
具有自适应距离对齐的时空步态特征
paper题目:Spatio-temporal Gait Feature with Adaptive Distance Alignment
paper是IEEE Fellow Xuelong Li发表在arxiv 2022的工作
paper地址:链接
Abstract
步态识别是一项重要的识别技术,因为它不易伪装,识别目标不需要合作。然而,步态识别仍然存在严重挑战,即步行姿势相似的人经常被错误识别。本文尝试从网络结构的优化和提取的步态特征的细化两个方面来增加不同目标的步态特征差异,从而提高对具有相似步行姿势的目标的识别效率。因此我出了本文的方法,它由时空特征提取 (SFE) 和自适应距离对齐 (ADA) 组成,其中 SFE 使用时间特征融合 (TFF) 和细粒度特征提取 (FFE) 从原始轮廓中有效地提取时空特征, ADA 以现实生活中大量未标记的步态数据为基准,对提取的时空特征进行细化,使其类间相似度低,类内相似度高。在 mini-OUMVLP 和 CASIA-B 上的大量实验证明,本文的结果比一些最先进的方法要好。
关键词——步态识别、时空特征提取、特征调整。
I. INTRODUCTION
与虹膜、指纹、人脸等生物特征不同,步态在识别过程中不需要目标的配合,在不受控制的场景下可以远距离识别目标。因此,步态在法医鉴定、视频监控、犯罪侦查等方面有着广泛的应用。作为一项视觉识别任务,其目的是学习不同目标的判别特征。然而,从原始步态序列中学习时空特征时,经常会受到许多外部因素的干扰,例如各种相机角度、不同的衣服/携带条件。
已经提出了许多基于深度学习的方法来克服这些问题。 DVGan 使用 GAN 生成整个时角空间,其视角从 0° 到 180°,间隔为 1°,以适应各种摄像机角度。 GaitNet 使用自编码器作为他们的框架来从原始 RGB 图像中学习与步态相关的信息。它还使用 LSTM 来学习时间信息的变化,以克服不同的衣服/携带条件。 GaitSet从由独立帧组成的集合中学习身份信息,以适应各种视角和不同的衣服/携带条件。 Gaitpart采用部分特征进行人体描述,以增强细粒度学习。
以往的方法要么只关注时间特征的处理,要么只关注细粒度特征的提取,不能保证同时充分提取时空信息。为了解决这个问题,尝试使用时间特征融合(TFF)融合最具代表性的时间特征,然后使用细粒度特征提取(FFE)从最具代表性的时间特征中提取细粒度特征,经过这些操作,可以完全提取原始步态轮廓的时空特征。然而,当遇到两个行走姿势相似的目标时,完美的网络结构只能保证充分提取他们的步态特征,而不能保证他们的判别力。为了解决这个问题,作者尝试使用自适应距离对齐技术从未标记的数据中自适应地选择合适的基准来细化提取的时空特征,该操作可以有效地增加具有相似步行的受试者的步态特征差异。因此,提出了方法:具有自适应距离对齐的时空步态特征,它由时空特征提取(SFE)和自适应距离对齐(ADA)组成。 SFE 包括 FFE 和 TFF。
具体来说,每个初始帧都已输入到 TFF 中,以通过最大池化选择最具代表性的时间特征。在此之后,作者将融合的最具代表性的时间特征分成 4 个块,并使用单个卷积层来提取细粒度特征。最后,使用 ADA 对提取的时空特征进行细化,使其具有低类间相似度和高类内相似度。
将从以下三个方面描述所提出方法的优点:
- 在 TFF 使用最大池化来融合最具代表性的时间特征,然后将最具代表性的时间特征分成 4 个块来提取细粒度的空间特征。这部分使用了一个简化的时空特征提取模块,可以有效地学习原始步态序列的时空特征。
- 改进了距离对齐技术并将其应用于步态识别领域。改进的距离对齐技术采用自适应的方法从现实生活中未标记的数据集中选择合适的基准,然后利用该基准对提取的时空特征进行细化,可以有效增加具有相似步行姿势的受试者的步态特征差异。
- 提出了一种称为具有自适应距离对齐的时空步态特征的方法。它可以有效地从原始步态轮廓中提取时空特征,增加不同目标之间的差异。对 CASIA-B 和 mini-OUMVLP 的大量实验证明,本文的方法比其他最先进的方法具有更好的结果。值得注意的是,本文的方法在正常步行条件下的 CASIA-B 步态数据集上实现了 97.0% 的平均 rank-1 准确度。
II. RELATED WORK
这部分主要介绍步态识别的相关工作,将从以下几个方面入手:步态识别的主要方法、从原始步态轮廓中学习时空信息的方法的演变以及距离对齐的启发。
步态识别。目前的步态识别方法可以分为基于模型的方法和基于外观的方法。基于外观的方法通过卷积神经网络(CNN)直接从步态序列中的原始轮廓中学习时空特征,然后通过特征匹配来判断步态序列的目标身份。基于模型的方法首先对步态序列中的原始轮廓进行建模,然后使用一种新的方式来表达原始轮廓,并学习它们的时空特征。一个具有代表性的基于模型的方法是JointsGait,它使用原始步态轮廓的人体关节来创建步态图结构,然后通过图卷积网络 (GCN) 从步态图结构中提取时空特征。然而,当用这种方法来表达步态序列中的轮廓时,往往会丢失很多重要的细节信息,增加识别难度。而其他基于模型的方法也遇到了这个问题,所以基于外观的方法已经成为目前最主流的步态识别方法。本文后面提到的方法都属于基于外观的方法。
时空特征提取模块。时空特征提取的效率是衡量基于外观的方法质量的重要因素,它会影响识别的准确性。时空特征提取模块可以分为两部分:空间特征提取模块和时间特征提取模块。
对于时间特征提取模块,有基于深度学习的方法和传统方法。传统方法首先通过一些操作将原始步态轮廓压缩成一张图像,例如 GEI、PEI 和 CGI。然后使用神经网络从该图像中提取时空特征。虽然这些传统方法很简单。以下研究人员发现他们不能很好地保存时间信息,并尝试使用基于深度学习的方法来提取时间特征。 LSTM使用重复的神经网络模块来保存和提取原始步态序列的时间信息。 GaitSet观察到即使步态序列被打乱,将它们重新排列成正确的顺序并不困难,然后使用打乱的轮廓来学习时空信息,以确保各种步态序列的适应性。但是 LSTM 和 GaitSet 都有一些缺点:它们的网络结构和计算过程复杂。本文尝试使用多个并行卷积层从原始步态轮廓中提取全局特征,并使用简单的最大池化操作来融合最具代表性的时间特征。这样可以简化网络结构,减少计算量,有效提取时间特征。值得注意的是,本文的方法总共只使用了 4 个卷积层和 2 个池化层。
