁移到NLP的实现方案,一作都是同一位作者大大。FGM的tensorflow实现详见Github-SimpleClassification
我们会集中讨论3个问题
- 对抗样本为何存在
- 对抗训练实现方案
- 对抗训练为何有效
存在性

对抗训练
下面我们看下如何在模型训练过程中引入对抗样本,并训练模型给出正确的预测
监督任务
这里的对抗训练和GAN这类生成对抗训练不同,这里的对抗主要指微小扰动,在CV领域可以简单解释为肉眼不可见的轻微扰动(如下图)

不过两类对抗训练的原理都可以被经典的min-max公式涵盖
- max:对抗的部分通过计算delta来最大化损失
- min:训练部分针对扰动后的输入进行训练最小化损失函数
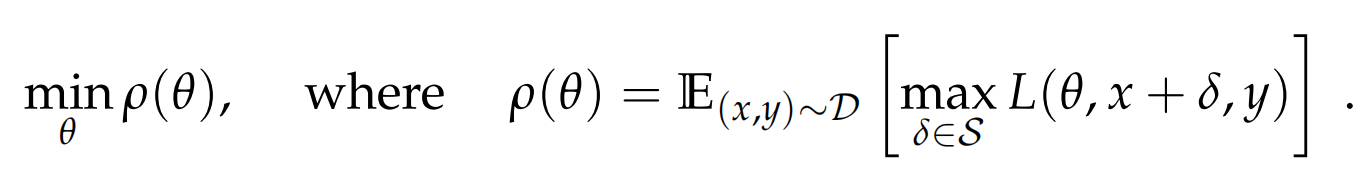
以上损失函数的视角,也可以切换成成极大似然估计的视角,也就是FGM中如下的公式,通过计算r,来使得扰动后y的条件概率最小化

于是问题就被简化成了如何计算扰动。最简单的方案就是和梯度下降相同沿用当前位置的一阶导数,梯度下降是沿graident去最小化损失,那沿反方向进行扰动不就可以最大化损失函数。不过因为梯度本身是对当前位置拟合曲线的线性化,所以需要控制步长来保证局部的线性,反向传播中我们用learning rate来控制步长,这里则需要控制扰动的大小。同时对抗扰动本身也需要控制扰动的幅度,不然就不符合微小扰动这个前提,放到NLP可以理解为为了防止扰动造成语义本身产生变化。
FGSM使用了(l_{\infty}) norm来对梯度进行正则化,只保留了方向信息丢弃了gradient各个维度上的scale

