
简单而强大的NLP框架,在5分钟内为命名实体识别(NER)、词性标注(PoS)和文本分类任务构建最新模型
喀什是:
- 人性化。喀什噶尔的代码是直截了当的,有很好的文档和测试,这使得它非常容易理解和修改。
- 功能强大且简单。喀什允许您将最先进的自然语言处理(nlp)模型应用于文本,如命名实体识别(ner)、词性标注(pos)和分类。
- keras基础。Kashgare直接构建在Keras上,使您可以轻松地训练模型,并使用不同的嵌入和模型结构尝试新方法。
- 易于微调。Kashgare构建了预先训练的Bert和Word2Vec嵌入模型,这使得基于此嵌入对模型进行微调变得非常简单。
- 完全可伸缩。喀什为快速实验提供了一个简单、快速、可扩展的环境。
功能列表
- 嵌入式支架
- 经典word2vec嵌入
- 伯特嵌入
- gpt-2嵌入
- 序列(文本)分类模型
- cnnmodel
- blstm模型
- cnnlstm模型
- avcnnmodel
- KMaxnn模型
- RCNN模型
- avrnnmodel
- dropoutbrumodel
- 删除avrnnmodel
- 序列(文本)标签模型(NER、POS)
- cnnlstm模型
- blstm模型
- BLSTMCRFModel
- 模特训练
- 模型评估
- GPU支持/多GPU支持
- 定制型号
TaskLanguageDatasetScoreDetailNamed Entity RecognitionChinesePeople's Daily Ner Corpus
(F1)
路线图
下面是一组快速教程,帮助您开始使用库:
还有一些文章和帖子说明了如何使用喀什喀里:
快速启动
该项目基于Keras 2.2.0+和Python 3.6+,因为现在是2019年,类型提示很酷
pip install kashgari
CPU
pip install tensorflow==1.12.0
GPU
pip install tensorflow-gpu==1.12.0
>>>fromkashgari.corpusimportSMP2017ECDTClassificationCorpus>>>fromkashgari.tasks.classificationimportCNNLSTMModel>>>x_data,y_data=SMP2017ECDTClassificationCorpus.get_classification_data()>>>x_data[0]['你','知','道','我','几','岁']>>>y_data[0]'chat'# provided classification models `CNNModel`, `BLSTMModel`, `CNNLSTMModel` >>>classifier=CNNLSTMModel()>>>classifier.fit(x_data,y_data)_________________________________________________________________Layer(type)OutputShapeParam# =================================================================input_1(InputLayer)(None,10)0_________________________________________________________________embedding_1(Embedding)(None,10,100)87500_________________________________________________________________conv1d_1(Conv1D)(None,10,32)9632_________________________________________________________________max_pooling1d_1(MaxPooling1(None,5,32)0_________________________________________________________________lstm_1(LSTM)(None,100)53200_________________________________________________________________dense_1(Dense)(None,32)3232=================================================================Totalparams:153,564Trainableparams:153,564Non-trainableparams:0_________________________________________________________________Epoch1/51/35[..............................]-ETA:32s-loss:3.4652-acc:0.0469...>>>x_test,y_test=SMP2017ECDTClassificationCorpus.get_classification_data('test')>>>classifier.evaluate(x_test,y_test)precisionrecallf1-scoresupportcalc0.750.750.758chat0.830.860.85154contacts0.540.700.6110cookbook0.970.940.9589datetime0.670.670.676email1.000.880.938epg0.610.560.5836flight1.000.900.9521...
