
2021SC@SDUSC
目录
2021SC@SDUSC
normal_bert.py 代码分析
代码输入包含七个部分,分别为
input_ids,input_mask,segment_ids,masked_lm_positions,mask_lm_ids,masked_lm_weights,next_sentence_labels.
input_ids:表示tokens的ids
input_mask:表示哪些是input,哪些是padding.len(input_ids)个1,后面继续补0.对于mask的词,主要占了全部vocabulary的15%左右,在代码中对于每个词80%replace with [mask],10% keep original,10% replace with random word.超过了mask的词数,则终止.
segment_ids:第一个句子到[SEP]为0,后面为1.主要是对输入进行区分,判断输入的两个句子.
masked_lm_positions:表示句子中mask的token的position.
mask_lm_ids:表示句子中mask的token的id.
masked_lm_weights:表示句子中mask的token的权重.
next_sentence_labels:表示两个句子是不是相连的.
代码示例
class ClassificationBert(nn.Module):
def __init__(self, num_labels=2):
super(ClassificationBert, self).__init__()
加载预训练bert模型
self.bert = BertModel.from_pretrained('bert-base-uncased')
self.linear = nn.Sequential(nn.Linear(768, 128),
nn.Tanh(),
nn.Linear(128, num_labels))
python中torch.nn解析
torch.nn是专门为神经网络设计的模块化接口。nn构建于autograd之上,可以用来定义和运行神经网络。
nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
定义自已的网络:
需要继承nn.Module类,并实现forward方法。
一般把网络中具有可学习参数的层放在构造函数__init__()中,
不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
在forward函数中可以使用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用if,for,print,log等python语法.
编码输入文本
def forward(self, x, length=256):
# Encode input text
all_hidden, pooler = self.bert(x)
使用linear layer(线性)层进行预测
pooled_output = torch.mean(all_hidden, 1)
predict = self.linear(pooled_output)
return predict
实验结果
使用的IMDB数据集,共5000条无标签样本和10到10000条有标签样本,这样进行组合。使用了5种对比模型,VAMPIRE, BERT, TMix, UDA , MixText,效果图如下: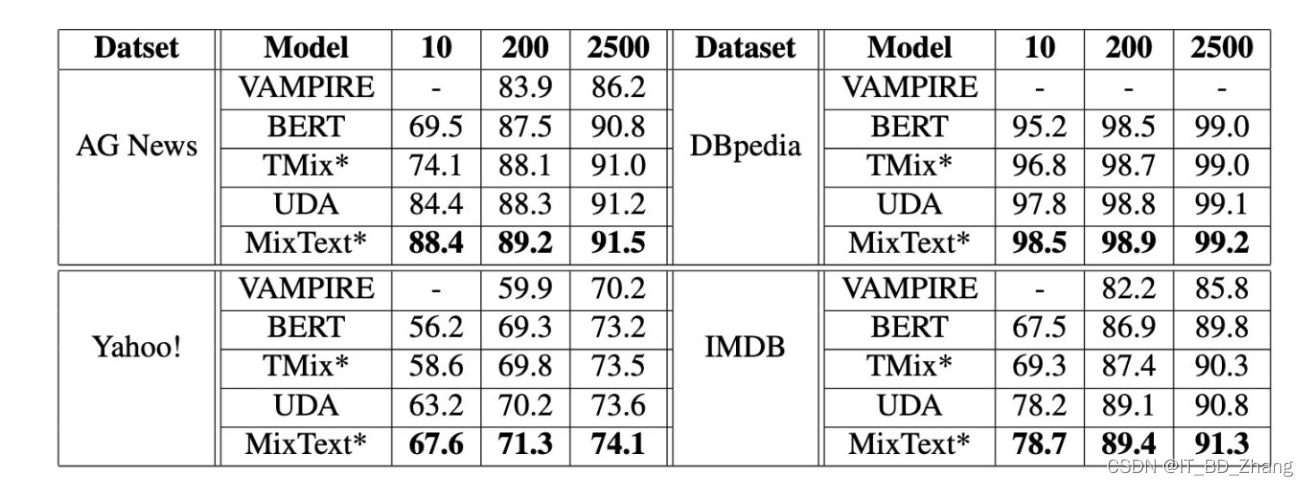
结果表明,Tmix的效果好于Bert,尤其当分类在10种的时候,MixText效果是最好的,因为MixText不仅合成了无标签数据,并且利用了有标签数据和无标签数据的隐含的关系,而且可以对无标签数据进行猜测标签,通过对数据增强和原始文件的权重平均。
无标签数据量对结果产生的影响,无标签数据越多,模型越准确。
学期学习总结
在本学期选择了该项目进行学习后,对自然语言处理方面有了更加深入的了解,从一开始读文章晦涩难懂,到最后查找资料逐步有了新的认识,逐渐学会了研究新项目,学习新知识的方法,现对相关领域的基础知识进行学习和弥补,再对某一部分深入了解的东西进行看网课,看其他的博客进行学习,并总结出其中的重点,主要代码以及其实现方式,可以自己手写进行练习。对任务中需要深入学习的模型和算法,进行每周的总结,虽然总结距离准确严谨还不够,但每次的总结都能有一些收获。与小组一起合作,互相讲自己负责的部分,最终对半监督文本分类的项目有了更进一步的了解。
Original: https://blog.csdn.net/m0_52073096/article/details/122153321
Author: IT_BD_Zhang
Title: 半监督文本分类学习代码展示及最终总结
相关阅读1
Title: 3060Ti显卡,tensorflow2.4-GPU安装
一、写在前面:
本来一直用的tensorflow2.3,换了新电脑就原样装的,但是怎么都调用不了GPU,2.3版本的安装大家可以参考:(37条消息) TensorFlow2.3(gpu)的安装简易教程及注意问题_qq_41876119的博客-CSDN博客
因为之前经受过很多折磨,所以比较快的想到可能是显卡,tensorflow,cuda的适配问题,事实证明确实,所以大家如果之后遇到类似的问题在比较确认自己安装流程没有问题的情况下,优先考虑这个问题。
二、安装步骤:
电脑配置:cpu:11400H;显卡:3060Ti(显存8G),系统:win10
1、安装anaconda
2、安装vscode
3、配置虚拟环境:
conda create -n tf2.4 python=3.8