而FGM中作者选择了l2 norm来对梯度进行正则化,在梯度上更多了更多的信息,不过感觉在模型初始拟合的过程中也可能引入更多的噪音。
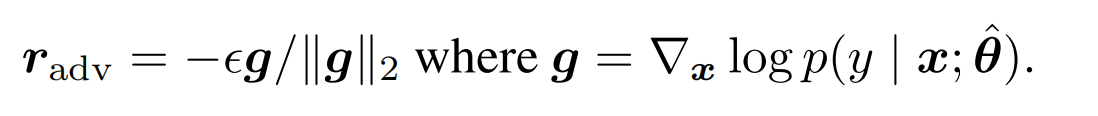
有了对抗样本,下一步就是如何让模型对扰动后的样本给出正确的分类结果。所以最简单的训练方式就是结合监督loss,和施加扰动之后的loss。FGSM中作者简单用0.5的权重来做融合。所以模型训练的方式是样本向前传递计算Loss,冻结梯度,计算扰动,对样本施加扰动再计算Loss,两个loss加权计算梯度。不过部分实现也有只保留对抗loss的操作,不妨作为超参对不同任务进行调整~
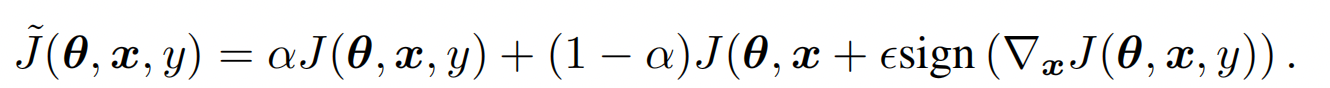
在使用对抗扰动时有两个需要注意的点
- 施加扰动的位置: 对输入层扰动更合理
- 扰动和扰动层的scale: 扰动层归一化
对于CV任务扰动位置有3个选择,输入层,隐藏层,或者输出层,对于NLP任务因为输入离散,所以输入层被替换成look up之后的embedding层。
作者基于万能逼近定理【简单说就是一个线性层+隐藏层如果有unit足够多可以逼近Rn上的任意函数0】指出因为输出层本身不满足万能逼近定理条件,所以对输出层(linear-softmax layer)扰动一般会导致模型underfit,因为模型会没有足够的能力来学习如何抵抗扰动。
而对于激活函数范围在[-inf, inf]的隐藏层进行扰动,会导致模型通过放大隐藏层scale来忽略扰动的影响。
因此一般是对输入层进行扰动,在下面FGM的实现中作者对word embedding进行归一化来规避上面scale的问题。不过这里有一个疑问就是对BERT这类预训练模型是不能对输入向量进行归一化的,那么如何保证BERT在微调的过程中不会通过放大输入层来规避扰动呢?后来想到的一个点是在探测Bert Finetune对向量空间的影响中提到的,微调对BERT各个层的影响是越接近底层影响越小的,所以从这个角度来说也是针对输入层做扰动更合理些~
半监督任务
以上的对抗训练只适用于标注样本,因为需要通过loss来计算梯度方向,而未标注样本无法计算loss,最简单的方案就是用模型预估来替代真实label。于是最大化loss的扰动,变成使得预测分布变化最大的扰动。
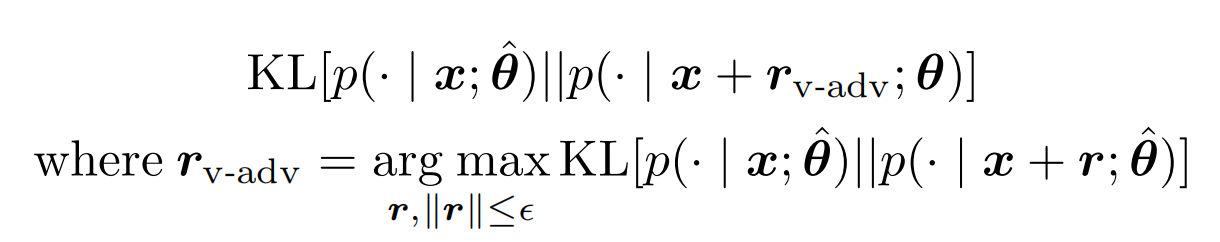
以上的虚拟扰动r无法直接计算,于是泰勒展开再次登场,不过这里因为把y替换成了模型预估p,所以一阶导数为0,于是最大化KL近似为最大化二阶导数的部分
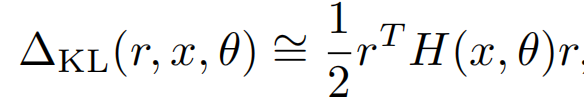
而以上r的求解,其实就是求解二阶海森矩阵的最大特征值对应的特征向量,以下u就是最大特征值对应的单位特征向量
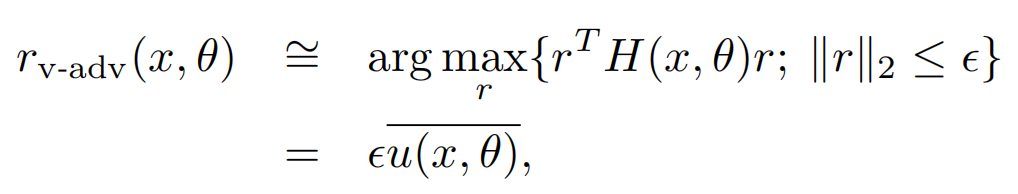
因为海森矩阵的计算复杂度较高,一般会采用迭代近似的方式来计算(详见REF12),简单说就是随机向量d(和u非正交),通过反复的下述迭代会趋近于u
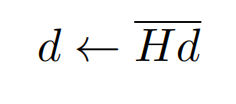
而以上Hd同样可以被近似计算,因为上面KL的一阶导数为0,所以我们可以用KL~rHr的一阶差分来估计Hd,于是也就得了d的近似值