fromkashgari.embeddingsimportGPT2Embeddingfromkashgari.tasks.classificationimportCNNLSTMModelfromkashgari.corpusimportSMP2017ECDTClassificationCorpusgpt2_embedding=GPT2Embedding('',sequence_length=30)model=CNNLSTMModel(gpt2_embedding)train_x,train_y=SMP2017ECDTClassificationCorpus.get_classification_data()model.fit(train_x,train_y)
fromkashgari.embeddingsimportBERTEmbeddingfromkashgari.tasks.classificationimportCNNLSTMModelfromkashgari.corpusimportSMP2017ECDTClassificationCorpusbert_embedding=BERTEmbedding('',sequence_length=30)model=CNNLSTMModel(bert_embedding)train_x,train_y=SMP2017ECDTClassificationCorpus.get_classification_data()model.fit(train_x,train_y)
fromkashgari.embeddingsimportWordEmbeddingsfromkashgari.tasks.classificationimportCNNLSTMModelfromkashgari.corpusimportSMP2017ECDTClassificationCorpusbert_embedding=WordEmbeddings('sgns.weibo.bigram',sequence_length=30)model=CNNLSTMModel(bert_embedding)train_x,train_y=SMP2017ECDTClassificationCorpus.get_classification_data()model.fit(train_x,train_y)
fromkashgari.embeddingsimportBERTEmbeddingfromkashgari.tasks.classificationimportCNNLSTMModeltrain_x,train_y=prepare_your_classification_data()# build model with embeddingbert_embedding=BERTEmbedding('bert-large-cased',sequence_length=128)model=CNNLSTMModel(bert_embedding)# or without pre-trained embeddingmodel=CNNLSTMModel()# Build model with your corpusmodel.build_model(train_x,train_y)# Add multi gpu supportmodel.build_multi_gpu_model(gpus=8)# Train, 256 / 8 = 32 samples for every GPU per batchmodel.fit(train_x,train_y,batch_size=256)
这个图书馆受到以下框架和论文的启发和参考。
Original: https://blog.csdn.net/javastart/article/details/122222867
Author: javastart
Title: kashgari的Python项目-NLP框架(实体识别(NER)、词性标注(PoS)和文本分类任务)
相关阅读1
Title: 瑞芯微rv1126+yolov3模型转换
环境版本dockerrknn-toolkit-1.7.1-docker.tar.gz
1.安装 Docker
请根据官方手册安装 Docker(https://docs.docker.com/install/linux/docker-ce/ubuntu/)。
2. 加载镜像
执行以下命令加载镜像:
docker load --input rknn-toolkit-lite-1.7.1-docker.tar.gz
加载成功后,执行"docker images"命令能够看到 rknn-toolkit-lite 的镜像,如下所示:
REPOSITORY TAG IMAGE ID CREATED SIZE
rknn-toolkit-lite 1.7.1 0f3af4fe47c3 1 hours ago 1.31GB
3、 运行镜像
执行以下命令运行 docker 镜像,运行后将进入镜像的 bash 环境。
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb rknn-toolkit:1.7.1 /bin/bash
如果想将自己代码映射进去可以加上"-v :"参数,例如:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/rk/test:/test rknn-toolkit-
lite:1.7.1 /bin/bash
1.下载yolov3_demo,进入yolov3_demo目录,并从darknet官网下载权重
cd yolov3_demo
wget https://pjreddie.com/media/files/yolov3-tiny.weights
wget https://pjreddie.com/media/files/yolov3.weights
2.根据目标板卡修改
修改rknn_transform_416x416.py文件中配置文件,增加目标板target_platform=['rv1126']
代码如下(示例):
from PIL import Image
import numpy as np
#from matplotlib import pyplot as plt
import re
import math
import random
from rknn.api import RKNN
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN()
# Load tensorflow model
print('--> Loading model')
rknn.load_darknet(model='./yolov3_416x416.cfg', weight="./yolov3.weights")
print('done')