对于空间特征提取模块,在[43]中,在步态识别中引入了partial的思想,认为不同的人体部位在身份信息的识别中会起到不同的作用。因此,将人体分为七个不同的部分,通过去除平均步态图像中的七个部位并观察识别率的变化来探索不同部位对步态识别的影响。为目前局部思想的使用奠定了基础。 GaitPart在深度学习领域利用这种思想对人体进行描述,充分提取细粒度信息,将多层特征分块提取细粒度特征,取得了很好的效果。但是,GaitPart 采用了partial in shallow features 的思想,将多层特征划分为block,增加了网络的复杂度。本文只对高层特征进行一次划分以提取细粒度特征,并且仅使用单个卷积层可以获得良好的性能。它还大大简化了网络结构。
自适应距离对齐。距离对齐技术首先用于细化人脸特征,具有良好的性能。它使用大量未标注数据来判断真实场景中特征分布的流行密度,并以此密度为基准对提取的时空特征进行细化,将收敛性差的特征收敛到一起,将特征分散收敛得太紧。人脸识别任务和步态识别任务的本质目的都是通过特征匹配来识别目标的身份。由于这两个任务的相似性,作者尝试改进距离对齐技术并将其引入步态识别领域。前面的距离对齐首先计算未标记数据集中的特征与图库集和探针集中提取的时空特征之间的距离,然后通过计算距离从未标记数据中选择一些与提取的时空特征相似的特征,它从这些相似特征中选择最大值作为基准来细化提取的时空特征。这种操作可以达到很好的效果,但是它只使用了这些特征与未标记数据中提取的时空特征相似的最大值,因此这些相似特征没有被充分利用。本文尽量充分利用这些相似的特征,适应性从整体(mean)、最大(maximum)、最适中(median)三个方面选择最合适的benchmark,达到最好的细化效果。将改进的距离对齐称为自适应距离对齐技术。
结合时空特征提取模块的发展和距离对齐的启发,提出了一种方法:时空步态特征与自适应距离对齐。它使用最大池化来融合最具代表性的时间特征,在高级特征上引入部分思想,改进距离对齐,并将其引入步态识别。它不仅通过时空特征提取模块有效地从原始步态轮廓中提取时空特征,而且使用自适应距离对齐技术对提取的时空特征进行细化,以增加不同目标之间步态特征的区分度。
III. OUR METHOD
这一部分将从三个方面介绍本文的方法:包括整体流水线、时空特征提取(SFE)模块和自适应距离对齐(ADA),其中时空特征提取主要包括两部分:粒度特征提取(FFE)和时间特征融合(TFF)。所提出方法的框架如图1所示。
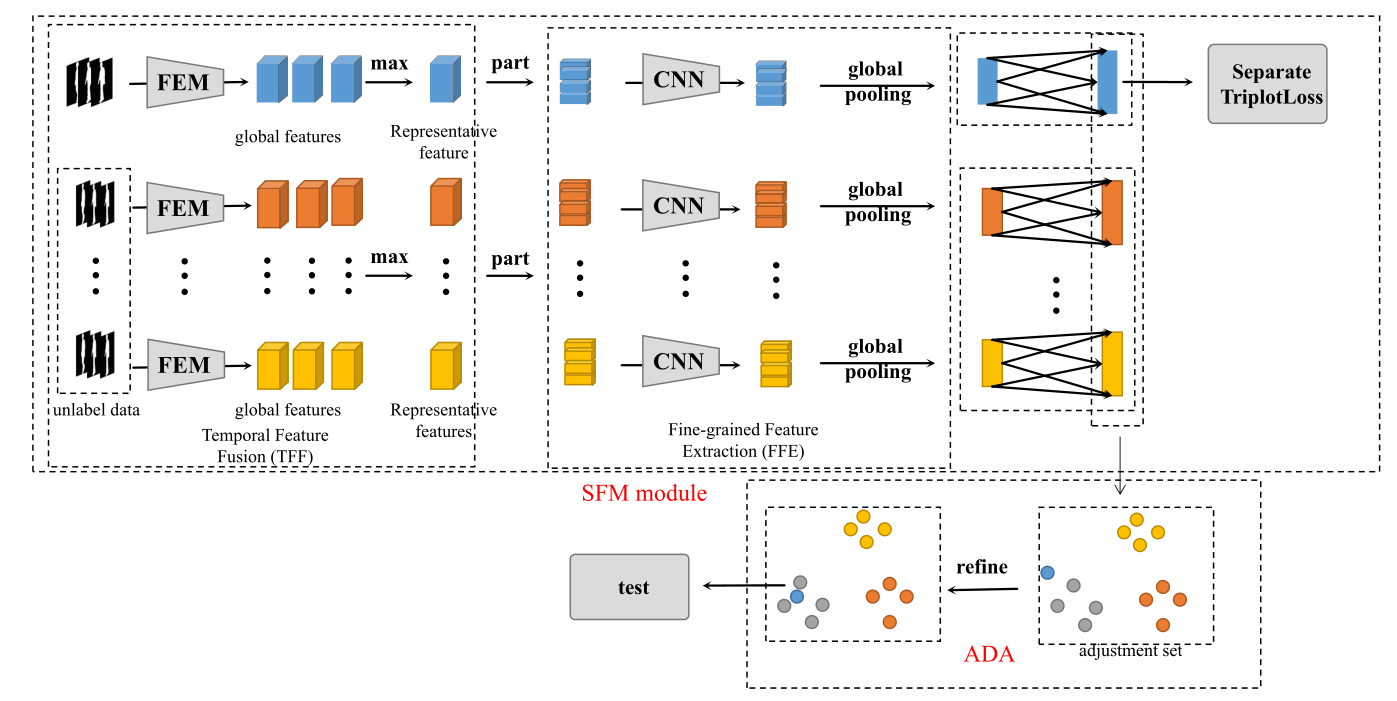
图 1. 本文方法的框架。可以清楚地观察到,本文的框架由两部分组成:时空特征提取(SFE)模块和自适应距离对齐(ADA)。 SFE模块主要是神经网络结构的优化。 ADA是对图库集和探针集中提取的时空特征的细化。在图的底部,为了方便查看特征的分布,用圆圈来表示特征。
; A. Pipeline
如图 1 所示,本文的网络主要由两部分组成:SFE 模块和 ADA。 SFE模块主要是神经网络结构的优化,它可以通过简单的网络结构有效地提取原始步态序列的时空特征。 ADA是一种后处理方法,主要以现实生活中大量未标记的步态数据为基准,对提取的时空特征进行细化,可以增加不同目标间步态特征的差异。
具体来说,在 SFE 部分,首先将一些原始步态轮廓逐帧输入到 TFF。 TFF 使用 Feature Extraction Module (FEM) 来学习每一帧的全局信息,FEM 只包含 4 个卷积层和 2 个 Max pooling 层,它可以保证每一帧的详细信息都能被充分学习,然后使用简单的操作max从提取的全局特征中融合最具代表性的时间特征。它可以在保证时间信息被充分提取的同时简化网络结构,减少计算量。在 TFF 之后,将最具代表性的时间特征输入到 FFE 以学习细粒度特征。代表帧首先被分为 4 个部分,然后仅使用一个卷积层来学习其细粒度信息。 TFF 和 FFE 都使用简单的网络结构。然后将提取的时空特征输入到下一部分。这部分使用由max pooling和mean pooling组成的Global Pooling来选择从每个块中提取的合适的细粒度特征。全连接层在全局池化之后,它可以整合之前提取的特征。最后,使用hard三元组损失作为微调网络参数的限制。
在 ADA 部分,首先从现实生活中找到大量未标记的步态数据,然后使用经过训练的 SFE 模块从未标记的步态数据集中提取时空特征,并将这些提取的时空特征作为调整集。然后计算调整集中这些特征与从原始步态序列中提取的时空特征之间的距离,并通过计算的距离从调整集中选择4个与提取的时空特征相似的特征。最后,适应性的从这些选择的特征中从整体(mean)、最大(maximum)和最适中(median)三个方面选择最合适的基准,并使用基准来细化提取的时空特征。
B. Spatio-temporal Feature Extraction module
这部分提出的模块主要是试图简化神经网络的结构,减少计算量,同时保证原始步态序列的时空特征能够被充分提取。将从 TFF 和 FEE 来介绍:其中 FFE 表示 Fine-grained Feature Extraction,TFF 表示 Temporal Feature Fusion。
- 时间特征融合:TFF 由多个并行 FEM 和一个最大池化层组成,其中 FEM 的参数是共享的。 FEMs用于从每一帧中提取全局特征,它们可以充分提取每一帧的重要信息。最大池化用于从每帧提取的全局特征中选择最具代表性的时间特征。接下来将介绍 FEM 的结构以及可以做些什么来有效地融合这些复杂的时间信息以获得最具代表性的时间特征。
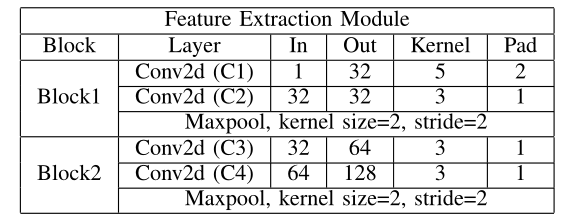
如表1所示,FEM 仅使用 4 个卷积层来提取原始轮廓的全局特征,并使用 2 个 Max pooling 层来选择这些全局特征的重要信息。这些操作可以充分提取每一帧的全局特征。然后尝试使用各种操作:max、mean、medium 来融合提取的全局特征中的代表帧,然后发现使用 max 操作可以更好地保留人类身份信息。最大操作定义为
T = Maxpooling ( T i ) , i ∈ 1 , 2 , ... , N . T=\operatorname{Maxpooling}\left(T_{i}\right), i \in 1,2, \ldots, N .T =M a x p o o l i n g (T i ),i ∈1 ,2 ,...,N .