activate tf2.4
4、安装cudatoolkit和cudnn:
首先确认自己显卡适配的cuda版本:
nvidia-smi

可以看到cuda的版本是11.4,其实,安装逻辑是根据这个版本确定要用哪个版本的tensorflow,我的1060ti显卡的电脑,cuda版本是10,所以用tf2.3。
conda install cudatoolkit=11.0
conda install cudnn==8.2.1
还有比较多的教程中cudnn是在官网下载安装的,也是可以的,anaconda中库的管理和更新可能会有点慢,不过这个方法目前亲测有效,之后的版本如果不行,就,再说吧。查看版本:
conda search cudnn

5、安装tensorflow2.4
pip install tensorflow-gpu==2.4.0 -i https://mirrors.aliyun.com/pypi/simple/
6、查看是否正确安装
conda list
python
import tensorflow as tf
tf.__version__
tf.test.is_gpu_available()
tf.config.list_physical_devices('GPU')
有如下显示说明安装正确:

Original: https://blog.csdn.net/weixin_45678589/article/details/121209358
Author: weixin_45678589
Title: 3060Ti显卡,tensorflow2.4-GPU安装
相关阅读2
Title: 远场多阵列语音识别(Far-filed multi-array speech recognition)
1. 本章内容
- 本博客介绍基于Attention的beamformer技术(多麦克风波束合成)。
- 对其文章中代码进行复现。
- 只复现了beamformer代码,集成到ASR(wenet)中的代码等待我后期GitHub开源。
2. 文章详情
-
引用:Gong, R. , et al. "Self-Attention Channel Combinator Frontend for End-to-End Multichannel Far-field Speech Recognition." 2021.
-
arXiv:https://arxiv.org/abs/2109.04783
3. 原文解读
- 网络结构(构思还是很easy的)

(1) 最下面:类似于mel谱
(2)右侧:计算多通路之间的cross-attention,然后经过一个softmax函数,来给每一个通路(channel)求出一个权重。
(3)最上面:求多通路语音信号的mel谱加权和,作为ASR的输入 - 结果展示
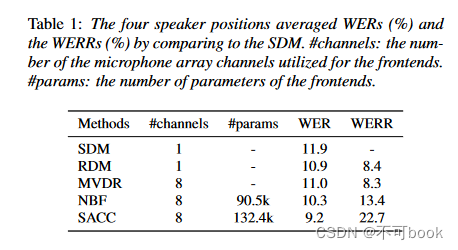
(1)自称是beamformer中最SOTA的,其实粒度还是蛮高的。(还有方法降低粒度,还可以更SOTA)
(2)效果绝对提升1-2%。
; 4. 代码/源码(只包含beamformer部分,具体融合到Wenet-ASR,参考我后期github更新)
import torch
import torch.nn as nn
import numpy as np
class beamformer_attention(nn.Module):
def __init__(self,d_model, d_k, d_v, n_heads):
super(beamformer_attention, self).__init__()
self.muttiheadatt = MultiHeadAttention(d_model, d_k, d_v, n_heads)
def forward(self,x):
attain = self.muttiheadatt(x,x,x)
softmax_att = nn.Softmax(dim=-1)(attain)
output = torch.matmul(x.transpose(-1,-2),attain)
length = output.size(0)
output = output.view(length,-1)
return output
class ScaledDotProductAttentionMask(nn.Module):
def __init__(self, d_k):
super(ScaledDotProductAttentionMask, self).__init__()
self.d_k = d_k
def forward(self, Q, K, V):
scores = torch.matmul(Q, K.transpose(-1,-2)) / np.sqrt(self.d_k)
attn = nn.Softmax(dim=-1)(scores)
context = torch.matmul(attn, V)
return context, attn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, d_k, d_v, n_heads):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.n_heads = n_heads
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v*n_heads)
self.layer_norm = nn.LayerNorm(d_model)
self.concat = nn.Linear(n_heads*d_v,d_v)