rknn.config(channel_mean_value='0 0 0 255', reorder_channel='0 1 2', batch_size=1, target_platform=['rv1126'])
# Build model
print('--> Building model')
rknn.build(do_quantization=True, dataset='./dataset_416x416.txt', pre_compile=True)
print('done')
rknn.export_rknn('./yolov3_416x416.rknn')
exit(0)
3.运行文件生成模型文件yolov3_416x416.rknn
python rknn_transform_416x416.py
在虚拟机中运行docker转换时出现内存不足的情况,后面直接在ubuntu系统中调用docker转换成功,特别要注意设置target_platform=['rv1126'],默认目标板为RK1808,不然目标板卡无法调用,单帧推理+后处理耗时250ms左右。
Original: https://blog.csdn.net/ZuoSeDiao/article/details/123394969
Author: 得一宝贝
Title: 瑞芯微rv1126+yolov3模型转换
相关阅读2
Title: CTR---DIN原理,及deepctr组网实现DIN
文章目录
原理小结
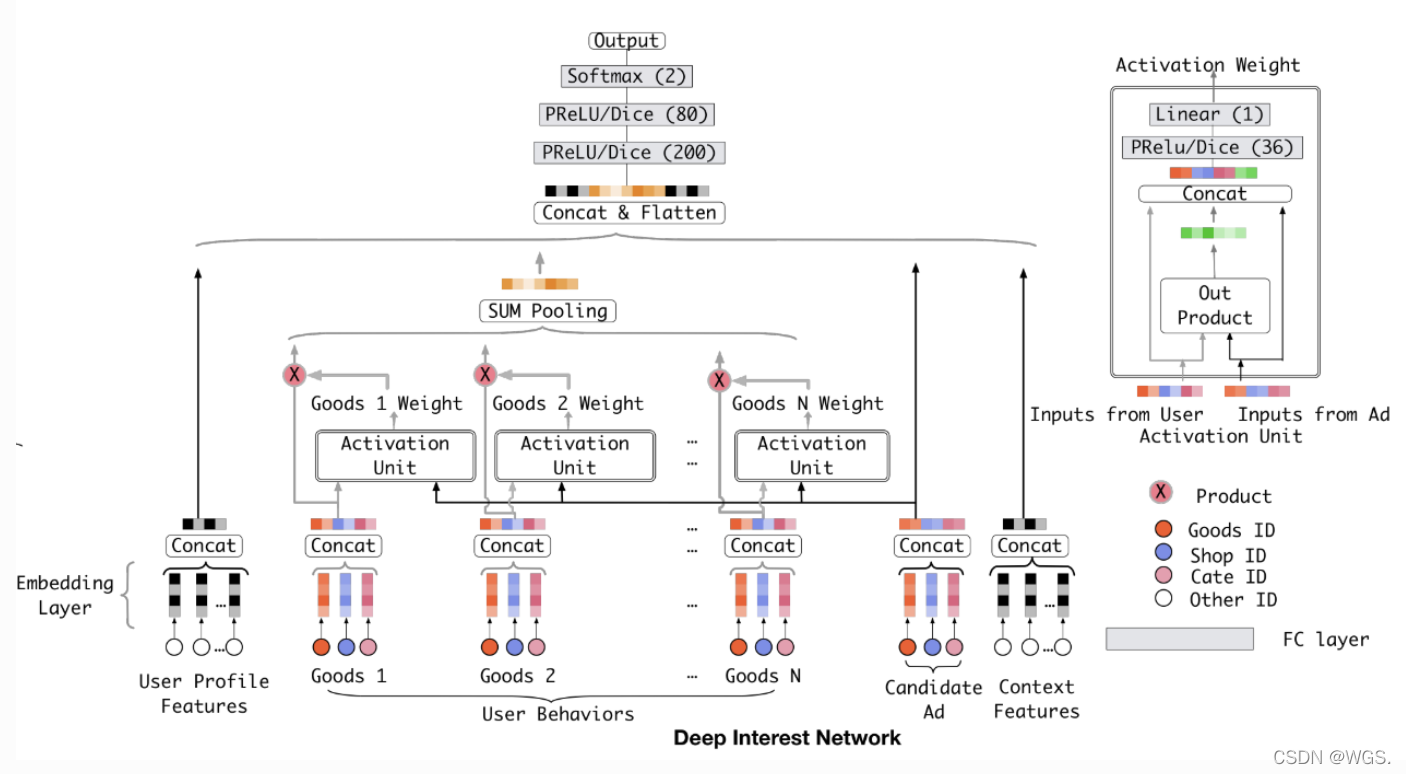

- Candidate Ad
- item,在这指广告特征。
- User profile features
- 代表用户的特征。
- Context Features
- 代表跟场景有关的特征,比如时间戳之类的。
- User Behaviors
- 代表着用户行为特征。
- 主要就是过去用户明确表示感兴趣的item统统都打包起来,我们看一个人不是看他说什么,是看他做什么,所以这些特征要重点关照。
- Activation Unit
- 通常DNN网络抽取特征的高阶特征,减少人工特征组合,对用户历史行为数据进行处理时,需要把它们编码成一个固定长的向量,但是每个用户的历史点击个数是不相等的,通常的做法是对每个item embedding后,进入pooling层(求和或最大值)。DIN认为这样操作损失了大量的信息,故此引入attention机制,并提出了 Dice 激活函数,自适应正则,显著提升了模型性能与收敛速度。
- 在Base Model里,这些用户行为特征在映射成embedding后直接一个sum/average pooling就算完事了,结果就是一个静态的embedding无法表征一个用户广泛的兴趣,所以在DIN中考虑加入Activation Unit,每个曾经的用户行为都跟Candidate Ad交互,交互的方法在上图的右上角也给出了,交互呢会交互出一个权重,代表着曾经的一个用户行为与Candidate Ad的相关性。比如你曾经买过篮球,买过毛衣针,那眼下有一个哈登同款保温杯,那我们肯定是更关注你以前买篮球的行为,那你买篮球的行为映射出的一个embedding的权重就大,买毛衣针的行为映射出的一个embedding的权重就小。有了这个权重,我们就可以在所有用户行为特征映射成embedding后做weighted sum pooling了。这样,针对每个不同的 Candidate Ad,每个用户行为特征在映射成embedding后经过weighted sum pooling后就会生成一个汇总的不同的embedding,这就是动态的embedding,动态的embedding就能表征出用户广泛的兴趣了。
关于DIN中,attention注意力机制、Dice激活函数、自适应正则详见:
注:链接文中Dice激活函数模块,PReLU的图是错的。
https://blog.csdn.net/Super_Json/article/details/105334936
参考自:
https://blog.csdn.net/Super_Json/article/details/105334936
https://blog.csdn.net/suspend2014/article/details/104377681
https://www.freesion.com/article/70981345211/
https://www.heywhale.com/mw/project/5d47d118c143cf002becca99
; deepctr实现DIN(基于df的数据格式)
import os, warnings, time, sys
import pickle
import matplotlib.pyplot as plt
import pandas as pd, numpy as np
from sklearn.utils import shuffle
from sklearn.metrics import f1_score, accuracy_score, roc_curve, precision_score, recall_score, roc_auc_score
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
from sklearn.preprocessing import LabelEncoder
from deepctr.models import DeepFM, xDeepFM, MLR, DeepFEFM, DIN, DIEN, AFM
from deepctr.feature_column import SparseFeat, DenseFeat, get_feature_names
from deepctr.layers import custom_objects
from tensorflow.keras.models import save_model, load_model
from tensorflow.keras.models import model_from_yaml
import tensorflow as tf
from tensorflow.python.ops import array_ops
import tensorflow.keras.backend as K
from sklearn import datasets
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from keras.models import model_from_json
from tensorflow.keras.callbacks import *