其中T i T_{i}T i 是 FEM 从原始步态序列中提取的全局特征,T T T是通过 max 操作从T i T_{i}T i 中融合的最具代表性的时间特征。经过此操作,步态序列中最具代表性的时间特征可以很好地融合。
表1 特征提取模块的结构。 IN、OUT、KERNEL和PAD分别代表了CONV2D的输入输出通道、内核大小和填充。
2)细粒度特征提取:在以往的文献中,有研究者发现用局部特征来描述人体有突出的表现。然而,以往的研究都是分析浅层局部特征来描述人体,并且需要在不同的层特征中多次划分以提取细粒度特征,这将使网络结构更加复杂。因此,本文尝试从深层提取细粒度的特征,以简化网络结构并获得更好的结果。将提取的最具代表性的时间特征依次划分为 1、2、4 和 8 个块来学习细粒度信息,其中最具代表性的时间特征是高级特征。可以观察到,当使用 4 个块来学习细粒度特征时,它具有最好的性能。结果表明,当学习细粒度信息时,过度的阻塞并不能使细粒度信息学习得更充分,反而可能会忽略相邻部分之间的关系。还尝试使用更深的卷积层再次学习细粒度信息。但在大多数情况下,它的性能不如单个卷积层。结果有力地证明,在高级特征中使用局部思想时,不需要太深的网络结构来学习细粒度的信息。
具体来说,首先将最具代表性的帧划分为 4 个块。然后使用单个卷积层从每个块中学习细粒度信息。在此之后,使用全局池化和全连接层分别进一步整合细粒度特征和时空信息。 Global Pooling 的公式如下所示
P = Avgpooling ( P i ) + Maxpooling ( P i ) , i ∈ 1 , 2 , ... , N P=\operatorname{Avgpooling}\left(P_{i}\right)+\operatorname{Maxpooling}\left(P_{i}\right), i \in 1,2, \ldots, N P =A v g p o o l i n g (P i )+M a x p o o l i n g (P i ),i ∈1 ,2 ,...,N
这两个池化操作都适用于 w 维度。通过这个操作,特征从包含 c、h 和 w 的三维数据变为包含 c 和 h 的二维数据。
步态识别主要使用特征匹配来识别目标。因此,不同目标之间的低相似度和同一目标之间的高相似度是决定识别准确率的重要因素。 hardtriplet loss在降低类间相似度和增加类内相似度方面有很好的表现。所以用这个损失作为约束来调整网络参数。硬三元组损失表示为
L trip = max ( max max ( d i + ) − min ( d i − ) , 0 ) d i + = ∥ f i a i − f i p i ∥ 2 2 d i − = ∥ f i a i − f i n i ∥ 2 2 \begin{gathered} L_{\text {trip }}=\max \left(\max \max \left(d_{i}^{+}\right)-\min \left(d_{i}^{-}\right), 0\right) \ d_{i}^{+}=\left\|f_{i}^{a_{i}}-f_{i}^{p_{i}}\right\|{2}^{2} \ d{i}^{-}=\left\|f_{i}^{a_{i}}-f_{i}^{n_{i}}\right\|{2}^{2} \end{gathered}L trip =max (max max (d i +)−min (d i −),0 )d i +=∥f i a i −f i p i ∥2 2 d i −=∥f i a i −f i n i ∥2 2
其中d i + d{i}^{+}d i +是表示正样本和锚点( a i \left(a_{i}\right.(a i 和p i ) \left.p_{i}\right)p i )的相异性的度量,d i − d_{i}^{-}d i −是表示负样本和锚点( a i \left(a_{i}\right.(a i 和n i ) \left.n_{i}\right)n i )的相异性的度量。使用欧几里得范数得到d i + d_{i}^{+}d i +和d i − d_{i}^{-}d i −的值。以d i − d_{i}^{-}d i −的最小值和d i + d_{i}^{+}d i +的最大值作为代表来计算损失,可以有效地降低类间相似度,增加类内相似度。
; C. Adaptive Distance Alignment
在大多数情况下,Triplet loss 可以增加类内相似性并降低目标的类间相似性。然而,当遇到具有相似步行姿势的目标时,triplet loss 并不能保证他们之间的步态特征差异。所以尝试使用后处理的方法对提取的特征再次进行细化,使其更具判别力。引入自适应距离对齐技术来解决这个问题。首先,会在现实生活中发现大量未标记的步态数据。然后,使用经过训练的 SFE 模块从这些未标记的步态数据中提取时空特征。使用这些时空特征作为调整集K G K_{G}K G 。然后,计算K G K_{G}K G 中的特征与probe set和gallery set中的时空特征之间的距离,并选择一些与从K G K_{G}K G 中提取的时空特征相似的特征F S F_{S}F S 。最后,适应性的从F S F_{S}F S 中从整体(mean)、最大(maximum)和最适中(median)方面选择最合适的基准,并使用基准来细化提取的时空特征。图 2 显示了完整的特征细化过程。可以清楚地看到,经过ADA细化后,probe set和gallery set中特征的类内相似度和类间相异度有了很大的提高。接下来,将从准备和细化两个部分来介绍ADA。
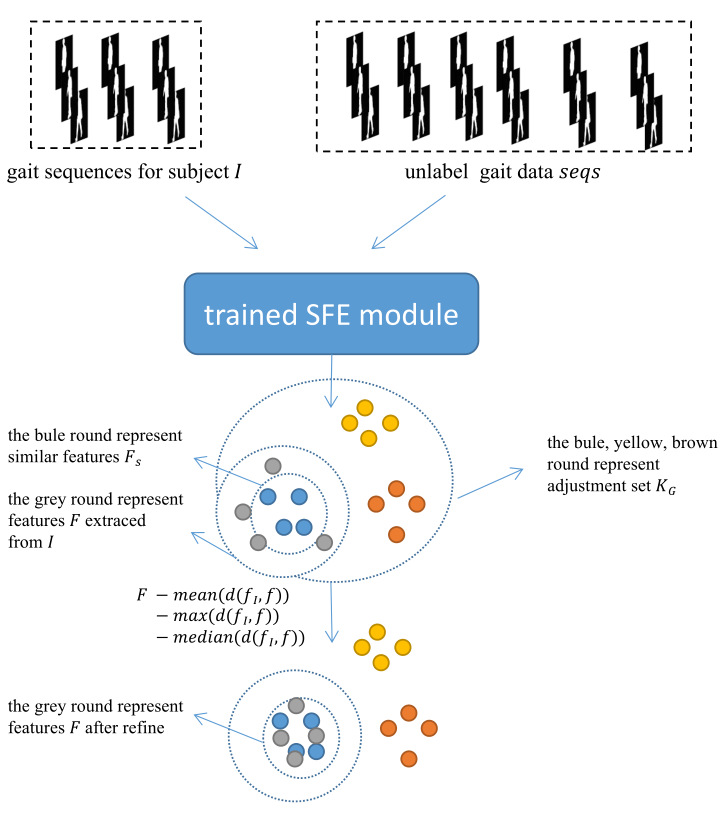
图 2. 目标I I I的步态序列和未标记的步态数据 Seqs 都输入到经过训练的 SFE 模块,可以看到从I I I中提取的特征F F F的类间差异和类内相似性很小,提取的时空特征来自未标记的被用作调整集K G K_{G}K G ,以细化从I I I中提取的特征。经过此操作,特征F的类间相异度和类内相似度都在增加。
- 准备工作:这部分主要介绍了用自适应距离对齐来提炼提取的时空特征的准备工作。它可以分为三个部分。第一部分是在现实生活中发现大量未标记的步态数据S e q s Seqs S e q s时应该遵守的。应确保该集合中未标记的数据应包含适当数量的目标,以确保集合的稳健性。如果目标数量少,则不够具有代表性,如果目标数量多,则会导致类似过拟合的问题。第二步是使用之前提出的 SFE 模块从集合S e q s Seqs S e q s中提取时空特征。这一步可以看到这些目标的类间相似度和类内相似度应该有多少,并以此为基准来细化probe set和gallery set中的时空特征。最后,将这些从未标记数据中提取的时空特征作为调整集K G K_{G}K G 。K G K_{G}K G 的公式定义为
K G = f ( Seqs ) K_{G}=f(\text { Seqs })K G =f (Seqs )
其中S e q s Seqs S e q s是来自未标记步态数据的步态序列,其中包含适当数量的受试者。f f f是上面提出的经过训练的时空特征提取模块。K G K_{G}K G 是用于细化图库集和探针集中时空特征的调整集。 - Refinement:当从未标记的步态数据S e q s Seqs S e q s中得到调整集K G K_{G}K G 时,首先计算K G K_{G}K G 中这些特征与probe set和gallery set中的时空特征之间的距离,并选择一些与提取的时空特征相似的特征来自K G K_{G}K G 。选择相似特征FS的公式定义为P { d ( f , q i ) − d ( k , q i ) ) < 0 , k ∈ K G , f ∈ F S , F S ∈ K G } = 1 0 − t 1 . \left.P\left{d\left(f, q_{i}\right)-d\left(k, q_{i}\right)\right)其中q i q_{i}q i 是从probe set和gallery set中目标i i i的步态序列中提取的时空特征,f f f是F S F_{S}F S 中的时空特征。k k k是K G K_{G}K G 中的时空特征。d ( f , q i ) d\left(f, q_{i}\right)d (f ,q i )表示f f f和q i q_{i}q i 之间的距离。d ( k , q i ) d\left(k, q_{i}\right)d (k ,q i )表示k k k和q i q_{i}q i 之间的距离。这个公式意味着F S F_{S}F S 中的f f f与q i q_{i}q i 的距离小于K G K_{G}K G 中的k k k与q i q_{i}q i 的距离的概率。它可以帮助找到一些特征F S F_{S}F S ,这些特征最类似于从K G K_{G}K G 中提取的时空特征。