def forward(self, Q, K, V):
batch_size = Q.size(0)
##下面这个就是先映射,后分头;这里都是dk
q_s = self.W_Q(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, self.n_heads, self.d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, self.n_heads, self.d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
## 输入进行的attn_mask形状是 batch_size x len_q x len_k,然后经过下面这个代码得到 新的attn_mask : [batch_size x n_heads x len_q x len_k],就是把pad信息重复了n个头上
#attn_mask = attn_mask.unsqueeze(1).repeat(1, self.n_heads, 1, 1)
context, attn = ScaledDotProductAttentionMask(self.d_k)(q_s, k_s, v_s)
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.n_heads * self.d_v) # context: [batch_size x len_q x n_heads * d_v]
#output = self.layer_norm(context)
output = self.concat(context)
return output # output: [batch_size x len_q x d_v]
if __name__ == '__main__':
beamformer = beamformer_attention(40,64,1,6)
input = torch.ones((10,8,40),dtype=torch.float32) # [seq_len channel fbank]
print(input)
output = beamformer(input)
print(output)
print(input.size(),'[seq_length,channels,fbank]')
print(output.size(),'[seq_length,fbank]')
print('succed')
Original: https://blog.csdn.net/qq_37258753/article/details/126427181
Author: 方付平
Title: 远场多阵列语音识别(Far-filed multi-array speech recognition)
相关阅读3
Title: 基于百度tts-实现文字转语音,支持下载,在线预览
1.新建一个.html 文件,将下面的代码复制到文件内,保存。
DOCTYPE html>
<html>
<head>
<title>title>
head>
<script src="https://cdn.jsdelivr.net/npm/vue@2">script>
<link rel="stylesheet" href="https://unpkg.com/element-ui/lib/theme-chalk/index.css">
<script src="https://unpkg.com/element-ui/lib/index.js">script>
<style type="text/css">
p{
background-color: #96b97db0;
padding: 6px;
font-size: 14px;
color: #f5fff4;
}
#text{
background-color: #e3e3e3;
border: 0;
width:99%;
height: 100px;
}
button{
background-color: #d4d3d3;
color: white;
margin: 5px;
}
#spd{
width: 50px;
}
.text {
font-size: 14px;
}
.item {
margin-bottom: 18px;
}
.clearfix:before,
.clearfix:after {
display: table;
content: "";
}
.clearfix:after {
clear: both
}
.box-card {
width: 480px;
}
style>
<body>
<div id="app" >
<el-card class="box-card">
<div slot="header" class="clearfix">
<span style="font-weight:bold;">文字转语音-百度ttsspan>
<el-button type="primary" icon="el-icon-headset" style="float: right;margin:3px;" @click="previewClick()">预览el-button>
div>
<div>
<span>语言:span>
<el-radio-group v-model="param.lan" @change="previewClick">
<el-radio v-for="item in language" :label="item.code" :key="item.code" >{{item.name}}el-radio>
el-radio-group>