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from keras.preprocessing.sequence import pad_sequences
from keras.preprocessing.text import one_hot
from keras.layers.embeddings import Embedding
from deepctr.feature_column import SparseFeat, VarLenSparseFeat, DenseFeat, get_feature_names
from toolsnn import *
import settings
def get_xy_fd2():
data = pd.DataFrame({
'user': [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'gender': [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20],
'item_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
'cate_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
'pay_score': [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.10, 0.11],
'hist_item_id': [np.array([1, 2, 3, 10]), np.array([6, 1, 0, 0]), np.array([3, 2, 1, 0]), np.array([1, 2, 10, 0]), np.array([1, 3, 0, 0]), np.array([3, 2, 0, 0]), np.array([5, 2, 0, 0]), np.array([10, 6, 0, 0]), np.array([1, 2, 10, 0]), np.array([3, 2, 10, 0]), np.array([9, 2, 10, 0])],
'hist_cate_id': [np.array([1, 2, 3, 10]), np.array([6, 1, 0, 0]), np.array([3, 2, 1, 0]), np.array([1, 2, 10, 0]), np.array([1, 3, 0, 0]), np.array([3, 2, 0, 0]), np.array([5, 2, 0, 0]), np.array([10, 6, 0, 0]), np.array([1, 2, 10, 0]), np.array([3, 2, 10, 0]), np.array([9, 2, 10, 0])],
'y': [1, 1, 1, 1, 0, 0, 0, 0, 0, 1, 0]
})
print(data)
print(data.dtypes)
dcols = len(data.columns)
bise_feature = [SparseFeat('user', vocabulary_size=int(data['user'].max())+1, embedding_dim=4),
SparseFeat('gender', vocabulary_size=int(data['gender'].max())+1, embedding_dim=4),
SparseFeat('item_id', vocabulary_size=int(data['item_id'].max())+1, embedding_dim=4),
SparseFeat('cate_id', vocabulary_size=int(data['cate_id'].max())+1, embedding_dim=4),
DenseFeat('pay_score', 1)]
behavior_feature_list = ["item_id", "cate_id"]
behavior_feature = [VarLenSparseFeat(SparseFeat('hist_item_id', vocabulary_size=int(data['item_id'].max())+1, embedding_dim=4, embedding_name='item_id'), maxlen=4),
VarLenSparseFeat(SparseFeat('hist_cate_id', vocabulary_size=int(data['cate_id'].max())+1, embedding_dim=4, embedding_name='cate_id'), maxlen=4)]
feature_columns = bise_feature + behavior_feature
feature_names = get_feature_names(bise_feature + behavior_feature)
print(feature_names)
x = {}
for name in feature_names:
if name not in ['hist_item_id', 'hist_cate_id']:
x[name] = data[name].values
print(name, type(data[name].values))
else:
tmp = [t for t in data[name].values]
x[name] = np.array(tmp)
print(name, type(x[name]))
y = data['y'].values
print(x)
print(y)
print(feature_columns)
print(behavior_feature_list)
return x, y, feature_columns, behavior_feature_list
if __name__ == "__main__":
x, y, feature_columns, behavior_feature_list = get_xy_fd2()
model = DIN(dnn_feature_columns=feature_columns, history_feature_list=behavior_feature_list)
model.compile('adam', 'binary_crossentropy',
metrics=['binary_crossentropy'])
history = model.fit(x, y, verbose=1, epochs=3)

Original: https://blog.csdn.net/qq_42363032/article/details/121678388
Author: WGS.