当得到F S F_{S}F S 时,会适应性地从整体(mean)、最大(maximum)和最适中(median)三个方面选择最合适的benchmark θ ( q i , 1 0 − t 1 ) \theta\left(q_{i}, 10^{-t 1}\right)θ(q i ,1 0 −t 1 ),以达到最佳的细化效果。确定θ ( q i , 1 0 − t 1 ) \theta\left(q_{i}, 10^{-t 1}\right)θ(q i ,1 0 −t 1 )的公式定义为
a d a p = ( max ( ∗ ) + mean ( ∗ ) + median ( ∗ ) ) / 3 , θ ( q i , 1 0 − t 1 ) = adap ( d ( f , q i ) ) , f ∈ F S \begin{gathered} a d a p=(\max ()+\operatorname{mean}()+\operatorname{median}(*)) / 3, \ \theta\left(q_{i}, 10^{-t 1}\right)=\operatorname{adap}\left(d\left(f, q_{i}\right)\right), f \in F_{S} \end{gathered}a d a p =(max (∗)+m e a n (∗)+m e d i a n (∗))/3 ,θ(q i ,1 0 −t 1 )=a d a p (d (f ,q i )),f ∈F S
其中F S F_{S}F S 是与probe set和gallery set中需要细化的特征相似的特征。 max、mean、median 分别代表最大值、平均值和中值。它可以确保F S F_{S}F S 中所有类似的功能都被充分利用。 adpt 是一种自适应方法来选择合适的基准θ ( q i , 1 0 − t 1 ) \theta\left(q_{i}, 10^{-t 1}\right)θ(q i ,1 0 −t 1 )。
当计算出合适的θ ( q i , 1 0 − t 1 ) \theta\left(q_{i}, 10^{-t 1}\right)θ(q i ,1 0 −t 1 )时,可以调整之前提取的时空特征 q i q_{i}q i 。使用θ ( q i , 1 0 − t 1 ) \theta\left(q_{i}, 10^{-t 1}\right)θ(q i ,1 0 −t 1 )作为基准来细化时空特征,并使它们更具判别力。具体公式定义如下:
d ′ ( g , q i , 1 0 − t 1 ) = d ( g , q i ) − θ ( q i , 1 0 − t 1 ) d^{\prime}\left(g, q_{i}, 10^{-t 1}\right)=d\left(g, q_{i}\right)-\theta\left(q_{i}, 10^{-t 1}\right)d ′(g ,q i ,1 0 −t 1 )=d (g ,q i )−θ(q i ,1 0 −t 1 )
其中d ( g , q i ) d\left(g, q_{i}\right)d (g ,q i )是在确定步态序列i i i属于哪个目标时,探针集中的目标i i i与画廊集中的目标之间的原始距离,θ ( q i , 1 0 − t 1 ) \theta\left(q_{i}, 10^{-t 1}\right)θ(q i ,1 0 −t 1 )是时空的值需要细化目标i i i的特征q i q_{i}q i ,d ′ ( g , q i , 1 0 − t 1 ) d^{\prime}\left(g, q_{i}, 10^{-t 1}\right)d ′(g ,q i ,1 0 −t 1 )是调整后的探针集中的目标i i i与图库集中的目标之间的距离,用于判断目标的身份。但是,该公式仅对探针集中的特征进行调整,以修改特征匹配的最终距离。当想用一个调整集同时细化图库集和探针集中的目标的时空特征时,公式可以定义如下:d ′ ( g , q , 1 0 − t 1 ) = d ( g , q ) − λ g ∗ θ ( g , 1 0 − t 1 ) − λ q ∗ θ ( q , 1 0 − t 1 ) d^{\prime}\left(g, q, 10^{-t 1}\right)=d(g, q)-\lambda_{g} * \theta\left(g, 10^{-t 1}\right)-\lambda_{q} * \theta\left(q, 10^{-t 1}\right)d ′(g ,q ,1 0 −t 1 )=d (g ,q )−λg ∗θ(g ,1 0 −t 1 )−λq ∗θ(q ,1 0 −t 1 )
其中θ ( g , 1 0 − t 1 ) \theta\left(g, 10^{-t 1}\right)θ(g ,1 0 −t 1 )是调整画廊集中目标时空特征的值,θ ( q , 1 0 − t 1 ) \theta\left(q, 10^{-t 1}\right)θ(q ,1 0 −t 1 )是调整探针集中对象时空特征的值. λ g \lambda_{g}λg 和λ q \lambda_{q}λq 是确定细化程度的超参数。
参考文献
[43] X. Li, S. J. Maybank, S. Yan, D. Tao, and D. Xu, "Gait components and their application to gender recognition," IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), vol. 38, no. 2, pp. 145–155, 2008.
Original: https://blog.csdn.net/wl1780852311/article/details/124673490
Author: 顾道长生'
Title: (arxiv-2022)具有自适应距离对齐的时空步态特征
相关阅读1
Title: pointnet++代码实现并训练自己的数据集

; 安装pointnet++
1.安装TensorFlow
安装TensorFlow,pointnet++使用的是TensorFlow1.0早期版本,经过多次编译失败以及bug,最终测试1.13.1版本,对应cuda10.0,cudnn7.4.具体查看页面

; 2.安装必要库
tensorflow-gpu==1.13.1
plyfile==0.7.3
numpy==1.16.4
scipy==1.5.2
opencv-python==4.5.2.54
h5py==2.10.0
matplotlib==3.2.2
克隆项目不说了
3.编译定制的 tf_ops 算子
更改nvcc和python路径。需要删除 -D_GLIBCXX_USE_CXX11_ABI=0g++ 命令中的标志才能正确编译

- 修改编译文件,以
/samping/tf_sampling_compile.sh为例
Github上提供的源代码如下,有TF1.2和TF1.4两种版本
/usr/local/cuda-8.0/bin/nvcc tf_sampling_g.cu -o tf_sampling_g.cu.o -c -O2 -DGOOGLE_CUDA=1 -x cu -Xcompiler -fPIC
g++ -std=c++11 tf_sampling.cpp tf_sampling_g.cu.o -o tf_sampling_so.so -shared -fPIC -I /usr/local/lib/python2.7/dist-packages/tensorflow/include -I /usr/local/cuda-8.0/include -lcudart -L /usr/local/cuda-8.0/lib64/ -O2 -D_GLIBCXX_USE_CXX11_ABI=0
为了减少改动,将代码中的CUDA路径和版本改成自己环境的版本,同时将路径用变量表示,替换源代码如下:
CUDA_ROOT=/usr/local/cuda-10.0
TF_ROOT=/home/chengle/anaconda3/envs/pn21/lib/python3.7/site-packages/tensorflow
/usr/local/cuda-10.0/bin/nvcc tf_sampling_g.cu -o tf_sampling_g.cu.o -c -O2 -DGOOGLE_CUDA=1 -x cu -Xcompiler -fPIC
g++ -std=c++11 tf_sampling.cpp tf_sampling_g.cu.o -o tf_sampling_so.so -shared -fPIC -I ${TF_ROOT}/include -I ${CUDA_ROOT}/include -I ${TF_ROOT}/include/external/nsync/public -lcudart -L ${CUDA_ROOT}/lib64/ -L ${TF_ROOT} -ltensorflow_framework -O2