div>
<div>
<span>后缀:span>
<el-radio-group v-model="param.aue" @change="previewClick">
<el-radio v-for="item in aue" :label="item.code" :key="item.code" >{{item.name}}el-radio>
el-radio-group>
div>
<audio style="width:100%;" id="tts_autio_id" autoplay="autoplay" controls="controls">
<source id="tts_source_id" :src="url">
<embed id="tts_embed_id" height="0" width="0" src="">
audio>
<el-tabs v-model="tabs">
<el-tab-pane label="基础音库" name="-1">
<el-button type="success" v-for="per in pers1" @click="param.per=per.code" style="margin: 3px;">{{ per.name }}el-tag>
el-tab-pane>
<el-tab-pane label="精品音库" name="1">
<el-button type="success" v-for="per in pers2" @click="param.per=per.code" style="margin: 3px;">{{ per.name }}
el-button>
el-tab-pane>
el-tabs>
<el-input v-model="param.tex" type="textarea"
:rows="10" placeholder="请输入需要转换的文字">el-input>
<div class="block">
<span class="demonstration">语速:span>
<el-slider v-model="param.spd" :min="0" :max="15" >el-slider>
div>
<div class="block">
<span class="demonstration">音调:span>
<el-slider v-model="param.pit" :min="0" :max="15">el-slider>
div>
<div class="block">
<span class="demonstration">音量:span>
<el-slider v-model="param.vol" :min="0" :max="15">el-slider>
div>
el-card>
div>
<script type="text/javascript">
var app = new Vue({
el: '#app',
data: {
message: 'Hello Vue!',
tabs: '-1',
url: "http://tts.baidu.com/text2audio?",
param:{
cuid: "baike",
lan: "ZH",
ctp:1,
pdt:301,
per: 0,
spd: 5,
pit: 5,
vol: 5,
tex: "林荒大吼出声,即便十年挣扎,他也从未感到过如此无助。自己的身体一点点陷入岁月之门,却眼睁睁的看着君倾城一手持剑,雪白的身影决然凄厉。就这样孤身一人,于漫天风雪中,对阵数千武者",
aue: 3
},
pers1: [
{"code":0,"name":"标准女音"},
{"code":1,"name":"标准男音"},
{"code":3,"name":"斯文男音"},
{"code":4,"name":"小萌萌"},
{"code":5,"name":"知性女音"}
],
pers2: [
{"code":5,"name":"度小娇"},
{"code":103,"name":"度米朵"},
{"code":106,"name":"度博文"},
],
aue: [{"code":3,"name":"mp3"},
{"code":6,"name":"wav"},
],
language: [{"code":"ZH","name":"普通话"},
]
},
methods:{
previewClick(){
this.url="http://tts.baidu.com/text2audio?";
for(var key in this.param){
this.url += key;
this.url += "=";
this.url += this.param[key];
this.url += "&";
}
this.url = this.url.substring(0,this.url.length - 1);
document.getElementById('tts_autio_id').setAttribute("src", this.url);
document.getElementById('tts_autio_id').play()
}
}
})
script>
body>
html>
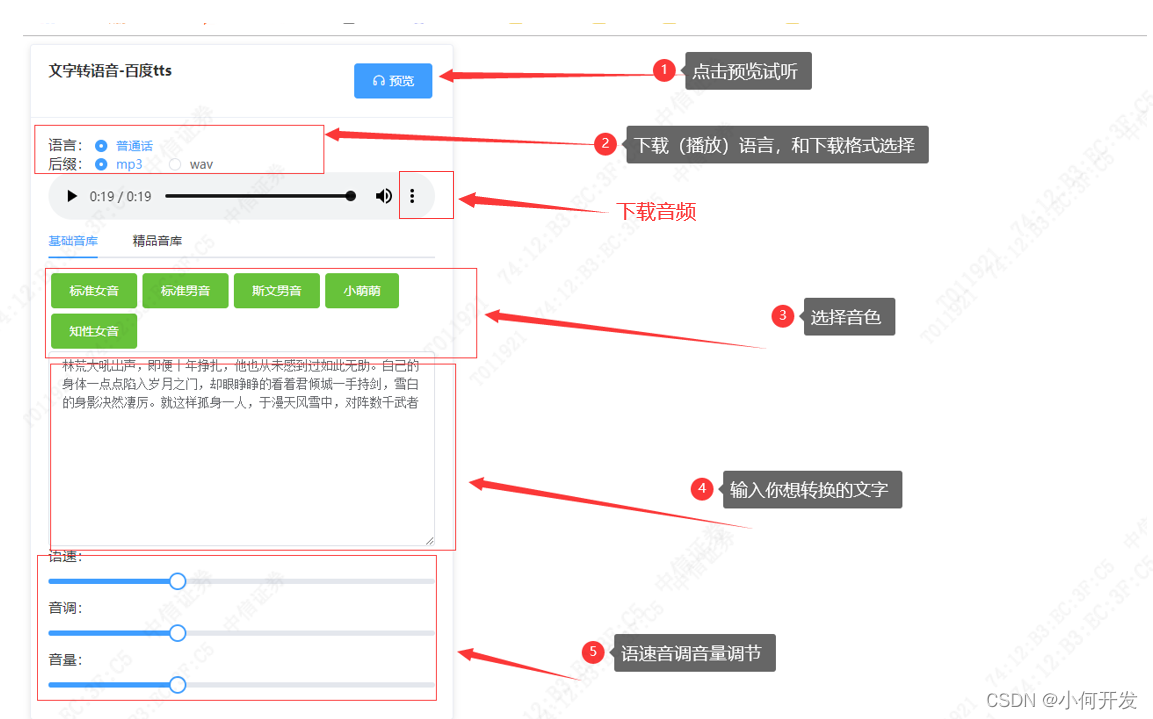
2、 将该文件鼠标拖到浏览器中,即可打开。
3、使用说明
Original: https://blog.csdn.net/weixin_43865196/article/details/122173434
Author: 小何开发
Title: 基于百度tts-实现文字转语音,支持下载,在线预览