Title: CTR---DIN原理,及deepctr组网实现DIN
相关阅读3
Title: 机器学习快速入门(一)
1.在机器学习算法中,按照学习方式大致可以分为四大类,分别是监督学习、半监督学习、无监督学习和强化学习。
2.监督学习是利用一组带标签的数据集,学习从输入到输出关系的映射关系f,然后将学习到的映射关系f应用到未知的数据上,用于预测未知数据的类别或数值。常见的有分类问题:预测的标签是离散的类别和回归问题:预测的标签是连续数值类型。
3,基于监督学习有这么一句话:数据和特征决定了机器学习的上限,模型和算法只是逼近这个上限。
4.半监督学习是输入的数据有少量的标签,进行学习,学习的目的就是在这些未标记的数据中获得最优的泛化性能。
5.无监督学习就是学习的数据没有任何标签,包括关联规则分析、数据降维、聚类算法、词嵌入。
关联规则:啤酒和纸尿裤
降维算法:主成分分析(PCA),奇异值分解,他们在最大限度的保留数据内部信息同时,将数据从高维到低维,便于数据的计算和可视化。
聚类算法:K-means、基于密度的DBSCAN聚类、基于层次聚类算法等,将数据划分为不同的簇。
6.强化学习的思想源于心理学的研究,学习智能体提高和改善其性能的过程,能够学习是计算机程序具有智能的基本标志。在给定情景下,得到奖励的行为会被"强化",而受到惩罚的行为会被"弱化"。
7.数据的标准化和数据正则化
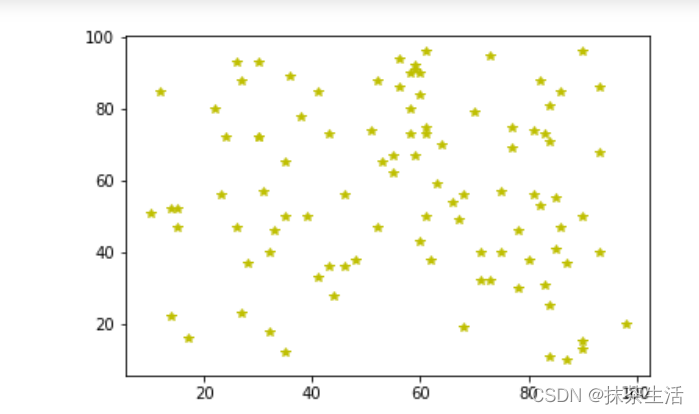
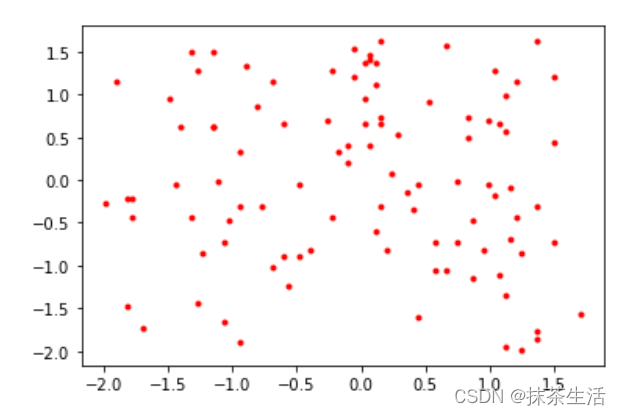
数据标准化也叫归一化。常见的数据标准有Z-Score,和Min-Max.