(1).查看CUDA版本方法:
cat /usr/local/cuda/version.txt
或
nvcc -V
(2).查看TensorFlow版本和路径方法:
import tensorflow as tf
print(tf.sysconfig.get_lib())
- *编译代码
在 .sh 文件夹下打开中端,激活环境
conda activate xxxxx
sh tf_sampling_compile.sh
如果生成了 tf_sampling_so.so文件则编译成功,如上过程编译其它的两种操作。( tf_sampling_so.so有大小,如果0kb也是失败了)
最终获得
- 编译
groupingand3d_interpolation代码同上
3.安装好,要让pointnet代码真正运行,还要修改很多代码内容
原文用到python2,我用的是python3.7,有些函数要改,像xrange,print函数
其实我改好了依然跑不起来
原因是我只有一个2080显卡,内存只有8GB,batch_size太大会让内存爆掉,batch_size设置4就还好
后面会继续讲训练过程
数据标注效果

预测效果

Original: https://blog.csdn.net/qq_41092406/article/details/118066551
Author: 易冷cheng
Title: pointnet++代码实现并训练自己的数据集
相关阅读2
Title: iptables防火墙原理详解
Netfilter是由Rusty Russell提出的Linux 2.4内核防火墙框架,该框架既简洁又灵活,可实现安全策略应用中的许多功能,如数据包过滤、数据包处理、地址伪装、透明代理、动态网络地址转换(Network Address Translation,NAT),以及基于用户及媒体访问控制(Media Access Control,MAC)地址的过滤和基于状态的过滤、包速率限制等。Iptables/Netfilter的这些规则可以通过灵活组合,形成非常多的功能、涵盖各个方面,这一切都得益于它的优秀设计思想。
Netfilter是Linux操作系统核心层内部的一个数据包处理模块,它具有如下功能:
- 网络地址转换(Network Address Translate)
- 数据包内容修改
- 以及数据包过滤的防火墙功能
Netfilter 平台中制定了数据包的五个挂载点(Hook Point,我们可以理解为回调函数点,数据包到达这些位置的时候会主动调用我们的函数,使我们有机会能在数据包路由的时候改变它们的方向、内容),这5个挂载点分别是 PRE_ROUTING、 INPUT、 OUTPUT、 FORWARD、 POST_ROUTING。
Netfilter 所设置的规则是存放在内核内存中的,而 iptables 是一个应用层的应用程序,它通过 Netfilter 放出的接口来对存放在内核内存中的 XXtables(Netfilter的配置表)进行修改。这个XXtables由表 tables、链 chains、规则 rules组成,iptables在应用层负责修改这个规则文件。类似的应用程序还有 firewalld 。
1.1 filter、nat、mangle等规则表
filter表
主要用于对数据包进行过滤,根据具体的规则决定是否放行该数据包(如DROP、ACCEPT、REJECT、LOG)。filter 表对应的内核模块为iptable_filter,包含三个规则链:
INPUT链:INPUT针对那些目的地是本地的包FORWARD链:FORWARD过滤所有不是本地产生的并且目的地不是本地(即本机只是负责转发)的包OUTPUT链:OUTPUT是用来过滤所有本地生成的包
nat表
主要用于修改数据包的IP地址、端口号等信息(网络地址转换,如SNAT、DNAT、MASQUERADE、REDIRECT)。属于一个流的包(因为包
的大小限制导致数据可能会被分成多个数据包)只会经过这个表一次。如果第一个包被允许做NAT或Masqueraded,那么余下的包都会自动地被做相同的操作,也就是说,余下的包不会再通过这个表。表对应的内核模块为 iptable_nat,包含三个链:
PREROUTING链:作用是在包刚刚到达防火墙时改变它的目的地址OUTPUT链:改变本地产生的包的目的地址POSTROUTING链:在包就要离开防火墙之前改变其源地址
mangle表
主要用于修改数据包的TOS(Type Of Service,服务类型)、TTL(Time To Live,生存周期)指以及为数据包设置Mark标记,以实现Qos(Quality Of Service,服务质量)调整以及策略路由等应用,由于需要相应的路由设备支持,因此应用并不广泛。包含五个规则链——PREROUTING,POSTROUTING,INPUT,OUTPUT,FORWARD。
raw表
是自1.2.9以后版本的iptables新增的表,主要用于决定数据包是否被状态跟踪机制处理。在匹配数据包时,raw表的规则要优先于其他表。包含两条规则链——OUTPUT、PREROUTING
iptables中数据包和4种被跟踪连接的4种不同状态:
NEW:该包想要开始一个连接(重新连接或将连接重定向)RELATED:该包是属于某个已经建立的连接所建立的新连接。例如:FTP的数据传输连接就是控制连接所 RELATED出来的连接。--icmp-type 0( ping 应答) 就是--icmp-type 8(ping 请求)所RELATED出来的。ESTABLISHED:只要发送并接到应答,一个数据连接从NEW变为ESTABLISHED,而且该状态会继续匹配这个连接的后续数据包。INVALID:数据包不能被识别属于哪个连接或没有任何状态比如内存溢出,收到不知属于哪个连接的ICMP错误信息,一般应该DROP这个状态的任何数据。
1.2 INPUT、FORWARD等规则链和规则
在处理各种数据包时,根据防火墙规则的不同介入时机,iptables供涉及5种默认规则链,从应用时间点的角度理解这些链:
INPUT链:当接收到防火墙本机地址的数据包(入站)时,应用此链中的规则。OUTPUT链:当防火墙本机向外发送数据包(出站)时,应用此链中的规则。FORWARD链:当接收到需要通过防火墙发送给其他地址的数据包(转发)时,应用此链中的规则。PREROUTING链:在对数据包作路由选择之前,应用此链中的规则,如DNAT。POSTROUTING链:在对数据包作路由选择之后,应用此链中的规则,如SNAT。
-->PREROUTING-->[ROUTE]-->FORWARD-->POSTROUTING-->
mangle | mangle ^ mangle
nat | filter | nat
| |
| |
v |
INPUT OUTPUT
| mangle ^ mangle
| filter | nat
v ------>local------->| filter
其中中INPUT、OUTPUT链更多的应用在"主机防火墙"中,即主要针对服务器本机进出数据的安全控制;而FORWARD、PREROUTING、POSTROUTING链更多的应用在"网络防火墙"中,特别是防火墙服务器作为网关使用时的情况。
防火墙处理数据包的方式(规则):
ACCEPT:允许数据包通过DROP:直接丢弃数据包,不给任何回应信息REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息。SNAT:源地址转换。在进入路由层面的route之前,重新改写源地址,目标地址不变,并在本机建立NAT表项,当数据返回时,根据NAT表将目的地址数据改写为数据发送出去时候的源地址,并发送给主机。解决内网用户用同一个公网地址上网的问题。
MASQUERADE,是SNAT的一种特殊形式,适用于像adsl这种临时会变的ip上DNAT:目标地址转换。和SNAT相反,IP包经过route之后、出本地的网络栈之前,重新修改目标地址,源地址不变,在本机建立NAT表项,当数据返回时,根据NAT表将源地址修改为数据发送过来时的目标地址,并发给远程主机。可以隐藏后端服务器的真实地址。
REDIRECT:是DNAT的一种特殊形式,将网络包转发到本地host上(不管IP头部指定的目标地址是啥),方便在本机做端口转发。LOG:在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则
除去最后一个 LOG,前3条规则匹配数据包后,该数据包不会再往下继续匹配了,所以编写的规则顺序极其关键。
我们已经知道了Netfilter和Iptables的架构和作用,并且学习了控制Netfilter行为的Xtables表的结构,那么这个Xtables表是怎么在内核协议栈的数据包路由中起作用的呢?