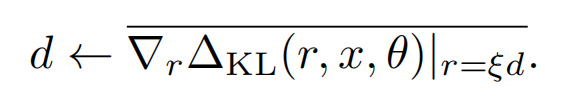
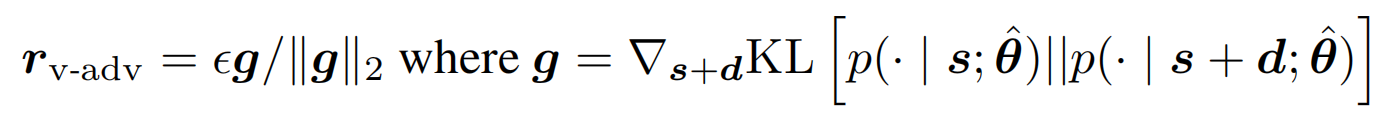
哈哈近似了一圈估计有的盆友们已经蒙圈了,可以对照着下面的计算方案再回来理解下上面的公式,计算虚拟扰动的算法如下(其中1~4可以多次迭代)
- 对embedding层施加随机扰动d
- 向前传递计算扰动后的logit
- 扰动logit和原始logit计算KL距离
- 对KL计算梯度
- 对梯度做归一化得到虚拟扰动的近似
- 对embedding层施加虚拟扰动,再计算一遍KL作为虚拟对抗部分的loss
这里暂时没有实现VAT因为时间复杂度有些高,之后有需要再补上VAT的部分
合理性
对抗扰动可以理解为一种正则方案,核心是为了提高模型鲁棒性,也就是样本外的泛化能力,这里给出两个视角
- 对比L1正则

- 对比一致性正则
这里和上一章我们提到的半监督之一致性正则有着相通之处,一致性正则强调模型应该对轻微扰动的样本给出一致的预测,但并没有对扰动本身进行太多的探讨,而对抗训练的核心在于如何对样本进行扰动。但核心都是扩充标注样本的覆盖范围,让标注样本的近邻拥有一致的模型预测。
效果
FGM论文是在LSTM,Bi-LSTM上做的测试会有比较明显的2%左右ErrorRate的下降。我在BERT上加入FGM在几个测试集上尝试指标效果并不明显,不过这里开源数据上测试集和训练集相似度比较高,而FGM更多是对样本外的泛化能力的提升。不过我在公司数据上使用FMG输出的预测概率的置信度会显著下降,一般bert微调会容易得到0.999这类高置信度预测,而加入FGM之后prob的分布变得更加合理,这个效果更容易用正则来进行解释。以下也给出了两个比赛方案链接里面都是用fgm做了优化也有一些insights,感兴趣的朋友可能在你的测试集上也实验下~
不过一言以蔽之,FGM的对抗方案,主要通过正则来约束模型学习,更多是锦上添花,想要学中送碳建议盆友们脚踏实地的去优化样本,优化标注,以及确认你的任务目标定义是否合理~
Reference
- FGSM- Explaining and Harnessing Adversarial Examples, ICLR2015
- FGM-Adversarial Training Methods for Semi-Supervised Text Classification, ICLR2017
- VAT-Virtual adversarial training: a regularization method for supervised and semi-supervised learning
- VAT-Distributional Smoothing with Virtual Adversarial Training
- Min-Max公式 Towards Deep Learning Models Resistant to Adversarial Attacks
- FGM-TF实现
- VAT-TF实现
- NLP中的对抗训练
- 苏神yyds:对抗训练浅谈:意义、方法和思考(附Keras实现)
- 天池大赛疫情文本挑战赛线上第三名方案分享
- 基于同音同形纠错的问题等价性判别第二名方案
- Eigenvalue computation in the 20th century
Original: https://www.cnblogs.com/gogoSandy/p/16419026.html
Author: 风雨中的小七
Title: 小样本利器2.文本对抗+半监督 FGSM & VAT & FGM代码实现