Score要计算数据的均值和标准差,利用均值和标准差将数据集转化为均值为0、方差为1的分布。
使用pytorch产生一个序列,然后用Z-Score来进行归一化处理
import torch
import matplotlib.pyplot as plt
data1=torch.randint(10,100,(2,100)).float()
data2=(data1-data1.mean())/data1.std()
plt.plot(data1[0].numpy(),data1[1].numpy(),'y*')
plt.figure()#创建新的画布
plt.plot(data2[0].numpy(),data2[1].numpy(),'r.')
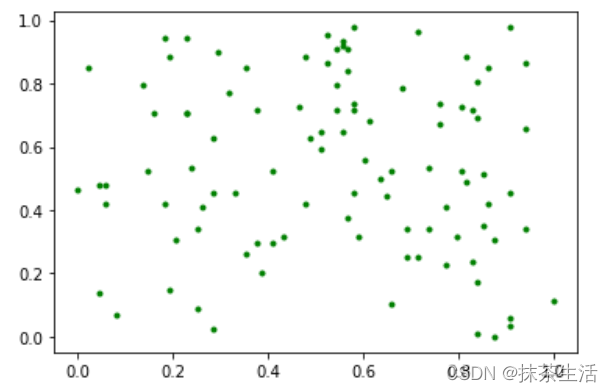
另一种数据标准化常用的方法是Min-Max
#Min-Max归一化处理
data3=(data1-data1.min())/(data1.max()-data1.min())
plt.plot(data3[0].numpy(),data3[1].numpy(),'g.')
另一个容易与数据标准化相混淆的概念是数据正则化,数据正则化与数据标准化最大的区别是:数据标准化针对的是列数据,数据正则化针对的是行数据。
数据正则化也叫特征正则化,使用p-norm范数对每行数据进行相应的转换。一般用2范数进行处理。
tmp_data=[
[1.0,0.5,-1.0],
[2.0,1.0,1.0],
[4.0,10.0,2.0]
]
data4=torch.Tensor(tmp_data)
data4

data4/(data4.pow(2).sum(dim=1).pow(1/2).unsqueeze(1))

从正则化的结果来看,特征之间的差别性没有正则化之前那么大,而且正则化之后的数据无量纲。通常,进行特征的正则化处理会为模型带来性能上的提升。
8.交叉验证
模型有很多技巧,核心思想是用一部分数据训练模型,然后再另一部分数据上进行验证,这种思想被称为交叉验证。
下面介绍三种交叉验证的方法:
(1)简单交叉验证:简单交叉验证就是从全部的数据S中随机选择S个样本作为训练集train,剩下的数据作为测试集test,在训练集train上训练模型,并在测试集test上进行测试,预测每条测试数据的标签,最后通过预测标签和真实标签计算分类的正确率。
train_test_split是由sklean的model_selection提供,可以对数据集进行划分。
(2)K折交叉验证:K折交叉验证将全部数据集划分成K个不相交的子集,每次从K个子集中选出一个作为测试集,剩下的作为验证集。
(3)留一法。留一法是每次只保留一个样本作为测试集,其他样本作为训练集。如果有K个样本,则需要训练K次。留一法计算最繁琐,但样本利用率最高,适合于小样本的情况。
9.过拟合和欠拟合
在数据科学中,有的模型效果好但是容易过拟合,有的模型效果差学习不到数据之间的规律。
欠拟合:一句话就是模型不懂数据,"你不懂我"
过拟合:一句话就是模型太懂数据,"失去了自我",防止过拟合的方法:1.增加数据量,2.合理的数据切分,传统的数据划分是6:2:2,大数据时代数据的划分应为98:1:1. 3.正则化,正则化是在损失函数上添加对训练参数的惩罚范数,通过添加的范数惩罚对需要训练的参数进行约束,防止模型过拟合。常用的正则化参数有L1和L2范数。
L1范数惩罚项的最终目的是将参数的绝对值最小化,L2范数惩罚项的最终目的是将参数的平方和最小化。在固定的深度学习中,使用L1范数会趋向于使用更少的参数,而其他的参数都是0,从而增加网络稀疏性,防止模型过拟合。实际中用L2范数进行正则化约束较多
4.最常用的正则化技术是引入Dropout层,随机丢掉一些神经元,减轻网络过拟合的现象。
5.提前结束训练,当网络在验证集上损失不在减小,精度不在增加时,即认为网络已经训练充分,终止网络训练。
Original: https://blog.csdn.net/ylycrp/article/details/122767047
Author: 抹茶生活
Title: 机器学习快速入门(一)