网口数据包由底层的网卡NIC接收,通过数据链路层的解包之后(去除数据链路帧头),就进入了TCP/IP协议栈(本质就是一个处理网络数据包的内核驱动)和Netfilter混合的数据包处理流程中了。数据包的接收、处理、转发流程构成一个有限状态向量机,经过一些列的内核处理函数、以及Netfilter Hook点,最后被转发、或者本次上层的应用程序消化掉。是时候看这张图了:
从上图中,我们可以总结出以下规律:
- 当一个数据包进入网卡时,数据包首先进入PREROUTING链,在PREROUTING链中我们有机会修改数据包的DestIP(目的IP),然后内核的"路由模块"根据"数据包目的IP"以及"内核中的路由表"判断是否需要转送出去(注意,这个时候数据包的DestIP有可能已经被我们修改过了)
- 如果数据包就是进入本机的(即数据包的目的IP是本机的网口IP),数据包就会沿着图向下移动,到达INPUT链。数据包到达INPUT链后,任何进程都会-收到它
- 本机上运行的程序也可以发送数据包,这些数据包经过OUTPUT链,然后到达POSTROTING链输出(注意,这个时候数据包的SrcIP有可能已经被我们修改过了)
- 如果数据包是要转发出去的(即目的IP地址不再当前子网中),且内核允许转发,数据包就会向右移动,经过FORWARD链,然后到达POSTROUTING链输出(选择对应子网的网口发送出去)
我们在写Iptables规则的时候,要时刻牢记这张路由次序图,根据所在Hook点的不同,灵活配置规则。
命令格式:
[-t 表名]:该规则所操作的哪个表,可以使用filter、nat等,如果没有指定则默认为filter-A:新增一条规则,到该规则链列表的最后一行-I:插入一条规则,原本该位置上的规则会往后顺序移动,没有指定编号则为1-D:从规则链中删除一条规则,要么输入完整的规则,或者指定规则编号加以删除-R:替换某条规则,规则替换不会改变顺序,而且必须指定编号。-P:设置某条规则链的默认动作-nL:-L、-n,查看当前运行的防火墙规则列表chain名:指定规则表的哪个链,如INPUT、OUPUT、FORWARD、PREROUTING等[规则编号]:插入、删除、替换规则时用,--line-numbers显示号码[-i|o 网卡名称]:i是指定数据包从哪块网卡进入,o是指定数据包从哪块网卡输出[-p 协议类型]:可以指定规则应用的协议,包含tcp、udp和icmp等[-s 源IP地址]:源主机的IP地址或子网地址[--sport 源端口号]:数据包的IP的源端口号[-d目标IP地址]:目标主机的IP地址或子网地址[--dport目标端口号]:数据包的IP的目标端口号-m:extend matches,这个选项用于提供更多的匹配参数,如:- -m state —state ESTABLISHED,RELATED
- -m tcp —dport 22
- -m multiport —dports 80,8080
- -m icmp —icmp-type 8
<-j 动作><!---j-->:处理数据包的动作,包括ACCEPT、DROP、REJECT等
Original: https://www.cnblogs.com/AloneSword/p/5079651.html
Author: 孤剑
Title: iptables防火墙原理详解
相关阅读3
Title: Tensorflow GPU版本安装教程,非常详细,建议收藏
Tensorflow GPU版本安装教程,非常详细,建议收藏
文章目录
*
- Tensorflow GPU版本安装教程,非常详细,建议收藏
* 前言
* 一、安装Anaconda
* 二、安装前的准备工作
*
- 1.检查版本
- 1.1 python版本查看:
- 1.2 cuda driver版本查看:
- 2.Tensorflow官网寻找适合自己的版本号
- 3.安装cuda和cdnn
-
+ 3.1 安装cuda
+ 3.2 安装cdnn
- 4.创建虚拟conda环境
- 5.使用pip安装tensorflow-gpu
-
+ 5.1 使用清华镜像
+ 5.2 安装tensorflow-gpu
- 6.在Pycharm中使用
* 总结
前言
我自己看了很多教程终于搞明白了。。。
接下来给大家分享一下,请大家一定按照步骤详细阅读全文,不然可能会掉坑里
一、安装Anaconda
这一步比较简单,也没有太多的需要注意的,去官网下载即可
官网下载传送门

; 二、安装前的准备工作
1.检查版本
我们需要检查的版本有:python的版本,cuda的版本(带n卡的电脑一般会默认安装好了cuda的driver包,但是tensoflow-gpu所需要的其他cuda组件仍然需要安装)
1.1 python版本查看:
在开始菜单栏打开Anaconda Prompt,以管理员身份运行,输入python,回车即可

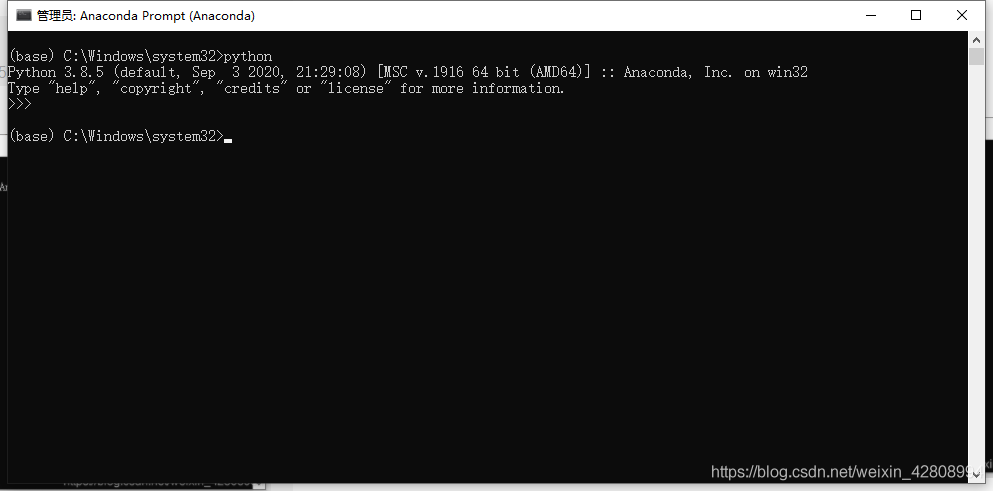
; 1.2 cuda driver版本查看:
按下图操作查看版本号
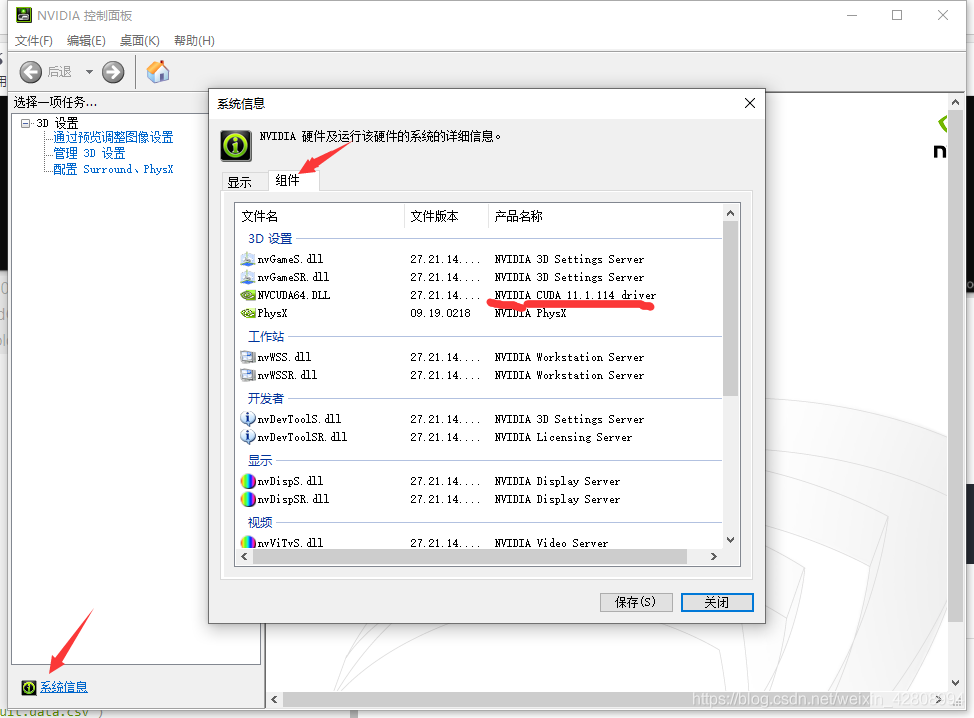
2.Tensorflow官网寻找适合自己的版本号
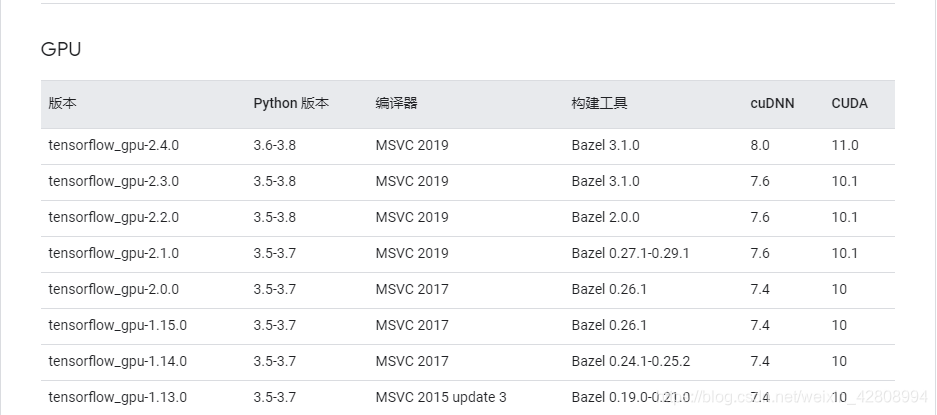
注意CUDA版本与显卡的对应关系,注意tensorflow-gpu和cuDNN之间版本的对应,版本对应关系具体请参考Tensorflow官网,如下图所示:
CDNN下载链接
CUDA下载链接
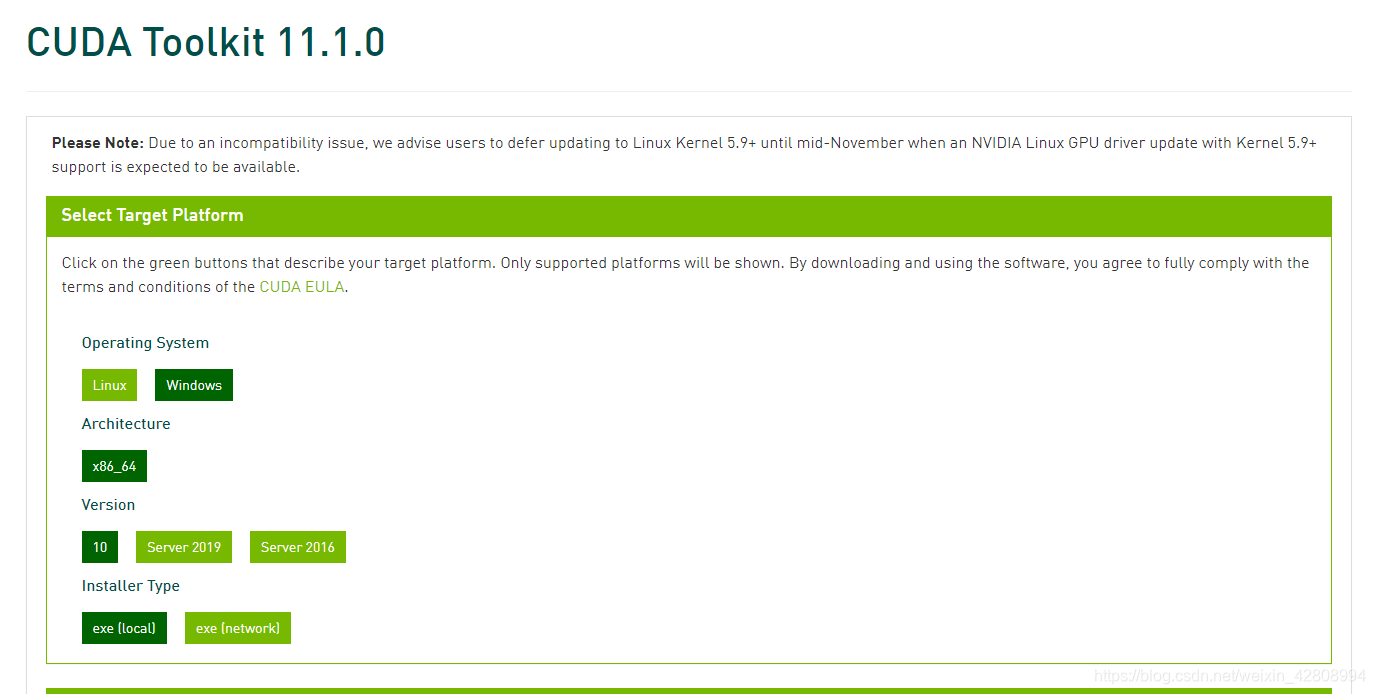
博主自己选择的版本发出来供大家参考:
注意!!!!
我们下载的cuda版本一定要低于或等于我们刚刚在英伟达控制面板查看的cuda driver版本

; 3.安装cuda和cdnn
3.1 安装cuda
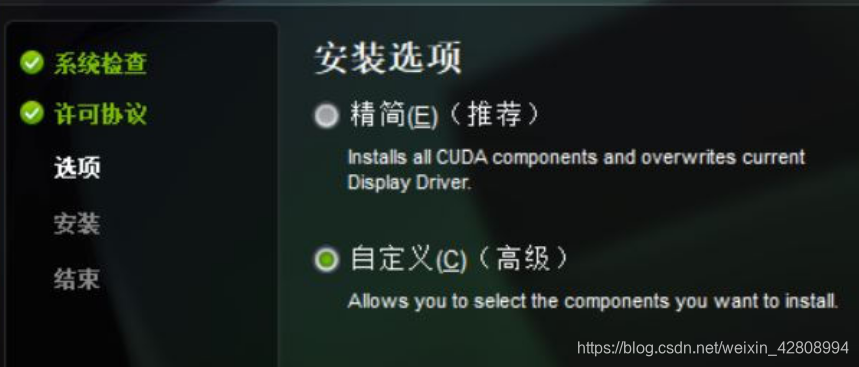
这里如果已经有了cuda driver(就是我们之前在英伟达控制面板看到的版本号)了的话,就取消勾选
; 3.2 安装cdnn
将cdnn解压以后的所有文件复制到cuda安装目录
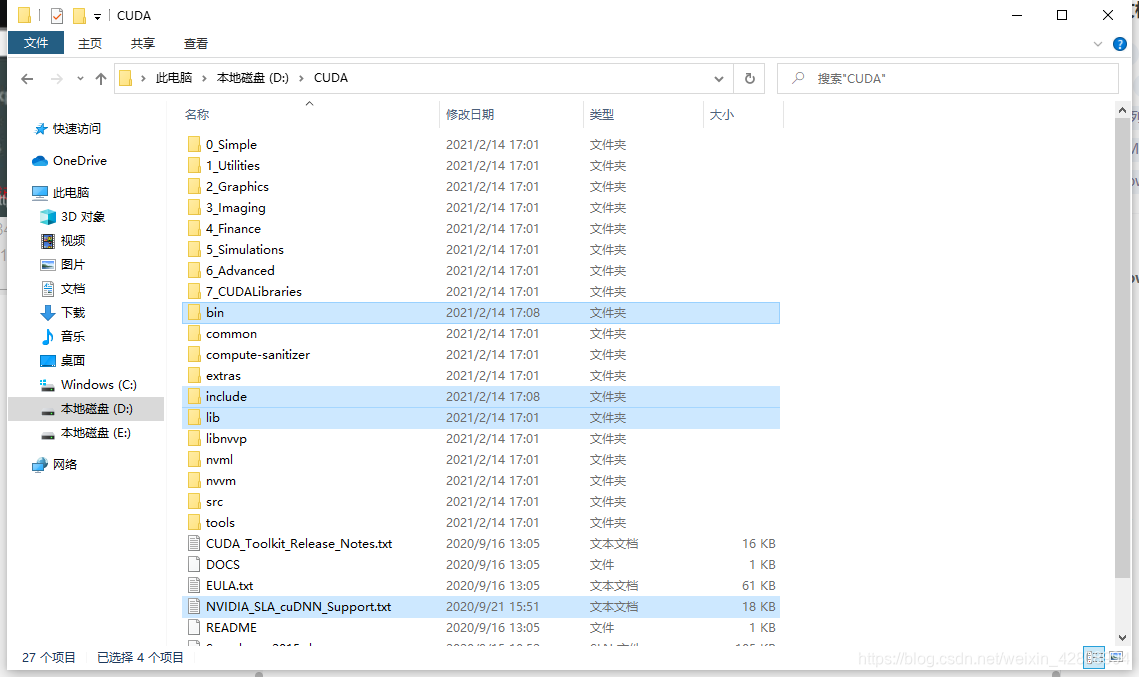
4.创建虚拟conda环境
由于我在base环境中已经装过了pytorch以及其他很多组件,这里我们最好是给tensorflow单独创建一个虚拟环境。
conda create -n tensorflow_gpu python=3.8
激活环境
activate tensorflow_gpu
5.使用pip安装tensorflow-gpu
5.1 使用清华镜像
临时使用
package-name为你要下载的包名
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple package-name
永久使用
pip install pip -U
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
5.2 安装tensorflow-gpu
选择之前找到的适合自己的版本
pip install tensorflow-gpu-x.x.x
我这里不带版本号默认下载了最新版
安装成功示意图
接下来测试一下是否可以使用了
import tensorflow as tf
print(tf.__version__)
print(tf.test.is_gpu_available())
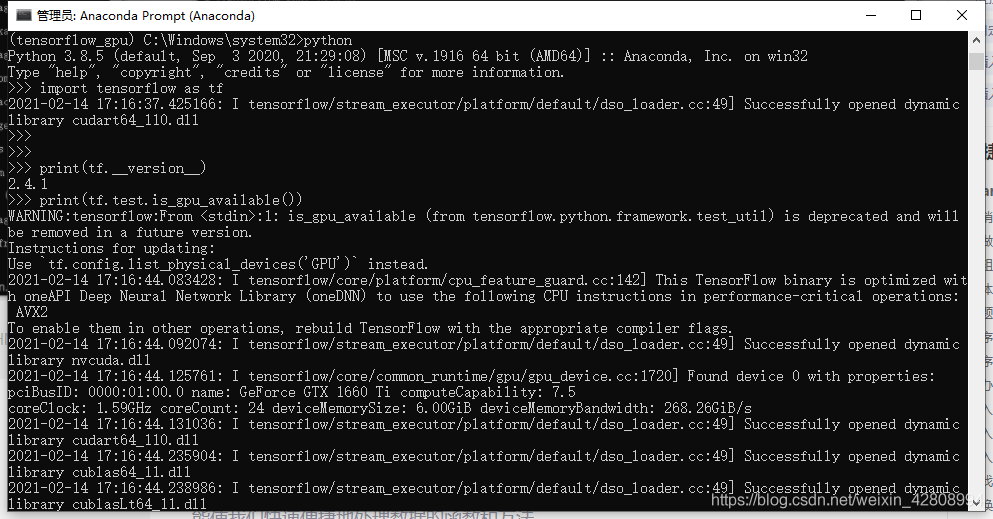
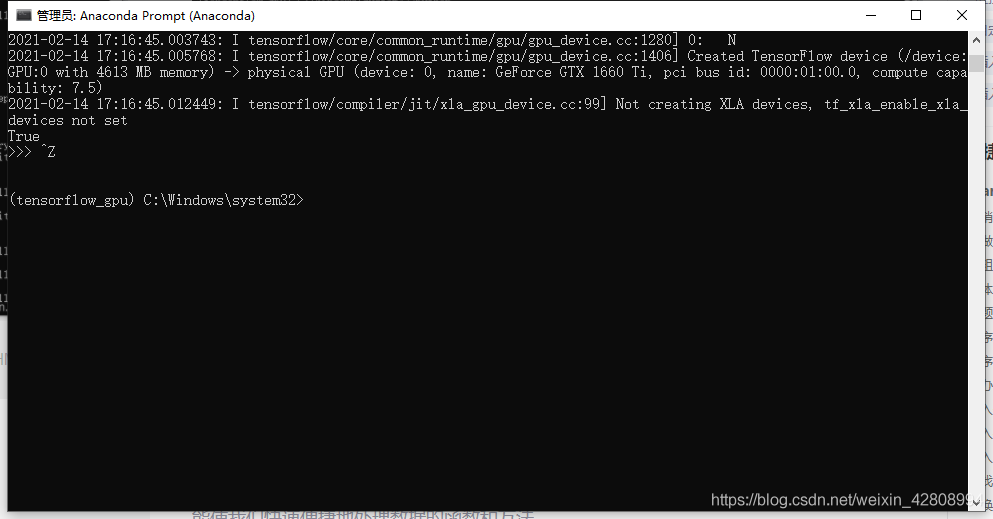
成功了!!
6.在Pycharm中使用
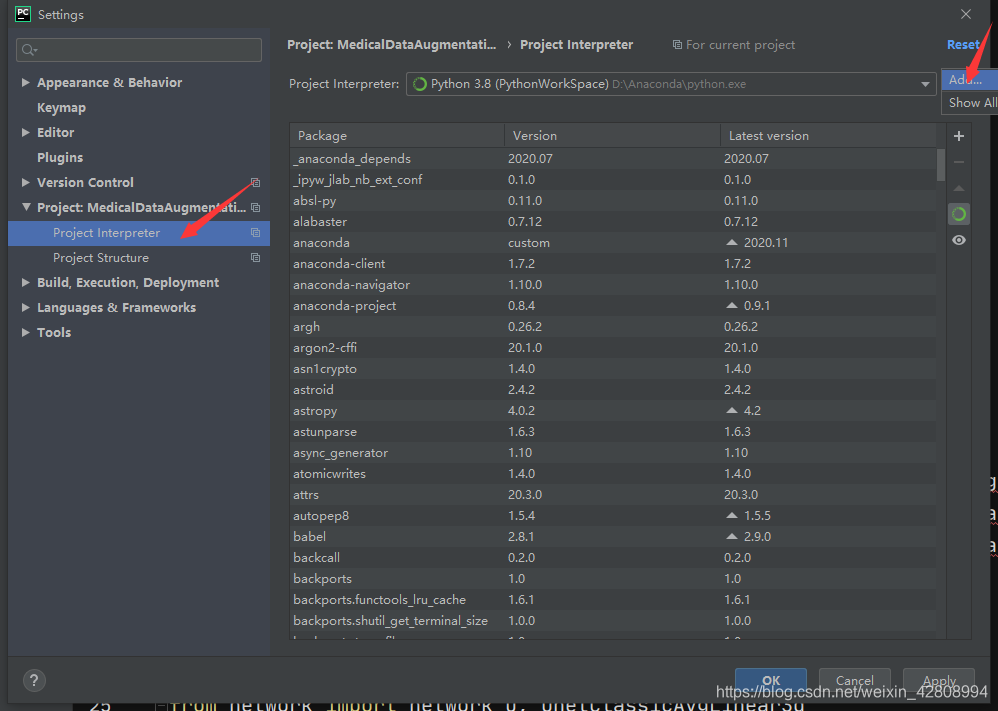
在如图所示目录找到我们配置的tensorflow_gpu虚拟环境,选择python.exe
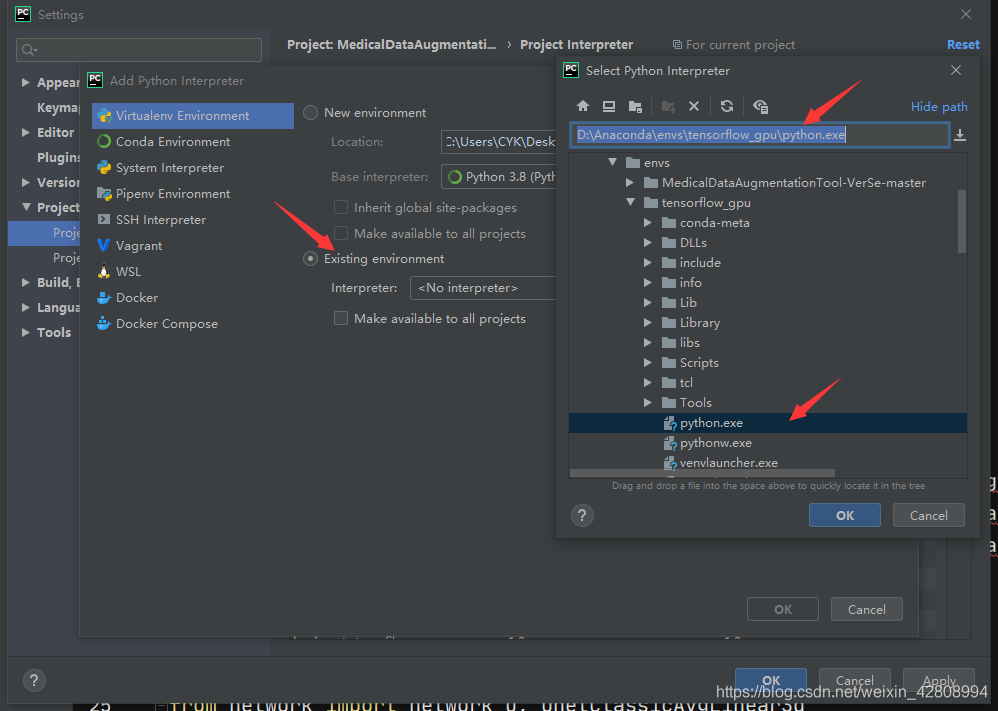
恭喜你已经成功配置好了所有环境,可以开始撸代码了!
; 总结
以上就是所有的内容了,谢谢大家。
Original: https://blog.csdn.net/weixin_42808994/article/details/113809484
Author: EminemBest
Title: Tensorflow GPU版本安装教程,非常详细,建议收藏